Создание агентов ИИ в коде
В этой статье показано, как создать агент ИИ в коде с помощью MLflow ChatModel. Azure Databricks использует MLflow ChatModel для обеспечения совместимости с функциями агента ИИ Databricks, такими как оценка, трассировка и развертывание.
Что такое ChatModel?
ChatModel — это класс MLflow, предназначенный для упрощения создания агентов общения СИ. Это обеспечивает стандартизированный интерфейс для построения моделей, совместимых с API ChatCompletion OpenAI .
ChatModel расширяет схему ChatCompletion от OpenAI. Этот подход позволяет поддерживать широкую совместимость с платформами, поддерживающими стандарт ChatCompletion, а также добавлять собственные пользовательские функции.
С помощью ChatModelразработчики могут создавать агенты, совместимые с средствами Databricks и MLflow для отслеживания агентов, оценки и управления жизненным циклом, которые необходимы для развертывания готовых к работе моделей.
См. MLflow: начало работы с ChatModel.
Требования
Databricks рекомендует установить последнюю версию клиента Python MLflow при разработке агентов.
Чтобы создавать и развертывать агентов с помощью подхода, описанного в этой статье, необходимо удовлетворять следующим требованиям:
- Установите
databricks-agentsверсии 0.15.0 и более поздней - Установите
mlflowверсии 2.20.0 и более поздней
%pip install -U -qqqq databricks-agents>=0.15.0 mlflow>=2.20.0
Создание агента ChatModel
Вы можете создать вашего агента в качестве подкласса mlflow.pyfunc.ChatModel. Этот метод предоставляет следующие преимущества:
- Позволяет писать код агента, совместимый со схемой ChatCompletion с помощью типизированных классов Python.
- MLflow автоматически определяет подпись, совместимую с завершением чата, при регистрации агента, даже без
input_example. Это упрощает процесс регистрации и развертывания агента. См. сигнатуру инферентного вывода модели при логировании.
Следующий код лучше всего выполняется в записной книжке Databricks. Блокноты обеспечивают удобную среду для разработки, тестирования и итерации вашего агента.
Класс MyAgent расширяет mlflow.pyfunc.ChatModel, реализуя необходимый метод predict. Это обеспечивает совместимость с Платформой агента ИИ Мозаики.
Класс также включает необязательные методы _create_chat_completion_chunk и predict_stream для обработки выходных данных потоковой передачи.
from dataclasses import dataclass
from typing import Optional, Dict, List, Generator
from mlflow.pyfunc import ChatModel
from mlflow.types.llm import (
# Non-streaming helper classes
ChatCompletionRequest,
ChatCompletionResponse,
ChatCompletionChunk,
ChatMessage,
ChatChoice,
ChatParams,
# Helper classes for streaming agent output
ChatChoiceDelta,
ChatChunkChoice,
)
class MyAgent(ChatModel):
"""
Defines a custom agent that processes ChatCompletionRequests
and returns ChatCompletionResponses.
"""
def predict(self, context, messages: list[ChatMessage], params: ChatParams) -> ChatCompletionResponse:
last_user_question_text = messages[-1].content
response_message = ChatMessage(
role="assistant",
content=(
f"I will always echo back your last question. Your last question was: {last_user_question_text}. "
)
)
return ChatCompletionResponse(
choices=[ChatChoice(message=response_message)]
)
def _create_chat_completion_chunk(self, content) -> ChatCompletionChunk:
"""Helper for constructing a ChatCompletionChunk instance for wrapping streaming agent output"""
return ChatCompletionChunk(
choices=[ChatChunkChoice(
delta=ChatChoiceDelta(
role="assistant",
content=content
)
)]
)
def predict_stream(
self, context, messages: List[ChatMessage], params: ChatParams
) -> Generator[ChatCompletionChunk, None, None]:
last_user_question_text = messages[-1].content
yield self._create_chat_completion_chunk(f"Echoing back your last question, word by word.")
for word in last_user_question_text.split(" "):
yield self._create_chat_completion_chunk(word)
agent = MyAgent()
model_input = ChatCompletionRequest(
messages=[ChatMessage(role="user", content="What is Databricks?")]
)
response = agent.predict(context=None, model_input=model_input)
print(response)
Хотя класс агента MyAgent определен в одной записной книжке, следует создать отдельную записную книжку драйвера. Записная книжка драйвера регистрирует агента в реестре моделей и развертывает его с помощью обслуживания моделей.
Это разделение процесса следует рекомендуемому рабочему процессу Databricks для логирования моделей с использованием методологии Models from Code MLflow.
Пример: обернуть LangChain в ChatModel
Если у вас есть существующую модель LangChain и хотите интегрировать ее с другими функциями агента ИИ Мозаики, вы можете упаковать ее в ChatModel MLflow, чтобы обеспечить совместимость.
В этом примере кода выполняются следующие действия для того, чтобы обернуть выполнение LangChain в ChatModel:
- Обрамите результат работы LangChain с помощью
mlflow.langchain.output_parsers.ChatCompletionOutputParser, чтобы создать подпись завершения чата. - Класс
LangchainAgentрасширяетmlflow.pyfunc.ChatModelи реализует два ключевых метода:-
predict: обрабатывает синхронные прогнозы, вызывая цепочку и возвращая форматированный ответ. -
predict_stream: обрабатывает прогнозы потоковой передачи, вызывая цепочку и предоставляя блоки ответов.
-
from mlflow.langchain.output_parsers import ChatCompletionOutputParser
from mlflow.pyfunc import ChatModel
from typing import Optional, Dict, List, Generator
from mlflow.types.llm import (
ChatCompletionResponse,
ChatCompletionChunk
)
chain = (
<your chain here>
| ChatCompletionOutputParser()
)
class LangchainAgent(ChatModel):
def _prepare_messages(self, messages: List[ChatMessage]):
return {"messages": [m.to_dict() for m in messages]}
def predict(
self, context, messages: List[ChatMessage], params: ChatParams
) -> ChatCompletionResponse:
question = self._prepare_messages(messages)
response_message = self.chain.invoke(question)
return ChatCompletionResponse.from_dict(response_message)
def predict_stream(
self, context, messages: List[ChatMessage], params: ChatParams
) -> Generator[ChatCompletionChunk, None, None]:
question = self._prepare_messages(messages)
for chunk in chain.stream(question):
yield ChatCompletionChunk.from_dict(chunk)
Использование параметров для настройки агента
В фреймворке агентов можно использовать параметры для управления выполнением агентов. Это позволяет быстро выполнять итерацию по различным характеристикам агента, не изменяя код. Параметры — это пары "ключ-значение", которые определяются в словаре Python или в файле .yaml.
Чтобы настроить код, создайте ModelConfig, набор параметров key-value.
ModelConfig — это словарь Python или файл .yaml. Например, можно использовать словарь во время разработки, а затем преобразовать его в файл .yaml для рабочего развертывания и CI/CD. Дополнительные сведения о ModelConfigсм. в документации по MLflow.
Ниже показан пример ModelConfig.
llm_parameters:
max_tokens: 500
temperature: 0.01
model_serving_endpoint: databricks-dbrx-instruct
vector_search_index: ml.docs.databricks_docs_index
prompt_template: 'You are a hello world bot. Respond with a reply to the user''s
question that indicates your prompt template came from a YAML file. Your response
must use the word "YAML" somewhere. User''s question: {question}'
prompt_template_input_vars:
- question
Чтобы вызвать конфигурацию из кода, используйте одно из следующих действий:
# Example for loading from a .yml file
config_file = "configs/hello_world_config.yml"
model_config = mlflow.models.ModelConfig(development_config=config_file)
# Example of using a dictionary
config_dict = {
"prompt_template": "You are a hello world bot. Respond with a reply to the user's question that is fun and interesting to the user. User's question: {question}",
"prompt_template_input_vars": ["question"],
"model_serving_endpoint": "databricks-dbrx-instruct",
"llm_parameters": {"temperature": 0.01, "max_tokens": 500},
}
model_config = mlflow.models.ModelConfig(development_config=config_dict)
# Use model_config.get() to retrieve a parameter value
value = model_config.get('sample_param')
Установка схемы извлекателя
Агенты ИИ часто используют ретриверы, тип инструмента агента, который находит и возвращает соответствующие документы с помощью индекса векторного поиска. Дополнительные сведения об инструментах извлечения данных см. в инструментах неструктурированного извлечения агентов ИИ.
Чтобы обеспечить правильную трассировку извлекателей, вызовите mlflow.models.set_retriever_schema при определении агента в коде. Используйте set_retriever_schema для сопоставления имен столбцов в возвращаемой таблице ожидаемым полям MLflow, таким как primary_key, text_columnи doc_uri.
# Define the retriever's schema by providing your column names
# These strings should be read from a config dictionary
mlflow.models.set_retriever_schema(
name="vector_search",
primary_key="chunk_id",
text_column="text_column",
doc_uri="doc_uri"
# other_columns=["column1", "column2"],
)
Заметка
Столбец doc_uri особенно важен при оценке производительности ретривера.
doc_uri — это основной идентификатор документов, возвращаемых извлекателем, позволяющий сравнить их с эталонными оценочными наборами данных. См. наборы оценок.
Можно также указать дополнительные столбцы в схеме извлекателя, указав список имен столбцов с полем other_columns.
Если у вас несколько извлекателей, можно определить несколько схем с помощью уникальных имен для каждой схемы извлекателя.
настраиваемые входы и выходы
В некоторых сценариях могут потребоваться дополнительные входные данные агентов, такие как client_type и session_id, или выходные данные, такие как ссылки на источник извлечения, которые не должны быть включены в журнал чата для будущих взаимодействий.
В этих сценариях MLflow ChatModel изначально поддерживает расширение запросов на завершение чата и ответов OpenAI с помощью полей ChatParams и custom_inputcustom_output.
Ознакомьтесь со следующими примерами, чтобы узнать, как создавать пользовательские входные и выходные данные для агентов PyFunc и LangGraph.
Предупреждение
Приложение для проверки агентов пока не поддерживает рендеринг трассировки для агентов с дополнительными полями ввода.
пользовательские схемы PyFunc
В следующих записных книжках показан пример пользовательской схемы с помощью PyFunc.
Записная книжка агента пользовательской схемы PyFunc
Записная книжка драйвера пользовательской схемы PyFunc
пользовательские схемы LangGraph
В следующих записных книжках показан пример пользовательской схемы с помощью LangGraph. Вы можете изменить функцию wrap_output в записных книжках, чтобы проанализировать и извлечь информацию из потока сообщений.
Записная книжка агента пользовательской схемы LangGraph
Записная книжка с пользовательской схемой драйвера LangGraph
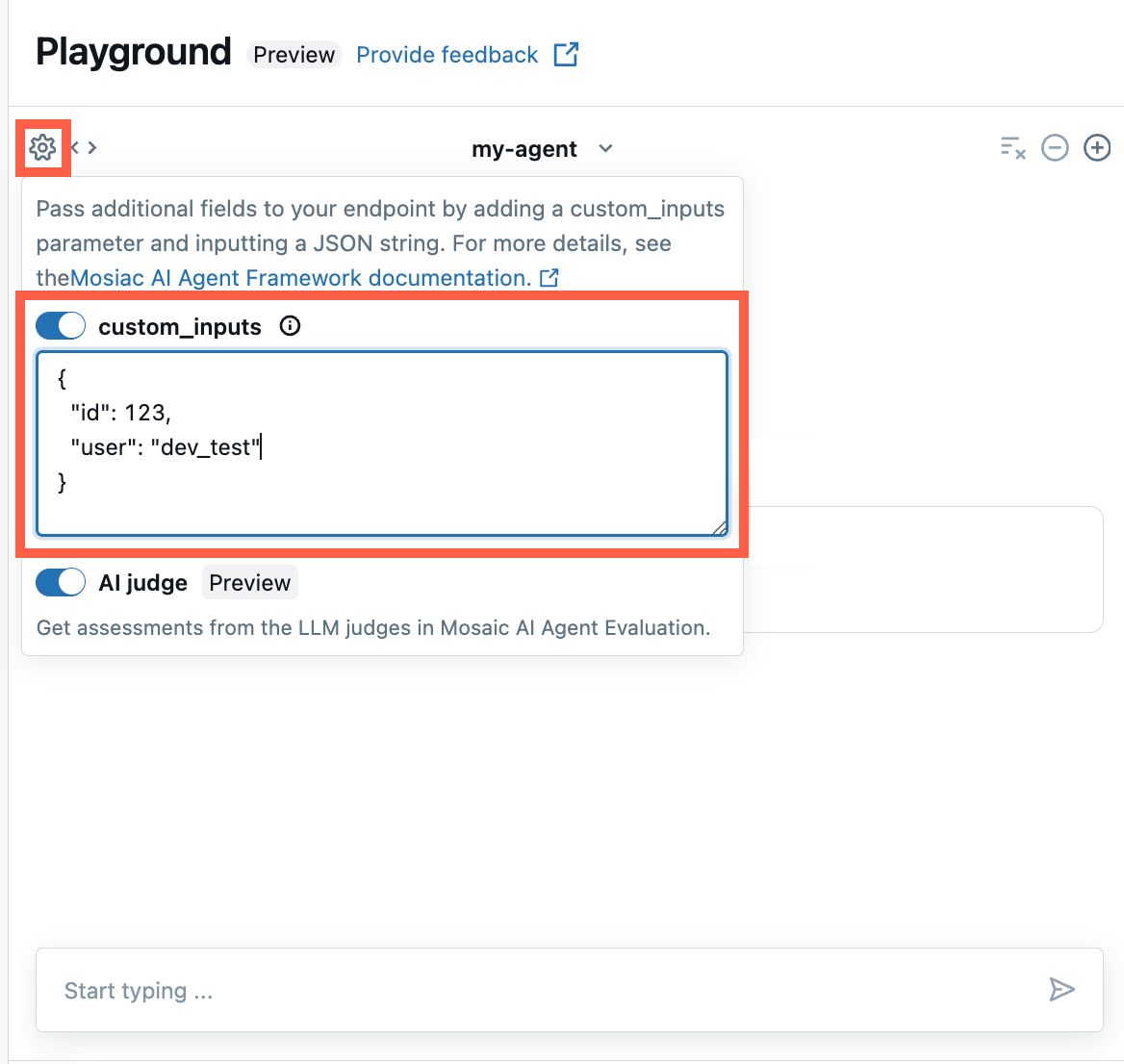
Предоставить custom_inputs в песочнице ИИ и приложении для проверки агента
Если ваш агент принимает дополнительные входные данные с помощью поля custom_inputs, вы можете вручную ввести эти данные как в AI Playground, так и в приложении для проверки агента .
В среде ИИ Плейграунд или в приложении для проверки агентов выберите значок шестеренки
 .
.Включите custom_inputs.
Укажите объект JSON, соответствующий определенной схеме входных данных агента.
Распространение ошибок потоковой передачи
Распространение мозаичного ИИ любых ошибок, встреченных при потоковой передаче с последним токеном под databricks_output.error. От вызывающего клиента зависит правильная обработка и отображение этой ошибки.
{
"delta": …,
"databricks_output": {
"trace": {...},
"error": {
"error_code": BAD_REQUEST,
"message": "TimeoutException: Tool XYZ failed to execute"
}
}
}
примеры записных книжек
Эти блокноты создают простую цепочку "Hello, world" для иллюстрации создания агента в Databricks. Первый пример создает простую цепочку, а второй пример записной книжки показывает, как использовать параметры для минимизации изменений кода во время разработки.