Необходимые действия клиента
Предварительный инцидент
Для служб Azure
- Ознакомьтесь со службой Работоспособности служб Azure в портал Azure. Эта страница будет выступать в качестве "однократного магазина" во время инцидента.
- Рассмотрите возможность использования оповещений о работоспособности служб, которые можно настроить для автоматического создания уведомлений при возникновении инцидентов Azure.
Для Power BI
- Будьте знакомы со службой работоспособности в Центр администрирования Microsoft 365. Эта страница будет выступать в качестве "однократного магазина" во время инцидента.
- Рассмотрите возможность использования мобильного приложения администратора Microsoft 365 для получения уведомлений об автоматическом предупреждении об инциденте службы.
Во время инцидента
Для служб Azure
- Работоспособность службы Azure на портале управления Azure предоставит последние обновления.
- Если последствия или проблемы не соответствуют инциденту (или сохраняются после устранения рисков), обратитесь в службу поддержки , чтобы получить запрос в службу поддержки.
Для Power BI
- Страница работоспособности служб в Центр администрирования Microsoft 365 предоставит последние обновления
- Если возникли проблемы с доступом к работоспособности службы, перейдите на страницу состояния Microsoft 365
- Если влияние и проблемы не соответствуют инциденту (или если проблемы сохраняются после устранения рисков), необходимо вызвать запрос в службу поддержки.
После восстановления Майкрософт
Дополнительные сведения см. в разделах ниже.
Инцидент после публикации
Для служб Azure
- Корпорация Майкрософт опубликует ПИР в портал Azure — работоспособности служб для проверки.
Для Power BI
- Корпорация Майкрософт опубликует ПИР для администратора Microsoft 365 — работоспособности служб для проверки.
Ожидание процесса Майкрософт
Процесс "Ожидание майкрософт" просто ждет, пока корпорация Майкрософт восстановит все компоненты и службы в затронутом регионе. После восстановления проверьте привязку платформы данных к корпоративным общим или другим службам, дате набора данных, а затем выполните процессы приведения системы к текущей дате.
После завершения этого процесса можно завершить проверку эксперта по техническим и бизнес-темам (SME), чтобы обеспечить одобрение заинтересованных лиц для восстановления службы.
Повторное развертывание при аварийном развертывании
Для стратегии "Повторное развертывание по аварийному развертыванию" можно описать следующий высокоуровневый поток процесса.
Восстановление корпоративных общих служб и исходных систем Contoso

- Этот шаг является обязательным условием для восстановления платформы данных.
- Этот шаг будет выполнен различными группами поддержки компании Contoso, отвечающими за общие службы предприятия и операционные системы.
Восстановление служб Azure служб Azure относится к приложениям и службам, которые делают предложение Azure Cloud, доступны в дополнительном регионе для развертывания.

Службы Azure относятся к приложениям и службам, которые делают предложение Azure Cloud, доступны в дополнительном регионе для развертывания.
- Этот шаг является обязательным условием для восстановления платформы данных.
- Этот шаг будет выполнен корпорацией Майкрософт и другими платформами как услуга (PaaS)/software как услуга (SaaS).
Восстановление основы платформы данных
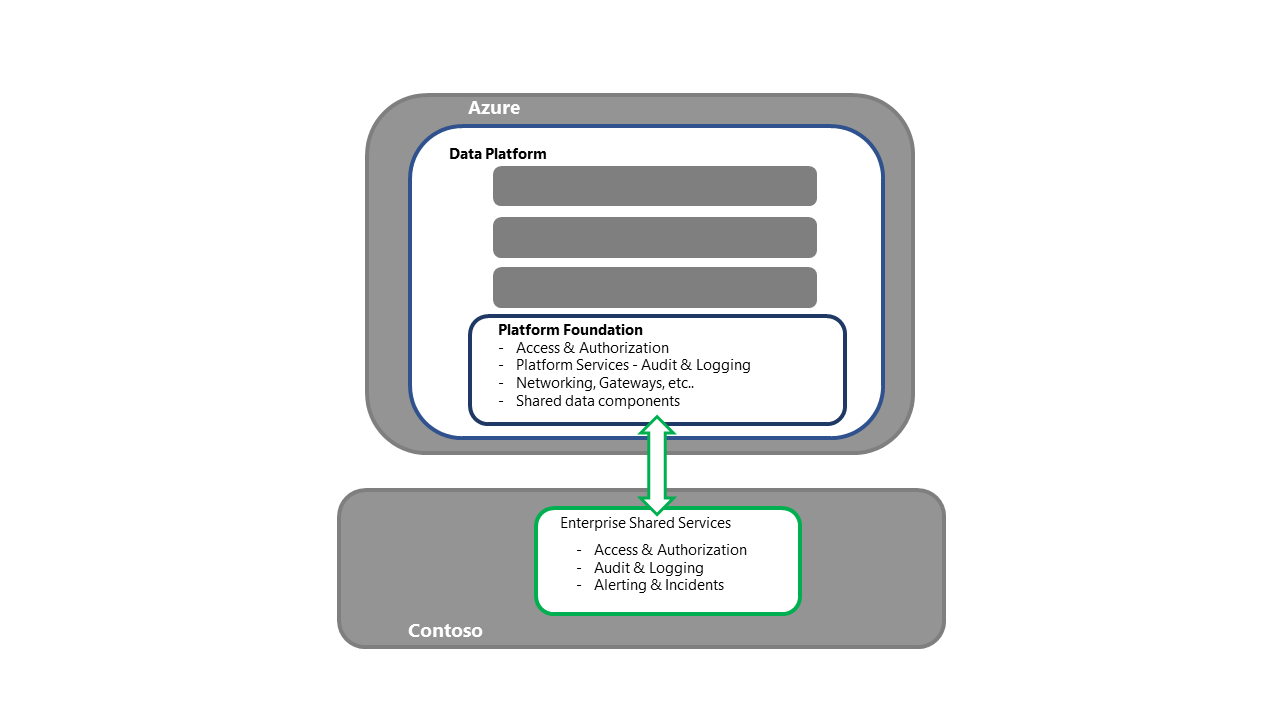
- Этот шаг является точкой входа для действий восстановления платформы.
- Для стратегии повторного развертывания все необходимые компоненты или службы будут приобретены и развернуты в дополнительном регионе.
- Подробные сведения о компонентах и стратегиях развертывания см. в разделе службы Azure и компонента в этой серии.
- Этот процесс также должен включать такие действия, как привязка к корпоративным общим службам, обеспечение подключения к доступу и проверке работы разгрузки журнала, а также обеспечение подключения как к вышестоящим, так и к подчиненным процессам.
- Данные и обработка должны быть подтверждены. Например, проверка метки времени восстановленной платформы.
- Если есть вопросы о целостности данных, решение может быть принято для отката еще больше времени, прежде чем выполнять новую обработку, чтобы обеспечить актуальность платформы.
- Наличие приоритета для процессов (на основе влияния на бизнес) поможет в оркестрации восстановления.
- Этот шаг должен быть закрыт технической проверкой, если бизнес-пользователи напрямую не взаимодействуют со службами. Если есть прямой доступ, потребуется выполнить проверку бизнеса.
- После завершения проверки выполняется передача отдельным группам решений для запуска собственного процесса аварийного восстановления (АВАРИЙНОго восстановления).
- Этот переход должен включать подтверждение текущей метки времени данных и процессов.
- Если будут выполняться основные корпоративные процессы данных, отдельные решения должны быть осведомлены об этом — исходящие или исходящие потоки, например.
Восстановление отдельных решений, размещенных платформой
- Каждое отдельное решение должно иметь собственный модуль Runbook аварийного восстановления. Модули Runbook должны, по крайней мере, содержать назначенных заинтересованных лиц бизнеса, которые будут тестировать и подтвердить, что восстановление службы завершено.
- В зависимости от конфликтов ресурсов или приоритета ключевые решения и рабочие нагрузки могут быть приоритетными по сравнению с другими — основными корпоративными процессами по поводу нерегламентированных лабораторий, например.
- После завершения проверки переключение на подчиненные решения для запуска процесса восстановления аварийного восстановления происходит.
Передача в подчиненные, зависимые системы
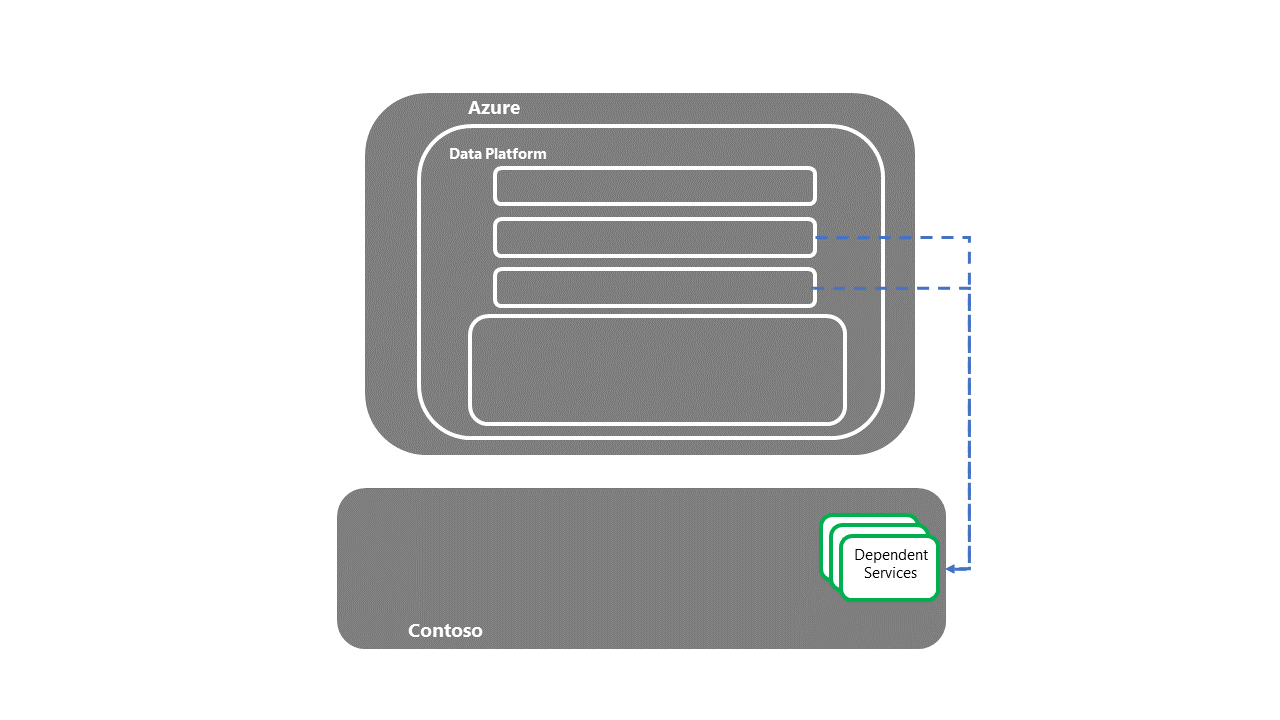
- После восстановления зависимых служб процесс восстановления аварийного восстановления E2E завершится.
Примечание.
Хотя теоретически можно полностью автоматизировать процесс аварийного восстановления E2E, маловероятно, учитывая риск события и затраты на действия SDLC, необходимые для покрытия процесса E2E.
Резервная копия основного региона — это процесс перемещения службы платформы данных и его данных обратно в основной регион после того, как он будет доступен для BAU.
В зависимости от характера исходных систем и различных процессов обработки данных резервная часть платформы данных может выполняться независимо от других частей экосистемы данных.
Клиентам рекомендуется проверить зависимости собственной платформы данных (как выше, так и ниже), чтобы принять соответствующее решение. В следующем разделе предполагается независимое восстановление платформы данных.
- После того как все необходимые компоненты и службы становятся доступными в основном регионе, клиенты завершат тестирование дыма для проверки восстановления Майкрософт.
- Будет проверена конфигурация компонента или службы. Разностные изменения будут устранены путем повторного развертывания из системы управления версиями.
- Системная дата в основном регионе будет установлена в компонентах с отслеживанием состояния. Разница между установленной датой и меткой даты и времени в дополнительном регионе должна быть устранена путем повторного выполнения или повторной обработки приема данных с этого момента.
- При утверждении от деловых и технических заинтересованных лиц будет выбрано резервное окно. В идеале это должно произойти во время затухания в системном действии и обработке.
- Во время резервной передачи основной регион будет синхронизирован с дополнительным регионом, прежде чем система была переключена.
- После параллельного выполнения дополнительный регион будет отключен от системы.
- Компоненты в дополнительном регионе будут удалены или удалены обратно в зависимости от выбранной стратегии аварийного восстановления.
Теплый резервный процесс
Для стратегии "Теплый запас" поток процесса высокого уровня тесно соответствует тому, что "Повторное развертывание по катастрофе", основное различие заключается в том, что компоненты уже были приобретены в дополнительном регионе. Эта стратегия устраняет риск возникновения несоответствия ресурсов от других организаций, желающих завершить собственное аварийное восстановление в этом регионе.
Горячий резервный процесс
Стратегия "Горячий запас" означает, что службы платформы, включая PaaS и инфраструктуру как услуга (IaaS), будут сохраняться, несмотря на событие аварии, так как вторичные системы выполняются в тандеме с основными системами. Как и в случае с стратегией "Теплый запас", эта стратегия устраняет риск возникновения несоответствия ресурсов от других организаций, желающих завершить собственное аварийное восстановление в этом регионе.
Клиенты Hot Spare отслеживают восстановление компонентов и служб Майкрософт в основном регионе. После завершения клиенты проверят системы основного региона и завершают резервное восстановление в основном регионе. Этот процесс будет похож на процесс отработки отказа аварийного восстановления, то есть проверьте доступную базу кода и данные, повторно развертывая по мере необходимости.
Примечание.
Следует отметить, что все системные метаданные согласованы между двумя регионами.
- После завершения резервного копирования к основному элементу системные подсистемы балансировки нагрузки можно обновить, чтобы вернуть основной регион в системную топологию. При наличии подход к выпуску канарной версии можно использовать для добавочного переключения основного региона в системе.
Структура плана аварийного восстановления
Эффективный план аварийного восстановления представляет пошаговое руководство по восстановлению службы, которое может выполняться техническим ресурсом Azure. Таким образом, в следующем списке представлена предлагаемая структура MVP для плана аварийного восстановления.
- Требования к процессу
- Все сведения о процессе аварийного восстановления клиента, такие как правильная авторизация, необходимая для запуска аварийного восстановления, и принятие ключевых решений о восстановлении по мере необходимости (включая "определение готово"), справочные материалы службы поддержки аварийного восстановления и сведения о военном помещении.
- Подтверждение ресурса, включая резервное копирование потенциальных и исполнителей аварийного восстановления. Все ресурсы должны быть задокументированы с основными и вторичными контактами, путями эскалации и оставлять календари. В критических ситуациях аварийного восстановления может потребоваться рассмотреть систему реестра.
- Ноутбук, пакеты питания или резервное копирование, сетевое подключение и мобильный телефон для исполнителя аварийного восстановления, резервного копирования аварийного восстановления и любых точек эскалации.
- Процесс, который следует выполнить, если какие-либо из требований процесса не выполнены.
- Список контактов
- Руководство аварийного восстановления и группы поддержки.
- Бизнес-компании, которые завершат цикл тестирования и проверки для технического восстановления.
- Затронутые владельцы бизнеса, в том числе утверждающие службы восстановления.
- Затронутые технические владельцы, включая утверждающих техническое восстановление.
- Поддержка SME во всех затронутых областях, включая ключевые решения, размещенные платформой.
- Затронутые подчиненные системы — операционная поддержка.
- Вышестоящей исходной системы — операционная поддержка.
- Контакты корпоративных общих служб. Например, поддержка доступа и проверки подлинности, мониторинг безопасности и поддержка шлюза
- Любые внешние или сторонние поставщики, включая контакты поддержки для поставщиков облачных служб.
- Проектирование архитектуры
- Подробно опишите полный сценарий (E2E) и вложите всю связанную документацию по поддержке.
- Зависимости
- Выведите список всех связей компонентов и зависимостей.
- Предварительные требования для аварийного восстановления
- Подтверждение того, что вышестоящей исходной системы доступны по мере необходимости.
- Повышенный доступ к стеку предоставляется ресурсам исполнителя аварийного восстановления.
- Службы Azure доступны по мере необходимости.
- Процесс, который следует выполнить, если какие-либо из предварительных требований не выполнены.
- Техническое восстановление — пошаговые инструкции
- Порядок выполнения.
- Описание шага.
- Предварительные требования к шагу.
- Подробные шаги процесса для каждого дискретного действия, включая URL-адреса.
- Инструкции по проверке, включая необходимые доказательства.
- Ожидаемое время выполнения каждого шага, включая непредвиденные ситуации.
- Процесс, который следует выполнить, если шаг завершается ошибкой.
- Точки эскалации в случае сбоя или поддержки SME.
- Техническое восстановление — необходимые компоненты
- Подтвердите текущую метку времени даты системы в ключевых компонентах.
- Подтвердите URL-адреса системы аварийного восстановления и IP-адреса.
- Подготовьтесь к процессу проверки заинтересованных лиц, включая подтверждение доступа к системам и бизнес-предприятиям, завершив проверку и утверждение.
- Обзор и утверждение бизнес-заинтересованных лиц
- Контактные данные о бизнес-ресурсах.
- Действия по проверке бизнеса согласно приведенному выше техническому восстановлению.
- След доказательств, необходимый от утверждающего предприятия, подписывал восстановление.
- Требования после восстановления
- Передача операционной поддержки для выполнения процессов данных для обновления системы.
- Передача подчиненных процессов и решений — подтверждение сведений о дате и подключении системы аварийного восстановления.
- Убедитесь, что процесс восстановления завершен с помощью свинца аварийного восстановления — подтверждение следа доказательств и завершенного модуля Runbook.
- Уведомите команды безопасности о том, что повышенные привилегии доступа можно удалить из команды аварийного восстановления.
Выноски
- Рекомендуется включить системные снимки экрана каждого этапа. Эти снимки экрана помогут устранить зависимость от системных SMEs для выполнения задач.
- Чтобы быстро развиваться облачные службы, план аварийного восстановления должен регулярно изменяться, тестироваться и выполняться ресурсами с текущими знаниями о Azure и ее службах.
- Шаги технического восстановления должны отражать приоритет компонента и решения для организации. Например, основные корпоративные потоки данных восстанавливаются перед нерегламентированными лабораториями анализа данных.
- Шаги технического восстановления должны соответствовать порядку рабочих процессов (обычно слева направо), после восстановления основных компонентов или служб, таких как Key Vault. Эта стратегия обеспечит доступность зависимостей вышестоящего потока, а компоненты можно протестировать соответствующим образом.
- После завершения пошагового плана необходимо получить общее время для действий с непредвиденными обстоятельствами. Если общая сумма превышает согласованную цель времени восстановления (RTO), доступны несколько вариантов:
- Автоматизируйте выбранные процессы восстановления (по возможности).
- Найдите возможности параллельного выполнения выбранных шагов восстановления (где это возможно). Однако, отметив, что эта стратегия может потребовать дополнительных ресурсов исполнителя аварийного восстановления.
- Повышение уровня обслуживания ключевых компонентов до более высоких уровней служб, таких как PaaS, где Корпорация Майкрософт несет большую ответственность за действия по восстановлению служб.
- Расширьте RTO с заинтересованными лицами.
Тестирование аварийного восстановления
Характер предложения облачной службы Azure приводит к ограничениям для любых сценариев тестирования аварийного восстановления. Поэтому руководство заключается в том, чтобы создать подписку на аварийное восстановление с компонентами платформы данных, так как они будут доступны в дополнительном регионе.
В этом базовом плане модуль Runbook плана аварийного восстановления можно выборочно выполнять, уделяя особое внимание службам и компонентам, которые можно развернуть и проверить. Для этого процесса потребуется проверенный тестовый набор данных, позволяющий подтвердить проверки технической и бизнес-проверки согласно плану.
План аварийного восстановления следует регулярно тестировать, чтобы не только обеспечить актуальность, но и создать "мышечную память" для команд, выполняющих отработку отказа и восстановление.
- Резервные копии данных и конфигурации также должны регулярно проверяться, чтобы гарантировать, что они подходят для поддержки любых действий восстановления.
Основная область, на основе которых следует сосредоточиться во время теста аварийного восстановления, заключается в том, чтобы убедиться, что предписные шаги по-прежнему верны, и предполагаемые сроки по-прежнему актуальны.
- Если инструкции отражают экраны портала, а не код, инструкции должны проверяться по крайней мере каждые 12 месяцев из-за изменения в облаке.
Хотя стремление состоит в том, чтобы иметь полностью автоматизированный процесс аварийного восстановления, полная автоматизация может оказаться маловероятной из-за редкости события. Поэтому рекомендуется установить базовые показатели восстановления с инфраструктурой требуемой конфигурации состояния (DSC) в виде кода (IaC), используемого для доставки платформы, а затем подняться в качестве новых проектов на основе базовых показателей.
- С течением времени по мере расширения компонентов и служб необходимо применять NFR, требуя рефакторинг конвейера развертывания рабочей среды для обеспечения покрытия аварийного восстановления.
Если время выполнения модуля Runbook превышает RTO, существует несколько вариантов:
- Расширьте RTO с заинтересованными лицами.
- Уменьшите время, необходимое для действий восстановления, используя автоматизацию, выполнение задач параллельно или миграцию на более высокие уровни облачных серверов.
Azure Chaos Studio
Azure Chaos Studio — это управляемая служба для повышения устойчивости путем внедрения ошибок в приложения Azure. Chaos Studio позволяет управлять внедрением ошибок в ресурсах Azure безопасным и контролируемым способом с помощью экспериментов. Сведения о типах ошибок, поддерживаемых в настоящее время, см. в документации по продукту.
Текущая итерация Chaos Studio охватывает только подмножество компонентов и служб Azure. Пока не будут добавлены дополнительные библиотеки сбоя, Chaos Studio — это рекомендуемый подход для изолированного тестирования устойчивости, а не полного тестирования системного аварийного восстановления.
Дополнительные сведения о студии Chaos см. в документации по Azure Chaos Studio.
Azure Site Recovery
Для компонентов IaaS Azure Site Recovery защищает большинство рабочих нагрузок, работающих на поддерживаемой виртуальной машине или физическом сервере .
Существует строгое руководство по следующим причинам:
- Выполнение аварийного восстановления виртуальной машины Azure
- Выполнение отработки отказа аварийного восстановления в дополнительный регион
- Выполнение резервного восстановления в основном регионе
- Включение автоматизации плана аварийного восстановления
Связанные ресурсы
- Проектирование для обеспечения устойчивости и доступности
- Непрерывность бизнес-процессов и аварийное восстановление
- Резервное копирование и аварийное восстановление для приложений Azure
- Устойчивость в Azure
- Сводка соглашений об уровне обслуживания (соглашения об уровне обслуживания)
- Пять рекомендаций по прогнозированию сбоя
Следующие шаги
Теперь, когда вы узнали, как развернуть сценарий, вы можете ознакомиться с сводкой по аварийному удалению для серии платформ данных Azure.