Чему мы научились
- Убедитесь, что все участвующие стороны понимают разницу между высокой доступностью (ВЫСОКОЙ доступности) и аварийного восстановления (DR): общая ошибка заключается в том, чтобы спутать две концепции и несоответствие решений, связанных с ними.
- Обсудите с заинтересованными лицами бизнес-заинтересованные стороны о своих ожиданиях в отношении следующих аспектов, чтобы определить цели точки восстановления (RPOs) и цели времени восстановления (ОСРВ):
- Сколько простоев они могут терпеть, учитывая, что обычно, чем быстрее восстановление, тем выше стоимость.
- Тип инцидентов, от которого они хотят защититься, говоря о связанной вероятности такого события. Например, вероятность падения сервера выше, чем в результате стихийных бедствий, влияющих на все центры обработки данных по всему региону.
- Что влияет на то, что система недоступна на их бизнес?
- Бюджет операционных расходов (OPEX) для решения движется вперед.
- Рассмотрим, какие варианты службы могут принимать ваши конечные пользователи. К ним могут относиться:
- Доступ к панелям мониторинга визуализации даже без самых актуальных данных, т. е. если конвейеры приема не работают, конечные пользователи по-прежнему имеют доступ к своим данным.
- Наличие доступа на чтение, но нет доступа на запись.
- Целевые метрики RTO и RPO могут определить, какую стратегию аварийного восстановления вы решили реализовать:
- Активный или активный.
- Активный или пассивный.
- Активный или повторное развертывание при аварии.
- Рассмотрите собственную цель уровня обслуживания (SLO), чтобы учитывать допустимые время простоя.
- Убедитесь, что все компоненты, которые могут повлиять на доступность систем, например:
- Управление удостоверениями.
- Топология сети.
- Управление секретами и ключами.
- Источники данных.
- Планировщик автоматизации и задания.
- Исходный репозиторий и конвейеры развертывания (GitHub, Azure DevOps).
- Раннее обнаружение сбоев также позволяет значительно уменьшить значения RTO и RPO. Ниже приведены некоторые аспекты, которые должны быть рассмотрены:
- Определите, что такое сбой и как он сопоставляется с определением сбоя Майкрософт. Определение Майкрософт доступно на странице соглашения об уровне обслуживания Azure на уровне продукта или обслуживания.
- Эффективная система мониторинга и оповещений с подотчетными командами для проверки этих метрик и оповещений своевременно помогает достичь цели.
- В отношении структуры подписки дополнительная инфраструктура для аварийного восстановления может храниться в исходной подписке. Службы платформы как услуга (PaaS), такие как Azure Data Lake Storage 2-го поколения или Фабрика данных Azure, обычно имеют собственные функции, которые позволяют выполнять отработку отказа на вторичные экземпляры в других регионах при сохранении в исходной подписке. Некоторые клиенты могут рассмотреть возможность использования выделенной группы ресурсов для ресурсов, используемых только в сценариях аварийного восстановления в целях затрат.
- Следует отметить, что ограничения подписки могут выступать в качестве ограничения для этого подхода.
- Другие ограничения могут включать элементы управления сложностью разработки и управления, чтобы группы ресурсов аварийного восстановления не использовались для рабочих процессов bAU.
- Проектируйте рабочий процесс аварийного восстановления на основе критически важных и зависимостей решения. Например, не пытайтесь перестроить экземпляр Служб Azure Analysis Services перед запуском и запуском хранилища данных, так как он активирует ошибку. Оставьте лаборатории разработки позже в процессе, сначала восстановите основные корпоративные решения.
- Попробуйте определить задачи восстановления, которые можно параллелизировать между решениями, уменьшая общий объем RTO.
- Если Фабрика данных Azure используется в решении, не забудьте включить в область выполнения локальной интеграции. Azure Site Recovery идеально подходит для этих компьютеров.
- Операции вручную должны быть автоматизированы как можно больше, чтобы избежать человеческих ошибок, особенно при давлении. Рекомендуется:
- Внедрение подготовки ресурсов с помощью Bicep, шаблонов ARM или сценариев PowerShell.
- Внедрение управления версиями исходного кода и конфигурации ресурсов.
- Используйте конвейеры выпуска CI/CD, а не щелчок.
- При наличии плана отработки отказа следует рассмотреть процедуры, чтобы вернуться к основным экземплярам.
- Определите четкие индикаторы и метрики, чтобы убедиться, что отработка отказа выполнена успешно, и решения выполняются или что ситуация возвращается к нормальной (также известной как основная функциональная функция).
- Определите, должны ли соглашения об уровне обслуживания (соглашения об уровне обслуживания) оставаться неизменными после отработки отказа или если разрешено снижение уровня обслуживания.
- Это решение будет значительно зависеть от поддерживаемого бизнес-процесса обслуживания. Например, отработка отказа для системы резервирования помещений будет отличаться от основной операционной системы.
- Определение RTO/RPO должно основываться на конкретных сценариях пользователя, а не на уровне инфраструктуры. Это позволит вам более детально определить, какие процессы и компоненты должны быть восстановлены в первую очередь, если произошел сбой или авария.
- Убедитесь, что вы включаете проверки емкости в целевой регион, прежде чем перейти к отработке отказа: если произошла серьезная авария, следует помнить, что многие клиенты будут пытаться выполнить отработку отказа в один и тот же регион, что может привести к задержкам или состязаниям в подготовке ресурсов.
- Если эти риски неприемлемы, следует рассмотреть стратегию активного или активного или пассивного аварийного восстановления.
- Необходимо создать и сохранить план аварийного восстановления, чтобы документировать процесс восстановления и владельцев действий. Кроме того, учитывайте, что люди могут находиться на отпуске, поэтому обязательно включите вторичные контакты.
- Для проверки рабочего процесса плана аварийного восстановления необходимо выполнить регулярные учения по аварийному восстановлению, которые соответствуют требуемому RTO/RPO, а также для обучения ответственных команд.
- Резервные копии данных и конфигурации также должны регулярно проверяться, чтобы гарантировать, что они подходят для поддержки любых действий восстановления.
- Раннее сотрудничество с командами, ответственными за сетевые сети, идентификацию и подготовку ресурсов, позволит обеспечить соглашение о наиболее оптимальном решении в отношении:
- Как перенаправить пользователей и трафик с основного сайта на дополнительный сайт. Такие понятия, как перенаправление DNS или использование конкретных инструментов, таких как Диспетчер трафика Azure, можно оценить.
- Как обеспечить доступ и права на вторичный сайт своевременно и безопасно.
- Во время аварии эффективное взаимодействие между многими сторонами является ключом к эффективному и быстрому выполнению плана. Команды могут включать:
- Лица, принимающие решения.
- Группа реагирования на инциденты.
- Затронутые внутренние пользователи и команды.
- Внешние команды.
- Оркестрация различных ресурсов в нужное время обеспечит эффективность выполнения плана аварийного восстановления.
Рекомендации
Антишаблоны
- Копирование и вставка этой серии статей предназначена для предоставления клиентам рекомендаций для получения следующего уровня детализации для процесса аварийного восстановления azure. Таким образом, он основан на универсальной архитектуре IP-адресов Майкрософт и эталонных архитектур, а не на любой реализации Azure для конкретного клиента.
Несмотря на то, что предоставленные подробные сведения помогут обеспечить надежное базовое понимание, клиенты должны применять собственный контекст, реализацию и требования, прежде чем получить стратегию аварийного восстановления и процесс "подходит для цели".
Обработка аварийного восстановления как технологических заинтересованных лиц бизнес-заинтересованных лиц играет важную роль в определении требований для аварийного восстановления и выполнении шагов проверки бизнеса, необходимых для подтверждения восстановления службы. Обеспечение того, чтобы заинтересованные лица бизнеса участвовали во всех действиях аварийного восстановления, обеспечивают процесс аварийного восстановления, который является "подходящим для цели", представляет ценность бизнеса и является исполняемым.
Планирование аварийного восстановления Azure постоянно развивается, так как это использование различных компонентов и служб отдельных клиентов. Процесс аварийного восстановления должен развиваться вместе с ними. Либо через процесс жизненного цикла разработки программного обеспечения (SDLC), либо периодические проверки, клиенты должны регулярно пересмотреть свой план аварийного восстановления. Цель заключается в том, чтобы обеспечить допустимость плана восстановления службы и что все разностные изменения между компонентами, службами или решениями были учтены.
Бумажные оценки , в то время как комплексное моделирование события аварийного восстановления будет трудно в современной экосистеме данных, необходимо предпринять усилия, чтобы получить максимально близкое к полному имитации в затронутых компонентах. Регулярно запланированные детализации будут создавать "мышечную память", необходимую организации для выполнения плана аварийного восстановления с уверенностью.
Опираясь на корпорацию Майкрософт, чтобы сделать все это в службах Microsoft Azure, существует четкое разделение ответственности, привязанное к используемому уровню облачных служб:
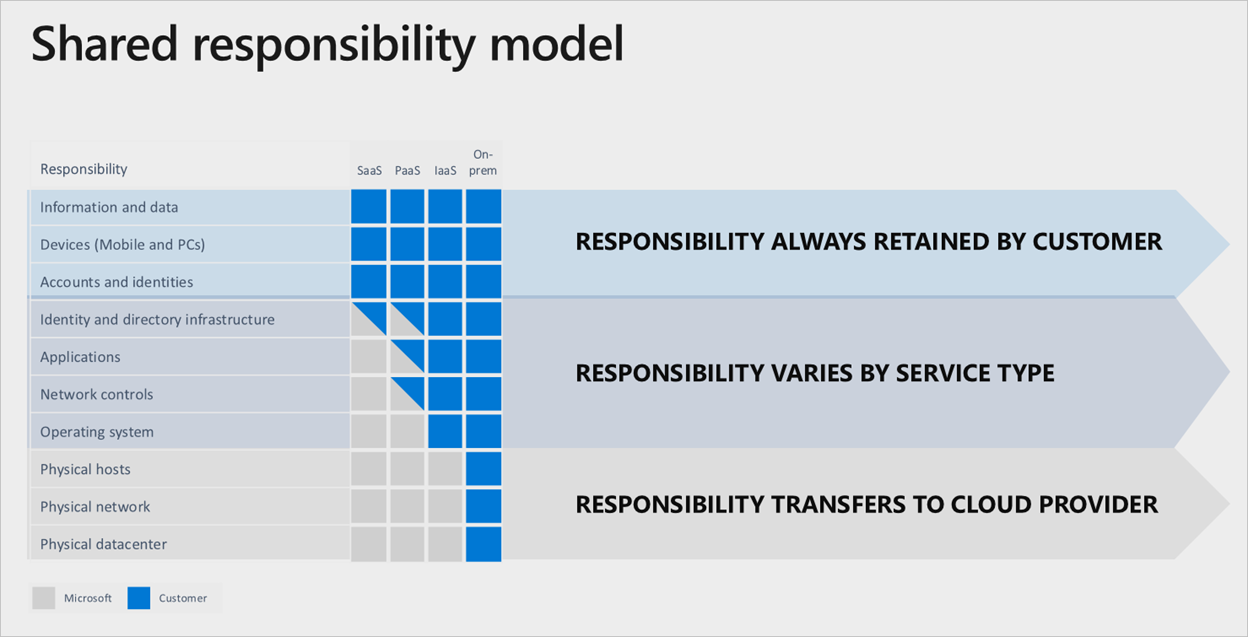 даже если используется полный стек как услуга (SaaS), клиент по-прежнему будет нести ответственность за обеспечение правильности учетных записей, удостоверений и данных, а также устройств, используемых для взаимодействия со службами Azure.
даже если используется полный стек как услуга (SaaS), клиент по-прежнему будет нести ответственность за обеспечение правильности учетных записей, удостоверений и данных, а также устройств, используемых для взаимодействия со службами Azure.
Область событий и стратегия
Область события аварии
Различные события будут иметь другую область влияния и, следовательно, другой ответ. На следующей схеме показано событие аварии: 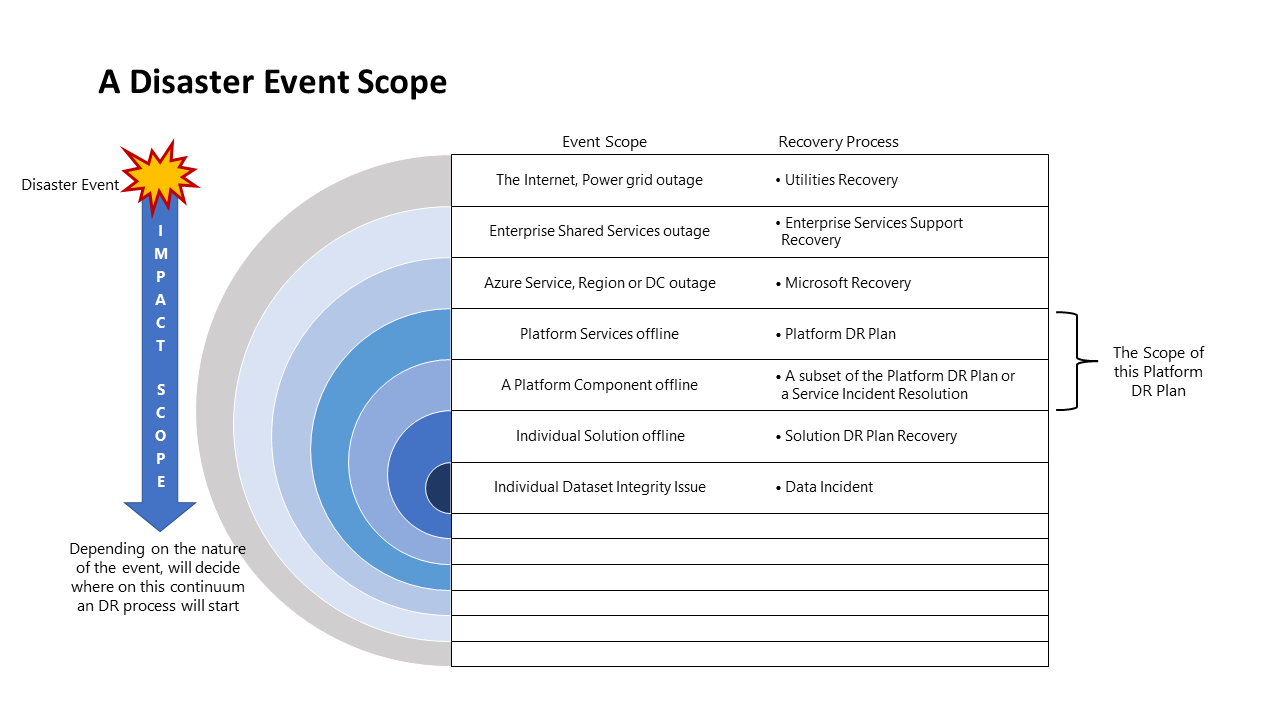
Варианты стратегии аварии
Существует четыре основных варианта стратегии аварийного восстановления:
- Дождитесь, пока корпорация Майкрософт не будет полностью восстановлена в затронутом регионе корпорацией Майкрософт. После восстановления решение проверяется клиентом, а затем будет обновлено для восстановления службы.
- Повторное развертывание при аварийном развертывании . Решение повторно развертывается вручную в доступном регионе с нуля, после аварии.
- Теплое резервное (активное или пассивное) — вторичное размещенное решение создается в альтернативном регионе, а компоненты развертываются для обеспечения минимальной емкости. Однако компоненты не получают рабочий трафик. Вторичные службы в альтернативном регионе могут быть "отключены" или работать на более низком уровне производительности до тех пор, пока не произойдет событие аварийного восстановления.
- Hot Spare (Active/Active) — решение размещается в активной или активной установке в нескольких регионах. Вторичное размещенное решение получает, обрабатывает и служит данными в рамках более крупной системы.
Влияние стратегии аварийного восстановления
Хотя операционные затраты, вызванные более высоким уровнем устойчивости службы, часто доминируют в ключевых решениях по проектированию (KDD) для стратегии аварийного восстановления. Существуют и другие важные соображения.
Примечание.
Оптимизация затрат является одним из пяти основных принципов архитектуры с помощью Azure Well-Architected Framework. Ее цель заключается в сокращении ненужных расходов и повышении эффективности работы.
Сценарий аварийного восстановления для этого рабочего примера — это полный региональный сбой Azure, который напрямую влияет на основной регион, на котором размещена платформа данных Contoso.
Для этого сценария сбоя относительные последствия для четырех высокоуровневых стратегий аварийного восстановления: 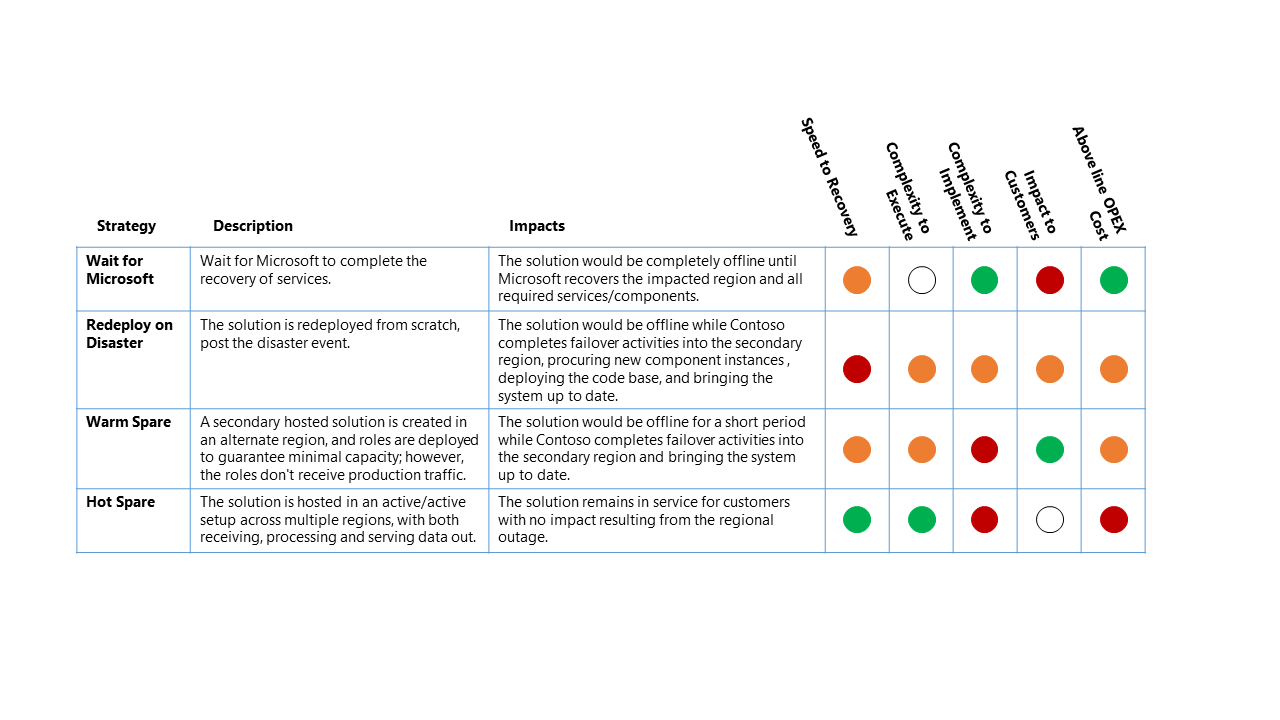
Ключ классификации
- Цель времени восстановления (RTO): ожидаемое время от события аварии до восстановления службы платформы.
- Сложность выполнения: сложность выполнения действий восстановления для организации.
- Сложность реализации: сложность для организации для реализации стратегии аварийного восстановления.
- Влияние на клиентов: прямое влияние на клиентов службы платформы данных из стратегии аварийного восстановления.
- Выше стоимость OPEX: дополнительная стоимость, ожидаемая от реализации этой стратегии, как увеличение ежемесячного выставления счетов для Azure для дополнительных компонентов и дополнительных ресурсов, необходимых для поддержки.
Примечание.
Приведенная выше таблица должна быть считана как сравнение параметров — стратегия, которая имеет зеленый индикатор лучше для этой классификации, чем другая стратегия с желтым или красным индикатором.
Следующие шаги
Теперь, когда вы узнали о рекомендациях, связанных с сценарием, вы можете узнать , как развернуть этот сценарий.