Tutorial: Analisar dependências funcionais em um modelo semântico
Neste tutorial, você aproveita o trabalho anterior feito por um analista do Power BI e armazenado na forma de modelos semânticos (conjuntos de dados do Power BI). Usando o SemPy (pré-visualização) na experiência Synapse Data Science no Microsoft Fabric, analisam-se dependências funcionais que existem nas colunas de um DataFrame. Essa análise ajuda a descobrir problemas não triviais de qualidade de dados para obter insights mais precisos.
Neste tutorial, você aprenderá a:
- Aplicar conhecimento de domínio para formular hipóteses sobre dependências funcionais em um modelo semântico.
- Familiarize-se com os componentes da biblioteca Python do link semântico (SemPy) que suportam a integração com o Power BI e ajudam a automatizar a análise da qualidade dos dados. Esses componentes incluem:
- FabricDataFrame - uma estrutura semelhante a pandas aprimorada com informações semânticas adicionais.
- Funções úteis para extrair modelos semânticos de um espaço de trabalho do Fabric para o seu bloco de anotações.
- Funções úteis que automatizam a avaliação de hipóteses sobre dependências funcionais e que identificam violações de relações em seus modelos semânticos.
Pré-requisitos
Obtenha uma assinatura Microsoft Fabric. Ou inscreva-se para obter uma avaliação gratuita do Microsoft Fabric.
Entre no Microsoft Fabric.
Use o seletor de experiência no canto inferior esquerdo da página inicial para alternar para o Fabric.
Selecione Workspaces no painel de navegação esquerdo para localizar e selecionar seu espaço de trabalho. Este espaço de trabalho torna-se o seu espaço de trabalho atual.
Faça o download do modelo semântico Customer Profitability Sample.pbix do repositório GitHub fabric-samples.
No seu espaço de trabalho, selecione Importar Relatório de>ou Relatório Paginado>a partir deste computador para importar o ficheiro Customer Profitability Sample.pbix para o seu espaço de trabalho.
Acompanhe no caderno
O notebook powerbi_dependencies_tutorial.ipynb acompanha este tutorial.
Para abrir o notebook que acompanha este tutorial, siga as instruções em Preparar o seu sistema para tutoriais de ciência de dados para importar o notebook para o seu espaço de trabalho.
Se preferir copiar e colar o código desta página, pode criar um novo bloco de notas.
Certifique-se de anexar um lakehouse ao bloco de anotações antes de começar a executar o código.
Configurar o notebook
Nesta seção, você configura um ambiente de notebook com os módulos e dados necessários.
Instale
SemPydo PyPI usando a capacidade de instalação em linha%pipno notebook.%pip install semantic-linkExecute as importações necessárias de módulos que você precisará mais tarde:
import sempy.fabric as fabric from sempy.dependencies import plot_dependency_metadata
Carregue e pré-processe os dados
Este tutorial usa um modelo semântico de exemplo padrão Customer Profitability Sample.pbix. Para obter uma descrição do modelo semântico, consulte exemplo de Rentabilidade do Cliente para o Power BI.
Carregue os dados do Power BI em FabricDataFrames, usando a função
read_tabledo SemPy:dataset = "Customer Profitability Sample" customer = fabric.read_table(dataset, "Customer") customer.head()Carregue a tabela
Stateem um FabricDataFrame:state = fabric.read_table(dataset, "State") state.head()Embora a saída deste código pareça um DataFrame do Pandas, você realmente inicializou uma estrutura de dados chamada
FabricDataFrameque suporta algumas operações úteis em cima do Pandas.Verifique o tipo de dados do
customer:type(customer)A saída confirma que
customeré do tiposempy.fabric._dataframe._fabric_dataframe.FabricDataFrame.'Junte-se ao
customerestateDataFrames:customer_state_df = customer.merge(state, left_on="State", right_on="StateCode", how='left') customer_state_df.head()
Identificar dependências funcionais
Uma dependência funcional se manifesta como uma relação um-para-muitos entre os valores em duas (ou mais) colunas dentro de um DataFrame. Essas relações podem ser usadas para detetar automaticamente problemas de qualidade de dados.
Execute a função
find_dependenciesdo SemPy no DataFrame mesclado para identificar quaisquer dependências funcionais existentes entre valores nas colunas:dependencies = customer_state_df.find_dependencies() dependenciesVisualize as dependências identificadas usando a função
plot_dependency_metadatado SemPy:plot_dependency_metadata(dependencies)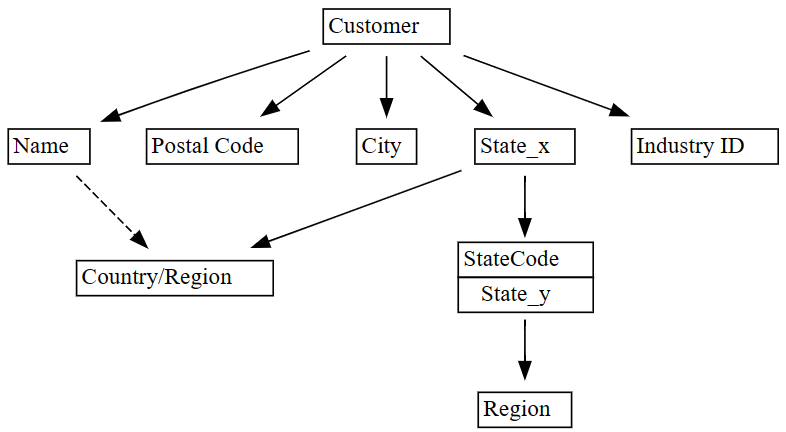
Como esperado, o gráfico de dependências funcionais mostra que a coluna
Customerdetermina algumas colunas comoCity,Postal CodeeName.Surpreendentemente, o gráfico não mostra uma dependência funcional entre
CityePostal Code, provavelmente porque há muitas violações nas relações entre as colunas. Você pode usar a funçãoplot_dependency_violationsdo SemPy para visualizar violações de dependências entre colunas específicas.

Explore os dados em busca de problemas de qualidade
Desenhe um gráfico com a função de visualização
plot_dependency_violationsdo SemPy.customer_state_df.plot_dependency_violations('Postal Code', 'City')
O gráfico de violações de dependência mostra valores para
Postal Codeno lado esquerdo e valores paraCityno lado direito. Uma aresta conecta umaPostal Codeno lado esquerdo com umaCityno lado direito se houver uma linha que contenha esses dois valores. As arestas são anotadas com a contagem do número dessas filas. Por exemplo, existem duas linhas com o código postal 20004, uma com cidade "North Tower" e outra com cidade "Washington".Além disso, a trama mostra algumas violações e muitos valores vazios.
Confirme o número de valores vazios para
Postal Code:customer_state_df['Postal Code'].isna().sum()50 linhas têm NA para código postal.
Eliminar linhas com valores vazios. Em seguida, encontre dependências usando a função
find_dependencies. Observe o parâmetro extraverbose=1que oferece um vislumbre do funcionamento interno do SemPy:customer_state_df2=customer_state_df.dropna() customer_state_df2.find_dependencies(verbose=1)A entropia condicional para
Postal CodeeCityé 0,049. Esse valor indica que há violações de dependência funcional. Antes de corrigir as violações, aumente o limite de entropia condicional do valor padrão de0.01para0.05, apenas para ver as dependências. Limiares mais baixos resultam em menos dependências (ou maior seletividade).Aumente o limite de entropia condicional do valor padrão de
0.01para0.05:plot_dependency_metadata(customer_state_df2.find_dependencies(threshold=0.05))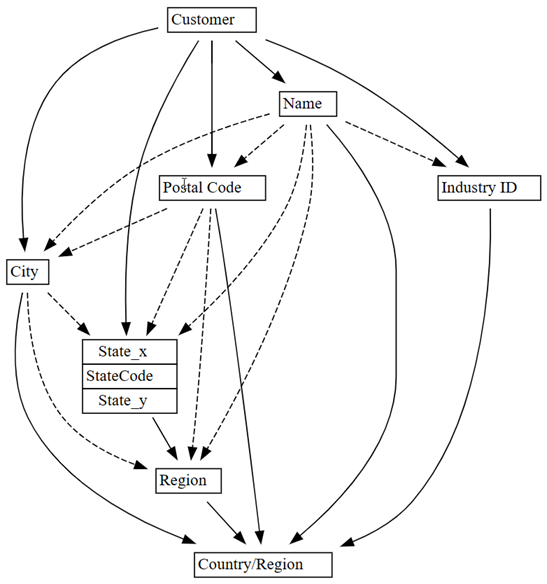
Se você aplicar o conhecimento de domínio de qual entidade determina valores de outras entidades, este gráfico de dependências parece preciso.
Explore mais problemas de qualidade de dados que foram detetados. Por exemplo, uma seta tracejada une
CityeRegion, o que indica que a dependência é apenas aproximada. Essa relação aproximada pode implicar que há uma dependência funcional parcial.customer_state_df.list_dependency_violations('City', 'Region')Dê uma olhada mais de perto em cada um dos casos em que um valor de
Regionnão vazio causa uma violação:customer_state_df[customer_state_df.City=='Downers Grove']O resultado mostra a cidade de Downers Grove ocorrendo em Illinois e Nebraska. No entanto, Downer's Grove é uma cidade em Illinois, não Nebraska.
Dê uma olhada na cidade de Fremont:
customer_state_df[customer_state_df.City=='Fremont']Há uma cidade chamada Fremont na Califórnia. No entanto, para o Texas, o motor de busca retorna Premont, não Fremont.
Também é suspeito ver violações da dependência entre
NameeCountry/Region, conforme indicado pela linha pontilhada no gráfico original de violações de dependência (antes de eliminar as linhas com valores vazios).customer_state_df.list_dependency_violations('Name', 'Country/Region')Parece que um cliente, SDI Design está presente em duas regiões - Estados Unidos e Canadá. Esta ocorrência pode não ser uma violação semântica, mas pode ser apenas um caso incomum. Ainda assim, vale a pena dar uma olhada de perto:
Dê uma olhada mais de perto no cliente SDI Design:
customer_state_df[customer_state_df.Name=='SDI Design']Uma inspeção mais aprofundada mostra que, na verdade, são dois clientes diferentes (de indústrias diferentes) com o mesmo nome.

A análise exploratória de dados é um processo empolgante, assim como a limpeza de dados. Há sempre algo que os dados estão escondendo, dependendo de como você olha para eles, o que você quer perguntar e assim por diante. O link semântico fornece novas ferramentas que você pode usar para obter mais com seus dados.
Conteúdo relacionado
Confira outros tutoriais para link semântico / SemPy:
- Tutorial: Limpar dados com dependências funcionais
- Tutorial: Extrair e calcular medidas do Power BI a partir de um bloco de anotações Jupyter
- Tutorial: Descubra relações em um modelo semântico, usando o link semântico
- Tutorial: Descubra relações no conjunto de dados Synthea, usando o link semântico
- Tutorial: Validar dados usando SemPy e Grandes Expectativas (GX)