Implantação de DBMS de Máquinas Virtuais do Azure do SQL Server para SAP NetWeaver
Este documento abrange várias áreas diferentes a serem consideradas ao implantar a carga de trabalho do SQL Server para SAP na IaaS do Azure. Como pré-condição para este documento, leia o documento Considerações para a implantação do DBMS de Máquinas Virtuais do Azure para carga de trabalho SAP e outros guias na documentação da carga de trabalho SAP no Azure.
Importante
O escopo deste documento é a versão do Windows no SQL Server. A SAP não está suportando a versão Linux do SQL Server com nenhum software SAP. O documento não está discutindo o Banco de Dados SQL do Microsoft Azure, que é uma oferta de Plataforma como Serviço da Plataforma Microsoft Azure. A discussão neste documento é sobre a execução do produto SQL Server como é conhecido para implantações locais em Máquinas Virtuais do Azure, aproveitando o recurso de Infraestrutura como Serviço do Azure. Os recursos e a funcionalidade do banco de dados entre essas duas ofertas são diferentes e não devem ser misturados entre si. Para obter mais informações, consulte Banco de Dados SQL do Azure.
Em geral, você deve considerar o uso das versões mais recentes do SQL Server para executar a carga de trabalho SAP na IaaS do Azure. As versões mais recentes do SQL Server oferecem uma melhor integração em alguns dos serviços e funcionalidades do Azure. Ou tenha alterações que otimizem as operações em uma infraestrutura IaaS do Azure.
A documentação geral sobre o SQL Server em execução nas Máquinas Virtuais (VM) do Azure pode ser encontrada nestes artigos:
- SQL Server em Máquinas Virtuais do Azure (Windows)
- Automatizar a gestão com a extensão do Agente IaaS do SQL Server do Windows
- Configurar a integração do Azure Key Vault para SQL Server em VMs do Azure (Gerenciador de Recursos)
- Lista de verificação: melhores práticas do SQL Server nas VMs do Azure
- Armazenamento: práticas recomendadas de desempenho para o SQL Server em VMs do Azure
- Melhores práticas de configuração do HADR (SQL Server nas VMs do Azure)
Nem todo o conteúdo e instruções feitas na documentação geral do SQL Server na VM do Azure se aplicam à carga de trabalho do SAP. Mas, a documentação dá uma boa impressão sobre os princípios. Um exemplo de funcionalidade não suportada para carga de trabalho SAP é o uso de clustering FCI.
Há algumas informações específicas do SQL Server em IaaS que você deve saber antes de continuar:
- Suporte à versão SQL: mesmo com a Nota SAP #1928533 informando que a versão mínima suportada do SQL Server é o SQL Server 2008 R2, a janela de versões com suporte do SQL Server no Azure também é ditada com o ciclo de vida do SQL Server. A manutenção estendida do SQL Server 2012 terminou em meados de 2022. Como resultado, a versão mínima atual para sistemas recém-implantados deve ser o SQL Server 2014. Quanto mais recente, melhor. As versões mais recentes do SQL Server oferecem uma melhor integração em alguns dos serviços e funcionalidades do Azure. Ou tenha alterações que otimizem as operações em uma infraestrutura IaaS do Azure.
- Usando imagens do Azure Marketplace: a maneira mais rápida de implantar uma nova VM do Microsoft Azure é usar uma imagem do Azure Marketplace. Há imagens no Azure Marketplace, que contêm as versões mais recentes do SQL Server. As imagens onde o SQL Server já está instalado não podem ser usadas imediatamente para aplicativos SAP NetWeaver. O motivo é que o agrupamento padrão do SQL Server é instalado nessas imagens e não o agrupamento necessário para sistemas SAP NetWeaver. Para usar essas imagens, verifique as etapas documentadas no capítulo Usando uma imagem do SQL Server fora do Microsoft Azure Marketplace.
- Suporte a várias instâncias do SQL Server em uma única VM do Azure: esse método de implantação é suportado. No entanto, esteja ciente das limitações de recursos, especialmente em relação à largura de banda de rede e armazenamento do tipo de VM que você está usando. Informações detalhadas estão disponíveis no artigo Tamanhos para máquinas virtuais no Azure. Essas limitações de cota podem impedir que você implemente a mesma arquitetura de várias instâncias que você pode implementar localmente. A partir da configuração e interferência do compartilhamento dos recursos disponíveis em uma única VM, as mesmas considerações locais precisam ser levadas em consideração.
- Vários bancos de dados SAP em uma única instância do SQL Server em uma única VM: configurações como essas são suportadas. As considerações sobre vários bancos de dados SAP compartilhando os recursos compartilhados de uma única instância do SQL Server são as mesmas que para implantações locais. Tenha em mente outros limites, como o número de discos que podem ser anexados a um tipo específico de VM. Ou limites de cota de rede e armazenamento de tipos específicos de VM, conforme Tamanhos detalhados para máquinas virtuais no Azure.
Novas VMs da série M e SQL Server
O Azure lançou algumas novas famílias de SKUs da série M sob a família Mv3. Alguns dos tipos de VM dessa família não devem ser usados para o SQL Server, incluindo o SQL Server 2022 sem desabilitar o SMT (Hyperthreading) no sistema operacional convidado do Windows Server. O motivo é o número de nós NUMA apresentados no sistema operacional convidado do Windows Server que, com mais de 64 vCPUs, é muito grande para o SQL Server acomodar. Ao desativar o SMT no sistema operacional convidado do Windows Server, o número de vCPUs está sendo reduzido. Assim, que o número de vCPUs é inferior a 64 em cada nó NUMA. A maneira de desativar o SMT é descrita aqui. Os tipos específicos de VM são:
- M176(d)s_3_v3 - desative o SMT ou use M176bds_4_v3 ou M176bds_4_v3 como alternativa
- M176(d)s_4_v3 - desative o SMT ou use M176bds_4_v3 como alternativa
- M624(d)s_12_v3 - desative o SMT ou use M416ms_v2 como alternativa
- M832(d)s_12_v3 - desative o SMT ou use M416ms_v2 como alternativa
- M832i(d)s_16_v3 - desative o SMT ou use M416ms_v2 como alternativa
Nota
Com alguns dos novos tipos de VM M(b)v3, o uso do armazenamento SSD Premium v1 em cache de leitura pode resultar em taxas de IOPS e taxa de transferência de leitura e gravação mais baixas do que se você não usasse o cache de leitura.
Recomendações sobre a estrutura VM/VHD para implantações do SQL Server relacionadas ao SAP
De acordo com a descrição geral, Sistema operacional, executáveis do SQL Server, os executáveis SAP devem estar localizados ou instalados discos do Azure separados. Normalmente, a maioria dos bancos de dados do sistema SQL Server não é utilizada em alto nível com a carga de trabalho do SAP NetWeaver. No entanto, os bancos de dados do sistema do SQL Server devem ser, juntamente com os outros diretórios do SQL Server em um disco do Azure separado. O tempdb do SQL Server deve estar localizado na unidade D:\ não perisisted ou em um disco separado.
- Com todos os tipos de VM certificados SAP (consulte SAP Note #1928533), os dados tempdb e os arquivos de log podem ser colocados na unidade D:\ não persistente.
- Com versões do SQL Server, em que o SQL Server instala tempdb com apenas um arquivo de dados, é recomendável usar vários arquivos de dados tempdb. Esteja ciente de que os volumes de unidade D:\ são diferentes em tamanho e recursos com base no tipo de VM. Para obter os tamanhos exatos da unidade D:\ das diferentes VMs, verifique o artigo Tamanhos para máquinas virtuais do Windows no Azure.
Essas configurações permitem que o tempdb consuma mais espaço e, mais importante, mais operações de E/S por segundo (IOPS) e largura de banda de armazenamento do que a unidade do sistema é capaz de fornecer. A unidade D:\ não persistente também oferece melhor latência e taxa de transferência de E/S. Para determinar o tamanho tempdb adequado, você pode verificar os tamanhos tempdb em sistemas existentes.
Nota
no caso de você colocar arquivos de dados tempdb e arquivo de log em uma pasta na unidade D:\ que você criou, você precisa se certificar de que a pasta existe após uma reinicialização da VM. Como a unidade D:\ pode ser inicializada recentemente após a reinicialização de uma VM, todas as estruturas de arquivos e diretórios podem ser eliminadas. Uma possibilidade de recriar eventuais estruturas de diretório na unidade D:\ antes do início do serviço SQL Server está documentada neste artigo.
Uma configuração de VM, que executa o SQL Server com um banco de dados SAP e onde os dados tempdb e o arquivo de log tempdb são colocados na unidade D:\ e no armazenamento premium do Azure v1 ou v2 teria a seguinte aparência:
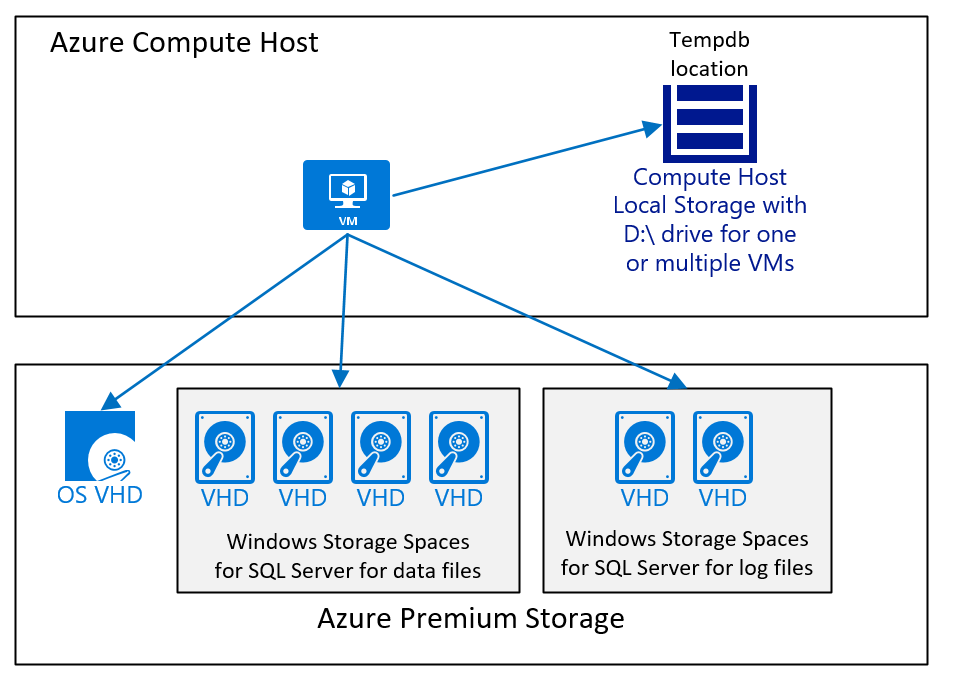
O diagrama exibe um caso simples. Conforme mencionado no artigo Considerações para a implantação do DBMS de Máquinas Virtuais do Azure para carga de trabalho SAP, o tipo, o número e o tamanho dos discos de armazenamento do Azure dependem de diferentes fatores. Mas, em geral, recomendamos:
- Para implantações menores e médias, usando um grande volume, que contém os arquivos de dados do SQL Server. A razão por trás dessa configuração é que é mais fácil lidar com diferentes cargas de trabalho de E/S caso os arquivos de dados do SQL Server não tenham o mesmo espaço livre. Enquanto em grandes implantações, especialmente implantações em que o cliente se moveu com uma migração de banco de dados heterogênea para o SQL Server no Azure, usamos discos separados e, em seguida, distribuímos os arquivos de dados entre esses discos. Tal arquitetura só é bem-sucedida quando cada disco tem o mesmo número de arquivos de dados, todos os arquivos de dados são do mesmo tamanho e aproximadamente têm o mesmo espaço livre.
- Use o D:\drive para tempdb, desde que o desempenho seja bom o suficiente. Se a carga de trabalho geral for limitada no desempenho do tempdb localizado na unidade D:\, você precisará mover o tempdb para o armazenamento premium do Azure v1 ou v2 ou para o disco Ultra, conforme recomendado neste artigo.
O mecanismo de preenchimento proporcional do SQL Server distribui leituras e gravações em todos os arquivos de dados uniformemente, desde que todos os arquivos de dados do SQL Server tenham o mesmo tamanho e o mesmo ritmo livre. O SAP no SQL Server oferece o melhor desempenho quando leituras e gravações são distribuídas uniformemente em todos os arquivos de dados disponíveis. Se um banco de dados tiver poucos arquivos de dados ou os arquivos de dados existentes estiverem altamente desequilibrados, o melhor método para corrigir é uma exportação e importação R3load. Uma exportação e importação do R3load envolve tempo de inatividade e só deve ser feita se houver um problema óbvio de desempenho que precise ser resolvido. Se os arquivos de dados tiverem apenas tamanhos moderadamente diferentes, aumente todos os arquivos de dados para o mesmo tamanho e o SQL Server estará reequilibrando os dados ao longo do tempo. O SQL Server aumenta automaticamente os arquivos de dados uniformemente se o sinalizador de rastreamento 1117 estiver definido ou se o SQL Server 2016 ou superior for usado sem o sinalizador de rastreamento.
Especial para VMs da série M
Para a VM do Azure M-Series, a latência de gravação no log de transações pode ser reduzida, em comparação com o desempenho de armazenamento premium do Azure v1, ao usar o Azure Write Accelerator. Se a latência fornecida pelo armazenamento premium v1 estiver limitando a escalabilidade da carga de trabalho do SAP, o disco que armazena o arquivo de log de transações do SQL Server poderá ser habilitado para o Acelerador de Gravação. Os detalhes podem ser lidos no documento Write Accelerator. O Azure Write Accelerator não funciona com o Azure Premium Storage v2 e Ultra disk. Em ambos os casos, a latência é melhor do que o que o armazenamento premium do Azure v1 oferece. O Write Accelerator não suporta SSD Premium v2.
Nota
Com alguns dos novos tipos de VM M(b)v3, o uso do armazenamento SSD Premium v1 em cache de leitura pode resultar em taxas de IOPS e taxa de transferência de leitura e gravação mais baixas do que se você não usasse o cache de leitura.
Formatar os discos
Para o SQL Server, o tamanho do bloco NTFS para discos que contêm dados e arquivos de log do SQL Server deve ser de 64 KB. Não há necessidade de formatar a unidade D:\. Esta unidade vem pré-formatada.
Para evitar que a restauração ou a criação de bancos de dados esteja inicializando os arquivos de dados zerando o conteúdo dos arquivos, verifique se o contexto do usuário no qual o serviço do SQL Server está sendo executado tem as tarefas de manutenção de volume User Right Execute. Para obter mais informações, consulte Inicialização instantânea de arquivos de banco de dados.
SQL Server 2014 e versões mais recentes do SQL Server - Armazenando arquivos de banco de dados diretamente no Armazenamento de Blobs do Azure
O SQL Server 2014 e versões posteriores abrem a possibilidade de armazenar arquivos de banco de dados diretamente no Azure Blob Store sem o 'wrapper' de um VHD ao redor deles. Essa funcionalidade foi criada para resolver deficiências do armazenamento de blocos do Azure anos atrás. Atualmente, não é recomendado usar esse método de implantação e, em vez disso, escolher o armazenamento premium do Azure v1, o armazenamento premium v2 ou o disco Ultra. Dependente dos requisitos.
Considerações sobre backup/recuperação para o SQL Server
Implantando o SQL Server no Azure, você precisa revisar sua arquitetura de backup. Mesmo que o sistema não seja um sistema de produção, o backup do banco de dados SAP do SQL Server deve ser feito periodicamente. Como o Armazenamento do Azure mantém três imagens, um backup agora é menos importante em relação à compensação de uma falha de armazenamento. O motivo prioritário para manter um plano de backup e recuperação adequado é importante para a funcionalidade de recuperação point-in-time para compensar erros lógicos/manuais. O objetivo é usar backups para restaurar o banco de dados de volta a um determinado ponto no tempo. Ou para usar os backups no Azure para semear outro sistema com a cópia do backup de banco de dados existente.
Há várias maneiras de fazer backup e restaurar bancos de dados do SQL Server no Azure. Para obter a melhor visão geral e detalhes, leia o documento Backup e restauração do SQL Server em VMs do Azure. O artigo abrange várias possibilidades diferentes.
Usando uma imagem do SQL Server fora do Microsoft Azure Marketplace
A Microsoft oferece VMs no Azure Marketplace, que já contém versões do SQL Server. Para clientes SAP que precisam de licenças para SQL Server e Windows, usar essas imagens pode ser uma oportunidade para cobrir a necessidade de licenças girando VMs com o SQL Server já instalado. Para usar essas imagens para SAP, as seguintes considerações precisam ser feitas:
- As versões sem avaliação do SQL Server adquirem custos mais altos do que uma VM 'somente Windows' implantada a partir do Azure Marketplace. Para comparar preços, consulte Preços de máquinas virtuais do Windows e Preços de máquinas virtuais corporativas do SQL Server.
- Você só pode usar versões do SQL Server, que são suportadas pelo SAP para seu software.
- O agrupamento da instância do SQL Server, que é instalado nas VMs oferecidas no Azure Marketplace, não é o agrupamento que o SAP NetWeaver requer que a instância do SQL Server seja executada. Você pode alterar o agrupamento com as instruções na seção a seguir.
Alterando o agrupamento do SQL Server de uma VM do Microsoft Windows/SQL Server
Como as imagens do SQL Server no Azure Marketplace não estão configuradas para usar o agrupamento, que é necessário para aplicativos SAP NetWeaver, ele precisa ser alterado imediatamente após a implantação. Para o SQL Server, essa alteração de agrupamento pode ser feita com as seguintes etapas assim que a VM for implantada e um administrador puder fazer logon na VM implantada:
- Abra uma janela de comando do Windows, como administrador.
- Altere o diretório para C:\Program Files\Microsoft SQL Server\110\Setup Bootstrap\SQLServer2012.
- Execute o comando: Setup.exe /QUIET /ACTION=REBUILDDATABASE /INSTANCENAME=MSSQLSERVER /SQLSYSADMINACCOUNTS=
<local_admin_account_name> /SQLCOLLATION=SQL_Latin1_General_Cp850_BIN2-
<local_admin_account_name> é a conta, que foi definida como a conta de administrador ao implantar a VM pela primeira vez através da galeria.
-
O processo deve demorar apenas alguns minutos. Para ter certeza se a etapa terminou com o resultado correto, execute as seguintes etapas:
- Abra o SQL Server Management Studio.
- Abra uma janela de consulta.
- Execute o comando sp_helpsort no banco de dados mestre do SQL Server.
O resultado desejado deve ser parecido com:
Latin1-General, binary code point comparison sort for Unicode Data, SQL Server Sort Order 40 on Code Page 850 for non-Unicode Data
Se o resultado for diferente, PARE qualquer implantação e investigue por que o comando de instalação não funcionou conforme o esperado. A implantação de aplicativos SAP NetWeaver em instâncias do SQL Server com páginas de código do SQL Server diferentes da mencionada NÃO é suportada para implantações do NetWeaver.
Alta disponibilidade do SQL Server para SAP no Azure
Usando o SQL Server em implantações IaaS do Azure para SAP, você tem várias possibilidades diferentes para adicionar para implantar a camada de banco de dados altamente disponível. O Azure fornece diferentes SLAs de tempo de atividade para uma única VM usando diferentes armazenamentos de bloco do Azure, um par de VMs implantadas em um conjunto de disponibilidade do Azure ou um par de VMs implantadas nas Zonas de Disponibilidade do Azure. Para sistemas de produção, esperamos que você implante um par de VMs em um conjunto de escala de máquina virtual com orquestração flexível em duas zonas de disponibilidade. Consulte a comparação de diferentes tipos de implantação para carga de trabalho SAP para obter mais informações. Uma VM executa a instância ativa do SQL Server. A outra VM executa a instância passiva
Clustering do SQL Server usando o Servidor de Arquivos de Expansão do Windows ou o disco compartilhado do Azure
Com o Windows Server 2016, a Microsoft introduziu os Espaços de Armazenamento Diretos. Com base em Espaços de Armazenamento, Implantação Direta, clustering FCI do SQL Server é suportado em geral. O Azure também oferece discos compartilhados do Azure que podem ser usados para clustering do Windows. Para a carga de trabalho SAP, não estamos suportando essas opções de HA.
Envio de logs do SQL Server
Uma funcionalidade de alta disponibilidade é o envio de logs do SQL Server. Se as VMs que participam da configuração HA tiverem resolução de nome de trabalho, não haverá problema. A configuração no Azure não difere de nenhuma configuração feita no local relacionada à configuração do envio de logs e aos princípios relacionados ao envio de logs. Detalhes do envio de logs do SQL Server podem ser encontrados no artigo Sobre o envio de logs (SQL Server).
A funcionalidade de envio de logs do SQL Server dificilmente foi usada no Azure para obter alta disponibilidade em uma região do Azure. No entanto, nos seguintes cenários, os clientes SAP estavam usando o envio de logs bem-sucedido com o Azure:
- Cenários de recuperação de desastres de uma região do Azure para outra região do Azure
- Configuração de recuperação de desastres do local para uma região do Azure
- Cenários de transferência do local para o Azure. Nesses casos, o envio de logs é usado para sincronizar a nova implantação de banco de dados no Azure com o sistema de produção local em andamento. No momento do corte, a produção é encerrada e certifica-se de que os últimos e mais recentes backups de log de transações foram transferidos para a implantação do banco de dados do Azure. Em seguida, a implantação do banco de dados do Azure é aberta para produção.
SQL Server Sempre Ativo
Como o Always On é suportado para SAP local (consulte SAP Note #1772688), ele é suportado em combinação com o SAP no Azure. Há algumas considerações especiais sobre a implantação do SQL Server Availability Group Listener (não confundir com o Conjunto de Disponibilidade do Azure). Portanto, algumas etapas de instalação diferentes são necessárias.
Algumas considerações usando um ouvinte do grupo de disponibilidade são:
- O uso de um Ouvinte do Grupo de Disponibilidade só é possível com o Windows Server 2012 ou superior como SO convidado da VM. Para o Windows Server 2012, verifique se a atualização para habilitar os ouvintes do Grupo de Disponibilidade do SQL Server em máquinas virtuais do Microsoft Azure baseadas no Windows Server 2008 R2 e no Windows Server 2012 foi aplicada.
- Para o Windows Server 2008 R2, esse patch não existe. Nesse caso, o Always On precisaria ser usado da mesma maneira que o espelhamento de banco de dados. Especificando um parceiro de failover na cadeia de conexões (feito por meio do parâmetro dbs/mss/server do SAP default.pfl - consulte SAP Note #965908).
- Usando um Ouvinte de Grupo de Disponibilidade, você precisa conectar as VMs de Banco de Dados a um Balanceador de Carga dedicado. Você deve atribuir endereços IP estáticos às interfaces de rede dessas VMs na configuração Always On (a definição de um endereço IP estático é descrita neste artigo). Os endereços IP estáticos em comparação com o DHCP estão impedindo a atribuição de novos endereços IP nos casos em que ambas as VMs podem ser interrompidas.
- Há etapas especiais necessárias ao criar a configuração do cluster WSFC em que o cluster precisa de um endereço IP especial atribuído, porque o Azure com sua funcionalidade atual atribuiria ao nome do cluster o mesmo endereço IP do nó no qual o cluster foi criado. Esse comportamento significa que uma etapa manual deve ser executada para atribuir um endereço IP diferente ao cluster.
- O Ouvinte do Grupo de Disponibilidade será criado no Azure com pontos de extremidade TCP/IP, que são atribuídos às VMs que executam as réplicas primária e secundária do grupo Disponibilidade.
- Pode haver a necessidade de proteger esses pontos de extremidade com ACLs.
Documentação detalhada sobre a implantação do Always On com o SQL Server em listas de VMs do Azure como:
- Apresentando os grupos de disponibilidade Always On do SQL Server em máquinas virtuais do Azure.
- Configure um grupo de disponibilidade Always On em máquinas virtuais do Azure em regiões diferentes.
- Configure um balanceador de carga para um grupo de disponibilidade Always On no Azure.
- Melhores práticas de configuração do HADR (SQL Server nas VMs do Azure)
Nota
Lendo Apresentando os grupos de disponibilidade Always On do SQL Server em máquinas virtuais do Azure, você vai ler sobre o ouvinte DNN (Direct Network Name) do SQL Server. Essa nova funcionalidade foi introduzida com o SQL Server 2019 CU8. Essa nova funcionalidade torna obsoleto o uso de um balanceador de carga do Azure que manipula o endereço IP virtual do Ouvinte do Grupo de Disponibilidade.
O SQL Server Always On é a funcionalidade de alta disponibilidade e recuperação de desastres usada mais comumente usada no Azure para implantações de carga de trabalho SAP. A maioria dos clientes usa o Always On para alta disponibilidade em uma única região do Azure. Se a implantação estiver restrita apenas a dois nós, você terá duas opções de conectividade:
- Usando o Ouvinte do Grupo de Disponibilidade. Com o Ouvinte do Grupo de Disponibilidade, é necessário implantar um balanceador de carga do Azure.
- Com o SQL Server 2016 SP3, SQL Server 2017 25 ou SQL Server 2019 CU8 ou versões mais recentes do SQL Server no Windows Server 2016 ou posterior, você pode usar o ouvinte DNN (Nome Direto da Rede) em vez de um balanceador de carga do Azure. A DNN está eliminando a necessidade de um balanceador de carga do Azure.
O uso dos parâmetros de conectividade do Espelhamento de Banco de Dados do SQL Server só deve ser considerado para a rodada de investigação de problemas com os outros dois métodos. Nesse caso, você precisa configurar a conectividade dos aplicativos SAP de uma forma em que ambos os nomes de nó sejam nomeados. Os detalhes exatos dessa configuração do lado SAP estão documentados na Nota SAP #965908. Usando essa opção, você não teria necessidade de configurar um ouvinte do Grupo de Disponibilidade. E com isso nenhum balanceador de carga do Azure e com isso poderia investigar problemas desses componentes. Mas lembre-se, essa opção só funciona se você restringir seu Grupo de Disponibilidade para abranger duas instâncias.
A maioria dos clientes está usando a funcionalidade Always On do SQL Server para a funcionalidade de recuperação de desastres entre regiões do Azure. Vários clientes também usam a capacidade de executar backups a partir de uma réplica secundária.
Criptografia de dados transparente do SQL Server
Muitos clientes estão usando a Criptografia de Dados Transparente (TDE) do SQL Server ao implantar seus bancos de dados SAP SQL Server no Azure. A funcionalidade TDE do SQL Server é totalmente suportada pelo SAP (consulte SAP Note #1380493).
Aplicando o SQL Server TDE
Nos casos em que você executa uma migração heterogênea de outro banco de dados, em execução local, para o Windows/SQL Server em execução no Azure, você deve criar seu banco de dados de destino vazio no SQL Server com antecedência. Como próxima etapa, você aplicaria a funcionalidade TDE do SQL Server nesse banco de dados vazio. A razão pela qual você deseja executar nesta sequência é que o processo de criptografia do banco de dados vazio pode levar um bom tempo. Os processos de importação SAP importariam os dados para o banco de dados criptografado durante a fase de tempo de inatividade. A sobrecarga de importação para um banco de dados criptografado tem um impacto de tempo muito menor do que criptografar o banco de dados após a fase de exportação na fase de tempo de inatividade. Experiências negativas foram feitas ao tentar aplicar TDE com a carga de trabalho SAP em execução sobre o banco de dados. Portanto, a recomendação é tratar a implantação do TDE como uma atividade que precisa ser feita com pouca ou nenhuma carga de trabalho SAP no banco de dados específico. A partir do SQL Server 2016, você pode parar e retomar a verificação TDE que executa a criptografia inicial. O documento Transparent Data Encryption (TDE) descreve o comando e os detalhes.
Nos casos em que você move bancos de dados SAP SQL Server do local para o Azure, recomendamos testar em qual infraestrutura você pode obter a criptografia aplicada mais rapidamente. Para este caso, tenha estes fatos em mente:
- Não é possível definir quantos threads são usados para aplicar criptografia de dados ao banco de dados. O número de threads depende principalmente do número de volumes de disco pelos quais os dados e arquivos de log do SQL Server são distribuídos. Significa que quanto mais volumes distintos (letras de unidade), mais threads são envolvidos em paralelo para executar a criptografia. Essa configuração contradiz um pouco com a sugestão anterior de configuração de disco na criação de um ou um número menor de espaços de armazenamento para os arquivos de banco de dados do SQL Server em VMs do Azure. Uma configuração com alguns volumes levaria a alguns threads executando a criptografia. Uma única criptografia de thread está lendo extensões de 64 KB, criptografa-a e, em seguida, grava um registro no arquivo de log de transações, informando que a extensão foi criptografada. Como resultado, a carga no log de transações é moderada.
- Em versões mais antigas do SQL Server, a compactação de backup não obtinha mais eficiência quando você criptografava seu banco de dados do SQL Server. Esse comportamento pode se transformar em um problema quando seu plano era criptografar seu banco de dados do SQL Server local e, em seguida, copiar um backup no Azure para restaurar o banco de dados no Azure. A compactação de backup do SQL Server pode atingir uma taxa de compactação de fator 4.
- Com o SQL Server 2016, o SQL Server introduziu uma nova funcionalidade que permite compactar o backup de bancos de dados criptografados também de maneira eficiente. Veja este blog para alguns detalhes.
Usando o Azure Key Vault
O Azure oferece o serviço de um Cofre de Chaves para armazenar chaves de criptografia. O SQL Server, por outro lado, oferece um conector para usar o Azure Key Vault como armazenamento para os certificados TDE.
Mais detalhes para usar o Azure Key Vault para listas TDE do SQL Server como:
- Configure a integração do Azure Key Vault para SQL Server em VMs do Azure (Gerenciador de Recursos).
- Mais perguntas de clientes sobre a Criptografia de Dados Transparente do SQL Server – TDE + Azure Key Vault.
Importante
Usando o SQL Server TDE, especialmente com o Cofre de chaves do Azure, é recomendável usar os patches mais recentes do SQL Server 2014, SQL Server 2016 e SQL Server 2017. A razão é que, com base no feedback do cliente, otimizações e correções foram aplicadas ao código. Como exemplo, marque KBA #4058175.
Configurações mínimas de implantação
Nesta seção, sugerimos um conjunto de configurações mínimas para diferentes tamanhos de bancos de dados sob carga de trabalho SAP. É muito difícil avaliar se esses tamanhos se ajustam à sua carga de trabalho específica. Em alguns casos, podemos ser generosos na memória em comparação com o tamanho do banco de dados. Por outro lado, o tamanho do disco pode ser muito baixo para algumas das cargas de trabalho. Portanto, essas configurações devem ser tratadas como o que são. São configurações que devem lhe dar um ponto para começar. Configurações para ajustar aos seus requisitos específicos de carga de trabalho e eficiência de custos.
Um exemplo de configuração para uma pequena instância do SQL Server com um tamanho de banco de dados entre 50 GB e 250 GB pode parecer
| Configuração | VM de banco de dados | Comentários |
|---|---|---|
| Tipo de VM | E4s_v3/v4/v5 (4 vCPU/32 GiB RAM) | |
| Redes Aceleradas | Ativar | |
| Versão do SQL Server | SQL Server 2019 ou mais recente | |
| # de arquivos de dados | 4 | |
| # de ficheiros de registo | 1 | |
| # de arquivos de dados temporários | 4 ou padrão desde o SQL Server 2016 | |
| Sistema operativo | Windows Server 2019 ou mais recente | |
| Agregação de disco | Espaços de armazenamento, se desejado | |
| Sistema de ficheiros | NTFS | |
| Formatar tamanho do bloco | 64 KB | |
| # e tipo de discos de dados | Armazenamento Premium v1: 2 x P10 (RAID0) Armazenamento Premium v2: 2 x 150 GiB (RAID0) - IOPS padrão e taxa de transferência ou SSD Premium v2 equivalente |
Cache = Somente leitura para armazenamento premium v1 |
| # e tipo de discos de log | Armazenamento Premium v1: 1 x P20 Armazenamento Premium v2: 1 x 128 GiB - IOPS padrão e taxa de transferência ou SSD Premium equivalente v2 |
Cache = NENHUM |
| Parâmetro de memória máxima do SQL Server | 90% de RAM física | Assumindo uma única instância |
Um exemplo de uma configuração ou uma pequena instância do SQL Server com um tamanho de banco de dados entre 250 GB e 750 GB, como um sistema SAP Business Suite menor, pode parecer
| Configuração | VM de banco de dados | Comentários |
|---|---|---|
| Tipo de VM | E16s_v3/v4/v5 (16 vCPU/128 GiB RAM) | |
| Redes Aceleradas | Ativar | |
| Versão do SQL Server | SQL Server 2019 ou mais recente | |
| # de arquivos de dados | 8 | |
| # de ficheiros de registo | 1 | |
| # de arquivos de dados temporários | 8 ou padrão desde o SQL Server 2016 | |
| Sistema operativo | Windows Server 2019 ou mais recente | |
| Agregação de disco | Espaços de armazenamento, se desejado | |
| Sistema de ficheiros | NTFS | |
| Formatar tamanho do bloco | 64 KB | |
| # e tipo de discos de dados | Armazenamento Premium v1: 4 x P20 (RAID0) Armazenamento Premium v2: 4 x 100 GiB - 200 GiB (RAID0) - IOPS padrão e taxa de transferência extra de 25 MB/seg por disco ou SSD Premium v2 equivalente |
Cache = Somente leitura para armazenamento premium v1 |
| # e tipo de discos de log | Armazenamento Premium v1: 1 x P20 Armazenamento Premium v2: 1 x 200 GiB - IOPS padrão e taxa de transferência ou SSD Premium equivalente v2 |
Cache = NENHUM |
| Parâmetro de memória máxima do SQL Server | 90% de RAM física | Assumindo uma única instância |
Um exemplo de configuração para uma instância média do SQL Server com um tamanho de banco de dados entre 750 GB e 2.000 GB, como um sistema SAP Business Suite médio, pode parecer
| Configuração | VM de banco de dados | Comentários |
|---|---|---|
| Tipo de VM | E64s_v3/v4/v5 (64 vCPU/432 GiB RAM) | |
| Redes Aceleradas | Ativar | |
| Versão do SQL Server | SQL Server 2019 ou mais recente | |
| # de dispositivos de dados | 16 | |
| # de dispositivos de log | 1 | |
| # de arquivos de dados temporários | 8 ou padrão desde o SQL Server 2016 | |
| Sistema operativo | Windows Server 2019 ou mais recente | |
| Agregação de disco | Espaços de armazenamento, se desejado | |
| Sistema de ficheiros | NTFS | |
| Formatar tamanho do bloco | 64 KB | |
| # e tipo de discos de dados | Armazenamento Premium v1: 4 x P30 (RAID0) Armazenamento Premium v2: 4 x 250 GiB - 500 GiB - mais 2.000 IOPS e taxa de transferência de 75 MB/seg por disco ou SSD Premium v2 equivalente |
Cache = Somente leitura para armazenamento premium v1 |
| # e tipo de discos de log | Armazenamento Premium v1: 1 x P20 Armazenamento Premium v2: 1 x 400 GiB - IOPS padrão e taxa de transferência extra de 75MB/seg ou SSD Premium v2 equivalente |
Cache = NENHUM |
| Parâmetro de memória máxima do SQL Server | 90% de RAM física | Assumindo uma única instância |
Um exemplo de configuração para uma instância maior do SQL Server com um tamanho de banco de dados entre 2.000 GB e 4.000 GB, como um sistema SAP Business Suite maior, pode ser parecido com
| Configuração | VM de banco de dados | Comentários |
|---|---|---|
| Tipo de VM | E96(d)s_v5 (96 vCPU/672 GiB RAM) | |
| Redes Aceleradas | Ativar | |
| Versão do SQL Server | SQL Server 2019 ou mais recente | |
| # de dispositivos de dados | 24 | |
| # de dispositivos de log | 1 | |
| # de arquivos de dados temporários | 8 ou padrão desde o SQL Server 2016 | |
| Sistema operativo | Windows Server 2019 ou mais recente | |
| Agregação de disco | Espaços de armazenamento, se desejado | |
| Sistema de ficheiros | NTFS | |
| Formatar tamanho do bloco | 64 KB | |
| # e tipo de discos de dados | Armazenamento Premium v1: 4 x P30 (RAID0) Armazenamento Premium v2: 4 x 500 GiB - 800 GiB - mais 2500 IOPS e 100 MB/seg de taxa de transferência por disco ou SSD Premium v2 equivalente |
Cache = Somente leitura para armazenamento premium v1 |
| # e tipo de discos de log | Armazenamento Premium v1: 1 x P20 Armazenamento Premium v2: 1 x 400 GiB - mais 1.000 IOPS e taxa de transferência extra de 75MB/seg ou SSD Premium v2 equivalente |
Cache = NENHUM |
| Parâmetro de memória máxima do SQL Server | 90% de RAM física | Assumindo uma única instância |
Um exemplo de configuração para uma instância grande do SQL Server com um tamanho de banco de dados de 4 TB+, como um grande sistema SAP Business Suite usado globalmente, pode parecer
| Configuração | VM de banco de dados | Comentários |
|---|---|---|
| Tipo de VM | Série M (1,0 a 4,0 TB de RAM) | |
| Redes Aceleradas | Ativar | |
| Versão do SQL Server | SQL Server 2019 ou mais recente | |
| # de dispositivos de dados | 32 | |
| # de dispositivos de log | 1 | |
| # de arquivos de dados temporários | 8 ou padrão desde o SQL Server 2016 | |
| Sistema operativo | Windows Server 2019 ou mais recente | |
| Agregação de disco | Espaços de armazenamento, se desejado | |
| Sistema de ficheiros | NTFS | |
| Formatar tamanho do bloco | 64 KB | |
| # e tipo de discos de dados | Armazenamento Premium v1: 4+ x P40 (RAID0) Armazenamento Premium v2: 4+ x 1.000 GiB - 4.000 GiB - mais 4.500 IOPS e taxa de transferência de 125 MB/seg por disco ou SSD Premium v2 equivalente |
Cache = Somente leitura para armazenamento premium v1 |
| # e tipo de discos de log | Armazenamento Premium v1: 1 x P30 Armazenamento Premium v2: 1 x 500 GiB - mais 2.000 IOPS e taxa de transferência de 125 MB/seg ou SSD Premium v2 equivalente |
Cache = NENHUM |
| Parâmetro de memória máxima do SQL Server | 95% da RAM física | Assumindo uma única instância |
Como exemplo, essa configuração é a configuração de VM de banco de dados de um SAP Business Suite no SQL Server. Esta VM hospeda o banco de dados de 30 TB da única instância global do SAP Business Suite de uma empresa global com receita anual de mais de US$ 200 bilhões e mais de 200 mil funcionários em tempo integral. O sistema executa todo o processamento financeiro, vendas e processamento de distribuição e muitos outros processos de negócios de diferentes áreas, incluindo a folha de pagamento norte-americana. O sistema está sendo executado no Azure desde o início de 2018 usando VMs da série M do Azure como VMs de banco de dados. Como alta disponibilidade, o sistema está usando o Always On com uma réplica síncrona em outra Zona de Disponibilidade da mesma região do Azure. E outra réplica assíncrona em outra região do Azure. A camada de aplicativo NetWeaver é implantada nas famílias de VM D(a)/E(a) mais recentes.
| Configuração | VM de banco de dados | Comentários |
|---|---|---|
| Tipo de VM | M192dms_v2 (192 vCPU/4,196 GiB RAM) | |
| Redes Aceleradas | Ativado(a) | |
| Versão do SQL Server | SQL Server 2019 | |
| # de arquivos de dados | 32 | |
| # de ficheiros de registo | 1 | |
| # de arquivos de dados temporários | 8 | |
| Sistema operativo | Windows Server 2019 | |
| Agregação de disco | Storage Spaces (Espaços de Armazenamento) | |
| Sistema de ficheiros | NTFS | |
| Formatar tamanho do bloco | 64 KB | |
| # e tipo de discos de dados | Armazenamento Premium v1: 16 x P40 ou SSD Premium v2 equivalente | Cache = Somente leitura |
| # e tipo de discos de log | Armazenamento Premium v1: 1 x P60 ou SSD Premium equivalente v2 | Usando o Acelerador de Gravação |
| # e tipo de discos tempdb | Armazenamento Premium v1: 1 x P30 ou SSD Premium equivalente v2 | Sem armazenamento em cache |
| Parâmetro de memória máxima do SQL Server | 95% da RAM física |
Resumo geral do SQL Server para SAP no Azure
Há muitas recomendações neste guia e recomendamos que você o leia mais de uma vez antes de planejar sua implantação do Azure. Em geral, porém, certifique-se de seguir as principais recomendações específicas do SQL Server no Azure:
- Use a versão mais recente do SQLServer, como o SQL Server 2022, que tem mais vantagens no Azure.
- Planeje cuidadosamente o cenário do sistema SAP no Azure para equilibrar o layout do arquivo de dados e as restrições do Azure:
- Não tenha muitos discos, mas tenha o suficiente para garantir que você possa alcançar o IOPS necessário.
- Distribua apenas entre discos se precisar obter uma taxa de transferência mais alta.
- Não tenha muitos discos, mas tenha o suficiente para garantir que você possa alcançar o IOPS necessário.
- Nunca instale software ou coloque quaisquer ficheiros que exijam persistência na unidade D:\, uma vez que não é permanente. Qualquer coisa nesta unidade pode ser perdida em uma reinicialização do Windows ou reinicialização da VM.
- Use sua solução Always On do SQL Server para replicar dados de banco de dados.
- Use sempre a Resolução de Nomes, não confie em endereços IP.
- Usando o SQL Server TDE, aplique os patches mais recentes do SQL Server.
- Tenha cuidado ao usar imagens do SQL Server do Azure Marketplace. Se você usar o SQL Server, deverá alterar o agrupamento de instâncias antes de instalar qualquer sistema SAP NetWeaver nele.
- Instale e configure o SAP Host Monitoring for Azure conforme descrito no Guia de Implantação.
Próximos passos
Leia o artigo