tables de inferência para monitorar e depurar modelos
Importante
Esta funcionalidade está em Pré-visualização Pública.
Importante
Este artigo descreve tópicos que se aplicam aos tables de inferência para modelos personalizados. Para modelos externos ou cargas de trabalho de taxa de transferência provisionadas, use a inferência habilitada por AI Gateway tables.
Este artigo descreve a inferência tables para monitorizar modelos servidos. O diagrama a seguir mostra um fluxo de trabalho típico com inferência tables. O table de inferência captura automaticamente solicitações de entrada e respostas de saída para um endpoint de serviço de modelo e as registra como um Unity Catalog Delta table. Você pode usar os dados nesta table para monitorar, depurar e melhorar modelos de ML.
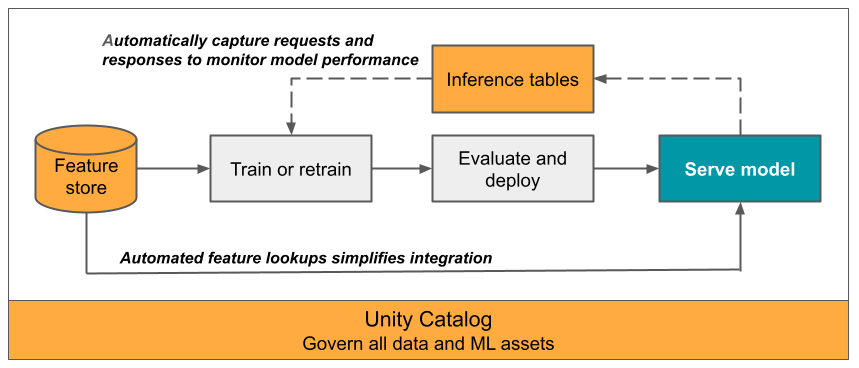
O que são inferências tables?
O monitoramento do desempenho de modelos em fluxos de trabalho de produção é um aspeto importante do ciclo de vida do modelo de IA e ML. O Inference tables simplifica o monitoramento e o diagnóstico de modelos ao registrar continuamente as entradas e as respostas das solicitações (previsões) dos endpoints do Mosaic AI Model Serving e salvando-as num Delta table no Unity Catalog. Em seguida, pode usar todas as capacidades da plataforma Databricks, como consultas Databricks SQL, notebooks e Lakehouse Monitoring para acompanhar, depurar e optimize os seus modelos.
Você pode ativar a inferência tables em qualquer ponto de extremidade de serviço de modelo existente ou recém-criado, e as solicitações para esse ponto de extremidade são automaticamente registadas em um table na UC.
Algumas aplicações comuns de inferência para tables são as seguintes:
- Monitore a qualidade dos dados e do modelo. Você pode monitorar continuamente o desempenho do seu modelo e o desvio de dados usando o Lakehouse Monitoring. O Lakehouse Monitoring gera automaticamente dados e painéis de qualidade de modelo que você pode compartilhar com as partes interessadas. Além disso, você pode habilitar alertas para saber quando precisa treinar novamente seu modelo com base em mudanças nos dados recebidos ou reduções no desempenho do modelo.
- Depurar problemas de produção. Dados de log de inferência Tables, como códigos de status HTTP, tempos de execução do modelo e códigos JSON de pedidos e respostas. Você pode usar esses dados de desempenho para fins de depuração. Você também pode usar os dados históricos no Inference Tables para comparar o desempenho do modelo em solicitações históricas.
- Crie um corpus de formação. Ao juntar o Inference Tables com rótulos de verdade básica, você pode criar um corpus de treinamento que pode usar para treinar novamente ou ajustar e melhorar seu modelo. Usando o Databricks Jobs, você pode set um ciclo de feedback contínuo e automatizar o retreinamento.
Requerimentos
- Seu espaço de trabalho deve ter o Unity Catalog habilitado.
- Tanto o criador do ponto de extremidade quanto o modificador devem ter a permissão Pode gerenciar no ponto de extremidade. Consulte Listas de controle de acesso.
- Tanto o criador quanto o modificador do endpoint devem ter as seguintes permissões de no Unity Catalog:
-
USE CATALOGpermissões especificadas no catalog. -
USE SCHEMApermissões especificadas no schema. -
CREATE TABLEpermissões no schema.
-
Habilitar e desabilitar inferência tables
Esta seção mostra como habilitar ou desabilitar a inferência tables usando a interface do usuário do Databricks. Você também pode usar a API; consulte Habilitar tables de inferência em pontos de extremidade de serviço de modelo usando a API para obter instruções.
O proprietário do tables de inferência é o usuário que criou o ponto de extremidade. Todas as listas de controle de acesso (ACLs) no table seguem as permissões padrão do Unity Catalog e podem ser modificadas pelo proprietário do table.
Aviso
O table de inferência pode ficar corrompido se fizeres uma das seguintes ações:
- Altere o tableschema.
- Altere o nome do table.
- Exclua o table.
- Perca as permissões para o Unity Catalogcatalog ou schema.
Nesse caso, a auto_capture_config do estado do ponto de extremidade indica um estado FAILED para a carga table. Se isso acontecer, você deverá criar um novo ponto de extremidade para continuar usando a inferência tables.
Para habilitar a inferência tables durante a criação do ponto de extremidade, siga as seguintes etapas:
Clique em Servindo na interface do usuário do Databricks Mosaic AI.
Clique em Criar ponto de extremidade de serviço.
Select Habilitar inferência tables.
Nos menus suspensos, selecione select o catalog desejado e schemawhere onde gostaria que o table fosse localizado.
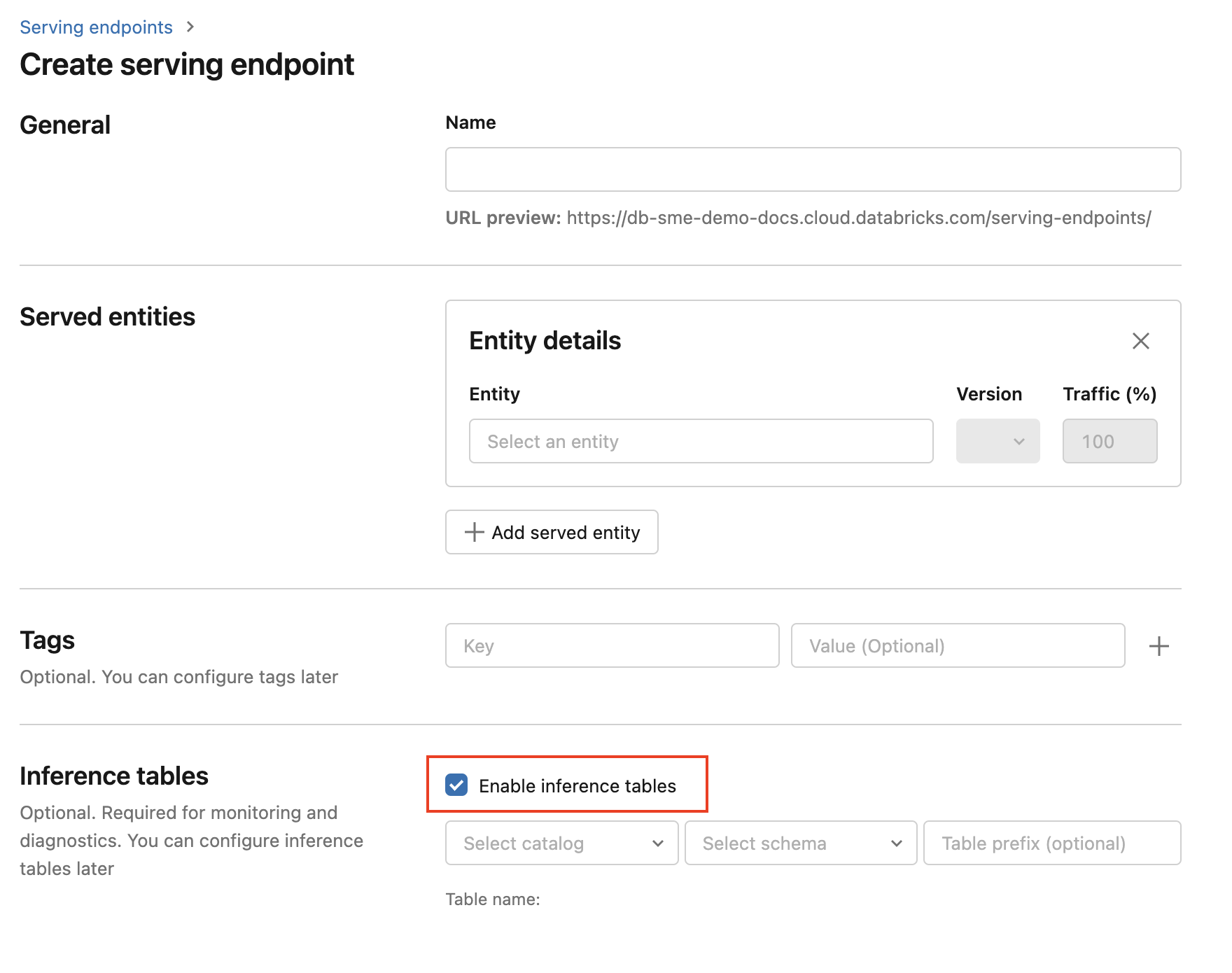
O nome table padrão é
<catalog>.<schema>.<endpoint-name>_payload. Se desejar, você pode inserir um prefixo de table personalizado.Clique em Criar ponto de extremidade de serviço.
Você também pode habilitar a inferência tables em um endpoint existente. Para editar uma configuração de ponto de extremidade existente, faça o seguinte:
- Navegue até a página do ponto final.
- Clique em Editar configuração.
- Siga as instruções anteriores, começando com o passo 3.
- Quando terminar, clique em Update endpoint de serviço.
Siga estas instruções para desativar a inferência tables:
- Navegue até a página do ponto final.
- Clique em Editar configuração.
- Clique em Ativar a inferência table para definir a marca de seleção remove.
- Quando estiver satisfeito com as especificações do ponto final, clique em Update.
Workflow: Monitore o desempenho do modelo usando inferência tables
Para monitorar o desempenho do modelo usando o tablesde inferência, siga estas etapas:
- Habilite tables de inferência em seu endpoint, durante a criação do endpoint ou atualizando-o posteriormente.
- Agende um fluxo de trabalho para processar as cargas JSON na inferência table, desempacotando-as de acordo com o schema do endpoint.
- (Opcional) Join as solicitações e respostas descompactadas com rótulos de verdade básica para permitir que as métricas de qualidade do modelo sejam calculadas.
- Crie um monitor sobre o Delta resultante table e as métricas refresh.
Os blocos de anotações iniciais implementam esse fluxo de trabalho.
Bloco de Notas inicial para monitorizar uma inferência table
O bloco de anotações a seguir implementa as etapas descritas acima para descompactar solicitações de um tablede inferência do Lakehouse Monitoring. O bloco de anotações pode ser executado sob demanda ou em uma programação recorrente usando o Databricks Jobs.
Inferência table Notebook inicial do Lakehouse Monitoring
Bloco de anotações inicial para monitorar a qualidade do texto de pontos finais que atendem LLMs
O notebook seguinte processa pedidos de inferência table, calcula um conjunto set de métricas de avaliação de texto (como legibilidade e toxicidade) e permite monitorizar estas métricas. O bloco de anotações pode ser executado sob demanda ou em uma programação recorrente usando o Databricks Jobs.
Inferência LLM table Caderno inicial Lakehouse Monitoring
Consultar e analisar resultados no table de inferência
Depois que os modelos atendidos estiverem prontos, todas as solicitações feitas aos seus modelos serão registradas automaticamente no tablede inferência, juntamente com as respostas. Você pode exibir o table na interface do usuário, consultar o table do DBSQL ou de um bloco de anotações ou consultar o table usando a API REST.
Para exibir o table na interface do usuário: Na página do ponto de extremidade, clique no nome do table de inferência para abrir o table no Catalog Explorer.

Para consultar o table do DBSQL ou de um bloco de anotações Databricks: Você pode executar um código semelhante ao seguinte para consultar a inferência table.
SELECT * FROM <catalog>.<schema>.<payload_table>
Se habilitaste a inferência tables usando a interface do utilizador, payload_table é o nome table que atribuíste quando criaste o endpoint. Se você habilitou a inferência tables usando a API, payload_table é relatado na seção state da resposta auto_capture_config. Para obter um exemplo, consulte Habilitar a inferência tables em endpoints de fornecimento de modelos usando a API.
Nota sobre o desempenho
Depois de invocar o ponto de extremidade, pode ver a invocação registada no seu table de inferência no prazo de uma hora após o envio de uma solicitação de pontuação. Além disso, o Azure Databricks garante que a entrega de logs aconteça pelo menos uma vez, portanto, é possível, embora improvável, que logs duplicados sejam enviados.
Unidade Catalog inferência tableschema
Cada pedido e resposta que é registado num table de inferência é gravado num table Delta com os seguintes schema:
Nota
Se você invocar o ponto de extremidade com um lote de entradas, todo o lote será registrado como uma linha.
| Column nome | Description | Type |
|---|---|---|
databricks_request_id |
Uma solicitação identifier gerada pelo Azure Databricks e anexada a todas as solicitações de serviço de modelo. | STRING |
client_request_id |
Uma solicitação opcional gerada pelo cliente, identifier, que pode ser especificada no corpo da solicitação do modelo de atendimento. Consulte Especificar client_request_id para obter mais informações. |
STRING |
date |
A data UTC em que o modelo de solicitação de notificação foi recebido. | DATE |
timestamp_ms |
O carimbo de data/hora em milissegundos de época quando a solicitação de serviço do modelo foi recebida. | LONGO |
status_code |
O código de status HTTP que foi retornado do modelo. | INT |
sampling_fraction |
A fração de amostragem utilizada no caso de o pedido ter sido reduzido para amostragem. Esse valor está entre 0 e 1, where 1 representa que 100% das solicitações de entrada foram incluídas. | DUPLO |
execution_time_ms |
O tempo de execução em milissegundos para o qual o modelo realizou inferência. Isso não inclui latências de rede de sobrecarga e representa apenas o tempo que o modelo levou para generate previsões. | LONGO |
request |
O corpo JSON de solicitação bruta que foi enviado para o ponto de extremidade de serviço do modelo. | STRING |
response |
O corpo JSON de resposta bruta que foi retornado pelo ponto de extremidade de serviço do modelo. | STRING |
request_metadata |
Um mapa de metadados relacionados ao modelo que serve o ponto de extremidade associado à solicitação. Este mapa contém o nome do ponto de extremidade, o nome do modelo e a versão do modelo usado para o seu ponto de extremidade. | CADEIA DE CARACTERES DO MAPA<, STRING> |
Especificar client_request_id
O client_request_id campo é um valor opcional que o usuário pode fornecer no corpo da solicitação de serviço do modelo. Isso permite que o usuário forneça seu próprio identifier para uma solicitação que aparece na inferência final table sob o client_request_id e pode ser usado para unir sua solicitação com outras tables que usam o client_request_id, como a junção de rótulo de verdade terreno. Para especificar um client_request_id, inclua-o como uma chave de nível superior da carga útil da solicitação. Se não client_request_id for especificado, o valor aparecerá como nulo na linha correspondente à solicitação.
{
"client_request_id": "<user-provided-id>",
"dataframe_records": [
{
"sepal length (cm)": 5.1,
"sepal width (cm)": 3.5,
"petal length (cm)": 1.4,
"petal width (cm)": 0.2
},
{
"sepal length (cm)": 4.9,
"sepal width (cm)": 3,
"petal length (cm)": 1.4,
"petal width (cm)": 0.2
},
{
"sepal length (cm)": 4.7,
"sepal width (cm)": 3.2,
"petal length (cm)": 1.3,
"petal width (cm)": 0.2
}
]
}
O client_request_id pode ser usado mais tarde para uniões de rótulos de verdade fundamental se houver outros tables que tenham rótulos associados ao client_request_id.
Limitações
- Não há suporte para chaves gerenciadas pelo cliente.
- Para endpoints que hospedam modelos de base
, a inferência só é suportada em cargas de trabalho com taxa de transferência provisionada . - O Firewall do Azure pode resultar em falhas na criação do Unity Catalog Delta table, portanto, não é suportado por padrão. Entre em contato com sua equipe de conta Databricks para ativá-lo.
- Quando os tables de inferência estão habilitados, a limit para a simultaneidade máxima total em todos os modelos servidos em um único ponto de extremidade é 128. Entre em contato com sua equipe de conta do Azure Databricks para solicitar um aumento para este limit.
- Se um table de inferência contiver mais de 500 mil arquivos, nenhum dado adicional será registrado. Para evitar exceder esse limit, execute OPTIMIZE ou set a retenção em seu table excluindo dados mais antigos. Para verificar o número de ficheiros no seu table, execute
DESCRIBE DETAIL <catalog>.<schema>.<payload_table>. - Atualmente, a entrega de logs da inferência tables é feita de forma otimizada, mas pode-se esperar que os logs estejam disponíveis dentro de uma hora após uma solicitação. Entre em contato com sua equipe de conta Databricks para obter mais informações.
Para obter limitações gerais do modelo que serve o ponto de extremidade, consulte Limites e regiões do serviço de modelo.