Formato Parquet no Azure Data Factory e Azure Synapse Analytics
APLICA-SE A: Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Gorjeta
Experimente o Data Factory no Microsoft Fabric, uma solução de análise tudo-em-um para empresas. O Microsoft Fabric abrange tudo, desde a movimentação de dados até ciência de dados, análises em tempo real, business intelligence e relatórios. Saiba como iniciar uma nova avaliação gratuitamente!
Siga este artigo quando quiser analisar os arquivos do Parquet ou gravar os dados no formato Parquet.
O formato Parquet é suportado para os seguintes conectores:
- Amazon S3
- Armazenamento compatível com Amazon S3
- Azure Blob
- Armazenamento do Azure Data Lake Ger1
- Azure Data Lake Storage Gen2 (Armazenamento do Azure Data Lake Gen2)
- Ficheiros do Azure
- Sistema de Ficheiros
- FTP
- Google Cloud Storage
- HDFS
- HTTP
- Armazenamento em nuvem Oracle
- SFTP
Para obter uma lista de recursos suportados para todos os conectores disponíveis, visite o artigo Visão geral dos conectores.
Usando o Self-hosted Integration Runtime
Importante
Para cópia habilitada pelo Self-hosted Integration Runtime, por exemplo, entre armazenamentos de dados locais e na nuvem, se você não estiver copiando arquivos do Parquet como estão, precisará instalar o JRE 8 de 64 bits (Java Runtime Environment), JDK 23 (Java Development Kit) ou OpenJDK em sua máquina IR. Confira o parágrafo a seguir com mais detalhes.
Para cópia executada em IR auto-hospedado com serialização/desserialização de arquivo Parquet, o serviço localiza o tempo de execução Java verificando, em primeiro lugar, o registro (SOFTWARE\JavaSoft\Java Runtime Environment\{Current Version}\JavaHome) para JRE, se não for encontrado, em segundo lugar, verificando a variável JAVA_HOME de sistema para OpenJDK.
- Para usar o JRE: O IR de 64 bits requer o JRE de 64 bits. Você pode encontrá-lo aqui.
-
Para usar o JDK: o IR de 64 bits requer o JDK 23 de 64 bits. Você pode encontrá-lo aqui. Certifique-se de atualizar a
JAVA_HOMEvariável de sistema para a pasta raiz da instalação do JDK 23, ou sejaC:\Program Files\Java\jdk-23, e adicione o caminho para asC:\Program Files\Java\jdk-23\binpastas eC:\Program Files\Java\jdk-23\bin\serverpara aPathvariável de sistema. - Para usar o OpenJDK: É suportado desde a versão 3.13 do IR. Empacote o jvm.dll com todos os outros assemblies necessários do OpenJDK na máquina IR auto-hospedada e defina a variável de ambiente do sistema JAVA_HOME de acordo e, em seguida, reinicie o IR auto-hospedado para entrar em vigor imediatamente. Para baixar o Microsoft Build do OpenJDK, consulte Microsoft Build do OpenJDK™.
Gorjeta
Se você copiar dados de/para o formato Parquet usando o Self-hosted Integration Runtime e clicar no erro "Ocorreu um erro ao invocar java, message: java.lang.OutOfMemoryError:Java heap space", você pode adicionar uma variável _JAVA_OPTIONS de ambiente na máquina que hospeda o IR auto-hospedado para ajustar o tamanho de heap min/max para a JVM para habilitar essa cópia e, em seguida, executar novamente o pipeline.
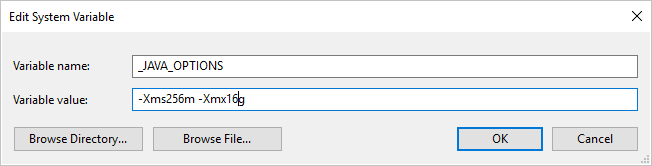
Exemplo: definir variável _JAVA_OPTIONS com valor -Xms256m -Xmx16g. O sinalizador Xms especifica o pool de alocação de memória inicial para uma Java Virtual Machine (JVM), enquanto Xmx especifica o pool máximo de alocação de memória. Isso significa que a JVM será iniciada com Xms quantidade de memória e poderá usar um máximo de Xmx quantidade de memória. Por padrão, o serviço usa min 64 MB e max 1G.
Propriedades do conjunto de dados
Para obter uma lista completa de seções e propriedades disponíveis para definir conjuntos de dados, consulte o artigo Conjuntos de dados. Esta seção fornece uma lista de propriedades suportadas pelo conjunto de dados Parquet.
| Property | Descrição | Obrigatório |
|---|---|---|
| tipo | A propriedade type do conjunto de dados deve ser definida como Parquet. | Sim |
| localização | Configurações de localização do(s) arquivo(s). Cada conector baseado em arquivo tem seu próprio tipo de local e propriedades suportadas em location.
Consulte os detalhes no artigo do conector -> seção Propriedades do conjunto de dados. |
Sim |
| compressãoCodec | O codec de compressão para usar ao gravar em arquivos Parquet. Ao ler a partir de arquivos Parquet, Data Factories determinar automaticamente o codec de compressão com base nos metadados do arquivo. Os tipos suportados são "none", "gzip", "snappy" (padrão) e "lzo". Observação atualmente A atividade de cópia não suporta LZO quando arquivos Parquet de leitura/gravação. |
Não |
Nota
O espaço em branco no nome da coluna não é suportado para arquivos Parquet.
Abaixo está um exemplo de conjunto de dados do Parquet no Armazenamento de Blobs do Azure:
{
"name": "ParquetDataset",
"properties": {
"type": "Parquet",
"linkedServiceName": {
"referenceName": "<Azure Blob Storage linked service name>",
"type": "LinkedServiceReference"
},
"schema": [ < physical schema, optional, retrievable during authoring > ],
"typeProperties": {
"location": {
"type": "AzureBlobStorageLocation",
"container": "containername",
"folderPath": "folder/subfolder",
},
"compressionCodec": "snappy"
}
}
}
Propriedades da atividade Copy
Para obter uma lista completa de seções e propriedades disponíveis para definir atividades, consulte o artigo Pipelines . Esta seção fornece uma lista de propriedades suportadas pela fonte e pia do Parquet.
Parquet como fonte
As propriedades a seguir são suportadas na seção copy activity *source* .
| Property | Descrição | Obrigatório |
|---|---|---|
| tipo | A propriedade type da fonte de atividade de cópia deve ser definida como ParquetSource. | Sim |
| storeSettings | Um grupo de propriedades sobre como ler dados de um armazenamento de dados. Cada conector baseado em arquivo tem suas próprias configurações de leitura suportadas em storeSettings.
Veja os detalhes no artigo do conector -> Seção Copiar propriedades da atividade. |
Não |
Parquet como lavatório
As propriedades a seguir são suportadas na seção de atividade de cópia *sink* .
| Property | Descrição | Obrigatório |
|---|---|---|
| tipo | A propriedade type do coletor de atividade de cópia deve ser definida como ParquetSink. | Sim |
| formatConfigurações | Um grupo de propriedades. Consulte a tabela de configurações de gravação do Parquet abaixo. | Não |
| storeSettings | Um grupo de propriedades sobre como gravar dados em um armazenamento de dados. Cada conector baseado em arquivo tem suas próprias configurações de gravação suportadas em storeSettings.
Veja os detalhes no artigo do conector -> Seção Copiar propriedades da atividade. |
Não |
Configurações de gravação do Parquet suportadas emformatSettings:
| Property | Descrição | Obrigatório |
|---|---|---|
| tipo | O tipo de formatSettings deve ser definido como ParquetWriteSettings. | Sim |
| maxRowsPerFile | Ao gravar dados em uma pasta, você pode optar por gravar em vários arquivos e especificar o máximo de linhas por arquivo. | Não |
| fileNamePrefix | Aplicável quando maxRowsPerFile configurado.Especifique o prefixo do nome do arquivo ao gravar dados em vários arquivos, resultando neste padrão: <fileNamePrefix>_00000.<fileExtension>. Se não for especificado, o prefixo do nome do arquivo será gerado automaticamente. Essa propriedade não se aplica quando a origem é armazenamento baseado em arquivo ou armazenamento de dados habilitado para opção de partição. |
Não |
Mapeando propriedades de fluxo de dados
No mapeamento de fluxos de dados, você pode ler e gravar no formato parquet nos seguintes armazenamentos de dados: Azure Blob Storage, Azure Data Lake Storage Gen1, Azure Data Lake Storage Gen2 e SFTP, e pode ler o formato parquet no Amazon S3.
Propriedades de origem
A tabela abaixo lista as propriedades suportadas por uma fonte de parquet. Você pode editar essas propriedades na guia Opções de origem .
| Nome | Descrição | Obrigatório | Valores permitidos | Propriedade do script de fluxo de dados |
|---|---|---|---|---|
| Formato | O formato deve ser parquet |
sim | parquet |
format |
| Caminhos curinga | Todos os arquivos correspondentes ao caminho curinga serão processados. Substitui a pasta e o caminho do arquivo definidos no conjunto de dados. | não | String[] | wildcardCaminhos |
| Caminho da raiz da partição | Para dados de arquivo particionados, você pode inserir um caminho raiz de partição para ler pastas particionadas como colunas | não | String | partitionRootPath |
| Lista de arquivos | Se sua fonte está apontando para um arquivo de texto que lista os arquivos a serem processados | não |
true ou false |
Lista de arquivos |
| Coluna para armazenar o nome do arquivo | Criar uma nova coluna com o nome do arquivo de origem e o caminho | não | String | rowUrlColumn |
| Após a conclusão | Exclua ou mova os arquivos após o processamento. O caminho do arquivo começa a partir da raiz do contêiner | não | Eliminar: true ou false Movimentar-se: [<from>, <to>] |
purgeFiles moveFiles |
| Filtrar por última modificação | Opte por filtrar ficheiros com base na data em que foram alterados pela última vez | não | Carimbo de Data/Hora | modificadoApós modificadoAntes |
| Não permitir que nenhum arquivo seja encontrado | Se verdadeiro, um erro não é lançado se nenhum arquivo for encontrado | não |
true ou false |
ignoreNoFilesFound |
Exemplo de fonte
A imagem abaixo é um exemplo de uma configuração de fonte de parquet no mapeamento de fluxos de dados.
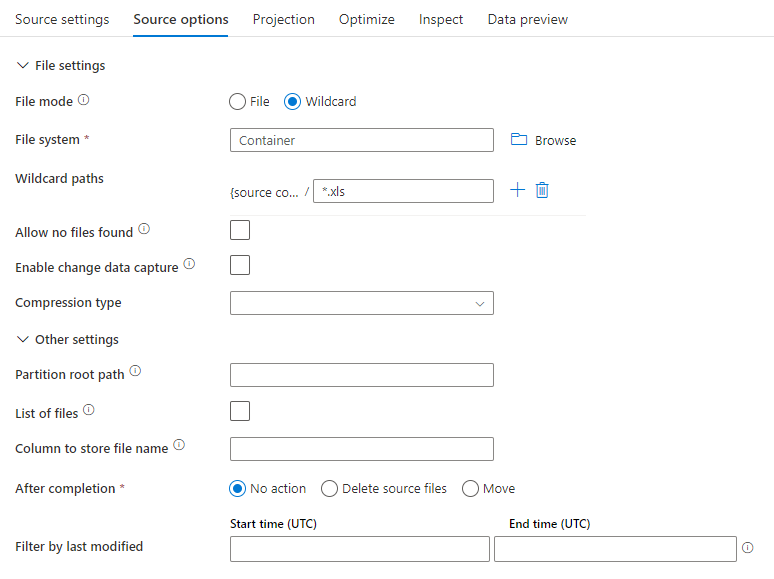
O script de fluxo de dados associado é:
source(allowSchemaDrift: true,
validateSchema: false,
rowUrlColumn: 'fileName',
format: 'parquet') ~> ParquetSource
Propriedades do lavatório
A tabela abaixo lista as propriedades suportadas por uma pia de parquet. Você pode editar essas propriedades na guia Configurações .
| Nome | Descrição | Obrigatório | Valores permitidos | Propriedade do script de fluxo de dados |
|---|---|---|---|---|
| Formato | O formato deve ser parquet |
sim | parquet |
format |
| Limpar a pasta | Se a pasta de destino for limpa antes da gravação | não |
true ou false |
truncate |
| Opção de nome de arquivo | O formato de nomenclatura dos dados gravados. Por padrão, um arquivo por partição no formato part-#####-tid-<guid> |
não | Padrão: String Por partição: String[] Como dados na coluna: String Saída para um único arquivo: ['<fileName>'] |
filePattern partitionFileNames rowUrlColumn partitionFileNames |
Exemplo de lavatório
A imagem abaixo é um exemplo de uma configuração de coletor de parquet no mapeamento de fluxos de dados.
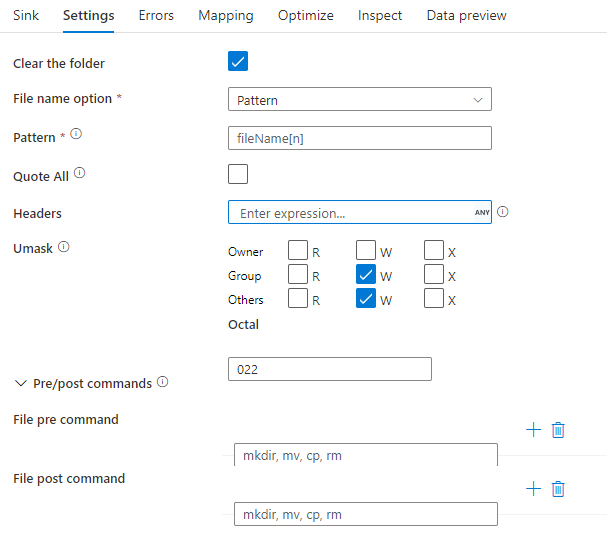
O script de fluxo de dados associado é:
ParquetSource sink(
format: 'parquet',
filePattern:'output[n].parquet',
truncate: true,
allowSchemaDrift: true,
validateSchema: false,
skipDuplicateMapInputs: true,
skipDuplicateMapOutputs: true) ~> ParquetSink
Suporte a tipos de dados
Atualmente, tipos de dados complexos de Parquet (por exemplo, MAP, LIST, STRUCT) são suportados apenas em Fluxos de Dados, não em Atividade de Cópia. Para usar tipos complexos em fluxos de dados, não importe o esquema de arquivo no conjunto de dados, deixando o esquema em branco no conjunto de dados. Em seguida, na transformação Source, importe a projeção.