Copiar recursos de otimização de desempenho de atividade
APLICA-SE A:  Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Gorjeta
Experimente o Data Factory no Microsoft Fabric, uma solução de análise tudo-em-um para empresas. O Microsoft Fabric abrange tudo, desde a movimentação de dados até ciência de dados, análises em tempo real, business intelligence e relatórios. Saiba como iniciar uma nova avaliação gratuitamente!
Este artigo descreve os recursos de otimização de desempenho da atividade de cópia que você pode aproveitar nos pipelines do Azure Data Factory e Synapse.
Configurando recursos de desempenho com a interface do usuário
Ao selecionar uma atividade Copiar na tela do editor de pipeline e escolher a guia Configurações na área de configuração da atividade abaixo da tela, você verá opções para configurar todos os recursos de desempenho detalhados abaixo.
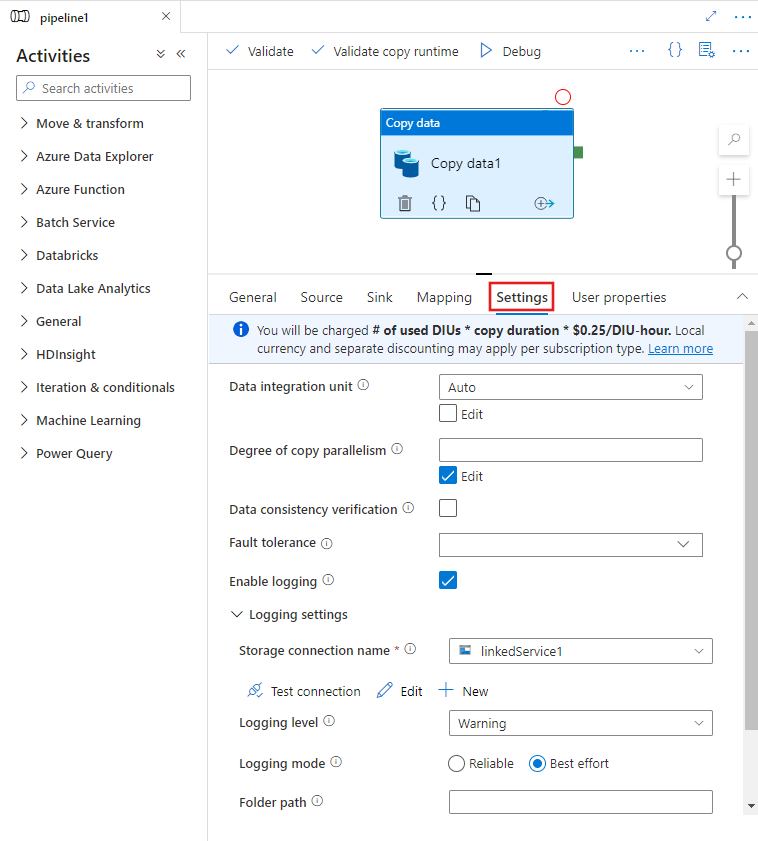
Unidades de Integração de Dados
Uma Unidade de Integração de Dados é uma medida que representa a potência (uma combinação de CPU, memória e alocação de recursos de rede) de uma única unidade dentro do serviço. A Unidade de Integração de Dados só se aplica ao tempo de execução de integração do Azure, mas não ao tempo de execução de integração auto-hospedado.
As DIUs permitidas para habilitar uma execução de atividade de cópia estão entre 4 e 256. Se não for especificado ou se você escolher "Auto" na interface do usuário, o serviço aplicará dinamicamente a configuração DIU ideal com base no seu par fonte-coletor e padrão de dados. A tabela a seguir lista os intervalos de DIU suportados e o comportamento padrão em diferentes cenários de cópia:
| Copiar cenário | Gama DIU suportada | DIUs padrão determinadas pelo serviço |
|---|---|---|
| Entre armazenamentos de arquivos | - Copiar de ou para um único ficheiro: 4 - Copiar de e para vários ficheiros: 4-256 dependendo do número e tamanho dos ficheiros Por exemplo, se você copiar dados de uma pasta com 4 arquivos grandes e optar por preservar a hierarquia, o DIU efetivo máximo é 16; quando você escolhe mesclar o arquivo, o DIU efetivo máximo é 4. |
Entre 4 e 32, dependendo do número e tamanho dos arquivos |
| Do armazenamento de arquivos para o armazenamento de não-arquivos | - Copiar de um único ficheiro: 4 - Cópia de vários arquivos: 4-256 dependendo do número e tamanho dos arquivos Por exemplo, se você copiar dados de uma pasta com 4 arquivos grandes, o DIU efetivo máximo é 16. |
- Copiar para o Banco de Dados SQL do Azure ou para o Azure Cosmos DB: entre 4 e 16, dependendo da camada de coletor (DTUs/RUs) e do padrão de arquivo de origem - Copiar para o Azure Synapse Analytics usando a instrução PolyBase ou COPY: 2 - Outro cenário: 4 |
| Do armazenamento de não-arquivos para o armazenamento de arquivos | - Copie de armazenamentos de dados habilitados para opção de partição (incluindo Banco de Dados do Azure para PostgreSQL, Banco de Dados SQL do Azure, Instância Gerenciada SQL do Azure, Azure Synapse Analytics, Oracle, Netezza, SQL Server e Teradata): 4-256 ao gravar em uma pasta e 4 ao gravar em um único arquivo. Nota por partição de dados de origem pode usar até 4 DIUs. - Outros cenários: 4 |
- Cópia de REST ou HTTP: 1 - Cópia do Amazon Redshift usando UNLOAD: 4 - Outro cenário: 4 |
| Entre armazenamentos que não são de arquivos | - Copie de armazenamentos de dados habilitados para opção de partição (incluindo Banco de Dados do Azure para PostgreSQL, Banco de Dados SQL do Azure, Instância Gerenciada SQL do Azure, Azure Synapse Analytics, Oracle, Netezza, SQL Server e Teradata): 4-256 ao gravar em uma pasta e 4 ao gravar em um único arquivo. Nota por partição de dados de origem pode usar até 4 DIUs. - Outros cenários: 4 |
- Cópia de REST ou HTTP: 1 - Outro cenário: 4 |
Você pode ver as DIUs usadas para cada execução de cópia na exibição de monitoramento de atividade de cópia ou saída de atividade. Para obter mais informações, consulte Monitoramento de atividade de cópia. Para substituir esse padrão, especifique um valor para a dataIntegrationUnits propriedade da seguinte maneira. O número real de DIUs que a operação de cópia usa em tempo de execução é igual ou menor do que o valor configurado, dependendo do seu padrão de dados.
Você será cobrado # de DIUs usados * duração da cópia * preço unitário / DIU-hora. Veja os preços atuais aqui. Moeda local e descontos separados podem ser aplicados por tipo de assinatura.
Exemplo:
"activities":[
{
"name": "Sample copy activity",
"type": "Copy",
"inputs": [...],
"outputs": [...],
"typeProperties": {
"source": {
"type": "BlobSource",
},
"sink": {
"type": "AzureDataLakeStoreSink"
},
"dataIntegrationUnits": 128
}
}
]
Escalabilidade do runtime de integração autoalojado
Se você quiser obter uma taxa de transferência mais alta, poderá aumentar ou expandir o IR auto-hospedado:
- Se a CPU e a memória disponível no nó IR auto-hospedado não forem totalmente utilizadas, mas a execução de trabalhos simultâneos estiver atingindo o limite, você deverá aumentar a escala aumentando o número de trabalhos simultâneos que podem ser executados em um nó. Veja aqui as instruções.
- Se, por outro lado, a CPU estiver alta no nó IR auto-hospedado ou a memória disponível estiver baixa, você poderá adicionar um novo nó para ajudar a dimensionar a carga entre os vários nós. Veja aqui as instruções.
Observe que, nos cenários a seguir, a execução de atividade de cópia única pode aproveitar vários nós de RI auto-hospedados:
- Copie dados de repositórios baseados em arquivos, dependendo do número e tamanho dos arquivos.
- Copie dados do armazenamento de dados habilitado para opção de partição (incluindo Banco de Dados SQL do Azure, Instância Gerenciada SQL do Azure, Azure Synapse Analytics, Oracle, Netezza, SAP HANA, SAP Open Hub, SAP Table, SQL Server e Teradata), dependendo do número de partições de dados.
Cópia paralela
Você pode definir cópia paralela (parallelCopies propriedade na definição JSON da atividade Copiar ou Degree of parallelism configuração na guia Configurações das propriedades da atividade Copiar na interface do usuário) na atividade de cópia para indicar o paralelismo que você deseja que a atividade de cópia use. Você pode pensar nessa propriedade como o número máximo de threads dentro da atividade de cópia que leem da fonte ou gravam nos armazenamentos de dados do coletor em paralelo.
A cópia paralela é ortogonal para Unidades de Integração de Dados ou nós IR auto-hospedados. Ele é contado em todas as DIUs ou nós IR auto-hospedados.
Para cada atividade de cópia executada, por padrão, o serviço aplica dinamicamente a configuração de cópia paralela ideal com base no par fonte-coletor e no padrão de dados.
Gorjeta
O comportamento padrão da cópia paralela geralmente oferece a melhor taxa de transferência, que é determinada automaticamente pelo serviço com base no seu par fonte-coletor, padrão de dados e número de DIUs ou na contagem de CPU/memória/nó do IR auto-hospedado. Consulte Solucionar problemas de desempenho da atividade de cópia sobre quando ajustar a cópia paralela.
A tabela a seguir lista o comportamento de cópia paralela:
| Copiar cenário | Comportamento de cópia paralela |
|---|---|
| Entre armazenamentos de arquivos | parallelCopies determina o paralelismo no nível do arquivo. A fragmentação dentro de cada arquivo acontece por baixo de forma automática e transparente. Ele foi projetado para usar o melhor tamanho de bloco adequado para um determinado tipo de armazenamento de dados para carregar dados em paralelo. O número real de cópias paralelas que a atividade de cópia usa em tempo de execução não é mais do que o número de arquivos que você tem. Se o comportamento de cópia for mergeFile no coletor de arquivos, a atividade de cópia não poderá tirar proveito do paralelismo no nível do arquivo. |
| Do armazenamento de arquivos para o armazenamento de não-arquivos | - Ao copiar dados para o Banco de Dados SQL do Azure ou para o Azure Cosmos DB, a cópia paralela padrão também depende da camada de coletor (número de DTUs/RUs). - Ao copiar dados para a Tabela do Azure, a cópia paralela padrão é 4. |
| Do armazenamento de não-arquivos para o armazenamento de arquivos | - Ao copiar dados do armazenamento de dados habilitado para opção de partição (incluindo Banco de Dados SQL do Azure, Instância Gerenciada SQL do Azure, Azure Synapse Analytics, Oracle, Amazon RDS for Oracle, Netezza, SAP HANA, SAP Open Hub, SAP Table, SQL Server, Amazon RDS for SQL Server e Teradata), a cópia paralela padrão é 4. O número real de cópias paralelas que a atividade de cópia usa em tempo de execução não é mais do que o número de partições de dados que você tem. Ao usar o Self-hosted Integration Runtime e copiar para o Azure Blob/ADLS Gen2, observe que a cópia paralela efetiva máxima é 4 ou 5 por nó IR. - Para outros cenários, a cópia paralela não entra em vigor. Mesmo que o paralelismo seja especificado, ele não é aplicado. |
| Entre armazenamentos que não são de arquivos | - Ao copiar dados para o Banco de Dados SQL do Azure ou para o Azure Cosmos DB, a cópia paralela padrão também depende da camada de coletor (número de DTUs/RUs). - Ao copiar dados do armazenamento de dados habilitado para opção de partição (incluindo Banco de Dados SQL do Azure, Instância Gerenciada SQL do Azure, Azure Synapse Analytics, Oracle, Amazon RDS for Oracle, Netezza, SAP HANA, SAP Open Hub, SAP Table, SQL Server, Amazon RDS for SQL Server e Teradata), a cópia paralela padrão é 4. - Ao copiar dados para a Tabela do Azure, a cópia paralela padrão é 4. |
Para controlar a carga em máquinas que hospedam seus armazenamentos de dados ou ajustar o desempenho da cópia, você pode substituir o valor padrão e especificar um valor para a parallelCopies propriedade. O valor deve ser um número inteiro maior ou igual a 1. Em tempo de execução, para obter o melhor desempenho, a atividade de cópia usa um valor menor ou igual ao valor definido.
Ao especificar um valor para a parallelCopies propriedade, leve em consideração o aumento de carga em seus armazenamentos de dados de origem e coletor. Considere também o aumento de carga para o tempo de execução de integração auto-hospedado se a atividade de cópia for habilitada por ele. Esse aumento de carga acontece especialmente quando você tem várias atividades ou execuções simultâneas das mesmas atividades que são executadas no mesmo armazenamento de dados. Se você notar que o armazenamento de dados ou o tempo de execução de integração auto-hospedado está sobrecarregado com a carga, diminua o parallelCopies valor para aliviar a carga.
Exemplo:
"activities":[
{
"name": "Sample copy activity",
"type": "Copy",
"inputs": [...],
"outputs": [...],
"typeProperties": {
"source": {
"type": "BlobSource",
},
"sink": {
"type": "AzureDataLakeStoreSink"
},
"parallelCopies": 32
}
}
]
Cópia faseada
Ao copiar dados de um armazenamento de dados de origem para um repositório de dados coletor, você pode optar por usar o armazenamento de Blob do Azure ou o Azure Data Lake Storage Gen2 como um repositório de preparo provisório. O estadiamento é especialmente útil nos seguintes casos:
- Você deseja ingerir dados de vários armazenamentos de dados no Azure Synapse Analytics via PolyBase, copiar dados de/para o Snowflake ou ingerir dados do Amazon Redshift/HDFS com desempenho. Saiba mais detalhes em:
- Você não deseja abrir portas diferentes da porta 80 e da porta 443 no firewall devido às políticas de TI corporativas. Por exemplo, quando você copia dados de um armazenamento de dados local para um Banco de Dados SQL do Azure ou um Azure Synapse Analytics, você precisa ativar a comunicação TCP de saída na porta 1433 para o firewall do Windows e o firewall corporativo. Nesse cenário, a cópia em estágios pode aproveitar o tempo de execução de integração auto-hospedado para primeiro copiar dados para um armazenamento de preparo via HTTP ou HTTPS na porta 443 e, em seguida, carregar os dados do preparo no Banco de Dados SQL ou no Azure Synapse Analytics. Nesse fluxo, você não precisa habilitar a porta 1433.
- Às vezes, leva um tempo para executar uma movimentação de dados híbrida (ou seja, copiar de um armazenamento de dados local para um armazenamento de dados em nuvem) através de uma conexão de rede lenta. Para melhorar o desempenho, você pode usar a cópia em estágios para compactar os dados no local para que leve menos tempo para mover os dados para o armazenamento de dados de preparo na nuvem. Em seguida, você pode descompactar os dados no repositório de preparo antes de carregar no armazenamento de dados de destino.
Como funciona a cópia faseada
Quando você ativa o recurso de preparo, primeiro os dados são copiados do armazenamento de dados de origem para o armazenamento de preparo (traga seu próprio Blob do Azure ou Azure Data Lake Storage Gen2). Em seguida, os dados são copiados do preparo para o armazenamento de dados do coletor. A atividade de cópia gerencia automaticamente o fluxo de dois estágios para você e também limpa dados temporários do armazenamento de preparo após a conclusão da movimentação de dados.

Você precisa conceder permissão de exclusão ao Azure Data Factory em seu armazenamento de preparo, para que os dados temporários possam ser limpos após a execução da atividade de cópia.
Ao ativar a movimentação de dados usando um repositório de preparo, você pode especificar se deseja que os dados sejam compactados antes de mover dados do armazenamento de dados de origem para o repositório de preparo e, em seguida, descompactados antes de mover dados de um armazenamento de dados provisório ou de preparo para o armazenamento de dados do coletor.
Atualmente, não é possível copiar dados entre dois armazenamentos de dados conectados por meio de diferentes IRs auto-hospedados, nem com nem sem cópia em estágios. Para esse cenário, você pode configurar duas atividades de cópia explicitamente encadeadas para copiar da origem para o preparo e, em seguida, do preparo para o coletor.
Configuração
Configure a configuração enableStaging na atividade de cópia para especificar se deseja que os dados sejam preparados no armazenamento antes de carregá-los em um armazenamento de dados de destino. Ao definir enableStaging como TRUE, especifique as propriedades adicionais listadas na tabela a seguir.
| Property | Descrição | Default value | Necessário |
|---|---|---|---|
| habilitarEstadiamento | Especifique se deseja copiar dados por meio de um repositório de preparo provisório. | False | Não |
| linkedServiceName | Especifique o nome de um armazenamento de Blob do Azure ou serviço vinculado do Azure Data Lake Storage Gen2 , que se refere à instância de Armazenamento que você usa como um repositório de preparo provisório. | N/A | Sim, quando enableStaging estiver definido como TRUE |
| path | Especifique o caminho que você deseja conter os dados em estágios. Se você não fornecer um caminho, o serviço criará um contêiner para armazenar dados temporários. | N/A | Não (Sim quando storageIntegration o conector Snowflake é especificado) |
| enableCompression | Especifica se os dados devem ser compactados antes de serem copiados para o destino. Essa configuração reduz o volume de dados que estão sendo transferidos. | False | Não |
Nota
Se você usar cópia em estágios com compactação habilitada, a entidade de serviço ou a autenticação MSI para serviço vinculado de blob de preparo não será suportada.
Aqui está uma definição de exemplo de uma atividade de cópia com as propriedades descritas na tabela anterior:
"activities":[
{
"name": "CopyActivityWithStaging",
"type": "Copy",
"inputs": [...],
"outputs": [...],
"typeProperties": {
"source": {
"type": "OracleSource",
},
"sink": {
"type": "SqlDWSink"
},
"enableStaging": true,
"stagingSettings": {
"linkedServiceName": {
"referenceName": "MyStagingStorage",
"type": "LinkedServiceReference"
},
"path": "stagingcontainer/path"
}
}
}
]
Impacto na faturação da cópia faseada
Você é cobrado com base em duas etapas: duração da cópia e tipo de cópia.
- Quando você usa o preparo durante uma cópia na nuvem, que é copiar dados de um armazenamento de dados na nuvem para outro armazenamento de dados na nuvem, ambos os estágios habilitados pelo tempo de execução da integração do Azure, é cobrado o [soma da duração da cópia para as etapas 1 e 2] x [preço unitário da cópia na nuvem].
- Quando você usa o preparo durante uma cópia híbrida, que é copiar dados de um armazenamento de dados local para um armazenamento de dados em nuvem, um estágio habilitado por um tempo de execução de integração auto-hospedado, você é cobrado por [duração da cópia híbrida] x [preço unitário da cópia híbrida] + [duração da cópia na nuvem] x [preço unitário da cópia na nuvem].
Conteúdos relacionados
Veja os outros artigos da atividade de cópia: