Use MirrorMaker to replicate Apache Kafka topics with Kafka on HDInsight (Utilizar o MirrorMaker para replicar tópicos do Apache Kafka com o Kafka no HDInsight)
Saiba como utilizar a funcionalidade de espelhamento do Apache Kafka para replicar tópicos para um cluster secundário. Pode executar o espelhamento como um processo contínuo ou intermitentemente para migrar dados de um cluster para outro.
Neste artigo, irá utilizar o espelhamento para replicar tópicos entre dois clusters do HDInsight. Estes clusters encontram-se em redes virtuais diferentes em datacenters diferentes.
Aviso
Não utilize o espelhamento como forma de alcançar a tolerância a falhas. O deslocamento para itens dentro de um tópico é diferente entre os clusters primário e secundário, pelo que os clientes não podem utilizar os dois alternadamente. Se estiver preocupado com a tolerância a falhas, deve definir a replicação para os tópicos no cluster. Para obter mais informações, veja Introdução ao Apache Kafka no HDInsight.
Como funciona o espelhamento do Apache Kafka
O espelhamento funciona com a ferramenta MirrorMaker , que faz parte do Apache Kafka. O MirrorMaker consome registos de tópicos no cluster primário e, em seguida, cria uma cópia local no cluster secundário. O MirrorMaker utiliza um (ou mais) consumidores que leem a partir do cluster primário e um produtor que escreve no cluster local (secundário).
A configuração de espelhamento mais útil para a recuperação após desastre utiliza clusters do Kafka em diferentes regiões do Azure. Para tal, as redes virtuais onde os clusters residem estão em modo de peering.
O diagrama seguinte ilustra o processo de espelhamento e como a comunicação flui entre clusters:
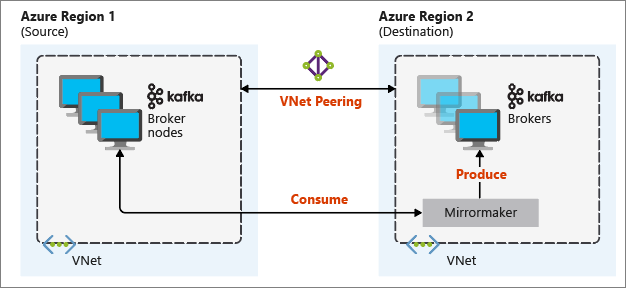
Os clusters primários e secundários podem ser diferentes no número de nós e partições, e os desvios dentro dos tópicos também são diferentes. O espelhamento mantém o valor de chave utilizado para a criação de partições, pelo que a ordem dos registos é preservada numa base por chave.
Espelhamento entre limites de rede
Se precisar de espelhar entre clusters do Kafka em redes diferentes, existem as seguintes considerações adicionais:
Gateways: as redes têm de conseguir comunicar ao nível do TCP/IP.
Endereçamento do servidor: pode optar por abordar os nós de cluster com os respetivos endereços IP ou nomes de domínio completamente qualificados.
Endereços IP: se configurar os clusters do Kafka para utilizar a publicidade de endereços IP, pode prosseguir com a configuração do espelhamento com os endereços IP dos nós do mediador e dos nós do ZooKeeper.
Nomes de domínio: se não configurar os clusters do Kafka para publicidade de endereços IP, os clusters têm de conseguir ligar-se uns aos outros através de nomes de domínio completamente qualificados (FQDNs). Isto requer um servidor de sistema de nomes de domínio (DNS) em cada rede configurada para reencaminhar pedidos para as outras redes. Quando estiver a criar uma rede virtual do Azure, em vez de utilizar o DNS automático fornecido com a rede, tem de especificar um servidor DNS personalizado e o endereço IP do servidor. Depois de criar a rede virtual, tem de criar uma máquina virtual do Azure que utilize esse endereço IP. Em seguida, instale e configure o software DNS no mesmo.
Importante
Crie e configure o servidor DNS personalizado antes de instalar o HDInsight na rede virtual. Não é necessária nenhuma configuração adicional para o HDInsight utilizar o servidor DNS configurado para a rede virtual.
Para obter mais informações sobre como ligar duas redes virtuais do Azure, veja Configurar uma ligação.
Arquitetura de espelhamento
Esta arquitetura inclui dois clusters em diferentes grupos de recursos e redes virtuais: um primário e um secundário.
Passos de criação
Criar dois novos grupos de recursos:
O grupo de recursos A localização kafka-primary-rg E.U.A. Central kafka-secondary-rg E.U.A. Centro-Norte Crie uma nova rede virtual kafka-primary-vnet no kafka-primary-rg. Deixe as predefinições.
Crie uma nova rede virtual kafka-secondary-vnet no kafka-secondary-rg, também com as predefinições.
Criar dois novos clusters do Kafka:
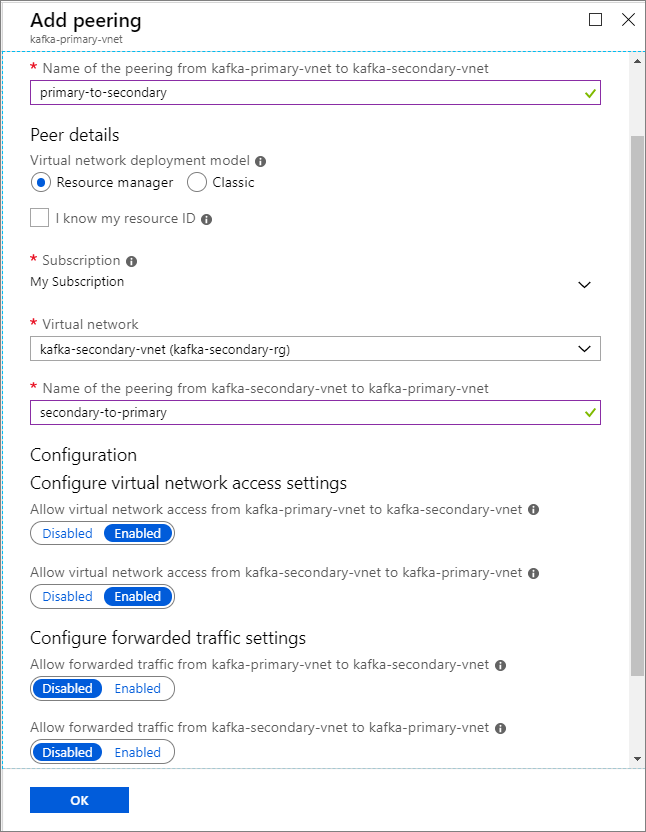
Nome do cluster Grupo de recursos Rede virtual Conta de armazenamento kafka-primary-cluster kafka-primary-rg kafka-primary-vnet kafkaprimarystorage kafka-secondary-cluster kafka-secondary-rg kafka-secondary-vnet kafkasecondarystorage Criar peerings de rede virtual. Este passo irá criar dois peerings: um de kafka-primary-vnet a kafka-secondary-vnet e outro de volta de kafka-secondary-vnet para kafka-primary-vnet.
Selecione a rede virtual kafka-primary-vnet .
Em Definições, selecione Peerings.
Selecione Adicionar.
No ecrã Adicionar peering , introduza os detalhes, conforme mostrado na seguinte captura de ecrã.
Configurar a publicidade IP
Configure a publicidade IP para permitir que um cliente se ligue através de endereços IP do mediador, em vez de nomes de domínio.
Aceda ao dashboard do Ambari para o cluster primário:
https://PRIMARYCLUSTERNAME.azurehdinsight.net.Selecione Serviços>Kafka. Selecione o separador Configurações .
Adicione as seguintes linhas de configuração à secção de modelo kafka-env inferior. Selecione Guardar.
# Configure Kafka to advertise IP addresses instead of FQDN IP_ADDRESS=$(hostname -i) echo advertised.listeners=$IP_ADDRESS sed -i.bak -e '/advertised/{/advertised@/!d;}' /usr/hdp/current/kafka-broker/conf/server.properties echo "advertised.listeners=PLAINTEXT://$IP_ADDRESS:9092" >> /usr/hdp/current/kafka-broker/conf/server.propertiesIntroduza uma nota no ecrã Guardar Configuração e selecione Guardar.
Se receber um aviso de configuração, selecione Continuar Mesmo Assim.
Em Guardar Alterações de Configuração, selecione OK.
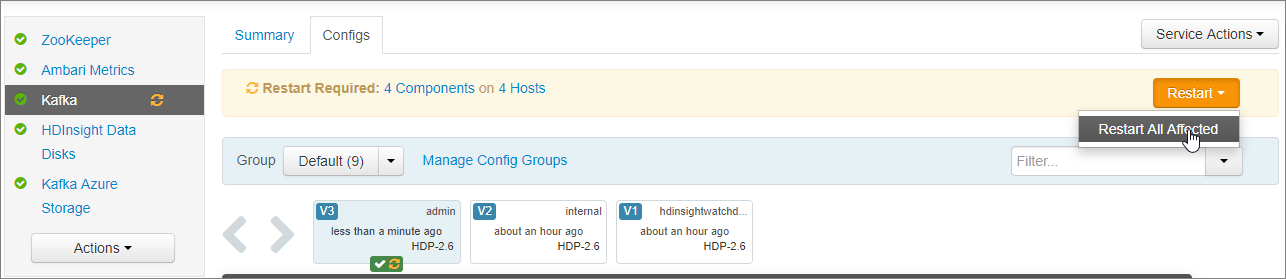
Na notificação Reiniciar Obrigatório , selecione Reiniciar Reiniciar>Tudo Afetado. Em seguida, selecione Confirmar Reiniciar Tudo.
Configurar o Kafka para escutar em todas as interfaces de rede
- Mantenha-se no separador Configurações em Serviços>Kafka. Na secção Mediador do Kafka , defina a propriedade de serviços de escuta como
PLAINTEXT://0.0.0.0:9092. - Selecione Guardar.
- Selecione Reiniciar>Confirmar Reiniciar Tudo.
Endereços IP do mediador de registos e endereços ZooKeeper para o cluster primário
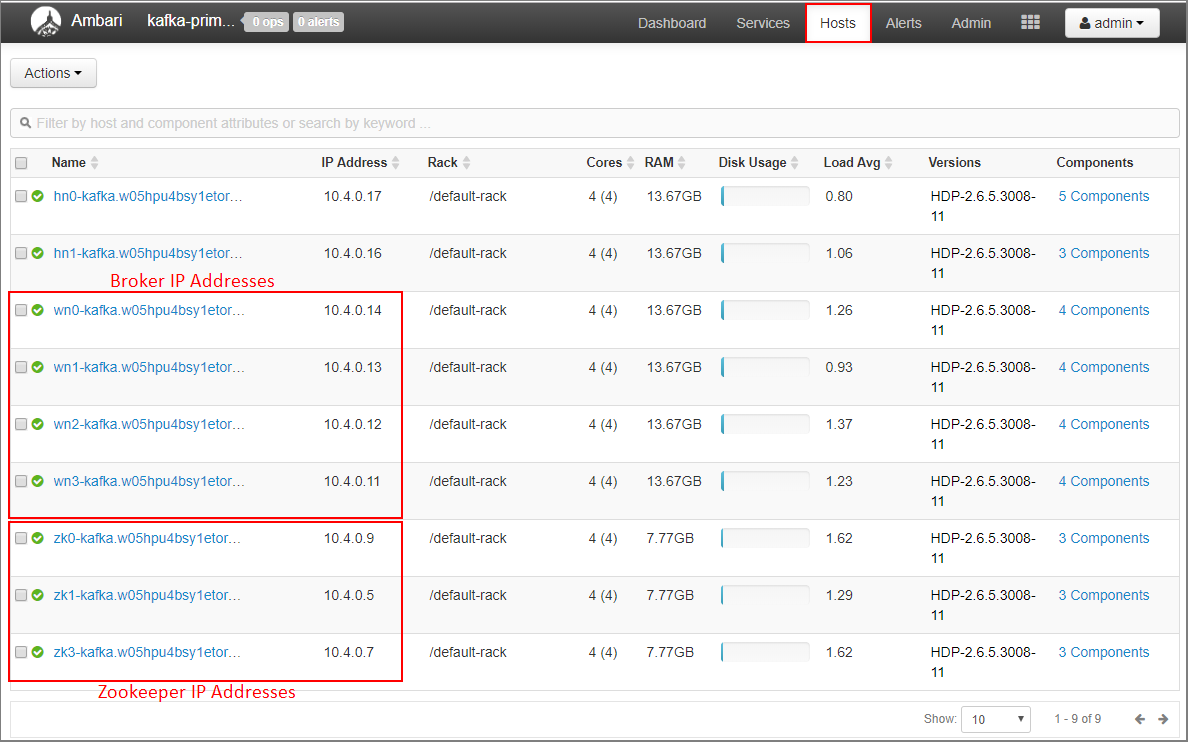
Selecione Anfitriões no dashboard do Ambari.
Tome nota dos endereços IP para os mediadores e ZooKeepers. Os nós do mediador foram apresentados como as duas primeiras letras do nome do anfitrião e os nós do ZooKeeper têm zk como as duas primeiras letras do nome do anfitrião.
Repita os três passos anteriores para o segundo cluster, kafka-secondary-cluster: configurar publicidade IP, definir serviços de escuta e tomar nota dos endereços IP do mediador e do ZooKeeper.
Criar tópicos
Ligue-se ao cluster primário através de SSH:
ssh sshuser@PRIMARYCLUSTER-ssh.azurehdinsight.netSubstitua
sshuserpelo nome de utilizador SSH que utilizou ao criar o cluster. SubstituaPRIMARYCLUSTERpelo nome base que utilizou ao criar o cluster.Para obter mais informações, veja Utilizar o SSH com o HDInsight.
Utilize o seguinte comando para criar duas variáveis de ambiente com os anfitriões do Apache ZooKeeper e anfitriões de mediador para o cluster primário. Substitua cadeias como
ZOOKEEPER_IP_ADDRESS1pelos endereços IP reais registados anteriormente, como10.23.0.11e10.23.0.7. O mesmo se aplica aBROKER_IP_ADDRESS1. Se estiver a utilizar a resolução FQDN com um servidor DNS personalizado, siga estes passos para obter nomes de mediador e ZooKeeper.# get the ZooKeeper hosts for the primary cluster export PRIMARY_ZKHOSTS='ZOOKEEPER_IP_ADDRESS1:2181, ZOOKEEPER_IP_ADDRESS2:2181, ZOOKEEPER_IP_ADDRESS3:2181' # get the broker hosts for the primary cluster export PRIMARY_BROKERHOSTS='BROKER_IP_ADDRESS1:9092,BROKER_IP_ADDRESS2:9092,BROKER_IP_ADDRESS2:9092'Para criar um tópico com o nome
testtopic, utilize o seguinte comando:/usr/hdp/current/kafka-broker/bin/kafka-topics.sh --create --replication-factor 2 --partitions 8 --topic testtopic --zookeeper $PRIMARY_ZKHOSTSUtilize o seguinte comando para verificar se o tópico foi criado:
/usr/hdp/current/kafka-broker/bin/kafka-topics.sh --list --zookeeper $PRIMARY_ZKHOSTSA resposta contém
testtopic.Utilize o seguinte para ver as informações do anfitrião do mediador para este cluster (o principal):
echo $PRIMARY_BROKERHOSTSEsta ação devolve informações semelhantes ao seguinte texto:
10.23.0.11:9092,10.23.0.7:9092,10.23.0.9:9092Guarde esta informação. É utilizado na secção seguinte.
Configurar espelhamento
Ligue-se ao cluster secundário com uma sessão SSH diferente:
ssh sshuser@SECONDARYCLUSTER-ssh.azurehdinsight.netSubstitua
sshuserpelo nome de utilizador SSH que utilizou ao criar o cluster. SubstituaSECONDARYCLUSTERpelo nome que utilizou ao criar o cluster.Para obter mais informações, veja Utilizar o SSH com o HDInsight.
Utilize um
consumer.propertiesficheiro para configurar a comunicação com o cluster primário. Para criar o ficheiro, utilize o seguinte comando:nano consumer.propertiesUtilize o seguinte texto como o conteúdo do
consumer.propertiesficheiro:bootstrap.servers=PRIMARY_BROKERHOSTS group.id=mirrorgroupSubstitua pelos
PRIMARY_BROKERHOSTSendereços IP do anfitrião do mediador do cluster primário.Este ficheiro descreve as informações de consumidor a utilizar ao ler a partir do cluster primário do Kafka. Para obter mais informações, veja Configurações de Consumidor em
kafka.apache.org.Para guardar o ficheiro, prima Ctrl+X, prima Y e, em seguida, prima Enter.
Antes de configurar o produtor que comunica com o cluster secundário, configure uma variável para os endereços IP do mediador do cluster secundário. Utilize os seguintes comandos para criar esta variável:
export SECONDARY_BROKERHOSTS='BROKER_IP_ADDRESS1:9092,BROKER_IP_ADDRESS2:9092,BROKER_IP_ADDRESS2:9092'O comando
echo $SECONDARY_BROKERHOSTSdeve devolver informações semelhantes ao seguinte texto:10.23.0.14:9092,10.23.0.4:9092,10.23.0.12:9092Utilize um
producer.propertiesficheiro para comunicar o cluster secundário. Para criar o ficheiro, utilize o seguinte comando:nano producer.propertiesUtilize o seguinte texto como o conteúdo do
producer.propertiesficheiro:bootstrap.servers=SECONDARY_BROKERHOSTS compression.type=noneSubstitua pelos
SECONDARY_BROKERHOSTSendereços IP do mediador utilizados no passo anterior.Para obter mais informações, veja Producer Configs (Configurações de Produtor) em
kafka.apache.org.Utilize os seguintes comandos para criar uma variável de ambiente com os endereços IP dos anfitriões ZooKeeper para o cluster secundário:
# get the ZooKeeper hosts for the secondary cluster export SECONDARY_ZKHOSTS='ZOOKEEPER_IP_ADDRESS1:2181,ZOOKEEPER_IP_ADDRESS2:2181,ZOOKEEPER_IP_ADDRESS3:2181'A configuração predefinida do Kafka no HDInsight não permite a criação automática de tópicos. Tem de utilizar uma das seguintes opções antes de iniciar o processo de espelhamento:
Criar os tópicos no cluster secundário: esta opção também lhe permite definir o número de partições e o fator de replicação.
Pode criar tópicos antecipadamente com o seguinte comando:
/usr/hdp/current/kafka-broker/bin/kafka-topics.sh --create --replication-factor 2 --partitions 8 --topic testtopic --zookeeper $SECONDARY_ZKHOSTSSubstitua
testtopicpelo nome do tópico a criar.Configurar o cluster para a criação automática de tópicos: esta opção permite que o MirrorMaker crie tópicos automaticamente. Tenha em atenção que pode criá-las com um número diferente de partições ou um fator de replicação diferente do tópico primário.
Para configurar o cluster secundário para criar tópicos automaticamente, execute estes passos:
- Aceda ao dashboard do Ambari para o cluster secundário:
https://SECONDARYCLUSTERNAME.azurehdinsight.net. - Selecione Serviços>Kafka. Em seguida, selecione o separador Configurações .
- No campo Filtro , introduza um valor de
auto.create. Esta ação filtra a lista de propriedades e apresenta aauto.create.topics.enabledefinição. - Altere o valor de
auto.create.topics.enableparatruee, em seguida, selecione Guardar. Adicione uma nota e, em seguida, selecione Guardar novamente. - Selecione o serviço Kafka , selecione Reiniciar e, em seguida, selecione Reiniciar todos os afetados. Quando lhe for pedido, selecione Confirmar reiniciar tudo.
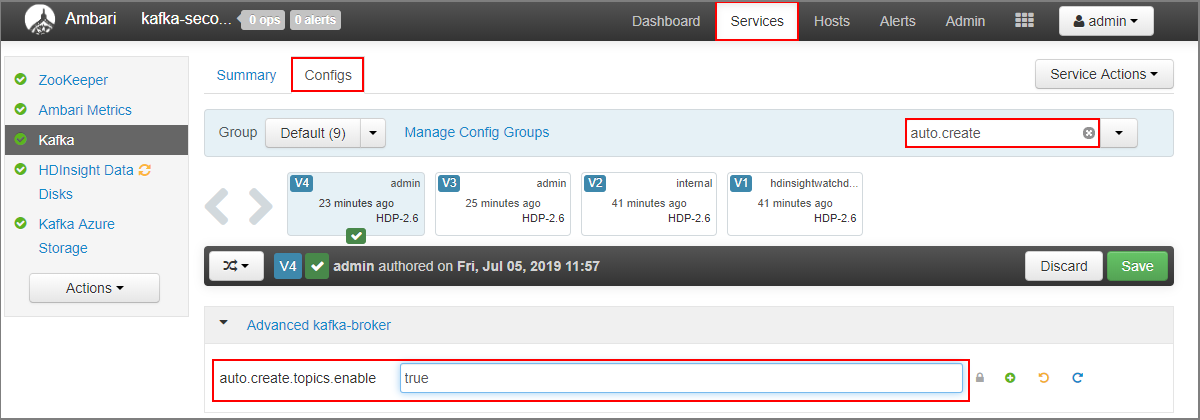
- Aceda ao dashboard do Ambari para o cluster secundário:
Iniciar o MirrorMaker
Nota
Este artigo contém referências a um termo que a Microsoft já não utiliza. Quando o termo for removido do software, iremos removê-lo deste artigo.
A partir da ligação SSH ao cluster secundário, utilize o seguinte comando para iniciar o processo MirrorMaker:
/usr/hdp/current/kafka-broker/bin/kafka-run-class.sh kafka.tools.MirrorMaker --consumer.config consumer.properties --producer.config producer.properties --whitelist testtopic --num.streams 4Os parâmetros utilizados neste exemplo são:
Parâmetro Description --consumer.configEspecifica o ficheiro que contém as propriedades do consumidor. Utilize estas propriedades para criar um consumidor que lê a partir do cluster primário do Kafka. --producer.configEspecifica o ficheiro que contém as propriedades do produtor. Utilize estas propriedades para criar um produtor que escreve no cluster secundário do Kafka. --whitelistUma lista de tópicos que o MirrorMaker replica do cluster primário para o secundário. --num.streamsO número de threads de consumidor a criar. O consumidor no nó secundário está agora à espera de receber mensagens.
A partir da ligação SSH ao cluster primário, utilize o seguinte comando para iniciar um produtor e enviar mensagens para o tópico:
/usr/hdp/current/kafka-broker/bin/kafka-console-producer.sh --broker-list $PRIMARY_BROKERHOSTS --topic testtopicQuando chegar a uma linha em branco com um cursor, escreva algumas mensagens SMS. As mensagens são enviadas para o tópico no cluster primário. Quando terminar, prima Ctrl+C para terminar o processo de produtor.
A partir da ligação SSH ao cluster secundário, prima Ctrl+C para terminar o processo do MirrorMaker. Pode demorar vários segundos a terminar o processo. Para verificar se as mensagens foram replicadas para a secundária, utilize o seguinte comando:
/usr/hdp/current/kafka-broker/bin/kafka-console-consumer.sh --bootstrap-server $SECONDARY_BROKERHOSTS --topic testtopic --from-beginningA lista de tópicos inclui
testtopicagora , que é criada quando o MirrorMaster espelha o tópico do cluster primário para o secundário. As mensagens obtidas do tópico são as mesmas que introduziu no cluster primário.
Eliminar o cluster
Aviso
A faturação dos clusters do HDInsight é proporcional por minuto, quer os utilize ou não. Certifique-se de que elimina o cluster depois de o utilizar. Veja como eliminar um cluster do HDInsight.
Os passos neste artigo criaram clusters em diferentes grupos de recursos do Azure. Para eliminar todos os recursos criados, pode eliminar os dois grupos de recursos criados: kafka-primary-rg e kafka-secondary-rg. Eliminar os grupos de recursos remove todos os recursos criados ao seguir este artigo, incluindo clusters, redes virtuais e contas de armazenamento.
Passos seguintes
Neste artigo, aprendeu a utilizar o MirrorMaker para criar uma réplica de um cluster do Apache Kafka . Utilize as seguintes ligações para descobrir outras formas de trabalhar com o Kafka: