Exemplo de streaming do Apache Spark (DStream) com Apache Kafka no HDInsight
Saiba como usar o Apache Spark para transmitir dados para dentro ou para fora do Apache Kafka no HDInsight usando o DStreams. Este exemplo usa um Jupyter Notebook que é executado no cluster Spark.
Nota
Os passos neste documento criam um grupo de recursos do Azure que contém um cluster do Spark no HDInsight e um cluster do Kafka no HDInsight. Estes dois clusters estão localizados numa Rede Virtual do Azure, o que permite que o cluster do Spark comunique diretamente com o cluster do Kafka.
Quando tiver concluído os passos neste documento, elimine os clusters para evitar encargos em excesso.
Importante
Este exemplo usa DStreams, que é uma tecnologia de streaming Spark mais antiga. Para obter um exemplo que usa recursos de streaming do Spark mais recentes, consulte o documento Spark Structured Streaming with Apache Kafka .
Criar os clusters
O Apache Kafka no HDInsight não fornece acesso aos corretores Kafka pela internet pública. Qualquer coisa que fale com Kafka deve estar na mesma rede virtual do Azure que os nós no cluster Kafka. Neste exemplo, os clusters Kafka e Spark estão localizados em uma rede virtual do Azure. O diagrama a seguir mostra como a comunicação flui entre os clusters:
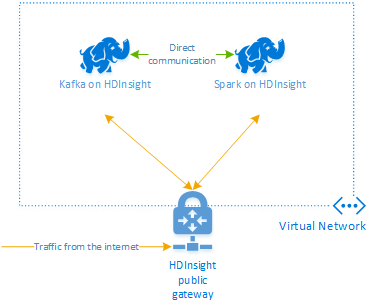
Nota
Embora Kafka em si seja limitado à comunicação dentro da rede virtual, outros serviços no cluster, como SSH e Ambari podem ser acessados pela internet. Para obter mais informações sobre as portas públicas disponíveis com o HDInsight, veja Portas e URIs utilizados pelo HDInsight.
Embora você possa criar uma rede virtual do Azure, Kafka e clusters Spark manualmente, é mais fácil usar um modelo do Azure Resource Manager. Use as etapas a seguir para implantar uma rede virtual do Azure, Kafka e clusters do Spark em sua assinatura do Azure.
Utilize o botão seguinte para iniciar sessão no Azure e abrir o modelo no Portal do Azure.

Aviso
Para garantir a disponibilidade do Kafka no HDInsight, o cluster deve conter pelo menos quatro nós de trabalho. Este modelo cria um cluster Kafka que contém quatro nós de trabalho.
Este modelo cria um cluster HDInsight 4.0 para Kafka e Spark.
Use as seguintes informações para preencher as entradas na seção Implantação personalizada:
Property valor Grupo de recursos Crie um grupo ou selecione um existente. Localização Selecione um local geograficamente próximo de si. Nome do cluster de base Esse valor é usado como o nome base para os clusters Spark e Kafka. Por exemplo, inserir hdistreaming cria um cluster Spark chamado spark-hdistreaming e um cluster Kafka chamado kafka-hdistreaming. Nome de Utilizador de Início de Sessão do Cluster O nome de usuário admin para os clusters Spark e Kafka. Palavra-passe de Início de Sessão do Cluster A senha de usuário administrador para os clusters Spark e Kafka. Nome de Utilizador SSH O usuário SSH para criar para os clusters Spark e Kafka. Palavra-passe do SSH A senha para o usuário SSH para os clusters Spark e Kafka. 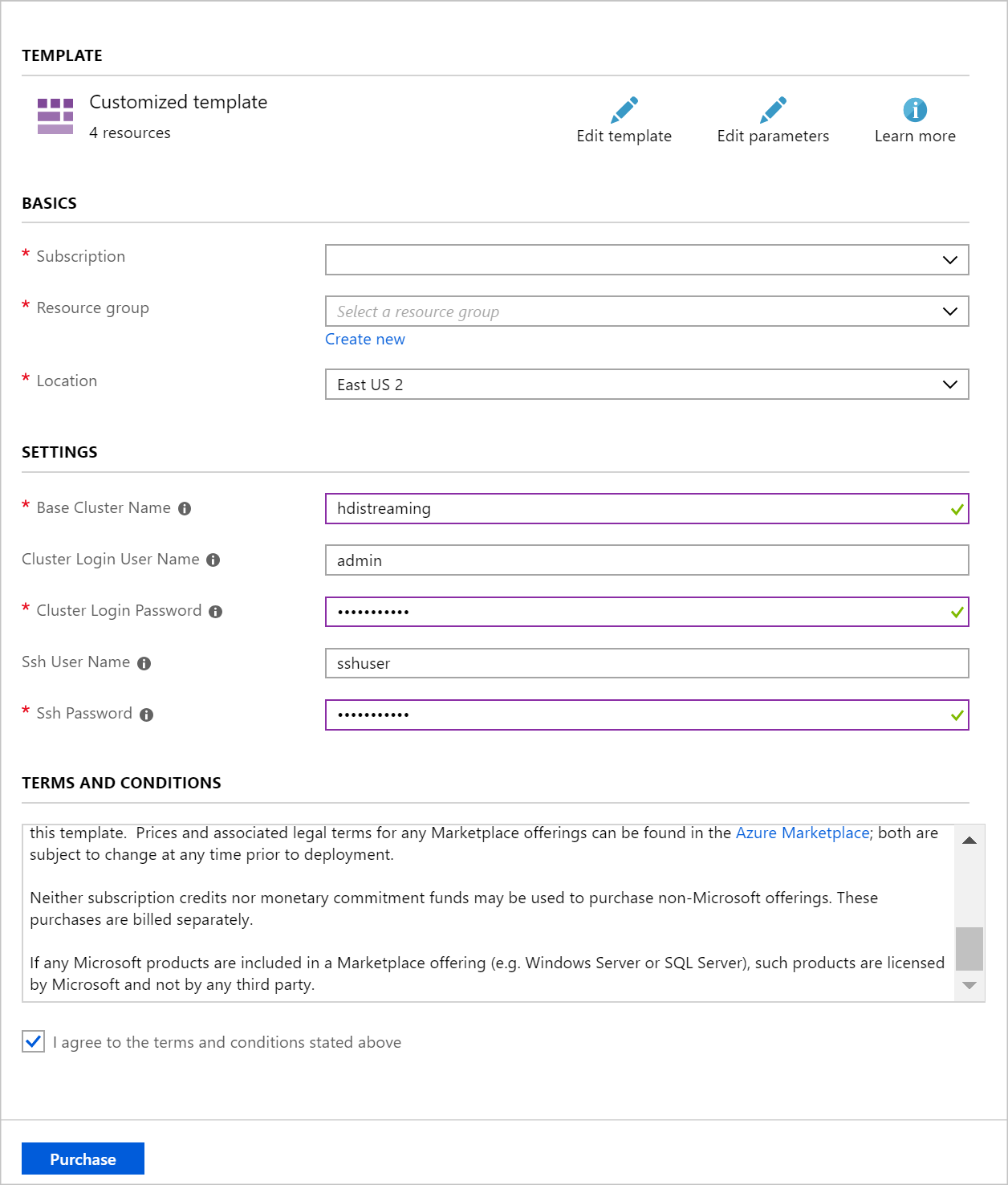
Leia os Termos e Condições e selecione Aceito os temos e as condições apresentados acima.
Por fim, selecione Comprar. Leva cerca de 20 minutos para criar os clusters.
Depois que os recursos forem criados, uma página de resumo será exibida.
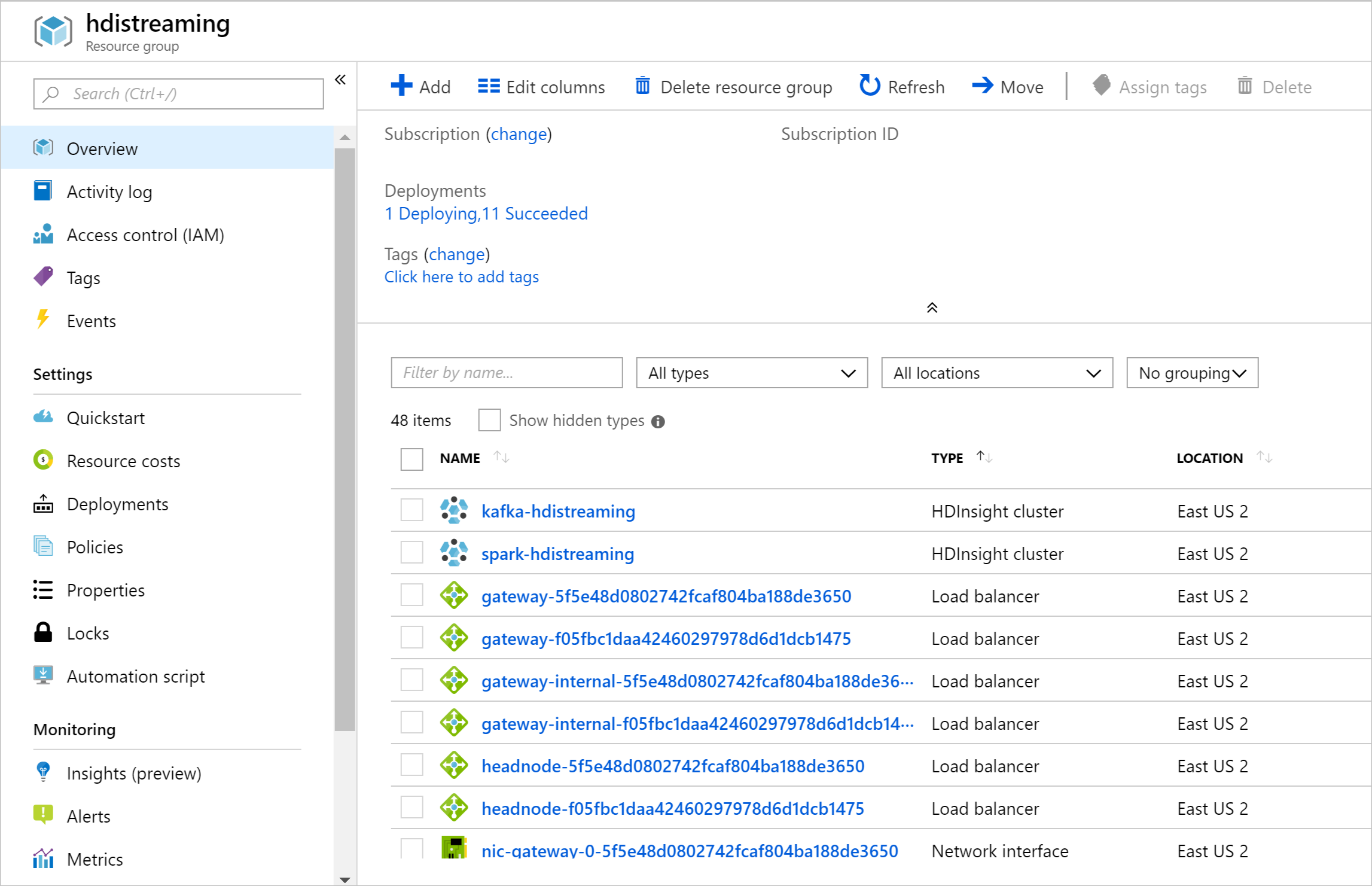
Importante
Observe que os nomes dos clusters HDInsight são spark-BASENAME e kafka-BASENAME, onde BASENAME é o nome fornecido ao modelo. Você usa esses nomes em etapas posteriores ao se conectar aos clusters.
Utilizar os blocos de notas
O código de exemplo descrito neste documento está disponível em https://github.com/Azure-Samples/hdinsight-spark-scala-kafka.
Eliminar o cluster
Aviso
A cobrança de clusters HDInsight é rateada por minuto, quer você os use ou não. Certifique-se de excluir o cluster depois de terminar de usá-lo. Veja como excluir um cluster HDInsight.
Como as etapas neste documento criam ambos os clusters no mesmo grupo de recursos do Azure, você pode excluir o grupo de recursos no portal do Azure. A exclusão do grupo remove todos os recursos criados seguindo este documento, a Rede Virtual do Azure e a conta de armazenamento usada pelos clusters.
Próximos passos
Neste exemplo, você aprendeu a usar o Spark para ler e gravar em Kafka. Use os links a seguir para descobrir outras maneiras de trabalhar com Kafka: