Copiar dados do PostgreSQL V1 usando o Azure Data Factory ou o Synapse Analytics
APLICA-SE A: Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Gorjeta
Experimente o Data Factory no Microsoft Fabric, uma solução de análise tudo-em-um para empresas. O Microsoft Fabric abrange tudo, desde a movimentação de dados até ciência de dados, análises em tempo real, business intelligence e relatórios. Saiba como iniciar uma nova avaliação gratuitamente!
Este artigo descreve como usar a Atividade de Cópia no Azure Data Factory e os pipelines do Synapse Analytics para copiar dados de um banco de dados PostgreSQL. Ele se baseia no artigo de visão geral da atividade de cópia que apresenta uma visão geral da atividade de cópia.
Importante
O conector PostgreSQL V2 fornece suporte nativo aprimorado ao PostgreSQL. Se você estiver usando o conector PostgreSQL V1 em sua solução, atualize seu conector PostgreSQL, pois V1 está no estágio de Fim de Suporte. Consulte esta seção para obter detalhes sobre a diferença entre V2 e V1.
Capacidades suportadas
Este conector PostgreSQL é suportado para os seguintes recursos:
| Capacidades suportadas | IR |
|---|---|
| Atividade de cópia (fonte/-) | (1) (2) |
| Atividade de Pesquisa | (1) (2) |
(1) Tempo de execução de integração do Azure (2) Tempo de execução de integração auto-hospedado
Para obter uma lista de armazenamentos de dados suportados como fontes/coletores pela atividade de cópia, consulte a tabela Armazenamentos de dados suportados.
Especificamente, este conector PostgreSQL suporta PostgreSQL versão 7.4 e superior.
Pré-requisitos
Se seu armazenamento de dados estiver localizado dentro de uma rede local, uma rede virtual do Azure ou a Amazon Virtual Private Cloud, você precisará configurar um tempo de execução de integração auto-hospedado para se conectar a ele.
Se o seu armazenamento de dados for um serviço de dados de nuvem gerenciado, você poderá usar o Tempo de Execução de Integração do Azure. Se o acesso for restrito a IPs aprovados nas regras de firewall, você poderá adicionar IPs do Azure Integration Runtime à lista de permissões.
Você também pode usar o recurso de tempo de execução de integração de rede virtual gerenciada no Azure Data Factory para acessar a rede local sem instalar e configurar um tempo de execução de integração auto-hospedado.
Para obter mais informações sobre os mecanismos de segurança de rede e as opções suportadas pelo Data Factory, consulte Estratégias de acesso a dados.
O Integration Runtime fornece um driver PostgreSQL integrado a partir da versão 3.7, portanto, você não precisa instalar manualmente nenhum driver.
Introdução
Para executar a atividade Copiar com um pipeline, você pode usar uma das seguintes ferramentas ou SDKs:
- A ferramenta Copiar dados
- O portal do Azure
- O SDK do .NET
- O SDK do Python
- Azure PowerShell
- A API REST
- O modelo do Azure Resource Manager
Criar um serviço vinculado ao PostgreSQL usando a interface do usuário
Use as etapas a seguir para criar um serviço vinculado ao PostgreSQL na interface do usuário do portal do Azure.
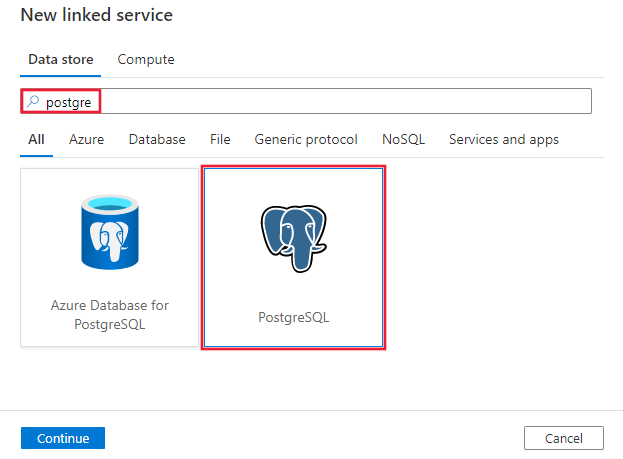
Navegue até a guia Gerenciar em seu espaço de trabalho do Azure Data Factory ou Synapse e selecione Serviços Vinculados e clique em Novo:
Procure Postgre e selecione o conector PostgreSQL.
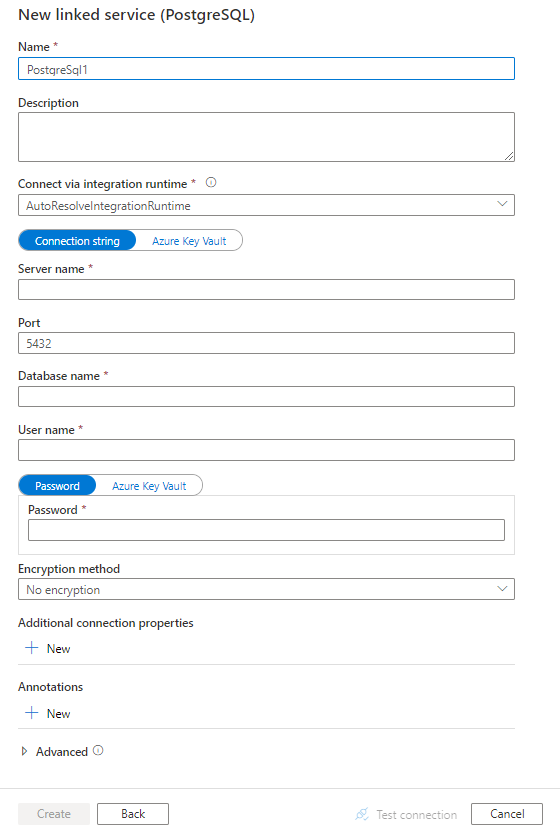
Configure os detalhes do serviço, teste a conexão e crie o novo serviço vinculado.
Detalhes de configuração do conector
As seções a seguir fornecem detalhes sobre as propriedades usadas para definir entidades do Data Factory específicas para o conector PostgreSQL.
Propriedades do serviço vinculado
As seguintes propriedades são suportadas para o serviço vinculado PostgreSQL:
| Property | Descrição | Obrigatório |
|---|---|---|
| tipo | A propriedade type deve ser definida como: PostgreSql | Sim |
| connectionString | Uma cadeia de conexão ODBC para se conectar ao Banco de Dados do Azure para PostgreSQL. Você também pode colocar a senha no Cofre de Chaves do Azure e extrair a password configuração da cadeia de conexão. Consulte os seguintes exemplos e o artigo Armazenar credenciais no Cofre de Chaves do Azure com mais detalhes. |
Sim |
| ConecteVia | O tempo de execução de integração a ser usado para se conectar ao armazenamento de dados. Saiba mais na seção Pré-requisitos . Se não for especificado, ele usará o Tempo de Execução de Integração do Azure padrão. | Não |
Uma cadeia de conexão típica é Server=<server>;Database=<database>;Port=<port>;UID=<username>;Password=<Password>. Mais propriedades que pode definir de acordo com o seu caso:
| Property | Description | Opções | Necessário |
|---|---|---|---|
| Método de criptografia (EM) | O método que o driver usa para criptografar dados enviados entre o driver e o servidor de banco de dados. Por exemplo, EncryptionMethod=<0/1/6>; |
0 (Sem criptografia) (padrão) / 1 (SSL) / 6 (RequestSSL) | Não |
| ValidateServerCertificate (VSC) | Determina se o driver valida o certificado enviado pelo servidor de banco de dados quando a criptografia SSL está habilitada (Método de Criptografia=1). Por exemplo, ValidateServerCertificate=<0/1>; |
0 (Desativado) (Padrão) / 1 (Habilitado) | Não |
Nota
Para ter uma verificação SSL completa por meio da conexão ODBC ao usar o Self Hosted Integration Runtime, você deve usar uma conexão do tipo ODBC em vez do conector PostgreSQL explicitamente e concluir a seguinte configuração:
- Configure o DSN em qualquer servidor SHIR.
- Coloque o certificado adequado para PostgreSQL em C:\Windows\ServiceProfiles\DIAHostService\AppData\Roaming\postgresql\root.crt nos servidores SHI. É aqui que o driver ODBC procura > o certificado SSL para verificar quando ele se conecta ao banco de dados.
- Na conexão de fábrica de dados, use uma conexão do tipo ODBC, com a cadeia de conexão apontando para o DSN criado nos servidores SHIRE.
Exemplo:
{
"name": "PostgreSqlLinkedService",
"properties": {
"type": "PostgreSql",
"typeProperties": {
"connectionString": "Server=<server>;Database=<database>;Port=<port>;UID=<username>;Password=<Password>"
},
"connectVia": {
"referenceName": "<name of Integration Runtime>",
"type": "IntegrationRuntimeReference"
}
}
}
Exemplo: armazenar senha no Cofre da Chave do Azure
{
"name": "PostgreSqlLinkedService",
"properties": {
"type": "PostgreSql",
"typeProperties": {
"connectionString": "Server=<server>;Database=<database>;Port=<port>;UID=<username>;",
"password": {
"type": "AzureKeyVaultSecret",
"store": {
"referenceName": "<Azure Key Vault linked service name>",
"type": "LinkedServiceReference"
},
"secretName": "<secretName>"
}
},
"connectVia": {
"referenceName": "<name of Integration Runtime>",
"type": "IntegrationRuntimeReference"
}
}
}
Se você estava usando o serviço vinculado PostgreSQL com a seguinte carga útil, ele ainda é suportado como está, enquanto você é sugerido para usar o novo no futuro.
Carga útil anterior:
{
"name": "PostgreSqlLinkedService",
"properties": {
"type": "PostgreSql",
"typeProperties": {
"server": "<server>",
"database": "<database>",
"username": "<username>",
"password": {
"type": "SecureString",
"value": "<password>"
}
},
"connectVia": {
"referenceName": "<name of Integration Runtime>",
"type": "IntegrationRuntimeReference"
}
}
}
Propriedades do conjunto de dados
Para obter uma lista completa de seções e propriedades disponíveis para definir conjuntos de dados, consulte o artigo sobre conjuntos de dados. Esta seção fornece uma lista de propriedades suportadas pelo conjunto de dados PostgreSQL.
Para copiar dados do PostgreSQL, as seguintes propriedades são suportadas:
| Property | Descrição | Obrigatório |
|---|---|---|
| tipo | A propriedade type do conjunto de dados deve ser definida como: PostgreSqlTable | Sim |
| esquema | Nome do esquema. | Não (se "consulta" na fonte da atividade for especificado) |
| tabela | Nome da tabela. | Não (se "consulta" na fonte da atividade for especificado) |
| tableName | Nome da tabela com esquema. Esta propriedade é suportada para compatibilidade com versões anteriores. Use schema e table para nova carga de trabalho. |
Não (se "consulta" na fonte da atividade for especificado) |
Exemplo
{
"name": "PostgreSQLDataset",
"properties":
{
"type": "PostgreSqlTable",
"typeProperties": {},
"schema": [],
"linkedServiceName": {
"referenceName": "<PostgreSQL linked service name>",
"type": "LinkedServiceReference"
}
}
}
Se você estava usando RelationalTable o conjunto de dados digitado, ele ainda é suportado no estado em que se encontra, enquanto você é sugerido para usar o novo no futuro.
Propriedades da atividade Copy
Para obter uma lista completa de seções e propriedades disponíveis para definir atividades, consulte o artigo Pipelines . Esta seção fornece uma lista de propriedades suportadas pela fonte PostgreSQL.
PostgreSQL como fonte
Para copiar dados do PostgreSQL, as seguintes propriedades são suportadas na seção copiar fonte de atividade:
| Property | Descrição | Obrigatório |
|---|---|---|
| tipo | A propriedade type da fonte de atividade de cópia deve ser definida como: PostgreSqlSource | Sim |
| query | Use a consulta SQL personalizada para ler dados. Por exemplo: "query": "SELECT * FROM \"MySchema\".\"MyTable\"". |
Não (se "tableName" no conjunto de dados for especificado) |
Nota
Os nomes de esquema e tabela diferenciam maiúsculas de minúsculas. Coloque-os entre "" aspas (aspas duplas) na consulta.
Exemplo:
"activities":[
{
"name": "CopyFromPostgreSQL",
"type": "Copy",
"inputs": [
{
"referenceName": "<PostgreSQL input dataset name>",
"type": "DatasetReference"
}
],
"outputs": [
{
"referenceName": "<output dataset name>",
"type": "DatasetReference"
}
],
"typeProperties": {
"source": {
"type": "PostgreSqlSource",
"query": "SELECT * FROM \"MySchema\".\"MyTable\""
},
"sink": {
"type": "<sink type>"
}
}
}
]
Se você estava usando RelationalSource fonte digitada, ela ainda é suportada como está, enquanto você é sugerido para usar a nova no futuro.
Propriedades da atividade de pesquisa
Para saber detalhes sobre as propriedades, verifique Atividade de pesquisa.
Conteúdos relacionados
Para obter uma lista de armazenamentos de dados suportados como fontes e coletores pela atividade de cópia, consulte Armazenamentos de dados suportados.