Preparar-se para usar o Apache Spark
Apache Spark é uma estrutura de processamento de dados distribuída que habilita a análise de dados em grande escala coordenando o trabalho nos vários nós de processamento de um cluster, conhecido no Microsoft Fabric como Pool do Spark. Simplificando, o Spark usa uma abordagem de "dividir para conquistar" a fim de processar grandes volumes de dados rapidamente, distribuindo o trabalho entre diversos computadores. O processo de distribuição de tarefas e agrupamento de resultados é feito para você pelo Spark.
O Spark pode executar códigos escritos em uma ampla variedade de linguagens, como Java, Scala (uma linguagem de script baseada em Java), Spark R, Spark SQL e PySpark (uma variante do Python específica do Spark). Na prática, a maioria das cargas de trabalho de análise e engenharia de dados é executada usando uma combinação entre o PySpark e o Spark SQL.
Pools do Spark
Um Pool do Spark consiste em nós de computação que distribuem tarefas de processamento de dados. A arquitetura de modo geral é mostrada no diagrama a seguir.
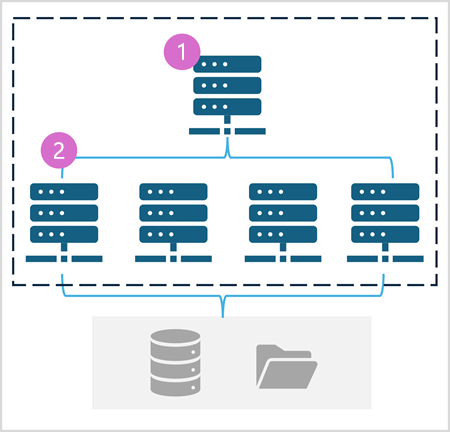
Conforme mostrado no diagrama, um Pool do Spark contém dois tipos de nós:
- Um nó principal em um Pool do Spark coordena os processos distribuídos por meio de um programa de driver.
- O pool inclui vários nós de trabalho nos quais os processos do executor executam as tarefas reais de processamento de dados.
O Pool do Spark usa essa arquitetura de computação distribuída para acessar e processar dados em um repositório de dados compatível — como um data lakehouse baseado no OneLake.
Pools do Spark no Microsoft Fabric
O Microsoft Fabric fornece um pool inicial em cada workspace, permitindo que os trabalhos do Spark sejam iniciados e executados rapidamente com um mínimo de instalação e configuração. Você pode configurar o pool inicial para otimizar os nós que contém de acordo com suas necessidades específicas de carga de trabalho ou restrições de custo.
Além disso, você pode criar Pools do Spark personalizados com configurações de nó específicas que dão suporte às suas necessidades específicas de processamento de dados.
Observação
A capacidade de personalizar as configurações do Pool do Spark pode ser desabilitada pelos administradores do Fabric no nível de Capacidade do Fabric. Para obter mais informações, confira Configurações de administração de capacidade para Engenharia de Dados e Ciência de Dados na documentação do Fabric.
Você pode gerenciar as configurações do pool inicial e criar novos Pools do Spark na seção Engenharia/Ciência de Dados das configurações do workspace.
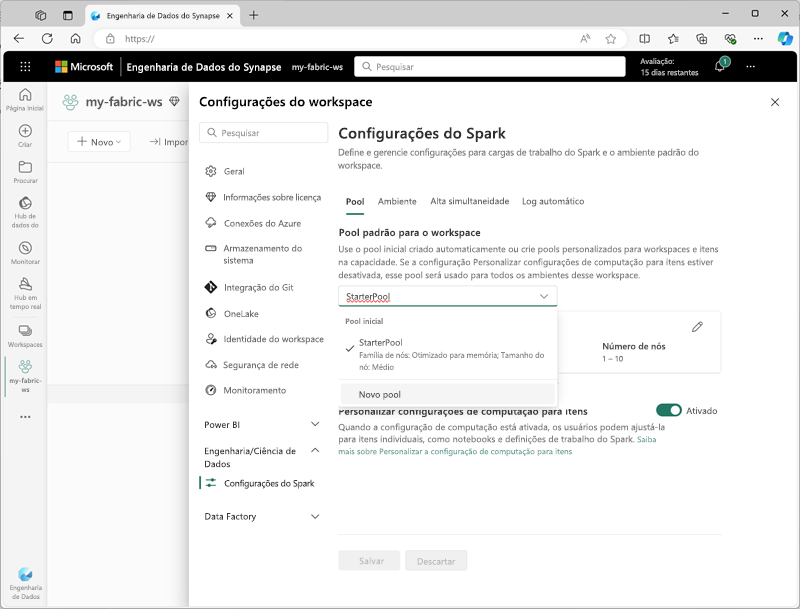
As definições de configurações específicas para Pools do Spark incluem:
- Família de nós: o tipo de máquinas virtuais usadas para os nós do cluster do Spark. Na maioria dos casos, os nós com otimização de memória fornecem desempenho ideal.
- Dimensionamento automático: Define se você quer ou não provisionar os nós automaticamente conforme necessário e, se for esse o caso, o número inicial e o número máximo de nós a serem alocados para o pool.
- Alocação dinâmica: Define se você quer ou não alocar dinamicamente os processos do executor nos nós de trabalho com base nos volumes de dados.
Se criar um ou mais Pools do Spark personalizados em um workspace, você poderá configurar um deles (ou o pool inicial) como o pool padrão a ser usado se um pool específico não for especificado para um determinado trabalho do Spark.
Dica
Para obter mais informações sobre como gerenciar Pools do Spark no Microsoft Fabric, confira Como configurar pools iniciais no Microsoft Fabric e Como criar Pools do Spark personalizados no Microsoft Fabric na documentação do Microsoft Fabric.
Runtimes e ambientes
O ecossistema de código aberto do Spark inclui várias versões do runtime do Spark, o que determina a versão do Apache Spark, do Delta Lake, do Python e de outros componentes básicos de software que são instalados. Além disso, dentro de um runtime, você pode instalar e usar uma ampla seleção de bibliotecas de código para tarefas comuns (e às vezes muito especializadas). Como uma grande parte do processamento do Spark é realizada usando o PySpark, a grande variedade de bibliotecas Python disponíveis garante que, independentemente da tarefa que você precisa executar, provavelmente haverá uma biblioteca para ajudar.
Em alguns casos, as organizações podem precisar configurar vários ambientes para dar suporte a uma diversificada variedade de tarefas de processamento de dados. Cada ambiente define uma versão de runtime específica, assim como as bibliotecas que precisam ser instaladas para executar operações específicas. Os engenheiros e cientistas de dados podem selecionar qual ambiente querem usar com um Pool do Spark para uma tarefa específica.
Runtimes do Spark no Microsoft Fabric
O Microsoft Fabric dá suporte a vários runtimes do Spark e continuará a adicionar o suporte a novos runtimes à medida que forem lançados. Você pode usar a interface de configurações do workspace para especificar o runtime do Spark a ser usado pelo ambiente padrão quando um Pool do Spark é iniciado.
Dica
Para obter mais informações sobre os runtimes do Spark no Microsoft Fabric, confira Runtimes do Apache Spark no Fabric na documentação do Microsoft Fabric.
Ambientes no Microsoft Fabric
Você pode criar ambientes personalizados em um workspace do Fabric, permitindo o uso de bibliotecas, definições de configurações e runtimes específicos do Spark para diferentes operações de processamento de dados.
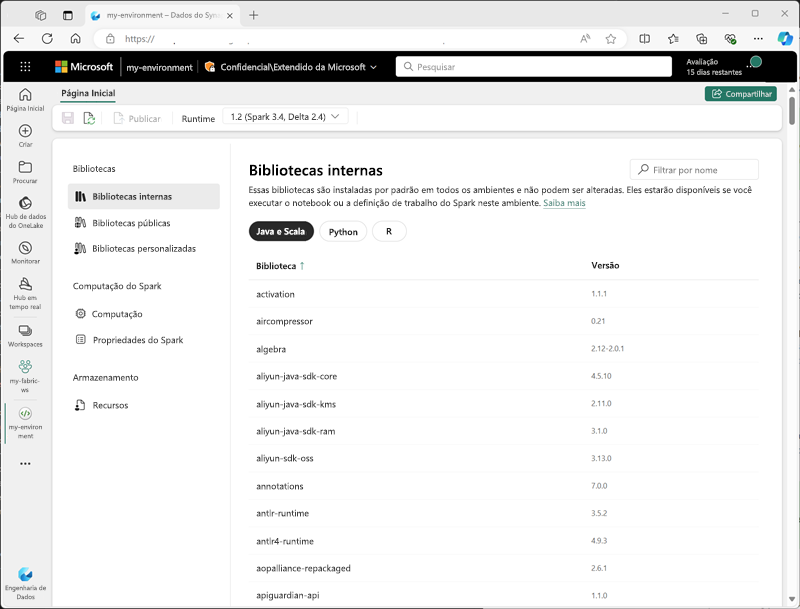
Ao criar um ambiente, você pode:
- Especificar o runtime do Spark que deve ser usado.
- Ver as bibliotecas integradas que estão instaladas em cada ambiente.
- Instalar bibliotecas públicas específicas do Índice de Pacotes do Python (PyPI).
- Instalar bibliotecas personalizadas carregando um arquivo de pacote.
- Especificar o Pool do Spark que o ambiente deve usar.
- Especificar as propriedades de configuração do Spark para substituir o comportamento padrão.
- Carregar arquivos de recurso que precisam estar disponíveis no ambiente.
Apos ter criado pelo menos um ambiente personalizado, você poderá especificá-lo como o ambiente padrão nas configurações do workspace.
Dica
Para obter mais informações sobre como usar ambientes personalizados no Microsoft Fabric, confira Criar, configurar e utilizar um ambiente no Microsoft Fabric na documentação do Microsoft Fabric.
Opções adicionais de configuração do Spark
Gerenciar os ambientes e Pools do Spark são as principais maneiras pelas quais você pode gerenciar o processamento do Spark em um workspace do Fabric. No entanto, existem algumas opções adicionais que você pode usar para fazer mais otimizações.
Mecanismo de execução nativo
O mecanismo de execução nativo no Microsoft Fabric é um mecanismo de processamento vetorizado que executa operações do Spark diretamente na infraestrutura do Lakehouse. O uso do mecanismo de execução nativa pode aprimorar o desempenho das consultas de forma significativa quando você estiver trabalhando com grandes conjuntos de dados nos formatos de arquivo Parquet ou Delta.
Para usar o mecanismo de execução nativo, você pode habilitá-lo no nível do ambiente ou dentro de um notebook individual. Para habilitar o mecanismo de execução nativo no nível do ambiente, defina as seguintes propriedades do Spark na configuração do ambiente:
- spark.native.enabled: true
- spark.shuffle.manager: org.apache.spark.shuffle.sort.ColumnarShuffleManager
Para habilitar o mecanismo de execução nativo para um script ou notebook específicos, você pode definir essas propriedades de configuração no início do seu código, como se segue:
%%configure
{
"conf": {
"spark.native.enabled": "true",
"spark.shuffle.manager": "org.apache.spark.shuffle.sort.ColumnarShuffleManager"
}
}
Dica
Para obter mais informações sobre o mecanismo de execução nativo, confira Mecanismo de execução nativo do Spark no Fabric na documentação do Microsoft Fabric.
Modo de alta simultaneidade
Quando você executa o código do Spark no Microsoft Fabric, uma sessão do Spark é iniciada. Você pode otimizar a eficiência do uso de recursos do Spark usando o modo de alta simultaneidade para compartilhar sessões do Spark entre vários usuários ou processos simultâneos. Quando o modo de alta simultaneidade está habilitado para Notebooks, vários usuários podem executar código em notebooks que usam a mesma sessão do Spark e, ao mesmo tempo, garantir o isolamento do código para evitar que as variáveis em um notebook sejam afetadas pelo código de outro notebook. Você também pode habilitar o modo de alta simultaneidade para trabalhos do Spark, permitindo eficiências semelhantes para a execução simultânea de scripts do Spark não interativos.
Para habilitar o modo de alta simultaneidade, use a seção Engenharia/Ciência de Dados da interface de configurações do espaço de trabalho.
Dica
Para obter mais informações sobre o modo de alta simultaneidade, confira Modo de alta simultaneidade no Apache Spark para Fabric na documentação do Microsoft Fabric.
Registro em log automático do MLFlow
MLFlow é uma biblioteca de código aberto usada em cargas de trabalho de ciência de dados para gerenciar o treinamento de machine learning e a implantação de modelos. Uma funcionalidade essencial do MLFlow é a capacidade de registrar em log as operações de treinamento e gerenciamento de modelos. Por padrão, o Microsoft Fabric usa o MLFlow para registrar implicitamente em log as atividades de experimentação de machine learning sem requerer que o cientista de dados inclua um código explícito para fazê-lo. Você pode desabilitar essa funcionalidade nas configurações do workspace.
Administração do Spark para uma capacidade do Fabric
Os administradores podem gerenciar as configurações do Spark em um nível de capacidade do Fabric, o que lhes permite restringir e substituir as configurações do Spark nos workspaces dentro de uma organização.
Dica
Para obter mais informações sobre como gerenciar a configuração do Spark no nível de capacidade do Fabric, confira Configurar e gerenciar configurações de engenharia de dados e ciência de dados para capacidades do Fabric na documentação do Microsoft Fabric.