Como criar pools personalizados do Spark no Microsoft Fabric
Neste documento, explicamos como criar pools personalizados do Apache Spark no Microsoft Fabric para suas cargas de trabalho de análise. Os pools do Apache Spark permitem que os usuários criem ambientes de computação personalizados com base em seus requisitos específicos, garantindo o desempenho ideal e a utilização de recursos.
Especifique os nós mínimos e máximos para dimensionamento automático. Com base nesses valores, o sistema adquire e desativa dinamicamente os nós à medida que os requisitos de computação do trabalho mudam, o que resulta em um dimensionamento eficiente e em melhor desempenho. A alocação dinâmica de executores em pools do Spark também alivia a necessidade de configuração manual do executor. Em vez disso, o sistema ajusta o número de executores dependendo do volume de dados e das necessidades de computação no nível do trabalho. Esse processo permite que você se concentre em suas cargas de trabalho sem se preocupar com a otimização de desempenho e o gerenciamento de recursos.
Nota
Para criar um pool personalizado do Spark, você precisa de acesso de administrador ao workspace. O administrador da capacidade deve habilitar a opção Pools de workspace personalizados na seção Computação do Spark das Configurações de Capacidade Administração. Para saber mais, confira Configurações de computação do Spark para capacidades do Fabric.
Criar pools personalizados do Spark
Para criar ou gerenciar o pool do Spark associado ao seu workspace:
Vá para seu workspace e selecione Configurações do workspace.
Selecione a opção Engenharia de Dados/Ciência para expandir o menu e selecione configurações do Spark.
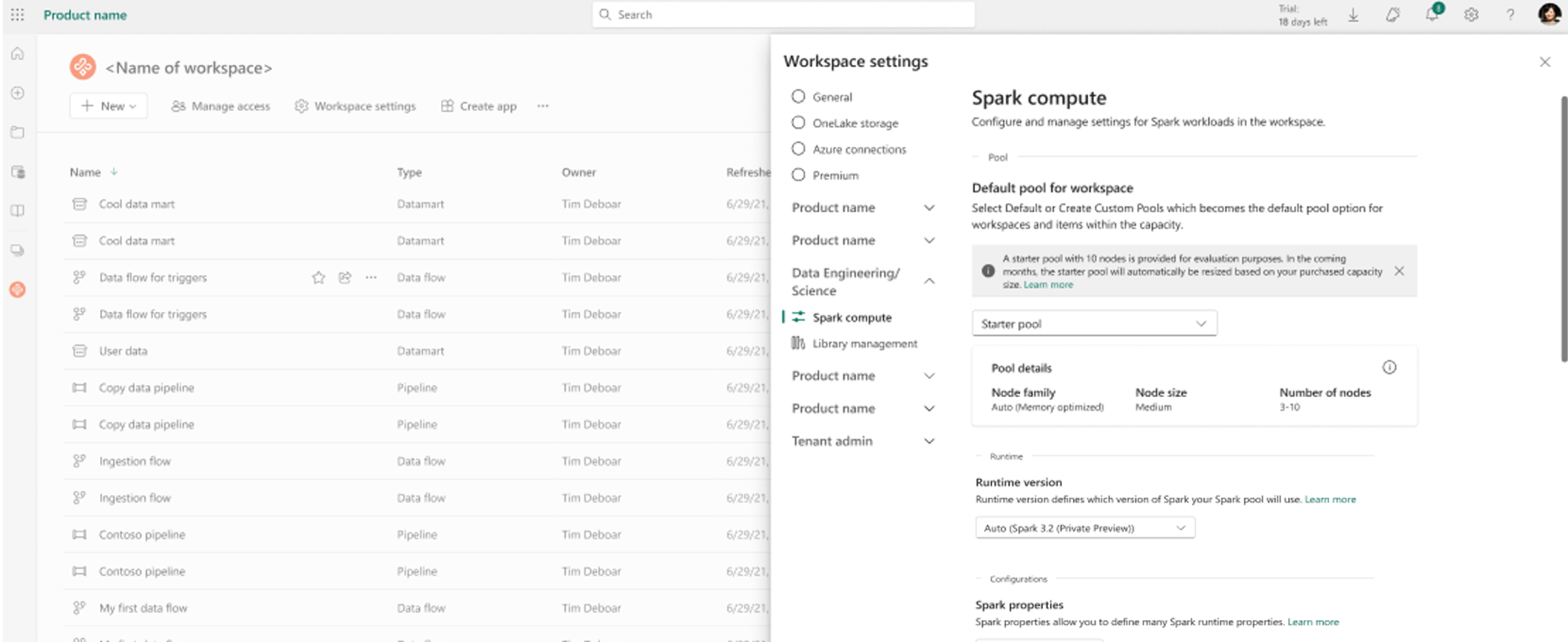
Selecione a opção Novo Pool. Na tela Criar Pool, nomeie o pool do Spark. Escolha também a Família do Nó e selecione um Tamanho do nó dos tamanhos disponíveis (Pequeno, Médio, Grande, Extra grande e Super extra grande), com base nos requisitos de computação para suas cargas de trabalho.
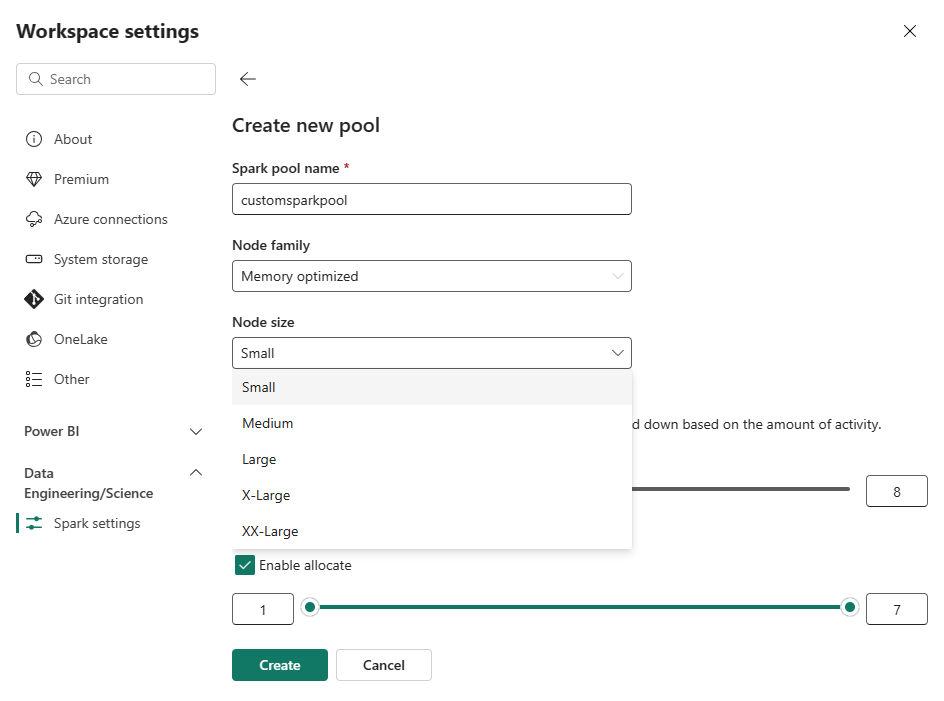
Você também pode definir a configuração mínima do nó para os pools personalizados como 1. Como o Fabric Spark fornece disponibilidade restaurável para clusters com um único nó, você não precisa se preocupar com falhas de tarefas, interrupção de sessão durante falhas ou pagar em excesso por computação para tarefas menores do Spark.
Você pode habilitar ou desabilitar o dimensionamento automático para seus pools personalizados do Spark. Quando o dimensionamento automático estiver habilitado, o pool adquirirá dinamicamente novos nós até o limite máximo de nós especificado pelo usuário, e os desativará após a execução do trabalho. Esse recurso garante um melhor desempenho ajustando os recursos com base nos requisitos de trabalho. Você tem permissão para dimensionar os nós, que se ajustam às unidades de capacidade adquiridas como parte do SKU de capacidade do Fabric.
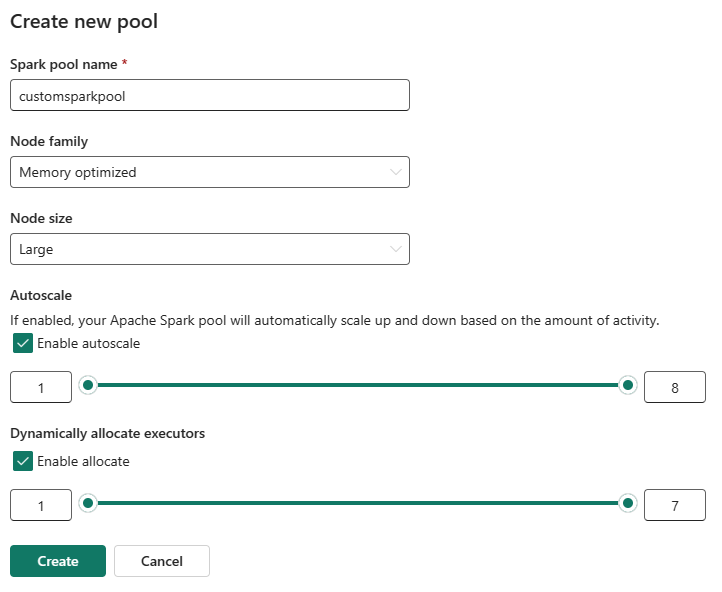
Você também pode optar por habilitar a alocação de executor dinâmico para o pool do Spark, que determina automaticamente o número ideal de executores dentro do limite máximo especificado pelo usuário. Esse recurso ajusta o número de executores com base no volume de dados, resultando em melhor desempenho e utilização de recursos.

Esses pools personalizados têm uma duração padrão de pausa automática de 2 minutos. Quando a duração da pausa automática for atingida, a sessão expirará e os clusters serão desalocados. Você é cobrado com base no número de nós e na duração para a qual os pools personalizados do Spark são usados.
Conteúdo relacionado
- Saiba mais na documentação pública do Apache Spark .
- Introdução às Configurações de administração de workspace do Spark no Microsoft Fabric.