Mecanismo de execução nativo para o Fabric Spark
O mecanismo de execução nativo é um aprimoramento inovador para execuções de trabalho do Apache Spark no Microsoft Fabric. Esse mecanismo vetorizado otimiza o desempenho e a eficiência de suas consultas do Spark, executando-as diretamente em sua infraestrutura de lakehouse. A integração perfeita do mecanismo significa que ele não requer modificações de código e evita o bloqueio do fornecedor. Ela oferece suporte a APIs do Apache Spark, é compatível com o Runtime 1.3 (Apache Spark 3.5) e funciona com os formatos Parquet e Delta. Independentemente da localização dos seus dados no OneLake, ou se você acessar os dados por meio de atalhos, o mecanismo de execução nativo maximiza a eficiência e o desempenho.
O mecanismo de execução nativo eleva significativamente o desempenho da consulta e, ao mesmo tempo, minimiza os custos operacionais. Ele oferece um notável aprimoramento de velocidade, alcançando um desempenho até quatro vezes mais rápido em comparação com o OSS (software de código aberto) tradicional Spark, conforme validado pelo benchmark TPC-DS de 1 TB. O mecanismo é hábil em gerenciar uma ampla gama de cenários de processamento de dados, que vão desde a ingestão de dados de rotina, trabalhos em lote e tarefas de ETL (extrair, transformar, carregar), até análises complexas de ciência de dados e consultas interativas responsivas. Os usuários se beneficiam de tempos de processamento acelerados, taxa de transferência aumentada e utilização otimizada de recursos.
O Native Execution Engine é baseado em dois componentes OSS principais: Velox, uma biblioteca de aceleração de banco de dados C++ introduzida pelo Meta, e Apache Gluten (incubação), uma camada intermediária responsável por descarregar a execução de mecanismos SQL baseados em JVM para mecanismos nativos introduzidos pela Intel.
Observação
O mecanismo de execução nativo está atualmente em visualização pública. Para obter mais informações, confira as limitações atuais. Incentivamos você a habilitar o mecanismo de execução nativo em suas cargas de trabalho sem custo adicional. Você se beneficiará de uma execução de trabalho mais rápida sem pagar mais; efetivamente, você pagará menos pelo mesmo trabalho.
Quando usar o mecanismo de execução nativo
O mecanismo de execução nativo oferece uma solução para executar consultas em conjuntos de dados de grande escala; ele otimiza o desempenho usando os recursos nativos das fontes de dados subjacentes e minimizando a sobrecarga normalmente associada à movimentação e serialização de dados em ambientes tradicionais do Spark. O mecanismo oferece suporte a vários operadores e tipos de dados, incluindo agregado de hash de rollup, BNLJ (Broadcast Nested Loop Unit) e formatos precisos de carimbo de data/hora. No entanto, para se beneficiar totalmente dos recursos do mecanismo, você deve considerar seus casos de uso ideais:
- O mecanismo é eficaz ao trabalhar com dados nos formatos Parquet e Delta, que pode ser processado de forma nativa e eficiente.
- As consultas que envolvem transformações e agregações complexas se beneficiam significativamente dos recursos de processamento colunar e vetorização do mecanismo.
- O aprimoramento de desempenho é mais notável em cenários em que as consultas não acionam o mecanismo de fallback, evitando recursos ou expressões sem suporte.
- O mecanismo é adequado para consultas que são computacionalmente intensivas, em vez de simples ou vinculadas a E/S.
Para obter informações sobre os operadores e funções suportados pelo mecanismo de execução nativo, consulte a documentação do Apache Gluten.
Habilitar o mecanismo de execução nativo
Para usar todos os recursos do mecanismo de execução nativo durante a fase de visualização, configurações específicas são necessárias. Os procedimentos a seguir mostram como ativar esse recurso para notebooks, definições de trabalho do Spark e ambientes inteiros.
Importante
O mecanismo de execução nativo dá suporte à versão mais recente do runtime de GA, que é Runtime 1.3 (Apache Spark 3.5, Delta Lake 3.2). Com o lançamento do mecanismo de execução nativo no Runtime 1.3, o suporte para a versão anterior—Runtime 1.2 (Apache Spark 3.4, Delta Lake 2.4)—foi descontinuado. Incentivamos todos os clientes a atualizar para o Runtime 1.3 mais recente. Observe que, se você estiver usando o Mecanismo de Execução Nativa no Runtime 1.2, a aceleração nativa será desabilitada em breve.
Habilitar no nível do ambiente
Para garantir um aprimoramento uniforme do desempenho, habilite o mecanismo de execução nativo em todos os trabalhos e notebooks associados ao seu ambiente:
Navegue até as configurações do seu ambiente.
Vá para Computação do Spark.
Acesse a guia Aceleração.
Marque a caixa rotulada Habilitar mecanismo de execução nativo.
Salve e publique as alterações.
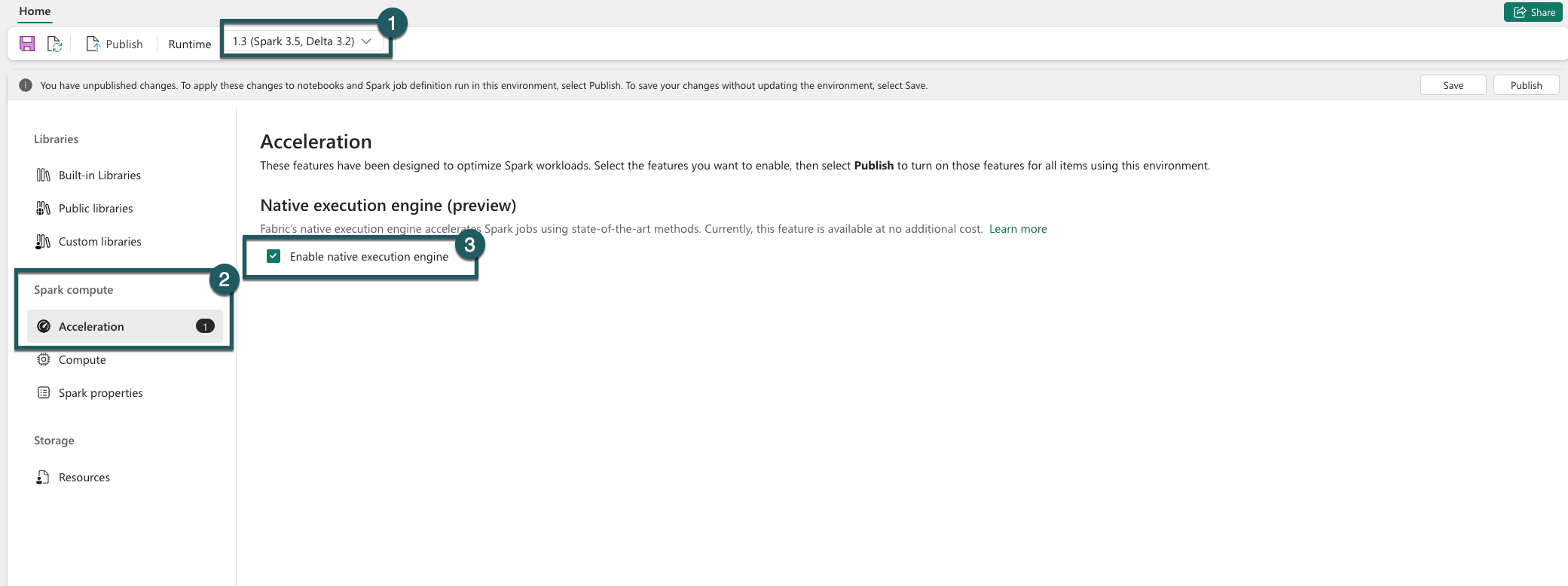

Quando habilitado no nível do ambiente, todos os trabalhos e notebooks subsequentes herdam a configuração. Essa herança garante que todas as novas sessões ou recursos criados no ambiente se beneficiem automaticamente dos recursos de execução aprimorados.
Importante
Anteriormente, o Mecanismo de Execução Nativa era habilitado por meio das configurações do Spark dentro da configuração do ambiente. Com nossa atualização mais recente (distribuição em andamento), simplificamos isso introduzindo um botão de alternância na guia Aceleração das configurações do ambiente. Habilite novamente o Mecanismo de Execução Nativa usando a nova alternância para continuar usando o Mecanismo de Execução Nativa, acesse a guia Aceleração nas configurações de ambiente e habilite-o por meio do botão de alternância. A nova configuração de alternância na interface do usuário agora tem prioridade em relação a qualquer configuração de propriedade anterior do Spark. Se você habilitou anteriormente o Mecanismo de Execução Nativa por meio das configurações do Spark, ele será desabilitado até que seja habilitado novamente por meio da alternância da interface do usuário.
De acordo com a política de congelamento de implantações do Microsoft Azure durante os feriados de Ação de Graças e Black Friday, reagendamos o lançamento para a região Centro-Norte dos EUA (NCUS) para o dia 6 de dezembro e para a região Leste dos EUA para o dia 9 de dezembro. Agradecemos sua compreensão e paciência durante este período movimentado.
Habilitar para um notebook ou definição de trabalho do Spark
Para habilitar o mecanismo de execução nativo para um único notebook ou definição de trabalho do Spark, você deve incorporar as configurações necessárias no início do script de execução:
%%configure
{
"conf": {
"spark.native.enabled": "true",
}
}
Para notebooks, insira os comandos de configuração necessários na primeira célula. Para definições de trabalho do Spark, inclua as configurações na linha de frente da definição de trabalho do Spark. O mecanismo de execução nativo é integrado a pools dinâmicos, portanto, depois de habilitar o recurso, ele entra em vigor imediatamente sem exigir que você inicie uma nova sessão.
Importante
A configuração do mecanismo de execução nativo deve ser feita antes do início da sessão do Spark. Depois que a sessão do Spark é iniciada, a configuração spark.shuffle.manager se torna imutável e não pode ser alterada. Certifique-se de que essas configurações estejam definidas dentro do bloco %%configure em notebooks ou no construtor de sessões do Spark para definições de trabalho do Spark.
Controle no nível de consulta
Os mecanismos para habilitar o Mecanismo de Execução Nativo nos níveis de locatário, espaço de trabalho e ambiente, perfeitamente integrados à interface do usuário, estão em desenvolvimento ativo. Você pode desabilitar o mecanismo de execução nativo para consultas específicas, especialmente se elas envolverem operadores sem suporte no momento (consulte limitações). Para desabilitá-lo, defina a configuração do Spark spark.native.enabled como false para a célula específica que contém sua consulta.
%%sql
SET spark.native.enabled=FALSE;

Depois de executar a consulta na qual o mecanismo de execução nativo está desabilitado, você deve reativá-lo para células subsequentes definindo spark.native.enabled como true. Essa etapa é necessária porque o Spark executa células de código sequencialmente.
%%sql
SET spark.native.enabled=TRUE;
Identificar operações executadas pelo mecanismo
Há vários métodos para determinar se um operador em seu trabalho do Apache Spark foi processado usando o mecanismo de execução nativo.
Interface do usuário do Spark e servidor de histórico do Spark
Acesse a interface do usuário do Spark ou o servidor de histórico do Spark para localizar a consulta que você precisa inspecionar. No plano de consulta em exibição na interface, procure por nomes de nós que terminem com o sufixo Transformer, NativeFileScan ou VeloxColumnarToRowExec. O sufixo indica que o mecanismo de execução nativo executou a operação. Por exemplo, nós podem ser rotulados como RollUpHashAggregateTransformer, ProjectExecTransformer, BroadcastHashJoinExecTransformer, ShuffledHashJoinExecTransformer ou BroadcastNestedLoopJoinExecTransformer.

Explicação de DataFrame
Como alternativa, você pode executar o comando df.explain() em seu notebook para exibir o plano de execução. Na saída, procure pelos mesmos sufixos Transformer, NativeFileScan ou VeloxColumnarToRowExec. Esse método fornece uma maneira rápida de confirmar se operações específicas estão sendo manipuladas pelo mecanismo de execução nativo.

Mecanismo de fallback
Em alguns casos, o mecanismo de execução nativo pode não ser capaz de executar uma consulta devido a motivos como recursos sem suporte. Nesses casos, a operação recai sobre o mecanismo Spark tradicional. Esse mecanismo de fallback automático garante que não haja interrupção no fluxo de trabalho.


Monitorar consultas e DataFrames executados pelo mecanismo
Para entender melhor como o mecanismo de execução nativo é aplicado a consultas SQL e operações DataFrame e para analisar detalhadamente os níveis de estágio e operador, você pode consulta a interface do usuário do Spark e o servidor de histórico do Spark para obter informações mais detalhadas sobre a execução do mecanismo nativo.
Guia Mecanismo de execução nativo
Você pode navegar para a nova guia “Gluten SQL / DataFrame” para exibir as informações de build do Gluten e os detalhes de execução da consulta. A tabela Consultas fornece insights sobre o número de nós em execução no mecanismo nativo e aqueles que voltam para a JVM para cada consulta.

Grafo de execução de consulta
Você também pode clicar na descrição da consulta para a visualização do plano de execução de consulta do Apache Spark. O grafo de execução fornece detalhes de execução nativos entre estágios e suas respectivas operações. As cores da tela de fundo diferenciam os mecanismo de execução: verde representa o mecanismo de execução nativo, enquanto azul-claro indica que a operação está sendo executada no mecanismo JVM padrão.

Limitações
Embora o mecanismo de execução nativo melhore o desempenho para trabalhos do Apache Spark, observe suas limitações atuais.
- (Ainda que estejamos trabalhando ativamente nisso) não há suporte para algumas operações específicas do Delta, incluindo operações de mesclagem, verificações de ponto de verificação e vetores de exclusão.
- Determinados recursos e expressões do Spark não são compatíveis com o mecanismo de execução nativo, como funções definidas pelo usuário (UDFs) e a função
array_contains, bem como o streaming estruturado do Spark. O uso dessas operações ou funções incompatíveis como parte de uma biblioteca importada também causará fallback para o mecanismo do Spark. - Não há suporte para varreduras de soluções de armazenamento que utilizam pontos de extremidade privados (ainda que estejamos trabalhando ativamente nisso).
- O mecanismo não oferece suporte ao modo ANSI, então ele pesquisa e, uma vez que o modo ANSI está habilitado, ele volta automaticamente para o Spark de baunilha.
Ao usar filtros de data em consultas, é essencial garantir que os tipos de dados em ambos os lados da comparação correspondam para evitar problemas de desempenho. Tipos de dados incompatíveis podem não trazer impulso de execução de consulta e podem exigir conversão explícita. Certifique-se sempre de que os tipos de dados do lado esquerdo (LHS) e do lado direito (RHS) de uma comparação sejam idênticos, pois os tipos incompatíveis nem sempre serão automaticamente convertidos. Se uma incompatibilidade de tipo for inevitável, use a conversão explícita para corresponder aos tipos de dados, como CAST(order_date AS DATE) = '2024-05-20'. Consultas com tipos de dados incompatíveis que exigem conversão não serão aceleradas pelo Native Execution Engine, portanto, garantir a consistência do tipo é crucial para manter o desempenho. Por exemplo, em vez de order_date em que order_date = '2024-05-20' é DATETIME e a cadeia de caracteres é DATE, converta explicitamente order_date em DATE garantir tipos de dados consistentes e melhorar o desempenho.