Introdução aos índices columnstore para análise operacional em tempo real
Aplica-se a: ![]() SQL Server
SQL Server ![]() Banco de Dados SQL do Azure
Banco de Dados SQL do Azure ![]() Instância Gerenciada de SQL do Azure
Instância Gerenciada de SQL do Azure ![]() Banco de Dados SQL no Microsoft Fabric
Banco de Dados SQL no Microsoft Fabric
O SQL Server 2016 (13.x) apresenta análise operacional em tempo real, a capacidade de executar cargas de trabalho OLTP e analíticas nas mesmas tabelas de banco de dados ao mesmo tempo. Além de executar análise em tempo real, você também pode eliminar a necessidade de ETL e de um data warehouse.
Análise operacional em tempo real explicada
Tradicionalmente, as empresas tinham sistemas separados para cargas de trabalho operacionais (isto é, OLTP) e analíticas. Para tais sistemas, os trabalhos ETL (Extrair, Transformar e Carregar) movem os dados regularmente do repositório operacional para um repositório analítico. Os dados analíticos geralmente são armazenados em um data warehouse ou data mart dedicado para execução de consultas analíticas. Embora essa solução tenha sido o padrão, ela apresenta estes três desafios principais:
Complexidade. Implementar o ETL pode exigir codificação considerável especialmente para carregar apenas as linhas modificadas. Pode haver complexidade na identificação de quais linhas foram modificadas.
Custo. Implementar o ETL exige o custo da compra de licenças adicionais de hardware e software.
Latência de dados. Implementar o ETL adiciona um atraso para execução da análise. Por exemplo, se o trabalho ETL for executado no final de cada dia útil, as consultas analíticas serão executadas nos dados com pelo menos um dia. Para muitas empresas, esse atraso é inaceitável porque a empresa depende da análise de dados em tempo real. Por exemplo, a detecção de fraudes requer análise em tempo real em dados operacionais.
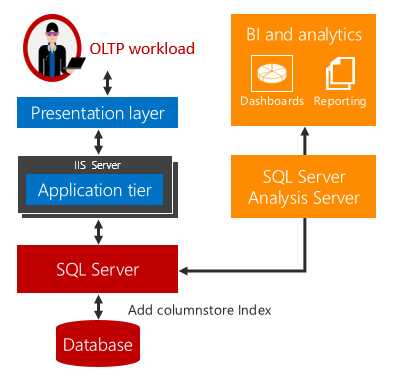
A análise operacional em tempo real oferece uma solução para esses desafios.
Não há atraso algum quando as cargas de trabalho OLTP e analíticas são executadas na mesma tabela subjacente. Em cenários que podem usar análise em tempo real, os custos e a complexidade são enormemente reduzidos com a eliminação da necessidade de ETL e da necessidade de compra e manutenção de um data warehouse separado.
Observação
A análise operacional em tempo real visa o cenário de uma fonte de dados individual, como um aplicativo ERP (planejamento de recursos empresariais) no qual é possível executar a carga de trabalho operacional e analítica. Isso não substitui a necessidade de um data warehouse separado quando você precisar integrar dados de várias fontes antes de executar a carga de trabalho analítica ou quando você exigir desempenho extremo de análise usando dados pré-agregados, como cubos.
A análise em tempo real usa um índice columnstore atualizável em uma tabela rowstore. O índice columnstore mantém uma cópia dos dados para que as cargas de trabalho OLTP e analítica sejam executadas em cópias separadas dos dados. Isso minimiza o impacto no desempenho de ambas as cargas de trabalho em execução ao mesmo tempo. O SQL Server mantém automaticamente as mudanças no índice para que as alterações no OLTP estejam sempre atualizadas para análise. Com esse design, é possível e prático executar análise em tempo real em dados atualizados. Isso funciona para tabelas com otimização de memória e baseadas em disco.
Exemplo de introdução
Para começar com a análise em tempo real:
Identifique as tabelas em seu esquema operacional que contenham dados obrigatórios para análise.
Em cada tabela, descarte todos os índices árvore B desenvolvidos basicamente para acelerar a análise existente em sua carga de trabalho OLTP. Substitua-os por um único índice columnstore. Isso pode melhorar o desempenho geral da carga de trabalho OLTP, já que haverá menos índices para manter.
--This example creates a nonclustered columnstore index on an existing OLTP table. --Create the table CREATE TABLE t_account ( accountkey int PRIMARY KEY, accountdescription nvarchar (50), accounttype nvarchar(50), unitsold int ); --Create the columnstore index with a filtered condition CREATE NONCLUSTERED COLUMNSTORE INDEX account_NCCI ON t_account (accountkey, accountdescription, unitsold) ;O índice columnstore em uma tabela na memória permite análise operacional integrando tecnologias OLTP in-memory e columnstore in-memory para oferecer alto desempenho a cargas de trabalho OLTP e analíticas. O índice columnstore em uma tabela na memória deve incluir todas as colunas.
-- This example creates a memory-optimized table with a columnstore index. CREATE TABLE t_account ( accountkey int NOT NULL PRIMARY KEY NONCLUSTERED, Accountdescription nvarchar (50), accounttype nvarchar(50), unitsold int, INDEX t_account_cci CLUSTERED COLUMNSTORE ) WITH (MEMORY_OPTIMIZED = ON ); GO
Agora você está pronto para executar análise operacional em tempo real sem fazer alterações no seu aplicativo. As consultas analíticas serão executadas no índice columnstore e as operações OLTP continuarão sendo executadas nos índices árvore B OLTP. As cargas de trabalho OLTP continuarão sendo executadas, mas incorrerão em alguma sobrecarga adicional para manter o índice columnstore. Veja as otimizações de desempenho na próxima seção.
Observação
A documentação usa o termo árvore B geralmente em referência a índices. Em índices de rowstore, o Database Engine implementa uma árvore B+. Isso não se aplica a índices columnstore ou índice em tabelas com otimização de memória. Para obter mais informações, confira o Guia de arquitetura e design do índice do SQL Server e SQL do Azure.
Postagens no blog
Leia as postagens no blog a seguir para saber mais sobre a análise operacional em tempo real. Talvez seja mais fácil entender as seções de dicas de desempenho se você ler essas postagens primeiro.
Vídeos
A série de vídeos Data Exposed em mais detalhes sobre alguns dos recursos e considerações.
- Parte 1: Como o SQL do Azure habilita a análise operacional em tempo real (HTAP)
- Parte 2: Otimize bancos de dados e aplicativos existentes com análise operacional
- Parte 3: Como criar análises operacionais com funções de janela.
Dica de desempenho nº 1: use índices filtrados para melhorar o desempenho da consulta
Executar a análise operacional em tempo real pode afetar o desempenho da carga de trabalho OLTP. Esse impacto deve ser mínimo. O exemplo A mostra como usar índices filtrados para minimizar o impacto do índice columnstore não clusterizado na carga de trabalho transacional e, ao mesmo tempo, fornecer análises em tempo real.
Para minimizar a sobrecarga de manter um índice columnstore não clusterizado em uma carga de trabalho operacional, você pode usar uma condição filtrada para criar um índice columnstore não clusterizado apenas de dados passivos ou que mudam de modo constante e lento. Por exemplo, em um aplicativo de gerenciamento de pedidos, você pode criar um índice columnstore não clusterizado dos pedidos que já foram despachados. Depois que o pedido tiver sido enviado, ele raramente muda e, portanto, pode ser considerado como dados passivos. Com o índice filtrado, os dados no índice columnstore não clusterizado exigem menos atualizações, reduzindo, assim, o impacto na carga de trabalho transacional.
As consultas analíticas acessam de modo transparente os dados passivos e ativos, conforme a necessidade de fornecer análise em tempo real. Se uma parte significativa da carga de trabalho operacional estiver tocando os dados "ativos", essas operações não exigirão manutenção adicional do índice columnstore. Uma prática recomendada é ter um índice clusterizado rowstore em colunas usadas na definição do índice filtrado. O SQL Server usa o índice clusterizado para verificar rapidamente as linhas que não atenderam à condição filtrada. Sem esse índice clusterizado, uma verificação de tabela completa da tabela rowstore será exigida para encontrar essas linhas, que podem afetar negativamente o desempenho da consulta analítica de modo significativo. Na ausência do índice clusterizado, você pode criar um índice árvore B não clusterizado filtrado complementar para identificar tais linhas, mas não é recomendado, pois acessar grandes intervalos de linhas por meio de índices árvore B não clusterizados custa caro.
Observação
Um índice columnstore não clusterizado filtrado é permitido apenas em tabelas baseadas em disco. Ele não é permitido em tabelas com otimização de memória
Exemplo A: acessar dados de acesso frequente do índice árvore B, dados passivos do índice columnstore
Este exemplo usa uma condição filtrada (accountkey > 0) para estabelecer quais linhas estarão no índice columnstore. A meta é criar a condição filtrada e as consultas subsequentes para acessar dados de acesso "frequente" que mudam no índice árvore B+ e acessar os dados "passivos" mais estáveis no índice columnstore.

Observação
O Otimizador de Consulta vai considerar, mas nem sempre escolherá, o índice columnstore para o plano de consulta. Quando o otimizador de consulta escolher o índice columnstore filtrado, ele combinará de modo transparente as linhas do índice columnstore, bem como as linhas que não atendem à condição filtrada para permitir análise em tempo real. Isso é diferente de um índice filtrado não clusterizado regular, que pode ser usado apenas em consultas que restringem a si mesmas a linhas presentes no índice.
--Use a filtered condition to separate hot data in a rowstore table
-- from "warm" data in a columnstore index.
-- create the table
CREATE TABLE orders (
AccountKey int not null,
Customername nvarchar (50),
OrderNumber bigint,
PurchasePrice decimal (9,2),
OrderStatus smallint not null,
OrderStatusDesc nvarchar (50));
-- OrderStatusDesc
-- 0 => 'Order Started'
-- 1 => 'Order Closed'
-- 2 => 'Order Paid'
-- 3 => 'Order Fullfillment Wait'
-- 4 => 'Order Shipped'
-- 5 => 'Order Received'
CREATE CLUSTERED INDEX orders_ci ON orders(OrderStatus);
--Create the columnstore index with a filtered condition
CREATE NONCLUSTERED COLUMNSTORE INDEX orders_ncci ON orders (accountkey, customername, purchaseprice, orderstatus)
where orderstatus = 5;
-- The following query returns the total purchase done by customers for items > $100 .00
-- This query will pick rows both from NCCI and from 'hot' rows that are not part of NCCI
SELECT top 5 customername, sum (PurchasePrice)
FROM orders
WHERE purchaseprice > 100.0
Group By customername;
A consulta analítica será executada com o plano de consulta a seguir. Você pode ver que as linhas que não atendem à condição filtrada são acessadas por meio do índice árvore B clusterizado.

Para obter mais informações, consulte Blog: índice columnstore não clusterizado filtrado.
Dica de desempenho nº 2: transferir a análise para o secundário legível Always On
Mesmo que você possa minimizar a manutenção do índice columnstore usando um índice columnstore filtrado, as consultas analíticas ainda podem exigir recursos consideráveis de computação (CPU, E/S, memória), que afetam o desempenho da carga de trabalho operacional. Para a maioria das cargas de trabalho de missão crítica, nossa recomendação é usar a configuração Always On. Nessa configuração, você pode eliminar o impacto de executar a análise transferindo-a para um secundário legível.
Dica de desempenho nº 3: reduzir a fragmentação de índice mantendo dados ativos em rowgroups delta
As tabelas com índice columnstore podem ficar significativamente fragmentadas (ou seja, linhas excluídas) se a carga de trabalho atualizar/excluir linhas que foram compactadas. Um índice columnstore fragmentado leva à utilização ineficaz de memória/armazenamento. Além do uso ineficaz de recursos, ele também afeta negativamente o desempenho da consulta de análise devido à E/S extra e à necessidade de filtrar as linhas excluídas no conjunto de resultados.
As linhas excluídas não são fisicamente removidas até que você execute a desfragmentação do índice com o comando REORGANIZE ou recrie o índice columnstore na tabela inteira ou nas partições afetadas. Ambos os índices REORGANIZE e REBUILD são operações caras que consomem recursos que, de outra forma, poderiam ser usados para a carga de trabalho. Além disso, se as linhas forem compactadas muito cedo, talvez seja necessário recompactá-las várias vezes devido a atualizações que levam a uma sobrecarga de compactação desperdiçada.
Você pode minimizar a fragmentação de índice usando a opção COMPRESSION_DELAY.
-- Create a sample table
CREATE TABLE t_colstor (
accountkey int not null,
accountdescription nvarchar (50) not null,
accounttype nvarchar(50),
accountCodeAlternatekey int);
-- Creating nonclustered columnstore index with COMPRESSION_DELAY. The columnstore index will keep the rows in closed delta rowgroup for 100 minutes
-- after it has been marked closed
CREATE NONCLUSTERED COLUMNSTORE index t_colstor_cci on t_colstor (accountkey, accountdescription, accounttype)
WITH (DATA_COMPRESSION= COLUMNSTORE, COMPRESSION_DELAY = 100);
Para obter mais informações, consulte Blog: Atraso de compactação.
Aqui estão as melhores práticas recomendadas:
Inserir/consultar a carga de trabalho: se a carga de trabalho for basicamente inserir dados e consultá-los, o padrão COMPRESSION_DELAY de 0 será a opção recomendada. As linhas recentemente inseridas serão compactadas uma vez que 1 milhão de linhas foram inseridas em um único rowgroup delta.
Alguns exemplos dessa carga de trabalho são (a) carga de trabalho DW tradicional (b) análise de fluxo de seleção quando você precisa analisar o padrão de seleção em um aplicativo Web.Carga de trabalho OLTP: se a carga de trabalho for pesada em DML (ou seja, combinação pesada de Atualizar, Excluir e Inserir), você poderá ver a fragmentação do índice columnstore examinando a DMV
sys. dm_db_column_store_row_group_physical_stats. Caso veja que > 10% das linhas são marcadas como excluídas em rowgroups recentemente compactados, você poderá usar a opção COMPRESSION_DELAY para adicionar atraso quando as linhas se tornarem qualificadas para compactação. Por exemplo, se para sua carga de trabalho, os dados recentemente inseridos permanecerem 'frequentes' (isso é, forem atualizados várias vezes) digamos que por 60 minutos, você deverá escolher COMPRESSION_DELAY para ser 60.
Esperamos que a maioria dos clientes não precise fazer nada. O valor padrão de COMPRESSION_DELAY option deve funcionar para eles.
Para usuários avançados, recomendamos executar a consulta a seguir e coletar % de linhas excluídas nos últimos sete dias.
SELECT row_group_id,cast(deleted_rows as float)/cast(total_rows as float)*100 as [% fragmented], created_time
FROM sys. dm_db_column_store_row_group_physical_stats
WHERE object_id = object_id('FactOnlineSales2')
AND state_desc='COMPRESSED'
AND deleted_rows>0
AND created_time > GETDATE() - 7
ORDER BY created_time DESC;
Se o número de linhas excluídas em rowgroups > compactados for de 20%, o platô em rowgroups mais antigos com < variação de 5% (chamados de rowgroups frios) for definido COMPRESSION_DELAY = (youngest_rowgroup_created_time - current_time). Essa abordagem funciona melhor com uma carga de trabalho estável e relativamente homogênea.