Entender o mapeamento de exibição de dados em visuais do Power BI
Este artigo discute o mapeamento de exibição de dados e descreve como as funções de dados são usadas para criar diferentes tipos de visuais. Ele explica como especificar requisitos condicionais para funções de dados e os diferentes tipos de dataMappings.
Cada mapeamento válido produz uma exibição de dados. Você pode fornecer vários mapeamentos de dados sob determinadas condições. As opções de pesquisa compatíveis são:
"dataViewMappings": [
{
"conditions": [ ... ],
"categorical": { ... },
"single": { ... },
"table": { ... },
"matrix": { ... }
}
]
O Power BI criará um mapeamento para uma exibição de dados se o mapeamento válido também estiver definido em dataViewMappings.
Em outras palavras, categorical pode ser definido em dataViewMappings, mas outros mapeamentos, como table ou single, podem não ser. Nesse caso, o Power BI produz uma exibição de dados com um só mapeamento categorical, enquanto table e outros mapeamentos permanecem indefinidos. Por exemplo:
"dataViewMappings": [
{
"categorical": {
"categories": [ ... ],
"values": [ ... ]
},
"metadata": { ... }
}
]
Condições
A seção conditions estabelece regras para um mapeamento de dados específico. Se os dados corresponderem a um dos conjuntos de condições descritos, o visual aceitará os dados como válidos.
Para cada campo, você pode especificar um valor mínimo e um máximo. O valor representa o número de campos que podem ser associados a essa função de dados.
Observação
Se uma função de dados for omitida na condição, ela poderá ter qualquer número de campos.
No exemplo a seguir, você o categoryé limitado a um campo de dados e measure a dois campos de dados.
"conditions": [
{ "category": { "max": 1 }, "measure": { "max": 2 } },
]
Você também pode definir várias condições para uma função de dados. Nesse caso, os dados serão válidos se qualquer uma das condições for atendida.
"conditions": [
{ "category": { "min": 1, "max": 1 }, "measure": { "min": 2, "max": 2 } },
{ "category": { "min": 2, "max": 2 }, "measure": { "min": 1, "max": 1 } }
]
No exemplo anterior, uma das duas seguintes condições é necessária:
- Exatamente um campo de categoria e exatamente duas medidas
- Exatamente duas categorias e exatamente uma medida
Mapeamento de dados único
O mapeamento de dados único é a forma mais simples de mapeamento de dados. Ele aceita apenas um campo de medida e fornece o total. Se o campo for numérico, ele retornará a soma. Caso contrário, ele retornará uma contagem de valores exclusivos.
Para usar o mapeamento de dados único, defina o nome da função de dados que você deseja mapear. Esse mapeamento funciona apenas com um único campo de medida. Se um segundo campo for atribuído, nenhuma exibição de dados será gerada, portanto, é uma boa prática incluir uma condição que limite os dados a um único campo.
Observação
Esse mapeamento de dados não pode ser usado junto com nenhum outro mapeamento de dados. Ele se destina a reduzir os dados a apenas um valor numérico.
Por exemplo:
{
"dataRoles": [
{
"displayName": "Y",
"name": "Y",
"kind": "Measure"
}
],
"dataViewMappings": [
{
"conditions": [
{
"Y": {
"max": 1
}
}
],
"single": {
"role": "Y"
}
}
]
}
A exibição de dados resultante ainda contém os outros tipos de mapeamento, como de tabela ou categórico, mas cada mapeamento contém apenas o valor único. A prática recomendada é acessar o valor somente no mapeamento de formato único.
{
"dataView": [
{
"metadata": null,
"categorical": null,
"matrix": null,
"table": null,
"tree": null,
"single": {
"value": 94163140.3560001
}
}
]
}
O exemplo de código a seguir processa o mapeamento de exibições de dados simples:
"use strict";
import powerbi from "powerbi-visuals-api";
import DataView = powerbi.DataView;
import DataViewSingle = powerbi.DataViewSingle;
// standard imports
// ...
export class Visual implements IVisual {
private target: HTMLElement;
private host: IVisualHost;
private valueText: HTMLParagraphElement;
constructor(options: VisualConstructorOptions) {
// constructor body
this.target = options.element;
this.host = options.host;
this.valueText = document.createElement("p");
this.target.appendChild(this.valueText);
// ...
}
public update(options: VisualUpdateOptions) {
const dataView: DataView = options.dataViews[0];
const singleDataView: DataViewSingle = dataView.single;
if (!singleDataView ||
!singleDataView.value ) {
return
}
this.valueText.innerText = singleDataView.value.toString();
}
}
O exemplo de código anterior resulta na exibição de apenas um valor do Power BI:
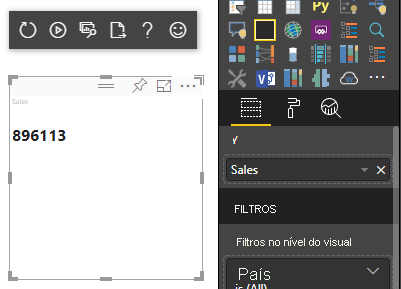
Mapeamento de dados categóricos
O mapeamento de dados categóricos é usado para obter agrupamentos independentes também chamados de categorias de dados. As categorias também podem ser agrupadas usando “group by” no mapeamento de dados.
Mapeamento de dados categórico básico
Considere as seguintes funções de dados e mapeamentos:
"dataRoles":[
{
"displayName": "Category",
"name": "category",
"kind": "Grouping"
},
{
"displayName": "Y Axis",
"name": "measure",
"kind": "Measure"
}
],
"dataViewMappings": {
"categorical": {
"categories": {
"for": { "in": "category" }
},
"values": {
"select": [
{ "bind": { "to": "measure" } }
]
}
}
}
O exemplo anterior diz: "Mapear minha função de dados category para que cada campo que eu arrasto para category seja mapeado para categorical.categories. Mapear também a minha função de dados measure para categorical.values".
- for...in: Inclui todos os itens nessa função de dados, na consulta de dados.
- bind...to: Produz o mesmo resultado que for...in, mas espera que a função de dados tenha uma condição que a restrinja a apenas um campo.
Agrupar dados categóricos
O exemplo a seguir usa as mesmas duas funções de dados do exemplo anterior, além de mais duas funções de dados chamadas grouping e measure2.
"dataRoles":[
{
"displayName": "Category",
"name": "category",
"kind": "Grouping"
},
{
"displayName": "Y Axis",
"name": "measure",
"kind": "Measure"
},
{
"displayName": "Grouping with",
"name": "grouping",
"kind": "Grouping"
},
{
"displayName": "X Axis",
"name": "measure2",
"kind": "Grouping"
}
],
"dataViewMappings": [
{
"categorical": {
"categories": {
"for": {
"in": "category"
}
},
"values": {
"group": {
"by": "grouping",
"select": [{
"bind": {
"to": "measure"
}
},
{
"bind": {
"to": "measure2"
}
}
]
}
}
}
}
]
A diferença entre esse mapeamento e o mapeamento básico está em como mapeamos categorical.values. Quando você mapeia as funções de dadosmeasure e measure2 para a função de dados grouping, o eixo x e o eixo y podem ser dimensionados adequadamente.
Consultar dados hierárquicos
No próximo exemplo, os dados categóricos são usados para criar uma hierarquia, que pode ser usada para dar suporte a ações de drill down.
O exemplo a seguir mostra as funções de dados e os mapeamentos:
"dataRoles": [
{
"displayName": "Categories",
"name": "category",
"kind": "Grouping"
},
{
"displayName": "Measures",
"name": "measure",
"kind": "Measure"
},
{
"displayName": "Series",
"name": "series",
"kind": "Measure"
}
],
"dataViewMappings": [
{
"categorical": {
"categories": {
"for": {
"in": "category"
}
},
"values": {
"group": {
"by": "series",
"select": [{
"for": {
"in": "measure"
}
}
]
}
}
}
}
]
Considere os seguintes dados categóricos:
| País/Região | 2013 | 2014 | 2015 | 2016 |
|---|---|---|---|---|
| EUA | x | x | 650 | 350 |
| Canada | x | 630 | 490 | x |
| México | 645 | x | x | x |
| Reino Unido | x | x | 831 | x |
O Power BI produz uma exibição de dados categóricos com o conjunto de categorias a seguir.
{
"categorical": {
"categories": [
{
"source": {...},
"values": [
"Canada",
"USA",
"UK",
"Mexico"
],
"identity": [...],
"identityFields": [...],
}
]
}
}
Cada category é mapeado para um conjunto de values. Cada um desses values é agrupado por series, que é expresso como anos.
Por exemplo, cada matriz values representa um ano.
Além disso, cada matriz values tem quatro valores: Canada, USA, UK e Mexico.
{
"values": [
// Values for year 2013
{
"source": {...},
"values": [
null, // Value for `Canada` category
null, // Value for `USA` category
null, // Value for `UK` category
645 // Value for `Mexico` category
],
"identity": [...],
},
// Values for year 2014
{
"source": {...},
"values": [
630, // Value for `Canada` category
null, // Value for `USA` category
null, // Value for `UK` category
null // Value for `Mexico` category
],
"identity": [...],
},
// Values for year 2015
{
"source": {...},
"values": [
490, // Value for `Canada` category
650, // Value for `USA` category
831, // Value for `UK` category
null // Value for `Mexico` category
],
"identity": [...],
},
// Values for year 2016
{
"source": {...},
"values": [
null, // Value for `Canada` category
350, // Value for `USA` category
null, // Value for `UK` category
null // Value for `Mexico` category
],
"identity": [...],
}
]
}
O exemplo de código a seguir é para processar o mapeamento categórico de exibição de dados. Este exemplo cria a estrutura hierárquica Valor > Ano >País/Região.
"use strict";
import powerbi from "powerbi-visuals-api";
import DataView = powerbi.DataView;
import DataViewCategorical = powerbi.DataViewCategorical;
import DataViewValueColumnGroup = powerbi.DataViewValueColumnGroup;
import PrimitiveValue = powerbi.PrimitiveValue;
// standard imports
// ...
export class Visual implements IVisual {
private target: HTMLElement;
private host: IVisualHost;
private categories: HTMLElement;
constructor(options: VisualConstructorOptions) {
// constructor body
this.target = options.element;
this.host = options.host;
this.categories = document.createElement("pre");
this.target.appendChild(this.categories);
// ...
}
public update(options: VisualUpdateOptions) {
const dataView: DataView = options.dataViews[0];
const categoricalDataView: DataViewCategorical = dataView.categorical;
if (!categoricalDataView ||
!categoricalDataView.categories ||
!categoricalDataView.categories[0] ||
!categoricalDataView.values) {
return;
}
// Categories have only one column in data buckets
// To support several columns of categories data bucket, iterate categoricalDataView.categories array.
const categoryFieldIndex = 0;
// Measure has only one column in data buckets.
// To support several columns on data bucket, iterate years.values array in map function
const measureFieldIndex = 0;
let categories: PrimitiveValue[] = categoricalDataView.categories[categoryFieldIndex].values;
let values: DataViewValueColumnGroup[] = categoricalDataView.values.grouped();
let data = {};
// iterate categories/countries-regions
categories.map((category: PrimitiveValue, categoryIndex: number) => {
data[category.toString()] = {};
// iterate series/years
values.map((years: DataViewValueColumnGroup) => {
if (!data[category.toString()][years.name] && years.values[measureFieldIndex].values[categoryIndex]) {
data[category.toString()][years.name] = []
}
if (years.values[0].values[categoryIndex]) {
data[category.toString()][years.name].push(years.values[measureFieldIndex].values[categoryIndex]);
}
});
});
this.categories.innerText = JSON.stringify(data, null, 6);
console.log(data);
}
}
Este é o visual resultante:
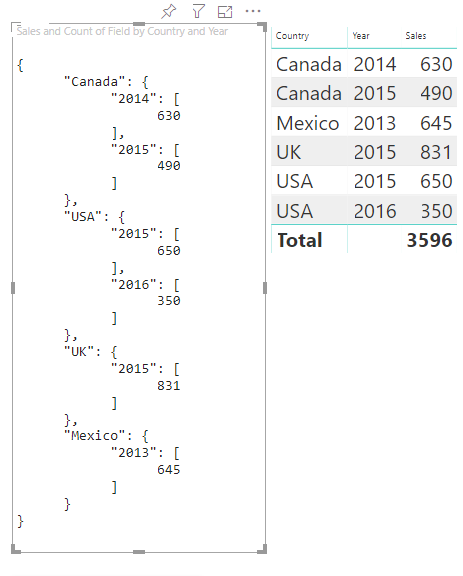
Tabelas de mapeamento
A exibição de dados da tabela é essencialmente uma lista de pontos de dados, em que os pontos de dados numéricos podem ser agregados.
Por exemplo, use os mesmos dados da seção anterior, mas com as seguintes funcionalidades:
"dataRoles": [
{
"displayName": "Column",
"name": "column",
"kind": "Grouping"
},
{
"displayName": "Value",
"name": "value",
"kind": "Measure"
}
],
"dataViewMappings": [
{
"table": {
"rows": {
"select": [
{
"for": {
"in": "column"
}
},
{
"for": {
"in": "value"
}
}
]
}
}
}
]
Visualize a exibição de dados da tabela como nesse exemplo:
| País/Região | Year | Sales |
|---|---|---|
| EUA | 2016 | 100 |
| EUA | 2015 | 50 |
| Canada | 2015 | 200 |
| Canada | 2015 | 50 |
| México | 2013 | 300 |
| Reino Unido | 2014 | 150 |
| EUA | 2015 | 75 |
Associação de dados:
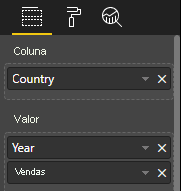
O Power BI exibe os dados como a exibição de dados da tabela. Não presuma que os dados sejam ordenados.
{
"table" : {
"columns": [...],
"rows": [
[
"Canada",
2014,
630
],
[
"Canada",
2015,
490
],
[
"Mexico",
2013,
645
],
[
"UK",
2014,
831
],
[
"USA",
2015,
650
],
[
"USA",
2016,
350
]
]
}
}
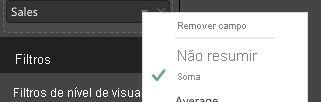
Para agregar os dados, selecione o campo desejado e, em seguida, selecione Soma.
Exemplo de código para processar o mapeamento de exibição de dados de tabela.
"use strict";
import "./../style/visual.less";
import powerbi from "powerbi-visuals-api";
// ...
import DataViewMetadataColumn = powerbi.DataViewMetadataColumn;
import DataViewTable = powerbi.DataViewTable;
import DataViewTableRow = powerbi.DataViewTableRow;
import PrimitiveValue = powerbi.PrimitiveValue;
// standard imports
// ...
export class Visual implements IVisual {
private target: HTMLElement;
private host: IVisualHost;
private table: HTMLParagraphElement;
constructor(options: VisualConstructorOptions) {
// constructor body
this.target = options.element;
this.host = options.host;
this.table = document.createElement("table");
this.target.appendChild(this.table);
// ...
}
public update(options: VisualUpdateOptions) {
const dataView: DataView = options.dataViews[0];
const tableDataView: DataViewTable = dataView.table;
if (!tableDataView) {
return
}
while(this.table.firstChild) {
this.table.removeChild(this.table.firstChild);
}
//draw header
const tableHeader = document.createElement("th");
tableDataView.columns.forEach((column: DataViewMetadataColumn) => {
const tableHeaderColumn = document.createElement("td");
tableHeaderColumn.innerText = column.displayName
tableHeader.appendChild(tableHeaderColumn);
});
this.table.appendChild(tableHeader);
//draw rows
tableDataView.rows.forEach((row: DataViewTableRow) => {
const tableRow = document.createElement("tr");
row.forEach((columnValue: PrimitiveValue) => {
const cell = document.createElement("td");
cell.innerText = columnValue.toString();
tableRow.appendChild(cell);
})
this.table.appendChild(tableRow);
});
}
}
O arquivo de estilos visuais style/visual.less contém o layout da tabela:
table {
display: flex;
flex-direction: column;
}
tr, th {
display: flex;
flex: 1;
}
td {
flex: 1;
border: 1px solid black;
}
O visual resultante tem esta aparência:
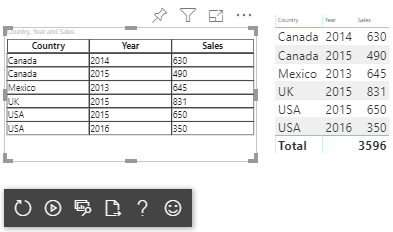
Mapeamento de dados de matriz
O mapeamento de dados de matriz é semelhante ao mapeamento de dados de tabela, mas as linhas são apresentadas hierarquicamente. Qualquer um dos valores de função de dados pode ser usado como um valor de cabeçalho de coluna.
{
"dataRoles": [
{
"name": "Category",
"displayName": "Category",
"displayNameKey": "Visual_Category",
"kind": "Grouping"
},
{
"name": "Column",
"displayName": "Column",
"displayNameKey": "Visual_Column",
"kind": "Grouping"
},
{
"name": "Measure",
"displayName": "Measure",
"displayNameKey": "Visual_Values",
"kind": "Measure"
}
],
"dataViewMappings": [
{
"matrix": {
"rows": {
"for": {
"in": "Category"
}
},
"columns": {
"for": {
"in": "Column"
}
},
"values": {
"select": [
{
"for": {
"in": "Measure"
}
}
]
}
}
}
]
}
Estrutura hierárquica de dados de matriz
O Power BI cria uma estrutura de dados hierárquica. A raiz da hierarquia de árvore inclui os dados da coluna Pais da função de dados Category, com filhos da coluna Filhos da tabela de função de dados.
Modelo semântico:
| Pais | Children | Netos | Colunas | Valores |
|---|---|---|---|---|
| Pai1 | Filho1 | Neto1 | Col1 | 5 |
| Pai1 | Filho1 | Neto1 | Col2 | 6 |
| Pai1 | Filho1 | Neto2 | Col1 | 7 |
| Pai1 | Filho1 | Neto2 | Col2 | 8 |
| Pai1 | Filho2 | Neto3 | Col1 | 5 |
| Pai1 | Filho2 | Neto3 | Col2 | 3 |
| Pai1 | Filho2 | Neto4 | Col1 | 4 |
| Pai1 | Filho2 | Neto4 | Col2 | 9 |
| Pai1 | Filho2 | Neto5 | Col1 | 3 |
| Pai1 | Filho2 | Neto5 | Col2 | 5 |
| Pai2 | Filho3 | Neto6 | Col1 | 1 |
| Pai2 | Filho3 | Neto6 | Col2 | 2 |
| Pai2 | Filho3 | Neto7 | Col1 | 7 |
| Pai2 | Filho3 | Neto7 | Col2 | 1 |
| Pai2 | Filho3 | Neto8 | Col1 | 10 |
| Pai2 | Filho3 | Neto8 | Col2 | 13 |
O visual de matriz principal do Power BI renderiza os dados como uma tabela.
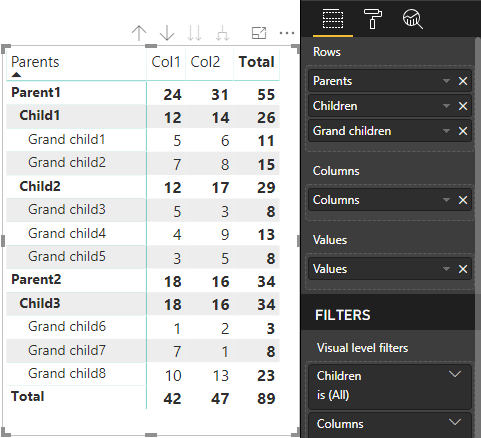
O visual obtém sua estrutura de dados conforme descrito no código a seguir (somente as duas primeiras linhas da tabela são mostradas aqui):
{
"metadata": {...},
"matrix": {
"rows": {
"levels": [...],
"root": {
"childIdentityFields": [...],
"children": [
{
"level": 0,
"levelValues": [...],
"value": "Parent1",
"identity": {...},
"childIdentityFields": [...],
"children": [
{
"level": 1,
"levelValues": [...],
"value": "Child1",
"identity": {...},
"childIdentityFields": [...],
"children": [
{
"level": 2,
"levelValues": [...],
"value": "Grand child1",
"identity": {...},
"values": {
"0": {
"value": 5 // value for Col1
},
"1": {
"value": 6 // value for Col2
}
}
},
...
]
},
...
]
},
...
]
}
},
"columns": {
"levels": [...],
"root": {
"childIdentityFields": [...],
"children": [
{
"level": 0,
"levelValues": [...],
"value": "Col1",
"identity": {...}
},
{
"level": 0,
"levelValues": [...],
"value": "Col2",
"identity": {...}
},
...
]
}
},
"valueSources": [...]
}
}
Expandir e recolher cabeçalhos de linha
Para a API 4.1.0 ou posterior, os dados de matriz dão suporte à expansão e recolhimento de cabeçalhos de linha. Na API 4.2, você pode expandir/recolher todo o nível programaticamente. O recurso expandir/recolher otimiza a busca de dados para o dataView, permitindo que o usuário expanda ou recolha uma linha sem buscar todos os dados para o próximo nível. Ele só busca os dados para a linha selecionada. O estado de expansão do cabeçalho de linha permanece consistente entre indicadores e até mesmo em relatórios salvos. Ele não é específico para cada visual.
Os comandos expandir e recolher podem ser adicionados ao menu de contexto fornecendo o parâmetro dataRoles ao método showContextMenu.
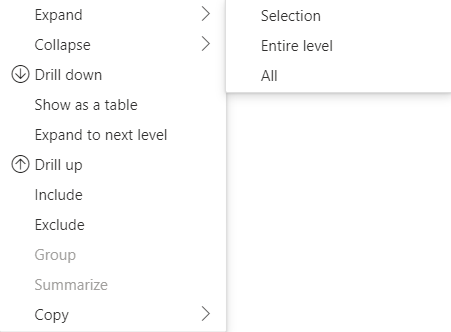
Para expandir um grande número de pontos de dados, use a API de buscar mais dados com a API de expansão/recolhimento.
Recursos de API
Os seguintes elementos foram adicionados à versão 4.1.0 da API para habilitar a expansão e o recolhimento de cabeçalhos de linha:
O sinalizador
isCollapsednoDataViewTreeNode:interface DataViewTreeNode { //... /** * TRUE if the node is Collapsed * FALSE if it is Expanded * Undefined if it cannot be Expanded (e.g. subtotal) */ isCollapsed?: boolean; }O método
toggleExpandCollapsena interfaceISelectionManger:interface ISelectionManager { //... showContextMenu(selectionId: ISelectionId, position: IPoint, dataRoles?: string): IPromise<{}>; // dataRoles is the name of the role of the selected data point toggleExpandCollapse(selectionId: ISelectionId, entireLevel?: boolean): IPromise<{}>; // Expand/Collapse an entire level will be available from API 4.2.0 //... }O sinalizador
canBeExpandedno DataViewHierarchyLevel:interface DataViewHierarchyLevel { //... /** If TRUE, this level can be expanded/collapsed */ canBeExpanded?: boolean; }
Requisitos visuais
Para habilitar o recurso de expandir e recolher para um visual usando a exibição de dados de matriz:
Adicione o seguinte código ao arquivo capabilities.json:
"expandCollapse": { "roles": ["Rows"], //”Rows” is the name of rows data role "addDataViewFlags": { "defaultValue": true //indicates if the DataViewTreeNode will get the isCollapsed flag by default } },Confirme se as funções são detalhadas:
"drilldown": { "roles": ["Rows"] },Para cada nó, crie uma instância do construtor de seleção e chame o método
withMatrixNodeno nível de hierarquia do nó selecionado e crie umselectionId. Por exemplo:let nodeSelectionBuilder: ISelectionIdBuilder = visualHost.createSelectionIdBuilder(); // parantNodes is a list of the parents of the selected node. // node is the current node which the selectionId is created for. parentNodes.push(node); for (let i = 0; i < parentNodes.length; i++) { nodeSelectionBuilder = nodeSelectionBuilder.withMatrixNode(parentNodes[i], levels); } const nodeSelectionId: ISelectionId = nodeSelectionBuilder.createSelectionId();Crie uma instância do gerenciador de seleção e use o método
selectionManager.toggleExpandCollapse()com o parâmetro doselectionIdque você criou para o nó selecionado. Por exemplo:// handle click events to apply expand\collapse action for the selected node button.addEventListener("click", () => { this.selectionManager.toggleExpandCollapse(nodeSelectionId); });
Observação
- Se o nó selecionado não for um nó de linha, o PowerBI ignorará as chamadas de expansão e recolhimento e os comandos expandir e recolher serão removidos do menu de contexto.
- O parâmetro
dataRolesserá necessário para o métodoshowContextMenusomente se o visual der suporte aos recursosdrilldownouexpandCollapse. Se o visual der suporte a esses recursos, mas dataRoles não tiver sido fornecido, um erro será gerado para o console ao usar o visual do desenvolvedor ou ao depurar um visual público com o modo de depuração habilitado.
Considerações e limitações
- Depois de expandir um nó, novos limites de dados serão aplicados ao DataView. O novo DataView pode não incluir alguns dos nós apresentados no DataView anterior.
- Ao usar a expansão ou recolhimento, os totais serão adicionados mesmo que o visual não os tenha solicitado.
- Não há suporte para a expansão e o recolhimento de colunas.
Manter todas as colunas de metadados
Para a API 5.1.0 ou posterior, há suporte para manter todas as colunas de metadados. Esse recurso permite que o visual receba os metadados de todas as colunas, independentemente de suas projeções ativas.
Adicione as seguintes linhas ao arquivo capabilities.json:
"keepAllMetadataColumns": {
"type": "boolean",
"description": "Indicates that visual is going to receive all metadata columns, no matter what the active projections are"
}
Definir essa propriedade como true resultará no recebimento de todos os metadados, incluindo de colunas recolhidas. Definir como false ou deixar indefinido resultará no recebimento de metadados somente em colunas com projeções ativas (por exemplo, expandidas).
Algoritmo de redução de dados
O algoritmo de redução de dados controla quais dados e quantos dados são recebidos na exibição de dados.
O count é definido como o número máximo de valores que a exibição de dados pode aceitar. Se houver mais de valores de count, o algoritmo de redução de dados determinará quais valores devem ser recebidos.
Tipos de algoritmo de redução de dados
Há quatro tipos de configurações de algoritmo de redução de dados:
top: os primeiros valores de count são obtidos do modelo semântico.bottom: os últimos valores de count são obtidos do modelo semântico.sample: o primeiro e o último itens estão incluídos e há um número de itens equivalente a count entre eles, com intervalos iguais. Por exemplo, se você tiver um modelo semântico [0, 1, 2, ... 100] e um count de 9, receberá os valores [0, 10, 20... 100].window: carrega uma janela de pontos de dados de cada vez contendo elementos count. Atualmente,topewindowsão equivalentes. No futuro, uma configuração de janela terá suporte total.
Por padrão, todos os visuais do Power BI têm o algoritmo de redução de dados principal aplicado com count definida como 1000 pontos de dados. Esse padrão é equivalente a definir as seguintes propriedades no arquivo capabilities.json:
"dataReductionAlgorithm": {
"top": {
"count": 1000
}
}
Você pode modificar o valor de count para qualquer valor inteiro até 30.000. Os visuais do Power BI baseados em R podem dar suporte a até 150000 linhas.
Uso de algoritmo de redução de dados
O algoritmo de redução de dados pode ser usado em mapeamento categórico, de tabela ou de exibição de dados de matriz.
No mapeamento de dados categóricos, você pode adicionar o algoritmo à seção "categorias" e/ou "grupo" de values para mapeamento de dados categóricos.
"dataViewMappings": {
"categorical": {
"categories": {
"for": { "in": "category" },
"dataReductionAlgorithm": {
"window": {
"count": 300
}
}
},
"values": {
"group": {
"by": "series",
"select": [{
"for": {
"in": "measure"
}
}
],
"dataReductionAlgorithm": {
"top": {
"count": 100
}
}
}
}
}
}
No mapeamento da exibição de dados de tabela, aplique o algoritmo de redução de dados à seção rows da tabela de mapeamento de Exibição de Dados.
"dataViewMappings": [
{
"table": {
"rows": {
"for": {
"in": "values"
},
"dataReductionAlgorithm": {
"top": {
"count": 2000
}
}
}
}
}
]
Você pode aplicar o algoritmo de redução de dados às seções rows e columns da matriz de mapeamento de Exibição de Dados.