Adicionar uma fonte do Kafka para Confluent a um eventstream
Este artigo mostra como adicionar uma fonte do Kafka para Confluent a um eventstream.
O Kafka para Confluent Cloud é uma plataforma de streaming que oferece recursos avançados de transmissão e processamento de dados usando o Apache Kafka. Ao integrar o Kafka para Confluent Cloud como uma origem no eventstream, você pode processar facilmente fluxos de dados em tempo real antes de encaminhá-los a vários destinos no Fabric.
Observação
Não há suporte para esta origem nas seguintes regiões de capacidade do espaço de trabalho: Oeste dos EUA 3 e Oeste da Suíça.
Pré-requisitos
- Acesso a um espaço de trabalho no modo de licença de capacidade do Fabric (ou) no modo de licença de Avaliação com permissões de Colaborador ou superior.
- Um cluster do Kafka para Confluent Cloud e uma chave de API.
- Seu cluster do Kafka para Confluent Cloud deve ser acessível publicamente e não estar por trás de um firewall ou protegido em uma rede virtual.
- Se você não tiver um Eventstream, crie um Eventstream.
Iniciar o assistente Selecionar uma fonte de dados
Se você ainda não adicionou nenhuma fonte ao Eventstream, selecione o bloco Usar fonte externa.

Caso esteja adicionando a fonte a um Eventstream já publicado, alterne para o modo Editar, selecione Adicionar fonte na faixa de opções e selecione Fontes externas.

Configurar e conectar-se ao Kafka para Confluent
Na página Selecionar uma fonte de dados, escolha Confluent.
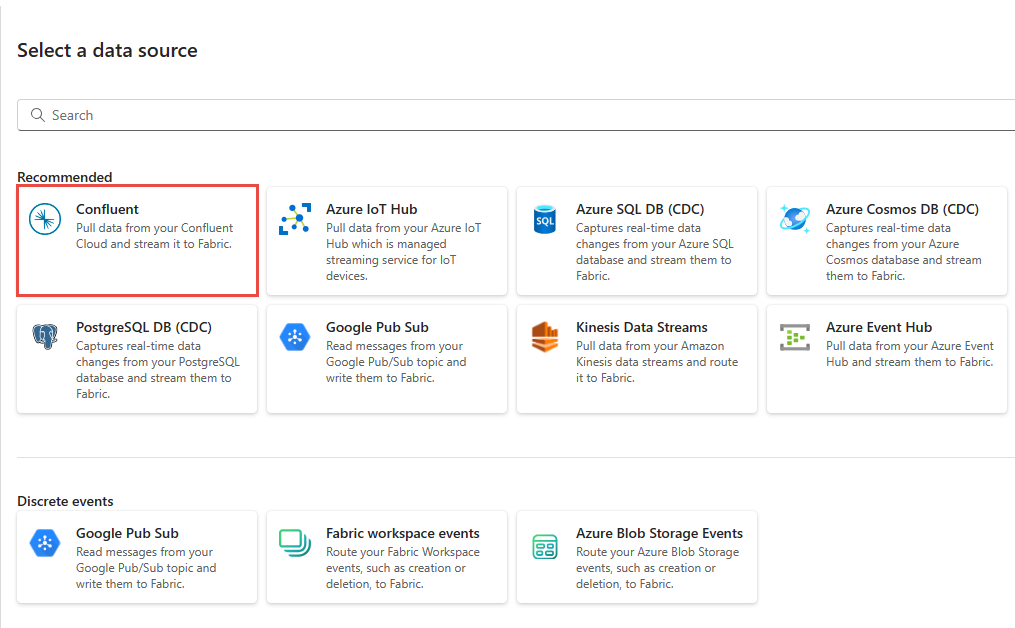
Para criar uma conexão com a origem do Kafka para Confluent Cloud, selecione Nova conexão.
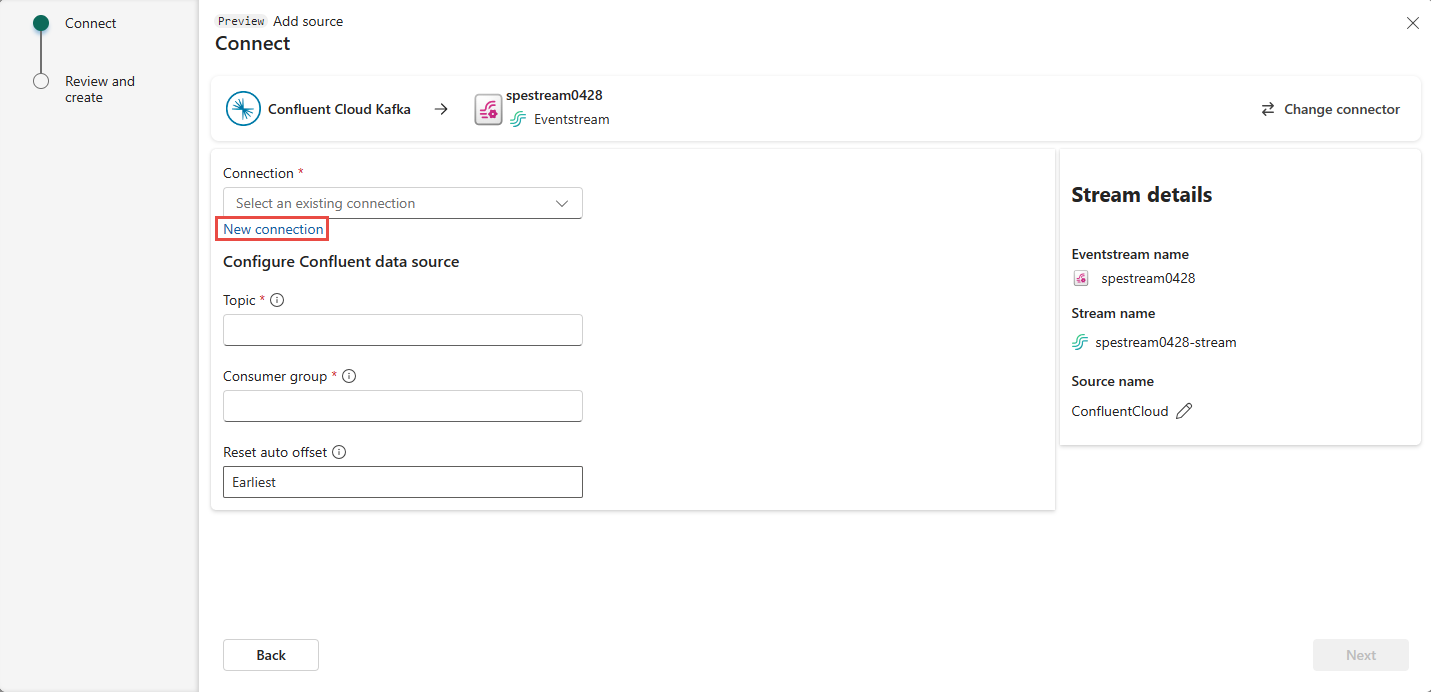
Na seção Configurações de conexão, insira Servidor de Inicialização do Confluent. Navegue até a home page do Confluent Cloud, selecione Configurações de Cluster e copie o endereço para o servidor de inicialização.
Na seção Credenciais de conexão, se você tiver uma conexão existente com o cluster do Confluent, selecione-a na lista suspensa de Conexão. Caso contrário, siga estas etapas:
- Em Nome da conexão, insira um nome para a conexão.
- Em Variante de autenticação, confirme se a Chave do Confluent Cloud está selecionada.
- Em Chave de API e Segredo da Chave de API:
Navegue até o Confluent Cloud.
Selecione Chaves de API no menu lateral.
Selecione o botão Adicionar chave para criar uma chave de API.
Copie a Chave de API e o Segredo.
Cole esses valores nos campos Chave de API e Segredo da Chave de API.
Selecione Conectar
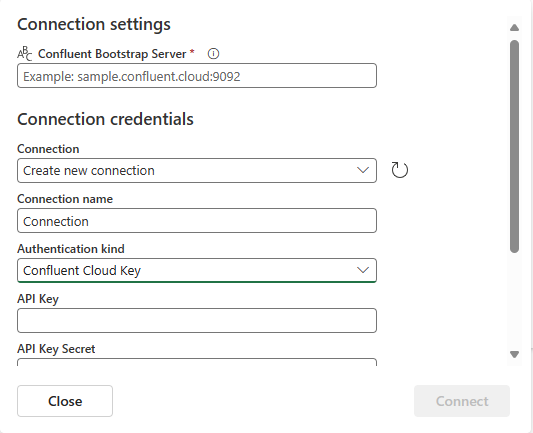
Role para ver a seção Configurar fonte de dados do Confluent na página. Insira as informações para concluir a configuração da fonte de dados do Confluent.
- Em Tópico, insira um nome de tópico do Confluent Cloud. Você pode criar ou gerenciar o tópico no console do Confluent Cloud.
- Em Grupo de consumidores, insira um grupo de consumidores do Confluent Cloud. Ele fornece o grupo de consumidores dedicado para obter os eventos do cluster do Confluent Cloud.
- Na configuração Restaurar deslocamento automático, selecione um dos seguintes valores:
Mais antigos – os primeiros dados disponíveis do cluster do Confluent
Mais recentes – os dados mais recentes disponíveis
Nenhum – não defina o deslocamento automaticamente.
Selecione Avançar. Na tela Revisar e criar, revise o resumo e selecione Adicionar.
Você verá que a fonte do Kafka para Confluent Cloud é adicionada ao eventstream na tela no Modo de edição. Para implementar essa fonte recém-adicionada do Kafka para Confluent Cloud, escolha Publicar na faixa.

Depois de concluir essas etapas, a fonte do Kafka para Confluent Cloud estará disponível para visualização na Exibição ao vivo.

Limitações
- Atualmente, não há suporte para o Confluent Kafka com formatos JSON e Avro, usando o registro de esquema.
- Atualmente, não há suporte para a decodificação de dados do Confluent Kafka usando o registro de esquema do Confluent.
Observação
O número máximo de origens e destinos para um fluxo de eventos é 11.
Conteúdo relacionado
Outros conectores:
- Amazon Kinesis Data Streams
- Azure Cosmos DB
- Hubs de eventos do Azure
- Hub IoT do Azure
- Captura de dados de alterações (CDA) com o Banco de Dados SQL do Azure
- Ponto de extremidade personalizado
- Pub/Sub do Google Cloud
- CDA do Banco de Dados MySQL
- CDA do Banco de dados PostgreSQL
- Dados de amostra
- Eventos de Armazenamento de Blobs do Azure
- Evento de espaço de trabalho do Fabric