Tutorial Parte 3: treinar e registrar um modelo de machine learning
Neste tutorial, você aprenderá a treinar vários modelos de aprendizado de máquina para selecionar o melhor, a fim de prever quais clientes bancários provavelmente vão sair.
Neste tutorial, você aprenderá a:
- Treinar modelos Random Forest e LightGBM.
- Use a integração nativa do Microsoft Fabric com a estrutura MLflow para registrar em log os modelos de aprendizado de máquina treinados, os hiperparâmetros usados e as métricas de avaliação.
- Registre o modelo de machine learning treinado.
- Avalie o desempenho dos modelos de aprendizado de máquina treinados no conjunto de dados de validação.
MLflow é uma plataforma de código aberto para gerenciar o ciclo de vida do aprendizado de máquina com recursos como Rastreamento, Modelos e Registro de Modelo. O MLflow é integrado nativamente à experiência de Ciência de Dados do Fabric.
Pré-requisitos
Obtenha uma assinatura do Microsoft Fabric. Ou, inscreva-se para uma avaliação gratuita do Microsoft Fabric.
Entre no Microsoft Fabric.
Use o alternador de experiência no lado inferior esquerdo da sua página inicial para alternar para o Fabric.
Esta é a parte 3 de 5 da série de tutoriais. Para concluir este tutorial, primeiro conclua:
- Parte 1: ingerir dados em um lakehouse do Microsoft Fabric usando o Apache Spark.
- Parte 2: explore e visualize dados usando blocos de anotações do Microsoft Fabric para saber mais sobre os dados.
Acompanhar no notebook
3-train-evaluate.ipynb é o notebook que acompanha este tutorial.
Para abrir o notebook que acompanha este tutorial, siga as instruções em Preparar seu sistema para tutoriais de ciência de dados para importar os notebooks para seu workspace.
Se preferir copiar e colar o código a partir dessa página, você poderá criar um novo notebook.
Certifique-se de anexar um lakehouse ao notebook antes de começar a executar o código.
Importante
Anexe a mesma lakehouse que você usou na parte 1 e na parte 2.
Instalar bibliotecas personalizadas
Para este bloco de anotações, você instalará o aprendizado desbalanceado (importado como imblearn) usando o %pip install. O aprendizado desbalanceado é uma biblioteca para Synthetic Minority Oversampling Technique (SMOTE) que é usada ao lidar com conjuntos de dados desbalanceados. O kernel do PySpark será reiniciado após %pip install, então você precisará instalar a biblioteca antes de executar qualquer outra célula.
Você acessará o SMOTE usando a biblioteca imblearn. Instale-o agora usando os recursos de instalação em linha (por exemplo, %pip, %conda).
# Install imblearn for SMOTE using pip
%pip install imblearn
Importante
Execute esta instalação sempre que reiniciar o notebook.
Quando você instala uma biblioteca em um notebook, ela só está disponível durante a sessão do bloco de anotações e não no espaço de trabalho. Se você reiniciar o bloco de anotações, precisará instalar a biblioteca novamente.
Se você tiver uma biblioteca que usa com frequência e quiser disponibilizá-la para todos os notebooks em seu espaço de trabalho, poderá usar um ambiente de Fabric para essa finalidade. Você pode criar um ambiente, instalar a biblioteca nele e, em seguida, o administrador do espaço de trabalho pode anexar o ambiente ao espaço de trabalho como seu ambiente padrão. Para obter mais informações sobre como definir um ambiente como padrão do espaço de trabalho, consulte Administrador define bibliotecas padrão para o espaço de trabalho.
Para obter informações sobre como migrar bibliotecas de espaço de trabalho existentes e propriedades do Spark para um ambiente, consulte Migrar bibliotecas de espaço de trabalho e propriedades do Spark para um ambiente padrão.
Carregar os dados
Antes de treinar qualquer modelo de machine learning, você precisa carregar a tabela delta do lakehouse para ler os dados limpos criados no bloco de anotações anterior.
import pandas as pd
SEED = 12345
df_clean = spark.read.format("delta").load("Tables/df_clean").toPandas()
Gerar experimento para rastrear e registrar o modelo usando MLflow
Esta seção demonstra como gerar um experimento, especificar o modelo de machine learning e os parâmetros de treinamento, bem como métricas de pontuação, treinar os modelos de aprendizado de máquina, registrá-los e salvar os modelos treinados para uso posterior.
import mlflow
# Setup experiment name
EXPERIMENT_NAME = "bank-churn-experiment" # MLflow experiment name
Ampliando as capacidades de registro automático do MLflow, o registro automático funciona capturando automaticamente os valores dos parâmetros de entrada e as métricas de saída de um modelo de machine learning à medida que ele está sendo treinado. Essas informações são então registradas em log no seu espaço de trabalho, na qual podem ser acessadas e visualizadas usando as APIs do MLflow ou o experimento correspondente no seu espaço de trabalho.
Todos os experimentos com seus respectivos nomes são registrados em log e você poderá acompanhar seus parâmetros e métricas de desempenho. Para obter mais informações sobre o registro Automático, consulte Registro Automático no Microsoft Fabric.
Definir especificações de experimento e registro automático
mlflow.set_experiment(EXPERIMENT_NAME)
mlflow.autolog(exclusive=False)
Importar o scikit-learn e o LightGBM
Com seus dados prontos, agora você pode definir os modelos de aprendizado de máquina. Você aplicará os modelos Random Forest e LightGBM neste notebook. Use scikit-learn e lightgbm para implementar os modelos em poucas linhas de código.
# Import the required libraries for model training
from sklearn.model_selection import train_test_split
from lightgbm import LGBMClassifier
from sklearn.ensemble import RandomForestClassifier
from sklearn.metrics import accuracy_score, f1_score, precision_score, confusion_matrix, recall_score, roc_auc_score, classification_report
Preparar conjuntos de dados de treinamento, validação e teste
Use a função train_test_split do scikit-learn para dividir os dados em conjuntos de treinamento, validação e teste.
y = df_clean["Exited"]
X = df_clean.drop("Exited",axis=1)
# Split the dataset to 60%, 20%, 20% for training, validation, and test datasets
# Train-Test Separation
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.20, random_state=SEED)
# Train-Validation Separation
X_train, X_val, y_train, y_val = train_test_split(X_train, y_train, test_size=0.25, random_state=SEED)
Salvar dados de teste em uma tabela delta
Salve os dados de teste na tabela delta para uso no próximo bloco de anotações.
table_name = "df_test"
# Create PySpark DataFrame from Pandas
df_test=spark.createDataFrame(X_test)
df_test.write.mode("overwrite").format("delta").save(f"Tables/{table_name}")
print(f"Spark test DataFrame saved to delta table: {table_name}")
Aplicar o SMOTE aos dados de treinamento para sintetizar novos exemplos para a classe minoritária
A exploração de dados na parte 2 mostrou que, dos 10.000 pontos de dados correspondentes a 10.000 clientes, apenas 2.037 clientes (cerca de 20%) deixaram o banco. Isso indica que o conjunto de dados está altamente desequilibrado. A classificação desequilibrada ocorre quando há poucos exemplos da classe minoritária para que um modelo aprenda efetivamente o limite de decisão. O SMOTE é a abordagem mais usada para sintetizar novos exemplos para a classe minoritária. Saiba mais sobre o SMOTE aqui e aqui.
Dica
Observe que o SMOTE só deve ser aplicado ao conjunto de dados de treinamento. Você deve deixar o conjunto de dados de teste em sua distribuição desbalanceada original para obter uma aproximação válida de como o modelo de machine learning será executado nos dados originais, que estão representando a situação em produção.
from collections import Counter
from imblearn.over_sampling import SMOTE
sm = SMOTE(random_state=SEED)
X_res, y_res = sm.fit_resample(X_train, y_train)
new_train = pd.concat([X_res, y_res], axis=1)
Dica
Você pode ignorar com segurança a mensagem de aviso MLflow que aparece quando você executa esta célula.
Se você vir uma mensagem ModuleNotFoundError, terá perdido a execução da primeira célula neste notebook, que instala a biblioteca imblearn. Você precisa instalar essa biblioteca toda vez que reiniciar o notebook. Volte e execute novamente todas as células começando com a primeira célula neste notebook.
Treinamento do modelo
- Treine o modelo usando Random Forest com profundidade máxima de 4 e 4 características
mlflow.sklearn.autolog(registered_model_name='rfc1_sm') # Register the trained model with autologging
rfc1_sm = RandomForestClassifier(max_depth=4, max_features=4, min_samples_split=3, random_state=1) # Pass hyperparameters
with mlflow.start_run(run_name="rfc1_sm") as run:
rfc1_sm_run_id = run.info.run_id # Capture run_id for model prediction later
print("run_id: {}; status: {}".format(rfc1_sm_run_id, run.info.status))
# rfc1.fit(X_train,y_train) # Imbalanaced training data
rfc1_sm.fit(X_res, y_res.ravel()) # Balanced training data
rfc1_sm.score(X_val, y_val)
y_pred = rfc1_sm.predict(X_val)
cr_rfc1_sm = classification_report(y_val, y_pred)
cm_rfc1_sm = confusion_matrix(y_val, y_pred)
roc_auc_rfc1_sm = roc_auc_score(y_res, rfc1_sm.predict_proba(X_res)[:, 1])
- Treine o modelo usando Random Forest com profundidade máxima de 8 e 6 características
mlflow.sklearn.autolog(registered_model_name='rfc2_sm') # Register the trained model with autologging
rfc2_sm = RandomForestClassifier(max_depth=8, max_features=6, min_samples_split=3, random_state=1) # Pass hyperparameters
with mlflow.start_run(run_name="rfc2_sm") as run:
rfc2_sm_run_id = run.info.run_id # Capture run_id for model prediction later
print("run_id: {}; status: {}".format(rfc2_sm_run_id, run.info.status))
# rfc2.fit(X_train,y_train) # Imbalanced training data
rfc2_sm.fit(X_res, y_res.ravel()) # Balanced training data
rfc2_sm.score(X_val, y_val)
y_pred = rfc2_sm.predict(X_val)
cr_rfc2_sm = classification_report(y_val, y_pred)
cm_rfc2_sm = confusion_matrix(y_val, y_pred)
roc_auc_rfc2_sm = roc_auc_score(y_res, rfc2_sm.predict_proba(X_res)[:, 1])
- Treinar o modelo usando LightGBM
# lgbm_model
mlflow.lightgbm.autolog(registered_model_name='lgbm_sm') # Register the trained model with autologging
lgbm_sm_model = LGBMClassifier(learning_rate = 0.07,
max_delta_step = 2,
n_estimators = 100,
max_depth = 10,
eval_metric = "logloss",
objective='binary',
random_state=42)
with mlflow.start_run(run_name="lgbm_sm") as run:
lgbm1_sm_run_id = run.info.run_id # Capture run_id for model prediction later
# lgbm_sm_model.fit(X_train,y_train) # Imbalanced training data
lgbm_sm_model.fit(X_res, y_res.ravel()) # Balanced training data
y_pred = lgbm_sm_model.predict(X_val)
accuracy = accuracy_score(y_val, y_pred)
cr_lgbm_sm = classification_report(y_val, y_pred)
cm_lgbm_sm = confusion_matrix(y_val, y_pred)
roc_auc_lgbm_sm = roc_auc_score(y_res, lgbm_sm_model.predict_proba(X_res)[:, 1])
Artefato de experimentos para acompanhar o desempenho do modelo
As execuções do experimento são salvas automaticamente no artefato do experimento que pode ser encontrado no espaço de trabalho. Eles são nomeados com base no nome utilizado para definir o experimento. Todos os modelos de aprendizado de máquina treinados, suas execuções, métricas de desempenho e parâmetros de modelo são registrados.
Para exibir seus experimentos:
No painel esquerdo, selecione seu espaço de trabalho.
No canto superior direito, filtre para mostrar apenas experimentos, para facilitar a localização do experimento que está procurando.
Encontre e selecione o nome do experimento, neste caso bank-churn-experiment. Se você não vir o experimento em seu workspace, atualize o navegador.
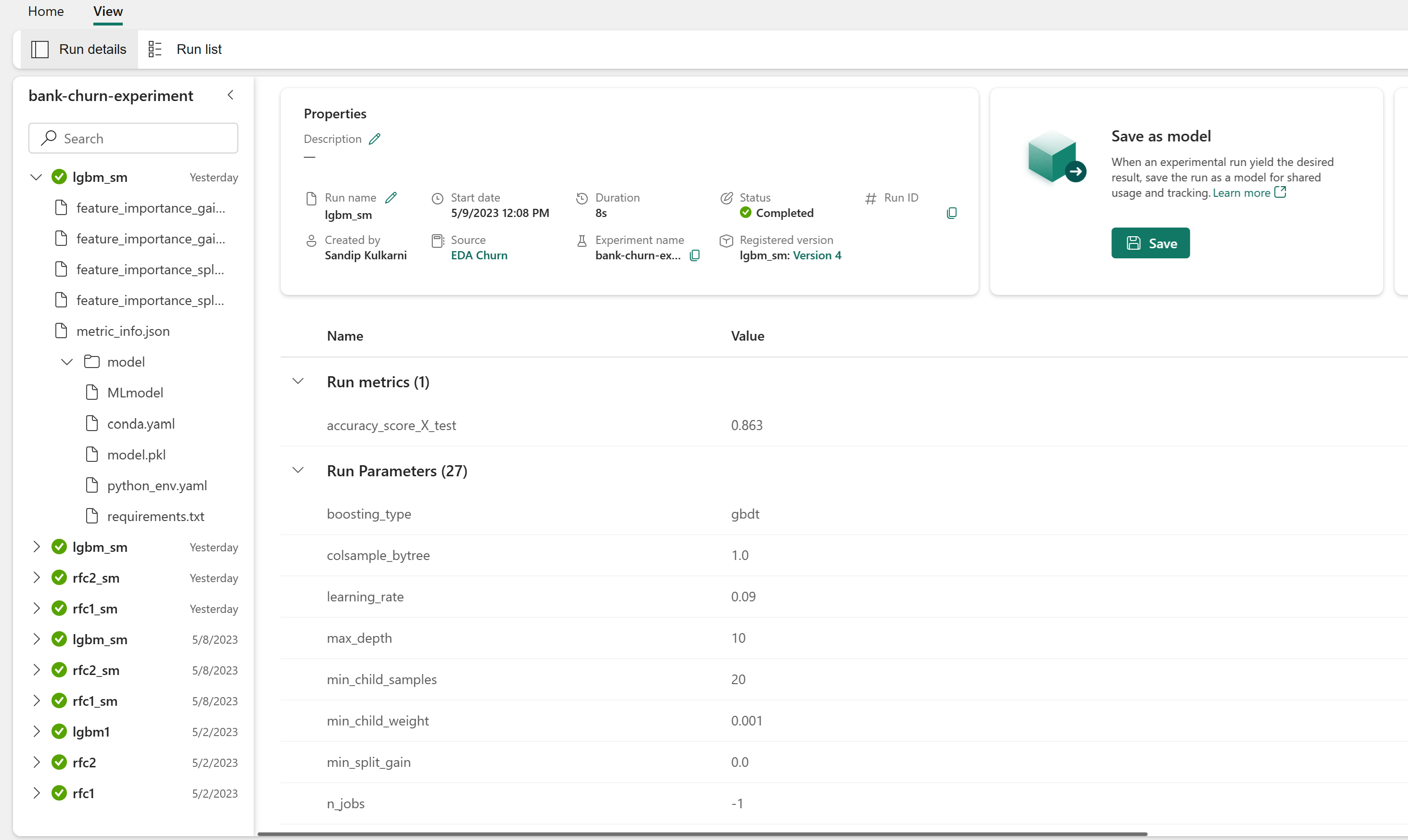


Avaliar o desempenho dos modelos treinados no conjunto de dados de validação
Uma vez feito o treinamento de modelo de machine learning, você pode avaliar o desempenho de modelos treinados de duas maneiras.
Abra o experimento salvo no espaço de trabalho, carregue os modelos de aprendizado de máquina e avalie o desempenho dos modelos carregados no conjunto de dados de validação.
# Define run_uri to fetch the model # mlflow client: mlflow.model.url, list model load_model_rfc1_sm = mlflow.sklearn.load_model(f"runs:/{rfc1_sm_run_id}/model") load_model_rfc2_sm = mlflow.sklearn.load_model(f"runs:/{rfc2_sm_run_id}/model") load_model_lgbm1_sm = mlflow.lightgbm.load_model(f"runs:/{lgbm1_sm_run_id}/model") # Assess the performance of the loaded model on validation dataset ypred_rfc1_sm_v1 = load_model_rfc1_sm.predict(X_val) # Random Forest with max depth of 4 and 4 features ypred_rfc2_sm_v1 = load_model_rfc2_sm.predict(X_val) # Random Forest with max depth of 8 and 6 features ypred_lgbm1_sm_v1 = load_model_lgbm1_sm.predict(X_val) # LightGBMAvalie diretamente o desempenho dos modelos de aprendizado de máquina treinados no conjunto de dados de validação.
ypred_rfc1_sm_v2 = rfc1_sm.predict(X_val) # Random Forest with max depth of 4 and 4 features ypred_rfc2_sm_v2 = rfc2_sm.predict(X_val) # Random Forest with max depth of 8 and 6 features ypred_lgbm1_sm_v2 = lgbm_sm_model.predict(X_val) # LightGBM
Dependendo da sua preferência, qualquer uma das abordagens é boa e deve oferecer desempenhos idênticos. Neste bloco de anotações, você escolherá a primeira abordagem para demonstrar melhor os recursos de log automático do MLflow no Microsoft Fabric.
Mostrar Verdadeiros/Falsos Positivos/Negativos usando a Matriz de Confusão
Em seguida, você desenvolverá um script para plotar a matriz de confusão a fim de avaliar a precisão da classificação usando o conjunto de dados de validação. A matriz de confusão também pode ser plotada usando as ferramentas SynapseML, que é mostrada no exemplo de detecção de fraude que está disponível aqui.
import seaborn as sns
sns.set_theme(style="whitegrid", palette="tab10", rc = {'figure.figsize':(9,6)})
import matplotlib.pyplot as plt
import matplotlib.ticker as mticker
from matplotlib import rc, rcParams
import numpy as np
import itertools
def plot_confusion_matrix(cm, classes,
normalize=False,
title='Confusion matrix',
cmap=plt.cm.Blues):
print(cm)
plt.figure(figsize=(4,4))
plt.rcParams.update({'font.size': 10})
plt.imshow(cm, interpolation='nearest', cmap=cmap)
plt.title(title)
plt.colorbar()
tick_marks = np.arange(len(classes))
plt.xticks(tick_marks, classes, rotation=45, color="blue")
plt.yticks(tick_marks, classes, color="blue")
fmt = '.2f' if normalize else 'd'
thresh = cm.max() / 2.
for i, j in itertools.product(range(cm.shape[0]), range(cm.shape[1])):
plt.text(j, i, format(cm[i, j], fmt),
horizontalalignment="center",
color="red" if cm[i, j] > thresh else "black")
plt.tight_layout()
plt.ylabel('True label')
plt.xlabel('Predicted label')
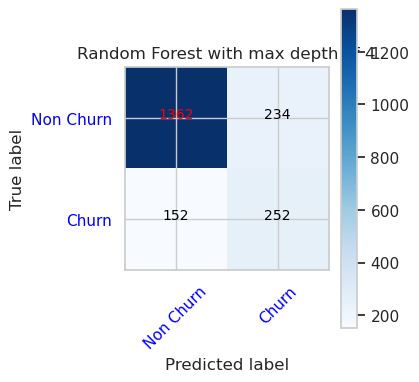
- Recursos da Matriz de Confusão para Classificador de Florestas Aleatórias com profundidade máxima de 4 e 4
cfm = confusion_matrix(y_val, y_pred=ypred_rfc1_sm_v1)
plot_confusion_matrix(cfm, classes=['Non Churn','Churn'],
title='Random Forest with max depth of 4')
tn, fp, fn, tp = cfm.ravel()
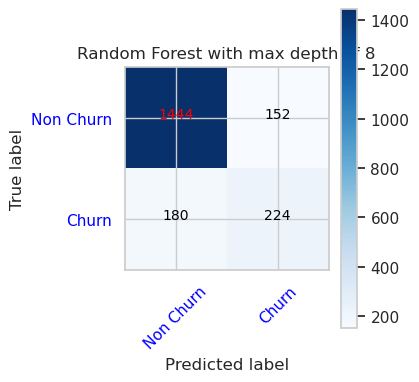
- Recursos da Matriz de Confusão para Classificador de Floresta Aleatória com profundidade máxima de 8 e 6
cfm = confusion_matrix(y_val, y_pred=ypred_rfc2_sm_v1)
plot_confusion_matrix(cfm, classes=['Non Churn','Churn'],
title='Random Forest with max depth of 8')
tn, fp, fn, tp = cfm.ravel()
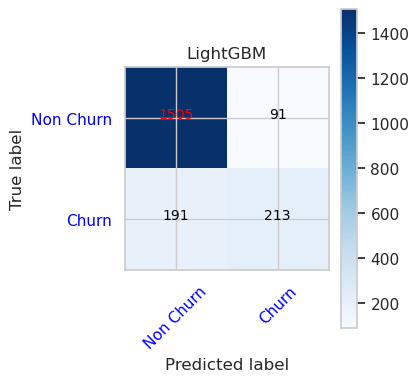
- Matriz de confusão para LightGBM
cfm = confusion_matrix(y_val, y_pred=ypred_lgbm1_sm_v1)
plot_confusion_matrix(cfm, classes=['Non Churn','Churn'],
title='LightGBM')
tn, fp, fn, tp = cfm.ravel()