Gerenciar bibliotecas do Apache Spark no Microsoft Fabric
Uma biblioteca é uma coleção de códigos pré-escritos que os desenvolvedores podem importar para fornecer funcionalidade. Ao usar bibliotecas, você pode economizar tempo e esforço por não precisar escrever código do zero para realizar tarefas comuns. Em vez disso, importe a biblioteca e use suas funções e classes para obter a funcionalidade desejada. O Microsoft Fabric fornece vários mecanismos para ajudá-lo a gerenciar e usar as bibliotecas.
- Bibliotecas internas: cada runtime do Spark do Fabric fornece um conjunto avançado de bibliotecas pré-instaladas populares. Você pode encontrar a lista completa de bibliotecas internas no Runtime do Spark do Fabric.
- Biblioteca pública: bibliotecas públicas são provenientes de repositórios como PyPI e Conda, que têm suporte no momento.
- Bibliotecas personalizadas: bibliotecas personalizadas referem-se ao código que você ou sua organização criam. O Fabric oferece suporte a eles nos formatos .whl, .jar e .tar.gz. O Fabric oferece suporte para .tar.gz somente para a linguagem R. Para bibliotecas personalizadas do Python, use o formato .whl.
Resumo do gerenciamento de bibliotecas e melhores práticas
Os cenários a seguir descrevem as práticas recomendadas ao usar bibliotecas no Microsoft Fabric.
Cenário 1: o administrador define bibliotecas padrão para o espaço de trabalho
Para definir bibliotecas padrão, você precisa ser o administrador do espaço de trabalho. Como administrador, você pode executar estas tarefas:
- Criar um novo ambiente
- Instale as bibliotecas necessárias no ambiente
- Anexe esse ambiente como o espaço de trabalho padrão
Quando seus notebooks e definições de trabalho do Spark são anexados às Configurações do Workspace, eles iniciam sessões com as bibliotecas instaladas no ambiente padrão do workspace.
Cenário 2: manter especificações de biblioteca para um ou vários itens de código
Se você tem bibliotecas comuns para diferentes itens de código e não precisa de atualizações frequentes, instalar as bibliotecas em um ambiente e anexá-las aos itens de código é uma boa escolha.
Levará algum tempo para que as bibliotecas nos ambientes se tornem efetivas na publicação. Normalmente leva de 5 a 15 minutos, dependendo da complexidade das bibliotecas. Durante esse processo, o sistema ajudará a resolver possíveis conflitos e baixar as dependências necessárias.
Um benefício dessa abordagem é que as bibliotecas instaladas com sucesso estarão disponíveis quando a sessão do Spark for iniciada com o ambiente anexado. Isso economiza esforço de manutenção de bibliotecas comuns para seus projetos.
É altamente recomendado para cenários de pipeline devido à sua estabilidade.
Cenário 3: instalação em linha em execução interativa
Se você estiver usando os notebooks para escrever código interativamente, usar a instalação inline para adicionar novas bibliotecas PyPI/conda ou validar suas bibliotecas personalizadas para uso único é a melhor prática. Os comandos inline no Fabric permitem que você tenha a biblioteca em vigor na sessão atual do Spark no notebook. Ele permite a instalação rápida, mas a biblioteca instalada não persiste em sessões diferentes.
Como %pip install geram diferentes árvores de dependência de tempos em tempos, o que pode levar a conflitos de biblioteca, os comandos inline são desativados por padrão nas execuções do pipeline e NÃO são recomendados para uso em seus pipelines.
Resumo dos tipos de biblioteca com suporte
| Tipo de biblioteca | Gerenciamento de bibliotecas de ambiente | Instalação embutida |
|---|---|---|
| Python Public (PyPI e Conda) | Com suporte | Com suporte |
| Python Personalizado (.whl) | Com suporte | Com suporte |
| R Public (CRAN) | Sem suporte | Com suporte |
| R personalizado (.tar.gz) | Com suporte como biblioteca personalizada | Com suporte |
| Jar | Com suporte como biblioteca personalizada | Com suporte |
Instalação embutida
Os comandos embutidos oferecem suporte ao gerenciamento de bibliotecas em cada sessão de notebook.
Instalação embutida do Python
O sistema reinicia o interpretador Python para aplicar a alteração de bibliotecas. Todas as variáveis definidas antes de executar a célula de comando serão perdidas. Recomendamos fortemente que você coloque todos os comandos para adicionar, excluir ou atualizar pacotes Python no início do seu notebook.
Os comandos embutidos para gerenciar bibliotecas Python são desabilitados na execução de pipeline do notebook por padrão. Se você quiser habilitar o %pip install para o pipeline, adicione "_inlineInstallationEnabled" como parâmetro bool igual a True nos parâmetros de atividade do notebook.
Observação
O %pip install pode levar a resultados divergentes de vez em quando. É recomendável instalar a biblioteca em um ambiente e usá-la no pipeline.
Em execuções de referência do notebook, não são aceitos comandos embutidos para gerenciar bibliotecas Python. Para garantir a exatidão da execução, recomenda-se remover esses comandos embutidos do notebook referenciado.
Recomendamos %pip em vez de !pip. !pip é um comando de shell interno do IPython que tem as seguintes limitações:
!pipinstala apenas um pacote no nó do driver, não nos nós do executor.- Os pacotes que são instalados por meio do
!pipnão afetam os conflitos com os pacotes incorporados ou se os pacotes já estão importados em um notebook.
No entanto, o %pip lida com esses cenários. As bibliotecas instaladas por meio do %pip estão disponíveis nos nós do driver e do executor e ainda são efetivas mesmo que a biblioteca já tenha sido importada.
Dica
O comando %conda install geralmente leva mais tempo do que o comando %pip install para instalar novas bibliotecas do Python. Ele verifica as dependências completas e resolve conflitos.
Talvez você queira usar %conda install para obter mais confiabilidade e estabilidade. Você pode usar %pip install install se tiver certeza de que a biblioteca que deseja instalar não está em conflito com as bibliotecas pré-instaladas no ambiente de runtime.
Para obter todos os comandos em linha do Python disponíveis e esclarecimentos, consulte comandos %pip e comandos %conda.
Gerenciar bibliotecas personalizadas do Python por meio da instalação embutida
Neste exemplo, veja como usar comandos inline para gerenciar bibliotecas. Suponha que você queira usar altair, uma poderosa biblioteca de visualização para Python, para uma exploração de dados única. Suponha que a biblioteca não esteja instalada em seu workspace. O exemplo a seguir usa comandos conda para ilustrar as etapas.
Você pode usar comandos em linha para habilitar o altair em sua sessão de notebook sem afetar outras sessões do notebook ou outros itens.
Execute os seguintes comandos em uma célula de código do notebook. O primeiro comando instala a biblioteca altair. Além disso, instale vega_datasets, que contém um modelo semântico que você pode usar para visualizar.
%conda install altair # install latest version through conda command %conda install vega_datasets # install latest version through conda commandA saída da célula indica o resultado da instalação.
Importe o pacote e o modelo semântico executando os seguintes códigos em outra célula do notebook:
import altair as alt from vega_datasets import dataAgora você pode brincar com a biblioteca altair com escopo de sessão:
# load a simple dataset as a pandas DataFrame cars = data.cars() alt.Chart(cars).mark_point().encode( x='Horsepower', y='Miles_per_Gallon', color='Origin', ).interactive()
Gerenciar bibliotecas personalizadas do Python por meio da instalação embutida
Você pode carregar suas bibliotecas personalizadas do Python para a pasta de recursos do seu notebook ou para o ambiente anexado. As pastas de recursos são o sistema de arquivos integrado fornecido por cada notebook e ambiente. Veja Recursos do Notebook para mais detalhes. Após o upload, você pode arrastar e soltar a biblioteca personalizada em uma célula de código; o comando embutido para instalar a biblioteca será gerado automaticamente. Ou você pode usar o seguinte comando para instalar.
# install the .whl through pip command from the notebook built-in folder
%pip install "builtin/wheel_file_name.whl"
Instalação embutida R
Para gerenciar bibliotecas do R, o Fabric oferece suporte a comandos install.packages(), remove.packages() e devtools::. Para obter todos os comandos embutidos do R disponíveis e esclarecimentos, consulte o comando install.packages e o comando remove.package.
Gerenciar bibliotecas públicas do R por meio da instalação embutida
Siga este exemplo para percorrer as etapas de instalação de uma biblioteca pública do R:
Para instalar uma biblioteca de feeds do R:
Alterne o idioma de trabalho para SparkR(R) na faixa de opções do notebook.
Instale a biblioteca caesar executando o seguinte comando em uma célula do notebook.
install.packages("caesar")Agora você pode brincar com a biblioteca caesar no escopo da sessão com o trabalho do Spark.
library(SparkR) sparkR.session() hello <- function(x) { library(caesar) caesar(x) } spark.lapply(c("hello world", "good morning", "good evening"), hello)
Gerenciar bibliotecas Jar por meio da instalação embutida
Os arquivos .jar são suportados em sessões de bloco de anotações com o seguinte comando.
%%configure -f
{
"conf": {
"spark.jars": "abfss://<<Lakehouse prefix>>.dfs.fabric.microsoft.com/<<path to JAR file>>/<<JAR file name>>.jar",
}
}
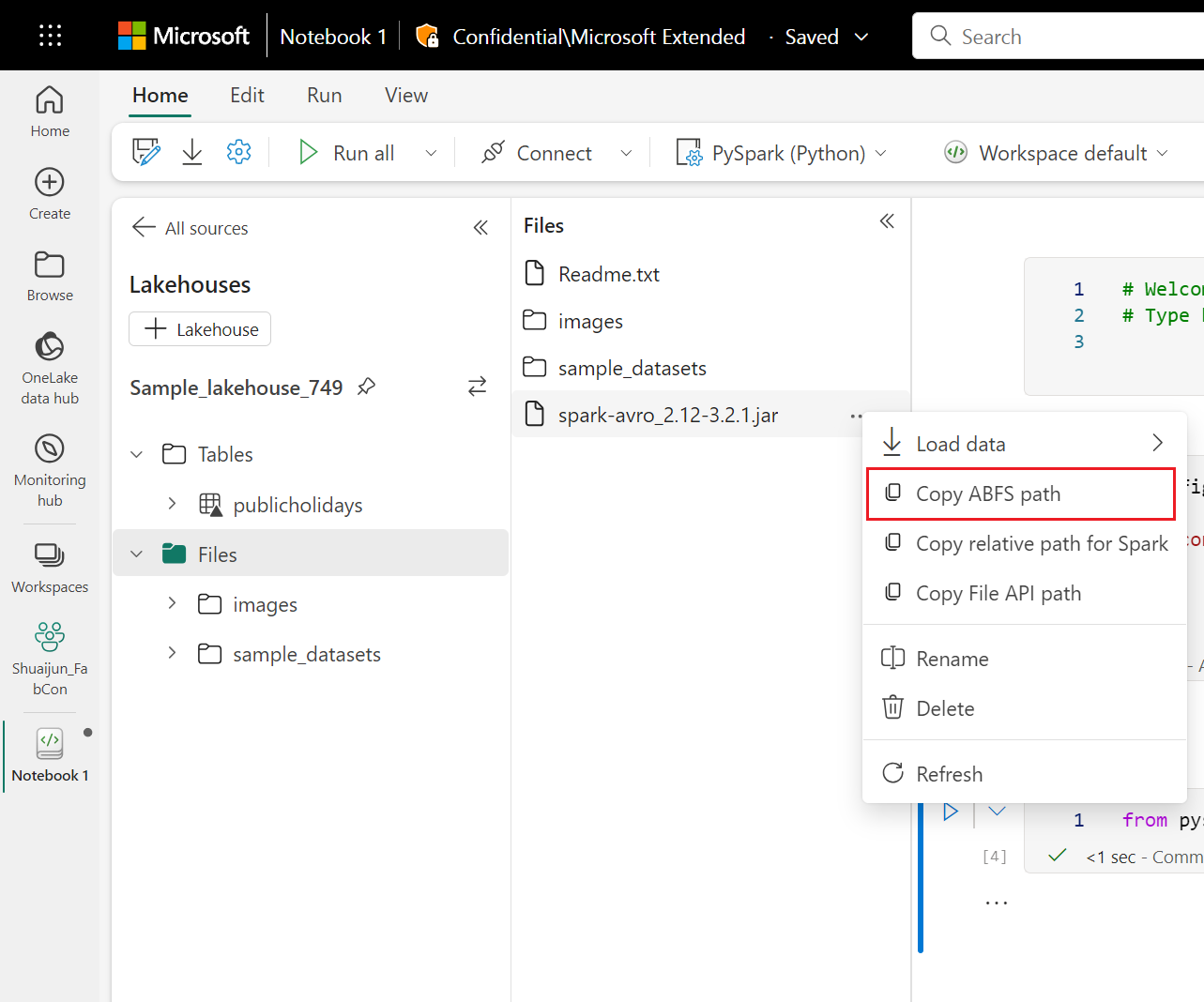
A célula de código está usando o armazenamento do Lakehouse como exemplo. No explorador de blocos de anotações, você pode copiar o caminho ABFS completo do arquivo e substituí-lo no código.