Usar Tidyverse
O Tidyverse é uma coleção de pacotes R que os cientistas de dados normalmente usam em análises de dados diárias. Ele inclui pacotes para importação de dados (readr), visualização de dados (ggplot2), manipulação de dados (dplyr, tidyr), programação funcional (purrr) e criação de modelos (tidymodels) etc. Os pacotes em tidyverse são projetados para trabalhar juntos perfeitamente e seguir um conjunto consistente de princípios de design.
O Microsoft Fabric distribui a versão estável mais recente do tidyverse a cada lançamento do runtime. Importe e comece a usar seus pacotes de R familiares.
Pré-requisitos
Obtenha uma assinatura do Microsoft Fabric. Ou, inscreva-se para uma avaliação gratuita do Microsoft Fabric.
Entre no Microsoft Fabric.
Use o alternador de experiência no lado esquerdo da sua página inicial para mudar para a experiência de Ciência de Dados Synapse.
Abrir ou criar um notebook. Para saber como, consulte Como usar notebooks do Microsoft Fabric.
Defina a opção de idioma para SparkR (R) para mudar o idioma principal.
Anexe o notebook a um lakehouse. No lado esquerdo, selecione Adicionar para adicionar um lakehouse existente ou para criar um.
Carregar tidyverse
# load tidyverse
library(tidyverse)
Importação de dados
O readr é um pacote R que fornece ferramentas para ler arquivos de dados retangulares, como CSV, TSV e arquivos de largura fixa. O readr fornece uma maneira rápida e amigável de ler arquivos de dados retangulares, como fornecer funções read_csv() e read_tsv() ler arquivos CSV e TSV, respectivamente.
Primeiro, vamos criar um data.frame do R, gravá-lo no Lakehouse usando readr::write_csv() e lê-lo novamente com readr::read_csv().
Observação
Para acessar arquivos do Lakehouse usando readr, você precisa usar o caminho da API de Arquivo. No Gerenciador do Lakehouse, clique com o botão direito do mouse no arquivo ou pasta que você deseja acessar e copie o caminho da API de Arquivo no menu contextual.
# create an R data frame
set.seed(1)
stocks <- data.frame(
time = as.Date('2009-01-01') + 0:9,
X = rnorm(10, 20, 1),
Y = rnorm(10, 20, 2),
Z = rnorm(10, 20, 4)
)
stocks
Em seguida, vamos gravar os dados no Lakehouse usando o caminho da API de Arquivo.
# write data to lakehouse using the File API path
temp_csv_api <- "/lakehouse/default/Files/stocks.csv"
readr::write_csv(stocks,temp_csv_api)
Leia os dados do Lakehouse.
# read data from lakehouse using the File API path
stocks_readr <- readr::read_csv(temp_csv_api)
# show the content of the R date.frame
head(stocks_readr)
Limpeza de dados
O tidyr é um pacote R que fornece ferramentas para trabalhar com dados confusos. As principais funções no tidyr foram projetadas para ajudá-lo a remodelar os dados em um formato arrumado. A opção Limpar dados têm uma estrutura específica em que cada variável é uma coluna e cada observação é uma linha, o que facilita o trabalho com dados no R e em outras ferramentas.
Por exemplo, a função gather() em tidyr pode ser usada para converter dados amplos em dados longos. Veja um exemplo:
# convert the stock data into longer data
library(tidyr)
stocksL <- gather(data = stocks, key = stock, value = price, X, Y, Z)
stocksL
Programação funcional
O purrr é um pacote R que aprimora o kit de ferramentas de programação funcional do R fornecendo um conjunto completo e consistente de ferramentas para trabalhar com funções e vetores. O melhor lugar para começar nopurrr é a família de funções map() que permitem substituir muitos loops for por um código mais sucinto e mais fácil de ler. Aqui está um exemplo de como usar map() para aplicar uma função a cada elemento de uma lista:
# double the stock values using purrr
library(purrr)
stocks_double = map(stocks %>% select_if(is.numeric), ~.x*2)
stocks_double
Manipulação de dados
O dplyr é um pacote R que fornece um conjunto consistente de verbos que ajudam a resolver os problemas mais comuns de manipulação de dados, como selecionar variáveis com base nos nomes, escolher casos com base nos valores, reduzir vários valores para um único resumo e alterar a ordenação das linhas etc. Aqui estão alguns exemplos:
# pick variables based on their names using select()
stocks_value <- stocks %>% select(X:Z)
stocks_value
# pick cases based on their values using filter()
filter(stocks_value, X >20)
# add new variables that are functions of existing variables using mutate()
library(lubridate)
stocks_wday <- stocks %>%
select(time:Z) %>%
mutate(
weekday = wday(time)
)
stocks_wday
# change the ordering of the rows using arrange()
arrange(stocks_wday, weekday)
# reduce multiple values down to a single summary using summarise()
stocks_wday %>%
group_by(weekday) %>%
summarize(meanX = mean(X), n= n())
Visualização de dados
O ggplot2 é um pacote R para criar gráficos declarativamente, com base na Gramática dos Gráficos. Você fornece os dados, informa ggplot2 como mapear variáveis para a estética, quais primitivos gráficos usar e cuida dos detalhes. Estes são alguns exemplos:
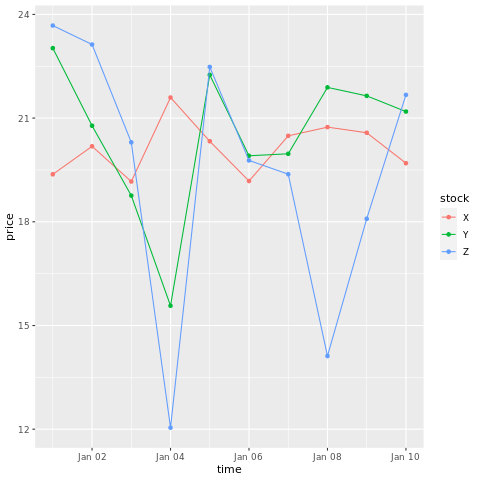
# draw a chart with points and lines all in one
ggplot(stocksL, aes(x=time, y=price, colour = stock)) +
geom_point()+
geom_line()
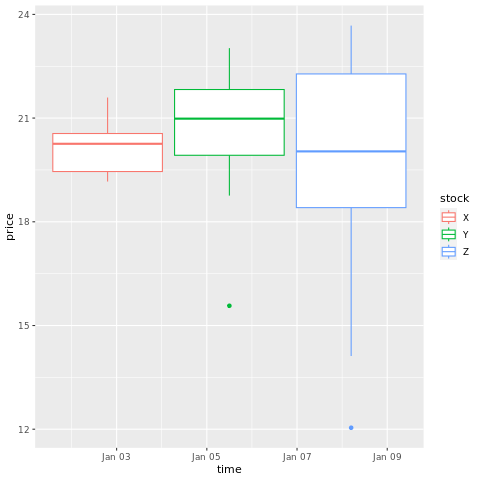
# draw a boxplot
ggplot(stocksL, aes(x=time, y=price, colour = stock)) +
geom_boxplot()
Criação de modelo
A estrutura tidymodels é uma coleção de pacotes para modelagem e aprendizado de máquina usando os princípios do tidyverse. Ele aborda uma lista de pacotes principais para uma ampla variedade de tarefas de criação de modelo, como rsample para divisão de amostra de conjunto de dados de treinamento/teste, parsnip para especificação de modelo, recipes para pré-processamento de dados, workflows para modelagem de fluxos de trabalho, tune para ajuste de hiperparâmetros, yardstick para avaliação de modelo, broom para definição de saídas de modelo e dials para gerenciamento de parâmetros de ajuste. Você pode saber mais sobre os pacotes visitando o site tidymodels. Aqui está um exemplo de criação de um modelo de regressão linear para prever as milhas por galão (mpg) de um carro com base em seu peso (wt):
# look at the relationship between the miles per gallon (mpg) of a car and its weight (wt)
ggplot(mtcars, aes(wt,mpg))+
geom_point()
Na dispersão, a relação parece aproximadamente linear e a variação parece constante. Vamos tentar modelar isso usando regressão linear.
library(tidymodels)
# split test and training dataset
set.seed(123)
split <- initial_split(mtcars, prop = 0.7, strata = "cyl")
train <- training(split)
test <- testing(split)
# config the linear regression model
lm_spec <- linear_reg() %>%
set_engine("lm") %>%
set_mode("regression")
# build the model
lm_fit <- lm_spec %>%
fit(mpg ~ wt, data = train)
tidy(lm_fit)
Aplique o modelo de regressão linear para prever no conjunto de dados de teste.
# using the lm model to predict on test dataset
predictions <- predict(lm_fit, test)
predictions
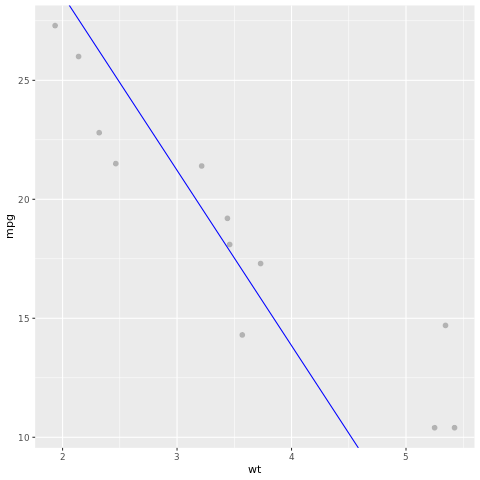
Vamos dar uma olhada no resultado do modelo. Podemos desenhar o modelo como um gráfico de linhas e os dados de verdade do campo de teste como pontos no mesmo gráfico. O modelo parece bom.
# draw the model as a line chart and the test data groundtruth as points
lm_aug <- augment(lm_fit, test)
ggplot(lm_aug, aes(x = wt, y = mpg)) +
geom_point(size=2,color="grey70") +
geom_abline(intercept = lm_fit$fit$coefficients[1], slope = lm_fit$fit$coefficients[2], color = "blue")