Tutorial: usar o R para prever o atraso de um voo
Este tutorial apresenta um exemplo de ponta a ponta de um fluxo de trabalho da Ciência de Dados do Synapse no Microsoft Fabric. Ele usa os dados de nycflights13 , e R, para prever se um avião chega mais de 30 minutos atrasado. Ele então usa os resultados da previsão para criar um dashboard interativo do Power BI.
Neste tutorial, você aprenderá a:
- Use pacotes tidymodels (receitas, parsnip, rsample, fluxos de trabalho) para processar dados e treinar um modelo de machine learning
- Escreva os dados de saída no lakehouse como uma tabela delta
- Crie um relatório visual do Power BI para acessar diretamente os dados no lakehouse
Pré-requisitos
Obtenha uma assinatura do Microsoft Fabric. Ou, inscreva-se para uma avaliação gratuita do Microsoft Fabric.
Entre no Microsoft Fabric.
Use o seletor de experiência no lado esquerdo da sua página inicial para alternar para a experiência de Ciência de Dados do Synapse.
Abrir ou criar um notebook. Para saber como, consulte Como usar notebooks do Microsoft Fabric.
Defina a opção de idioma para SparkR (R) para mudar o idioma principal.
Anexe seu bloco de anotações a um lakehouse. No lado esquerdo, selecione Adicionar para adicionar um lakehouse existente ou para criar um.
Instalar Pacotes
Instale o pacote nycflights13 para usar o código neste tutorial.
install.packages("nycflights13")
# Load the packages
library(tidymodels) # For tidymodels packages
library(nycflights13) # For flight data
Explorar os dados
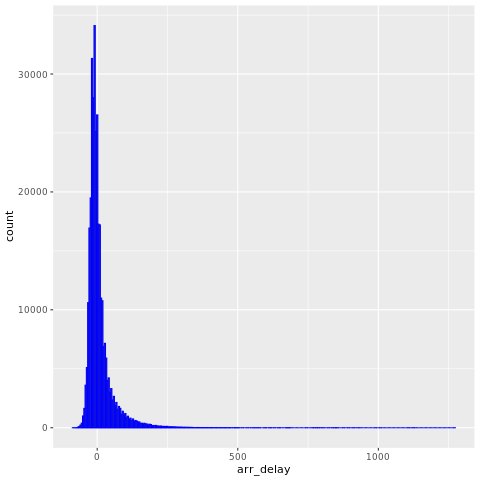
Os dados do nycflights13 possuem informações sobre 325.819 voos que chegaram perto de Nova York em 2013. Primeiro, veja a distribuição dos atrasos de voo. Este gráfico mostra que a distribuição dos atrasos de chegada está inclinada para a direita. Tem uma cauda longa nos valores altos.
ggplot(flights, aes(arr_delay)) + geom_histogram(color="blue", bins = 300)
Carregue os dados e faça algumas alterações nas variáveis:
set.seed(123)
flight_data <-
flights %>%
mutate(
# Convert the arrival delay to a factor
arr_delay = ifelse(arr_delay >= 30, "late", "on_time"),
arr_delay = factor(arr_delay),
# You'll use the date (not date-time) for the recipe that you'll create
date = lubridate::as_date(time_hour)
) %>%
# Include weather data
inner_join(weather, by = c("origin", "time_hour")) %>%
# Retain only the specific columns that you'll use
select(dep_time, flight, origin, dest, air_time, distance,
carrier, date, arr_delay, time_hour) %>%
# Exclude missing data
na.omit() %>%
# For creating models, it's better to have qualitative columns
# encoded as factors (instead of character strings)
mutate_if(is.character, as.factor)
Antes de construir o modelo, considere algumas variáveis específicas que são importantes para o pré-processamento e a modelagem.
Variável arr_delay é uma variável de fator. Para treinar um modelo de regressão logística é importante que sua variável de resultado seja uma variável de fator.
glimpse(flight_data)
Cerca de 16% dos voos neste conjunto de dados chegaram com mais de 30 minutos de atraso.
flight_data %>%
count(arr_delay) %>%
mutate(prop = n/sum(n))
O recurso dest conta com 104 destinos de voos.
unique(flight_data$dest)
Há 16 operadoras distintas.
unique(flight_data$carrier)
Dividir os dados
Divida esse único conjunto de dados em dois conjuntos: um conjunto de treinamento e um de testes . Mantenha a maioria das linhas no conjunto de dados original (como um subconjunto escolhido aleatoriamente) no conjunto de dados de treinamento. Use o conjunto de dados de treinamento para se ajustar ao modelo e o conjunto de dados de testes é usado para medir o desempenho do modelo.
Use o pacote rsample para criar um objeto que contém informações sobre como dividir os dados. Em seguida, use mais duas funções rsample para criar DataFrames para os conjuntos de treinamento e teste:
set.seed(123)
# Keep most of the data in the training set
data_split <- initial_split(flight_data, prop = 0.75)
# Create DataFrames for the two sets:
train_data <- training(data_split)
test_data <- testing(data_split)
Crie uma receita e funções
Crie uma receita para um modelo de regressão logística simples. Antes de treinar o modelo, use uma receita para criar novos preditores e realizar o pré-processamento que o modelo exige.
Use a função update_role() para que as receitas saibam que flight e time_hour são variáveis, com uma função personalizada chamada ID. Uma função pode ter qualquer valor de caractere. A fórmula inclui todas as variáveis no conjunto de treinamento, com exceção de arr_delay, como preditores. A receita mantém essas duas variáveis de ID, mas não as usa como resultados ou preditores.
flights_rec <-
recipe(arr_delay ~ ., data = train_data) %>%
update_role(flight, time_hour, new_role = "ID")
Para exibir o conjunto atual de variáveis e funções, use a função summary():
summary(flights_rec)
Criar recursos
Execute alguma engenharia de recursos para melhorar seu modelo. A data do seu voo talvez afete a probabilidade de um atraso na chegada.
flight_data %>%
distinct(date) %>%
mutate(numeric_date = as.numeric(date))
Talvez ajude ao adicionar termos de modelo derivados de datas que potencialmente tenham importância para o modelo. Derive os seguintes recursos significativos de uma única variável de data:
- Dia da semana
- Mensal
- Se a data corresponde ou não a um feriado
Adicione as três etapas à sua receita:
flights_rec <-
recipe(arr_delay ~ ., data = train_data) %>%
update_role(flight, time_hour, new_role = "ID") %>%
step_date(date, features = c("dow", "month")) %>%
step_holiday(date,
holidays = timeDate::listHolidays("US"),
keep_original_cols = FALSE) %>%
step_dummy(all_nominal_predictors()) %>%
step_zv(all_predictors())
Ajuste um modelo com uma receita
Use regressão logística para modelar os dados de voo. Primeiro, crie uma especificação de modelo com o pacote parsnip:
lr_mod <-
logistic_reg() %>%
set_engine("glm")
Use o pacote workflows para agrupar seu modelo parsnip (lr_mod) com sua receita (flights_rec):
flights_wflow <-
workflow() %>%
add_model(lr_mod) %>%
add_recipe(flights_rec)
flights_wflow
Treinar o modelo
Esta função pode preparar a receita e treinar o modelo dos preditores resultantes:
flights_fit <-
flights_wflow %>%
fit(data = train_data)
Use as funções auxiliares xtract_fit_parsnip() e extract_recipe() para extrair os objetos de modelo ou receita do fluxo de trabalho. Neste exemplo, efetue o pull do objeto de modelo ajustado e, em seguida, use a função broom::tidy() para obter um tibble organizado dos coeficientes de modelo:
flights_fit %>%
extract_fit_parsnip() %>%
tidy()
Prever resultados
Uma chamada única para predict() usa o fluxo de trabalho treinado (flights_fit) para fazer previsões com os dados de teste não vistos. O método predict() aplica a receita aos novos dados e passa os resultados para o modelo ajustado.
predict(flights_fit, test_data)
Obter a saída de predict() para retornar a classe prevista: late versus on_time. No entanto, para as probabilidades de classe previstas para cada voo, use augment() com o modelo, agrupados com os dados de teste, para salvá-los juntos:
flights_aug <-
augment(flights_fit, test_data)
Examinar os dados:
glimpse(flights_aug)
Avaliar o modelo
Agora temos um tibble com as probabilidades de classe previstas. Nas primeiras linhas, o modelo previu corretamente cinco voos pontuais (valores de .pred_on_time são p > 0.50). No entanto, temos 81.455 linhas no total para prever.
Precisamos de uma métrica que informe o quão bem o modelo previu as chegadas atrasadas, em comparação com o verdadeiro status da variável de resultado, arr_delay.
Usar a AUC-ROC (área embaixo da Curva de Característica Operacional do Receptor) como a métrica. Computar com roc_curve() e roc_auc(), a partir do pacote yardstick:
flights_aug %>%
roc_curve(truth = arr_delay, .pred_late) %>%
autoplot()
Gerar um relatório do Power BI
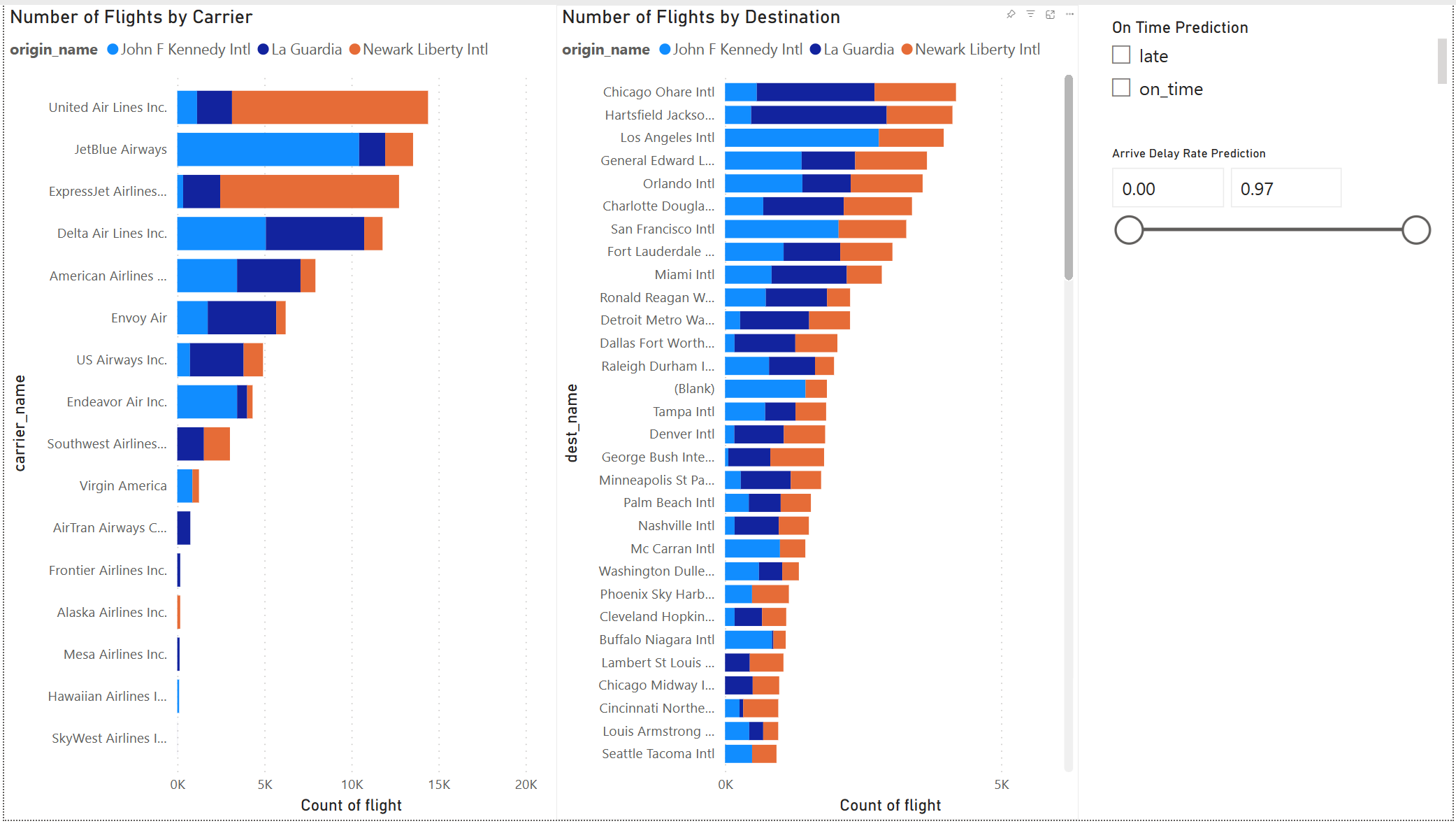
O resultado do modelo parece bom. Usar os resultados da previsão para criar um dashboard interativo do Power BI. O dashboard mostra o número de voos por companhia aérea e o número de voos por destino. O dashboard pode filtrar pelos resultados da previsão de atraso.
Incluir o nome da companhia e o nome do aeroporto para o conjunto de dados do resultado da previsão:
flights_clean <- flights_aug %>%
# Include the airline data
left_join(airlines, c("carrier"="carrier"))%>%
rename("carrier_name"="name") %>%
# Include the airport data for origin
left_join(airports, c("origin"="faa")) %>%
rename("origin_name"="name") %>%
# Include the airport data for destination
left_join(airports, c("dest"="faa")) %>%
rename("dest_name"="name") %>%
# Retain only the specific columns you'll use
select(flight, origin, origin_name, dest,dest_name, air_time,distance, carrier, carrier_name, date, arr_delay, time_hour, .pred_class, .pred_late, .pred_on_time)
Examinar os dados:
glimpse(flights_clean)
Converter os dados para um dataframe do Spark:
sparkdf <- as.DataFrame(flights_clean)
display(sparkdf)
Gravar os dados em uma tabela delta em seu lakehouse:
# Write data into a delta table
temp_delta<-"Tables/nycflight13"
write.df(sparkdf, temp_delta ,source="delta", mode = "overwrite", header = "true")
Usar a tabela delta para criar um modelo semântico.
À esquerda, selecione Hub de dados do OneLake
Selecionar o Lakehouse que você anexou ao notebook
Selecionar Abrir
Selecionar Novos modelos semânticos
Selecionar nycflight13 para o novo modelo semântico e, em seguida, selecionar Confirmar
Seu modelo semântico foi criado. Selecionar Novo relatório
Selecionar ou arrastar os campos dos painéis de Dados e Visualizações para a tela do relatório para criar seu relatório
Para criar o relatório mostrado no início desta seção, use essas visualizações e dados:
 Gráfico de barras empilhadas com:
Gráfico de barras empilhadas com:- Eixo Y: carrier_name
- Eixo X: voo. Selecione Contagem para a agregação
- Legenda: origin_name
- Gráfico de barras empilhadas com:
- Eixo Y: dest_name
- Eixo X: voo. Selecione Contagem para a agregação
- Legenda: origin_name
 Segmentação com:
Segmentação com:- Campo: _pred_class
- Segmentação com:
- Campo: _pred_late