Tutorial: Usar o R para prever os preços do abacate
Este tutorial apresenta um exemplo de ponta a ponta de um fluxo de trabalho da Ciência de Dados do Synapse no Microsoft Fabric. Ele usa o R para analisar e visualizar os preços do abacate nos Estados Unidos, para construir um modelo de machine learning que prevê os preços futuros do abacate.
Este tutorial cobre estas etapas:
- Carregar bibliotecas padrão
- Carregar os dados
- Personalizar os dados
- Adicionar novos pacotes à sessão
- Analise e visualize os dados.
- Treinar o modelo

Pré-requisitos
Obtenha uma assinatura do Microsoft Fabric. Ou, inscreva-se para uma avaliação gratuita do Microsoft Fabric.
Entre no Microsoft Fabric.
Use o alternador de experiência no lado esquerdo da sua página inicial para mudar para a experiência de Ciência de Dados Synapse.
Abrir ou criar um notebook. Para saber como, consulte Como usar notebooks do Microsoft Fabric.
Defina a opção de idioma para SparkR (R) para mudar o idioma principal.
Anexe o notebook a um lakehouse. No lado esquerdo, selecione Adicionar para adicionar um lakehouse existente ou para criar um.
Carregar bibliotecas
Use bibliotecas do runtime do R padrão:
library(tidyverse)
library(lubridate)
library(hms)
Carregar os dados
Leia os preços do abacate de um arquivo de .CSV baixado da Internet:
df <- read.csv('https://synapseaisolutionsa.blob.core.windows.net/public/AvocadoPrice/avocado.csv', header = TRUE)
head(df,5)
Manipular os dados
Primeiro, atribua nomes mais amigáveis para as colunas.
# To use lowercase
names(df) <- tolower(names(df))
# To use snake case
avocado <- df %>%
rename("av_index" = "x",
"average_price" = "averageprice",
"total_volume" = "total.volume",
"total_bags" = "total.bags",
"amount_from_small_bags" = "small.bags",
"amount_from_large_bags" = "large.bags",
"amount_from_xlarge_bags" = "xlarge.bags")
# Rename codes
avocado2 <- avocado %>%
rename("PLU4046" = "x4046",
"PLU4225" = "x4225",
"PLU4770" = "x4770")
head(avocado2,5)
Altere os tipos de dados, remova colunas indesejadas e adicione o consumo total:
# Convert data
avocado2$year = as.factor(avocado2$year)
avocado2$date = as.Date(avocado2$date)
avocado2$month = factor(months(avocado2$date), levels = month.name)
avocado2$average_price =as.numeric(avocado2$average_price)
avocado2$PLU4046 = as.double(avocado2$PLU4046)
avocado2$PLU4225 = as.double(avocado2$PLU4225)
avocado2$PLU4770 = as.double(avocado2$PLU4770)
avocado2$amount_from_small_bags = as.numeric(avocado2$amount_from_small_bags)
avocado2$amount_from_large_bags = as.numeric(avocado2$amount_from_large_bags)
avocado2$amount_from_xlarge_bags = as.numeric(avocado2$amount_from_xlarge_bags)
# Remove unwanted columns
avocado2 <- avocado2 %>%
select(-av_index,-total_volume, -total_bags)
# Calculate total consumption
avocado2 <- avocado2 %>%
mutate(total_consumption = PLU4046 + PLU4225 + PLU4770 + amount_from_small_bags + amount_from_large_bags + amount_from_xlarge_bags)
Instalar novos pacotes
Use a instalação do pacote embutido para adicionar novos pacotes à sessão:
install.packages(c("repr","gridExtra","fpp2"))
Carregue as bibliotecas necessárias.
library(tidyverse)
library(knitr)
library(repr)
library(gridExtra)
library(data.table)
Analise e visualize os dados.
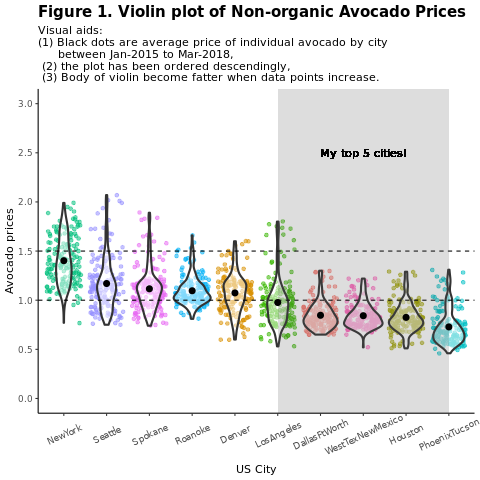
Compare os preços convencionais do abacate (não orgânico) por região:
options(repr.plot.width = 10, repr.plot.height =10)
# filter(mydata, gear %in% c(4,5))
avocado2 %>%
filter(region %in% c("PhoenixTucson","Houston","WestTexNewMexico","DallasFtWorth","LosAngeles","Denver","Roanoke","Seattle","Spokane","NewYork")) %>%
filter(type == "conventional") %>%
select(date, region, average_price) %>%
ggplot(aes(x = reorder(region, -average_price, na.rm = T), y = average_price)) +
geom_jitter(aes(colour = region, alpha = 0.5)) +
geom_violin(outlier.shape = NA, alpha = 0.5, size = 1) +
geom_hline(yintercept = 1.5, linetype = 2) +
geom_hline(yintercept = 1, linetype = 2) +
annotate("rect", xmin = "LosAngeles", xmax = "PhoenixTucson", ymin = -Inf, ymax = Inf, alpha = 0.2) +
geom_text(x = "WestTexNewMexico", y = 2.5, label = "My top 5 cities!", hjust = 0.5) +
stat_summary(fun = "mean") +
labs(x = "US city",
y = "Avocado prices",
title = "Figure 1. Violin plot of nonorganic avocado prices",
subtitle = "Visual aids: \n(1) Black dots are average prices of individual avocados by city \n between January 2015 and March 2018. \n(2) The plot is ordered descendingly.\n(3) The body of the violin becomes fatter when data points increase.") +
theme_classic() +
theme(legend.position = "none",
axis.text.x = element_text(angle = 25, vjust = 0.65),
plot.title = element_text(face = "bold", size = 15)) +
scale_y_continuous(lim = c(0, 3), breaks = seq(0, 3, 0.5))
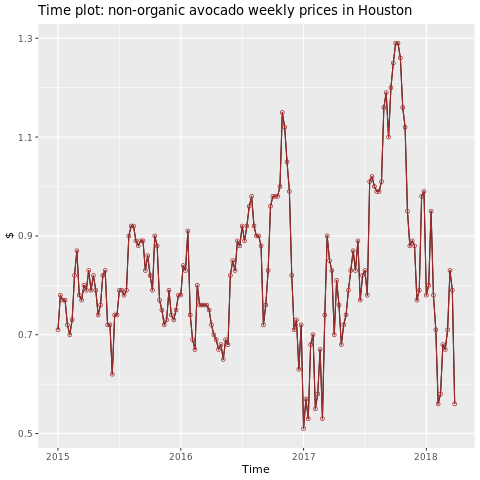
Foco na região de Houston.
library(fpp2)
conv_houston <- avocado2 %>%
filter(region == "Houston",
type == "conventional") %>%
group_by(date) %>%
summarise(average_price = mean(average_price))
# Set up ts
conv_houston_ts <- ts(conv_houston$average_price,
start = c(2015, 1),
frequency = 52)
# Plot
autoplot(conv_houston_ts) +
labs(title = "Time plot: nonorganic avocado weekly prices in Houston",
y = "$") +
geom_point(colour = "brown", shape = 21) +
geom_path(colour = "brown")
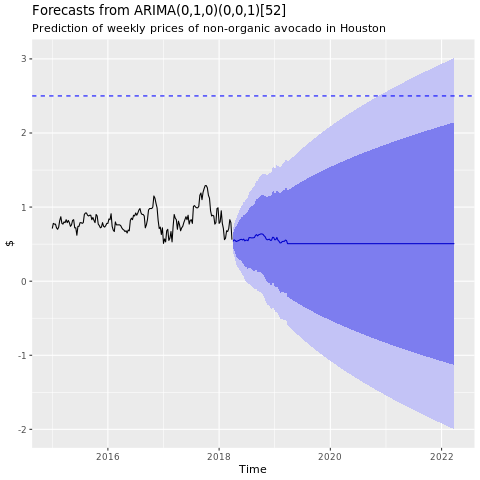
Treinar um modelo de machine learning
Crie um modelo de previsão de preços para a área de Houston, com base na Média de Movimentação Integrada de Regressão Automática (ARIMA):
conv_houston_ts_arima <- auto.arima(conv_houston_ts,
d = 1,
approximation = F,
stepwise = F,
trace = T)
checkresiduals(conv_houston_ts_arima)
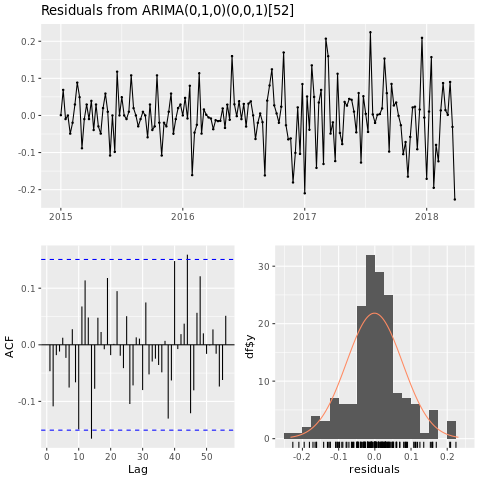
Mostre um grafo de previsões do modelo ARIMA de Houston:
conv_houston_ts_arima_fc <- forecast(conv_houston_ts_arima, h = 208)
autoplot(conv_houston_ts_arima_fc) + labs(subtitle = "Prediction of weekly prices of nonorganic avocados in Houston",
y = "$") +
geom_hline(yintercept = 2.5, linetype = 2, colour = "blue")