Padrões de resiliência de aplicativo
Dica
Esse conteúdo é um trecho do livro eletrônico, para Projetar os Aplicativos .NET nativos de nuvem para o Azure, disponível no .NET Docs ou como um PDF para download gratuito que pode ser lido offline.

A primeira linha de defesa é a resiliência do aplicativo.
Embora você possa investir um tempo considerável escrevendo a sua estrutura de resiliência, esses produtos já existem. O Polly é uma biblioteca .NET abrangente de tratamento de falhas transitórias e de resiliência que permite que os desenvolvedores expressem políticas de resiliência de maneira fluente e thread-safe. O Polly tem como destino aplicativos criados com o .NET Framework ou o .NET 7. A tabela a seguir descreve os recursos de resiliência, chamados de policies, disponíveis na biblioteca Polly. Eles podem ser aplicados individualmente ou agrupados.
| Política | Experiência |
|---|---|
| Tentar novamente | Configura operações de repetição em operações designadas. |
| Disjuntor | Bloqueia as operações solicitadas por um período predefinido quando as falhas excedem um limite configurado |
| Tempo limite | Coloca um limite na duração da espera pela resposta para um chamador. |
| Bulkhead | Restringe as ações ao pool de recursos de tamanho fixo para impedir que chamadas com falha prejudiquem um recurso. |
| Cache | Armazena respostas automaticamente. |
| Fallback | Define o comportamento estruturado após uma falha. |
Observe como, na figura anterior, as políticas de resiliência se aplicam a mensagens de solicitação, sejam provenientes de um cliente externo ou do serviço de back-end. A meta é compensar a solicitação de um serviço que pode não estar disponível temporariamente. Essas interrupções de curta duração normalmente se manifestam com os códigos de status HTTP mostrados na tabela a seguir.
| Código de status HTTP | Causa |
|---|---|
| 404 | Não encontrado |
| 408 | Tempo limite da solicitação |
| 429 | Muitas solicitações (provavelmente há uma restrição) |
| 502 | Gateway inválido |
| 503 | Serviço indisponível |
| 504 | Tempo limite do gateway |
Pergunta: você repetiria um código de status HTTP 403 – Proibido? Não. Aqui, o sistema está funcionando corretamente, mas informando ao chamador que ele não está autorizado a executar a operação solicitada. É necessário ter cuidado e repetir apenas as operações causadas por falhas.
Conforme recomendado no Capítulo 1, os desenvolvedores da Microsoft que constroem aplicativos nativos de nuvem devem ter como destino a plataforma .NET. A versão 2.1 introduziu a biblioteca HTTPClientFactory para criar instâncias de cliente HTTP para interagir com recursos baseados em URL. Substituindo a classe HTTPClient original, a classe factory dá suporte a muitos recursos aprimorados, um dos quais é uma forte integração com a biblioteca de resiliência Polly. Com ela, você pode definir facilmente políticas de resiliência na classe Startup do aplicativo para lidar com falhas parciais e problemas de conectividade.
Depois, vamos detalhar melhor os padrões de repetição e disjuntor.
Padrão de repetição
Em um ambiente nativo de nuvem distribuído, as chamadas a serviços e recursos de nuvem podem falhar devido a falhas transitórias (de curta duração), que normalmente se corrigem após um breve período de tempo. A implementação de uma estratégia de repetição ajuda um serviço nativo de nuvem a atenuar esses cenários.
O padrão de repetição permite que um serviço repita uma operação de solicitação com falha um número (configurável) de vezes com um tempo de espera exponencialmente crescente. A Figura 6-2 mostra uma repetição em ação.
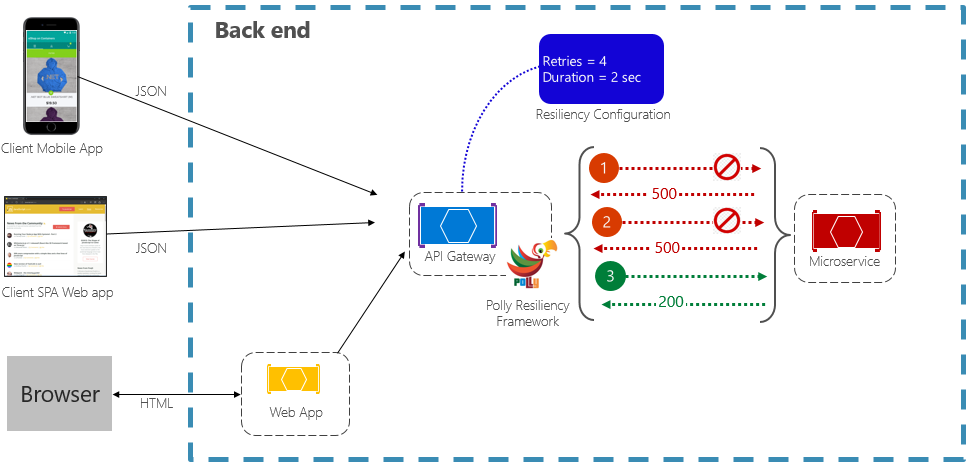
Figura 6-2. Padrão de repetição em ação
Na figura anterior, um padrão de repetição foi implementado para uma operação de solicitação. Ele é configurado para permitir até quatro repetições antes de falhar com um intervalo de retirada (tempo de espera) começando em dois segundos, que é dobrado exponencialmente para cada tentativa subsequente.
- A primeira invocação falha e retorna um código de status HTTP 500. O aplicativo aguarda dois segundos e repete a chamada.
- A segunda invocação também falha e retorna um código de status HTTP 500. O aplicativo agora dobra o intervalo de retirada para quatro segundos e repete a chamada.
- Por fim, a terceira chamada é bem-sucedida.
- Nesse cenário, a operação de repetição teria feito até quatro tentativas duplicando a duração da retirada antes de falhar a chamada.
- Se a 4ª tentativa de repetição falhasse, uma política de fallback seria invocada para lidar com o problema normalmente.
É importante aumentar o período de retirada antes de repetir a chamada para permitir que o tempo de serviço seja corrigido por conta própria. É uma boa prática implementar uma retirada exponencialmente crescente (duplicando o período a cada repetição) para permitir um tempo de correção adequado.
Padrão de disjuntor
Embora o padrão de repetição ajude a recuperar uma solicitação paralisada em uma falha parcial, há situações em que as falhas podem ser causadas por eventos imprevistos que exigirão períodos mais longos para serem resolvidos. Essas falhas podem variar de gravidade de uma perda parcial de conectividade até a falha completa de um serviço. Nessas situações, é inútil que o aplicativo repita continuamente uma operação improvável de ser bem-sucedida.
Para piorar as coisas, a execução de operações de repetição contínuas em um serviço sem resposta pode passá-lo para um cenário de negação de serviço autoimposto, em que você inunda o serviço com chamadas contínuas esgotando recursos, como memória, threads e conexões de banco de dados, causando falha em partes não relacionadas do sistema que usam os mesmos recursos.
Nessas situações, seria preferível que a operação falhasse imediatamente e somente tentasse invocar o serviço se houvesse probabilidade de sucesso.
O padrão de disjuntor pode impedir que um aplicativo tente executar repetidamente uma operação que provavelmente falhará. Após um número predefinido de chamadas com falha, ele bloqueia todo o tráfego para o serviço. Periodicamente, ele permitirá uma chamada de avaliação para determinar se a falha foi resolvida. A Figura 6-3 mostra o padrão de disjuntor em ação.
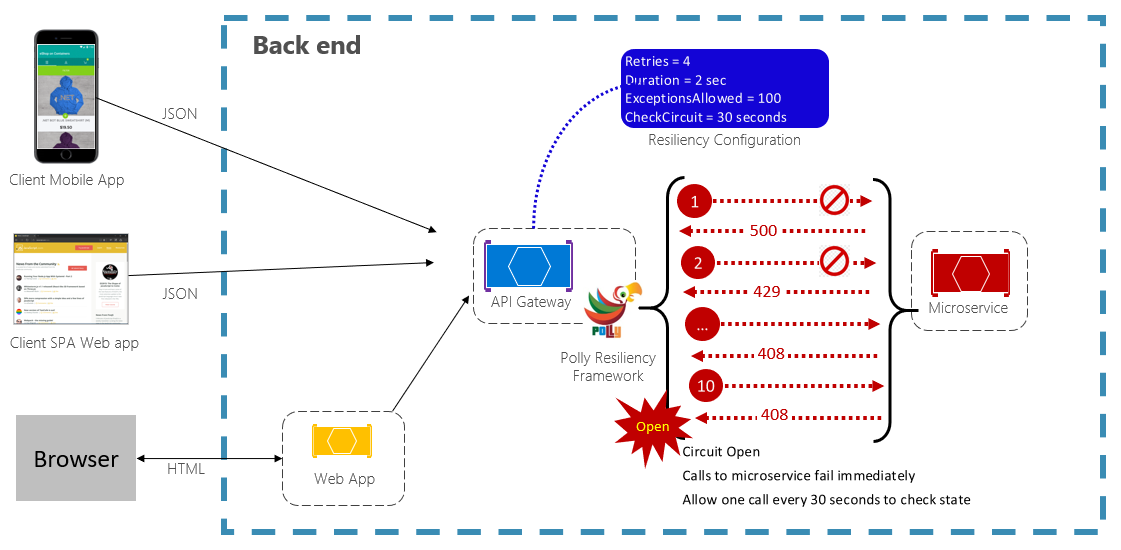
Figura 6-3. Padrão de disjuntor em ação
Na figura anterior, um padrão de disjuntor foi adicionado ao padrão de repetição original. Observe como, após 100 solicitações com falha, os disjuntores são abertos e não permitem mais chamadas para o serviço. O valor de CheckCircuit, definido como 30 segundos, especifica com que frequência a biblioteca permite que uma solicitação prossiga para o serviço. Se essa chamada for bem-sucedida, o circuito será fechado e o serviço ficará novamente disponível para o tráfego.
Tenha em mente que a intenção do padrão de disjuntor é diferente da intenção do padrão de repetição. O padrão de repetição permite que o aplicativo repita uma operação na expectativa de que terá êxito. O padrão de disjuntor impede que o aplicativo faça uma operação que provavelmente falhará. Normalmente, o aplicativo combinará esses dois padrões usando o padrão de repetição para invocar uma operação por meio de um disjuntor.
Teste de resiliência
O teste de resiliência nem sempre pode ser feito da mesma maneira que você testa a funcionalidade do aplicativo (executando testes de unidade, testes de integração e assim por diante). Nesse caso, é necessário testar a execução da carga de trabalho de ponta a ponta sob condições de falha intermitentes. Por exemplo: injetar falhas falhando processos, certificados expirados, fazer com que serviços dependentes não fiquem disponíveis etc. Estruturas como chaos-monkey podem ser usadas para esses testes do caos.
A resiliência do aplicativo é um requisito para lidar com operações solicitadas problemáticas. Mas, é apenas metade da história. Em seguida, abordaremos os recursos de resiliência disponíveis na nuvem do Azure.