Trate as falhas que possam consumir uma quantidade variável de tempo para serem recuperadas ao se conectar a um serviço ou recurso remoto. Esse padrão pode melhorar a estabilidade e a resiliência de um aplicativo.
Contexto e problema
Em um ambiente distribuído, as chamadas para recursos e serviços remotos podem falhar devido a falhas transitórias, como conexões de rede lentas, tempos limite ou recursos sendo supercompactados ou temporariamente indisponíveis. Essas falhas geralmente são corrigidas automaticamente após um breve período de tempo e um aplicativo de nuvem robusto deve estar preparado para tratá-las usando uma estratégia, como o Padrão de repetição.
No entanto, também pode haver situações em que as falhas ocorrem devido a eventos inesperados e que podem demorar muito mais para serem corrigidos. Essas falhas podem variar de gravidade de uma perda parcial de conectividade até a falha completa de um serviço. Nessas situações, pode ser inútil para um aplicativo repetir continuamente uma operação que é improvável que tenha êxito e, em vez disso, o aplicativo deve aceitar rapidamente que a operação falhou e lidar com essa falha adequadamente.
Além disso, se um serviço estiver muito ocupado, a falha em uma parte do sistema poderá resultar em falhas em cascata. Por exemplo, uma operação que invoca um serviço pode ser configurada para implementar um tempo limite e responder com uma mensagem de falha se o serviço não responder dentro desse período. No entanto, essa estratégia pode fazer com que muitas solicitações simultâneas para a mesma operação sejam bloqueadas até que o período de tempo limite expire. Essas solicitações bloqueadas podem conter recursos críticos do sistema, como memória, threads, conexões de banco de dados, etc. Portanto, esses recursos podem se esgotar, causando falha de outras partes possivelmente não relacionadas do sistema que precisam usar os mesmos recursos. Nessas situações, seria preferível que a operação falhasse imediatamente e somente tentasse invocar o serviço se o êxito fosse provável. A configuração de um tempo limite menor pode ajudar a resolver esse problema, mas o tempo limite não deve ser tão curto que a operação falhe na maior parte do tempo, mesmo que a solicitação para o serviço eventualmente tenha êxito.
Solução
O padrão disjuntor pode impedir que um aplicativo tente executar repetidamente uma operação que provavelmente falhará. Ele permite continuar sem aguardar que a falha seja corrigida ou sem desperdiçar ciclos de CPU enquanto determina-se que a falha é de longa duração. O padrão de Disjuntor também permite que um aplicativo detecte se a falha foi resolvida. Se o problema aparentar ter sido corrigido, o aplicativo poderá tentar invocar a operação.
A finalidade do padrão de Disjuntor é diferente do padrão de Repetição. O padrão de Repetição permite que um aplicativo tente novamente uma operação na expectativa que haverá êxito. O padrão de Disjuntor impede que um aplicativo tente execute uma operação em que a falha é provável. Um aplicativo pode combinar esses dois padrões usando o padrão de Repetição para invocar uma operação por meio de um disjuntor. No entanto, a lógica de repetição deverá ser sensível às exceções retornadas pelo disjuntor e abandonar as novas tentativas se o disjuntor indicar que uma falha não é transitória.
Um disjuntor atua como um proxy para operações que podem falhar. O proxy deve monitorar o número de falhas recentes que ocorreram e usar essas informações para decidir se deseja permitir que a operação prossiga ou retornar uma exceção imediatamente.
O proxy pode ser implementado como um computador de estado com os seguintes estados que imitam a funcionalidade de um disjuntor elétrico:
Fechado: a solicitação do aplicativo é encaminhada para a operação. O proxy mantém a contagem do número de falhas recentes e, se a chamada à operação não for bem-sucedida, o proxy incrementará essa contagem. Se o número de falhas recentes exceder um limite especificado em um determinado período de tempo, o proxy será colocado no estado Aberto. Neste ponto, o proxy inicia um tempo limite e, quando esse temporizador expira, o proxy é colocado no estado de semiaberto.
A finalidade do tempo limite é dar tempo ao sistema para corrigir o problema que causou a falha antes de permitir que o aplicativo tente executar a operação novamente.
Aberto: a solicitação do aplicativo falha imediatamente e uma exceção é retornada ao aplicativo.
Entreaberto: um número limitado de solicitações do aplicativo pode ser passado e invocar a operação. Se essas solicitações forem bem-sucedidas, será considerado que o problema anterior que estava causando a falha foi corrigido e o disjuntor mudará para o estado Fechado (o contador de falhas será reiniciado). Se qualquer solicitação falhar, o disjuntor pressupõe que a falha ainda esteja presente para que ela seja revertida para o estado Abrir e reinicie o tempo limite para dar ao sistema um período adicional de tempo para se recuperar da falha.
O estado Entreaberto é útil para impedir que um serviço de recuperação seja inundado repentinamente com solicitações. Conforme um serviço é recuperado, ele pode dar suporte a um volume limitado de solicitações até que a recuperação seja concluída, mas enquanto a recuperação estiver em andamento, um fluxo grande de trabalho poderá fazer com que o tempo limite do serviço seja atingido ou falhe novamente.
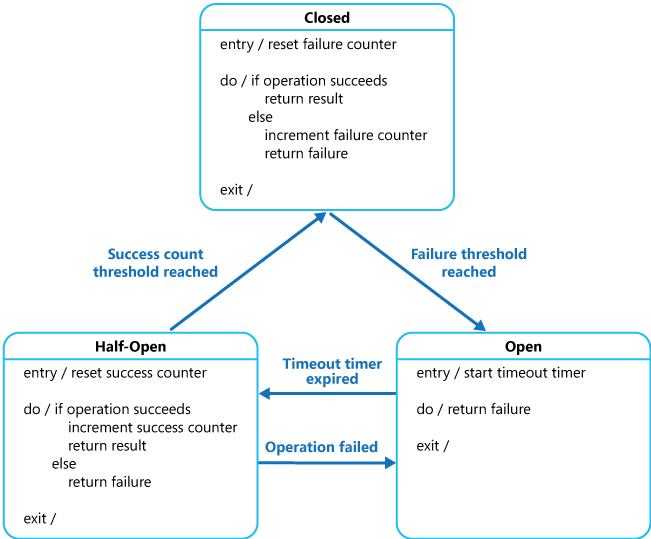
Na figura, o contador de falhas é usado no estado Fechado é baseado em tempo. Ele é reiniciado automaticamente em intervalos periódicos. Esse design ajuda a impedir que o disjuntor entre no estado Abrir se ele apresentar falhas ocasionais. O limite de falhas que aciona o disjuntor no estado Aberto só é atingido quando um número especificado de falhas ocorrer durante um intervalo especificado. O contador usado no estado Entreaberto registra o número de tentativas bem-sucedidas para invocar a operação. O disjuntor será revertido para o estado Fechado após um número especificado de invocações bem-sucedidas da operação ser obtido de maneira consecutiva. Se alguma invocação falhar, o disjuntor entrará no estado Aberto imediatamente e o contador de êxito será reiniciado na próxima vez que ele entrar no estado Entreaberto.
O modo que o sistema é recuperado é tratado de maneira externa, possivelmente restaurando ou reiniciando um componente com falha ou reparando uma conexão de rede.
O padrão de disjuntor fornece estabilidade enquanto o sistema se recupera de uma falha e minimiza o impacto no desempenho. Ele pode ajudar a manter o tempo de resposta do sistema rejeitando rapidamente uma solicitação para uma operação em que a falha é provável, em vez de aguardar o tempo limite da operação ou nunca retornar. Se o disjuntor acionar um evento sempre que mudar de estado, essas informações poderão ser usadas para monitorar a integridade da parte do sistema protegido pelo disjuntor ou para alertar o administrador quando um disjuntor acionar o estado Aberto.
O padrão é personalizável e pode ser adaptado de acordo com o tipo de falha possível. Por exemplo, você pode aplicar um tempo limite de tempo limite crescente a um disjuntor. Você pode colocar o disjuntor no estado Abrir por alguns segundos inicialmente e, em seguida, se a falha não tiver sido resolvida, aumentar o tempo limite para alguns minutos e assim por diante. Em alguns casos, em vez de o estado Aberto retornar a falha e gerar uma exceção, pode ser útil retornar um valor padrão que seja significativo para o aplicativo.
Observação
Tradicionalmente, os disjuntores se baseavam em limites pré-configurados, como contagem de falhas e duração do tempo limite, resultando em um comportamento determinístico, mas às vezes abaixo do ideal. No entanto, técnicas adaptáveis usando IA e ML podem ajustar dinamicamente limites com base em padrões de tráfego em tempo real, anomalias e taxas de falha histórica, tornando o disjuntor mais resiliente e eficiente.
Problemas e considerações
Os seguintes pontos devem ser considerados ao decidir como implementar esse padrão:
Tratamento de exceções: um aplicativo que invoca uma operação por meio de um disjuntor deve estar preparado para lidar com as exceções geradas se a operação não estiver disponível. A maneira como são as exceções são tratadas dependerá do aplicativo. Por exemplo, um aplicativo pode sofrer uma degradação temporária de sua funcionalidade, invocar uma operação alternativa para tentar executar a mesma tarefa ou obter os mesmos dados ou relatar a exceção ao usuário e pedir a que ele tente novamente mais tarde.
tipos de exceções: uma solicitação pode falhar por muitos motivos, alguns dos quais podem indicar um tipo mais grave de falha do que outros. Por exemplo, uma solicitação pode falhar porque um serviço remoto falhou e levará vários minutos para ser recuperado ou devido a um tempo limite devido ao serviço estar temporariamente sobrecarregado. Um disjuntor poderá examinar os tipos de exceções que ocorrem e ajustar a estratégia dependendo da natureza dessas exceções. Por exemplo, pode exigir um número maior de exceções de tempo limite para deslocar o disjuntor para o estado Abrir em comparação com o número de falhas devido ao serviço estar completamente indisponível.
Monitoramento: um disjuntor deve fornecer uma observabilidade clara em solicitações com falha e êxito, permitindo que as equipes de operações avaliem a integridade do sistema. Use o rastreamento distribuído para visibilidade de ponta a ponta entre serviços.
de recuperação: você deve configurar o disjuntor para corresponder ao padrão de recuperação provável da operação que está protegendo. Por exemplo, se o disjuntor permanece no estado Aberto por um longo período, ele pode gerar exceções mesmo se o motivo da falha foi resolvido. De forma semelhante, um disjuntor pode flutuar e reduzir os tempos de resposta dos aplicativos se mudar do estado Aberto para o estado Entreaberto muito rapidamente.
Operações com falha de teste: no estado Abrir, em vez de usar um temporizador para determinar quando alternar para o estado de semiaberto, um disjuntor pode, em vez disso, executar ping periodicamente no serviço ou recurso remoto para determinar se ele está disponível novamente. Esse ping pode assumir a forma de uma tentativa de invocar uma operação que falhou anteriormente ou pode usar uma operação especial fornecida pelo serviço remoto especificamente para testar a integridade do serviço, conforme descrito pelo Padrão de monitoramento do ponto de extremidade de integridade.
Substituição manual: em um sistema em que o tempo de recuperação de uma operação com falha é extremamente variável, é benéfico fornecer uma opção de redefinição manual que permite que um administrador feche um disjuntor (e redefina o contador de falhas). Da mesma forma, um administrador pode forçar um disjuntor no estado Abrir (e reiniciar o tempo limite) se a operação protegida pelo disjuntor estiver temporariamente indisponível.
de simultaneidade: o mesmo disjuntor pode ser acessado por um grande número de instâncias simultâneas de um aplicativo. A implementação não deve bloquear solicitações simultâneas nem adicionar uma sobrecarga excessiva a cada chamada a uma operação.
Diferenciação de recursos: tenha cuidado ao usar um único disjuntor para um tipo de recurso se houver vários provedores independentes subjacentes. Por exemplo, em um armazenamento de dados contendo vários fragmentos, um fragmento pode estar totalmente acessível enquanto outro está enfrentando um problema temporário. Se as respostas de erro nesses cenários forem mescladas, um aplicativo poderá tentar acessar alguns fragmentos, mesmo quando a falha for altamente provável, enquanto o acesso aos outros fragmentos poderá ser bloqueado, mesmo que provavelmente tenham êxito.
de interrupção acelerada do circuito: às vezes, uma resposta de falha pode conter informações suficientes para o disjuntor tropeçar imediatamente e permanecer tropeçado por um período mínimo de tempo. Por exemplo, a resposta de erro de um recurso compartilhado sobrecarregado pode indicar que uma nova tentativa imediata não seja recomendada e que o aplicativo, em vez disso, devesse tentar novamente em alguns minutos.
implantações de várias regiões: um disjuntor pode ser projetado para implantações de várias regiões ou única. Este último pode ser implementado usando balanceadores de carga globais ou estratégias personalizadas de quebra de circuito com reconhecimento de região que garantem failover controlado, otimização de latência e conformidade regulatória.
disjuntores de malha de serviço: os disjuntores podem ser implementados na camada do aplicativo ou como um recurso de corte cruzado e abstraído. Por exemplo, as malhas de serviço geralmente dão suporte à quebra de circuito como um sidecar ou como uma funcionalidade autônoma sem modificar o código do aplicativo.
Observação
Um serviço poderá retornar HTTP 429 (Muitas Solicitações) se estiver limitando o cliente ou HTTP 503 (Serviço Indisponível) se o serviço não estiver disponível no momento. A resposta pode incluir informações adicionais, como a duração prevista do atraso.
Reprodução de solicitações com falha: no estado Abrir, em vez de simplesmente falhar rapidamente, um disjuntor também pode registrar os detalhes de cada solicitação em um diário e organizar para que essas solicitações sejam reproduzidas quando o recurso ou serviço remoto estiver disponível.
tempos limite inadequados em serviços externos: um disjuntor pode não ser capaz de proteger totalmente os aplicativos contra operações que falham em serviços externos configurados com um longo período de tempo limite. Se o tempo limite for muito longo, um thread executando um disjuntor poderá ser bloqueado por um período estendido antes que o disjuntor indique que a operação falhou. Nesse momento, muitas outras instâncias do aplicativo também poderão tentar invocar o serviço por meio do disjuntor e associar um número significativo de threads antes que todos falhem.
Adaptabilidade para calcular a diversificação: os disjuntores devem considerar diferentes ambientes de computação, desde cargas de trabalho sem servidor até cargas de trabalho em contêineres, em que fatores como inícios frios e escalabilidade afetam o tratamento de falhas. Abordagens adaptáveis podem ajustar dinamicamente estratégias com base no tipo de computação, garantindo resiliência entre arquiteturas heterogêneas.
Quando usar esse padrão
Use este padrão:
- Para evitar falhas em cascata, interrompendo invocações excessivas por um serviço remoto ou solicitações de acesso a um recurso compartilhado se essas operações forem altamente propensas a falhar.
- Para aprimorar a resiliência de várias regiões roteando o tráfego de forma inteligente com base em sinais de falha em tempo real.
- Para proteger contra dependências lentas, ajude você a acompanhar seus SLOs (objetivos de nível de serviço) e evitar degradação de desempenho devido a serviços de alta latência.
- Para lidar com problemas intermitentes de conectividade e reduzir falhas de solicitação em ambientes distribuídos.
Este padrão não é recomendável:
- Para tratar do acesso a recursos particulares locais em um aplicativo, como a estrutura de dados na memória. Nesse ambiente, usar um disjuntor poderia adicionar uma sobrecarga ao sistema.
- Como substituto para o tratamento de exceções na lógica de negócios dos seus aplicativos.
- Quando algoritmos de repetição conhecidos são suficientes e suas dependências são projetadas para lidar com mecanismos de repetição. Implementar um disjuntor em seu aplicativo, nesse caso, pode adicionar complexidade desnecessária ao seu sistema.
- Ao esperar que um disjuntor seja redefinido pode introduzir atrasos inaceitáveis.
- Se você tiver uma arquitetura controlada por mensagens ou controlada por eventos, como elas geralmente roteiam mensagens com falha para uma DLQ (Fila de Mensagens Mortas) para processamento manual ou adiado. Os mecanismos internos de isolamento e repetição de falhas normalmente implementados nesses designs geralmente são suficientes.
- Se a recuperação de falha for gerenciada no nível da infraestrutura ou da plataforma, como com verificações de integridade em balanceadores de carga globais ou malhas de serviço, os disjuntores podem não ser necessários.
Design de carga de trabalho
Um arquiteto deve avaliar como o padrão Disjuntor pode ser usado no design das suas cargas de trabalho para abordar os objetivos e os princípios discutidos nos pilares do Azure Well-Architected Framework. Por exemplo:
| Pilar | Como esse padrão apoia os objetivos do pilar |
|---|---|
| As decisões de design de confiabilidade ajudam sua carga de trabalho a se tornar resiliente ao mau funcionamento e a garantir que ela se recupere para um estado totalmente funcional após a ocorrência de uma falha. | Esse padrão evita a sobrecarga de uma dependência com falha. Você também pode usar esse padrão para acionar a degradação normal na carga de trabalho. Os disjuntores são frequentemente acoplados à recuperação automática para fornecer autopreservação e autorrecuperação. - RE:03 Análise do modo de falha - RE:07 Falhas transitórias - RE:07 Autopreservação |
| A eficiência de desempenho ajuda sua carga de trabalho a atender com eficiência às demandas por meio de otimizações em dimensionamento, dados e código. | Esse padrão evita a abordagem de nova tentativa em caso de erro, que pode levar à utilização excessiva de recursos durante a recuperação de dependência e também pode sobrecarregar o desempenho em uma dependência que está tentando a recuperação. - PE:07 Código e infraestrutura - PE:11 Respostas a problemas em tempo real |
Tal como acontece com qualquer decisão de design, considere quaisquer compensações em relação aos objetivos dos outros pilares que possam ser introduzidos com este padrão.
Recursos relacionados
Os seguintes padrões também serão úteis ao implementar este padrão:
O padrão de aplicativo web confiável mostra como aplicar o padrão circuit-breaker a aplicativos web convergindo na nuvem.
Padrão de repetição. Descreve como um aplicativo pode tratar falhas previstas e temporárias quando tentar se conectar a um serviço ou recurso de rede repetindo de forma transparente uma operação que falhou anteriormente.
Padrão de monitoramento do ponto de extremidade de integridade. Um disjuntor pode testar a integridade de um serviço enviando uma solicitação para um ponto de extremidade exposto pelo serviço. O serviço deve retornar informações indicando seu status.