Resiliência da plataforma do Azure
Dica
Esse conteúdo é um trecho do livro eletrônico, para Projetar os Aplicativos .NET nativos de nuvem para o Azure, disponível no .NET Docs ou como um PDF para download gratuito que pode ser lido offline.

A criação de um aplicativo confiável na nuvem é diferente do desenvolvimento de aplicativos locais tradicionais. Tradicionalmente um hardware de nível superior era comprado para ser escalado verticalmente, mas em um ambiente de nuvem, você escala horizontalmente. Em vez de tentar evitar falhas, o objetivo é minimizar seus efeitos e manter o sistema estável.
Dito isso, os aplicativos de nuvem confiáveis exibem características distintas:
- Eles são resilientes, recuperam-se normalmente de problemas e continuam a funcionar.
- Eles são altamente disponíveis (HA) e são executados conforme projetados em um estado íntegro sem tempo de inatividade significativo.
Para criar um aplicativo de nuvem confiável, é fundamental entender como essas características funcionam em conjunto e como elas afetam o custo. Depois, veremos como você pode criar resiliência e disponibilidade nos aplicativos nativos de nuvem aproveitando os recursos da nuvem do Azure.
Design com resiliência
Dissemos que a resiliência permite que o aplicativo reaja a uma falha e ainda permaneça funcional. O white paper, Resiliência no Azure, fornece diretrizes para obter resiliência na plataforma Azure. Veja algumas recomendações importantes:
Falha de hardware. Crie redundância no aplicativo implantando componentes em diferentes domínios de falha. Por exemplo, verifique se as VMs do Azure estão colocadas em racks diferentes usando conjuntos de disponibilidade.
Falha no datacenter. Crie redundância no aplicativo com zonas de isolamento de falha em vários data centers. Por exemplo, verifique se as VMs do Azure estão colocadas em diferentes data centers com isolamento de falha usando as Zonas de Disponibilidade do Azure.
Falha regional. Replique os dados e os componentes para outra região a fim de que os aplicativos possam ser recuperados rapidamente. Por exemplo, use o Azure Site Recovery a fim de replicar VMs do Azure para outra região do Azure.
Carga pesada. Balanceie a carga entre instâncias para lidar com picos de uso. Por exemplo, coloque duas ou mais VMs do Azure atrás de um balanceador de carga para distribuir o tráfego a todas as VMs.
Exclusão ou corrupção acidental de dados. Faça backup dos dados para que eles possam ser restaurados se houver alguma exclusão ou corrupção. Por exemplo, use o Backup do Azure para fazer backup das VMs do Azure periodicamente.
Design com redundância
As falhas variam no escopo do impacto. Uma falha de hardware, como um disco com falha, pode afetar um só nó em um cluster. Um comutador de rede com falha pode afetar um rack de servidores inteiro. Falhas menos comuns, como perda de energia, podem interromper um datacenter inteiro. Raramente, uma região inteira fica não disponível.
A redundância é uma forma de fornecer resiliência ao aplicativo. O nível exato de redundância necessário depende dos requisitos comerciais e afetará o custo e a complexidade do sistema. Por exemplo, uma implantação em várias regiões é mais cara e mais complexa de ser gerenciada do que uma implantação de região única. Você precisará de procedimentos operacionais para gerenciar o failover e o failback. O custo e a complexidade adicionais podem ser justificados para alguns cenários de negócios, mas não para outros.
Para arquitetar a redundância, você precisa identificar os caminhos críticos no aplicativo e depois determinar se há redundância em cada ponto do caminho. Se um subsistema falhar, o aplicativo fará failover para outra opção? Por fim, você precisa de uma compreensão clara dos recursos integrados à plataforma de nuvem do Azure que podem ser aproveitados para atender aos requisitos de redundância. Veja as recomendações para a arquitetura de redundância:
Implante várias instâncias de serviços. Se seu aplicativo depender de uma única instância de um serviço, ele criará um único ponto de falha. O provisionamento de várias instâncias melhora a resiliência e a escalabilidade. Ao fazer a hospedagem no Serviço de Kubernetes do Azure, você pode configurar instâncias redundantes de modo declarativo (conjuntos de réplicas) no arquivo de manifesto do Kubernetes. O valor da contagem de réplicas pode ser gerenciado programaticamente, no portal ou por meio de recursos de dimensionamento automático.
Aproveitar um balanceador de carga. O balanceamento de carga distribui as solicitações do aplicativo para instâncias de serviço íntegras e remove automaticamente as instâncias não íntegras da rotação. Ao fazer a implantação no Kubernetes, o balanceamento de carga pode ser especificado no arquivo de manifesto do Kubernetes na seção Services.
Planejar implantações em várias regiões. Se você implantar o aplicativo em uma só região e essa região ficar não disponível, o aplicativo também ficará não disponível. Isso pode ser inaceitável nos termos dos Contratos de Nível de Serviço do aplicativo. Nesse caso, considere implantar o aplicativo e os serviços em várias regiões. Por exemplo, um cluster do AKS (Serviço de Kubernetes do Azure) é implantado em uma só região. Para proteger o sistema contra uma falha regional, você pode implantar o aplicativo em vários clusters do AKS em regiões diferentes e usar o recurso de regiões emparelhadas para coordenar as atualizações da plataforma e priorizar os esforços de recuperação.
Habilitar a replicação geográfica. A replicação geográfica de serviços, como o Banco de Dados SQL do Azure e o Cosmos DB, criará réplicas secundárias dos dados em várias regiões. Embora os dois serviços repliquem automaticamente os dados na mesma região, a replicação geográfica protege você contra uma interrupção regional, permitindo o failover para uma região secundária. Outra prática recomendada para a replicação geográfica está relacionada ao armazenamento de imagens de contêiner. Para implantar um serviço no AKS, você precisa armazenar e efetuar pull da imagem de um repositório. O Registro de Contêiner do Azure se integra ao AKS e pode armazenar imagens de contêiner com segurança. Para aprimorar o desempenho e a disponibilidade, considere a replicação geográfica das imagens para um registro em cada região em que haja um cluster do AKS. Depois, cada cluster do AKS efetuará pull das imagens de contêiner do registro de contêiner local em sua região, conforme é mostrado na Figura 6-4:
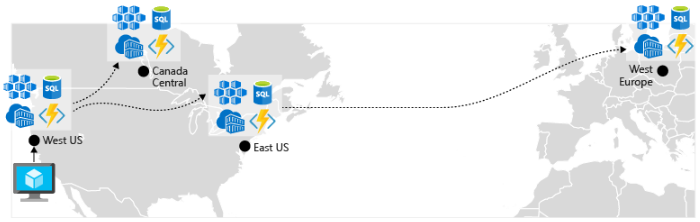
Figura 6-4. Recursos replicados entre regiões
- Implementar um balanceador de carga de tráfego DNS. O Gerenciador de Tráfego do Azure fornece alta disponibilidade para aplicativos críticos por meio do balanceamento de carga no nível do DNS. Ele pode rotear o tráfego para diferentes regiões com base na geografia, no tempo de resposta do cluster e até mesmo na integridade do ponto de extremidade do aplicativo. Por exemplo, Gerenciador de Tráfego do Azure pode direcionar os clientes para a instância de aplicativo e de cluster do AKS mais próxima. Se tiver vários clusters AKS em regiões diferentes, use o Gerenciador de Tráfego para controlar como o tráfego flui para os aplicativos que são executados em cada cluster. A Figura 6-5 mostra esse cenário.
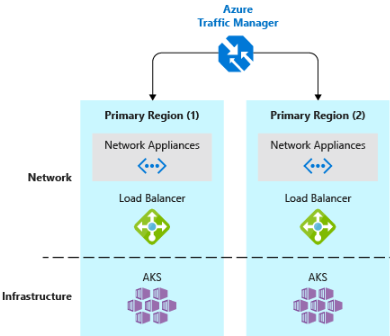
Figura 6-5. AKS e Gerenciador de Tráfego do Azure
Design para escalabilidade
A nuvem é excelente em dimensionamento. A capacidade de aumentar/diminuir os recursos do sistema para lidar com a carga crescente/decrescente do sistema é um princípio fundamental da nuvem do Azure. Mas, para dimensionar um aplicativo com eficiência, você precisa compreender os recursos de dimensionamento de cada serviço do Azure que incluído no aplicativo. Veja as recomendações para implementar o dimensionamento efetivamente no sistema.
Design para dimensionamento. O aplicativo precisa ser projetado para dimensionamento. Para iniciar, os serviços devem ser sem estado para que as solicitações possam ser roteadas a qualquer instância. Além disso, com serviços sem estado, a adição ou a remoção de uma instância não prejudica os usuários atuais.
Cargas de trabalho de partição. A decomposição de domínios em microsserviços independentes e autossuficientes permite que cada serviço seja dimensionado de maneira independente dos outros. Normalmente, os serviços terão necessidades e requisitos de escalabilidade diferentes. O particionamento permite que você dimensione apenas a parte que precisa ser dimensionada sem o custo desnecessário de dimensionar um aplicativo inteiro.
Favorecer a escala horizontal. Os aplicativos baseados em nuvem favorecem a escala horizontal dos recursos em oposição à escala vertical. A escala horizontal (também conhecida como expansão) envolve a adição de mais recursos de serviço a um sistema existente para atender a um nível de desempenho desejado e compartilhá-lo. A escala vertical (também conhecida como dimensionamento vertical) envolve a substituição de recursos existentes por hardware mais potente (mais núcleos de disco, memória e processamento). A escala horizontal pode ser invocada automaticamente com os recursos de dimensionamento automático disponíveis em alguns recursos de nuvem do Azure. A escala horizontal em vários recursos também adiciona redundância ao sistema geral. Por fim, a escala vertical de um só recurso é mais cara do que a escala horizontal de vários recursos menores. A Figura 6-6 mostra as duas abordagens:
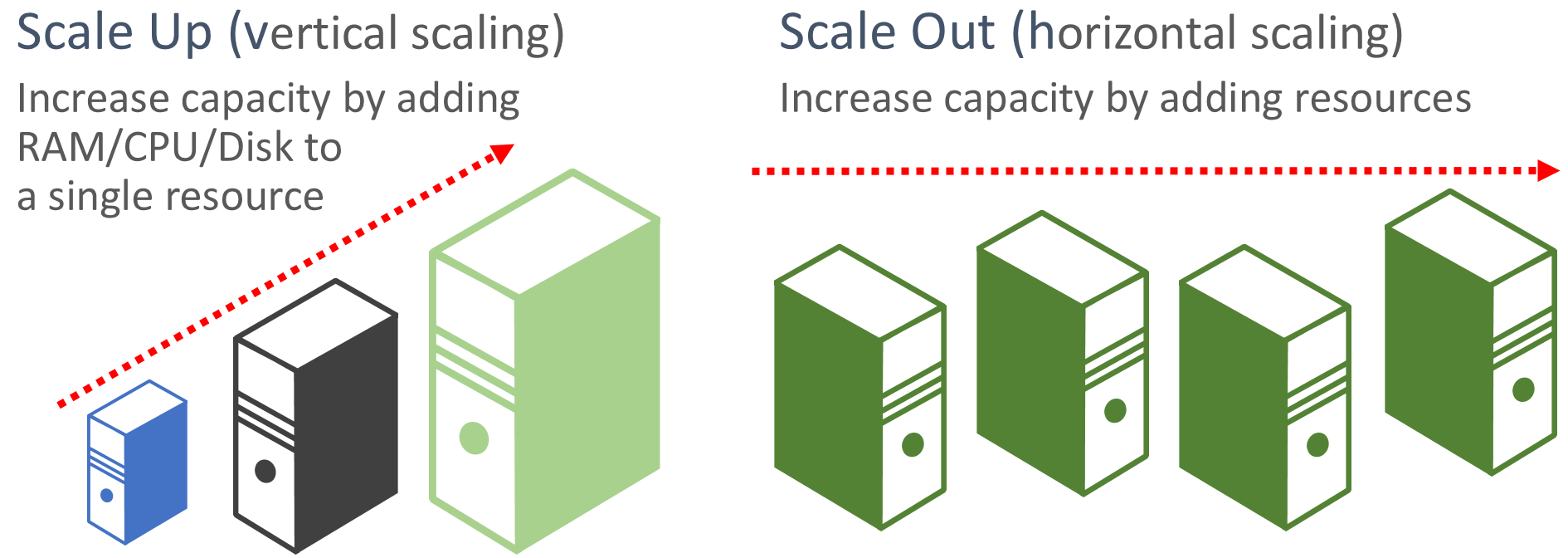
Figura 6-6. Escalar verticalmente em comparação com escalar horizontalmente
Dimensionar proporcionalmente. Ao dimensionar um serviço, pense em termos de conjuntos de recursos. Se você fosse expandir radicalmente um serviço específico, que impacto haveria nos armazenamentos de dados de back-end, nos caches e nos serviços dependentes? Alguns recursos, como o Cosmos DB, podem ser escalados horizontalmente proporcionalmente, enquanto muitos outros não podem. Convém garantir que um recurso não seja dimensionado horizontalmente a ponto de esgotar os outros recursos associados.
Evite afinidade. Uma boa prática é garantir que um nó não exija afinidade local, geralmente conhecida como sessão temporária. Uma solicitação deve ter a capacidade de fazer roteamento para qualquer instância. Se você precisar que o estado persista, ele deverá ser salvo em um cache distribuído, como o Cache Redis do Azure.
Aproveite os recursos de dimensionamento automático da plataforma. Use recursos de dimensionamento automático integrados sempre que possível, em vez de mecanismos personalizados ou de terceiros. Sempre que possível, use regras de dimensionamento agendadas para garantir que os recursos estejam disponíveis sem atraso de inicialização, mas adicione o dimensionamento automático reativo às regras de modo apropriado para lidar com alterações inesperadas na demanda. Para obter mais informações, confira Diretrizes de dimensionamento automático.
Escalar horizontalmente de modo agressivo. Uma prática final seria escalar horizontalmente de modo agressivo para que você possa atender rapidamente a picos imediatos no tráfego sem perder negócios. E depois reduzir horizontalmente (ou seja, remover as instâncias desnecessárias) de modo conservador para manter o sistema estável. Uma forma simples de implementar isso é definir o período de resfriamento, que é o tempo de espera entre as operações de dimensionamento, como 5 minutos para adicionar recursos e como até 15 minutos para remover instâncias.
Repetição interna em serviços
Incentivamos a melhor prática de implementar operações de repetição programáticas em uma seção anterior. Tenha em mente que muitos serviços do Azure e seus SDKs cliente correspondentes também incluem mecanismos de repetição. A lista a seguir resume os recursos de repetição em muitos dos serviços do Azure que são discutidos neste livro:
Azure Cosmos DB. A classe DocumentClient da API do cliente repete automaticamente tentativas com falha. O número de repetições e o tempo máximo de espera são configuráveis. As exceções geradas pela API do cliente são solicitações que excedem a política de repetição ou erros não transitórios.
Cache Redis do Azure. O cliente Redis StackExchange usa uma classe do gerenciador de conexões que inclui repetições de tentativas com falha. O número de repetições, a política de repetição específica e o tempo de espera são configuráveis.
Barramento de Serviço do Azure. O cliente Barramento de Serviço expõe uma classe RetryPolicy que pode ser configurada com um intervalo de retirada, uma contagem de repetições e TerminationTimeBuffer, que especifica o tempo máximo que uma operação pode levar. A política padrão é de nove tentativas de repetição no máximo, com um período de retirada de 30 segundos entre as tentativas.
Banco de Dados SQL do Azure. O suporte à repetição é fornecido ao usar a biblioteca Entity Framework Core.
Armazenamento do Microsoft Azure. A biblioteca de clientes de armazenamento dá suporte a operações de repetição. As estratégias variam entre tabelas, blobs e filas do Armazenamento do Azure. Além disso, as repetições alternativas alternam entre locais de serviços de armazenamento primários e secundários quando o recurso de redundância geográfica está habilitado.
Hubs de Eventos do Azure. A biblioteca de clientes do Hub de Eventos apresenta uma propriedade RetryPolicy, que inclui um recurso de retirada exponencial configurável.