Identificar informações confidenciais e de segurança classificadas para a conformidade do Governo Australiano com o PSPF
Este artigo fornece orientações para organizações do Governo Australiano sobre a utilização do Microsoft Purview para identificar informações confidenciais e classificadas de segurança. O seu objetivo é ajudar essas organizações a reforçar a sua abordagem em matéria de segurança de dados e a sua capacidade de cumprir os requisitos descritos no Framework de Políticas de Segurança De Proteção (PSPF) e no Manual de Segurança da Informação (ISM).
A chave para proteger as informações e protegê-la contra a perda de dados é compreender primeiro quais são as informações. Este artigo explora métodos de identificação de informações num ambiente de organizações do Microsoft 365. Estas abordagens são frequentemente referidas como os aspetos conhecidos dos seus dados do Microsoft Purview. Depois de identificadas, as informações podem ser protegidas através da etiquetagem automática de confidencialidade e da Prevenção de Perda de Dados (DLP).
Tipos de informações confidenciais
Os tipos de informações confidenciais (SITs) são classificadores baseados em padrões. Detetam informações confidenciais através de expressões regulares (RegEx) ou palavras-chave.
Existem muitos tipos diferentes de SITs que são relevantes para as organizações do Governo Australiano:
- O SITS pré-criado criado pela Microsoft, vários dos quais estão alinhados com tipos de dados australianos comuns.
- Os SITs personalizados são criados com base nos requisitos organizacionais.
- Os SITs de entidades nomeadas incluem identificadores complexos baseados em dicionários, como endereços físicos australianos.
- Os SITs de Correspondência de Dados Exata (EDM) são gerados com base em dados confidenciais reais.
- Os SITs de impressão digital do documento baseiam-se no formato dos documentos e não nos respetivos conteúdos.
- Os SITs relevantes para a segurança da rede ou da informação , embora tecnicamente pré-criados SITs, têm especial relevância para as equipas cibernéticas que trabalham para organizações do Governo Australiano, pelo que são dignos da sua própria categoria.
Tipos de Informações Confidenciais Pré-criados
Os tipos de informações confidenciais pré-criados baseiam-se em tipos comuns de informações que os clientes normalmente consideram confidenciais. Estes podem ser genéricos e ter relevância global (por exemplo, números de card de crédito) ou ter relevância local (por exemplo, números de contas bancárias australianas).
A lista completa de SITs Pré-criados da Microsoft pode ser encontrada em definições de entidades de tipo de informações confidenciais
Os SITs específicos australianos incluem:
- Número de conta bancária australiana
- Número de carta de condução australiana
- Número de passaporte australiano
- Endereços físicos australianos
- Número de ficheiro fiscal australiano
- Número de negócio australiano
- Número da empresa australiana
- Número da conta médica australiana
Estes SITs podem ser encontrados no portal de classificação de Dados do Microsoft Purview, emTipos de informações confidenciaisdos Classificadores>.
Os SITs pré-criados são valiosos para as organizações que iniciam a sua Proteção de Informações ou o Percurso de Governação, uma vez que fornecem um guia para a ativação de capacidades como dLP e etiquetagem automática. As duas formas mais fáceis de utilizar estes SITs são:
Utilização de SITs pré-criados através de modelos de política DLP
Alguns SITs pré-criados estão incluídos em modelos de política DLP criados pela Microsoft que se alinham com os regulamentos australianos. Os seguintes modelos de política DLP que se alinham com os requisitos australianos estão disponíveis para utilização:
- Australia Privacy Act Enhanced
- Dados Financeiros da Austrália
- Padrão de Segurança de Dados PCI (PCI DSS)
- Dados de Informações Identificáveis Pessoalmente (PII) da Austrália
A ativação de políticas DLP baseadas nestes modelos permite a monitorização inicial de eventos de perda de dados, que constituem um excelente ponto de partida para as organizações que introduzem o DLP do Microsoft 365. Depois de implementadas, estas políticas fornecem informações sobre a extensão de um problema de perda de dados das organizações e podem ajudar a impulsionar decisões nos próximos passos.
A utilização destes modelos de política é ainda mais explorada na limitação da distribuição de informações confidenciais.
Utilização de SITs pré-criados na etiquetagem automática de confidencialidade
Se um item for detectado para conter um número de conta médica australiana, um ou mais termos médicos e um nome completo, então pode ser justo assumir que o item contém informações médicas pessoalmente identificáveis e pode constituir um registo de saúde. Com base neste pressuposto, podemos sugerir a um utilizador que o item seja identificado como "OFICIAL: Privacidade Pessoal Confidencial" ou qualquer etiqueta mais adequada na sua organização para identificação e proteção de registos de estado de funcionamento.
Para obter mais informações em que esta funcionalidade pode ajudar as Organizações Governamentais a cumprir a conformidade com o PSPF, veja a aplicação automática de etiquetas de confidencialidade e cenários de etiquetagem automática com base no cliente para o Governo australiano.
Tipos de Informações Confidenciais Personalizados
Além dos SITs pré-criados, as organizações podem criar SITs com base nas suas próprias definições de informações confidenciais. Exemplos de informações relevantes para organizações do Governo Australiano que podem ser identificadas através do SIT personalizado são:
- Marcas de proteção
- ID de Desalfandegamento ou ID da aplicação Desalfandegamento
- Classificações de outros estados ou territórios
- Classificações que não devem ser apresentadas na plataforma (por exemplo, SEGREDO MÁXIMO)
- Briefings ou correspondência dos ministros
- Número do Pedido de Liberdade de Informação (FOI)
- Informações relacionadas com a probidade
- Termos relacionados com sistemas, projetos ou aplicações confidenciais
- Marcas de parágrafo
- Cortar ou Criar números de registo de objetivos
Os SITs personalizados são compostos por um identificador principal, que pode ser baseado numa Expressão Regular ou palavras-chave, nível de confiança e elementos de suporte opcionais.
Para obter uma explicação mais detalhada dos SITs e dos respetivos componentes, veja Saiba mais sobre os tipos de informações confidenciais.
Expressões Regulares (RegEx)
As expressões regulares são identificadores baseados em código que podem ser utilizados para identificar padrões de informações. Por exemplo, se um número de Liberdade de Informação (FOI) fosse constituído pelas letras seguidas FOI de um ano de quatro dígitos, um hífen e mais três dígitos (por exemplo, FOI2023-123), poderia ser representado numa expressão regular de:
[Ff][Oo][Ii]20[01234]\d{1}-\d{3}
Para explicar esta expressão:
-
[Ff][Oo][Ii]corresponde às letras maiúsculas ou minúsculas F, O e I. -
20corresponde ao número 20 como a primeira metade de um ano de quatro dígitos. -
[0123]corresponde a 0, 1, 2 ou 3 no terceiro dígito no nosso valor de ano de quatro dígitos, o que nos permite corresponder aos números da FOI do ano 2000 até 2039. -
-corresponde a um hífen. -
\d{3}corresponde a qualquer três dígitos.
Dica
O Copilot é bastante adepto na geração de expressões regulares (RegEx). Pode utilizar linguagem natural para pedir ao Copilot para gerar o RegEx por si.
Lista de palavras-chave ou um dicionário de palavra-chave
As listas de palavras-chave e dicionários consistem em palavras, termos ou expressões que provavelmente serão incluídos nos itens que procura identificar. briefing cab ou aplicação de concurso são termos que podem ser úteis como palavras-chave.
As palavras-chave podem ser sensíveis a maiúsculas e minúsculas ou não são sensíveis a maiúsculas e minúsculas. O caso pode ser útil na eliminação de falsos positivos. Por exemplo, é mais provável que as minúsculas sejam utilizadas em conversações gerais, official mas maiúsculas OFFICIAL têm uma maior probabilidade de fazer parte de uma marcação protetora.
Os dicionários de palavras-chave que contêm grandes conjuntos de dados também podem ser carregados através do formato CSV ou TXT . Para obter mais informações sobre como carregar um dicionário palavra-chave, veja como criar um dicionário palavra-chave.
Nível de confiança
Algumas palavras-chave ou expressões regulares podem fornecer uma correspondência precisa sem necessidade de refinamento. É pouco provável que a expressão Freedom of Information (FOI) incluída no exemplo anterior de um valor apareça numa conversação geral e, quando aparece em correspondência, é provável que corresponda a informações relevantes. No entanto, se estávamos a tentar corresponder ao número de um funcionário do Serviço Público Australiano, que é representado como oito dígitos numéricos, é provável que a nossa correspondência resulte em inúmeros falsos positivos. O nível de confiança permite-nos atribuir uma probabilidade de que a presença do palavra-chave ou padrão num item, como um e-mail ou documento, seja realmente o que procuramos. Para obter mais informações sobre os níveis de confiança, veja Gerir níveis de confiança.
Elementos principais e de suporte
Os SITs personalizados também têm um conceito de elementos principais e de suporte. O elemento principal é o padrão chave que queremos detetar no conteúdo. Os elementos de suporte podem ser adicionados a um principal para criar um caso para a ocorrência de um valor ser uma correspondência exata. Por exemplo, se tentarmos corresponder com base num número de funcionário de oito dígitos numéricos, podemos utilizar palavras-chave de "número de funcionário" ou Número AGSdo Governo Australiano ou Base APSED de Dados de Funcionários do Serviço Público Australiano como um elemento de suporte para aumentar a confiança de que a correspondência é relevante. Para obter mais informações sobre como criar elementos principais e de suporte, veja Compreender os elementos.
Proximidade de carateres
O valor final que geralmente configuraríamos num SIT é a proximidade de carateres. Esta é a distância entre os elementos primários e de suporte. Se esperarmos que o palavra-chave AGS esteja próximo do nosso valor numérico de oito dígitos, configuramos uma proximidade de 10 carateres. Se não for provável que os elementos principais e de suporte apareçam ao lado uns dos outros, definimos o valor de proximidade como um maior número de carateres. Para obter mais informações sobre como criar a proximidade de carateres, veja Compreender a proximidade.
SITs para identificar marcas de proteção
Uma forma valiosa para as organizações do Governo australiano utilizarem SITs personalizados é identificar marcas de proteção. Numa organização greenfield, todos os itens num ambiente têm uma etiqueta de confidencialidade aplicada aos mesmos. No entanto, a maioria das organizações governamentais tem etiquetas legadas que requerem modernização para o Microsoft Purview. Os SITs são utilizados para identificar e aplicar marcas a:
- Ficheiros legados marcados
- Ficheiros marcados gerados por entidades externas
- Email conversações iniciadas e marcadas externamente
- E-mails que perderam as informações da etiqueta (cabeçalhos de x)
- E-mails, que tiveram as suas etiquetas incorretamente desvalorizadas
Quando este marcador é identificado, o utilizador é avisado da deteção e é-lhe fornecida uma recomendação de etiqueta. Se aceitarem a recomendação, as proteções baseadas em etiquetas aplicam-se ao item. Estes conceitos são abordados em cenários de etiquetagem automática com base no cliente para o Governo australiano.
Os SITs baseados na classificação também são úteis no DLP. Os exemplos incluem:
- Um utilizador recebe informações e identifica-as como confidenciais através da marcação, mas não quer reclassificá-la, uma vez que não se traduz numa classificação PSPF (por exemplo, "GOVERNO NSP Confidencial OFICIAL"). Construir uma política DLP para proteger as informações incluídas com base na marcação em vez da etiqueta aplicada significa que podemos aplicar uma medida de segurança de dados à mesma.
- Um utilizador copia texto de uma conversação por e-mail, que inclui uma marcação protetora. Colam as informações numa conversa do Teams com um participante externo que não deve ter acesso às informações. Através de uma política DLP que se aplica ao serviço Teams, a marcação pode ser detetada e a divulgação impedida.
- Um utilizador reduz incorretamente uma etiqueta de confidencialidade numa conversação de e-mail (maliciosamente ou por erro do utilizador). Uma vez que as marcas de proteção foram aplicadas ao e-mail anteriormente visíveis no corpo do e-mail, o Microsoft Purview deteta que as marcas atuais e anteriores estão desalinhadas. Dependendo da configuração, a ação regista o evento, avisa o utilizador ou bloqueia o e-mail.
- Um e-mail marcado é enviado para um destinatário externo que está a utilizar um cliente ou plataforma de e-mail nonenterprise. A plataforma ou cliente remove os metadados do e-mail (cabeçalhos x), o que faz com que o e-mail de resposta do destinatário externo não tenha uma etiqueta de confidencialidade aplicada quando chega à caixa de correio do utilizador da organização. A deteção da marcação anterior através de um SIT permite a replicação da etiqueta de forma transparente ou recomenda que o utilizador volte a aplicar a etiqueta na resposta seguinte.
Em cada um destes cenários, os SITs baseados na classificação podem ser utilizados para detetar marcas de proteção aplicadas e mitigar a potencial falha de segurança de dados.
Sintaxe SIT de exemplo para detetar marcas de proteção
As seguintes expressões regulares podem ser utilizadas em SITs personalizados para identificar marcas de proteção.
Importante
A criação de SITs para identificar marcas de proteção ajuda na conformidade PSPF. Os SITs baseados na classificação também são utilizados em cenários de DLP e de etiquetagem automática.
| Nome SIT | Expressão regular |
|---|---|
| Regex1 NÃO OFICIAL | UNOFFICIAL |
| OFICIAL Regex1,2 | (?<!UN)OFFICIAL |
| OFFICIAL Sensitive Regex1,3,4,5 | OFFICIAL[:- ]\s?Sensitive(?!(?:\s\|\/\/\|\s\/\/\s)[Pp]ersonal[- ][Pp]rivacy)(?!(?:\s\|\/\/\|\s\/\/\s)[Ll]egislative[- ][Ss]ecrecy)(?!(?:\s\|\/\/\|\s\/\/\s)[Ll]egal[- ][Pp]rivilege)(?!(?:\s\|\/\/\|\s\/\/\s)NATIONAL[ -]CABINET) |
| OFICIAL Confidencial Privacidade Pessoal Regex1,4,5 | OFFICIAL[:- ]\s?Sensitive(?:\s\|\/\/\|\s\/\/\s\|,\sACCESS=)Personal[ -]Privacy |
| OFFICIAL Sensitive Legal Privilege Regex1,4,5 | OFFICIAL[:- ]\s?Sensitive(?:\s\|\/\/\|\s\/\/\s\|,\sACCESS=)Legal[ -]Privilege |
| OFICIAL Confidencial Sigilo Legislativo Regex1,4,5 | OFFICIAL[:- ]\s?Sensitive(?:\s\|\/\/\|\s\/\/\s\|,\sACCESS=)Legislative[ -]Secrecy |
| OFICIAL Confidencial NATIONAL CABINET Regex1,4,5 | OFFICIAL[:- ]\s?Sensitive(?:\s\|\/\/\|\s\/\/\s\|,\sCAVEAT=SH:)NATIONAL[ -]CABINET |
| Regex PROTEGIDO1,3,5 | PROTECTED(?!,\sACCESS=)(?!(?:\s\|\/\/\|\s\/\/\s)[Pp]ersonal[- ][Pp]rivacy)(?!(?:\s\|\/\/\|\s\/\/\s)[Ll]egislative[- ][Ss]ecrecy)(?!(?:\s\|\/\/\|\s\/\/\s)[Ll]egal[- ][Pp]rivilege)(?!(?:\s\|\/\/\|\s\/\/\s)NATIONAL[ -]CABINET)(?!(?:\s\|\/\/\|\s\/\/\s)CABINET) |
| Proteção da Privacidade Pessoal Regex1,5 | PROTECTED(?:\s\|\/\/\|\s\/\/\s\|,\sACCESS=)Personal[ -]Privacy |
| PROTECTED Legal Privilege Regex1,5 | PROTECTED(?:\s\|\/\/\|\s\/\/\s\|,\sACCESS=)Legal[ -]Privilege |
| Protegido Sigilo Legislativo Regex1,5 | PROTECTED(?:\s\|\/\/\|\s\/\/\s\|,\sACCESS=)Legislative[ -]Secrecy |
| PROTECTED NATIONAL CABINET Regex1,5 | PROTECTED(?:\s\|\/\/\|\s\/\/\s\|,\sCAVEAT=SH:)NATIONAL[ -]CABINET |
| PROTECTED CABINET Regex1,5 | PROTECTED(?:\s\|\/\/\|\s\/\/\s\|,\sCAVEAT=SH:)CABINET |
Ao avaliar os exemplos anteriores do SIT, tenha em atenção a seguinte lógica de expressão:
- 1 Estas expressões correspondem às marcações aplicadas a ambos os documentos (por exemplo, OFICIAL: GABINETE NACIONAL Confidencial) e e-mail (por exemplo, "[SEC=OFICIAL:Confidencial, CAVEAT=NATIONAL-CABINET]").
-
2 O aspeto negativo no Regex OFICIAL (
(?<!UN)) impede que os itens NÃO OFICIAIS sejam correspondidos como OFICIAL. -
3OFFICIAL Sensitive Regex and PROTECTED Regex use negative lookaheads (
(?!)) to ensure that an Information Management Markers (IMM) or caveat is t applied after the security classification. Isto ajuda a impedir que itens com MI ou avisos sejam identificados como a versão não IMM ou de aviso da classificação. -
4 A utilização de
[:\- ]em OFICIAL: Confidencial destina-se a permitir flexibilidade no formato desta marcação e é importante devido à utilização de dois carateres em cabeçalhos x. -
5
(?:\s\|\/\/\|\s\/\/\s)é utilizado para identificar o espaço entre os componentes de marcação e permite espaço único, espaço duplo, barra dupla ou barra dupla com espaços. Isto destina-se a permitir as diferentes interpretações do formato de marcação PSPF que existe entre organizações do Governo Australiano.
Tipos de informações confidenciais de entidades nomeadas
Os SITs de entidades nomeadas são identificadores complexos baseados em padrões e dicionários criados pela Microsoft, que podem ser utilizados para detetar informações como:
- nomes de Pessoas
- Endereços físicos
- Termos e condições médicos
Os SITs de entidades nomeadas podem ser utilizados isoladamente, mas também podem ser valiosos como elementos de suporte. Por exemplo, um termo médico existente num e-mail pode não ser útil como indicação de que o item contém informações confidenciais. No entanto, um termo médico quando emparelhado com um valor que possa indicar um número de cliente ou paciente e um nome próprio e familiar, forneceria uma indicação forte de que o item é sensível.
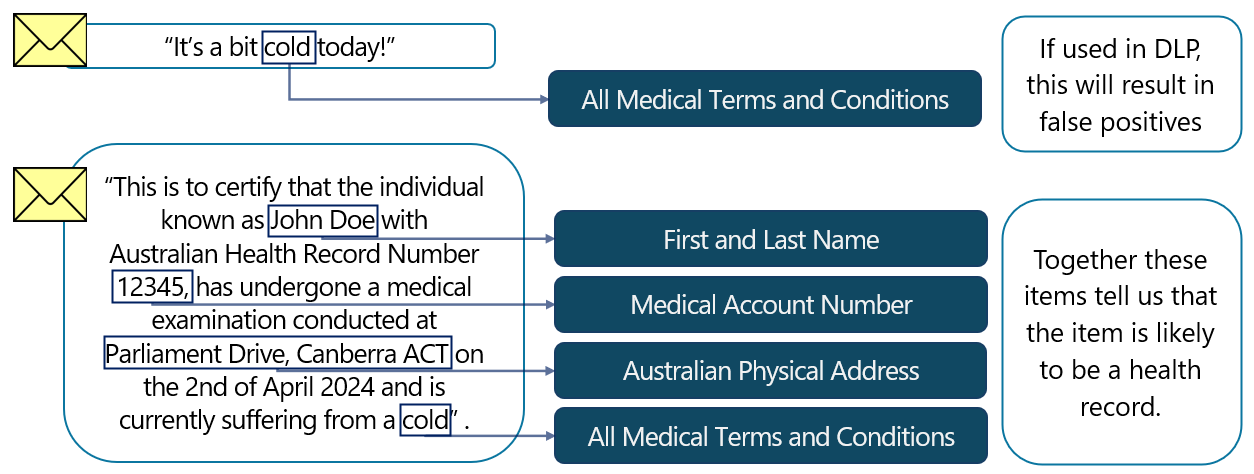
Os SITs de entidades nomeadas podem ser emparelhados com SITs personalizados, utilizados como elementos de suporte ou até incluídos com outros SITs em políticas DLP.
Para obter mais informações sobre SITs de entidades nomeadas, veja Saiba mais sobre as entidades nomeadas.
Os dados exatos correspondem a tipos de informações confidenciais
Os SITs de Correspondência de Dados Exata (EDM) são gerados com base nos dados reais. Os valores numéricos, como os IDs de cliente numéricos, são difíceis de corresponder através de SITs padrão devido a choques com outros valores numéricos, como números de telefone. Os elementos de suporte que melhoram a correspondência ajudam a reduzir os falsos positivos.
A Correspondência de Dados Exata ajuda as organizações do Governo australiano que têm sistemas que contêm dados relacionados com funcionários, clientes ou cidadãos para identificar com precisão estas informações.
Para obter mais informações sobre a implementação de SITs EDM, veja saiba mais sobre os tipos de informações confidenciais baseados na correspondência de dados exatas.
Impressão digital de documento
A Identificação de Impressões Digitais de Documentos é uma técnica de identificação de informações que, em vez de procurar valores contidos num item, analisa o formato e a estrutura do item. Essencialmente, isto permite-nos converter um formulário padrão num tipo de informação confidencial que pode ser utilizado para identificar informações.
As organizações governamentais podem utilizar o método de identificação de conteúdos para identificação de impressões digitais de documentos para identificar itens que tenham sido gerados através de um fluxo de trabalho ou formulários submetidos por outras organizações ou membros do público.
Para obter informações sobre a implementação de impressões digitais de documentos, veja identificação digital do documento.
Tipos de informações confidenciais relacionadas com a rede ou a segurança
Existem inúmeras utilizações para SITs para além da identificação de informações confidenciais ou confidenciais de segurança. Uma dessas utilizações é a deteção de credenciais. Os SITs pré-criados são fornecidos para os seguintes tipos de credenciais:
- Credenciais de início de sessão do utilizador
- Microsoft Entra ID tokens de acesso de cliente
- Lote do Azure chaves de acesso partilhado
- Assinaturas de acesso partilhado da conta de Armazenamento do Azure
- Segredo do cliente/chaves de API
Estes SITs pré-criados são utilizados de forma independente e também são agrupados num SIT denominado Todas as credenciais.O SIT de todas as credenciais é útil para equipas cibernéticas que as utilizam em:
- Políticas DLP para identificar e impedir movimentos laterais por utilizadores maliciosos ou atacantes externos.
- Políticas de etiquetagem automática, para aplicar encriptação a itens que não devem conter credenciais, bloquear os utilizadores fora dos ficheiros e permitir o início das ações de remediação.
- Políticas DLP para impedir que os utilizadores partilhem as suas credenciais com outros utilizadores em relação às políticas da organização.
- Para realçar itens armazenados em localizações do SharePoint ou do Exchange, que estão a reter inadequadamente informações de credenciais.
Os SITs pré-criados também existem para endereços de rede (IPv4 e IPv6) e são úteis para proteger itens que contêm informações de rede ou impedir que os utilizadores partilhem endereços IP por e-mail, chat do Teams ou mensagens de canal.
Classificadores treináveis
Os classificadores treináveis são modelos de machine learning que podem ser preparados para reconhecer informações confidenciais. Tal como acontece com os SITs, a Microsoft fornece classificadores pré-preparados. Uma extração de classificadores pré-preparados relevantes para as organizações do Governo Australiano está listado na seguinte tabela:
| Categoria do Classificador | Classificadores Treináveis de Exemplo |
|---|---|
| Financeiro | Extratos bancários, orçamento, relatórios de auditoria financeira, demonstrações financeiras, impostos, extrato de contas, Estimativas Orçamentais (BE), Declaração de Atividade Empresarial (BAS). |
| Business | Procedimentos operacionais, acordos de não divulgação, aprovisionamento, palavras de código do projeto, Estimativas do Senado (SE), Perguntas sobre Aviso (QoNs). |
| Recursos humanos | Currículos, ficheiros de ação disciplinar de funcionários, contrato de trabalho, autorizações da Agência Australiana de Verificação de Segurança do Governo (AGSVA), Programa de Empréstimos ao Ensino Superior (HELP), ID militar, Autorização de Trabalho Estrangeiro (FWA). |
| Médicos | Cuidados de saúde, formulários médicos, MyHealth Record. |
| Jurídico | Assuntos jurídicos, contratos, contratos de licença. |
| Técnico | Ficheiros de desenvolvimento de software, documentos de projeto, ficheiros de estrutura de rede. |
| Comportamental | linguagem ofensiva, profanação, ameaça, assédio direcionado, discriminação, conluio regulamentar, queixa do cliente. |
Alguns exemplos de como as organizações governamentais podem utilizar estes classificadores pré-criados incluem:
- As regras de negócio podem ditar que alguns itens na categoria de RH, como currículos, devem ser marcados como "OFICIAL: Privacidade Pessoal Confidencial" porque contêm informações pessoais confidenciais. Para estes itens, uma recomendação de etiqueta pode ser configurada através da etiquetagem automática baseada no cliente.
- Os ficheiros de design de rede, especialmente para redes seguras, devem ser tratados cuidadosamente para evitar compromissos. Estes podem ser dignos de uma etiqueta PROTECTED ou, pelo menos, de políticas DLP que impedem a divulgação não autorizada a utilizadores não autorizados.
- Os classificadores comportamentais são interessantes e, embora possam não ter uma correlação direta com marcas de proteção ou requisitos de DLP, ainda podem ter um valor comercial elevado. Por exemplo, as equipas de RH podem ser notificadas de ocorrências de assédio e/ou fornecidas com a capacidade de rastrear a correspondência sinalizada através da Conformidade de Comunicações.
As organizações também podem preparar os seus próprios classificadores. Os classificadores podem ser preparados ao fornecer-lhes conjuntos de amostras positivas e negativas. O classificador processa os exemplos e cria um modelo de predição. Quando a preparação estiver concluída, os classificadores podem ser utilizados para a aplicação de etiquetas de confidencialidade, políticas de conformidade de comunicações e políticas de etiquetagem de retenção. A utilização de classificadores em políticas DLP está disponível em pré-visualização.
Para obter mais informações sobre classificadores treináveis, consulte Saiba mais sobre classificadores treináveis.
Utilizar informações confidenciais identificadas
Assim que as informações forem identificadas através do SIT ou do classificador (através dos aspetos conhecidos dos seus dados do Microsoft Purview), podemos utilizar estes conhecimentos para nos ajudar na conclusão dos outros três pilares da gestão de informações do Microsoft 365, nomeadamente:
- Proteja os seus dados,
- Evitar a perda de dados e
- Controlar os seus dados.
A tabela seguinte fornece vantagens e exemplos de como o conhecimento de um item que contém informações confidenciais pode ajudar na gestão das informações na plataforma do Microsoft 365:
| Recursos | Exemplo de utilização |
|---|---|
| Prevenção contra Perda de Dados | Ajuda na gestão ao reduzir os riscos de transposição de dados. |
| Etiquetagem de confidencialidade | Recomenda a aplicação da etiqueta de confidencialidade adequada. Depois de etiquetadas, as proteções relacionadas com etiquetas aplicam-se às informações. |
| Etiquetagem de retenção | Aplica automaticamente uma etiqueta de retenção, permitindo que os requisitos de gestão de arquivos ou registos sejam cumpridos. |
| Explorer de conteúdo | Veja onde os itens que contêm informações confidenciais residem nos serviços do Microsoft 365, incluindo o SharePoint, Teams, OneDrive e Exchange. |
| Gerenciamento de riscos internos | Monitorize a atividade do utilizador em torno de informações confidenciais, estabeleça um nível de risco de utilizador com base no comportamento e aumente o comportamento suspeito para as equipas relevantes. |
| Conformidade em comunicações | Filtrar correspondência de alto risco, incluindo qualquer chat ou e-mail que contenha conteúdo confidencial ou suspeito. A conformidade com a comunicação pode ajudar a garantir que as obrigações de probidade são cumpridas pelo Governo australiano. |
| Microsoft Priva | Detete o armazenamento de informações confidenciais, incluindo dados pessoais em localizações como o OneDrive, e oriente os utilizadores em torno do armazenamento correto de informações. |
| Descoberta eletrônica | As informações confidenciais do Surface fazem parte dos processos de RH ou FOI e aplicam retenções a informações que podem fazer parte de um pedido ou investigação ativo. |
Explorer de conteúdo
O explorador de conteúdos do Microsoft 365 permite que os seus responsáveis pela conformidade, segurança e privacidade obtenham informações rápidas, mas abrangentes, sobre onde residem informações confidenciais num ambiente do Microsoft 365. Esta ferramenta permite que os utilizadores autorizados procurem localizações e itens por tipo de informação. O serviço indexa e apresenta itens que residem no Exchange, OneDrive e SharePoint. Os itens localizados nos sites de equipa do SharePoint subjacentes do Teams também estão visíveis.
Através desta ferramenta, podemos selecionar um tipo de informação confidencial ou etiqueta de confidencialidade, ver o número de itens alinhados com o mesmo em cada um dos serviços do Microsoft 365:
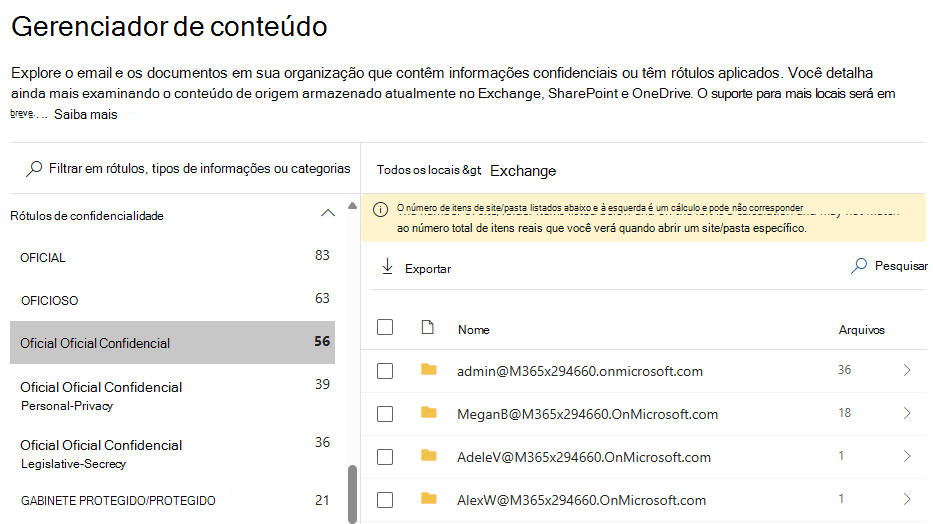
O explorador de conteúdos pode fornecer informações valiosas sobre as localizações onde os itens confidenciais ou confidenciais de segurança residem num ambiente. É pouco provável que essa vista consolidada na localização das informações seja possível através de sistemas no local.
Para as organizações que incluem etiquetas que não são permitidas na conta da organização (por exemplo, SECRET ou TOP SECRET) juntamente com as políticas de etiquetagem automática associadas para aplicar as etiquetas, o explorador de conteúdos pode encontrar informações que não devem ser armazenadas na plataforma. Como o explorador de conteúdos também pode surface SITs, uma abordagem semelhante poderia ser alcançada através de SITs para identificar marcas de proteção.
Para obter mais informações sobre o Content Explorer, consulte Introdução ao explorador de conteúdos.