Solucionar problemas de pool de SQL sem servidor no Azure Synapse Analytics
Este artigo contém informações sobre como solucionar os problemas mais frequentes com o pool de SQL sem servidor no Azure Synapse Analytics.
Para saber mais sobre o Azure Synapse Analytics, confira os tópicos na Visão geral.
Synapse Studio
O Synapse Studio é uma ferramenta fácil de usar que você pode usar para acessar seus dados usando um navegador sem a necessidade de instalar ferramentas de acesso ao banco de dados. O Synapse Studio não foi desenvolvido para ler um grande conjunto de dados ou realizar um gerenciamento completo de objetos do SQL.
O pool de SQL sem servidor está esmaecido no Synapse Studio
Se o Synapse Studio não puder estabelecer uma conexão com o pool de SQL sem servidor, você observará que o pool de SQL sem servidor fica esmaecido ou mostra o status Offline.
Normalmente, esse problema ocorre por um dos dois motivos:
- Sua rede impede a comunicação com o back-end do Azure Synapse Analytics. O caso mais frequente é o bloqueio da porta TCP 1443. Para que o pool de SQL sem servidor funcione, desbloqueie essa porta. Outros problemas também podem impedir o funcionamento do pool de SQL sem servidor. Para obter mais informações, confira o Guia de solução de problemas.
- Você não tem permissão para entrar no pool de SQL sem servidor. Para obter acesso, um dos administradores do workspace do Azure Synapse deve adicionar você à função de administrador do workspace ou de administrador do SQL. Para saber mais, confira Controle de acesso do Azure Synapse.
Conexão WebSocket fechada inesperadamente
Sua consulta pode falhar com a mensagem de erro Websocket connection was closed unexpectedly. Essa mensagem significa que a conexão do navegador com o Synapse Studio foi interrompida, por exemplo, devido a um problema de rede.
- Para resolver esse problema, execute sua consulta novamente.
- Tente o Azure Data Studio ou o SQL Server Management Studio em vez de insistir no Synapse Studio para investigar com mais detalhes.
- Se essa mensagem ocorrer com frequência em seu ambiente, peça ajuda ao seu administrador de rede. Você também pode verificar as configurações de firewall e consultar o Guia de solução de problemas.
- Se o problema continuar, crie um tíquete de suporte pelo portal do Azure.
Bancos de dados sem servidor não são exibidos no Synapse Studio
Caso não veja os bancos de dados criados no pool de SQL sem servidor, verifique para conferir se ele foi iniciado. Se o pool de SQL sem servidor estiver desativado, os bancos de dados não serão exibidos. Execute qualquer consulta, por exemplo, SELECT 1, no pool de SQL sem servidor para ativá-la e exibir os bancos de dados.
O pool de SQL sem servidor do Synapse é exibido como indisponível
Geralmente, a causa desse comportamento é a configuração de rede incorreta. Verifique se as portas estão configuradas corretamente. Se você usar um firewall ou pontos de extremidade privados, verifique também essas configurações.
Por fim, certifique-se de que as funções apropriadas tenham sido concedidas e não tenham sido revogadas.
Não é possível criar um novo banco de dados, pois a solicitação usará a chave antiga/expirada
Esse erro é causado pela alteração da chave gerenciada pelo cliente do espaço de trabalho usada para criptografia. Você pode optar por criptografar novamente todos os dados no espaço de trabalho com a versão mais recente da chave ativa. Para criptografar novamente, altere a chave no portal do Azure para uma chave temporária e, em seguida, volte para a chave que você deseja usar para criptografia. Saiba aqui como gerenciar as chaves do espaço de trabalho.
O pool de SQL sem servidor do Synapse está indisponível após a transferência de uma assinatura para outro locatário do Microsoft Entra
Se você moveu uma assinatura para outro locatário do Microsoft Entra, talvez tenha alguns problemas com o pool de SQL sem servidor. Crie um ticket de suporte e o suporte do Azure entrará em contato com você para resolver o problema.
Acesso de armazenamento
Se receber erros ao tentar acessar os arquivos no armazenamento do Azure, verifique se você tem a permissão para acessar dados. Você deve ser capaz de acessar os arquivos disponíveis publicamente. Se você tentar acessar dados sem credenciais, verifique se sua identidade do Microsoft Entra permite acessar diretamente os arquivos.
Caso tenha uma chave de assinatura de acesso compartilhado que deve ser usada para acessar arquivos, verifique se você criou uma credencial no nível do servidor ou no escopo do banco de dados que contenha essa credencial. As credenciais serão necessárias caso você precise acessar dados usando a identidade gerenciada do workspace e o SPN (nome da entidade de serviço) personalizado.
Não é possível ler, listar ou acessar arquivos no Azure Data Lake Storage
Se você usar um logon do Microsoft Entra sem credenciais explícitas, verifique se sua identidade do Microsoft Entra consegue acessar os arquivos no armazenamento. Para acessar os arquivos, sua identidade do Microsoft Entra deve ter a permissão Leitor de Dados do Blob ou permissões para Listar e LerACL (listas de controle de acesso) no ADLS. Para obter mais informações, confira Falha na consulta porque o arquivo não pode ser aberto.
Se você acessar o armazenamento usando as credenciais, verifique se a Identidade gerenciada ou o SPN tem uma função de Leitor de Dados ou Colaborador ou permissões específicas de ACL. Se você usou um token de assinatura de acesso compartilhado, verifique se ele tem permissão de rl e se ainda não expirou.
Caso você use um logon do SQL e a função OPENROWSETsem uma fonte de dados, verifique se tem uma credencial de nível de servidor que corresponda ao URI de armazenamento e tenha permissão para acessar o armazenamento.
A consulta falha porque o arquivo não pode ser aberto
Se a consulta falhar com o erro File cannot be opened because it does not exist or it is used by another process e você tiver certeza de que os dois arquivos existem e não estão sendo usados por outro processo, o pool de SQL sem servidor não poderá acessar o arquivo. Esse problema geralmente ocorre porque a identidade do Microsoft Entra não tem direitos para acessar o arquivo ou porque um firewall está bloqueando o acesso ao arquivo.
Por padrão, o pool de SQL sem servidor tenta acessar o arquivo usando a identidade do Microsoft Entra. Para resolver esse problema, você precisa ter os direitos apropriados para acessar o arquivo. A maneira mais fácil é conceder a si mesmo a função de Colaborador de Dados de Blob de Armazenamento na conta de armazenamento que você está tentando consultar.
Para saber mais, veja:
- Controle de acesso do Microsoft Entra ID para armazenamento
- Controlar o acesso à conta de armazenamento para o pool de SQL sem servidor no Synapse Analytics
Alternativa para a função de Colaborador de dados de blob de armazenamento
Em vez de conceder a si mesmo a função de Colaborador de Dados de Blob de Armazenamento, você também pode conceder permissões mais granulares em um subconjunto de arquivos.
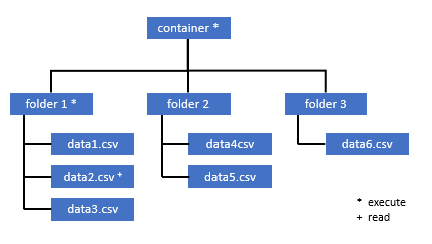
Todos os usuários que precisem acessar alguns dados nesse contêiner também devem ter a permissão EXECUTAR em todas as pastas pai até a raiz (o contêiner).
Saiba mais sobre como definir ACLs no Azure Data Lake Storage Gen2.
Observação
A permissão Executar no nível de contêiner precisa ser definida dentro do Azure Data Lake Storage Gen2. As permissões na pasta podem ser definidas no Azure Synapse.
Se você quiser consultar o data2.csv deste exemplo, as seguintes permissões são necessárias:
- Permissão Executar no contêiner
- Permissão Executar na pasta1
- Permissão Ler em data2.csv
Entre no Azure Synapse com um usuário administrador que tenha permissões completas para os dados que você deseja acessar.
No painel dados, clique com o botão direito do mouse no arquivo e selecione Gerenciar acesso.
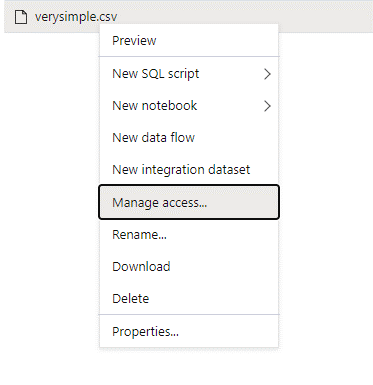
Selecione pelo menos a permissão Ler. Insira o UPN do usuário ou a ID do objeto, por exemplo,
user@contoso.com. Selecione Adicionar.Conceda permissão de leitura para este usuário.

Observação
Para usuários convidados, essa etapa precisa ser feita diretamente no Azure Data Lake, pois isso não pode ser feito diretamente por meio do Azure Synapse.
O conteúdo do diretório no caminho não pode ser listado
Esse erro indica que o usuário que está consultando o Azure Data Lake não pode listar os arquivos no armazenamento. Há vários cenários em que esse erro pode ocorrer:
- O usuário do Microsoft Entra que está usando a autenticação de passagem do Microsoft Entra não tem a permissão para listar os arquivos no Data Lake Storage.
- O usuário SQL ou do Microsoft Entra ID que está lendo dados usando uma chave de assinatura de acesso compartilhado ou identidade gerenciada de workspace e essa chave ou identidade não tem permissão para listar os arquivos no armazenamento.
- O usuário que está acessando dados do Dataverse não tem permissão para consultar dados no Dataverse. Esse cenário pode acontecer se você estiver usando usuários SQL.
- O usuário que está acessando o Delta Lake pode não ter permissão para ler o log de transações do Delta Lake.
A maneira mais fácil de resolver esse problema é conceder a si mesmo a função de Colaborador de Dados de Blob de Armazenamento na conta de armazenamento que você está tentando consultar.
Para saber mais, veja:
- Controle de acesso do Microsoft Entra ID para armazenamento
- Controlar o acesso à conta de armazenamento para o pool de SQL sem servidor no Synapse Analytics
O conteúdo da tabela do Dataverse não pode ser listado
Se você estiver usando o Link do Azure Synapse para o Dataverse para ler as tabelas vinculadas do DataVerse, será necessário usar a conta do Microsoft Entra para acessar os dados vinculados usando o pool de SQL sem servidor. Para obter mais informações, consulte Link do Azure Synapse para Dataverse com o Azure Data Lake.
Se você tentar usar um logon do SQL para ler uma tabela externa que faz referência à tabela do DataVerse, você receberá o seguinte erro: External table '???' is not accessible because content of directory cannot be listed.
As tabelas externas do Dataverse sempre usam a autenticação de passagem do Microsoft Entra. Você não pode configurá-las para usar uma chave de assinatura de acesso compartilhado ou uma identidade gerenciada do workspace.
O conteúdo do log de transações do Delta Lake não pode ser listado
O erro a seguir é retornado quando o pool de SQL sem servidor não pode ler a pasta do log de transações do Delta Lake:
Content of directory on path 'https://.....core.windows.net/.../_delta_log/*.json' cannot be listed.
Verifique se a pasta _delta_log existe. Talvez você esteja consultando arquivos Parquet sem formatação que não estão convertidos para o formato do Delta Lake. Se a pasta _delta_log existir, verifique se você tem permissão de Leitura e Lista nas pastas subjacentes do Delta Lake. Tente ler arquivos json diretamente usando FORMAT='csv'. Coloque o seu URI no parâmetro BULK:
select top 10 *
from openrowset(BULK 'https://.....core.windows.net/.../_delta_log/*.json',FORMAT='csv', FIELDQUOTE = '0x0b', FIELDTERMINATOR ='0x0b',ROWTERMINATOR = '0x0b')
with (line varchar(max)) as logs
Se essa consulta falhar, o chamador não terá permissão para ler os arquivos de armazenamento subjacentes.
Execução de consulta
Você pode receber erros durante a execução da consulta nos casos a seguir:
- O chamador não pode acessar alguns objetos.
- A consulta não pode acessar dados externos.
- A consulta contém algumas funcionalidades que não têm suporte em pools de SQL sem servidor.
A consulta falha porque não pode ser executada devido às restrições de recursos atuais
Sua consulta pode falhar com a mensagem de erro This query cannot be executed due to current resource constraints. Essa mensagem significa que o pool de SQL sem servidor não pode ser executado neste momento. Aqui estão algumas opções para solucionar problemas:
- Use tipos de dados de tamanhos razoáveis.
- Se a consulta tiver como destino arquivos Parquet, considere a possibilidade de definir tipos explícitos para colunas de cadeia de caracteres porque eles serão VARCHAR(8000) por padrão. Verifique os tipos de dados inferidos.
- Se a consulta for direcionada a arquivos CSV, considere a possibilidade de criar estatísticas.
- Para otimizar a sua consulta, veja as Melhores práticas de desempenho do pool de SQL sem servidor.
O tempo limite da consulta expirou
O erro Query timeout expired será retornado se a consulta tiver sido executada mais de 30 minutos no pool de SQL sem servidor. Esse limite para o pool de SQL sem servidor não pode ser alterado.
- Tente otimizar sua consulta aplicando as melhores práticas.
- Tente materializar partes de suas consultas usando CETAS (create external table as select).
- Verifique se há uma carga de trabalho simultânea em execução no pool de SQL sem servidor, porque as outras consultas podem usar os recursos. Nesse caso, é possível dividir a carga de trabalho em vários workspaces.
Nome de objeto inválido
O erro Invalid object name 'table name' indica que você está usando um objeto, como uma tabela ou exibição, que não existe no banco de dados do pool de SQL sem servidor. Tente estas opções:
Liste as tabelas ou exibições e verifique se o objeto existe. Use o SQL Server Management Studio ou o Azure Data Studio porque Synapse Studio pode exibir algumas tabelas que não estão disponíveis no pool de SQL sem servidor.
Se você vir o objeto, verifique se está usando algum agrupamento de banco de dados binário ou que diferencie maiúsculas de minúsculas. Talvez o nome do objeto não corresponda ao nome que você usou na consulta. Com um agrupamento de banco de dados binário,
Employeeeemployeesão dois objetos diferentes.Se você não vir o objeto, talvez esteja tentando consultar uma tabela de um banco de dados do Lake ou Spark. A tabela pode não estar disponível no pool de SQL sem servidor porque:
- A tabela tem alguns tipos de coluna que não podem ser representados no pool de SQL sem servidor.
- A tabela tem um formato que não tem suporte no pool de SQL sem servidor. Exemplos são o Avro ou o ORC.
Dados de cadeia de caracteres ou binários seriam truncados
Esse erro ocorrerá se o comprimento do tipo de coluna de cadeia de caracteres ou binária (por exemplo VARCHAR, VARBINARY ou NVARCHAR) for menor que o tamanho real dos dados que você está lendo. Você pode corrigir esse erro aumentando o comprimento do tipo de coluna:
- Se a coluna de cadeia de caracteres for definida como o tipo
VARCHAR(32)e o texto tiver 60 caracteres, use o tipoVARCHAR(60)(ou maior) no esquema de coluna. - Se você estiver usando a inferência de esquema (sem o esquema
WITH), todas as colunas de cadeia de caracteres serão definidas automaticamente como o tipoVARCHAR(8000). Se você estiver recebendo este erro, defina explicitamente o esquema em uma cláusulaWITHcom o tipo de coluna maiorVARCHAR(MAX)para resolver este erro. - Se a tabela estiver no banco de dados Lake, tente aumentar o tamanho da coluna de cadeia de caracteres no pool do Spark.
- Experimente
SET ANSI_WARNINGS OFFpara habilitar o pool de SQL sem servidor para truncar automaticamente os valores de VARCHAR, se isso não afetar suas funcionalidades.
Aspas não fechadas depois da cadeia de caracteres
Em alguns casos raros, quando você estiver usando o operador LIKE em uma coluna de cadeia de caracteres ou alguma comparação com os literais de cadeia de caracteres, poderá receber o seguinte erro:
Unclosed quotation mark after the character string
Esse erro talvez ocorra se você usar a ordenação Latin1_General_100_BIN2_UTF8 na coluna. Tente definir a ordenação Latin1_General_100_CI_AS_SC_UTF8 na coluna em vez da ordenação Latin1_General_100_BIN2_UTF8 para resolver o problema. Se o erro ainda for retornado, gere uma solicitação de suporte por meio do portal do Azure.
Não foi possível alocar espaço tempdb durante a transferência de dados de uma distribuição para outra
O erro Could not allocate tempdb space while transferring data from one distribution to another é retornado quando o mecanismo de execução da consulta não consegue processar os dados e transferi-los entre os nós que estão executando a consulta. É um caso especial do erro Falha na consulta genérica pois ela não pode ser executada devido às restrições de recurso atuais. Esse erro é retornado quando os recursos alocados ao banco de dados tempdb são insuficientes para executar a consulta.
Aplique as melhores práticas antes de registrar um tíquete de suporte.
A consulta falha com um erro ao manipular um arquivo externo (contagem máxima de erros atingida)
Se a consulta falhar com a mensagem de erro error handling external file: Max errors count reached, isso significa que há uma incompatibilidade de um tipo de coluna especificado e os dados que precisam ser carregados.
Para saber mais sobre o erro e quais linhas e colunas precisam ser examinadas, altere a versão do analisador de 2.0 para 1.0.
Exemplo
Se você quiser consultar o arquivo names.csv com esta Consulta 1, o pool de SQL sem servidor do Azure Synapse retornará com o seguinte erro: Error handling external file: 'Max error count reached'. File/External table name: [filepath]. Por exemplo:
O arquivo names.csv contém:
Id,first name,
1, Adam
2,Bob
3,Charles
4,David
5,Eva
Consulta 1:
SELECT
TOP 100 *
FROM
OPENROWSET(
BULK '[FILE-PATH OF CSV FILE]',
FORMAT = 'CSV',
PARSER_VERSION='2.0',
FIELDTERMINATOR =';',
FIRSTROW = 2
)
WITH (
[ID] SMALLINT,
[Text] VARCHAR (1) COLLATE Latin1_General_BIN2
)
AS [result]
Causa
Assim que a versão do analisador for alterada da versão 2.0 para a 1.0, as mensagens de erro ajudarão a identificar o problema. A nova mensagem de erro agora é Bulk load data conversion error (truncation) for row 1, column 2 (Text) in data file [filepath].
O truncamento informa você que o seu tipo de coluna é muito pequeno para se ajustar aos seus dados. O primeiro nome mais longo neste arquivo names.csv tem sete caracteres. O tipo de dados certo a ser usado deve ser pelo menos VARCHAR(7). O erro é causado por esta linha de código:
[Text] VARCHAR (1) COLLATE Latin1_General_BIN2
Alterar a consulta de acordo resolve o erro. Após a depuração, altere a versão do analisador para 2.0 novamente para obter o desempenho máximo.
Para saber mais sobre quando usar qual versão do analisador, consulte Usar OPENROWSET usando o pool de SQL sem servidor no Synapse Analytics.
SELECT
TOP 100 *
FROM
OPENROWSET(
BULK '[FILE-PATH OF CSV FILE]',
FORMAT = 'CSV',
PARSER_VERSION='2.0',
FIELDTERMINATOR =';',
FIRSTROW = 2
)
WITH (
[ID] SMALLINT,
[Text] VARCHAR (7) COLLATE Latin1_General_BIN2
)
AS [result]
Não é possível o carregamento em massa porque o arquivo não pôde ser aberto
Esse erro Cannot bulk load because the file could not be opened retornará se um arquivo for modificado durante a execução da consulta. Normalmente, você pode receber um erro, como Cannot bulk load because the file {file path} could not be opened. Operating system error code 12. (The access code is invalid.)
Os pools de SQL sem servidor não podem ler arquivos que estão sendo modificados enquanto a consulta estiver em execução. A consulta não pode ter um bloqueio nos arquivos. Se você souber que a operação de modificação é acrescentar, poderá tentar definir a seguinte opção: {"READ_OPTIONS":["ALLOW_INCONSISTENT_READS"]}.
Para obter mais informações, veja como consultar arquivos somente de acréscimo ou criar tabelas em arquivos somente de acréscimo.
A consulta falha com erro de conversão de dados
A consulta pode falhar com a mensagem de erro Bulk load data conversion error (type mismatches or invalid character for the specified code page) for row n, column m [columnname] in the data file [filepath]. Essa mensagem significa que os tipos de dados não correspondem aos dados reais da linha número n e da coluna m.
Por exemplo, se você espera apenas inteiros em seus dados, mas na linha n há uma cadeia de caracteres, essa é a mensagem de erro que você receberá.
Para resolver esse problema, inspecione o arquivo e os tipos de dados escolhidos. Verifique também se as configurações de delimitador de linha e terminador de campo estão corretas. O exemplo a seguir mostra como a inspeção pode ser feita usando VARCHAR como o tipo de coluna.
Para obter mais informações sobre terminadores de campo, delimitadores de linha e caracteres de escape entre aspas, consulte Consultar arquivos CSV.
Exemplo
Se você quiser consultar o arquivo names.csv:
Id, first name,
1,Adam
2,Bob
3,Charles
4,David
five,Eva
Com a seguinte consulta:
Consulta 1:
SELECT
TOP 100 *
FROM
OPENROWSET(
BULK '[FILE-PATH OF CSV FILE]',
FORMAT = 'CSV',
PARSER_VERSION='1.0',
FIELDTERMINATOR =',',
FIRSTROW = 2
)
WITH (
[ID] SMALLINT,
[Firstname] VARCHAR (25) COLLATE Latin1_General_BIN2
)
AS [result]
O pool de SQL sem servidor do Azure Synapse retorna o erro Bulk load data conversion error (type mismatch or invalid character for the specified code page) for row 6, column 1 (ID) in data file [filepath].
É necessário procurar os dados e tomar uma decisão fundamentada para tratar esse problema. Para examinar os dados que causam esse problema, primeiro é necessário alterar o tipo de dados. Em vez de consultar a coluna ID com o tipo de dados SMALLINT, agora o VARCHAR(100) é usado para analisar esse problema.
Com esta Consulta 2 ligeiramente alterada, agora os dados agora podem ser processados para retornar a lista de nomes.
Consulta 2:
SELECT
TOP 100 *
FROM
OPENROWSET(
BULK '[FILE-PATH OF CSV FILE]',
FORMAT = 'CSV',
PARSER_VERSION='1.0',
FIELDTERMINATOR =',',
FIRSTROW = 2
)
WITH (
[ID] VARCHAR(100),
[Firstname] VARCHAR (25) COLLATE Latin1_General_BIN2
)
AS [result]
Você pode observar que os dados têm valores inesperados para a ID na quinta linha. Em tais circunstâncias, é importante chegar a um acordo com o proprietário da empresa dos dados sobre como esse tipo de dados corrompidos, como neste exemplo, podem ser evitados. Se a prevenção não for possível no nível do aplicativo, um VARCHAR de tamanho razoável talvez seja a única opção aqui.
Dica
Tente diminuir ao máximo o VARCHAR (). Evite o VARCHAR(MAX), se possível, pois isso pode prejudicar o desempenho.
O resultado da consulta não se parece como o esperado
Sua consulta pode não falhar, mas talvez você veja que o conjunto de resultados não é o esperado. As colunas resultantes podem estar vazias ou dados inesperados podem ser retornados. Nesse cenário, é provável que um delimitador de linha ou um terminador de campo tenha sido escolhido incorretamente.
Para resolver esse problema, revise novamente os dados e altere essas configurações. A depuração dessa consulta é fácil, conforme mostrado no exemplo a seguir.
Exemplo
Se você quiser consultar o arquivo names.csv com a consulta na Consulta 1, o pool de SQL sem servidor do Azure Synapse retorna com um resultado que parece estranho:
Em names.csv:
Id,first name,
1, Adam
2, Bob
3, Charles
4, David
5, Eva
SELECT
TOP 100 *
FROM
OPENROWSET(
BULK '[FILE-PATH OF CSV FILE]',
FORMAT = 'CSV',
PARSER_VERSION='1.0',
FIELDTERMINATOR =';',
FIRSTROW = 2
)
WITH (
[ID] VARCHAR(100),
[Firstname] VARCHAR (25) COLLATE Latin1_General_BIN2
)
AS [result]
| ID | Firstname |
| ------------- |------------- |
| 1,Adam | NULL |
| 2,Bob | NULL |
| 3,Charles | NULL |
| 4,David | NULL |
| 5,Eva | NULL |
Aparentemente não há um valor na coluna Firstname. Em vez disso, todos os valores acabaram ficando na coluna ID. Esses valores são separados por uma vírgula. O problema foi causado por essa linha de código, pois é necessário escolher o símbolo de vírgula em vez do ponto e vírgula como terminador de campo:
FIELDTERMINATOR =';',
A alteração desse único caractere resolve o problema:
FIELDTERMINATOR =',',
O conjunto de resultados criado pela Consulta 2 agora aparenta ser o esperado:
Consulta 2:
SELECT
TOP 100 *
FROM
OPENROWSET(
BULK '[FILE-PATH OF CSV FILE]',
FORMAT = 'CSV',
PARSER_VERSION='1.0',
FIELDTERMINATOR =',',
FIRSTROW = 2
)
WITH (
[ID] VARCHAR(100),
[Firstname] VARCHAR (25) COLLATE Latin1_General_BIN2
)
AS [result]
Retorna:
| ID | Firstname |
| ------------- |------------- |
| 1 | Adam |
| 2 | Bob |
| 3 | Charles |
| 4 | David |
| 5 | Eva |
A coluna do tipo não é compatível com o tipo de dados externo
Caso a consulta falhe com a mensagem de erro Column [column-name] of type [type-name] is not compatible with external data type […],, é provável que um tipo de dados PARQUET tenha sido mapeado para um tipo de dados SQL incorreto.
Por exemplo, se o arquivo Parquet tiver uma coluna de preço com números flutuantes (como 12.89) e você tentar mapeá-lo como INT, essa será a mensagem de erro que você receberá.
Para resolver esse problema, inspecione o arquivo e os tipos de dados escolhidos. Essa tabela de mapeamento ajuda a escolher o tipo de dados SQL correto. Como uma melhor prática: especifique o mapeamento somente para colunas que, de outra forma, seriam resolvidas pelo tipo de dados VARCHAR. Evitar o VARCHAR sempre que possível resulta em melhor desempenho em consultas.
Exemplo
Se você quiser consultar o arquivo taxi-data.parquet com esta Consulta 1, o pool de SQL sem servidor do Azure Synapse retornará o seguinte erro:
O arquivo taxi-data.parquet contém:
|PassengerCount |SumTripDistance|AvgTripDistance |
|---------------|---------------|----------------|
| 1 | 2635668.66000064 | 6.72731710678951 |
| 2 | 172174.330000005 | 2.97915543404919 |
| 3 | 296384.390000011 | 2.8991352022851 |
| 4 | 12544348.58999806| 6.30581582240281 |
| 5 | 13091570.2799993 | 111.065989028627 |
Consulta 1:
SELECT
*
FROM
OPENROWSET(
BULK '<filepath>taxi-data.parquet',
FORMAT='PARQUET'
) WITh
(
PassengerCount INT,
SumTripDistance INT,
AVGTripDistance FLOAT
)
AS [result]
Column 'SumTripDistance' of type 'INT' is not compatible with external data type 'Parquet physical type: DOUBLE', please try with 'FLOAT'. File/External table name: '<filepath>taxi-data.parquet'.
Essa mensagem de erro informa você que os tipos de dados não são compatíveis e indica a sugestão de usar FLOAT em vez de INT. O erro é causado por esta linha de código:
SumTripDistance INT,
Usando esta consulta 2 ligeiramente alterada, os dados agora podem ser processados e exibem todas as três colunas:
Consulta 2:
SELECT
*
FROM
OPENROWSET(
BULK '<filepath>taxi-data.parquet',
FORMAT='PARQUET'
) WITh
(
PassengerCount INT,
SumTripDistance FLOAT,
AVGTripDistance FLOAT
)
AS [result]
A consulta referencia um objeto sem suporte no modo de processamento distribuído
O erro The query references an object that is not supported in distributed processing mode indica que você usou um objeto ou uma função que não pode ser usada ao consultar dados no Armazenamento do Azure ou no armazenamento analítico do Azure Cosmos DB.
Alguns objetos, como exibições do sistema, e funções não podem ser usados ao consultar dados armazenados no Azure Data Lake ou no armazenamento analítico do Azure Cosmos DB. Evite usar as consultas que unem dados externos com exibições do sistema, que carregam dados externos em uma tabela temporária ou use algumas funções de segurança ou metadados para filtrar dados externos.
Falha na chamada WaitIOCompletion
A mensagem de erro WaitIOCompletion call failed indica que a consulta falhou ao aguardar a conclusão da operação de E/S que lê dados do armazenamento remoto, Azure Data Lake.
A mensagem de erro tem o seguinte padrão: Error handling external file: 'WaitIOCompletion call failed. HRESULT = ???'. File/External table name...
Verifique se o repositório está localizado na mesma região que o pool de SQL sem servidor. Confira as métricas de armazenamento e verifique se não há outras cargas de trabalho na camada de armazenamento, como o carregamento de novos arquivos, que poderiam saturar as solicitações de E/S.
O campo HRESULT contém o código de resultado. Os códigos de erro a seguir são os mais comuns, juntamente com suas possíveis soluções.
Esse código de erro significa que o arquivo de origem não está no armazenamento.
Há algumas razões pelas quais esse código de erro pode ocorrer:
- O arquivo foi excluído por outro aplicativo.
- Nesse cenário comum, a execução da consulta é iniciada, enumera os arquivos e os arquivos são encontrados. Posteriormente, durante a execução da consulta, um arquivo é excluído. Por exemplo, ele pode ser excluído por Databricks, Spark ou Azure Data Factory. A consulta falha porque o arquivo não foi encontrado.
- Esse problema também pode ocorrer com o formato Delta. A consulta pode ter sucesso ao tentar novamente porque há uma nova versão da tabela e o arquivo excluído não é consultado novamente.
- Um plano de execução inválido foi armazenado em cache.
- Como mitigação temporária, execute o comando
DBCC FREEPROCCACHE. Se o problema persistir, crie um tíquete de suporte.
- Como mitigação temporária, execute o comando
Sintaxe incorreta próxima a NOT
O erro Incorrect syntax near 'NOT' indica que há algumas tabelas externas com as colunas que contêm a restrição NOT NULL na definição de coluna.
- Atualize a tabela a ser removida NOT NULL da definição de coluna.
- Às vezes, esse erro também pode ocorrer transitoriamente com tabelas criadas de uma instrução CETAS. Se o problema não for resolvido, você poderá tentar remover e recriar a tabela externa.
A coluna de partição retorna valores NULL
Se a consulta retornar valores NULL em vez de particionar colunas ou se não conseguir encontrar as colunas de partição, você terá que realizar algumas etapas possíveis de solução de problemas:
- Se você usar tabelas para consultar um conjunto de dados particionado, as tabelas não dão suporte ao particionamento. Substitua a tabela por exibições particionadas.
- Se você usar as exibições particionadas com o OPENROWSET que consulta arquivos particionados usando a função FILEPATH(), verifique se especificou corretamente o padrão curinga na localização e se usou o índice adequado para referenciar o curinga.
- Se você estiver consultando os arquivos diretamente na pasta particionada, as colunas de particionamento não serão as partes das colunas de arquivo. Os valores de particionamento são colocados nos caminhos de pasta e não nos arquivos. Por esse motivo, os arquivos não contêm os valores de particionamento.
Falha ao inserir o valor no lote para o tipo de coluna DATETIME2
O erro Inserting value to batch for column type DATETIME2 failed indica que o pool sem servidor não pode ler os valores de data nos arquivos subjacentes. O valor datetime armazenado no arquivo Parquet ou Delta Lake não pode ser representado como uma coluna DATETIME2.
Inspecione o valor mínimo no arquivo usando o Spark e verifique se algumas datas estão inferiores a 0001-01-03. Se você armazenou os arquivos usando a versão 2.4 do Spark (versão de runtime sem suporte) ou com a versão superior do Spark que ainda usa o formato de armazenamento de data e hora legado, os valores de data e hora anteriores serão gravados usando o calendário juliano que não está alinhado com o calendário gregoriano proléptico utilizado nos pools de SQL sem servidor.
Pode haver uma diferença de dois dias entre o calendário juliano usado para gravar os valores em Parquet (em algumas versões do Spark) e o calendário gregoriano proléptico usado no pool de SQL sem servidor. Essa diferença pode causar a conversão para um valor de data negativo, o que é inválido.
Tente usar o Spark para atualizar esses valores porque eles são tratados como valores de data inválidos no SQL. O exemplo a seguir mostra como atualizar os valores que estão fora dos intervalos de datas do SQL para NULL no Delta Lake:
from delta.tables import *
from pyspark.sql.functions import *
deltaTable = DeltaTable.forPath(spark,
"abfss://my-container@myaccount.dfs.core.windows.net/delta-lake-data-set")
deltaTable.update(col("MyDateTimeColumn") < '0001-02-02', { "MyDateTimeColumn": null } )
Essa alteração remove os valores que não podem ser representados. Os outros valores de data podem ser carregados corretamente, mas representados incorretamente porque ainda há uma diferença entre os calendários juliano e gregoriano proléptico. Você poderá ver deslocamentos de datas inesperados até mesmo para as datas anteriores a 1900-01-01 se estiver usando o Spark 3.0 ou versões mais antigas.
Considere migrar para o Spark 3.1 ou superior e alternar para o calendário gregoriano proléptico. As versões mais recentes do Spark usam por padrão um calendário gregoriano proléptico alinhado com o calendário no pool de SQL sem servidor. Recarregue seus dados herdados com a versão mais recente do Spark e use a seguinte configuração para corrigir as datas:
spark.conf.set("spark.sql.legacy.parquet.int96RebaseModeInWrite", "CORRECTED")
Falha na consulta devido a uma alteração de topologia ou falha de contêiner de computação
Esse erro pode indicar que algum problema de processo interno ocorreu no pool de SQL sem servidor. Abra um tíquete de suporte com todos os detalhes necessários que possam ajudar a equipe de suporte do Azure a investigar o problema.
Descreva tudo que possa ser incomum em comparação com a carga de trabalho regular. Por exemplo, talvez havia um grande número de solicitações simultâneas ou uma carga de trabalho ou consulta especial iniciada antes desse erro acontecer.
Expansão de caractere curinga atingiu o tempo limite
Conforme descrito na seção Pastas de consulta e vários arquivos, o pool de SQL Sem Servidor dá suporte à leitura de vários arquivos/pastas usando caracteres curinga. Há um limite de 10 caracteres curingas por consulta. É preciso estar ciente de que essa funcionalidade tem um custo. Leva tempo para o pool sem servidor listar todos os arquivos que possam corresponder ao curinga. Isso introduz latência e essa latência pode aumentar se o número de arquivos que você está tentando consultar for alto. Nesse caso, você poderá encontrar o seguinte erro:
"Wildcard expansion timed out after X seconds."
Há várias etapas de mitigação que você poderá fazer para evitar isso:
- Aplique as melhores práticas descritas em Melhores práticas para pool de SQL Sem Servidor.
- Tente reduzir o número de arquivos que você está tentando consultar compactando arquivos em arquivos maiores. Tente manter seus tamanhos de arquivo acima de 100 MB.
- Sempre que possível, use os filtros nas colunas de particionamento.
- Se você estiver usando o formato de arquivo Delta, use o recurso de otimização de gravação no Spark. Isso poderá melhorar o desempenho das consultas, reduzindo a quantidade de dados que precisam ser lidos e processados. Como usar a otimização de gravação está descrito em Usar a otimização de gravação no Apache Spark.
- Para evitar alguns dos caracteres curinga de nível superior, codificando efetivamente os filtros implícitos nas colunas de particionamento, use SQL dinâmico.
Coluna ausente ao usar a inferência automática de esquema
Você pode consultar com facilidade arquivos sem conhecer ou especificar o esquema omitindo a cláusula WITH. Nesse caso, os nomes de coluna e os tipos de dados serão inferidos dos arquivos. Tenha em mente que, se você estiver lendo o número de arquivos de uma só vez, o esquema será inferido do primeiro arquivo obtido do armazenamento. Isso pode significar que algumas das colunas esperadas serão omitidas porque o arquivo usado pelo serviço para definir o esquema não as continha. Para especificar explicitamente o esquema, use a cláusula OPENROWSET WITH. Se você especificar o esquema (usando a tabela externa ou a cláusula OPENROWSET WITH), o modo de caminho lax padrão será usado. Isso significa que as colunas que não existem em alguns arquivos serão retornadas como NULO (para as linhas desses arquivos). Para entender como o modo de caminho é usado, verifique a documentação e o exemplo a seguir.
Configuração
Os pools de SQL sem servidor permitem que você use o T-SQL para configurar objetos de banco de dados. Há algumas restrições:
- Não é possível criar objetos em bancos de dados
masterelakehouseou Spark. - Você deve possuir uma chave mestra para criar credenciais.
- Você deve ter permissão para dados de referência usados nos objetos.
Não é possível criar um banco de dados
Caso você receba o erro CREATE DATABASE failed. User database limit has been already reached., você criou o número máximo de bancos de dados com suporte em um workspace. Para saber mais, veja Restrições.
- Caso precise separar os objetos, use esquemas dentro dos bancos de dados.
- Caso precise apenas referenciar o armazenamento do Azure Data Lake, crie bancos de dados do lakehouse ou bancos de dados do Spark que serão sincronizados no pool de SQL sem servidor.
Falha na criação ou alteração da tabela, devido ao tamanho mínimo da linha exceder o tamanho máximo permitido da linha da tabela de 8.060 bytes
Qualquer tabela pode ter até 8 KB de tamanho por linha (sem incluir dados VARCHAR(MAX)/VARBINARY(MAX) fora da linha). Se você criar uma tabela em que o tamanho total das células na linha exceda 8.060 bytes, você receberá o seguinte erro:
Msg 1701, Level 16, State 1, Line 3
Creating or altering table '<table name>' failed because the minimum row size would be <???>,
including <???> bytes of internal overhead.
This exceeds the maximum allowable table row size of 8060 bytes.
Este erro também poderá ocorrer no banco de dados Lake se você criar uma tabela do Spark com tamanhos de coluna que excedam 8.060 bytes e o pool de SQL sem servidor não puder criar uma tabela que referencie os dados da tabela do Spark.
Como uma mitigação, evite usar os tipos de tamanho fixo como CHAR(N) e substitua-os por tipos VARCHAR(N) de tamanho variável ou diminua o tamanho em CHAR(N). Confira Limitação do grupo de linhas de 8 KB no SQL Server.
Crie uma chave mestra no banco de dados ou abra a chave mestra na sessão antes de executar esta operação
Se a consulta falha com a mensagem de erro Please create a master key in the database or open the master key in the session before performing this operation., isso significa que o banco de dados do usuário não tem acesso a uma chave mestra no momento.
Muito provavelmente, você acabou de criar um novo banco de dados de usuário e ainda não criou uma chave mestra.
Para resolver esse problema, crie uma chave mestra usando a seguinte consulta:
CREATE MASTER KEY [ ENCRYPTION BY PASSWORD ='strongpasswordhere' ];
Observação
Substitua 'strongpasswordhere' por um segredo diferente aqui.
Não há suporte para a instrução CREATE no banco de dados mestre
Caso sua consulta falhe com a mensagem de erro Failed to execute query. Error: CREATE EXTERNAL TABLE/DATA SOURCE/DATABASE SCOPED CREDENTIAL/FILE FORMAT is not supported in master database., isso significa que o banco de dados master no pool de SQL sem servidor não dá suporte para a criação de:
- Tabelas externas.
- Fontes de dados externas.
- Credenciais no escopo do banco de dados.
- Formatos de arquivo externos.
Aqui está a solução:
Crie um banco de dados de usuário:
CREATE DATABASE <DATABASE_NAME>Execute uma instrução CREATE no contexto de <DATABASE_NAME>, que falhou anteriormente para o banco de dados
master.Segue um exemplo da criação de um formato de arquivo externo:
USE <DATABASE_NAME> CREATE EXTERNAL FILE FORMAT [SynapseParquetFormat] WITH ( FORMAT_TYPE = PARQUET)
Não é possível criar o logon ou o usuário do Microsoft Entra
Se receber um erro ao tentar criar um novo logon ou usuário do Microsoft Entra em um banco de dados, verifique o logon que você usou para se conectar ao banco de dados. O logon que está tentando criar um novo usuário do Microsoft Entra deve ter permissão para acessar o domínio do Microsoft Entra e verificar se o usuário existe. Esteja ciente do seguinte:
- Os logons do SQL não têm essa permissão, portanto, você sempre receberá esse erro se usar a autenticação do SQL.
- Se usar um logon do Microsoft Entra entrar para criar novos logons, verifique se você tem permissão para acessar o domínio do Microsoft Entra.
Azure Cosmos DB
Os pools de SQL sem servidor permitem consultar o armazenamento analítico do Azure Cosmos DB usando a função OPENROWSET. Verifique se o contêiner do Azure Cosmos DB tem o armazenamento analítico. Verifique se você especificou corretamente a conta, o banco de dados e o nome do contêiner. Além disso, verifique se a chave de conta do Azure Cosmos DB é válida. Para obter mais informações, veja Pré-requisitos.
Não é possível consultar o Azure Cosmos DB usando a função OPENROWSET
Caso não consiga se conectar na sua conta do Azure Cosmos DB, confira os pré-requisitos. Possíveis erros e ações de solução de problemas estão listados na tabela a seguir.
| Erro | Causa raiz |
|---|---|
| Erros de sintaxe: - Sintaxe incorreta próxima a OPENROWSET.- ... não é uma opção de provedor BULK OPENROWSET reconhecida.- Sintaxe incorreta próxima a .... |
Possíveis causas raízes: - Não usar o Azure Cosmos DB como o primeiro parâmetro. - Usa um literal de cadeia de caracteres em vez de um identificador no terceiro parâmetro. - Não especifica o terceiro parâmetro (nome do contêiner). |
| Houve um erro na cadeia de conexão do Azure Cosmos DB. | - A conta, o banco de dados ou a chave não foi especificado. - Uma opção em uma cadeia de conexão não é reconhecida. - Um ponto e vírgula ( ;) foi adicionado no final de uma cadeia de conexão. |
| Falha ao resolver o caminho do Azure Cosmos DB com o erro "Nome de conta incorreto" ou "Nome de banco de dados incorreto". | O nome da conta, o nome do banco de dados ou o contêiner especificado não pode ser encontrado ou o repositório analítico não foi habilitado para a coleção especificada. |
| Falha ao resolver o caminho do Azure Cosmos DB com o erro "Valor de segredo incorreto" ou "O segredo é nulo ou está vazio". | A chave de conta não é válida ou está ausente. |
O aviso de ordenação UTF-8 é retornado ao ler os tipos de cadeia de caracteres do Azure Cosmos DB
O pool de SQL sem servidor retorna um aviso de tempo de compilação se o agrupamento de coluna OPENROWSET não tiver codificação UTF-8. Você pode alterar facilmente o agrupamento padrão para todas as funções OPENROWSET em execução no banco de dados atual usando a instrução T-SQL:
ALTER DATABASE CURRENT COLLATE Latin1_General_100_CI_AS_SC_UTF8;
Agrupamento Latin1_General_100_BIN2_UTF8 oferece o melhor desempenho ao filtrar os dados usando predicados de cadeia de caracteres.
Linhas ausentes no armazenamento analítico do Azure Cosmos DB
Alguns itens do Azure Cosmos DB podem não ser retornados pela função OPENROWSET. Esteja ciente do seguinte:
- Há um atraso na sincronização entre os repositórios transacionais e analíticos. O documento inserido no repositório transacional do Azure Cosmos DB pode aparecer no repositório analítico após dois a três minutos.
- O documento pode violar algumas restrições de esquema.
A consulta retorna valores NULL em alguns itens do Cosmos DB
O SQL do Azure Synapse retorna NULL em vez dos valores vistos no repositório de transações nos seguintes casos:
- Há um atraso na sincronização entre os repositórios transacionais e analíticos. O valor inserido no repositório transacional do Azure Cosmos DB pode aparecer no repositório analítico após dois a três minutos.
- Talvez haja um nome de coluna errado ou uma expressão de caminho na cláusula WITH. O nome de coluna (ou a expressão de caminho após o tipo de coluna) na cláusula WITH deve corresponder aos nomes de propriedade na coleção do Azure Cosmos DB. A comparação diferencia maiúsculas de minúsculas. Por exemplo,
productCodeeProductCodesão propriedades diferentes. Confira se os nomes de coluna correspondem exatamente aos nomes das propriedades do Azure Cosmos DB. - A propriedade pode não ser movida para o repositório analítico porque viola algumas restrições de esquema, como por exemplo, mais de 1.000 propriedades ou mais de 127 níveis de aninhamento.
- Se você usar representação de esquema bem definida, o valor no repositório transacional poderá ter um tipo errado. O esquema bem definido bloqueia os tipos de cada propriedade por meio da amostragem dos documentos. Qualquer valor adicionado no repositório transacional que não corresponder ao tipo é tratado como um valor errado e não é migrado para o repositório analítico.
- Se você usar representação de esquema de fidelidade total, confira se está adicionando o sufixo de tipo após o nome da propriedade, como
$.price.int64. Se você não vir um valor para o caminho referenciado, talvez ele esteja armazenado em um caminho de tipo diferente, por exemplo$.price.float64. Para saber mais, confira Consultar coleções de banco de dados do Azure Cosmos DB no esquema de fidelidade total.
A coluna não é compatível com o tipo de dados externo
O erro Column 'column name' of the type 'type name' is not compatible with the external data type 'type name'. será retornado se o tipo de coluna especificado na cláusula WITH não corresponder ao tipo no contêiner do Azure Cosmos DB. Tente alterar o tipo de coluna conforme descrito na seção Mapeamentos de tipo SQL para o Azure Cosmos DB ou use o tipo VARCHAR.
Resolver: falha no caminho do Azure Cosmos DB com erro
Se você receber o erro Resolving Azure Cosmos DB path has failed with error 'This request is not authorized to perform this operation'., verifique se usou pontos de extremidade privados no Azure Cosmos DB. Para permitir que o pool de SQL sem servidor acesse um repositório analítico com ponto de extremidade privado, você precisa configurar pontos de extremidade privados para o repositório analítico do Azure Cosmos DB.
Problemas de desempenho do Azure Cosmos DB
Se você estiver enfrentando alguns problemas de desempenho inesperados, certifique-se de ter aplicado as melhores práticas, tais como:
- Verifique se colocou o aplicativo cliente, o pool sem servidor e o repositório analítico do Azure Cosmos DB na mesma região.
- Verifique se usa a cláusula WITH com tipos de dados ideais.
- Verifique se usa o agrupamento Latin1_General_100_BIN2_UTF8 ao filtrar os dados usando predicados de cadeia de caracteres.
- Se houver consultas repetidas que podem ser armazenadas em cache, tente usar CETAS para armazenar os resultados da consulta no Azure Data Lake Storage.
Delta Lake
Há algumas limitações que você pode ver no suporte do Delta Lake em pools do SQL sem servidor:
- Confira se você está referenciando a pasta raiz do Delta Lake na função OPENROWSET ou no local da tabela externa.
- A pasta raiz deve ter uma subpasta chamada
_delta_log. A consulta falhará se não houver pasta_delta_log. Se não vir essa pasta, você deve estar referenciando arquivos Parquet simples que devem ser convertidos para o Delta Lake usando os Pools do Apache Spark. - Não especifique curingas para descrever o esquema de partição. A consulta do Delta Lake identifica automaticamente as partições do Delta Lake.
- A pasta raiz deve ter uma subpasta chamada
- As tabelas do Delta Lake criadas nos pools do Apache Spark estão automaticamente disponíveis no pool de SQL sem servidor, mas o esquema não é atualizado (limitação da visualização pública). Se você adicionar colunas na tabela Delta usando um pool do Spark, as alterações não serão mostradas no banco de dados do pool de SQL sem servidor.
- As tabelas externas não dão suporte ao particionamento. Use as exibições particionadas na pasta do Delta Lake para usar a eliminação de partição. Confira os problemas conhecidos e as soluções alternativas mais adiante neste artigo.
- Os pools de SQL sem servidor não dão suporte a consultas de viagem no tempo. Use os Pools do Apache Spark no Synapse Analytics para ler dados históricos.
- Os pools de SQL sem servidor não dão suporte à atualização de arquivos do Delta Lake. Você pode usar o pool de SQL sem servidor para consultar a versão mais recente do Delta Lake. Use os Pools do Apache Spark no Synapse Analytics para atualizar o Delta Lake.
- Não é possível armazenar os resultados da consulta no armazenamento no formato Delta Lake usando o comando CETAS. O comando CETAS dá suporte apenas a Parquet e CSV como os formatos de saída.
- Pools de SQL sem servidor no Synapse Analytics são compatíveis com o leitor Delta versão 1.
- Os pools de SQL sem servidor no Synapse Analytics não dão suporte a conjuntos de dados com o Filtro de BLOOM. O pool de SQL sem servidor ignora os filtros de BLOOM.
- O suporte ao Delta Lake não está disponível em pools de SQL dedicados. Verifique se usa pools de SQL sem servidor para consultar os arquivos do Delta Lake.
- Para obter mais informações sobre problemas conhecidos com pools de SQL sem servidor, consulte Problemas conhecidos do Azure Synapse Analytics.
Suporte sem servidor à versão Delta 1.0
Os pools de SQL sem servidor estão lendo apenas a versão do Delta Lake 1.0. Os pools de SQL sem servidor são um leitor Delta de nível 1 e não dão suporte aos seguintes recursos:
- Mapeamentos de coluna são ignorados – pools de SQL sem servidor retornarão nomes de coluna originais.
- Os vetores de exclusão são ignorados, e a versão antiga das linhas excluídas/atualizadas será retornada (possivelmente resultados errados).
- Não há suporte para os seguintes recursos do Delta Lake: pontos de verificação V2, carimbo de data/hora sem fuso horário, verificação de protocolo VACUUM
Os vetores de exclusão são ignorados
Se a tabela Delta Lake estiver configurada para usar o gravador Delta versão 7, ela armazenará linhas excluídas e versões antigas de linhas atualizadas no DV (Delete Vectors). Como os pools de SQL sem servidor têm o nível de leitor Delta 1, eles ignorarão os vetores de exclusão e provavelmente produzirão resultados errados ao ler a versão do Delta Lake sem suporte.
Não há suporte para renomeação de colunas na tabela Delta
O pool de SQL sem servidor não dá suporte à consulta de tabelas Delta Lake com as colunas renomeadas. O pool de SQL sem servidor não pode ler dados da coluna renomeada.
O valor de uma coluna na tabela Delta é NULL
Se você estiver usando um conjunto de dados Delta que exija um leitor Delta versão 2 ou superior e usar os recursos que não têm suporte na versão 1 (por exemplo, renomeando colunas, descartando colunas ou mapeamento de colunas), os valores nas colunas referenciadas podem não ser mostrados.
O texto JSON não está formatado corretamente
Esse erro indica que o pool de SQL sem servidor não consegue ler o log de transações do Delta Lake. Provavelmente, você verá o seguinte erro:
Msg 13609, Level 16, State 4, Line 1
JSON text is not properly formatted. Unexpected character '' is found at position 263934.
Msg 16513, Level 16, State 0, Line 1
Error reading external metadata.
Verifique se o conjunto de dados do Delta Lake não está corrompido. Verifique se você consegue ler o conteúdo da pasta do Delta Lake usando o Pool do Apache Spark no Azure Synapse. Dessa forma, você garantirá que o arquivo _delta_log não está corrompido.
Solução alternativa
Tente criar um ponto de verificação no conjunto de dados do Delta Lake usando o Pool do Apache Spark e execute novamente a consulta. O ponto de verificação agrega arquivos de log JSON transacionais e poderá resolver o problema.
Se o conjunto de dados for válido, crie um tíquete de suporte e forneça mais informações:
- Não faça nenhuma alteração, como adicionar/remover as colunas ou otimizar a tabela, pois essa operação poderá alterar o estado dos arquivos de log de transações do Delta Lake.
- Copie o conteúdo da pasta
_delta_logem uma nova pasta vazia. Não copie os arquivos.parquet data. - Tente ler o conteúdo que você copiou na nova pasta e verifique se está recebendo o mesmo erro.
- Envie o conteúdo do arquivo copiado
_delta_logpara o suporte do Azure.
Agora, você pode continuar usando a pasta do Delta Lake com o Pool do Spark. Você fornece os dados copiados para o suporte da Microsoft se tiver permissão para compartilhar essas informações. A equipe do Azure investigará o conteúdo do arquivo delta_log e fornecerá mais informações sobre os possíveis erros e as soluções alternativas.
Falha ao resolver logs Delta
O erro a seguir indica que o pool de SQL sem servidor não pode resolver logs Delta: Resolving Delta logs on path '%ls' failed with error: Cannot parse json object from log folder. A causa mais comum é que o last_checkpoint_file na pasta _delta_log é maior que 200 bytes devido ao campo checkpointSchema adicionado no Spark 3.3.
Há duas opções disponíveis para contornar esse erro:
- Modifique a configuração apropriada no notebook Spark e gere um novo ponto de verificação, de modo que
last_checkpoint_fileseja recriado. Caso você esteja usando o Azure Databricks, a modificação da configuração é a seguinte:spark.conf.set("spark.databricks.delta.checkpointSchema.writeThresholdLength", 0); - Fazer downgrade para Spark 3.2.1.
Nossa equipe de engenharia está trabalhando em um suporte completo para o Spark 3.3.
A tabela Delta criada no Spark não é mostrada no pool sem servidor
Observação
A replicação de tabelas Delta criadas no Spark ainda está em versão prévia pública.
Se você tiver criado uma tabela Delta no Spark e ela não for mostrada no pool de SQL sem servidor, verifique o seguinte:
- Aguarde algum tempo (geralmente 30 segundos), porque as tabelas do Spark são sincronizadas com atraso.
- Se a tabela não aparecer no pool de SQL sem servidor após algum tempo, verifique o esquema da tabela Delta do Spark. Tabelas do Spark com tipos complexos ou tipos que não têm suporte sem servidor não estão disponíveis. Tente criar uma tabela Parquet do Spark com o mesmo esquema em um banco de dados lake e verifique se essa tabela aparece no pool de SQL sem servidor.
- Verifique se a Identidade Gerenciada do workspace pode acessar a pasta do Delta Lake referenciada pela tabela. O pool de SQL sem servidor usa a Identidade Gerenciada do workspace para obter as informações de coluna da tabela do armazenamento para criar a tabela.
Banco de dados Lake
As tabelas do banco de dados Lake, que são criadas usando o Designer do Spark ou do Synapse, são disponibilizadas automaticamente no pool de SQL sem servidor para consulta. Você pode usar o pool de SQL sem servidor para consultar as tabelas Parquet, CSV e Delta Lake criadas usando o pool do Spark e adicionar outros esquemas, exibições, procedimentos, funções de valor de tabela e usuários do Microsoft Entra na função db_datareader ao banco de dados Lake. Os possíveis problemas estão listados nesta seção.
Uma tabela criada no Spark não fica disponível no pool sem servidor
As tabelas criadas podem não ser disponibilizadas imediatamente no pool de SQL sem servidor.
- As tabelas serão disponibilizadas nos pools sem servidor com um pouco de atraso. Talvez seja necessário aguardar de 5 a 10 minutos após a criação de uma tabela no Spark para vê-la no pool de SQL sem servidor.
- Somente as tabelas que referenciam os formatos Parquet, CSV e Delta estão disponíveis no pool de SQL sem servidor. Outros tipos de tabela não estão disponíveis.
- Uma tabela que contém alguns tipos de coluna sem suporte não estará disponível no pool de SQL sem servidor.
- O acesso a tabelas do Delta Lake nos bancos de dados Lake está em visualização pública. Verifique os outros problemas listados nesta seção ou na seção Delta Lake.
Uma tabela externa criada no Spark está mostrando resultados inesperados no pool sem servidor
Pode acontecer de haver uma incompatibilidade entre a tabela externa do Spark de origem e a tabela externa replicada no pool sem servidor. Isso pode acontecer se os arquivos usados na criação de tabelas externas do Spark estiverem sem extensões. Para obter os resultados adequados, certifique-se de que todos os arquivos estejam com extensões como .parquet.
Operação não permitida para um banco de dados replicado
Este erro será retornado se você estiver tentando modificar um banco de dados Lake ou criar tabelas externas, fontes de dados externas, credenciais com escopo de banco de dados ou outros objetos no Banco de dados Lake. Esses objetos só podem ser criados em bancos de dados SQL.
Os bancos de dados Lake são replicados a partir do pool do Apache Spark e gerenciados pelo Apache Spark. Portanto, você não pode criar objetos como em Bancos de Dados SQL usando a linguagem T-SQL.
Somente as seguintes operações são permitidas nos bancos de dados do Lake:
- Criar, descartar ou alterar exibições, procedimentos e iTVF (funções de valor de tabela embutida) nos esquemas diferentes de
dbo. - Criar e remover os usuários do banco de dados do Microsoft Entra ID.
- Adicionar ou remover usuários do banco de dados do esquema
db_datareader.
Outras operações não são permitidas em bancos de dados Lake.
Observação
Se você estiver criando uma função de exibição, procedimento ou função no esquema dbo (ou omitindo o esquema e usando o padrão, que normalmente é dbo), receberá a mensagem de erro.
As tabelas Delta nos bancos de dados Lake não estão disponíveis no pool de SQL sem servidor
Verifique se a Identidade Gerenciada do workspace tem acesso de leitura no armazenamento do ADLS que contém a pasta Delta. O pool de SQL sem servidor lê o esquema de tabela Delta Lake nos logs Delta que são colocados no ADLS e usa a Identidade Gerenciada do workspace para acessar os logs de transações Delta.
Tente configurar uma fonte de dados em alguns Banco de Dados SQL que referenciem o armazenamento do Azure Data Lake usando a credencial de Identidade Gerenciada; e tente criar uma tabela externa sobre a fonte de dados com a Identidade Gerenciada para confirmar que uma tabela com a Identidade Gerenciada pode acessar o armazenamento.
As tabelas delta em bancos de dados lake não têm esquema idêntico nos pools do Spark e sem servidor
Os pools de SQL sem servidor permitem acessar tabelas Parquet, CSV e Delta criadas no banco de dados Lake usando o Spark ou o designer do Azure Synapse. O acesso às tabelas Delta ainda está em versão prévia pública e, no momento, sem servidor sincronizará uma tabela Delta com o Spark no momento da criação, mas não atualizará o esquema se as colunas forem adicionadas posteriormente usando a instrução ALTER TABLE no Spark.
Esta é uma limitação da versão prévia pública. Solte e recite a tabela Delta no Spark (se possível) em vez de alterar tabelas para resolver este problema.
Tempo limite de consulta ou degradação do desempenho em uma tabela
Quando a tabela original no Spark ou no Dataverse é modificada, as tabelas correspondentes no pool sem servidor são recriadas automaticamente. Esse processo resulta na perda de estatísticas existentes na tabela. Sem essas estatísticas, as consultas na tabela podem sofrer atrasos ou até mesmo atingir o tempo limite.
Se esse problema ocorrer, configure um trabalho para recriar as estatísticas das tabelas após mudanças no Spark/Dataverse ou em um agendamento regular.
Desempenho
O pool de SQL sem servidor atribui os recursos às consultas com base no tamanho do conjunto de dados e na complexidade da consulta. Você não pode alterar nem limitar os recursos que são fornecidos para as consultas. Há alguns casos em que você pode experimentar degradações inesperadas de desempenho de consulta e talvez seja preciso identificar as causas raiz.
A duração da consulta é muito longa
Caso você tenha consultas com uma duração superior a 30 minutos, a consulta retorna lentamente os resultados para o cliente. O pool de SQL sem servidor tem um limite de 30 minutos para execução. Mais tempo é gasto na transmissão dos resultados. Tente as seguintes soluções alternativas:
- Se você usar o Synapse Studio, tente reproduzir os problemas com algum outro aplicativo, como SQL Server Management Studio ou Azure Data Studio.
- Caso a consulta esteja lenta ao ser executada usando SQL Server Management Studio, Azure Data Studio, Power BI ou algum outro aplicativo, verifique os problemas de rede e as melhores práticas.
- Coloque a consulta no comando CETAS e meça a duração da consulta. O comando CETAS armazena os resultados para Azure Data Lake Storage e não depende da conexão do cliente. Se o comando CETAS for concluído mais rápido do que a consulta original, verifique a largura de banda de rede entre o cliente e o pool de SQL sem servidor.
A consulta fica lenta quando executada usando o Synapse Studio
Se você usa o Synapse Studio, tente usar um cliente da área de trabalho, como o SQL Server Management Studio ou o Azure Data Studio. O Synapse Studio é um cliente da Web que se conecta ao pool de SQL sem servidor usando o protocolo HTTP, o qual geralmente é mais lento do que as conexões de SQL nativas usadas no SQL Server Management Studio ou no Azure Data Studio.
A consulta fica lenta quando executada usando o aplicativo
Verifique os seguintes problemas se você enfrentar lentidão na execução de consultas:
- Verifique se os aplicativos cliente estão colocados com o pool de SQL sem servidor. A execução de uma consulta em toda a região pode causar latência extra e fluxo lento do conjunto de resultados.
- Verifique se você não tem problemas de rede que possam causar a transmissão lenta do conjunto de resultados
- Verifique se o aplicativo cliente tem recursos suficientes (por exemplo, não esteja usando 100% da CPU).
- Verifique se a conta de armazenamento ou o armazenamento analítico do Azure Cosmos DB está colocado na mesma região que o seu ponto de extremidade de SQL sem servidor.
Confira as melhores práticas para colocação dos recursos.
Altas variações em durações de consulta
Se você estiver executando a mesma consulta e observando variações nas durações da consulta, várias razões podem causar esse comportamento:
- Verifique se esta é a primeira execução de uma consulta. A primeira execução de uma consulta coleta as estatísticas necessárias para criar um plano. As estatísticas são coletadas pela verificação dos arquivos subjacentes e podem aumentar a duração da consulta. No Synapse Studio, você verá as consultas de "criação de estatísticas globais" na lista de solicitações do SQL, que são executadas antes da consulta.
- As estatísticas podem expirar após algum tempo. Periodicamente, você talvez observe um impacto no desempenho, porque o pool sem servidor precisa examinar e recompilar as estatísticas. Você talvez perceba outras consultas de "criação de estatísticas globais" na lista de solicitações SQL, que são executadas antes da consulta.
- Verifique se há uma carga de trabalho em execução no mesmo ponto de extremidade quando você executou a consulta com a duração mais longa. O ponto de extremidade do SQL sem servidor aloca igualmente os recursos para todas as consultas executadas em paralelo, e a consulta poderá ser atrasada.
conexões
O pool de SQL sem servidor permite a você se conectar usando o protocolo TDS e user a linguagem T-SQL para consultar dados. A maioria das ferramentas que pode se conectar ao SQL Server ou ao Banco de Dados SQL do Azure também pode se conectar ao pool de SQL sem servidor.
O pool de SQL está sendo preparado
Após um longo período de inatividade, o pool de SQL sem servidor será desativado. A ativação ocorre automaticamente na primeira atividade seguinte, por exemplo, a primeira tentativa de conexão. O processo de ativação pode demorar um pouco mais do que um intervalo de tentativa de conexão única, portanto, a mensagem de erro é exibida. Uma nova tentativa de conexão deve ser suficiente.
Como melhor prática, para os clientes que dão suporte a isso, use as palavras-chave da cadeia de conexão ConnectionRetryCount e ConnectRetryInterval para controlar o comportamento de reconexão.
Caso a mensagem de erro persista, arquive um tíquete de suporte por meio do portal do Azure.
Não é possível conectar no Synapse Studio
Confira a seção do Synapse Studio.
Não é possível se conectar ao pool do Azure Synapse a partir de uma ferramenta
Algumas ferramentas podem não ter uma opção explícita que você pode usar para se conectar ao pool de SQL sem servidor do Azure Synapse. Use uma opção que você usaria para se conectar ao SQL Server ou ao Banco de Dados SQL. A caixa de diálogo de conexão não precisa estar marcada como "Synapse" porque o pool de SQL sem servidor usa o mesmo protocolo que o SQL Server ou o Banco de Dados SQL.
Mesmo se uma ferramenta permitir que você insira apenas um nome de servidor lógico e predefina o domínio database.windows.net, coloque o nome do workspace do Azure Synapse seguido pelo sufixo -ondemand e pelo domínio database.windows.net.
Segurança
Verifique se um usuário tem permissões para acessar bancos de dados, permissões para executar comandos e permissões para acessar o Azure Data Lake ou o armazenamento do Azure Cosmos DB.
Não é possível acessar a conta do Azure Cosmos DB
Você deve usar a chave de somente leitura do Azure Cosmos DB para acessar o repositório analítico, portanto, verifique se ela não expirou ou se não foi regenerada.
Se você receber o erro "A resolução do caminho do BD Cosmos do Azure falhou com erro", verifique se você configurou um firewall.
Não é possível acessar o banco de dados do Lakehouse ou Spark
Se um usuário não puder acessar um banco de dados do Spark, o usuário talvez não tenha permissão para acessar e ler o banco de dados. Um usuário com a permissão CONTROL SERVER deve ter acesso completo a todos os bancos de dados. Como uma permissão restrita, você pode tentar usar CONECTAR QUALQUER BANCO DE DADOS e SELECIONAR TODOS OS PROTEGÍVEIS DE USUÁRIO.
O usuário do SQL não consegue acessar as tabelas do Dataverse
As tabelas do Dataverse acessam o armazenamento usando a identidade do Microsoft Entra do chamador. O usuário do SQL com permissões altas pode tentar selecionar dados de uma tabela, mas a tabela não conseguirá acessar dados do Dataverse. Não há suporte para esse cenário.
Falhas de entrada da entidade de serviço do Microsoft Entra quando o SPI cria uma atribuição de função
Se você quiser criar uma atribuição de função para um SPI (identificador de entidade de serviço) ou aplicativo do Microsoft Entra usando outro SPI, ou já tiver criado um e ele não conseguir entrar, você provavelmente receberá o seguinte erro: Login error: Login failed for user '<token-identified principal>'.
Para entidades de serviço, o logon deve ser criado com uma ID de aplicativo como uma SID (ID de segurança), não com uma ID de objeto. Há uma limitação conhecida em entidades de serviço, a qual impede que o serviço do Azure Synapse busque a ID de aplicativo do Microsoft Graph ao criar a atribuição de função para outro SPI ou aplicativo.
Solução 1
Vá até o portal do Azure>Synapse Studio>Gerenciar>Controle de acesso e adicione manualmente Administrador do Synapse ou Administrador SQL do Synapse para a entidade de serviço desejada.
Solução 2
Você deve criar manualmente um logon adequado com o código SQL:
use master
go
CREATE LOGIN [<service_principal_name>] FROM EXTERNAL PROVIDER;
go
ALTER SERVER ROLE sysadmin ADD MEMBER [<service_principal_name>];
go
Solução 3
Também é possível configurar a entidade de serviço de administrador do Azure Synapse usando o PowerShell. É necessário ter o módulo Az.Synapse instalado.
A solução é usar o cmdlet New-AzSynapseRoleAssignment com -ObjectId "parameter". Nesse campo de parâmetro, forneça a ID de aplicativo em vez da ID de objeto usando as credenciais da entidade de serviço do administrador do workspace do Azure.
Script do PowerShell:
$spAppId = "<app_id_which_is_already_an_admin_on_the_workspace>"
$SPPassword = "<application_secret>"
$tenantId = "<tenant_id>"
$secpasswd = ConvertTo-SecureString -String $SPPassword -AsPlainText -Force
$cred = New-Object -TypeName System.Management.Automation.PSCredential -ArgumentList $spAppId, $secpasswd
Connect-AzAccount -ServicePrincipal -Credential $cred -Tenant $tenantId
New-AzSynapseRoleAssignment -WorkspaceName "<workspaceName>" -RoleDefinitionName "Synapse Administrator" -ObjectId "<app_id_to_add_as_admin>" [-Debug]
Observação
Nesse caso, a interface do usuário do Synapse Data Studio não exibirá a atribuição de função adicionada pelo método acima, portanto, é recomendável adicionar a atribuição de função à ID do objeto e à ID do aplicativo ao mesmo tempo para que ela também possa ser exibida na interface do usuário.
New-AzSynapseRoleAssignment -WorkspaceName "<workspaceName>" -RoleDefinitionName "Administrador do Synapse" -ObjectId "<object_id_to_add_as_admin>" [-Debug]
Validação
Conecte-se ao ponto de extremidade de SQL sem servidor e verifique se o logon externo com SID (app_id_to_add_as_admin no exemplo anterior) foi criado:
SELECT name, convert(uniqueidentifier, sid) AS sid, create_date
FROM sys.server_principals
WHERE type in ('E', 'X');
Ou tente entrar no ponto de extremidade de SQL sem servidor usando o aplicativo de administração definido.
Restrições
Algumas restrições gerais do sistema que podem afetar a carga de trabalho:
| Propriedade | Limitação |
|---|---|
| Número máximo de workspaces do Azure Synapse por assinatura | Veja os limites. |
| Número máximo de bancos de dados por pool sem servidor | 100 (não incluindo os bancos de dados sincronizados do pool do Apache Spark). |
| Número máximo de bancos de dados sincronizados do Pool do Apache Spark | Não limitado. |
| Número máximo de objetos de banco de dados por banco de dados | A soma do número de todos os objetos em um banco de dados não pode exceder 2.147.483.647. Consulte Limitações no mecanismo de banco de dados do SQL Server. |
| Comprimento máximo do identificador em caracteres | 128. Consulte Limitações no mecanismo de banco de dados do SQL Server. |
| Duração máxima da consulta | 30 minutos. |
| Tamanho máximo do conjunto de resultados | Até 400 GB compartilhados entre consultas simultâneas. |
| Simultaneidade máxima | Não limitado e depende da complexidade da consulta e da quantidade de dados examinados. Um pool de SQL sem servidor pode lidar simultaneamente com 1.000 sessões ativas que estão executando consultas leves. Os números serão suspensos se as consultas forem mais complexas ou verificarem uma quantidade maior de dados, portanto, nesse caso, considere diminuir a simultaneidade e executar consultas por um período maior de tempo, se possível. |
| Tamanho máximo do nome da tabela externa | 100 caracteres. |
Não é possível criar um banco de dados no pool de SQL sem servidor
Os pools de SQL sem servidor têm limitações, e não é possível criar mais de 100 bancos de dados por workspace. Caso precise separar objetos e isolá-los, use esquemas.
Caso você receba o erro CREATE DATABASE failed. User database limit has been already reached, você criou o número máximo de bancos de dados com suporte em um workspace.
Você não precisa usar bancos de dados separados para isolar os dados em locatários diferentes. Todos os dados são armazenados externamente em um data lake e no Azure Cosmos DB. Os metadados, como tabela, exibições e definições de função, podem ser isolados com êxito usando esquemas. O isolamento baseado em esquema também é usado no Spark, em que bancos de dados e esquemas são os mesmos conceitos.