Configurar os Hubs de Eventos do Azure e os pontos de extremidade de fluxo de dados do Kafka
Importante
Esta página inclui instruções para gerenciar componentes do serviço Operações do Azure IoT usando manifestos de implantação do Kubernetes, que estão em versão prévia. Esse recurso é fornecido com várias limitações, e não deve ser usado para cargas de trabalho de produção.
Veja os Termos de Uso Complementares para Versões Prévias do Microsoft Azure para obter termos legais que se aplicam aos recursos do Azure que estão em versão beta, versão prévia ou que, de outra forma, ainda não foram lançados em disponibilidade geral.
Para configurar a comunicação bidirecional entre o Operações do Azure IoT e os agentes do Apache Kafka, você poderá configurar um ponto de extremidade de fluxo de dados. Essa configuração permite especificar o ponto de extremidade, o TLS (Transport Layer Security), a autenticação e outras configurações.
Pré-requisitos
- Uma instância do Operações do Azure IoT
Hubs de eventos do Azure
Os Hubs de Eventos do Azure são compatíveis com o protocolo do Kafka e podem ser usados com fluxos de dados com algumas limitações.
Crie um namespace do Hubs de Eventos do Azure e um hub de eventos
Primeiro, crie um namespace do Hubs de Eventos do Azure habilitado para Kafka
Próximo, crie um hub de eventos no namespace. Cada hub de eventos individual corresponde a um tópico do Kafka. Você pode criar vários hubs de eventos no mesmo namespace para representar vários tópicos do Kafka.
Atribuir permissão à identidade gerenciada
Para configurar um ponto de extremidade de fluxo de dados para o serviço Hubs de Eventos do Azure, recomendamos usar uma identidade gerenciada atribuída pelo usuário ou atribuída pelo sistema. Essa abordagem é segura e elimina a necessidade de gerenciar credenciais manualmente.
Depois que o namespace e o hub de eventos do Hubs de Eventos do Azure forem criados, você precisará atribuir uma função à identidade gerenciada do Operações IoT do Azure que concede permissão para enviar ou receber mensagens para o hub de eventos.
Se estiver usando a identidade gerenciada atribuída pelo sistema, no portal do Azure, vá para a instância do Operações do Azure IoT e selecione Visão geral. Copie o nome da extensão listada após Extensão do Azure IoT Operations Arc. Por exemplo, azure-iot-operations-xxxx7. Sua identidade gerenciada atribuída pelo sistema pode ser encontrada usando o mesmo nome da extensão Arc do Operações do Azure IoT.
Em seguida, vá para o namespace do Hubs de Eventos >Controle de acesso (IAM)>Adicionar atribuição de função.
- Na guia Função, selecione uma função apropriada como
Azure Event Hubs Data SenderouAzure Event Hubs Data Receiver. Isso fornece à identidade gerenciada as permissões necessárias para enviar ou receber mensagens para todos os hubs de eventos no namespace. Para saber mais, consulte Autenticar um aplicativo com o Microsoft Entra ID para acessar recursos dos Hubs de Eventos. - Na guia Membros:
- Se estiver usando a identidade gerenciada atribuída pelo sistema, para Atribuir acesso a, selecione a opção usuário, grupo ou entidade de serviço, selecione + Selecionar membros e pesquise o nome da extensão Arc do serviço Operações do Azure IoT.
- Se estiver usando a identidade gerenciada atribuída pelo usuário, para atribuir acesso a, selecione a opção Identidade Gerenciada e selecione + Selecionar membros e pesquise sua identidade gerenciada atribuída pelo usuário configurada para conexões de nuvem.
Criar ponto de extremidade de fluxo de dados para Hubs de Eventos do Azure
Depois que o namespace e o hub de eventos do Hubs de Eventos do Azure estiverem configurados, você poderá criar um ponto de extremidade de fluxo de dados para o namespace do Hubs de Eventos do Azure habilitado para Kafka.
Na experiência de operações, selecione a guia Pontos de extremidade do fluxo de dados.
Em Criar novo ponto de extremidade do fluxo de dados, selecione Hubs de Eventos do Azure>Novo.
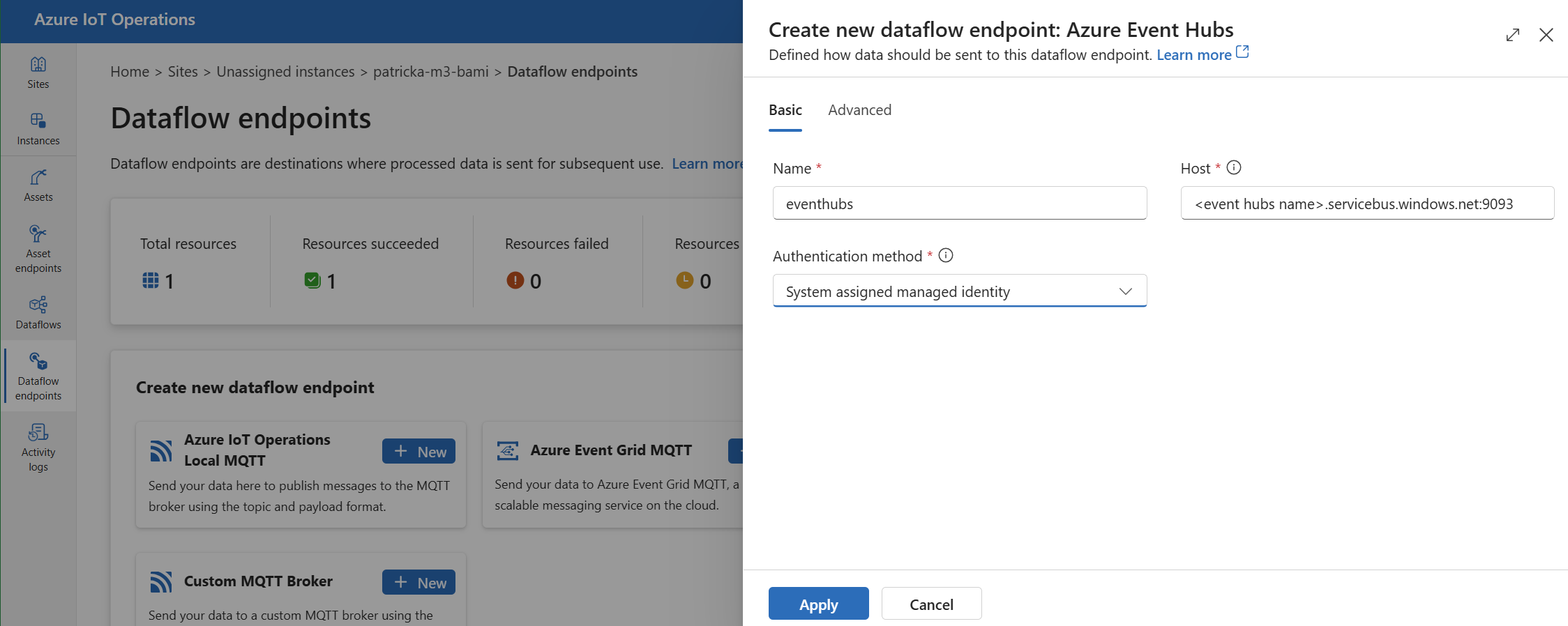
Insira as configurações a seguir para o ponto de extremidade:
Configuração Descrição Nome O nome do ponto de extremidade do fluxo de dados. Host O nome do host do agente Kafka no formato <NAMESPACE>.servicebus.windows.net:9093. Inclua o número da porta9093na configuração do host para os Hubs de Eventos.Método de autenticação O método usado para autenticação. Recomendamos que você escolha identidade gerenciada atribuída pelo sistema ou identidade gerenciada atribuída pelo usuário. Selecione Aplicar para provisionar o ponto de extremidade.
Observação
O tópico do Kafka ou do hub de eventos individual, é configurado posteriormente ao criar o fluxo de dados. O tópico do Kafka é o destino das mensagens de fluxo de dados.
Usar a cadeia de conexão para autenticação nos Hubs de Eventos
Importante
Para usar o portal de experiência de operações para gerenciar segredos, primeiro, as Operações do Azure IoT precisam ser habilitadas com as configurações seguras por meio da definição de um cofre de chaves do Azure e da habilitação de identidades de carga de trabalho. Para saber mais, confira Habilitar configurações seguras na implantação de Operações do Azure IoT.
Na página de configurações do ponto de extremidade do fluxo de dados da experiência de operações, selecione a guia Básico e escolha Método de autenticação>SASL.
Insira as configurações a seguir para o ponto de extremidade:
| Configuração | Descrição |
|---|---|
| Tipo SASL | Escolha Plain. |
| Nome do segredo sincronizado | Insira o nome do segredo do Kubernetes que contém a cadeia de conexão. |
| Referência de nome de usuário ou segredo de token | A referência ao nome de usuário ou ao segredo do token usado para autenticação SASL. Escolha-o na lista do Key Vault ou crie um novo. O valor deve ser $ConnectionString. |
| Referência de senha do segredo do token | A referência ao segredo de senha ou token usado para autenticação SASL. Escolha-o na lista do Key Vault ou crie um novo. O valor deve estar no formato de Endpoint=sb://<NAMESPACE>.servicebus.windows.net/;SharedAccessKeyName=<KEY-NAME>;SharedAccessKey=<KEY>. |
Depois de selecionar Adicionar referência, se você selecionar Criar novo, insira as seguintes configurações:
| Configuração | Descrição |
|---|---|
| Nome do segredo | O nome do segredo no Azure Key Vault. Escolha um nome que seja fácil de lembrar para selecionar o segredo posteriormente na lista. |
| Valor do segredo | Para o nome de usuário, insira $ConnectionString. Para a senha, insira a cadeia de conexão no formato Endpoint=sb://<NAMESPACE>.servicebus.windows.net/;SharedAccessKeyName=<KEY-NAME>;SharedAccessKey=<KEY>. |
| Definir data de ativação | Se ativada, a data em que o segredo se torna ativo. |
| Definir a data de validade | Se ativada, a data em que o segredo vence. |
Para saber mais sobre segredos, consulte Criar e gerenciar segredos nas Operações do Azure IoT.
Limitações
Os Hubs de Eventos do Azure não dão suporte a todos os tipos de compactação compatíveis com o Kafka. Somente a compactação GZIP tem suporte em camadas premium e dedicadas dos Hubs de Eventos do Azure no momento. O uso de outros tipos de compactação pode resultar em erros.
Corretores Kafka personalizados
Para configurar um ponto de extremidade de fluxo de dados para agentes do Kafka que não sejam do Hub de Eventos, defina o host, o TLS, a autenticação e outras configurações conforme necessário.
Na experiência de operações, selecione a guia Pontos de extremidade do fluxo de dados.
Em Criar novo ponto de extremidade do fluxo de dados, selecione Agente Kafka personalizado>Novo.
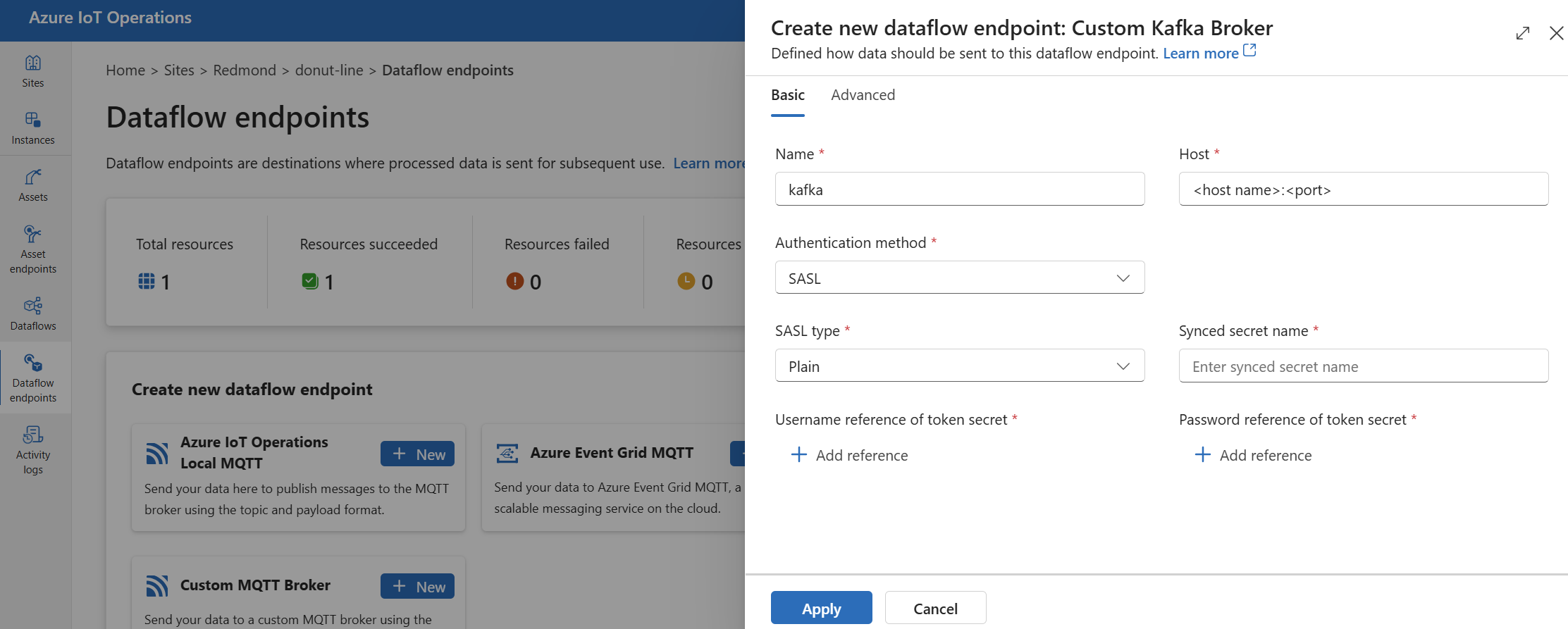
Insira as configurações a seguir para o ponto de extremidade:
Configuração Descrição Nome O nome do ponto de extremidade do fluxo de dados. Host O nome do host do agente Kafka no formato <Kafka-broker-host>:xxxx. Inclua o número da porta na configuração do host.Método de autenticação O método usado para autenticação. Escolha SASL. Tipo SASL O tipo de autenticação SASL. Selecione Simples, ScramSha256 ou ScramSha512. Necessário se estiver usando SASL. Nome do segredo sincronizado O nome do segredo. Necessário se estiver usando SASL. Referência de nome de usuário do segredo do token A referência ao nome de usuário no segredo do token do SASL. Necessário se estiver usando SASL. Selecione Aplicar para provisionar o ponto de extremidade.
Observação
Atualmente, a experiência de operações não dá suporte ao uso de um ponto de extremidade de fluxo de dados do Kafka como fonte. É possível criar um fluxo de dados com um ponto de extremidade de fluxo de dados Kafka como fonte usando Kubernetes ou Bicep.
Para personalizar as configurações do ponto de extremidade, use as seções a seguir para obter mais informações.
Métodos de autenticação disponíveis
Os métodos de autenticação a seguir estão disponíveis para pontos de extremidade do fluxo de dados do agente Kafka.
Identidade gerenciada atribuída pelo sistema
Antes de configurar o ponto de extremidade de fluxo de dados, atribua uma função à identidade gerenciada de Operações do Azure IoT que concede permissão para se conectar ao agente Kafka:
- No portal do Azure, acesse sua instância do Azure IoT Operations e selecione Visão geral.
- Copie o nome da extensão listada após Extensão do Azure IoT Operations Arc. Por exemplo, azure-iot-operations-xxxx7.
- Vá para o recurso de nuvem que você precisa para conceder permissões. Por exemplo, vá para o namespace do Hubs de Eventos >Controle de acesso (IAM)>Adicionar atribuição de função.
- Na guia Função, selecione uma função apropriada.
- Na guia Membros, para Atribuir acesso a, selecione Usuário, grupo ou opção de entidade de serviço e selecione + Selecionar membros e pesquise a identidade gerenciada do serviço Operações do Azure IoT. Por exemplo, azure-iot-operations-xxxx7.
Em seguida, defina o ponto de extremidade de fluxo de dados com as configurações de identidade gerenciada atribuídas pelo sistema.
Na página de configurações do ponto de extremidade do fluxo de dados da experiência de operações, selecione a guia Básico e escolha Método de autenticação>Identidade gerenciada atribuída pelo sistema.
Essa configuração cria uma identidade gerenciada com o público-alvo padrão, que é o mesmo que o valor do host do namespace dos Hubs de Eventos, na forma de https://<NAMESPACE>.servicebus.windows.net. No entanto, caso precise substituir o público-alvo padrão, poderá definir o campo audience como o valor desejado.
Não há suporte na experiência de operações.
Identidade gerenciada atribuída pelo usuário
Para usar a identidade gerenciada atribuída pelo usuário para autenticação, primeiro você precisa implantar as Operações do Azure IoT com as configurações seguras habilitadas. Em seguida, você precisa configurar uma identidade gerenciada atribuída pelo usuário para conexões de nuvem. Para saber mais, confira Habilitar configurações seguras na implantação de Operações do Azure IoT.
Antes de configurar o ponto de extremidade de fluxo de dados, atribua uma função à identidade gerenciada atribuída pelo usuário que concede permissão para se conectar ao agente Kafka:
- No portal do Azure, vá para o recurso de nuvem que você precisa para conceder permissões. Por exemplo, acesse o namespace da Grade de Eventos >Controle de acesso (IAM)>Adicionar atribuição de função.
- Na guia Função, selecione uma função apropriada.
- Na guia Membros, para Atribuir acesso a, selecione a opção Identidade Gerenciada e selecione + Selecionar membros e pesquise sua identidade gerenciada atribuída pelo usuário.
Em seguida, defina o ponto de extremidade de fluxo de dados com as configurações de identidade gerenciada atribuídas pelo usuário.
Na página de configurações do ponto de extremidade do fluxo de dados da experiência de operações, selecione a guia Básico e escolha Método de autenticação>Identidade gerenciada atribuída pelo usuário.
Aqui, o escopo é o público da identidade gerenciada. O valor padrão é o mesmo que o valor do host do namespace do Hubs de Eventos do Azure no formato de https://<NAMESPACE>.servicebus.windows.net. No entanto, se você precisar substituir o público padrão, poderá definir o campo de escopo para o valor desejado usando o Bicep ou o Kubernetes.
SASL
Para usar o SASL para autenticação, especifique o método de autenticação SASL e configure o tipo SASL e uma referência secreta com o nome do segredo que contém o token SASL.
Na página de configurações do ponto de extremidade do fluxo de dados da experiência de operações, selecione a guia Básico e escolha Método de autenticação>SASL.
Insira as configurações a seguir para o ponto de extremidade:
| Configuração | Descrição |
|---|---|
| Tipo SASL | O tipo de autenticação SASL a ser usada. Os tipos com suporte são Plain, ScramSha256, e ScramSha512. |
| Nome do segredo sincronizado | O nome do segredo do Kubernetes que contém o token de SASL. |
| Referência de nome de usuário ou segredo de token | A referência ao nome de usuário ou ao segredo do token usado para autenticação SASL. |
| Referência de senha do segredo do token | A referência ao segredo de senha ou token usado para autenticação SASL. |
Os tipos de SASL com suporte são:
PlainScramSha256ScramSha512
O segredo deve estar no mesmo namespace que o ponto de extremidade do fluxo de dados do Kafka. O segredo deve ter o token de SASL como um par chave-valor.
Anônimo
Para usar a autenticação anônima, atualize a seção de autenticação das configurações do Kafka para usar o método Anônimo.
Na página de configurações do ponto de extremidade do fluxo de dados da experiência de operações, selecione a guia Básico e escolha Método de autenticação>Nenhum.
Configurações avançadas
É possível definir configurações avançadas para o ponto de extremidade de fluxo de dados do Kafka, como TLS, Certificado de Autoridade de Certificação Confiável, configurações de mensagens do Kafka, envio em lote e CloudEvents. Você pode definir essas configurações na guia Avançado do portal do ponto de extremidade de fluxo de dados ou dentro do recurso do ponto de extremidade de fluxo de dados.
Na experiência de operações, selecione a guia Avançado do ponto de extremidade do fluxo de dados.
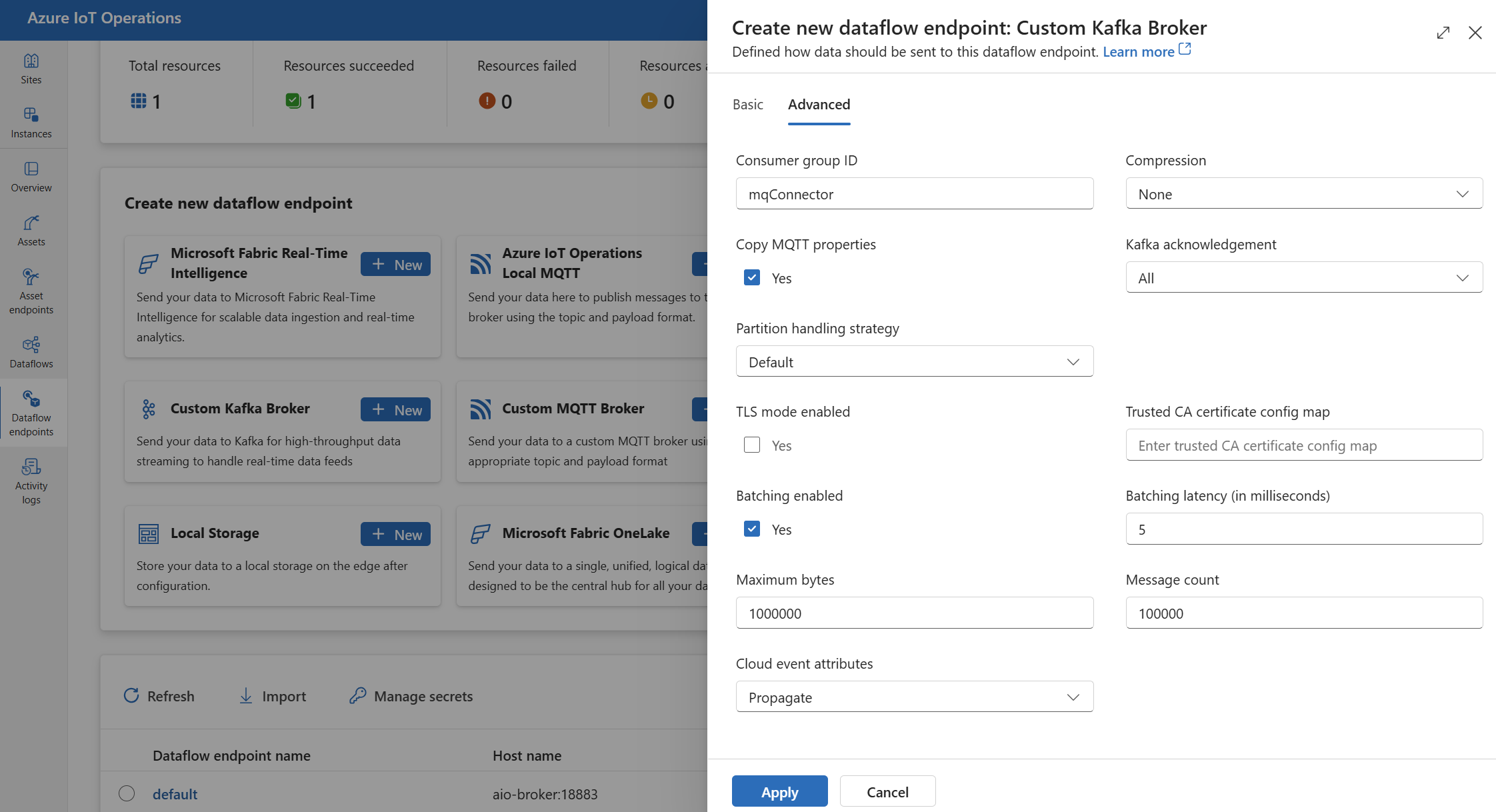
Configurações de protocolo TLS
Modo TLS
Para habilitar ou desabilitar o TLS para o ponto de extremidade do Kafka, atualize a configuração mode nas configurações do TLS.
Na página de configurações do ponto de extremidade de fluxo de dados da experiência de operações, selecione a guia Avançado e use a caixa de seleção ao lado de modo TLS habilitado.
O modo TLS pode ser definido como Enabled ou Disabled. Se o modo estiver definido como Enabled, o fluxo de dados usará uma conexão segura com o agente Kafka. Se o modo estiver definido como Disabled, o fluxo de dados usará uma conexão insegura com o agente Kafka.
Certificado de Autoridade de Certificação confiável
Configure o certificado de Autoridade de Certificação confiável para o ponto de extremidade do Kafka para estabelecer uma conexão segura com o agente Kafka. Essa configuração é importante se o agente Kafka usa um certificado autoassinado ou um certificado assinado por um CA personalizado que não é confiável por padrão.
Na página de configurações do ponto de extremidade de fluxo de dados da experiência de operações, selecione a guia Avançado e use o campo Mapa de configuração do Certificado de Autoridade de Certificação Confiável para especificar o ConfigMap que contém o certificado de Autoridade de Certificação Confiável.
Esse ConfigMap deve conter o Certificado de Autoridade de Certificação no formato PEM. O ConfigMap deve estar no mesmo namespace que o recurso de fluxo de dados do Kafka. Por exemplo:
kubectl create configmap client-ca-configmap --from-file root_ca.crt -n azure-iot-operations
Dica
Ao se conectar aos Hubs de Eventos do Azure, o certificado de Autoridade de Certificação não é necessário porque o serviço Hubs de Eventos usa um certificado assinado por uma CA pública confiável por padrão.
ID do grupo de consumidores
A ID do grupo de consumidores é usada para identificar o grupo de consumidores que o fluxo de dados usa para fazer a leitura das mensagens do tópico do Kafka. A ID do grupo de consumidores deve ser exclusiva no agente Kafka.
Importante
Quando o ponto de extremidade do Kafka é usado como origem, o ID do grupo de consumidores é necessário. Caso contrário, o fluxo de dados não poderá ler mensagens do tópico do Kafka, e você receberá um erro "Os pontos de extremidade de origem do tipo Kafka devem ter um consumerGroupId definido".
Na página de configurações do ponto de extremidade de fluxo de dados da experiência de operações, selecione a guia Avançado e use o campo ID do grupo de consumidores para especificar a ID do grupo de consumidores.
Essa configuração só entrará em vigor se o ponto de extremidade for usado como uma fonte (ou seja, o fluxo de dados é um consumidor).
Compactação
O campo de compactação permite a compactação para as mensagens enviadas aos tópicos de Kafka. A compactação ajuda a reduzir a largura de banda da rede e o espaço de armazenamento necessários para a transferência de dados. No entanto, a compactação também adiciona alguma sobrecarga e latência ao processo. Os tipos de compactação com suporte estão listados na tabela a seguir.
| Valor | Descrição |
|---|---|
None |
Nenhuma compactação ou lote é aplicada. Nenhum é o valor padrão se nenhuma compactação for especificada. |
Gzip |
A compactação GZIP e o processamento em lote são aplicados. GZIP é um algoritmo de compressão de uso geral que oferece um bom equilíbrio entre taxa de compressão e velocidade. Somente a compactação GZIP tem suporte em camadas premium e dedicadas dos Hubs de Eventos do Azure no momento. |
Snappy |
A compactação rápida e o processamento em lote são aplicados. Snappy é um algoritmo de compressão rápida que oferece taxa de compressão moderada e velocidade. Esse modo de compactação não é suportado pelos Hubs de Eventos do Azure. |
Lz4 |
A compactação LZ4 e o processamento em lote são aplicados. LZ4 é um algoritmo de compressão rápida que oferece baixa taxa de compressão e alta velocidade. Esse modo de compactação não é suportado pelos Hubs de Eventos do Azure. |
Para configurar a compactação:
Na página de configurações do ponto de extremidade de fluxo de dados da experiência de operações, selecione a guia Avançado e use o campo Compactação para especificar o tipo de compactação.
Essa configuração entrará em vigor somente se o ponto de extremidade for usado como um destino em que o fluxo de dados é um produtor.
Envio em lote
Além da compactação, você também pode configurar o envio em lote de mensagens antes de enviá-las para os tópicos do Kafka. O envio em lote permite agrupar várias mensagens e compactá-las como uma única unidade, o que pode melhorar a eficiência da compactação e reduzir a sobrecarga de rede.
| Campo | Descrição | Obrigatório |
|---|---|---|
mode |
Pode ser Enabled ou Disabled. O valor padrão é Enabled porque o Kafka não tem noção de mensagens não em lote. Se definido como Disabled, o processamento em lote será minimizado para criar um lote com uma única mensagem por vez. |
Não |
latencyMs |
O intervalo de tempo máximo em milissegundos em que as mensagens podem ser armazenadas em buffer antes de serem enviadas. Se esse intervalo for atingido, todas as mensagens em buffer serão enviadas como um lote, independentemente de quantas ou quão grandes elas sejam. Se não for definido, o valor padrão será 5. | Não |
maxMessages |
O número máximo de mensagens que podem ser armazenadas em buffer antes de serem enviadas. Se esse número for atingido, todas as mensagens armazenadas em buffer serão enviadas como um lote, independentemente do tamanho ou da duração do armazenamento em buffer. Se não for definido, o valor padrão será 100000. | Não |
maxBytes |
O tamanho máximo em bytes que pode ser armazenado em buffer antes de ser enviado. Se esse tamanho for atingido, todas as mensagens armazenadas em buffer serão enviadas como um lote, independentemente de quantas ou por quanto tempo elas permanecerão armazenadas em buffer. O valor padrão é 1000000 (1 MB). | Não |
Por exemplo, se você definir latencyMs como 1000, maxMessages como 100 e maxBytes como 1024, as mensagens serão enviadas quando houver 100 mensagens no buffer, ou quando houver 1.024 bytes no buffer, ou quando se passarem 1.000 milissegundos desde o último envio, o que ocorrer primeiro.
Para configurar o envio em lote:
Na página de configurações do ponto de extremidade de fluxo de dados da experiência de operações, selecione a guia Avançado e use o campo Habilitado para lote para habilitar o envio em lote. Use os campos Latência do envio em lote, Máximo de bytes e Contagem de mensagens para especificar as configurações do envio em lote.
Essa configuração entrará em vigor somente se o ponto de extremidade for usado como um destino em que o fluxo de dados é um produtor.
Estratégia de manipulação de partições
A estratégia de tratamento de partição controla como as mensagens são atribuídas às partições do Kafka ao enviá-las para tópicos do Kafka. As partições Kafka são segmentos lógicos de um tópico Kafka que permitem processamento paralelo e tolerância a falhas. Cada mensagem em um tópico do Kafka tem uma partição e um deslocamento que são usados para identificar e ordenar as mensagens.
Essa configuração entrará em vigor somente se o ponto de extremidade for usado como um destino em que o fluxo de dados é um produtor.
Por padrão, um fluxo de dados atribui mensagens a partições aleatórias, usando um algoritmo round-robin. No entanto, você pode usar estratégias diferentes para atribuir mensagens a partições com base em alguns critérios, como o nome do tópico MQTT ou uma propriedade de mensagem MQTT. Isso pode ajudá-lo a obter melhor balanceamento de carga, localidade de dados ou ordenação de mensagens.
| Valor | Descrição |
|---|---|
Default |
Atribui mensagens a partições aleatórias, usando um algoritmo round-robin. Este é o valor padrão se nenhuma estratégia for especificada. |
Static |
Atribui mensagens a um número de partição fixo derivado da ID do fluxo de dados. Isso significa que cada instância do fluxo de dados envia mensagens para uma partição diferente. Isso pode ajudar a obter melhor balanceamento de carga e localidade de dados. |
Topic |
Usa o nome do tópico do MQTT da fonte de fluxo de dados como a chave para particionamento. Isso significa que as mensagens com o mesmo nome de tópico MQTT são enviadas para a mesma partição. Isso pode ajudar a obter uma melhor ordenação de mensagens e localidade de dados. |
Property |
Usa uma propriedade de mensagem do MQTT da fonte de fluxo de dados como a chave para particionamento. Especifique o nome da propriedade no campo partitionKeyProperty. Isso significa que as mensagens com o mesmo valor de propriedade são enviadas para a mesma partição. Isso pode ajudar a obter uma melhor ordenação de mensagens e localidade de dados com base em um critério personalizado. |
Por exemplo, se você definir a estratégia de manipulação de partições como Property e a propriedade da chave de partição como device-id, as mensagens com a mesma propriedade device-id são enviadas para a mesma partição.
Para configurar a estratégia de manipulação de partição:
Na página de configurações do ponto de extremidade de fluxo de dados da experiência de operações, selecione a guia Avançado e use o campo Estratégia de manipulação de partições para especificar a estratégia de manipulação de partições. Use o campo Propriedade da chave de partição para especificar a propriedade usada para particionamento se a estratégia estiver definida como Property.
Reconhecimentos do Kafka
Os reconhecimentos do Kafka (acks) são usados para controlar a durabilidade e a consistência das mensagens enviadas aos tópicos do Kafka. Quando um produtor envia uma mensagem para um tópico do Kafka, ele pode solicitar diferentes níveis de reconhecimentos do agente Kafka para garantir que a mensagem seja gravada com êxito no tópico e replicada no cluster do Kafka.
Essa configuração só entrará em vigor se o ponto de extremidade for usado como um destino (ou seja, o fluxo de dados é um produtor).
| Valor | Descrição |
|---|---|
None |
O fluxo de dados não aguarda os reconhecimentos do agente Kafka. Essa configuração é a opção mais rápida, mas menos durável. |
All |
O fluxo de dados aguarda que a mensagem seja gravada na partição de líder e em todas as partições de seguidor. Essa configuração é a opção mais lenta, porém mais durável. Essa configuração também é a opção padrão |
One |
O fluxo de dados aguarda que a mensagem seja gravada na partição de líder e pelo menos uma partição de seguidor. |
Zero |
O fluxo de dados aguarda que a mensagem seja gravada na partição líder, mas não espera por nenhum reconhecimento dos seguidores. Isso é mais rápido do que One, mas menos durável. |
Por exemplo, se você definir a confirmação do Kafka como All, o fluxo de dados aguardará que a mensagem seja gravada na partição líder e em todas as partições seguidoras antes de enviar a próxima mensagem.
Para configurar os reconhecimentos do Kafka:
Na página de configurações do ponto de extremidade do fluxo de dados da experiência de operações, selecione a guia Avançado e use o campo Confirmação do Kafka para especificar o nível de confirmação do Kafka.
Essa configuração só entra em vigor se o ponto de extremidade for usado como um destino onde o fluxo de dados é um produtor.
Copie as propriedades do MQTT
Por padrão, a configuração de propriedades do MQTT de cópia está habilitada. Essas propriedades do usuário incluem valores como subject, que armazena o nome do ativo que está enviando a mensagem.
Na página de configurações do ponto de extremidade de fluxo de dados da experiência de operações, selecione a guia Avançado e marque a caixa ao lado do campo Copiar propriedades MQTT para habilitar ou desabilitar a cópia das propriedades MQTT.
As seções a seguir descrevem como as propriedades do MQTT são traduzidas para cabeçalhos de usuário do Kafka e vice-versa quando a configuração está habilitada.
O ponto de extremidade do Kafka é um destino
Quando um ponto de extremidade do Kafka é um destino de fluxo de dados, todas as propriedades definidas pela especificação do MQTT v5 são cabeçalhos de usuário do Kafka traduzidos. Por exemplo, uma mensagem do MQTT v5 com "Tipo de Conteúdo" sendo encaminhada ao Kafka se traduz no cabeçalho do usuário do Kafka"Content Type":{specifiedValue}. Regras semelhantes se aplicam a outras propriedades do MQTT internas, definidas na tabela a seguir.
| Propriedade do MQTT | Comportamento traduzido |
|---|---|
| Indicador de formato de conteúdo | Chave: "Indicador de Formato de Conteúdo" Valor: "0" (o conteúdo é bytes) ou "1" (o conteúdo é UTF-8) |
| Tópico de Resposta | Chave: "Tópico de Resposta" Valor: Cópia do Tópico de Resposta da mensagem original. |
| Intervalo de Expiração da Mensagem | Chave: "Intervalo de Expiração da Mensagem" Valor: representação UTF-8 de número de segundos antes da mensagem expirar. Consulte a propriedade de Intervalo de Expiração de Mensagem para obter mais detalhes. |
| Dados de Correlação: | Chave: "Dados de Correlação" Valor: cópia dos Dados de Correlação da mensagem original. Ao contrário de muitas propriedades do MQTT v5 codificadas em UTF-8, os dados de correlação podem ser dados arbitrários. |
| Tipo de Conteúdo: | Chave: "Tipo de Conteúdo" Valor: cópia do Tipo de Conteúdo da mensagem original. |
Os pares de valor da chave de propriedade do usuário do MQTT v5 são traduzidos diretamente para cabeçalhos de usuário do Kafka. Se um cabeçalho de usuário em uma mensagem tiver o mesmo nome de uma propriedade do MQTT interna (por exemplo, um cabeçalho de usuário chamado "Dados de Correlação"), então, se o encaminhamento do valor da propriedade de especificação do MQTT v5 ou a propriedade do usuário será indefinido.
Os fluxos de dados nunca recebem essas propriedades de um Agente MQTT. Assim, um fluxo de dados nunca os encaminha:
- Alias do Tópico
- Identificadores de assinatura
A propriedade de Intervalo de Expiração da Mensagem
O Intervalo de Expiração da Mensagem especifica por quanto tempo uma mensagem pode permanecer em um agente MQTT antes de ser descartada.
Quando um fluxo de dados recebe uma mensagem do MQTT com o Intervalo de Expiração da Mensagem especificado, ele:
- Registra a hora em que a mensagem foi recebida.
- Antes que a mensagem seja emitida para o destino, o tempo é subtraído da mensagem que foi colocada na fila do tempo de intervalo de expiração original.
- Se a mensagem não tiver expirado (a operação acima é > 0), a mensagem será emitida para o destino e conterá o Tempo de Expiração da Mensagem atualizado.
- Se a mensagem tiver expirado (a operação acima é <= 0), então, a mensagem não será emitida pelo Destino.
Exemplos:
- Um fluxo de dados recebe uma mensagem do MQTT com Intervalo de Expiração de Mensagem = 3.600 segundos. O destino correspondente está temporariamente desconectado, mas pode se reconectar. 1.000 segundos passam antes que essa mensagem MQTT seja enviada para o Destino. Nesse caso, a mensagem do destino tem seu Intervalo de Expiração de Mensagem definido como 2.600 (3.600 a 1.000) segundos.
- O fluxo de dados recebe uma mensagem do MQTT com Intervalo de Expiração da Mensagem = 3.600 segundos. O destino correspondente está temporariamente desconectado, mas pode se reconectar. Nesse caso, no entanto, leva 4.000 segundos para se reconectar. A mensagem expirou e o fluxo de dados não encaminha essa mensagem para o destino.
O ponto de extremidade do Kafka é uma fonte de fluxo de dados
Observação
Há um problema conhecido ao usar o ponto de extremidade dos Hubs de Eventos como uma fonte de fluxo de dados em que o cabeçalho do Kafka é corrompido como traduzido para MQTT. Isso só acontecerá caso esteja usando o Hub de Eventos no entanto, o cliente do Hub de Eventos que usa o AMQP sob as coberturas. Por exemplo, "foo"="bar", o "foo" é traduzido, mas o valor se torna"\xa1\x03bar".
Quando um ponto de extremidade do Kafka é uma fonte de fluxo de dados, os cabeçalhos de usuário do Kafka são traduzidos para propriedades do MQTT v5. A tabela a seguir descreve como os cabeçalhos de usuário do Kafka são traduzidos para propriedades do MQTT v5.
| Cabeçalho do Kafka | Comportamento traduzido |
|---|---|
| Chave | Chave: "Chave" Valor: cópia da Chave da mensagem original. |
| Timestamp | Chave: "Carimbo de data/hora" Valor: codificação UTF-8 do Carimbo de Data/Hora do Kafka, que é o número de milissegundos desde a época do Unix. |
Os pares chave/valor do cabeçalho do usuário do Kafka, desde que estejam todos codificados em UTF-8, são traduzidos diretamente em propriedades de chave/valor do usuário do MQTT.
UTF-8/Incompatibilidades binárias
O MQTT v5 só pode dar suporte a propriedades baseadas em UTF-8. Se o fluxo de dados receber uma mensagem do Kafka que contenha um ou mais cabeçalhos não de UTF-8, o fluxo de dados será:
- Remova a propriedade ou as propriedades ofensivas.
- Encaminhe o restante da mensagem, seguindo as regras anteriores.
Aplicativos que exigem transferência binária em cabeçalhos de origem do Kafka => propriedades de destino do MQTT devem primeiro codificar UTF-8, por exemplo, através da Base64.
Incompatibilidades da propriedade >=64KB
As propriedades do MQTT v5 devem ser menores que 64 KB. Se o fluxo de dados receber uma mensagem do Kafka que contenha um ou mais cabeçalhos que seja >= 64 KB, o fluxo de dados será:
- Remova a propriedade ou as propriedades ofensivas.
- Encaminhe o restante da mensagem, seguindo as regras anteriores.
Conversão de propriedades ao usar Hubs de Eventos e produtores que usam o AMQP
Caso tenha um cliente encaminhando mensagens para um ponto de extremidade de fonte de fluxo de dados do Kafka executando qualquer uma das seguintes ações:
- Enviar mensagens para Hubs de Eventos usando bibliotecas de clientes como Azure.Messaging.EventHubs
- Usando o AMQP diretamente
Há nuances de tradução de propriedade para estar ciente.
Você deverá fazer um dos seguintes procedimentos:
- Evitar o envio de propriedades
- Caso precise enviar propriedades, envie valores codificados como UTF-8.
Quando os Hubs de Eventos convertem propriedades do AMQP para o Kafka, ele inclui os tipos codificados do AMQP subjacentes em sua mensagem. Para obter mais informações sobre o comportamento, consulte Troca de eventos entre consumidores e produtores usando protocolos diferentes.
No exemplo de código a seguir, quando o ponto de extremidade do fluxo de dados recebe o valor "foo":"bar", ele recebe a propriedade como <0xA1 0x03 "bar">.
using global::Azure.Messaging.EventHubs;
using global::Azure.Messaging.EventHubs.Producer;
var propertyEventBody = new BinaryData("payload");
var propertyEventData = new EventData(propertyEventBody)
{
Properties =
{
{"foo", "bar"},
}
};
var propertyEventAdded = eventBatch.TryAdd(propertyEventData);
await producerClient.SendAsync(eventBatch);
O ponto de extremidade de fluxo de dados não pode encaminhar a propriedade de conteúdo <0xA1 0x03 "bar"> para uma mensagem do MQTT porque os dados não são UTF-8. No entanto, caso especifique uma cadeia de caracteres UTF-8, o ponto de extremidade de fluxo de dados converterá a cadeia de caracteres antes de enviar ao MQTT. Caso use uma cadeia de caracteres UTF-8, a mensagem do MQTT terá "foo":"bar" como propriedades do usuário.
Somente os cabeçalhos UTF-8 são traduzidos. Por exemplo, dado o seguinte cenário em que a propriedade é definida como um float:
Properties =
{
{"float-value", 11.9 },
}
O ponto de extremidade do fluxo de dados descarta pacotes que contêm o campo "float-value".
Nem todas as propriedades de dados de eventos, incluindo propertyEventData.correlationId, são encaminhadas. Para obter mais informações, confira Propriedades do Usuário do Evento,
CloudEvents
CloudEvents são uma maneira de descrever dados de evento de maneira comum. As configurações de CloudEvents são usadas para enviar ou receber mensagens no formato CloudEvents. Você pode usar CloudEvents para arquiteturas orientadas por eventos em que diferentes serviços precisam se comunicar entre si nos mesmos provedores de nuvem ou em provedores de nuvem diferentes.
As opções de CloudEventAttributes são Propagate ou CreateOrRemap.
Na página de configurações do ponto de extremidade de fluxo de dados da experiência de operações, selecione a guia Avançado e use o campo Atributos do evento em nuvem para especificar a configuração do CloudEvents.
As seções a seguir descrevem como as propriedades do CloudEvent são propagadas ou criadas e remapeadas.
Configuração Propagar
As propriedades do CloudEvent são passadas para mensagens que contêm as propriedades necessárias. Se a mensagem não contiver as propriedades necessárias, a mensagem será passada como está. Se as propriedades necessárias estiverem presentes, um prefixo ce_ será adicionado ao nome da propriedade de CloudEvent.
| Nome | Obrigatório | Valor de exemplo | Nome de saída | Valor de saída |
|---|---|---|---|---|
specversion |
Sim | 1.0 |
ce-specversion |
Passado como está |
type |
Sim | ms.aio.telemetry |
ce-type |
Passado como está |
source |
Sim | aio://mycluster/myoven |
ce-source |
Passado como está |
id |
Sim | A234-1234-1234 |
ce-id |
Passado como está |
subject |
Não | aio/myoven/telemetry/temperature |
ce-subject |
Passado como está |
time |
Não | 2018-04-05T17:31:00Z |
ce-time |
Passado como está. Não é carimbado novamente. |
datacontenttype |
Não | application/json |
ce-datacontenttype |
Alterado para o tipo de conteúdo de dados de saída após o estágio de transformação opcional. |
dataschema |
Não | sr://fabrikam-schemas/123123123234234234234234#1.0.0 |
ce-dataschema |
Se um esquema de transformação de dados de saída for fornecido na configuração de transformação, dataschema será alterado para o esquema de saída. |
Configuração CreateOrRemap
As propriedades do CloudEvent são passadas para mensagens que contêm as propriedades necessárias. Se a mensagem não contiver as propriedades necessárias, as propriedades serão geradas.
| Nome | Obrigatório | Nome de saída | Valor gerado se ausente |
|---|---|---|---|
specversion |
Sim | ce-specversion |
1.0 |
type |
Sim | ce-type |
ms.aio-dataflow.telemetry |
source |
Sim | ce-source |
aio://<target-name> |
id |
Sim | ce-id |
UUID gerado no cliente de destino |
subject |
Não | ce-subject |
O tópico de saída para onde a mensagem é enviada |
time |
Não | ce-time |
Gerado como RFC 3339 no cliente de destino |
datacontenttype |
Não | ce-datacontenttype |
Alterado para o tipo de conteúdo de dados de saída após o estágio de transformação opcional |
dataschema |
Não | ce-dataschema |
Esquema definido no registro de esquema |
Próximas etapas
Para saber mais sobre fluxos de dados, confira Criar um fluxo de dados.