Configurar fluxos de dados no Azure IoT Operations
Importante
Esta página inclui instruções para gerenciar componentes do serviço Operações do Azure IoT usando manifestos de implantação do Kubernetes, que estão em versão prévia. Esse recurso é fornecido com várias limitações, e não deve ser usado para cargas de trabalho de produção.
Veja os Termos de Uso Complementares para Versões Prévias do Microsoft Azure para obter termos legais que se aplicam aos recursos do Azure que estão em versão beta, versão prévia ou que, de outra forma, ainda não foram lançados em disponibilidade geral.
Um fluxo de dados é o caminho que os dados percorrem da origem ao destino com transformações opcionais. Você pode configurar o fluxo de dados criando um recurso personalizado Fluxo de dados ou usando o portal do Azure IoT Operations Studio. Um fluxo de dados é composto de três partes: a origem, a transformação e o destino.

Para definir a origem e o destino, você precisa configurar os pontos de extremidade de fluxo de dados. A transformação é opcional e pode incluir operações como enriquecimento de dados, filtragem de dados e mapeamento de dados para outro campo.
Importante
Cada fluxo de dados deve ter o ponto de extremidade padrão do agente MQTT local das Operações de IoT do Azure como qualquer a origem ou o destino.
Você pode usar a experiência de operações no Azure IoT Operations para criar um fluxo de dados. A experiência de operações fornece uma interface visual para configurar o fluxo de dados. Você também pode usar o Bicep para criar um fluxo de dados usando um arquivo de modelo Bicep ou usar o Kubernetes para criar um fluxo de dados usando um arquivo YAML.
Continue lendo para saber como configurar a fonte, a transformação e o destino.
Pré-requisitos
Você pode implantar fluxos de dados assim que tiver uma instância do Azure IoT Operations usando o perfil de fluxo de dados e o ponto de extremidade padrão. No entanto, talvez você queira configurar perfis de fluxo de dados e pontos de extremidade para personalizar o fluxo de dados.
Perfil de fluxo de dados
Se você não precisar de configurações de dimensionamento diferentes para seus fluxos de dados, use o perfil de fluxo de dados padrão fornecido pelo Azure IoT Operations. Para saber como configurar um perfil de fluxo de dados, consulte Configurar perfis de fluxo de dados.
Pontos de extremidade de fluxo de dados
Os pontos de extremidade de fluxo de dados são necessários para configurar a origem e o destino do fluxo de dados. Para começar rapidamente, você pode usar o ponto de extremidade de fluxo de dados padrão para o broker MQTT local. Você também pode criar outros tipos de pontos de extremidade de fluxo de dados, como Kafka, Hubs de Eventos ou Azure Data Lake Storage. Para saber como configurar cada tipo de ponto de extremidade de fluxo de dados, consulte Configurar pontos de extremidade de fluxo de dados.
Introdução
Depois de ter os pré-requisitos, você pode começar a criar um fluxo de dados.
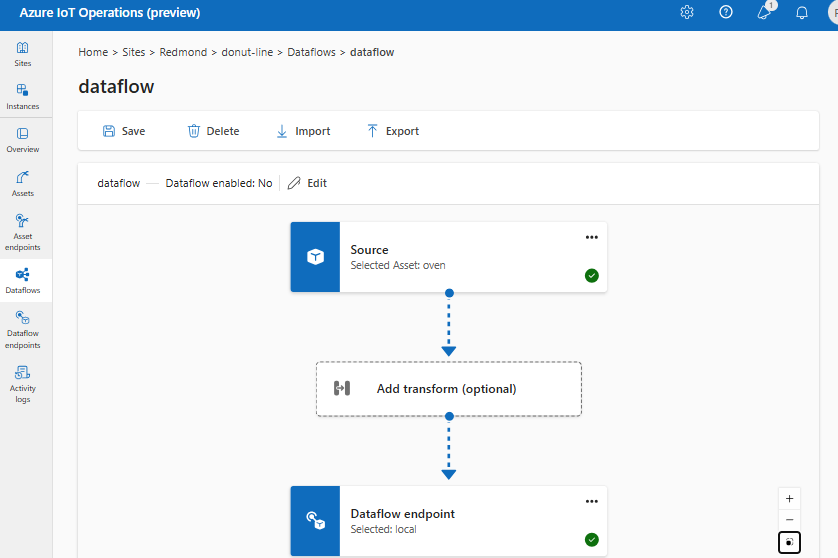
Para criar um fluxo de dados na experiência de operações, selecione Fluxo de dados>Criar fluxo de dados. Em seguida, você verá a página em que pode configurar a origem, a transformação e o destino do fluxo de dados.
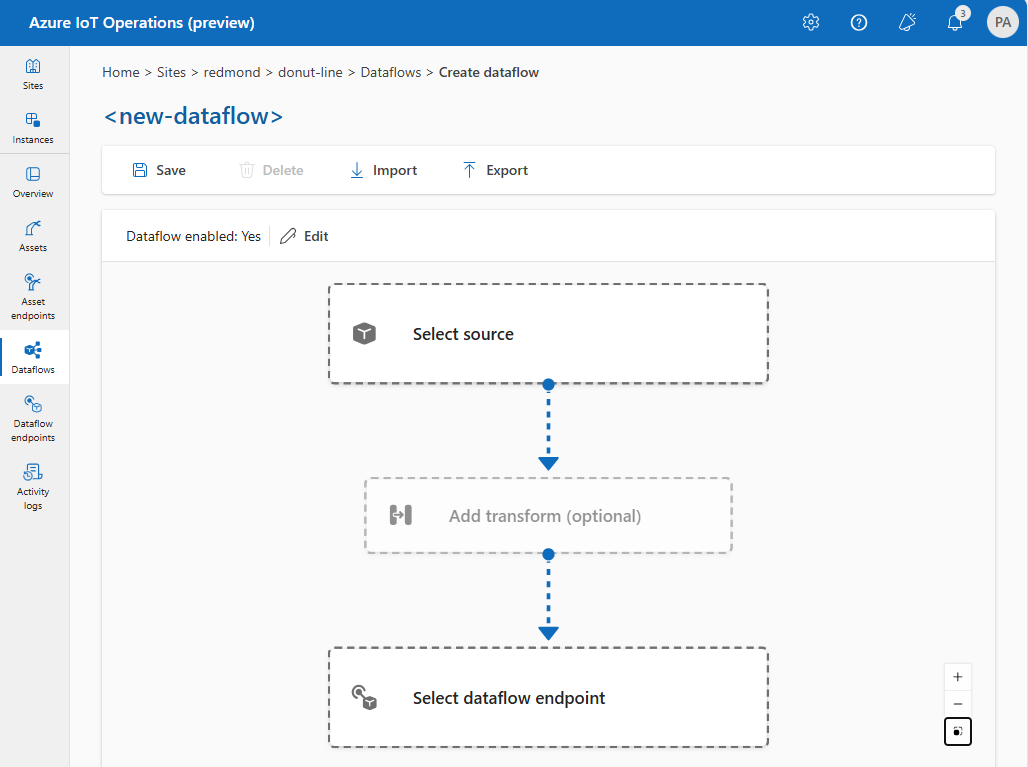
Examine as seções a seguir para saber como configurar os tipos de operação do fluxo de dados.
Origem
Para configurar uma fonte para o fluxo de dados, especifique a referência do ponto de extremidade e uma lista de fontes de dados para o ponto de extremidade. Escolha uma das opções a seguir como a origem do fluxo de dados.
Se o ponto de extremidade padrão não for usado como origem, ele deve ser usado como destino. Para saber mais sobre, consulte Os fluxos de dados devem usar o ponto de extremidade do agente MQTT local.
Opção 1: usar o ponto de extremidade do agente de mensagens padrão como origem
Em Detalhes da fonte, selecione Agente de mensagens.
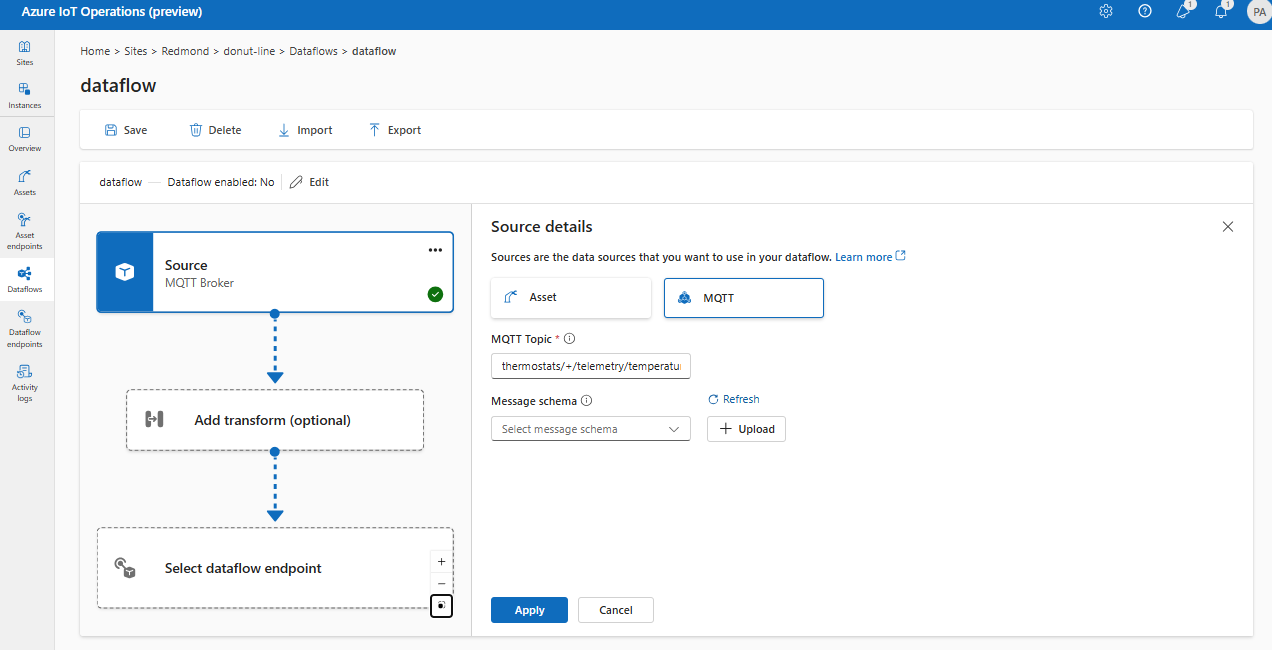
Insira as seguintes configurações para a fonte do agente de mensagens:
Configuração Descrição Ponto de extremidade de fluxo de dados Selecione padrão para usar o ponto de extremidade do agente de mensagens MQTT padrão. Tópico O filtro de tópico a ser assinado para as mensagens de entrada. Use Tópico(s)>Adicionar linha para adicionar vários tópicos. Para obter mais informações sobre tópicos, consulte Configurar tópicos MQTT ou Kafka. Esquema de mensagem O esquema a ser usado para desserializar as mensagens de entrada. Confira Especificar o esquema para desserializar dados. Escolha Aplicar.
Opção 2: Usar o ativo como origem
Você pode usar um ativo como a origem do fluxo de dados. O uso de um ativo como fonte só está disponível na experiência de operações.
Em Detalhes da fonte, selecione Ativo.
Selecione o ativo que você deseja usar como ponto de extremidade de origem.
Selecione Continuar.
Uma lista de pontos de dados para o ativo selecionado é exibida.
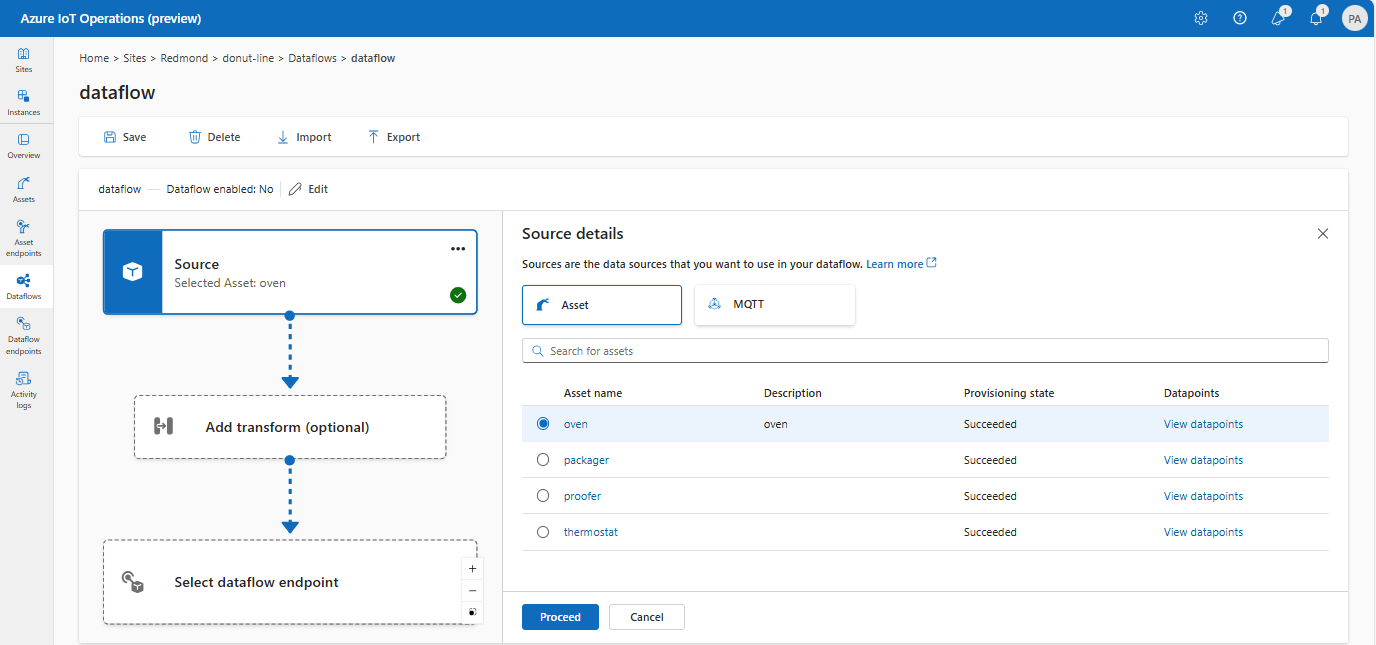
Selecione Aplicar para usar o ativo como o ponto de extremidade de origem.
Ao usar um ativo como origem, a definição de ativo é usada para inferir o esquema para o fluxo de dados. A definição do ativo inclui o esquema para os pontos de dados do ativo. Para saber mais, consulte Gerenciar configurações do ativo remotamente.
Uma vez configurados, os dados do ativo chegam ao fluxo de dados por meio do broker MQTT local. Portanto, ao usar um ativo como origem, o fluxo de dados usa o ponto de extremidade padrão do broker MQTT local como a origem na realidade.
Opção 3: usar o ponto de extremidade de fluxo de dados MQTT ou Kafka personalizado como origem
Se você criou um ponto de extremidade de fluxo de dados MQTT ou Kafka personalizado (por exemplo, para usar com a Grade de Eventos ou os Hubs de Eventos), poderá usá-lo como a origem do fluxo de dados. Lembre-se de que os pontos de extremidade do tipo de armazenamento, como Data Lake ou Fabric OneLake, não podem ser usados como fonte.
Em Detalhes da fonte, selecione Agente de mensagens.
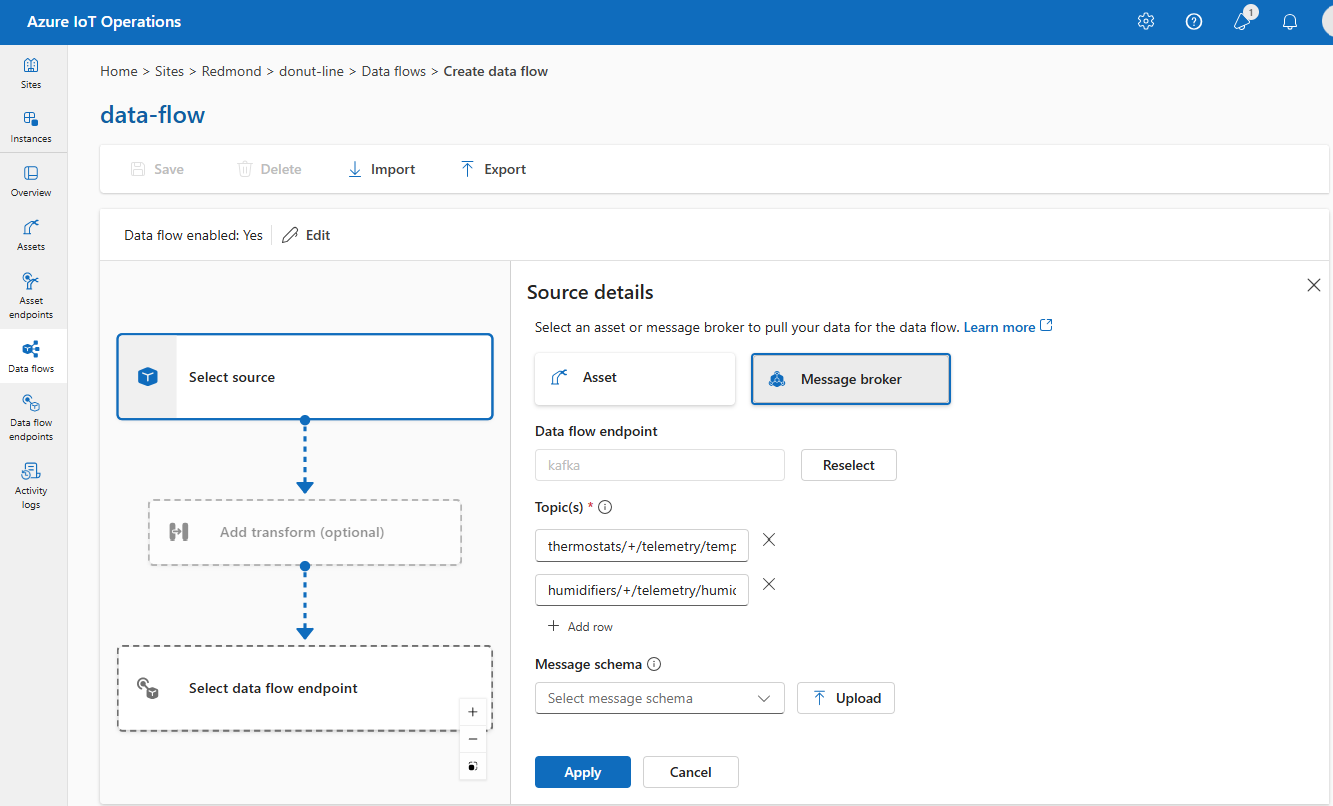
Insira as seguintes configurações para a fonte do agente de mensagens:
Configuração Descrição Ponto de extremidade de fluxo de dados Use o botão Selecionar novamente para selecionar um ponto de extremidade de fluxo de dados MQTT ou Kafka personalizado. Para obter mais informações, consulte Configurar pontos de extremidade de fluxo de dados MQTT ou Configurar pontos de extremidade de fluxo de dados do Azure Event Hubs e Kafka. Tópico O filtro de tópico a ser assinado para as mensagens de entrada. Use Tópico(s)>Adicionar linha para adicionar vários tópicos. Para obter mais informações sobre tópicos, consulte Configurar tópicos MQTT ou Kafka. Esquema de mensagem O esquema a ser usado para desserializar as mensagens de entrada. Confira Especificar o esquema para desserializar dados. Escolha Aplicar.
Configurar fontes de dados (tópicos MQTT ou Kafka)
Você pode especificar vários tópicos MQTT ou Kafka em uma origem sem precisar modificar a configuração do ponto de extremidade do fluxo de dados. Essa flexibilidade significa que o mesmo ponto de extremidade pode ser reutilizado em vários fluxos de dados, mesmo que os tópicos variem. Para obter mais informações, consulte Reutilizar pontos de extremidade de fluxo de dados.
Tópicos do MQTT
Quando a fonte for um ponto de extremidade MQTT (Grade de Eventos incluída), você pode usar o filtro de tópico MQTT para assinar mensagens de entrada. O filtro de tópico pode incluir curingas para assinar vários tópicos. Por exemplo, thermostats/+/telemetry/temperature/# assina todas as mensagens de telemetria de temperatura dos termostatos. Para configurar os filtros de tópico do MQTT:
No fluxo de dados de experiência de operações Detalhes da origem, selecione Message broker e use o campo Tópico(s) para especificar os filtros de tópico MQTT para assinar mensagens recebidas. Você pode adicionar vários tópicos MQTT selecionando Adicionar linha e inserindo um novo tópico.
Assinaturas compartilhadas
Para usar assinaturas compartilhadas com fontes do agente de mensagens, você pode especificar o tópico de assinatura compartilhada no formato de $shared/<GROUP_NAME>/<TOPIC_FILTER>.
No fluxo de dados da experiência de operações Detalhes da fonte, selecione Agente de mensagens e use o campo Tópico para especificar o grupo de assinatura compartilhado e o tópico.
Se a contagem de instâncias no perfil de fluxo de dados for maior que um, a assinatura compartilhada será ativada automaticamente para todos os fluxos de dados que usam uma origem do agente de mensagens. Neste caso, o prefixo $shared é adicionado e o nome do grupo de assinatura compartilhada gerado automaticamente. Por exemplo, se você tiver um perfil de fluxo de dados com uma contagem de instâncias de 3 e seu fluxo de dados usar um ponto de extremidade do agente de mensagens como origem configurada com tópicos topic1 e topic2, eles serão convertidos automaticamente em assinaturas compartilhadas como $shared/<GENERATED_GROUP_NAME>/topic1 e $shared/<GENERATED_GROUP_NAME>/topic2.
Você pode criar explicitamente um tópico nomeado $shared/mygroup/topic em sua configuração. No entanto, adicionar o tópico $shared explicitamente não é recomendado, pois o prefixo $shared é adicionado automaticamente quando necessário. Os fluxos de dados podem fazer otimizações com o nome do grupo se ele não estiver definido. Por exemplo, $share não está definido e os fluxos de dados só precisam operar sobre o nome do tópico.
Importante
Os fluxos de dados que exigem assinatura compartilhada quando a contagem de instâncias é maior que um são importantes ao usar o agente MQTT da Grade de Eventos como origem, pois ele não dá suporte a assinaturas compartilhadas. Para evitar mensagens ausentes, defina a contagem de instâncias do perfil de fluxo de dados como um ao usar o agente MQTT da Grade de Eventos como a origem. É quando o fluxo de dados é o assinante e recebe mensagens da nuvem.
Tópico do Kafka
Quando a origem for um ponto de extremidade Kafka (Hubs de Eventos do Azure incluídos), especifique os tópicos individuais do Kafka aos quais assinar mensagens de entrada. Não há suporte para curingas, portanto, você deve especificar cada tópico estaticamente.
Observação
Ao usar os Hubs de Eventos por meio do ponto de extremidade do Kafka, cada hub de eventos individual dentro do namespace é o tópico do Kafka. Por exemplo, se você tiver um namespace dos Hubs de Eventos com dois hubs de eventos, thermostats e humidifiers, poderá especificar cada hub de eventos como um tópico do Kafka.
Para configurar os tópicos do Kafka:
No fluxo de dados da experiência de operações Detalhes da origem, selecione Agente de mensagens e use o campo Tópico para especificar o filtro de tópico do Kafka para assinar mensagens de entrada.
Observação
Somente um filtro de tópico pode ser especificado na experiência de operações. Para usar vários filtros de tópico, use o Bicep ou o Kubernetes.
Especificar esquema de origem
Ao usar MQTT ou Kafka como origem, você pode especificar um esquema para exibir a lista de pontos de dados no portal de experiência de operações. No momento, não há suporte para usar um esquema para desserializar e validar mensagens de entrada.
Se a fonte for um ativo, o esquema será automaticamente inferido da definição de ativo.
Dica
Para gerar o esquema de um arquivo de dados de exemplo, use o Auxiliar de Geração de Esquema.
Para configurar o esquema usado para desserializar as mensagens de entrada de uma fonte:
No fluxo de dados da experiência de operações Detalhes da fonte, selecione Agente de mensagens e use o campo Esquema de mensagem para especificar o esquema. Você pode usar o botão Carregar para carregar um arquivo de esquema primeiro. Para saber mais, confira Entenda os esquemas de mensagens.
Para saber mais, confira Entenda os esquemas de mensagens.
Transformação
A operação de transformação é o local em que você pode transformar os dados da fonte antes de enviá-los para o destino. As transformações são opcionais. Se você não precisar fazer alterações nos dados, não inclua a operação de transformação na configuração do fluxo de dados. Várias transformações são encadeadas em fases, independentemente da ordem em que são especificadas na configuração. A ordem dos estágios é sempre:
- Enriquecer: adicione dados adicionais aos dados de origem, considerando um conjunto de dados e uma condição correspondente.
- Filtro: Filtra os dados com base em uma condição.
- Mapear, Computação, Renomear ou adicionar uma Nova propriedade: mover dados de um campo para outro com uma conversão opcional.
Esta seção é uma introdução às transformações de fluxo de dados. Para obter informações mais detalhadas, consulte Mapear dados usando fluxos de dados, Converter dados usando conversões de fluxo de dados e Enriquecer dados usando fluxos de dados.
Na experiência de operações, selecione Fluxo de dados>Adicionar transformação (opcional).
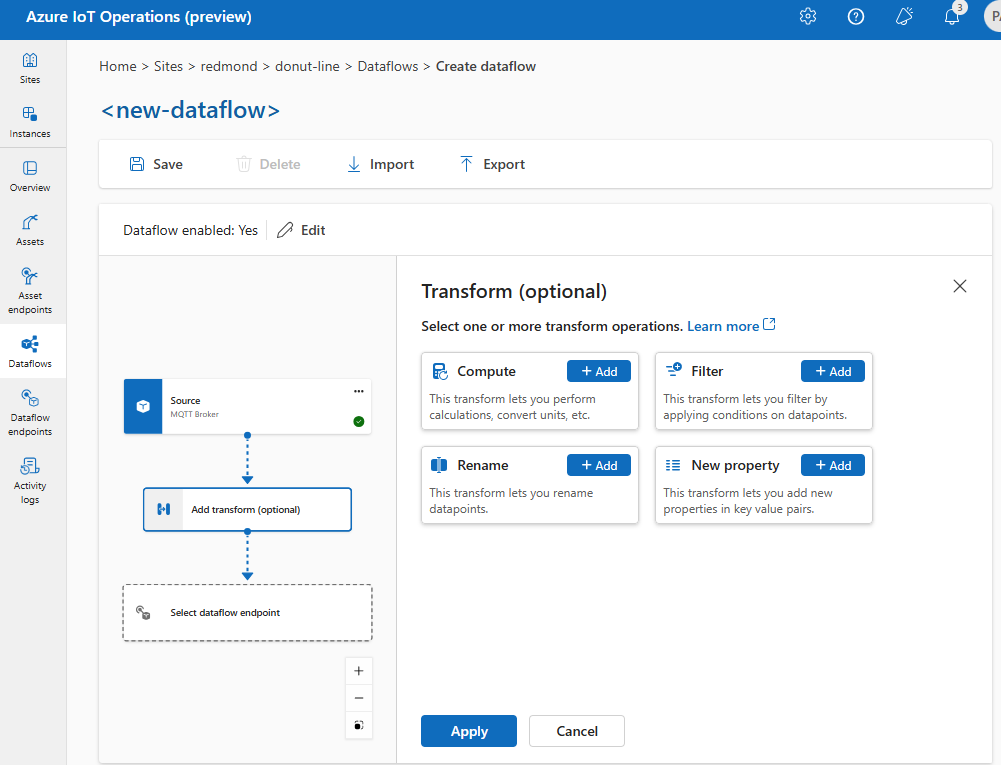
Enriquecer: adicionar dados de referência
Para enriquecer os dados, primeiro adicione o conjunto de dados de referência no repositório de estado das Operações do Azure IoT. O conjunto de dados é usado para adicionar dados extras aos dados de origem com base em uma condição. A condição é especificada como um campo nos dados de origem que corresponde a um campo no conjunto de dados.
Você pode carregar dados de exemplo no repositório de estado usando a CLI do repositório de estado. Os nomes de chave no repositório de estado correspondem a um conjunto de dados na configuração do fluxo de dados.
Atualmente, não há suporte para o estágio Enriquecer na experiência de operações.
Se o conjunto de dados tiver um registro com o campo asset, semelhante a:
{
"asset": "thermostat1",
"location": "room1",
"manufacturer": "Contoso"
}
Os dados da fonte com o campo deviceId correspondente a thermostat1 têm os campos location e manufacturer disponíveis nos estágios de filtro e mapa.
Para obter mais informações sobre a sintaxe de condição, consulte Enriquecer dados usando fluxos de dados e Converter dados usando fluxos de dados.
Filtro: filtrar dados com base em uma condição
Para filtrar os dados em uma condição, você pode usar o estágio filter. A condição é especificada como um campo nos dados de origem que corresponde a um valor.
Em Transformar (opcional), selecione Filtrar>Adicionar.
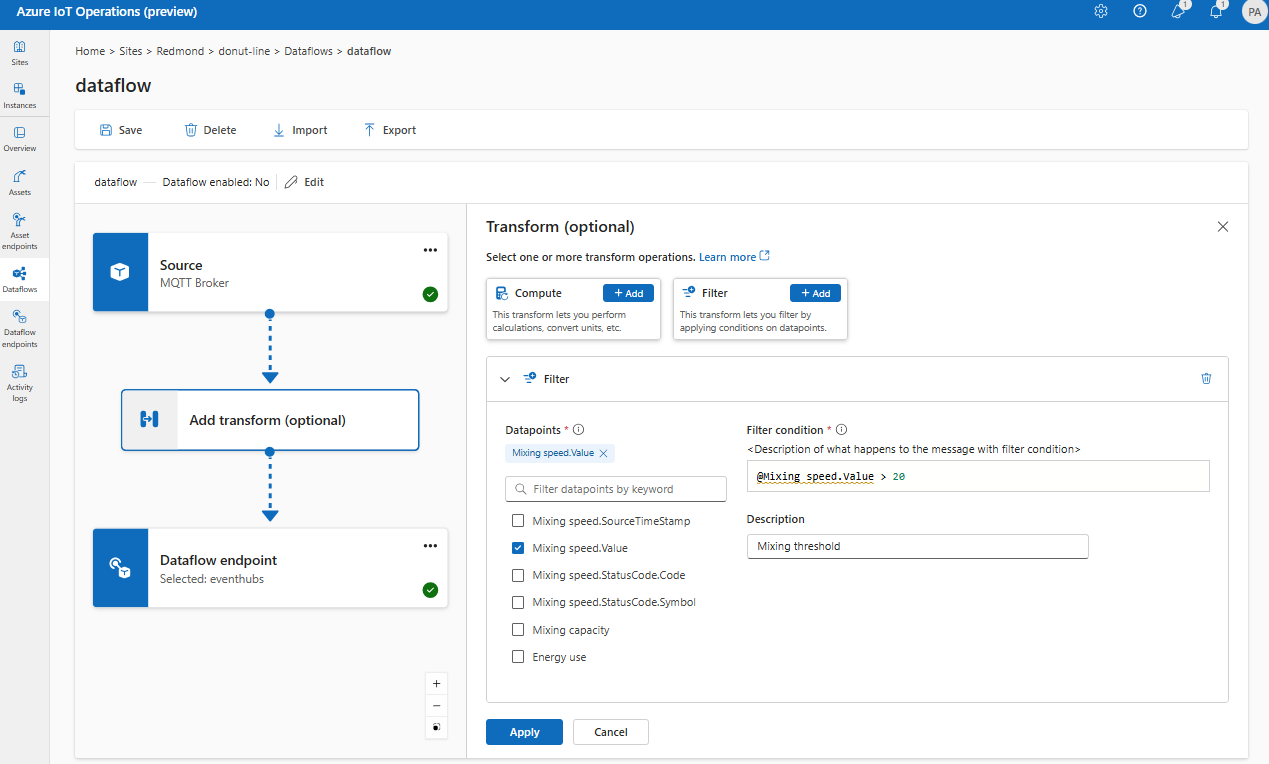
Insira as configurações necessárias.
Configuração Descrição Condição de filtro A condição para filtrar os dados com base em um campo nos dados de origem. Descrição Forneça uma descrição para a condição de filtro. No campo de condição de filtro, insira
@ou selecione Ctrl + Espaço para escolher pontos de dados em uma lista suspensa.Você pode inserir propriedades de metadados MQTT usando o formato
@$metadata.user_properties.<property>ou@$metadata.topic. Você também pode inserir cabeçalhos $metadata usando o formato@$metadata.<header>. A sintaxe$metadatasó é necessária para propriedades MQTT que fazem parte do cabeçalho da mensagem. Para mais informações, confira referências de campo.A condição pode usar os campos nos dados de origem. Por exemplo, você pode usar uma condição de filtro como
@temperature > 20para filtrar dados menores ou iguais a 20 com base no campo de temperatura.Escolha Aplicar.
Mapeamento: mover dados de um campo para outro
Para mapear os dados para outro campo com conversão opcional, você pode usar a operação map. A conversão é especificada como uma fórmula que usa os campos nos dados de origem.
Na experiência de operações, atualmente há suporte para mapeamento usando transformações Computação, Renomear, e Nova Propriedade.
Computação
Você pode usar a transformação Computação para aplicar uma fórmula aos dados de origem. Essa operação é usada para aplicar uma fórmula aos dados de origem e armazenar o campo de resultado.
Em Transformar (opcional), selecione Calcular >Adicionar.
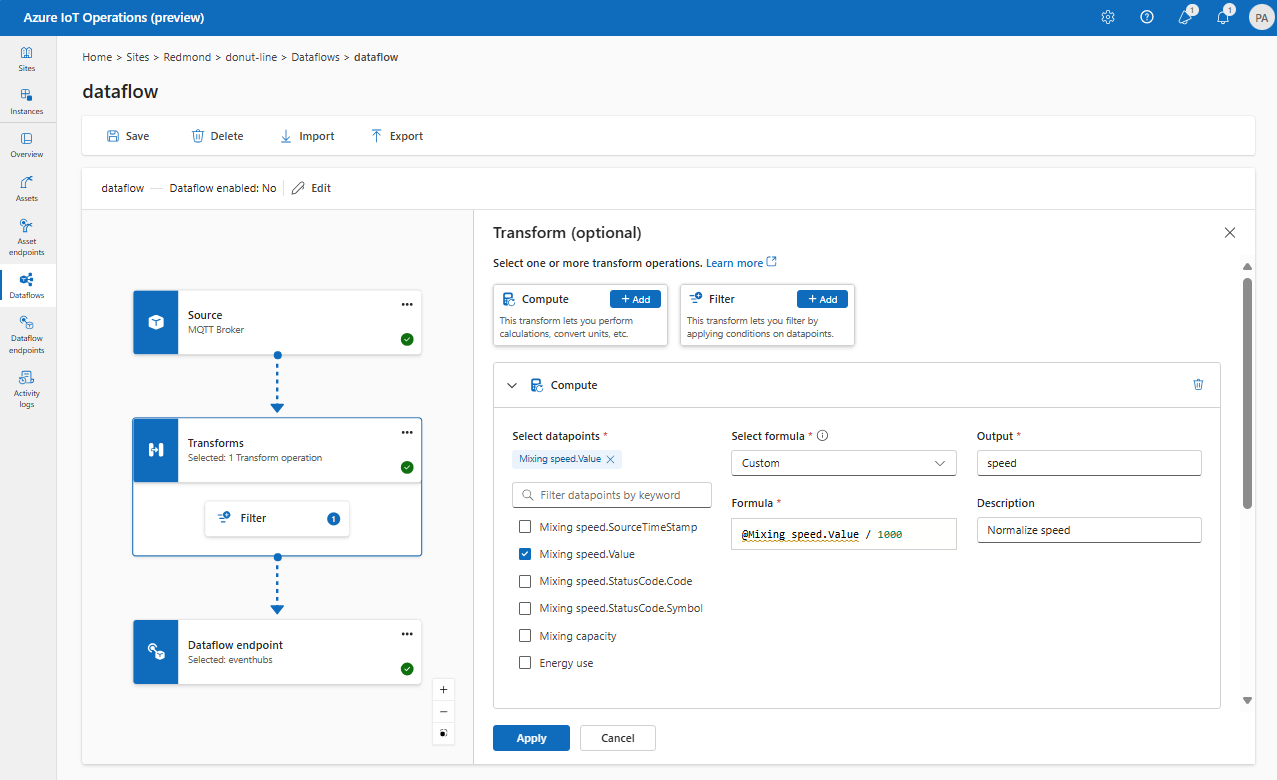
Insira as configurações necessárias.
Configuração Descrição Selecionar fórmula Escolha uma fórmula existente na lista suspensa ou selecione Personalizar para inserir uma fórmula manualmente. Saída Especifique o nome de exibição de saída para o resultado. Fórmula Insira a fórmula a ser aplicada aos dados de origem. Descrição Forneça uma descrição para a transformação. Último valor conhecido Opcionalmente, use o último valor conhecido se o valor atual não estiver disponível. Você pode inserir ou editar uma fórmula no campo Fórmula. A fórmula pode usar os campos nos dados de origem. Insira
@ou selecione Ctrl + Espaço para escolher pontos de dados em uma lista suspensa. Para fórmulas internas, selecione o espaço reservado<dataflow>para ver a lista de pontos de dados disponíveis.Você pode inserir propriedades de metadados MQTT usando o formato
@$metadata.user_properties.<property>ou@$metadata.topic. Você também pode inserir cabeçalhos $metadata usando o formato@$metadata.<header>. A sintaxe$metadatasó é necessária para propriedades MQTT que fazem parte do cabeçalho da mensagem. Para mais informações, confira referências de campo.A fórmula pode usar os campos nos dados de origem. Por exemplo, você pode usar o campo
temperaturenos dados de origem para converter a temperatura em Celsius e armazená-la no campo de saídatemperatureCelsius.Escolha Aplicar.
Renomear
Você pode renomear um ponto de dados usando a transformação Renomear. Essa operação é usada para renomear um ponto de dados nos dados de origem para um novo nome. O novo nome pode ser usado nos estágios subsequentes do fluxo de dados.
Em Transformar (opcional), selecione Renomear>Adicionar.
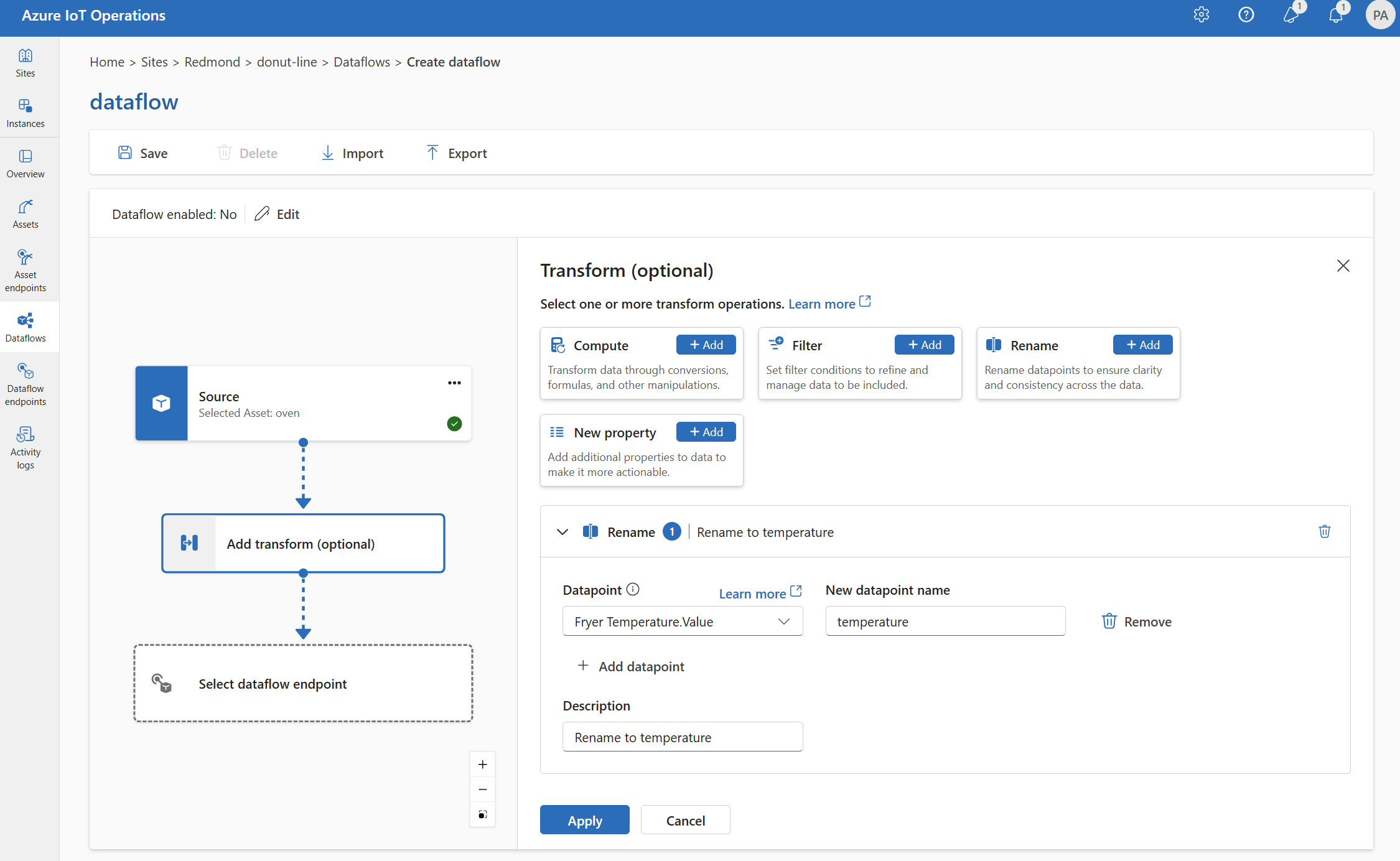
Insira as configurações necessárias.
Configuração Descrição Datapoint Selecione um ponto de dados na lista suspensa ou insira um cabeçalho $metadata. Novo nome do ponto de dados Insira o novo nome para o ponto de dados. Descrição Forneça uma descrição para a transformação. Você pode inserir propriedades de metadados MQTT usando o formato
@$metadata.user_properties.<property>ou@$metadata.topic. Você também pode inserir cabeçalhos $metadata usando o formato@$metadata.<header>. A sintaxe$metadatasó é necessária para propriedades MQTT que fazem parte do cabeçalho da mensagem. Para mais informações, confira referências de campo.Escolha Aplicar.
Nova propriedade
Você pode adicionar uma nova propriedade aos dados de origem usando a transformação Nova propriedade. Essa operação é usada para adicionar uma nova propriedade aos dados de origem. A nova propriedade pode ser usada nos estágios subsequentes do fluxo de dados.
Em Transformar (opcional), selecione Nova propriedade>Adicionar.
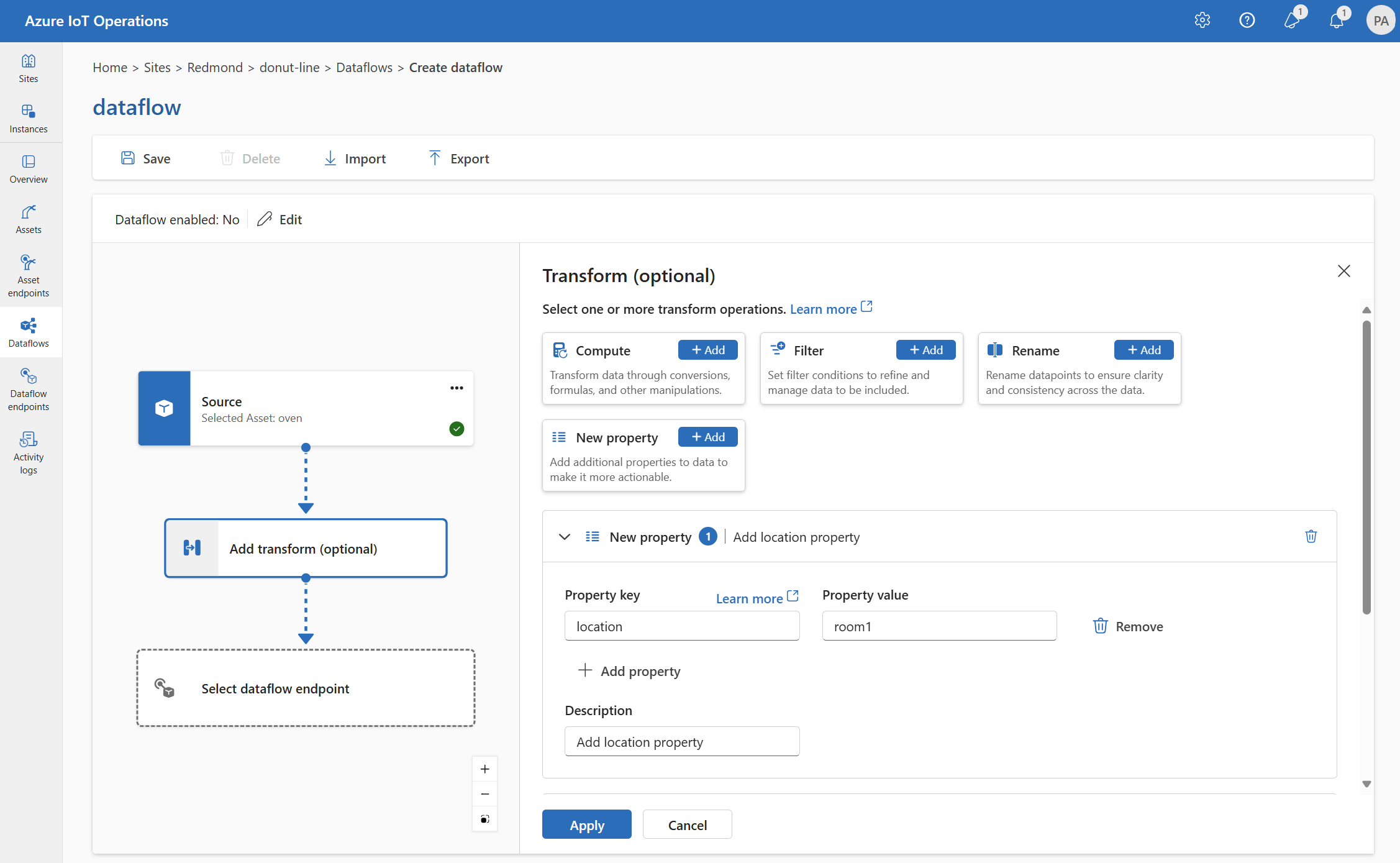
Insira as configurações necessárias.
Configuração Descrição Chave da propriedade Insira a chave para a nova propriedade. Valor da propriedade Insira o valor da nova propriedade. Descrição Forneça uma descrição para a nova propriedade. Escolha Aplicar.
Para saber mais, consulte Mapear dados usando fluxos de dados e Converter dados usando fluxos de dados.
Serializar dados de acordo com um esquema
Se você quiser serializar os dados antes de enviá-los ao destino, precisará especificar um esquema e um formato de serialização. Caso contrário, os dados são serializados em JSON com os tipos inferidos. Os pontos de extremidade de armazenamento, como o Microsoft Fabric ou o Azure Data Lake, exigem um esquema para garantir a consistência dos dados. Os formatos de serialização com suporte são o Parquet e o Delta.
Dica
Para gerar o esquema de um arquivo de dados de exemplo, use o Auxiliar de Geração de Esquema.
Para experiência de operações, você especifica o esquema e o formato de serialização nos detalhes do ponto de extremidade do fluxo de dados. Os pontos de extremidade que dão suporte a formatos de serialização são o Microsoft Fabric OneLake, o Azure Data Lake Storage Gen2, o Azure Data Explorer e o armazenamento local. Por exemplo, para serializar os dados no formato Delta, você precisa fazer upload de um esquema para o registro de esquema e referenciá-lo na configuração do ponto final de destino do fluxo de dados.
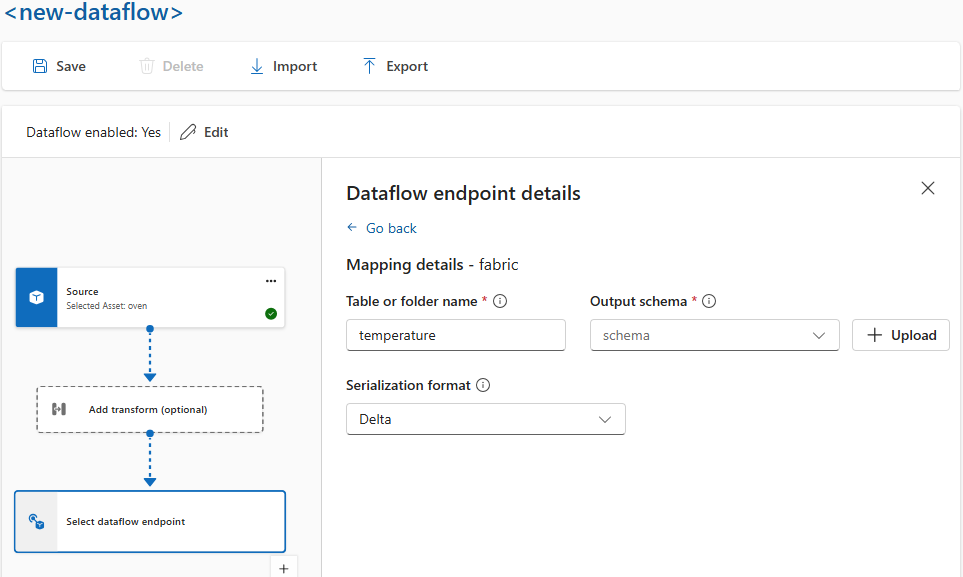
Para obter mais informações sobre o registro de esquemas, veja Entender esquemas de mensagens.
Destino
Para configurar um destino para o fluxo de dados, especifique a referência do ponto de extremidade e o destino dos dados. Você pode especificar uma lista de destinos de dados para o ponto de extremidade.
Para enviar dados para um destino diferente do agente MQTT local, crie um ponto de extremidade de fluxo de dados. Para saber como, consulte Configurar pontos de extremidade de fluxo de dados. Se o destino não for o agente MQTT local, ele deve ser usado como origem. Para saber mais sobre, consulte Os fluxos de dados devem usar o ponto de extremidade do agente MQTT local.
Importante
Os pontos de extremidade de armazenamento exigem um esquema para serialização. Para usar o fluxo de dados com o Microsoft Fabric OneLake, o Azure Data Lake Storage, o Azure Data Explorer ou o Armazenamento Local, você deve especificar uma referência de esquema.
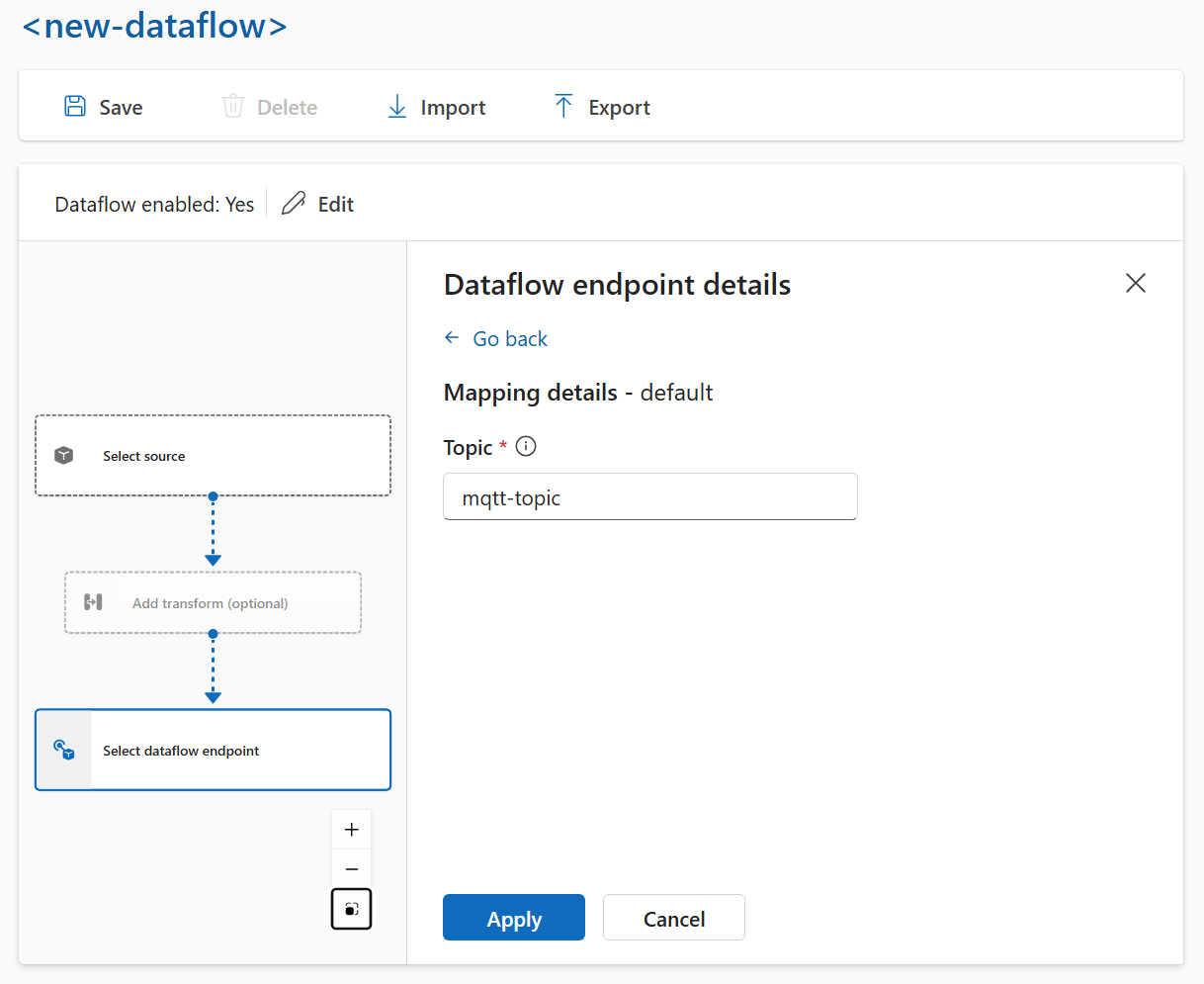
Selecione o ponto de extremidade de fluxo de dados a ser usado como destino.
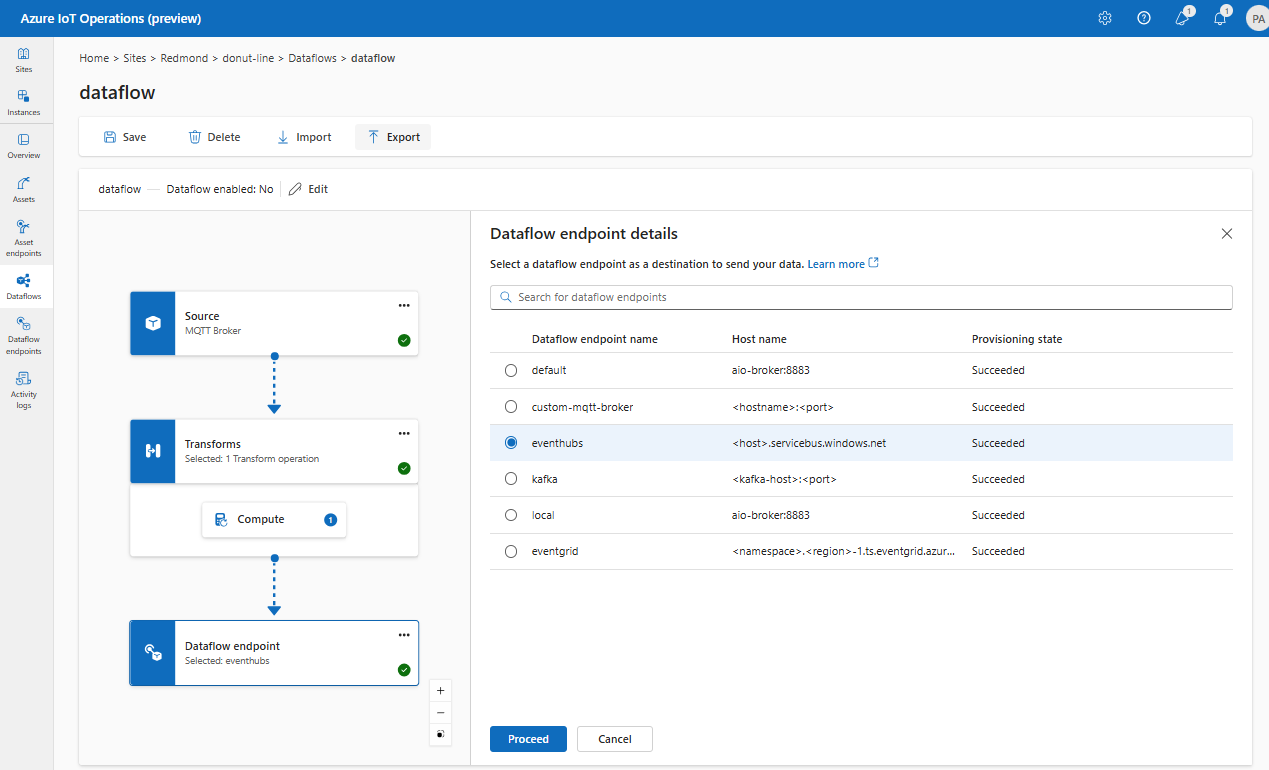
Os pontos de extremidade de armazenamento exigem um esquema para serialização. Se você escolher um ponto de extremidade de destino do Microsoft Fabric OneLake, do Azure Data Lake Storage, do Azure Data Explorer ou do Local Storage, deverá especificar uma referência de esquema. Por exemplo, para serializar os dados em um ponto de extremidade do Microsoft Fabric no formato Delta, você precisa carregar um esquema no registro de esquemas e referenciá-lo na configuração do ponto de extremidade de destino do fluxo de dados.
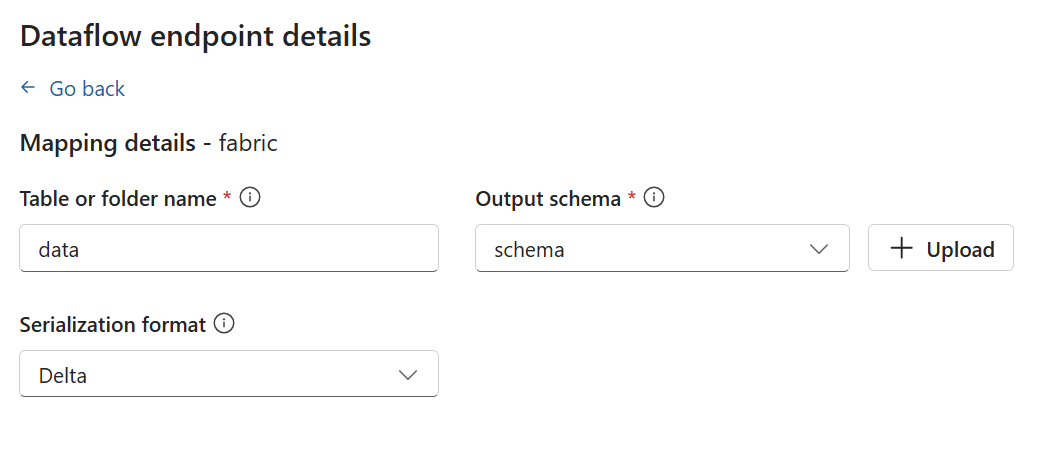
Selecione Continuar para configurar o destino.
Insira as configurações necessárias para o destino, incluindo o tópico ou a tabela para o qual enviar os dados. Confira Configurar o destino dos dados (tópico, contêiner ou tabela) para obter mais informações.
Configurar o destino dos dados (tópico, contêiner ou tabela)
Semelhante às fontes de dados, o destino de dados é um conceito usado para manter os pontos de extremidade de fluxo de dados reutilizáveis em vários fluxos de dados. Essencialmente, ele representa o subdiretório na configuração do ponto de extremidade de fluxo de dados. Por exemplo, se o ponto de extremidade de fluxo de dados for um ponto de extremidade de armazenamento, o destino de dados será a tabela na conta de armazenamento. Se o ponto de extremidade de fluxo de dados for um ponto de extremidade do Kafka, o destino dos dados será o tópico do Kafka.
| Tipo de ponto de extremidade | Significado do destino de dados | Descrição |
|---|---|---|
| MQTT (ou Grade de Eventos) | Tópico | O tópico MQTT para onde os dados são enviados. Há suporte apenas para tópicos estáticos, sem curingas. |
| Kafka (ou Hubs de Eventos) | Tópico | O tópico do Kafka para onde os dados são enviados. Há suporte apenas para tópicos estáticos, sem curingas. Se o ponto de extremidade for um namespace dos Hubs de Eventos, o destino dos dados será o hub de eventos individual dentro do namespace. |
| Armazenamento do Azure Data Lake | Contêiner | O contêiner na conta de armazenamento. Não é a tabela. |
| Microsoft Fabric OneLake | Arquivo ou Pasta | Corresponde ao tipo de caminho configurado para o ponto de extremidade. |
| Azure Data Explorer | Tabela | A tabela no banco de dados do Azure Data Explorer. |
| Armazenamento local | Pasta | O nome da pasta ou do diretório na montagem do volume persistente do armazenamento local. Ao usar o Armazenamento de contêineres do Azure habilitado pelo Azure Arc Cloud Ingest Edge Volumes, isso deve corresponder ao parâmetro spec.path para o subvolume que você criou. |
Para configurar o destino de dados:
Ao usar a experiência de operações, o campo de destino dos dados é interpretado automaticamente com base no tipo de ponto de extremidade. Por exemplo, se o ponto de extremidade de fluxo de dados for um ponto de extremidade de armazenamento, a página de detalhes do destino solicitará que você insira o nome do contêiner. Se o ponto de extremidade de fluxo de dados for um ponto de extremidade MQTT, a página de detalhes do destino solicitará que você insira o tópico e assim por diante.
Exemplo
O exemplo a seguir é uma configuração de fluxo de dados que usa o ponto de extremidade MQTT para a origem e o destino. A origem filtra os dados do tópico MQTT azure-iot-operations/data/thermostat. A transformação converte a temperatura em Fahrenheit e filtra os dados em que a temperatura multiplicada pela umidade é menor que 100000. O destino envia os dados para o tópico MQTT factory.

Para ver mais exemplos de configurações de fluxo de dados, consulte API REST do Azure – Fluxo de dados e o início rápido do Bicep.
Verificar se um fluxo de dados está funcionando
Siga Tutorial: Ponte MQTT bidirecional para a Grade de Eventos do Azure para verificar se o fluxo de dados está funcionando.
Exportar configuração de fluxo de dados
Para exportar a configuração de fluxo de dados, você pode usar a experiência de operações ou exportando o recurso personalizado de fluxo de dados.
Selecione o fluxo de dados que deseja exportar e selecione Exportar na barra de ferramentas.
Configuração adequada do fluxo de dados
Para garantir que o fluxo de dados esteja funcionando conforme o esperado, verifique o seguinte:
- O ponto de extremidade de fluxo de dados MQTT padrão deve ser usado como origem ou destino.
- O perfil de fluxo de dados existe e é referenciado na configuração do fluxo de dados.
- A origem é um ponto de extremidade MQTT, ponto de extremidade Kafka ou um ativo. Os pontos de extremidade do tipo armazenamento não podem ser usados como origem.
- Ao usar a Grade de Eventos como origem, a contagem de instâncias do perfil do fluxo de dados é definida como 1 porque o agente MQTT da Grade de Eventos não suporta assinaturas compartilhadas.
- Ao usar os Hubs de Eventos como origem, cada hub de eventos no namespace é um tópico Kafka separado e deve ser especificado como a fonte de dados.
- A transformação, se usada, é configurada com a sintaxe adequada, incluindo o escape de caracteres especiais adequado.
- Ao usar pontos de extremidade do tipo armazenamento como destino, um esquema é especificado.