Notas de versão arquivadas
Resumo
O Microsoft Azure HDInsight é um dos serviços mais populares entre os clientes empresariais para análise de software livre no Azure. Assine as Notas de Lançamento do HDInsight para obter informações atualizadas sobre o HDInsight e todas as versões do HDInsight.
Para se inscrever, clique no botão "assistir" na faixa e fique atento aos Lançamentos do HDInsight.
Informações sobre a versão
Data de lançamento: 22 de outubro de 2024
Observação
Esta é uma versão de hotfix/manutenção para o Provedor de recursos. Para obter mais informações, confira o Provedor de recursos.
O Azure HDInsight libera periodicamente atualizações de manutenção para fornecer correções de bugs, aprimoramentos de desempenho e patches de segurança, garantindo que você se mantenha atualizado com essas atualizações para obter o desempenho e a confiabilidade ideais.
Esta nota de versão se aplica à
![]() versão HDInsight 5.1.
versão HDInsight 5.1.
![]() versão HDInsight 5.0.
versão HDInsight 5.0.
![]() versão HDInsight 4.0.
versão HDInsight 4.0.
A versão do HDInsight é disponibilizada para todas as regiões durante vários dias. Esta nota de versão é aplicável para o número de imagem 2409240625. Como verificar o número da imagem?
O HDInsight usa práticas de implantação segura que envolvem a implantação gradual de região. Pode levar até 10 dias úteis para uma nova versão ficar disponível em todas as regiões.
Versões do sistema operacional
- HDInsight 5.1: Ubuntu 18.04.5 LTS Linux Kernel 5.4
- HDInsight 5.0: Ubuntu 18.04.5 LTS Linux Kernel 5.4
- HDInsight 4.0: Ubuntu 18.04.5 LTS Linux Kernel 5.4
Observação
O Ubuntu 18.04 tem suporte em ESM (Manutenção de Segurança Estendida) pela equipe do Azure Linux para o Azure HDInsight versão de julho de 2023 em diante.
Para versões específicas de carga de trabalho, confira as versões de componente do HDInsight 5.x.
Atualizado
Suporte de autenticação baseado em MSI disponível para o armazenamento de blobs do Azure.
- O Azure HDInsight agora dá suporte à autenticação baseada em OAuth para acessar o armazenamento de Blobs do Azure, aproveitando o Azure Active Directory (AAD) e identidades gerenciadas (MSI). Com esta melhoria, o HDInsight usa identidades gerenciadas atribuídas pelo usuário para acessar o armazenamento de blobs do Azure. Para saber mais, confira Gerenciar identidades para recursos do Azure.
O serviço HDInsight fez a transição para usar balanceadores de carga padrão para todas as suas configurações de cluster devido ao anúncio de descontinuação do balanceador de carga básico do Azure.
Observação
Essa alteração está disponível em todas as regiões. Recrie seu cluster para consumir essa alteração. Para obter assistência, entre em contato com o suporte ao cliente.
Importante
Ao usar sua própria Rede Virtual (VNet personalizada) durante a criação do cluster, esteja ciente de que a criação do cluster não será bem-sucedida depois que essa alteração for habilitada. É recomendável fazer referência ao guia de migração para recriar o cluster. Para obter assistência, entre em contato com o suporte ao cliente.
 Em breve
Em breve
Desativação de VMs das séries A Básica e Standard.
- Em 31 de agosto de 2024, vamos desativar as VMs da série A Básica e Standard. Antes dessa data, você precisará migrar suas cargas de trabalho para as VMs da série Av2, que oferecem mais memória por vCPU e armazenamento mais rápido em unidades de estado sólido (SSDs).
- Para evitar interrupções no serviço, migre suas cargas de trabalho das VMs de série A Basic e Standard para VMs da série Av2 antes de 31 de agosto de 2024.
Notificações de Desativação do HDInsight 4.0 e HDInsight 5.0.
Se você tiver mais alguma dúvida, contate o Suporte do Azure.
Você sempre pode nos perguntar sobre o HDInsight em Azure HDInsight - Microsoft Q&A.
Estamos ouvindo: você pode adicionar mais ideias e outros tópicos aqui e votar neles - Ideias do HDInsight e nos seguir para obter mais atualizações em Comunidade do AzureHDInsight.
Observação
Aconselhamos os clientes a usar as versões mais recentes do HDInsight Images, pois elas trazem o melhor das atualizações de código aberto, atualizações do Azure e correções de segurança. Para obter mais informações, veja Melhores práticas.
Data de lançamento: 30 de agosto de 2024
Observação
Esta é uma versão de hotfix/manutenção para o Provedor de recursos. Para obter mais informações, confira o Provedor de recursos.
O Azure HDInsight libera periodicamente atualizações de manutenção para fornecer correções de bugs, aprimoramentos de desempenho e patches de segurança, garantindo que você se mantenha atualizado com essas atualizações para obter o desempenho e a confiabilidade ideais.
Esta nota de versão se aplica à
![]() versão HDInsight 5.1.
versão HDInsight 5.1.
![]() versão HDInsight 5.0.
versão HDInsight 5.0.
![]() versão HDInsight 4.0.
versão HDInsight 4.0.
A versão do HDInsight é disponibilizada para todas as regiões durante vários dias. Esta nota de versão é aplicável à imagem número 2407260448. Como verificar o número da imagem?
O HDInsight usa práticas de implantação segura que envolvem a implantação gradual de região. Pode levar até 10 dias úteis para uma nova versão ficar disponível em todas as regiões.
Versões do sistema operacional
- HDInsight 5.1: Ubuntu 18.04.5 LTS Linux Kernel 5.4
- HDInsight 5.0: Ubuntu 18.04.5 LTS Linux Kernel 5.4
- HDInsight 4.0: Ubuntu 18.04.5 LTS Linux Kernel 5.4
Observação
O Ubuntu 18.04 tem suporte em ESM (Manutenção de Segurança Estendida) pela equipe do Azure Linux para o Azure HDInsight versão de julho de 2023 em diante.
Para versões específicas de carga de trabalho, confira as versões de componente do HDInsight 5.x.
Problema corrigido
- Correção de bug padrão do BD.
Em breve
-
Desativação de VMs das séries A Básica e Standard.
- Em 31 de agosto de 2024, vamos desativar as VMs da série A Básica e Standard. Antes dessa data, você precisará migrar suas cargas de trabalho para as VMs da série Av2, que oferecem mais memória por vCPU e armazenamento mais rápido em unidades de estado sólido (SSDs).
- Para evitar interrupções no serviço, migre suas cargas de trabalho das VMs de série A Basic e Standard para VMs da série Av2 antes de 31 de agosto de 2024.
- Notificações de Desativação do HDInsight 4.0 e HDInsight 5.0.
Se você tiver mais alguma dúvida, contate o Suporte do Azure.
Você sempre pode nos perguntar sobre o HDInsight em Azure HDInsight - Microsoft Q&A.
Estamos ouvindo: você pode adicionar mais ideias e outros tópicos aqui e votar neles - Ideias do HDInsight e nos seguir para obter mais atualizações em Comunidade do AzureHDInsight.
Observação
Aconselhamos que os clientes usem versões mais recentes de Imagens HDInsight, pois eles trazem as melhores atualizações de código aberto, atualizações do Azure e correções de segurança. Para obter mais informações, confira Boas Práticas.
Data de lançamento: 09 de agosto de 2024
Esta nota de versão se aplica à
![]() versão HDInsight 5.1.
versão HDInsight 5.1.
![]() versão HDInsight 5.0.
versão HDInsight 5.0.
![]() versão HDInsight 4.0.
versão HDInsight 4.0.
A versão do HDInsight é disponibilizada para todas as regiões durante vários dias. Esta nota de versão é aplicável à imagem número 2407260448. Como verificar o número da imagem?
O HDInsight usa práticas de implantação segura que envolvem a implantação gradual de região. Pode levar até 10 dias úteis para uma nova versão ficar disponível em todas as regiões.
Versões do sistema operacional
- HDInsight 5.1: Ubuntu 18.04.5 LTS Linux Kernel 5.4
- HDInsight 5.0: Ubuntu 18.04.5 LTS Linux Kernel 5.4
- HDInsight 4.0: Ubuntu 18.04.5 LTS Linux Kernel 5.4
Observação
O Ubuntu 18.04 tem suporte em ESM (Manutenção de Segurança Estendida) pela equipe do Azure Linux para o Azure HDInsight versão de julho de 2023 em diante.
Para versões específicas de carga de trabalho, confira as versões de componente do HDInsight 5.x.
Atualizações
Adição do Agente do Azure Monitor para Log Analytics no HDInsight
Adição de SystemMSI e DCR automatizado para Análise de Log, considerando a substituição da Nova Experiência do Azure Monitor (versão prévia).
Observação
Número de imagem efetivo 2407260448, os clientes que usam o portal para análise de logs terão a experiência do agente do Azure Monitor padrão. Caso deseje mudar para a experiência do Azure Monitor (versão prévia), você pode fixar seus clusters em imagens antigas criando uma solicitação de suporte.
Data de lançamento: 05 de julho de 2024
Observação
Esta é uma versão de hotfix/manutenção para o Provedor de recursos. Para saber mais, consulte Provedor de recursos
Problemas corrigidos
Os rótulos HOBO substituem os rótulos de usuário.
- Os rótulos HOBO substituem os rótulos de usuário em sub-recursos na criação do cluster HDInsight.
Data de lançamento: 19 de junho de 2024
Esta nota de versão se aplica à
![]() versão HDInsight 5.1.
versão HDInsight 5.1.
![]() versão HDInsight 5.0.
versão HDInsight 5.0.
![]() versão HDInsight 4.0.
versão HDInsight 4.0.
A versão do HDInsight é disponibilizada para todas as regiões durante vários dias. Esta nota de versão é aplicável à imagem número 2406180258. Como verificar o número da imagem?
O HDInsight usa práticas de implantação segura que envolvem a implantação gradual de região. Pode levar até 10 dias úteis para uma nova versão ficar disponível em todas as regiões.
Versões do sistema operacional
- HDInsight 5.1: Ubuntu 18.04.5 LTS Linux Kernel 5.4
- HDInsight 5.0: Ubuntu 18.04.5 LTS Linux Kernel 5.4
- HDInsight 4.0: Ubuntu 18.04.5 LTS Linux Kernel 5.4
Observação
O Ubuntu 18.04 tem suporte em ESM (Manutenção de Segurança Estendida) pela equipe do Azure Linux para o Azure HDInsight versão de julho de 2023 em diante.
Para versões específicas de carga de trabalho, confira as versões de componente do HDInsight 5.x.
Problemas corrigidos
Aprimoramentos de segurança
Melhorias no Log Analytics do HDInsight com suporte à Identidade Gerenciada do Sistema para o provedor de recursos do HDInsight.
Adição de nova atividade para atualizar a versão
mdsddo agente para a imagem antiga (criada antes de 2024).Habilitar o MISE no gateway como parte das melhorias contínuas para a Migração da MSAL.
Incorporar o servidor Thrift
Httpheader hiveConfdo Spark ao HTTP ConnectionFactory do Jetty.Reverter RANGER-3753 e RANGER-3593.
A implementação
setOwnerUserfornecida na versão do Ranger 2.3.0 tem um problema crítico de regressão ao ser usado pelo Hive. No Ranger 2.3.0, quando o HiveServer2 tenta avaliar as políticas, o cliente do Ranger tenta obter o proprietário da tabela hive chamando o metastore na função setOwnerUser, que essencialmente faz uma chamada ao armazenamento para verificar o acesso a essa tabela. Esse problema faz com que as consultas fiquem lentas quando o Hive é executado no Ranger 2.3.0.
Novas regiões adicionadas
- Norte da Itália
- Israel Central
- Espanha Central
- México Central
- Jio India Central
Adicionar às Notas de Arquivo de junho de 2024
Em breve
-
Desativação de VMs das séries A Básica e Standard.
- Em 31 de agosto de 2024, vamos desativar as VMs da série A Básica e Standard. Antes dessa data, você precisará migrar suas cargas de trabalho para as VMs da série Av2, que oferecem mais memória por vCPU e armazenamento mais rápido em unidades de estado sólido (SSDs).
- Para evitar interrupções no serviço, migre suas cargas de trabalho das VMs de série A Basic e Standard para VMs da série Av2 antes de 31 de agosto de 2024.
- Notificações de Desativação do HDInsight 4.0 e HDInsight 5.0.
Se você tiver mais alguma dúvida, contate o Suporte do Azure.
Você sempre pode nos perguntar sobre o HDInsight em Azure HDInsight - Microsoft Q&A.
Estamos ouvindo: você pode adicionar mais ideias e outros tópicos aqui e votar neles - Ideias do HDInsight e nos seguir para obter mais atualizações em Comunidade do AzureHDInsight.
Observação
Aconselhamos que os clientes usem versões mais recentes de Imagens HDInsight, pois eles trazem as melhores atualizações de código aberto, atualizações do Azure e correções de segurança. Para obter mais informações, confira Boas Práticas.
Data do lançamento: 16 de maio de 2024
Esta nota de versão se aplica à
![]() versão HDInsight 5.0.
versão HDInsight 5.0.
![]() versão HDInsight 4.0.
versão HDInsight 4.0.
A versão do HDInsight é disponibilizada para todas as regiões durante vários dias. Esta nota de versão é aplicável à imagem número 2405081840. Como verificar o número da imagem?
O HDInsight usa práticas de implantação segura que envolvem a implantação gradual de região. Pode levar até 10 dias úteis para uma nova versão ficar disponível em todas as regiões.
Versões do sistema operacional
- HDInsight 5.0: Ubuntu 18.04.5 LTS Linux Kernel 5.4
- HDInsight 4.0: Ubuntu 18.04.5 LTS Linux Kernel 5.4
Observação
O Ubuntu 18.04 tem suporte em ESM (Manutenção de Segurança Estendida) pela equipe do Azure Linux para o Azure HDInsight versão de julho de 2023 em diante.
Para versões específicas de carga de trabalho, confira as versões de componente do HDInsight 5.x.
Problemas corrigidos
- API adicionada no gateway para obter token para Keyvault, como parte da iniciativa SFI.
- Na nova tabela
HDInsightSparkLogsdo monitor de log, para o tipo de logSparkDriverLog, alguns dos campos estavam ausentes. Por exemplo,LogLevel & Message. Esta versão adiciona os campos ausentes a esquemas e formatação fixa paraSparkDriverLog. - Os logs do Livy não estão disponíveis na tabela
SparkDriverLogde monitoramento do Log Analytics, que ocorreu devido a um problema com o caminho de origem de log do Livy e o regex de análise de log em configurações deSparkLivyLog. - Qualquer cluster HDInsight, usando o ADLS Gen2 como uma conta de armazenamento primária, pode utilizar o acesso baseado em MSI a qualquer um dos recursos do Azure (por exemplo, SQL, Keyvaults) que são usados no código do aplicativo.
Em breve
-
Desativação de VMs das séries A Básica e Standard.
- Em 31 de agosto de 2024, vamos desativar as VMs da série A Básica e Standard. Antes dessa data, você precisará migrar suas cargas de trabalho para as VMs da série Av2, que oferecem mais memória por vCPU e armazenamento mais rápido em unidades de estado sólido (SSDs).
- Para evitar interrupções no serviço, migre suas cargas de trabalho das VMs de série A Basic e Standard para VMs da série Av2 antes de 31 de agosto de 2024.
- Notificações de Desativação do HDInsight 4.0 e HDInsight 5.0.
Se você tiver mais alguma dúvida, contate o Suporte do Azure.
Você sempre pode nos perguntar sobre o HDInsight em Azure HDInsight - Microsoft Q&A.
Estamos ouvindo: você pode adicionar mais ideias e outros tópicos aqui e votar neles - Ideias do HDInsight e nos seguir para obter mais atualizações em Comunidade do AzureHDInsight.
Observação
Aconselhamos que os clientes usem versões mais recentes de Imagens HDInsight, pois eles trazem as melhores atualizações de código aberto, atualizações do Azure e correções de segurança. Para obter mais informações, confira Boas Práticas.
Data do lançamento: 15 de abril de 2024
Esta nota de versão se aplica ao ![]() HDInsight versão 5.1.
HDInsight versão 5.1.
A versão do HDInsight é disponibilizada para todas as regiões durante vários dias. Esta nota sobre a versão é aplicável à imagem número 2403290825. Como verificar o número da imagem?
O HDInsight usa práticas de implantação segura que envolvem a implantação gradual de região. Pode levar até 10 dias úteis para uma nova versão ficar disponível em todas as regiões.
Versões do sistema operacional
- HDInsight 5.1: Ubuntu 18.04.5 LTS Linux Kernel 5.4
Observação
O Ubuntu 18.04 tem suporte em ESM (Manutenção de Segurança Estendida) pela equipe do Azure Linux para o Azure HDInsight versão de julho de 2023 em diante.
Para versões específicas de carga de trabalho, confira as versões de componente do HDInsight 5.x.
Problemas corrigidos
- Correções de bugs do Ambari DB, Hive Warehouse Controller (HWC), Spark, HDFS
- Correções de bugs do módulo de análise de logs do HDInsightSparkLogs
- Correções de CVE para o Provedor de Recursos do HDInsight.
Em breve
-
Desativação de VMs das séries A Básica e Standard.
- Em 31 de agosto de 2024, vamos desativar as VMs da série A Básica e Standard. Antes dessa data, você precisará migrar suas cargas de trabalho para as VMs da série Av2, que oferecem mais memória por vCPU e armazenamento mais rápido em unidades de estado sólido (SSDs).
- Para evitar interrupções no serviço, migre suas cargas de trabalho das VMs de série A Basic e Standard para VMs da série Av2 antes de 31 de agosto de 2024.
- Notificações de Desativação do HDInsight 4.0 e HDInsight 5.0.
Se você tiver mais alguma dúvida, contate o Suporte do Azure.
Você sempre pode nos perguntar sobre o HDInsight em Azure HDInsight - Microsoft Q&A.
Estamos ouvindo: você pode adicionar mais ideias e outros tópicos aqui e votar neles - Ideias do HDInsight e nos seguir para obter mais atualizações em Comunidade do AzureHDInsight.
Observação
Aconselhamos que os clientes usem versões mais recentes de Imagens HDInsight, pois eles trazem as melhores atualizações de código aberto, atualizações do Azure e correções de segurança. Para obter mais informações, confira Boas Práticas.
Data de lançamento: 15 de fevereiro de 2024
Esta versão se aplica às versões 4.x e 5.x do HDInsight. A versão do HDInsight é disponibilizada para todas as regiões durante vários dias. Esta versão é aplicável ao número de imagem 2401250802. Como verificar o número da imagem?
O HDInsight usa práticas de implantação segura que envolvem a implantação gradual de região. Pode levar até 10 dias úteis para uma nova versão ficar disponível em todas as regiões.
Versões do sistema operacional
- HDInsight 4.0: Ubuntu 18.04.5 LTS Linux Kernel 5.4
- HDInsight 5.0: Ubuntu 18.04.5 LTS Linux Kernel 5.4
- HDInsight 5.1: Ubuntu 18.04.5 LTS Linux Kernel 5.4
Observação
O Ubuntu 18.04 tem suporte em ESM (Manutenção de Segurança Estendida) pela equipe do Azure Linux para o Azure HDInsight versão de julho de 2023 em diante.
Para versões específicas da carga de trabalho, consulte
Novos recursos
- Suporte do Apache Ranger para Spark SQL no Spark 3.3.0 (HDInsight versão 5.1) com pacote de segurança Enterprise. Saiba mais sobre isso aqui.
Problemas corrigidos
- Correções de segurança dos componentes do Ambari e do Oozie
Em breve
- Desativação de VMs das séries A Básica e Standard.
- Em 31 de agosto de 2024, vamos desativar as VMs da série A Básica e Standard. Antes dessa data, você precisará migrar suas cargas de trabalho para as VMs da série Av2, que oferecem mais memória por vCPU e armazenamento mais rápido em unidades de estado sólido (SSDs).
- Para evitar interrupções no serviço, migre suas cargas de trabalho das VMs de série A Basic e Standard para VMs da série Av2 antes de 31 de agosto de 2024.
Se você tiver mais alguma dúvida, contate o Suporte do Azure.
Você sempre pode nos perguntar sobre o HDInsight no Azure HDInsight – Microsoft Q&A
Somos todos ouvidos: você está convidado a adicionar mais ideias e outros tópicos aqui e a votar neles – Ideias do HDInsight e nos acompanhe para obter mais atualizações sobre a Comunidade do AzureHDInsight
Observação
Aconselhamos que os clientes usem versões mais recentes de Imagens HDInsight, pois eles trazem as melhores atualizações de código aberto, atualizações do Azure e correções de segurança. Para obter mais informações, confira Boas Práticas.
Próximas etapas
- Azure HDInsight: perguntas frequentes
- Configurar o agendamento de aplicação de patch no SO para clusters HDInsight baseados em Linux
- Nota sobre a versão anterior
O Microsoft Azure HDInsight é um dos serviços mais populares entre os clientes empresariais para análise de software livre no Azure. Se você quiser assinar as notas de versão, observe as versões neste repositório GitHub.
Data de lançamento: 10 de janeiro de 2024
Essa versão de correção se aplica às versões 4.x e 5.x do HDInsight. A versão do HDInsight é disponibilizada para todas as regiões durante vários dias. Essa versão é aplicável à imagem número 2401030422. Como verificar o número da imagem?
O HDInsight usa práticas de implantação segura que envolvem a implantação gradual de região. Pode levar até 10 dias úteis para uma nova versão ficar disponível em todas as regiões.
Versões do sistema operacional
- HDInsight 4.0: Ubuntu 18.04.5 LTS Linux Kernel 5.4
- HDInsight 5.0: Ubuntu 18.04.5 LTS Linux Kernel 5.4
- HDInsight 5.1: Ubuntu 18.04.5 LTS Linux Kernel 5.4
Observação
O Ubuntu 18.04 tem suporte em ESM (Manutenção de Segurança Estendida) pela equipe do Azure Linux para o Azure HDInsight versão de julho de 2023 em diante.
Para versões específicas da carga de trabalho, consulte
Problemas corrigidos
- Correções de segurança dos componentes do Ambari e do Oozie
Em breve
- Desativação de VMs das séries A Básica e Standard.
- Em 31 de agosto de 2024, vamos desativar as VMs da série A Básica e Standard. Antes dessa data, você precisará migrar suas cargas de trabalho para as VMs da série Av2, que oferecem mais memória por vCPU e armazenamento mais rápido em unidades de estado sólido (SSDs).
- Para evitar interrupções no serviço, migre suas cargas de trabalho das VMs de série A Basic e Standard para VMs da série Av2 antes de 31 de agosto de 2024.
Se você tiver mais alguma dúvida, contate o Suporte do Azure.
Você sempre pode nos perguntar sobre o HDInsight no Azure HDInsight – Microsoft Q&A
Somos todos ouvidos: você está convidado a adicionar mais ideias e outros tópicos aqui e a votar neles – Ideias do HDInsight e nos acompanhe para obter mais atualizações sobre a Comunidade do AzureHDInsight
Observação
Aconselhamos que os clientes usem versões mais recentes de Imagens HDInsight, pois eles trazem as melhores atualizações de código aberto, atualizações do Azure e correções de segurança. Para obter mais informações, confira Boas Práticas.
Data do lançamento: 26 de outubro de 2023
Esta versão se aplica ao HDInsight 4.x e 5.x; a versão do HDInsight estará disponível para todas as regiões ao longo de vários dias. Essa versão é aplicável à imagem número 2310140056. Como verificar o número da imagem?
O HDInsight usa práticas de implantação segura que envolvem a implantação gradual de região. Pode levar até 10 dias úteis para uma nova versão ficar disponível em todas as regiões.
Versões do sistema operacional
- HDInsight 4.0: Ubuntu 18.04.5 LTS Linux Kernel 5.4
- HDInsight 5.0: Ubuntu 18.04.5 LTS Linux Kernel 5.4
- HDInsight 5.1: Ubuntu 18.04.5 LTS Linux Kernel 5.4
Para versões específicas da carga de trabalho, consulte
Novidades
O HDInsight anuncia a disponibilidade geral do HDInsight 5.1 a partir de 1° de novembro de 2023. Esta versão traz uma atualização de pilha completa para os componentes de código aberto e as integrações da Microsoft.
- As versões mais recentes de código aberto – HDInsight 5.1 saem com a versão de código aberto estável mais recente disponível. Os clientes podem se beneficiar de todos os recursos de código aberto mais recentes, melhorias de desempenho e correções de bugs da Microsoft.
- Segurança – As versões mais recentes saem com as correções de segurança mais recentes, correções de segurança de código aberto e melhorias de segurança da Microsoft.
- TCO reduzido – com melhorias de desempenho, os clientes podem reduzir o custo operacional e obter o dimensionamento automático aprimorado.
Permissões de cluster para armazenamento seguro
- Os clientes podem especificar (durante a criação do cluster) se um canal seguro deve ser usado para nós de cluster do HDInsight contatarem a conta de armazenamento.
Criação de Cluster do HDInsight com redes virtuais personalizadas.
- Para aprimorar a postura total de segurança dos clusters do HDInsight, os clusters do HDInsight usando VNETs precisam se certificar de que o usuário precise ter permissão para que a
Microsoft Network/virtualNetworks/subnets/join/actionrealize operações de criação. O cliente pode enfrentar falhas de criação se essa verificação não estiver habilitada.
- Para aprimorar a postura total de segurança dos clusters do HDInsight, os clusters do HDInsight usando VNETs precisam se certificar de que o usuário precise ter permissão para que a
Clusters do ABFS sem ESP [Permissões de Cluster para Leitura Universal]
- Clusters ABFS não ESP restringem os usuários do grupo não Hadoop de executar comandos Hadoop para operações de armazenamento. Essa alteração melhora a postura de segurança do cluster.
Atualização de cotas em linha.
- Agora você pode solicitar aumento de cota diretamente da página Minha Cota, com a chamada direta à API é muito mais rápida. Caso a chamada à API falhe, você pode criar uma nova solicitação de suporte para aumento de cota.
Em breve
O comprimento máximo do nome do cluster será alterado de 59 para 45 caracteres, para melhorar a postura de segurança dos clusters. Essa alteração será implementada em todas as regiões a partir da próxima versão.
Desativação de VMs de série A Basic e Standard.
- Em 31 de agosto de 2024, vamos desativar as VMs Básica e Standard da série A. Antes dessa data, você precisará migrar suas cargas de trabalho para as VMs da série Av2, que oferecem mais memória por vCPU e armazenamento mais rápido em unidades de estado sólido (SSDs).
- Para evitar interrupções no serviço, migre suas cargas de trabalho das VMs de série A Basic e Standard para VMs da série Av2 antes de 31 de agosto de 2024.
Se você tiver mais alguma dúvida, contate o Suporte do Azure.
Você sempre pode nos perguntar sobre o HDInsight no Azure HDInsight – Microsoft Q&A
Somos todos ouvidos: você está convidado a adicionar mais ideias e outros tópicos aqui e a votar neles – Ideias do HDInsight e nos acompanhe para obter mais atualizações sobre a Comunidade do AzureHDInsight
Observação
Esta versão aborda os seguintes CVEs lançados pelo MSRC em 12 de setembro de 2023. A ação serve para atualizar para a imagem mais recente 2308221128 ou 2310140056. Os clientes são orientados a se planejar adequadamente.
| CVE | Severidade | Título CVE | Comentário |
|---|---|---|---|
| CVE-2023-38156 | Importante | Vulnerabilidade de Elevação de Privilégio do Apache Ambari no Azure HDInsight | Incluído na imagem 2308221128 ou 2310140056 |
| CVE-2023-36419 | Importante | Vulnerabilidade de elevação de privilégio do Agendador de fluxo de trabalho do Apache Oozie do Azure HDInsight | Aplicar a Ação do script em seus clusters ou atualizar para a imagem 2310140056 |
Observação
Aconselhamos que os clientes usem versões mais recentes de Imagens HDInsight, pois eles trazem as melhores atualizações de código aberto, atualizações do Azure e correções de segurança. Para obter mais informações, confira Boas Práticas.
Data da versão: 7 de setembro de 2023
Esta versão se aplica ao HDInsight 4.x e 5.x; a versão do HDInsight estará disponível para todas as regiões ao longo de vários dias. Essa versão é aplicável à imagem número 2308221128. Como verificar o número da imagem?
O HDInsight usa práticas de implantação segura que envolvem a implantação gradual de região. Pode levar até 10 dias úteis para uma nova versão ficar disponível em todas as regiões.
Versões do sistema operacional
- HDInsight 4.0: Ubuntu 18.04.5 LTS Linux Kernel 5.4
- HDInsight 5.0: Ubuntu 18.04.5 LTS Linux Kernel 5.4
- HDInsight 5.1: Ubuntu 18.04.5 LTS Linux Kernel 5.4
Para versões específicas da carga de trabalho, consulte
Importante
Esta versão aborda os seguintes CVEs lançados pelo MSRC em 12 de setembro de 2023. A ação é atualizar para a imagem mais recente 2308221128. Os clientes são orientados a se planejar adequadamente.
| CVE | Severidade | Título CVE | Comentário |
|---|---|---|---|
| CVE-2023-38156 | Importante | Vulnerabilidade de Elevação de Privilégio do Apache Ambari no Azure HDInsight | Incluído na imagem 2308221128 |
| CVE-2023-36419 | Importante | Vulnerabilidade de elevação de privilégio do Agendador de fluxo de trabalho do Apache Oozie do Azure HDInsight | Aplique a Ação do script em seus clusters |
Em breve
- O comprimento máximo do nome do cluster será alterado de 59 para 45 caracteres, para melhorar a postura de segurança dos clusters. Essa alteração será implementada até 30 de setembro de 2023.
- Permissões de cluster para armazenamento seguro
- Os clientes podem especificar (durante a criação do cluster) se um canal seguro deve ser usado para nós de cluster HDInsight contatarem a conta de armazenamento.
- Atualização de cotas em linha.
- Solicite um aumento de cotas diretamente na página Minha Cota, que será uma chamada direta à API, que é mais rápida. Se a chamada APdI falhar, os clientes precisarão criar uma nova solicitação de suporte para aumentar a cota.
- Criação de Cluster do HDInsight com redes virtuais personalizadas.
- Para aprimorar a postura total de segurança dos clusters do HDInsight, os clusters do HDInsight usando VNETs precisam se certificar de que o usuário precise ter permissão para que a
Microsoft Network/virtualNetworks/subnets/join/actionrealize operações de criação. Os clientes precisam se planejar de acordo porque essa mudança será uma verificação obrigatória para evitar falhas na criação do cluster antes de 30 de setembro de 2023.
- Para aprimorar a postura total de segurança dos clusters do HDInsight, os clusters do HDInsight usando VNETs precisam se certificar de que o usuário precise ter permissão para que a
- Desativação de VMs de série A Basic e Standard.
- Em 31 de agosto de 2024, vamos desativar as VMs da série A Básica e Standard. Antes dessa data, você precisará migrar suas cargas de trabalho para as VMs da série Av2, que oferecem mais memória por vCPU e armazenamento mais rápido em unidades de estado sólido (SSDs). Para evitar interrupções no serviço, migre suas cargas de trabalho das VMs de série A Basic e Standard para VMs da série Av2 antes de 31 de agosto de 2024.
- Clusters ABFS não ESP [Permissões de cluster para leitura de palavras]
- Planeje introduzir uma alteração em clusters ABFS não ESP, o que restringe os usuários do grupo não Hadoop de executar comandos Hadoop em operações de armazenamento. Essa alteração melhora a postura de segurança do cluster. Os clientes precisam planejar as atualizações antes de 30 de setembro de 2023.
Se você tiver mais alguma dúvida, contate o Suporte do Azure.
Você sempre pode nos perguntar sobre o HDInsight no Azure HDInsight – Microsoft Q&A
Você pode adicionar mais propostas, ideias e outros tópicos aqui e votar neles - Comunidade HDInsight (azure.com).
Observação
Aconselhamos que os clientes usem versões mais recentes de Imagens HDInsight, pois eles trazem as melhores atualizações de código aberto, atualizações do Azure e correções de segurança. Para obter mais informações, confira Boas Práticas.
Data de lançamento: 25 de julho de 2023
Esta versão se aplica ao HDInsight 4.x e 5.x; a versão do HDInsight estará disponível para todas as regiões ao longo de vários dias. Essa versão se aplica à imagem número 2307201242. Como verificar o número da imagem?
O HDInsight usa práticas de implantação segura que envolvem a implantação gradual de região. Pode levar até 10 dias úteis para uma nova versão ficar disponível em todas as regiões.
Versões do sistema operacional
- HDInsight 4.0: Ubuntu 18.04.5 LTS Linux Kernel 5.4
- HDInsight 5.0: Ubuntu 18.04.5 LTS Linux Kernel 5.4
- HDInsight 5.1: Ubuntu 18.04.5 LTS Linux Kernel 5.4
Para versões específicas da carga de trabalho, consulte
 O que há de novo
O que há de novo
- O HDInsight 5.1 agora tem suporte com o cluster do ESP.
- A versão atualizada do Ranger 2.3.0 e do Oozie 5.2.1 agora faz parte do HDInsight 5.1
- O cluster do Spark 3.3.1 (HDInsight 5.1) vem com o Hive Warehouse Connector (HWC) 2.1, que funciona junto com o cluster de Interactive Query (HDInsight 5.1).
- O Ubuntu 18.04 tem suporte em Manutenção de Segurança Estendida (ESM) pela equipe do Azure Linux para o Azure HDInsight versão de julho de 2023 em diante.
Importante
Esta versão aborda os seguintes CVEs lançados pelo MSRC em 8 de agosto de 2023. A ação é atualizar para a imagem mais recente 2307201242. Os clientes são orientados a se planejar adequadamente.
| CVE | Severidade | Título CVE |
|---|---|---|
| CVE-2023-35393 | Importante | Vulnerabilidade de falsificação do Apache Hive no Azure |
| CVE-2023-35394 | Importante | Vulnerabilidade de falsificação do Jupyter Notebook no Azure HDInsight |
| CVE-2023-36877 | Importante | Vulnerabilidade de falsificação do Apache Oozie no Azure |
| CVE-2023-36881 | Importante | Vulnerabilidade de falsificação do Apache Ambari no Azure |
| CVE-2023-38188 | Importante | Vulnerabilidade de falsificação do Apache Hadoop no Azure |
Em breve
- O comprimento máximo do nome do cluster será alterado de 59 para 45 caracteres, para melhorar a postura de segurança dos clusters. Os clientes precisam se planejar para as atualizações antes de 30 de setembro de 2023.
- Permissões de cluster para armazenamento seguro
- Os clientes podem especificar (durante a criação do cluster) se um canal seguro deve ser usado para nós de cluster HDInsight contatarem a conta de armazenamento.
- Atualização de cotas em linha.
- Solicite um aumento de cotas diretamente na página Minha Cota, que será uma chamada direta à API, que é mais rápida. Se a chamada à API falhar, os clientes precisarão criar uma nova solicitação de suporte para aumentar a cota.
- Criação de Cluster do HDInsight com redes virtuais personalizadas.
- Para aprimorar a postura total de segurança dos clusters do HDInsight, os clusters do HDInsight usando VNETs precisam se certificar de que o usuário precise ter permissão para que a
Microsoft Network/virtualNetworks/subnets/join/actionrealize operações de criação. Os clientes precisam se planejar de acordo porque essa mudança será uma verificação obrigatória para evitar falhas na criação do cluster antes de 30 de setembro de 2023.
- Para aprimorar a postura total de segurança dos clusters do HDInsight, os clusters do HDInsight usando VNETs precisam se certificar de que o usuário precise ter permissão para que a
- Desativação de VMs de série A Basic e Standard.
- Em 31 de agosto de 2024, vamos desativar as VMs da série A Básica e Standard. Antes dessa data, você precisará migrar suas cargas de trabalho para as VMs da série Av2, que oferecem mais memória por vCPU e armazenamento mais rápido em unidades de estado sólido (SSDs). Para evitar interrupções no serviço, migre suas cargas de trabalho das VMs de série A Basic e Standard para VMs da série Av2 antes de 31 de agosto de 2024.
- Clusters ABFS não ESP [Permissões de cluster para leitura universal]
- Planeje introduzir uma alteração em clusters ABFS não ESP, o que restringe os usuários do grupo não Hadoop de executar comandos Hadoop em operações de armazenamento. Essa alteração melhora a postura de segurança do cluster. Os clientes precisam se planejar para as atualizações antes de 30 de setembro de 2023.
Se você tiver mais alguma dúvida, contate o Suporte do Azure.
Você sempre pode nos perguntar sobre o HDInsight no Azure HDInsight – Microsoft Q&A
Você pode adicionar mais propostas, ideias e outros tópicos aqui e votar neles - HDInsight Community (azure.com) e nos seguir para obter mais atualizações no X
Observação
Aconselhamos que os clientes usem versões mais recentes de Imagens HDInsight, pois eles trazem as melhores atualizações de código aberto, atualizações do Azure e correções de segurança. Para obter mais informações, confira Boas Práticas.
Data do lançamento: 08 de maio de 2023
Esta versão se aplica ao HDInsight 4.x e 5.x; a versão do HDInsight estará disponível para todas as regiões ao longo de vários dias. Essa versão é aplicável à imagem número 2304280205. Como verificar o número da imagem?
O HDInsight usa práticas de implantação segura que envolvem a implantação gradual de região. Pode levar até 10 dias úteis para uma nova versão ficar disponível em todas as regiões.
Versões do sistema operacional
- HDInsight 4.0: Ubuntu 18.04.5 LTS Linux Kernel 5.4
- HDInsight 5.0: Ubuntu 18.04.5 LTS Linux Kernel 5.4
Para versões específicas da carga de trabalho, consulte
![]()
O Azure HDInsight 5.1 inclui as seguintes atualizações
- Apache HBase 2.4.11
- Apache Phoenix 5.1.2
- Apache Hive 3.1.2
- Apache Spark 3.3.1
- Apache TEZ 0.9.1
- Apache Zeppelin 0.10.1
- Apache Livy 0.5
- Apache Kafka 3.2.0
Observação
- Todos os componentes são integrados ao Hadoop 3.3.4 e ao ZK 3.6.3
- Todos os componentes atualizados acima já estão disponíveis para uso em clusters não ESP da versão preliminar pública.
![]()
Dimensionamento automático aprimorado para HDInsight
O Azure HDInsight fez melhorias notáveis na estabilidade e na latência na escala automática. As mudanças essenciais incluem um loop de comentários aprimorados para decisões de colocação em escala, melhoria significativa na latência para escala e suporte ao recomissionamento dos nós descomissionados. Saiba mais sobre os aprimoramentos, como personalizar e migrar seu cluster para a dimensionamento automático aprimorada. O recurso de Dimensionamento Automático aprimorado ficou disponível a partir de 17 de maio de 2023 em todas as regiões com suporte.
Azure HDInsight ESP para Apache Kafka 2.4.1 já está em Disponibilidade Geral.
Azure HDInsight ESP para Apache Kafka 2.4.1 está em versão preliminar pública desde abril de 2022. Após aprimoramentos notáveis nas correções de CVE e na estabilidade, o Azure HDInsight ESP Kafka 2.4.1 agora está disponível de forma geral e pronto para cargas de trabalho de produção, saiba mais sobre os procedimentos detalhados de configuração e migração.
Gerenciamento de Cotas para HDInsight
Atualmente, o HDInsight aloca cotas para assinaturas de clientes em nível regional. Os núcleos alocados aos clientes são genéricos e não são classificados em nível de família de VM (por exemplo,
Dv2,Ev3,Eav4etc.).O HDInsight introduziu uma exibição aprimorada, que fornece detalhes e classificação de cotas para VMs em nível de família. Esse recurso exibe as cotas atuais e restantes de uma região no nível da família de VMs. A exibição aprimorada melhora a experiência do usuário, oferecendo mais opções de tomada de decisão para o planejamento de cotas. No momento, este recurso está disponível no HDInsight 4.x e 5.x para a região Leste dos EUA EUAP. Outras regiões a serem acrescentadas posteriormente.
Para obter mais informações, consulte Planejamento de capacidade do cluster no Azure HDInsight | Microsoft Learn
![]()
- Polônia Central
- O comprimento máximo do nome do cluster foi alterado de 59 para 45 caracteres, para melhorar a postura de segurança dos clusters.
- Permissões de cluster para armazenamento seguro
- Os clientes podem especificar (durante a criação do cluster) se um canal seguro deve ser usado para nós de cluster HDInsight contatarem a conta de armazenamento.
- Atualização de cotas em linha.
- Solicite um aumento de cotas diretamente na página Minha Cota, que é uma chamada direta à API, que é mais rápida. Se a chamada à API falhar, os clientes precisarão criar uma nova solicitação de suporte para aumentar a cota.
- Criação de Cluster do HDInsight com redes virtuais personalizadas.
- Para aprimorar a postura geral de segurança dos clusters do HDInsight, os clusters do HDInsight que usam VNETs personalizadas precisam garantir que o usuário precise ter permissão para que
Microsoft Network/virtualNetworks/subnets/join/actionrealize operações de criação. Os clientes precisariam se planejar adequadamente, pois essa seria uma verificação obrigatória para evitar falhas na criação do cluster.
- Para aprimorar a postura geral de segurança dos clusters do HDInsight, os clusters do HDInsight que usam VNETs personalizadas precisam garantir que o usuário precise ter permissão para que
- Desativação de VMs de série A Basic e Standard.
- Em 31 de agosto de 2024, vamos desativar as VMs da série A Básica e Standard. Antes dessa data, você precisará migrar suas cargas de trabalho para as VMs da série Av2, que oferecem mais memória por vCPU e armazenamento mais rápido em unidades de estado sólido (SSDs). Para evitar interrupções no serviço, migre suas cargas de trabalho das VMs de série A Basic e Standard para VMs da série Av2 antes de 31 de agosto de 2024.
- Clusters ABFS não ESP [Permissões de cluster para leitura universal]
- Planeje introduzir uma alteração em clusters ABFS não ESP, o que restringe os usuários do grupo não Hadoop de executar comandos Hadoop em operações de armazenamento. Essa alteração melhora a postura de segurança do cluster. Os clientes precisam planejar as atualizações.
Data de lançamento: 28 de fevereiro de 2023
Esta versão se aplica ao HDInsight 4.0. and 5.0, 5.1. A versão do HDInsight estará disponível para todas as regiões ao longo de vários dias. Esta versão é aplicável ao número de imagem 2302250400. Como verificar o número da imagem?
O HDInsight usa práticas de implantação segura que envolvem a implantação gradual de região. Pode levar até 10 dias úteis para uma nova versão ficar disponível em todas as regiões.
Versões do sistema operacional
- HDInsight 4.0: Ubuntu 18.04.5 LTS Linux Kernel 5.4
- HDInsight 5.0: Ubuntu 18.04.5 LTS Linux Kernel 5.4
Para versões específicas da carga de trabalho, consulte
Importante
A Microsoft emitiu o CVE-2023-23408, que foi corrigido na versão atual e os clientes são aconselhados a atualizar seus clusters para a imagem mais recente.
![]()
HDInsight 5.1
Começamos a implantar uma nova versão do HDInsight 5.1. Todas as novas versões de código aberto serão adicionadas como versões incrementais no HDInsight 5.1.
Para obter mais informações, confira versão 5.1.0 do HDInsight
![]()
Atualização do Kafka 3.2.0 (versão prévia)
- O Kafka 3.2.0 inclui vários novos recursos/melhorias significativos.
- Zookeeper atualizado para 3.6.3
- Suporte ao Kafka Streams
- Garantias de entrega mais fortes para o produtor Kafka habilitado por padrão.
-
log4j1.x substituído porreload4j. - Envie uma dica para o líder de partição para recuperar a partição.
-
JoinGroupRequesteLeaveGroupRequesttêm um motivo anexado. - Métricas de contagem de agente adicionadas8.
- Aprimoramentos do Mirror
Maker2.
Atualização do HBase 2.4.11 (versão prévia)
- Esta versão tem novos recursos, como a adição de novos tipos de mecanismo de cache para cache de blocos, a capacidade de alterar
hbase:meta tablee exibir ahbase:metatabela da interface do usuário da WEB do HBase.
Atualização do Phoenix 5.1.2 (versão prévia)
- Versão do Phoenix atualizada para 5.1.2 nesta versão. Essa atualização inclui o Phoenix Query Server. O Phoenix Query Server faz proxies do driver JDBC phoenix padrão e fornece um protocolo de transmissão compatível com versões anteriores para invocar esse driver JDBC.
Ambari CVEs
- Vários CVEs do Ambari são fixos.
Observação
Não há suporte para ESP para Kafka e HBase nesta versão.
![]()
O que vem a seguir
- Autoscale
- Dimensionamento automático com latência aprimorada e várias melhorias
- Limitação de alteração de nome do cluster
- O comprimento máximo do nome do cluster muda para 45 de 59 em Público, Azure China e Azure Governamental.
- Permissões de cluster para armazenamento seguro
- Os clientes podem especificar (durante a criação do cluster) se um canal seguro deve ser usado para nós de cluster HDInsight contatarem a conta de armazenamento.
- Clusters ABFS não ESP [Permissões de cluster para leitura universal]
- Planeje introduzir uma alteração em clusters ABFS não ESP, o que restringe os usuários do grupo não Hadoop de executar comandos Hadoop em operações de armazenamento. Essa alteração melhora a postura de segurança do cluster. Os clientes precisam planejar as atualizações.
- Atualizações de software livre
- O Apache Spark 3.3.0 e o Hadoop 3.3.4 estão em desenvolvimento no HDInsight 5.1 e incluem vários novos recursos significativos, desempenho e outras melhorias.
Observação
Aconselhamos que os clientes usem versões mais recentes de Imagens HDInsight, pois eles trazem as melhores atualizações de código aberto, atualizações do Azure e correções de segurança. Para obter mais informações, confira Boas Práticas.
Data de lançamento: 12 de dezembro de 2022
Esta versão se aplica ao HDInsight 4.0. e a versão do HDInsight 5.0 é disponibilizada para todas as regiões durante vários dias.
O HDInsight usa práticas de implantação segura que envolvem a implantação gradual de região. Pode levar até 10 dias úteis para uma nova versão ficar disponível em todas as regiões.
Versões do sistema operacional
- HDInsight 4.0: Ubuntu 18.04.5 LTS Linux Kernel 5.4
- HDInsight 5.0: Ubuntu 18.04.5 LTS Linux Kernel 5.4
![]()
- Log Analytics – os clientes podem habilitar o monitoramento clássico para obter a versão mais recente do OMS 14.19. Para remover as versões antigas, desabilite e habilite o monitoramento clássico.
- O usuário do Ambari foi desconectado automaticamente da interface do usuário devido à inatividade. Para saber mais, confira aqui
- Spark – Uma versão nova e otimizada do Spark 3.1.3 está incluída nesta versão. Testamos o Apache Spark 3.1.2 (versão anterior) e o Apache Spark 3.1.3 (versão atual) usando o parâmetro de comparação TPC-DS. O teste foi realizado usando o SKU do E8 V3 para Apache Spark na carga de trabalho de 1 TB. O Apache Spark 3.1.3 (versão atual) superou o Apache Spark 3.1.2 (versão anterior) em mais de 40% no runtime total de consulta para consultas TPC-DS usando as mesmas especificações de hardware. A equipe do Microsoft Spark adicionou otimizações disponíveis no Azure Synapse com o Azure HDInsight. Para obter mais informações, consulte Acelerar suas cargas de trabalho de dados com atualizações de desempenho para o Apache Spark 3.1.2 no Azure Synapse
![]()
- Catar Central
- Norte da Alemanha
![]()
O HDInsight migrou do Azul Zulu Java JDK 8 para o
Adoptium Temurin JDK 8, que dá suporte a runtimes certificados pelo TCK de alta qualidade e tecnologia associada para uso em todo o ecossistema Java.O HDInsight migrou para o
reload4j. São aplicáveis as alterações delog4j- Apache Hadoop
- O Apache Zookeeper
- Apache Oozie
- Apache Ranger
- Apache Sqoop
- Apache Pig
- Apache Ambari
- Apache Kafka
- Apache Spark
- Apache Zeppelin
- Apache Livy
- Apache Rubix
- Apache Hive
- Apache Tez
- HBase no Apache
- OMI
- Apache Pheonix
![]()
HDInsight para implantar o TLS1.2 em andamento, e as versões anteriores são atualizadas na plataforma. Se você estiver executando todos os aplicativos no HDInsight e eles usarem o TLS 1.0 e 1.1, atualize para o TLS 1.2 para evitar qualquer interrupção nos serviços.
Para obter mais informações, consulte Como habilitar o protocolo TLS
![]()
Fim do suporte para clusters do Azure HDInsight no Ubuntu 16.04 LTS a partir de 30 de novembro de 2022. HDInsight começa o lançamento de imagens de cluster usando o Ubuntu 18.04 a partir de 27 de junho de 2021. Recomendamos que nossos clientes que estejam executando clusters usando o Ubuntu 16.04 recompilem seus clusters com as imagens mais recentes do HDInsight até 30 de novembro de 2022.
Para obter mais informações sobre como verificar a versão do cluster do Ubuntu, veja aqui
Execute o comando "lsb_release -a" no terminal.
Se o valor da propriedade "Description" na saída for "Ubuntu 16.04 LTS", essa atualização será aplicável ao cluster.
![]()
- Suporte para seleção das Zonas de Disponibilidade para os clusters Kafka e HBase (acesso de gravação).
Correções de bug de software livre
Correções de bug do Hive
| Correções de bugs | Apache JIRA |
|---|---|
| HIVE-26127 | Erro INSERT OVERWRITE - Arquivo não encontrado |
| HIVE-24957 | Resultados errados quando a subconsulta possui COALESCE no predicado de correlação |
| HIVE-24999 | HiveSubQueryRemoveRule gera um plano inválido para a subconsulta IN com várias correlações |
| HIVE-24322 | Se houver uma inserção direta, a ID da tentativa deverá ser verificada quando a leitura do manifesto falhar |
| HIVE-23363 | Atualizar a dependência do DataNucleus para 5.2 |
| HIVE-26412 | Criar a interface para buscar os slots disponíveis e adicionar o padrão |
| HIVE-26173 | Atualizar o derby para 10.14.2.0 |
| HIVE-25920 | Aumento do Xerce2 para a versão 2.12.2. |
| HIVE-26300 | Atualizar a versão de associação de dados do Jackson para 2.12.6.1+ para evitar o CVE-2020-36518 |
Data de lançamento: 10/08/2022
Esta versão se aplica ao HDInsight 4.0. A versão do HDInsight é disponibilizada para todas as regiões durante vários dias.
O HDInsight usa práticas de implantação segura que envolvem a implantação gradual de região. Pode levar até 10 dias úteis para uma nova versão ficar disponível em todas as regiões.
![]()
Novo recurso
1. Anexar discos externos aos clusters do HDI Hadoop/Spark
O cluster do HDInsight vem com espaço em disco predefinido com base no SKU. Esse espaço pode não ser suficiente em cenários de trabalho grande.
Este novo recurso permite adicionar mais discos ao cluster, que eram usados como diretório local do gerenciador de nós. Adicione diversos discos aos nós de trabalho durante a criação do cluster do HIVE e do Spark, enquanto os discos selecionados fazem parte dos diretórios locais do gerenciador de nó.
Observação
Os discos adicionados são configurados apenas para diretórios locais do gerenciador de nós.
Para obter mais informações, confira aqui
2. Análise seletiva de log
Agora a análise seletiva de log está disponível em todas as regiões para visualização pública. Você pode conectar o cluster a um workspace do Log Analytics. Depois de habilitado, você pode ver os logs e as métricas, como os Logs de Segurança do HDInsight, o Yarn Resource Manager, as Métricas do Sistema etc. Você pode monitorar as cargas de trabalho e ver como elas estão afetando a estabilidade do cluster. O log seletivo permite habilitar/desabilitar todas as tabelas ou habilitar tabelas seletivas no workspace do Log Analytics. Você pode ajustar o tipo de origem de cada tabela, pois na nova versão do Genebra, o monitoramento de uma tabela tem várias origens.
- O sistema de monitoramento do Genebra usa mdsd(MDS daemon), que é um agente de monitoramento e fluentd para coletar logs usando a camada de log unificada.
- O log seletivo usa a ação de script para desabilitar/habilitar as tabelas e os tipos de log. Como ele não abre novas portas nem altera as configurações de segurança existentes, não há alterações de segurança.
- A Ação de Script é executada paralelamente em todos os nós especificados e altera os arquivos de configuração para desabilitar/habilitar as tabelas e os tipos de log.
Para obter mais informações, confira aqui
![]()
Fixo
Análise de logs
O Log Analytics integrado ao Azure HDInsight que executa o OMS versão 13 requer uma atualização para o OMS versão 14, para aplicar as atualizações de segurança mais recentes. Os clientes que usam a versão mais antiga do cluster com o OMS versão 13 precisam instalar o OMS versão 14 para atender aos requisitos de segurança. (Como verificar a versão atual e instalar a 14)
Como verificar a versão atual do OMS
- Entre no cluster usando o SSH.
- Execute o comando a seguir no Cliente SSH.
sudo /opt/omi/bin/ominiserver/ --version

Como atualizar a versão do OMS de 13 para 14
- Entre no Portal do Azure
- No grupo de recursos, selecione o recurso de cluster do HDInsight
- Selecione Ações de Script
- No painel Enviar ação de script, escolha o Tipo script como personalizado
- Cole o link a seguir na caixa de URL do script Bash https://hdiconfigactions.blob.core.windows.net/log-analytics-patch/OMSUPGRADE14.1/omsagent-vulnerability-fix-1.14.12-0.sh
- Selecionar os Tipos de nó
- Escolha Criar
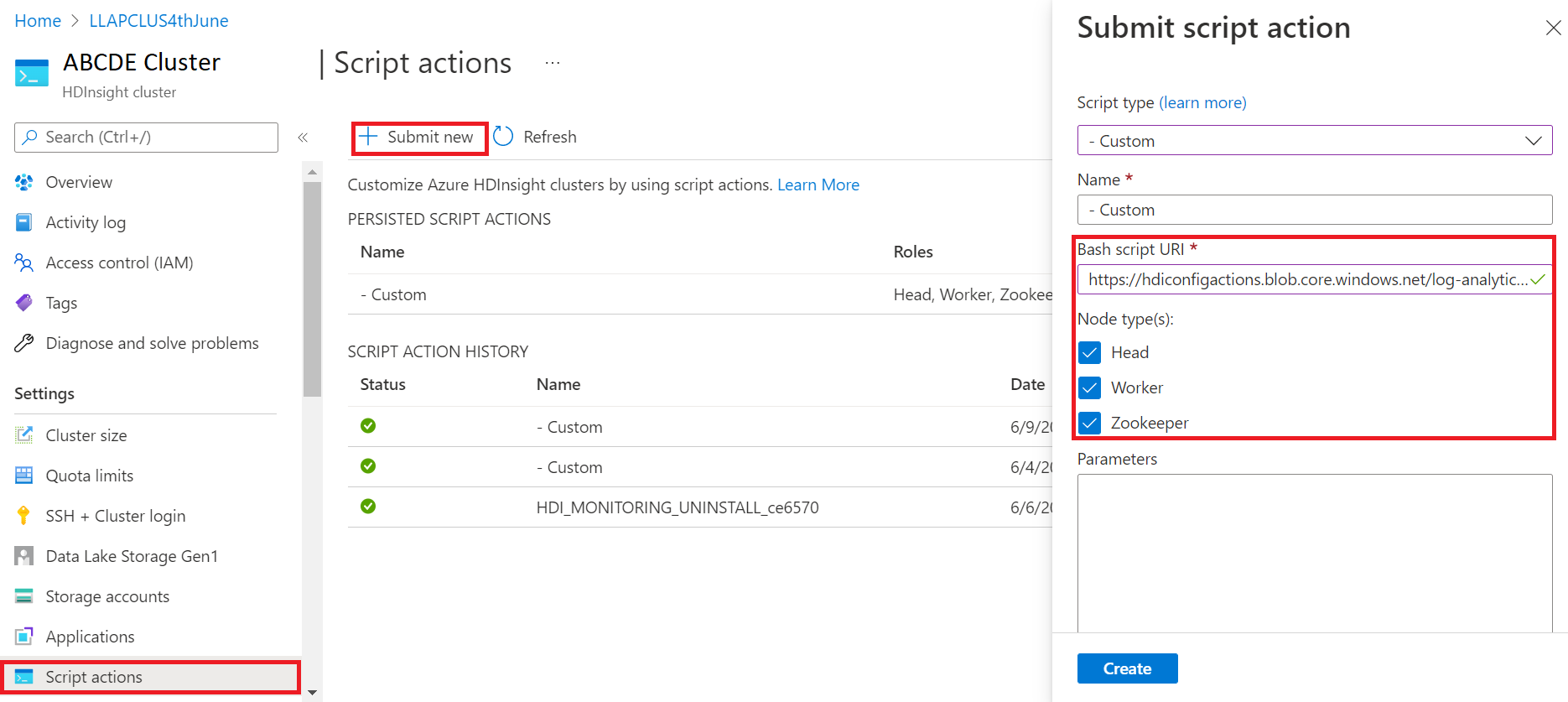
Verifique se a instalação do patch foi realizada com sucesso, usando as seguintes etapas:
Entre no cluster usando o SSH.
Execute o comando a seguir no Cliente SSH.
sudo /opt/omi/bin/ominiserver/ --version
Outras correções de bug
- A CLI de log do Yarn falhou ao recuperar os logs se algum
TFileestiver corrompido ou vazio. - Resolução do erro de detalhes inválidos da entidade de serviço, ao obter o token OAuth do Azure Active Directory.
- Melhoria da confiabilidade de criação do cluster, quando mais de 100 nós de trabalho são configurados.
Correções de bug de software livre
Correções de bug do TEZ
| Correções de bugs | Apache JIRA |
|---|---|
| Falha de Compilação do Tez: FileSaver.js não encontrado | TEZ-4411 |
Exceção de FS errada quando o warehouse e scratchdir estão em FS diferentes |
TEZ-4406 |
| O TezUtils.createConfFromByteString em uma configuração com mais de 32 MB lança a exceção com.google.protobuf.CodedInputStream | TEZ-4142 |
| TezUtils createByteStringFromConf deve usar o Snappy, em vez do DeflaterOutputStream | TEZ-4113 |
| Atualizar a dependência do protobuf para 3.x | TEZ-4363 |
Correções de bug do Hive
| Correções de bugs | Apache JIRA |
|---|---|
| Otimizações de desempenho na geração de divisão do ORC | HIVE-21457 |
| Evite ler a tabela como ACID, quando o nome da tabela começar com "delta", mas a tabela não for transacional e a Estratégia de Divisão de BI for usada | HIVE-22582 |
| Remover uma chamada de FS#exists do AcidUtils#getLogicalLength | HIVE-23533 |
| OrcAcidRowBatchReader.computeOffset vetorizado e otimização de bucket | HIVE-17917 |
Problemas conhecidos
O HDInsight é compatível com o Apache HIVE 3.1.2. Devido a um bug nesta versão, a versão do Hive é mostrada como 3.1.0 nas interfaces do Hive. No entanto, não há impacto na funcionalidade.
Data de lançamento: 10/08/2022
Esta versão se aplica ao HDInsight 4.0. A versão do HDInsight é disponibilizada para todas as regiões durante vários dias.
O HDInsight usa práticas de implantação segura que envolvem a implantação gradual de região. Pode levar até 10 dias úteis para uma nova versão ficar disponível em todas as regiões.
![]()
Novo recurso
1. Anexar discos externos aos clusters do HDI Hadoop/Spark
O cluster do HDInsight vem com espaço em disco predefinido com base no SKU. Esse espaço pode não ser suficiente em cenários de trabalho grande.
Esse novo recurso permite adicionar mais discos ao cluster, que serão usados como diretório local do gerenciador de nós. Adicione diversos discos aos nós de trabalho durante a criação do cluster do HIVE e do Spark, enquanto os discos selecionados fazem parte dos diretórios locais do gerenciador de nó.
Observação
Os discos adicionados são configurados apenas para diretórios locais do gerenciador de nós.
Para obter mais informações, confira aqui
2. Análise seletiva de log
Agora a análise seletiva de log está disponível em todas as regiões para visualização pública. Você pode conectar o cluster a um workspace do Log Analytics. Depois de habilitado, você pode ver os logs e as métricas, como os Logs de Segurança do HDInsight, o Yarn Resource Manager, as Métricas do Sistema etc. Você pode monitorar as cargas de trabalho e ver como elas estão afetando a estabilidade do cluster. O log seletivo permite habilitar/desabilitar todas as tabelas ou habilitar tabelas seletivas no workspace do Log Analytics. Você pode ajustar o tipo de origem de cada tabela, pois na nova versão do Genebra, o monitoramento de uma tabela tem várias origens.
- O sistema de monitoramento do Genebra usa mdsd(MDS daemon), que é um agente de monitoramento e fluentd para coletar logs usando a camada de log unificada.
- O log seletivo usa a ação de script para desabilitar/habilitar as tabelas e os tipos de log. Como ele não abre novas portas nem altera as configurações de segurança existentes, não há alterações de segurança.
- A Ação de Script é executada paralelamente em todos os nós especificados e altera os arquivos de configuração para desabilitar/habilitar as tabelas e os tipos de log.
Para obter mais informações, confira aqui
![]()
Fixo
Análise de logs
O Log Analytics integrado ao Azure HDInsight que executa o OMS versão 13 requer uma atualização para o OMS versão 14, para aplicar as atualizações de segurança mais recentes. Os clientes que usam a versão mais antiga do cluster com o OMS versão 13 precisam instalar o OMS versão 14 para atender aos requisitos de segurança. (Como verificar a versão atual e instalar a 14)
Como verificar a versão atual do OMS
- Entre no cluster usando o SSH.
- Execute o comando a seguir no Cliente SSH.
sudo /opt/omi/bin/ominiserver/ --version
Como atualizar a versão do OMS de 13 para 14
- Entre no Portal do Azure
- No grupo de recursos, selecione o recurso de cluster do HDInsight
- Selecione Ações de Script
- No painel Enviar ação de script, escolha o Tipo script como personalizado
- Cole o link a seguir na caixa de URL do script Bash https://hdiconfigactions.blob.core.windows.net/log-analytics-patch/OMSUPGRADE14.1/omsagent-vulnerability-fix-1.14.12-0.sh
- Selecionar os Tipos de nó
- Escolha Criar
Verifique se a instalação do patch foi realizada com sucesso, usando as seguintes etapas:
Entre no cluster usando o SSH.
Execute o comando a seguir no Cliente SSH.
sudo /opt/omi/bin/ominiserver/ --version
Outras correções de bug
- A CLI de log do Yarn falhou ao recuperar os logs se algum
TFileestiver corrompido ou vazio. - Resolução do erro de detalhes inválidos da entidade de serviço, ao obter o token OAuth do Azure Active Directory.
- Melhoria da confiabilidade de criação do cluster, quando mais de 100 nós de trabalho são configurados.
Correções de bug de software livre
Correções de bug do TEZ
| Correções de bugs | Apache JIRA |
|---|---|
| Falha de Compilação do Tez: FileSaver.js não encontrado | TEZ-4411 |
Exceção de FS errada quando o warehouse e scratchdir estão em FS diferentes |
TEZ-4406 |
| O TezUtils.createConfFromByteString em uma configuração com mais de 32 MB lança a exceção com.google.protobuf.CodedInputStream | TEZ-4142 |
| TezUtils createByteStringFromConf deve usar o Snappy, em vez do DeflaterOutputStream | TEZ-4113 |
| Atualizar a dependência do protobuf para 3.x | TEZ-4363 |
Correções de bug do Hive
| Correções de bugs | Apache JIRA |
|---|---|
| Otimizações de desempenho na geração de divisão do ORC | HIVE-21457 |
| Evite ler a tabela como ACID, quando o nome da tabela começar com "delta", mas a tabela não for transacional e a Estratégia de Divisão de BI for usada | HIVE-22582 |
| Remover uma chamada de FS#exists do AcidUtils#getLogicalLength | HIVE-23533 |
| OrcAcidRowBatchReader.computeOffset vetorizado e otimização de bucket | HIVE-17917 |
Problemas conhecidos
O HDInsight é compatível com o Apache HIVE 3.1.2. Devido a um bug nesta versão, a versão do Hive é mostrada como 3.1.0 nas interfaces do Hive. No entanto, não há impacto na funcionalidade.
Data de lançamento: 03/06/2022
Esta versão se aplica ao HDInsight 4.0. A versão do HDInsight é disponibilizada para todas as regiões durante vários dias. A data de lançamento mostrada aqui indica a data de lançamento da primeira região. Caso as alterações a seguir não apareçam, aguarde vários dias até que a versão esteja ativa em sua região.
Destaques da versão
O HWC (Hive Warehouse Connector) no Spark v3.1.2
O HWC (Hive Warehouse Connector) permite que você aproveite os recursos exclusivos do Hive e do Spark para criar aplicativos de Big Data poderosos. No momento, há suporte para o HWC somente no Spark v2.4. Esse recurso agrega valor comercial permitindo transações ACID em tabelas do Hive usando o Spark. Ele é útil para clientes que usam o Hive e o Spark no ambiente de dados. Para obter mais informações, consulte Apache Spark e Hive – Hive Warehouse Connector – Azure HDInsight | Microsoft Docs
Ambari
- Alterações de aprimoramento de dimensionamento e provisionamento
- O HDI Hive agora é compatível com o OSS versão 3.1.2
A versão HDI Hive 3.1 foi atualizada para a versão OSS Hive 3.1.2. Essa versão tem todas as correções e os recursos disponíveis na versão do Hive 3.1.2 de código aberto.
Observação
Spark
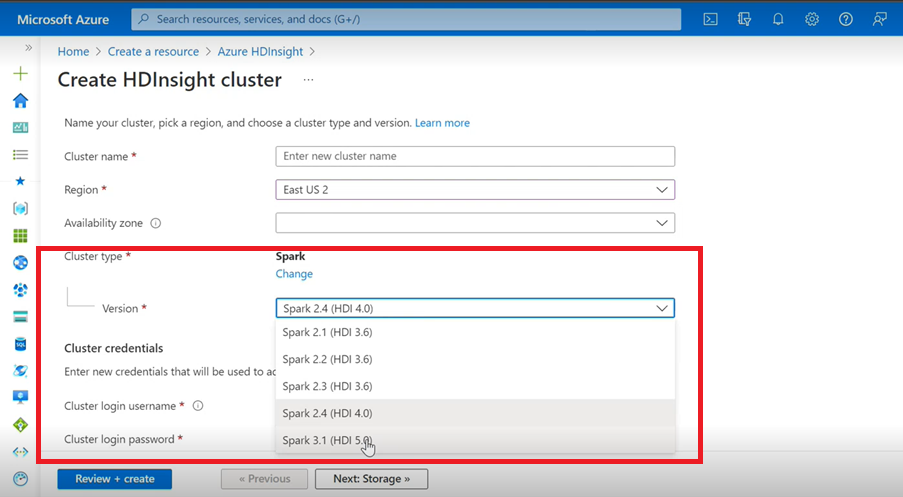
- Se você estiver usando a Interface de Usuário do Azure para criar o Spark Cluster para HDInsight, verá na lista suspensa uma outra versão do Spark 3.1.(HDI 5.0) junto com as versões mais antigas. Essa é uma versão renomeada do Spark 3.1. (HDI 4.0). Essa é apenas uma alteração no nível da interface do usuário, o que não afeta nada para os usuários existentes e aqueles que já estão usando o modelo do ARM.
Observação
Consulta Interativa
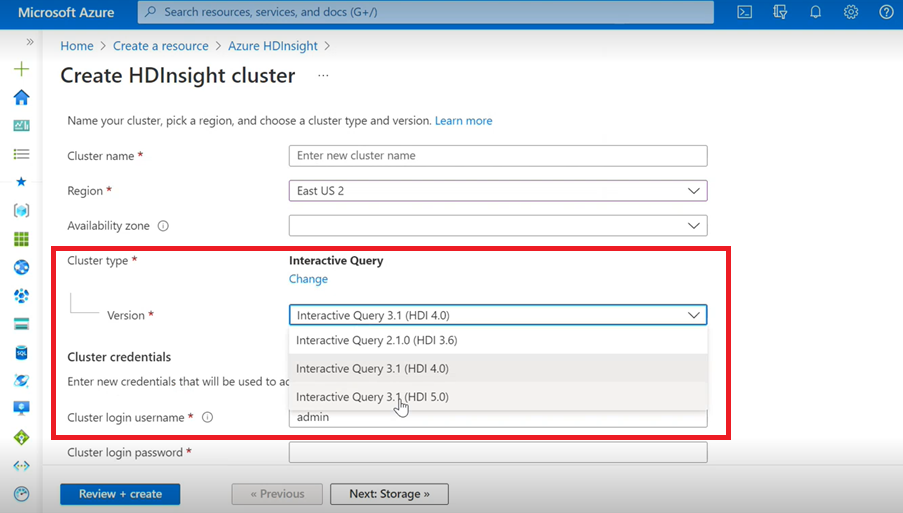
- Se você estiver criando um Cluster de Interactive Query, verá na lista suspensa uma outra versão como Interactive Query 3.1 (HDI 5.0).
- Se você vai usar a versão do Spark 3.1 junto com o Hive, o que exige suporte de ACID, selecione esta versão: Interactive Query 3.1 (HDI 5.0).
Correções de bug do TEZ
| Correções de bugs | Apache JIRA |
|---|---|
| O TezUtils.createConfFromByteString em uma configuração com mais de 32 MB lança a exceção com.google.protobuf.CodedInputStream | TEZ-4142 |
| TezUtils createByteStringFromConf deve usar o Snappy em vez do DeflaterOutputStream | TEZ-4113 |
Correções de bug do HBase
| Correções de bugs | Apache JIRA |
|---|---|
TableSnapshotInputFormat deve usar ReadType.STREAM para a verificação de HFiles |
HBASE-26273 |
| Adicionar uma opção para desabilitar o scanMetrics no TableSnapshotInputFormat | HBASE-26330 |
| Correção para ArrayIndexOutOfBoundsException quando o balanceador é executado | HBASE-22739 |
Correções de bug do Hive
| Correções de bugs | Apache JIRA |
|---|---|
| NPE ao inserir dados com a cláusula 'distribute by' com a otimização de classificação de dynpart | HIVE-18284 |
| O comando MSCK REPAIR com filtragem de partição falha ao remover partições | HIVE-23851 |
| Exceção errada gerada se capacity<=0 | HIVE-25446 |
| Suporte à carga paralela para HastTables – Interfaces | HIVE-25583 |
| Incluir MultiDelimitSerDe no HiveServer2 por padrão | HIVE-20619 |
| Remover as classes glassfish.jersey e mssql-jdbc do jar jdbc-standalone | HIVE-22134 |
| Exceção de ponteiro nulo na execução da compactação em uma tabela MM. | HIVE-21280 |
A consulta do Hive com tamanho grande via knox falha com o pipe quebrado de falha na gravação |
HIVE-22231 |
| Adicionar a capacidade para o usuário definir o usuário associado | HIVE-21009 |
| Implementar o UDF para interpretar data e carimbo de data/hora usando a representação interna e o calendário híbrido gregoriano/juliano | HIVE-22241 |
| Opção direta para mostrar/não mostrar o relatório de execução | HIVE-22204 |
| Tez: SplitGenerator tenta procurar arquivos de plano, o que não existe para o Tez | HIVE-22169 |
Remover o registro em log caro do cache do LLAP hotpath |
HIVE-22168 |
| O UDF: FunctionRegistry é sincronizado na classe org.apache.hadoop.hive.ql.udf.UDFType | HIVE-22161 |
| Impedir a criação do appender de roteamento de consulta se a propriedade estiver definida como false | HIVE-22115 |
| Remover a sincronização entre consultas para partition-eval | HIVE-22106 |
| Ignorar a configuração do diretório temporário do Hive durante o planejamento | HIVE-21182 |
| Ignorar a criação de diretórios temporários do Tez se a RPC estiver ativada | HIVE-21171 |
mudar os UDFs do Hive para usar o mecanismo regex Re2J |
HIVE-19661 |
| Tabelas clusterizadas migradas usando bucketing_version 1 no Hive 3 que o usa bucketing_version 2 para inserções | HIVE-22429 |
| Bucketing: o Bucketing versão 1 está particionando dados incorretamente | HIVE-21167 |
| Adição do cabeçalho de licença do ASF ao arquivo recém-adicionado | HIVE-22498 |
| Aprimoramentos da ferramenta de esquema para dar suporte ao mergeCatalog | HIVE-22498 |
| O Hive com TEZ UNION ALL e UDTF resulta em perda de dados | HIVE-21915 |
| Dividir arquivos de texto mesmo se houver cabeçalho/rodapé | HIVE-21924 |
| O MultiDelimitSerDe retorna resultados errados na última coluna quando o arquivo carregado tem mais colunas além da que está presente no esquema da tabela | HIVE-22360 |
| Cliente externo LLAP – É necessário reduzir o volume de LlapBaseInputFormat#getSplits() | HIVE-22221 |
| Os nomes de coluna com palavra-chave reservada não têm escape quando uma consulta incluindo a junção na tabela com a coluna de máscara é reescrita (Zoltan Matyus por Zoltan Haindrich) | HIVE-22208 |
Impedir o desligamento do LLAP no RuntimeException relacionado ao AMReporter |
HIVE-22113 |
| O driver de serviço de status LLAP pode ficar paralisado com a ID do aplicativo Yarn errada | HIVE-21866 |
| O OperationManager.queryIdOperation não limpa corretamente várias queryIds | HIVE-22275 |
| A desativação de um gerenciador de nós bloqueia a reinicialização do serviço LLAP | HIVE-22219 |
| Empilhar OverflowError ao remover muitas partições | HIVE-15956 |
| Falha na verificação de acesso quando um diretório temporário é removido | HIVE-22273 |
| Corrigir resultados errados/exceção ArrayOutOfBound em junções left outer de mapa sob condições de limite específicas | HIVE-22120 |
| Remover a marca de gerenciamento de distribuição de pom.xml | HIVE-19667 |
| O tempo de análise poderá ser alto se houver subconsultas profundamente aninhadas | HIVE-21980 |
Para ALTER TABLE t SET TBLPROPERTIES ('EXTERNAL'='TRUE'), as alterações do atributo TBL_TYPE não refletem para não CAPS |
HIVE-20057 |
JDBC: interfaces de log4j sombras do HiveConnection |
HIVE-18874 |
Atualizar as URLs de repositório no poms – versão de branch 3.1 |
HIVE-21786 |
Testes de DBInstall interrompidos no master e no branch-3.1 |
HIVE-21758 |
| O carregamento de dados em uma tabela em bucket está ignorando as especificações de partições e carrega dados na partição padrão | HIVE-21564 |
| As consultas com condição de junção com carimbo de data/hora ou carimbo de data/hora com literal de fuso horário local geram SemanticException | HIVE-21613 |
| A análise das estatísticas de computação da coluna deixa para trás o diretório temporário no HDFS | HIVE-21342 |
| Alteração incompatível na computação de bucket do Hive | HIVE-21376 |
| Fornecer um autorizador de fallback quando não houver nenhum outro autorizador em uso | HIVE-20420 |
| Algumas invocações de alterPartitions geram 'NumberFormatException: null' | HIVE-18767 |
| HiveServer2: a entidade pré-autenticada para o transporte http não é mantida em toda a duração da comunicação http em alguns casos | HIVE-20555 |
Data de lançamento: 10/03/2022
Esta versão se aplica ao HDInsight 4.0. A versão do HDInsight é disponibilizada para todas as regiões durante vários dias. A data de lançamento mostrada aqui indica a data de lançamento da primeira região. Caso as alterações a seguir não apareçam, aguarde vários dias até que a versão esteja ativa em sua região.
As versões do sistema operacional desta versão são:
- HDInsight 4.0: Ubuntu 18.04.5
O Spark 3.1 já está em disponibilidade geral
O Spark 3.1 já está em disponibilidade geral no HDInsight 4.0. Esta versão inclui
- execução de consulta adaptável;
- conversão, classificação, mesclagem e junção para junção hash de transmissão;
- Catalyst Optimizer do Spark;
- remoção de partição dinâmica.
- Os clientes poderão criar novos clusters do Spark 3.1, e não do Spark 3.0 (versão prévia).
Para obter mais informações, consulte o Apache Spark 3.1, geralmente disponível no HDInsight – Comunidade Microsoft Tech.
Para ver a lista completa de melhorias, confira as Notas sobre a versão do Apache Spark 3.1.
Para obter mais informações sobre migração, consulte o Guia de migração
O Kafka 2.4 já está em disponibilidade geral
O Kafka 2.4.1 já está em disponibilidade geral. Para obter mais informações, confira as Notas sobre a versão do Kafka 2.4.1. Outros recursos incluem disponibilidade do MirrorMaker 2, nova categoria de métrica de partição de tópico AtMinIsr, tempo de inicialização do agente aprimorado por demanda lenta mmap de arquivos de índice, mais métricas de consumidor para observar o comportamento de pesquisa do usuário.
O tipo de dados de mapa no HWC é compatível com o HDInsight 4.0
Nesta versão, o tipo de dados de mapa é compatível com o HWC 1.0 (Spark 2.4) por meio do aplicativo spark-shell, bem como todos os outros clientes Spark compatíveis com o HWC. Estes aprimoramentos são incluídos como qualquer outro tipo de dados:
Um usuário pode
- Criar uma tabela do Hive com colunas que contenham um tipo de dados de mapa, inserir dados e ler os resultados.
- Criar um dataframe do Apache Spark com o tipo de mapa e realizar leituras e gravações de lote/fluxo.
Novas regiões
Agora o HDInsight está presente em mais duas novas regiões: Leste da China 3 e Norte da China 3.
Alterações de backport de software de código aberto
Os backports de software de código aberto incluídos no Hive, como HWC 1.0 (Spark 2.4), compatíveis com o tipo de dados de mapa.
Estes são os software de código aberto com backport para os JIRAs do Apache nesta versão:
| Recurso afetado | Apache JIRA |
|---|---|
| Consultas SQL diretas do metastore com IN/(NOT IN) devem ser divididas com base nos parâmetros máximos permitidos pelo BD SQL | HIVE-25659 |
Upgrade do log4j 2.16.0 para a 2.17.0 |
HIVE-25825 |
Atualizar versão Flatbuffer |
HIVE-22827 |
| Suporte nativo para o tipo de dados de mapa no formato de seta | HIVE-25553 |
| Cliente externo LLAP – Tratar valores aninhados quando o struct pai é nulo | HIVE-25243 |
| Atualizar a versão de seta para 0.11.0 | HIVE-23987 |
Aviso de substituição
Conjuntos de Dimensionamento de Máquinas Virtuais do Azure no HDInsight
O HDInsight não usará mais os Conjuntos de Dimensionamento de Máquinas Virtuais do Azure para provisionar os clusters, nenhuma alteração interruptiva é esperada. Os clusters HDInsight existentes em conjuntos de dimensionamentos de máquinas virtuais não têm impacto, quaisquer novos clusters nas imagens mais recentes não usarão mais os conjuntos de dimensionamentos de máquinas virtuais.
O dimensionamento de cargas de trabalho do HBase do Azure HDInsight agora serão compatíveis apenas com o uso do dimensionamento manual
A partir de 1º de março de 2022, o HDInsight só será compatível com o dimensionamento manual para HBase, não há nenhum impacto na execução de clusters. Novos clusters HBase não poderão habilitar o dimensionamento automático baseado em agendamento. Para saber mais sobre como dimensionar manualmente o cluster HBase, confira a documentação Dimensionar manualmente clusters do Azure HDInsight
Data de lançamento: 27/12/2021
Esta versão se aplica ao HDInsight 4.0. A versão do HDInsight é disponibilizada para todas as regiões durante vários dias. A data de lançamento mostrada aqui indica a data de lançamento da primeira região. Caso as alterações a seguir não apareçam, aguarde vários dias até que a versão esteja ativa em sua região.
As versões do sistema operacional desta versão são:
- HDInsight 4.0: Ubuntu 18.04.5 LTS
A imagem do HDInsight 4.0 foi atualizada para mitigar a vulnerabilidade do Log4j descrita na Resposta da Microsoft ao CVE-2021-44228 Apache Log4j 2.
Observação
- Todos os clusters HDI 4.0 criados após 27 de dezembro de 2021 às 00:00 UTC são criados com uma versão atualizada da imagem que mitiga as vulnerabilidades de
log4j. Portanto, os clientes não precisam aplicar patch/reinicializar esses clusters. - Para os novos clusters do HDInsight 4.0 criados entre 16 de dezembro de 2021, 1h15 UTC e 27 de dezembro de 2021, 0h UTC, no HDInsight 3.6 ou nas assinaturas fixadas após 16 de dezembro de 2021, o patch é aplicado automaticamente na hora em que o cluster é criado. No entanto, os clientes precisam reinicializar os nós para que a aplicação de patch seja concluída (exceto os nós de gerenciamento do Kafka, que são reinicializados automaticamente).
Data de lançamento: 27/07/2021
Esta versão se aplica ao HDInsight 3.6 e HDInsight 4.0. A versão do HDInsight é disponibilizada para todas as regiões durante vários dias. A data de lançamento mostrada aqui indica a data de lançamento da primeira região. Caso as alterações a seguir não apareçam, aguarde alguns dias até que a versão esteja ativa em sua região.
As versões do sistema operacional desta versão são:
- HDInsight 3.6: Ubuntu 16.04.7 LTS
- HDInsight 4.0: Ubuntu 18.04.5 LTS
Novos recursos
O suporte do Azure HDInsight para Conectividade Pública Restrita está geralmente disponível em 15 de outubro de 2021.
O Azure HDInsight agora dá suporte à conectividade pública restrita em todas as regiões. Abaixo estão alguns dos principais destaques dessa funcionalidade:
- Capacidade de reverter o provedor de recursos para a comunicação de cluster de forma que ele seja de saída do cluster para o provedor de recursos
- Suporte para trazer seus próprios recursos habilitados para Link Privado (por exemplo, armazenamento, SQL, cofre de chaves) para o cluster HDInsight acessar os recursos somente pela rede privada
- Nenhum endereço IP público é provisionado por recursos
Usando essa nova funcionalidade, você também pode ignorar as regras de marca de serviço do NSG (Grupo de Segurança de Rede) de entrada para IPs de gerenciamento do HDInsight. Saiba mais sobre como restringir a conectividade pública
O suporte do Azure HDInsight para Link Privado do Azure está disponível em 15 de outubro de 2021
Agora você pode usar pontos de extremidade privados para se conectar aos clusters HDInsight por link privado. O link privado pode ser usado em cenários de VNET cruzados em que o emparelhamento de VNET não está disponível ou habilitado.
O Link Privado do Azure lhe permite acessar os serviços de PaaS do Azure (por exemplo, Armazenamento do Azure e Banco de Dados SQL) e serviços de parceiros/de propriedade de clientes hospedados no Azure em um ponto de extremidade privado em sua rede virtual.
O tráfego entre sua rede virtual e o serviço viaja a rede de backbone da Microsoft. Expor seu serviço à Internet pública não é mais necessário.
Saiba mais em habilitar o link privado.
Nova experiência de integração do Azure Monitor (versão prévia)
A nova experiência de integração do Azure Monitor estará em Versão Prévia no Leste dos EUA e no Oeste da Europa com esta versão. Saiba mais detalhes sobre a nova experiência de do Azure Monitor aqui.
Reprovação
A versão do HDInsight 3.6 foi em 1º de outubro de 2022.
Alterações de comportamento
O Interactive Query do HDInsight é compatível somente com um Dimensionamento Automático baseado em agenda
Conforme os cenários do cliente se tornam mais desenvolvidos e diversos, identificamos algumas limitações no Dimensionamento Automático baseado em carga do Interactive Query (LLAP). Essas limitações são causadas pela natureza da dinâmica de consulta do LLAP, de problemas de precisão na previsão de cargas futuras e problemas na redistribuição de tarefas do agendador do LLAP. Devido a essas limitações, talvez os usuários vejam suas consultas serem executadas de modo mais lento em clusters LLAP quando o Dimensionamento automático estiver habilitado. O efeito no desempenho pode superar o custo-benefício do Dimensionamento Automático.
A partir de julho de 2021, a carga de trabalho do Interactive Query no HDInsight é compatível somente com o Dimensionamento Automático baseado em agenda. Não é mais possível habilitar o dimensionamento automático baseado em carga em novos clusters da Interactive Query. Os clusters existentes podem continuar em execução com as limitações conhecidas descritas acima.
A Microsoft recomenda migrar para um Dimensionamento Automático baseado em agenda para o LLAP. É possível analisar o padrão de uso atual do cluster por meio do painel do Hive do Grafana. Para obter mais informações, consulte Dimensionar automaticamente clusters do Azure HDInsight.
Alterações futuras
As seguintes alterações ocorrem nas próximas versões.
O componente LLAP integrado ao cluster do Spark ESP será removido
O cluster do Spark ESP do HDInsight 4.0 tem componentes de LLAP internos em execução em ambos os nós principais. Os componentes LLAP no cluster do Spark ESP foram originalmente adicionados ao HDInsight 3.6 ESP Spark, mas não tem caso de usuário real para o Spark ESP do HDInsight 4.0. Na próxima versão agendada em setembro de 2021, o HDInsight removerá o componente LLAP integrado do cluster do Spark ESP do HDInsight 4.0. Esta alteração ajuda a descarregar a carga de trabalho do nó de cabeça e evitar confusão entre o tipo de cluster do Spark ESP e o tipo de cluster Hive Interativo ESP.
Nova região
- Oeste dos EUA 3
- Oeste da Índia do
Jio - Austrália Central
Alteração na versão do componente
A seguinte versão do componente foi alterada com esta versão:
- Versão ORC de 1.5.1 para 1.5.9
Você pode encontrar as versões de componente atuais para o HDInsight 4.0 e o HDInsight 3.6 neste documento.
JIRAs portados de volta
Aqui estão os JIRAs do Apache portados de volta para esta versão:
| Recurso afetado | Apache JIRA |
|---|---|
| Data/carimbo de data/hora | HIVE-25104 |
| HIVE-24074 | |
| HIVE-22840 | |
| HIVE-22589 | |
| HIVE-22405 | |
| HIVE-21729 | |
| HIVE-21291 | |
| HIVE-21290 | |
| UDF | HIVE-25268 |
| HIVE-25093 | |
| HIVE-22099 | |
| HIVE-24113 | |
| HIVE-22170 | |
| HIVE-22331 | |
| ORC | HIVE-21991 |
| HIVE-21815 | |
| HIVE-21862 | |
| Esquema de tabela | HIVE-20437 |
| HIVE-22941 | |
| HIVE-21784 | |
| HIVE-21714 | |
| HIVE-18702 | |
| HIVE-21799 | |
| HIVE-21296 | |
| Gerenciamento de carga de trabalho | HIVE-24201 |
| Compactação | HIVE-24882 |
| HIVE-23058 | |
| HIVE-23046 | |
| Exibição materializada | HIVE-22566 |
Correção de Preço para Máquinas Virtuais Dv2 do HDInsight
Um erro de preço foi corrigido em 25 de abril de 2021, para a série de VM Dv2 no HDInsight. O erro de precificação resultou em um preço reduzido nas contas de alguns clientes antes de 25 de abril. Com a correção, agora os preços correspondem ao que foi anunciado na página de preços e na calculadora de preços do HDInsight. O erro de preço afetou os clientes das seguintes regiões que usavam VMs Dv2:
- Canadá Central
- Leste do Canadá
- Leste da Ásia
- Norte da África do Sul
- Sudeste Asiático
- EAU Central
A partir de 25 de abril de 2021, o valor corrigido para as VMs Dv2 estará em sua conta. As notificações de cliente foram enviadas aos proprietários da assinatura antes da alteração. Você pode usar a Calculadora de preços, a página de preços do HDInsight ou a folha Criar cluster do HDInsight no portal do Azure para ver os custos corrigidos para VMs Dv2 em sua região.
Não é preciso executar ações adicionais. A correção do preço será aplicada somente ao uso a partir de 25 de abril de 2021 em regiões específicas, não a usos anteriores a essa data. Para garantir que você tenha a solução mais eficiente e econômica, recomendamos examinar o preço, a VCPU e a RAM dos seus clusters Dv2 e comparar as especificações de Dv2 com as VMs Ev3 para ver se a solução se beneficiaria com a utilização de uma das séries de VMs mais recentes.
Data de lançamento: 02/06/2021
Esta versão se aplica ao HDInsight 3.6 e HDInsight 4.0. A versão do HDInsight é disponibilizada para todas as regiões durante vários dias. A data de lançamento mostrada aqui indica a data de lançamento da primeira região. Caso as alterações a seguir não apareçam, aguarde alguns dias até que a versão esteja ativa em sua região.
As versões do sistema operacional desta versão são:
- HDInsight 3.6: Ubuntu 16.04.7 LTS
- HDInsight 4.0: Ubuntu 18.04.5 LTS
Novos recursos
Atualização de versão do SO
Conforme referência mostrada no ciclo de lançamento do Ubuntu, o kernel do Ubuntu 16.04 atingiu o Fim da Vida Útil (EOL) em abril de 2021. Começamos a liberar a nova imagem do cluster HDInsight 4.0 em execução no Ubuntu 18.04 com essa versão. Os clusters do HDInsight 4.0 recém-criados são executados no Ubuntu 18.04 por padrão quando este se torna disponível. Os clusters existentes no Ubuntu 16.04 são executados no estado em que estão com suporte completo.
O HDInsight 3.6 continuará em execução no Ubuntu 16.04. Ele será alterado para suporte Básico (do suporte Standard) a partir de 1 de julho de 2021. Para obter mais informações sobre datas e opções de suporte, confira as versões do Azure HDInsight. O Ubuntu 18.04 não será compatível com o HDInsight 3.6. Se quiser usar o Ubuntu 18.04, será necessário migrar os clusters para o HDInsight 4.0.
Caso queira migrar os clusters HDInsight 4.0 existentes para o Ubuntu 18.04, será preciso remover os clusters e recriá-los. Planeje criar ou recriar seus clusters após o suporte para o Ubuntu 18.04 ficar disponível.
Depois de criar o novo cluster, você pode executar o SSH nele e executar sudo lsb_release -a para verificar se ele é executado no Ubuntu 18.04. Recomendamos que você teste seus aplicativos em suas assinaturas de teste primeiro antes de passar para a produção.
Dimensionamento de otimizações em clusters de gravações aceleradas do HBase
O HDInsight fez algumas melhorias e otimizações no dimensionamento para clusters habilitados para gravação acelerada do HBase. Saiba mais sobre a gravação acelerada do HBase.
Reprovação
Nenhuma desativação nesta versão.
Alterações de comportamento
Desabilitar o tamanho da VM Standard_A5 como Nó de Cabeçalho para o HDInsight 4.0
O Nó de Cabeçalho do cluster HDInsight é responsável por inicializar e gerenciar o cluster. O tamanho da VM Standard_A5 tem problemas de confiabilidade como Nó de Cabeçalho para o HDInsight 4.0. A partir desta versão, os clientes não podem criar clusters usando o tamanho da VM Standard_A5 como Nó de Cabeçalho. É possível usar outras VMs de dois núcleos, como E2_v3 ou E2s_v3. Clusters existentes serão executados integralmente. Recomendamos usar uma VM de quatro núcleos em um Nó de Cabeçalho para garantir uma alta disponibilidade e confiabilidade de clusters HDInsight de produção.
O recurso de interface de rede não fica visível para clusters em execução em conjuntos de dimensionamento de máquinas virtuais do Azure
O HDInsight está migrando gradualmente para os conjuntos de dimensionamento de máquinas virtuais do Azure. As interfaces de rede para máquinas virtuais não são mais visíveis para os clientes em clusters que usam conjuntos de dimensionamento de máquinas virtuais do Azure.
Alterações futuras
As alterações a seguir ocorrerão em versões futuras.
O Interactive Query do HDInsight é compatível somente com um Dimensionamento Automático baseado em agenda
Conforme os cenários do cliente se tornam mais desenvolvidos e diversos, identificamos algumas limitações no Dimensionamento Automático baseado em carga do Interactive Query (LLAP). Essas limitações são causadas pela natureza da dinâmica de consulta do LLAP, de problemas de precisão na previsão de cargas futuras e problemas na redistribuição de tarefas do agendador do LLAP. Devido a essas limitações, talvez os usuários vejam suas consultas serem executadas de modo mais lento em clusters LLAP quando o Dimensionamento automático estiver habilitado. O efeito no desempenho pode superar o custo-benefício do Dimensionamento Automático.
A partir de julho de 2021, a carga de trabalho do Interactive Query no HDInsight é compatível somente com o Dimensionamento Automático baseado em agenda. Não é mais possível habilitar o Dimensionamento Automático em novos clusters do Interactive Query. Os clusters existentes podem continuar em execução com as limitações conhecidas descritas acima.
A Microsoft recomenda migrar para um Dimensionamento Automático baseado em agenda para o LLAP. É possível analisar o padrão de uso atual do cluster por meio do painel do Hive do Grafana. Para obter mais informações, consulte Dimensionar automaticamente clusters do Azure HDInsight.
A nomenclatura do host da VM será alterada em 1º de julho de 2021
O HDInsight atualmente usa máquinas virtuais do Azure para provisionar o cluster. O serviço está migrando gradualmente para os conjuntos de dimensionamento de máquinas virtuais do Azure. Essa migração alterará o formato de nome FQDN do nome de host do cluster, e os números no nome do host não serão garantidos em sequência. Se você quiser obter os nomes de FQDN para cada nó, consulte Localizar os nomes de Host dos Nós do Cluster.
Mover para os Conjuntos de Dimensionamento de Máquinas Virtuais do Azure
O HDInsight atualmente usa máquinas virtuais do Azure para provisionar o cluster. O serviço irá migrar gradualmente para os conjuntos de dimensionamento de máquinas virtuais do Azure. Todo o processo pode levar meses. Depois que suas regiões e assinaturas forem migradas, os clusters do HDInsight recém-criados serão executados em conjuntos de dimensionamento de máquinas virtuais sem ações do cliente. Nenhuma alteração interruptiva é esperada.
Data da versão: 24/03/2021
Novos recursos
Versão prévia do Spark 3.0
O HDInsight adicionou suporte para Spark 3.0.0 ao HDInsight 4.0 como uma versão prévia do recurso.
Versão prévia do Kafka 2.4
O HDInsight adicionou suporte para Kafka 2.4.1 ao HDInsight 4.0 como uma versão prévia do recurso.
Suporte à série Eav4
O HDInsight adicionou suporte à série Eav4 nesta versão.
Migrar para Conjuntos de Dimensionamento de Máquinas Virtuais do Azure
O HDInsight atualmente usa máquinas virtuais do Azure para provisionar o cluster. O serviço está migrando gradualmente para os conjuntos de dimensionamento de máquinas virtuais do Azure. Todo o processo pode levar meses. Depois que suas regiões e assinaturas forem migradas, os clusters do HDInsight recém-criados serão executados em conjuntos de dimensionamento de máquinas virtuais sem ações do cliente. Nenhuma alteração interruptiva é esperada.
Reprovação
Nenhuma desativação nesta versão.
Alterações de comportamento
A versão padrão de cluster é alterada para 4.0
A versão padrão do cluster HDInsight é alterada de 3.6 para 4.0. Para obter mais informações sobre as versões disponíveis, consulte versões disponíveis. Saiba mais sobre as atualizações no HDInsight 4.0.
Os tamanhos padrão das VMs do cluster foram alterados para a série Ev3
Os tamanhos padrão de VM de cluster foram alterados da série D para a série Ev3. Essa alteração se aplica a nós de cabeçalho e nós de trabalho. Para evitar que essa alteração afete os fluxos de trabalho testados, especifique os tamanhos de VM que deseja usar no modelo do ARM.
O recurso de interface de rede não fica visível para clusters em execução em conjuntos de dimensionamento de máquinas virtuais do Azure
O HDInsight está migrando gradualmente para os conjuntos de dimensionamento de máquinas virtuais do Azure. As interfaces de rede para máquinas virtuais não são mais visíveis para os clientes em clusters que usam conjuntos de dimensionamento de máquinas virtuais do Azure.
Alterações futuras
As alterações a seguir ocorrerão em versões futuras.
O Interactive Query do HDInsight é compatível somente com um Dimensionamento Automático baseado em agenda
Conforme os cenários do cliente se tornam mais desenvolvidos e diversos, identificamos algumas limitações no Dimensionamento Automático baseado em carga do Interactive Query (LLAP). Essas limitações são causadas pela natureza da dinâmica de consulta do LLAP, de problemas de precisão na previsão de cargas futuras e problemas na redistribuição de tarefas do agendador do LLAP. Devido a essas limitações, talvez os usuários vejam suas consultas serem executadas de modo mais lento em clusters LLAP quando o Dimensionamento automático estiver habilitado. O impacto no desempenho pode superar o custo-benefício do Dimensionamento Automático.
A partir de julho de 2021, a carga de trabalho do Interactive Query no HDInsight é compatível somente com o Dimensionamento Automático baseado em agenda. Não é mais possível habilitar o Dimensionamento Automático em novos clusters do Interactive Query. Os clusters existentes podem continuar em execução com as limitações conhecidas descritas acima.
A Microsoft recomenda migrar para um Dimensionamento Automático baseado em agenda para o LLAP. É possível analisar o padrão de uso atual do cluster por meio do painel do Hive do Grafana. Para obter mais informações, consulte Dimensionar automaticamente clusters do Azure HDInsight.
Atualização de versão do SO
No momento, os clusters HDInsight estão em execução no LTS do Ubuntu 16.04. Conforme referência mostrada no ciclo de lançamento do Ubuntu, o kernel do Ubuntu 16.04 atingiu o EOL (Fim da Vida Útil) em abril de 2021. Começamos a implementar a nova imagem do cluster HDInsight 4.0 em execução no Ubuntu 18.04 em maio de 2021. Os clusters HDInsight 4.0 recém-criados serão executados no Ubuntu 18.04 por padrão quando estiverem disponíveis. Os clusters existentes no Ubuntu 16.04 serão executados no estado em que estão com suporte completo.
O HDInsight 3.6 continuará em execução no Ubuntu 16.04. Ele atingiu o término do suporte padrão em 30 de junho de 2021 e foi alterado para o suporte básico a partir de 1º de julho de 2021. Para obter mais informações sobre datas e opções de suporte, confira as Versões do Azure HDInsight. O Ubuntu 18.04 não será compatível com o HDInsight 3.6. Caso queria usar o Ubuntu 18.04, será preciso migrar seus clusters para o HDInsight 4.0.
Caso queira migrar clusters existentes para o Ubuntu 18.04, será preciso remover seus clusters e recriá-los. Planeje criar ou recriar o cluster depois que o suporte ao Ubuntu 18.04 estiver disponível. Enviaremos outra notificação quando a nova imagem estiver disponível em todas as regiões.
Recomendamos testar com antecedência ações de script e aplicativos personalizados implantados em nós de borda em uma VM (máquina virtual) do Ubuntu 18.04. É possível criar uma VM do Ubuntu Linux no LTS 18.04, depois criar e usar um par de chaves SSH (Secure Shell) na VM para executar e testar ações de script e aplicativos personalizados implantados em nós de borda.
Desabilitar o tamanho da VM Standard_A5 como Nó de Cabeçalho para o HDInsight 4.0
O Nó de Cabeçalho do cluster HDInsight é responsável por inicializar e gerenciar o cluster. O tamanho da VM Standard_A5 tem problemas de confiabilidade como Nó de Cabeçalho para o HDInsight 4.0. Desde o lançamento em maio de 2021, os clientes não podem criar clusters usando o tamanho da VM Standard_A5 como Nó de Cabeçalho. É possível usar outras VMs de dois núcleos, como E2_v3 ou E2s_v3. Clusters existentes serão executados integralmente. Recomendamos usar uma VM de quatro núcleos em um Nó de Cabeçalho para garantir uma alta disponibilidade e confiabilidade de clusters HDInsight de produção.
Correções de bug
O HDInsight continua a fazer aprimoramentos de desempenho e confiabilidade do cluster.
Alteração na versão do componente
Adicionado suporte para Spark 3.0.0 e Kafka 2.4.1 como versão prévia. Você pode encontrar as versões de componente atuais para o HDInsight 4.0 e o HDInsight 3.6 neste documento.
Data do lançamento: 05/02/2021
Esta versão se aplica ao HDInsight 3.6 e 4.0. A versão do HDInsight é disponibilizada para todas as regiões durante vários dias. A data de lançamento mostrada aqui indica a data de lançamento da primeira região. Caso as alterações a seguir não apareçam, aguarde alguns dias até que a versão esteja ativa em sua região.
Novos recursos
Suporte à série Dav4
O HDInsight acrescentou suporte à série Dav4 nesta versão. Saiba mais sobre a série Dav4 aqui.
GA do Proxy REST do Kafka
O Proxy REST do Kafka permite interagir com o cluster do Kafka por meio de uma API REST via HTTPS. O proxy REST do Kafka está disponível a partir desta versão. Saiba mais sobre o Proxy REST do Kafka aqui.
Migrar para Conjuntos de Dimensionamento de Máquinas Virtuais do Azure
O HDInsight atualmente usa máquinas virtuais do Azure para provisionar o cluster. O serviço está migrando gradualmente para os conjuntos de dimensionamento de máquinas virtuais do Azure. Todo o processo pode levar meses. Depois que suas regiões e assinaturas forem migradas, os clusters do HDInsight recém-criados serão executados em conjuntos de dimensionamento de máquinas virtuais sem ações do cliente. Nenhuma alteração interruptiva é esperada.
Reprovação
Tamanhos de VM desabilitados
A partir de 9 de janeiro de 2021, o HDInsight bloqueará todos os clientes que criarem clusters usando tamanhos de VM standard_A8, standard_A9, standard_A10 e standard_A11. Clusters existentes serão executados integralmente. Considere a possibilidade de migrar para o HDInsight 4.0 para evitar a potencial interrupção do sistema/suporte.
Alterações de comportamento
Alterações de tamanho de VM de cluster padrão para a série Ev3
Os tamanhos padrão de VM de cluster serão alterados da série D para a série Ev3. Essa alteração se aplica a nós de cabeçalho e nós de trabalho. Para evitar que essa alteração afete os fluxos de trabalho testados, especifique os tamanhos de VM que deseja usar no modelo do ARM.
O recurso de interface de rede não fica visível para clusters em execução em conjuntos de dimensionamento de máquinas virtuais do Azure
O HDInsight está migrando gradualmente para os conjuntos de dimensionamento de máquinas virtuais do Azure. As interfaces de rede para máquinas virtuais não são mais visíveis para os clientes em clusters que usam conjuntos de dimensionamento de máquinas virtuais do Azure.
Alterações futuras
As alterações a seguir ocorrerão em versões futuras.
A versão de cluster padrão será alterada para 4.0
A partir de fevereiro de 2021, a versão padrão do cluster HDInsight será alterada de 3.6 para 4.0. Para mais informações sobre as versões disponíveis, consulte versões disponíveis. Saiba mais sobre as atualizações no HDInsight 4.0.
Atualização de versão do Sistema Operacional
O HDInsight está atualizando a versão do sistema operacional do Ubuntu 16.04 ao 18.04. A atualização será concluída antes de abril de 2021.
Fim do suporte do HDInsight 3.6 em 30 de junho de 2021
O HDInsight 3.6 terá seu suporte encerrado. A partir de 30 de junho de 2021, os clientes não poderão criar novos clusters HDInsight 3.6. Os clusters existentes serão executados como estão, sem o suporte da Microsoft. Considere a possibilidade de migrar para o HDInsight 4.0 para evitar a potencial interrupção do sistema/suporte.
Alteração na versão do componente
Nenhuma alteração de versão de componente para esta versão. Você pode encontrar as versões de componente atuais para o HDInsight 4.0 e HDInsight 3.6 aqui.
Data do lançamento: 18/11/2020
Esta versão se aplica ao HDInsight 3.6 e 4.0. A versão do HDInsight é disponibilizada para todas as regiões durante vários dias. A data de lançamento mostrada aqui indica a data de lançamento da primeira região. Caso as alterações a seguir não apareçam, aguarde alguns dias até que a versão esteja ativa em sua região.
Novos recursos
Rotação de chaves automática para criptografia de chave gerenciada pelo cliente inativo
A partir dessa versão, os clientes poderão usar URLs de chave de criptografia sem versão do Azure KeyVault para criptografia com a chave gerenciada pelo cliente inativa. O HDInsight irá girar automaticamente as chaves conforme elas expiram ou são substituídas por novas versões. Veja mais detalhes aqui.
Capacidade de selecionar diferentes tamanhos de máquina virtual Zookeeper para serviços Spark, Hadoop e ML
Anteriormente, o HDInsight não tinha suporte à personalização do tamanho do nó Zookeeper para os tipos de cluster Spark, Hadoop e ML Services. O padrão são tamanhos de máquina virtual A2_v2/A2, que são fornecidos gratuitamente. A partir desta versão, é possível selecionar um tamanho de máquina virtual Zookeeper que seja mais apropriado para seu cenário. Os nós do Zookeeper com tamanho de máquina virtual diferente de A2_v2/A2 serão cobrados. As máquinas virtuais A2_v2 e A2 ainda são fornecidas gratuitamente.
Migrar para Conjuntos de Dimensionamento de Máquinas Virtuais do Azure
O HDInsight atualmente usa máquinas virtuais do Azure para provisionar o cluster. A partir desta versão, o serviço migrará gradualmente para os conjuntos de dimensionamento de máquinas virtuais do Azure. Todo o processo pode levar meses. Depois que suas regiões e assinaturas forem migradas, os clusters do HDInsight recém-criados serão executados em conjuntos de dimensionamento de máquinas virtuais sem ações do cliente. Nenhuma alteração interruptiva é esperada.
Reprovação
Substituição do cluster do HDInsight 3.6 ML Services
O tipo de cluster de serviços do HDInsight 3.6 ML terá seu suporte encerrado em 31 de dezembro de 2020. Os clientes não poderão criar novos clusters ML Services 3.6 após 31 de dezembro de 2020. Os clusters existentes serão executados como estão, sem o suporte da Microsoft. Verifique a expiração do suporte para versões e tipos de cluster do HDInsight aqui.
Tamanhos de VM desabilitados
A partir de 16 de novembro de 2020, o HDInsight bloqueará novos clientes que criarem clusters usando tamanhos de VM standard_A8, standard_A9, standard_A10 e standard_A11. Os clientes que usaram esses tamanhos de VM nos últimos três meses não serão afetados. A partir de 9 de janeiro de 2021, o HDInsight bloqueará todos os clientes que criarem clusters usando tamanhos de VM standard_A8, standard_A9, standard_A10 e standard_A11. Clusters existentes serão executados integralmente. Considere a possibilidade de migrar para o HDInsight 4.0 para evitar a potencial interrupção do sistema/suporte.
Alterações de comportamento
Adicionar a verificação de regra NSG antes da operação de dimensionamento
O HDInsight adicionou NSGs (grupos de segurança de rede) e a verificação de rotas definidas pelo usuário (UDRs) com a operação de dimensionamento. A mesma validação é feita para o dimensionamento de cluster, além da criação do cluster. Essa validação ajuda a evitar erros imprevisíveis. Se a validação não for aprovada, o dimensionamento falhará. Saiba mais sobre como configurar o NSGs e o UDRs corretamente. Consulte endereços IP de gerenciamento do HDInsight.
Alteração na versão do componente
Nenhuma alteração de versão de componente para esta versão. Você pode encontrar as versões de componente atuais para o HDInsight 4.0 e HDInsight 3.6 aqui.
Data do lançamento: 09/11/2020
Esta versão se aplica ao HDInsight 3.6 e 4.0. A versão do HDInsight é disponibilizada para todas as regiões durante vários dias. A data de lançamento mostrada aqui indica a data de lançamento da primeira região. Caso as alterações a seguir não apareçam, aguarde alguns dias até que a versão esteja ativa em sua região.
Novos recursos
O Agente de Identidade do HDInsight (HIB) agora está disponível
O HIB (Agente de Identidade do HDInsight) que habilita a autenticação OAuth para clusters ESP agora está disponível com esta versão. Os clusters HIB criados após esta versão terão os recursos de HIB mais recentes:
- Alta disponibilidade (HA)
- Suporte para autenticação multifator (MFA)
- Usuários federados entram sem sincronização de hash de senha para AAD-DS para obter mais informações, consulte a documentação do HIB.
Migrar para Conjuntos de Dimensionamento de Máquinas Virtuais do Azure
O HDInsight atualmente usa máquinas virtuais do Azure para provisionar o cluster. A partir desta versão, o serviço migrará gradualmente para os conjuntos de dimensionamento de máquinas virtuais do Azure. Todo o processo pode levar meses. Depois que suas regiões e assinaturas forem migradas, os clusters do HDInsight recém-criados serão executados em conjuntos de dimensionamento de máquinas virtuais sem ações do cliente. Nenhuma alteração interruptiva é esperada.
Reprovação
Substituição do cluster do HDInsight 3.6 ML Services
O tipo de cluster de serviços do HDInsight 3.6 ML terá seu suporte encerrado em 31 de dezembro de 2020. Os clientes não criarão novos clusters ML Services 3.6 após 31 de dezembro de 2020. Os clusters existentes serão executados como estão, sem o suporte da Microsoft. Verifique a expiração do suporte para versões e tipos de cluster do HDInsight aqui.
Tamanhos de VM desabilitados
A partir de 16 de novembro de 2020, o HDInsight bloqueará novos clientes que criarem clusters usando tamanhos de VM standard_A8, standard_A9, standard_A10 e standard_A11. Os clientes que usaram esses tamanhos de VM nos últimos três meses não serão afetados. A partir de 9 de janeiro de 2021, o HDInsight bloqueará todos os clientes que criarem clusters usando tamanhos de VM standard_A8, standard_A9, standard_A10 e standard_A11. Clusters existentes serão executados integralmente. Considere a possibilidade de migrar para o HDInsight 4.0 para evitar a potencial interrupção do sistema/suporte.
Alterações de comportamento
Nenhuma alteração de comportamento para esta versão.
Alterações futuras
As alterações a seguir ocorrerão em versões futuras.
Capacidade de selecionar diferentes tamanhos de máquina virtual Zookeeper para serviços Spark, Hadoop e ML
Atualmente, o HDInsight não dá suporte à personalização do tamanho do nó Zookeeper para os tipos de cluster Spark, Hadoop e ML Services. O padrão são tamanhos de máquina virtual A2_v2/A2, que são fornecidos gratuitamente. Na próxima versão, você pode selecionar um tamanho de máquina virtual Zookeeper que seja mais apropriado para seu cenário. Os nós do Zookeeper com tamanho de máquina virtual diferente de A2_v2/A2 serão cobrados. As máquinas virtuais A2_v2 e A2 ainda são fornecidas gratuitamente.
A versão de cluster padrão será alterada para 4.0
A partir de fevereiro de 2021, a versão padrão do cluster HDInsight será alterada de 3.6 para 4.0. Para obter mais informações sobre as versões disponíveis, consulte versões com suporte. Saiba mais sobre o que há de novo no HDInsight 4.0
Fim do suporte do HDInsight 3.6 em 30 de junho de 2021
O HDInsight 3.6 terá seu suporte encerrado. A partir de 30 de junho de 2021, os clientes não poderão criar novos clusters HDInsight 3.6. Os clusters existentes serão executados como estão, sem o suporte da Microsoft. Considere a possibilidade de migrar para o HDInsight 4.0 para evitar a potencial interrupção do sistema/suporte.
Correções de bug
O HDInsight continua a fazer aprimoramentos de desempenho e confiabilidade do cluster.
Correção do problema para reiniciar as VMs no cluster
O problema para reiniciar as VMs no cluster foi corrigido. Você pode usar o PowerShell ou a API REST para reinicializar os nós no cluster novamente.
Alteração na versão do componente
Nenhuma alteração de versão de componente para esta versão. Você pode encontrar as versões de componente atuais para o HDInsight 4.0 e HDInsight 3.6 aqui.
Data do lançamento: 08/10/2020
Esta versão se aplica ao HDInsight 3.6 e 4.0. A versão do HDInsight é disponibilizada para todas as regiões durante vários dias. A data de lançamento mostrada aqui indica a data de lançamento da primeira região. Caso as alterações a seguir não apareçam, aguarde alguns dias até que a versão esteja ativa em sua região.
Novos recursos
Clusters privados do HDInsight sem IP público e link privado (pré-visualização)
O HDInsight agora dá suporte à criação de clusters sem IP público e acesso por link privado aos clusters na pré-visualização. Os clientes podem usar as novas configurações avançadas de rede para criar um cluster totalmente isolado sem IP público e usar seus próprios pontos de extremidade privados para acessar o cluster.
Migrar para Conjuntos de Dimensionamento de Máquinas Virtuais do Azure
O HDInsight atualmente usa máquinas virtuais do Azure para provisionar o cluster. A partir desta versão, o serviço migrará gradualmente para os conjuntos de dimensionamento de máquinas virtuais do Azure. Todo o processo pode levar meses. Depois que suas regiões e assinaturas forem migradas, os clusters do HDInsight recém-criados serão executados em conjuntos de dimensionamento de máquinas virtuais sem ações do cliente. Nenhuma alteração interruptiva é esperada.
Reprovação
Substituição do cluster do HDInsight 3.6 ML Services
O tipo de cluster HDInsight 3.6 ML Services terá seu suporte suspenso em 31 de dezembro de 2020. Os clientes não criarão novos clusters 3.6 ML Services depois dessa data. Os clusters existentes serão executados como estão, sem o suporte da Microsoft. Verifique a expiração do suporte para versões e tipos de cluster do HDInsight aqui.
Alterações de comportamento
Nenhuma alteração de comportamento para esta versão.
Alterações futuras
As alterações a seguir ocorrerão em versões futuras.
Capacidade de selecionar diferentes tamanhos de máquina virtual Zookeeper para serviços Spark, Hadoop e ML
Atualmente, o HDInsight não dá suporte à personalização do tamanho do nó Zookeeper para os tipos de cluster Spark, Hadoop e ML Services. O padrão são tamanhos de máquina virtual A2_v2/A2, que são fornecidos gratuitamente. Na próxima versão, você pode selecionar um tamanho de máquina virtual Zookeeper que seja mais apropriado para seu cenário. Os nós do Zookeeper com tamanho de máquina virtual diferente de A2_v2/A2 serão cobrados. As máquinas virtuais A2_v2 e A2 ainda são fornecidas gratuitamente.
Correções de bug
O HDInsight continua a fazer aprimoramentos de desempenho e confiabilidade do cluster.
Alteração na versão do componente
Nenhuma alteração de versão de componente para esta versão. Você pode encontrar as versões de componente atuais para o HDInsight 4.0 e HDInsight 3.6 aqui.
Data do lançamento: 28/09/2020
Esta versão se aplica ao HDInsight 3.6 e 4.0. A versão do HDInsight é disponibilizada para todas as regiões durante vários dias. A data de lançamento mostrada aqui indica a data de lançamento da primeira região. Caso as alterações a seguir não apareçam, aguarde alguns dias até que a versão esteja ativa em sua região.
Novos recursos
O dimensionamento automático para consulta interativa com o HDInsight 4.0 já está disponível para o público geral
O dimensionamento automático para o tipo de cluster de consulta interativa agora é geral disponível (GA) para o HDInsight 4.0. Todos os clusters de consulta interativa 4.0 criados após 27 de agosto de 2020 terão suporte de GA para dimensionamento automático.
O cluster HBase dá suporte a ADLS Gen2 Premium
O HDInsight agora dá suporte ao ADLS Gen2 Premium como conta de armazenamento principal para clusters HDInsight HBase 3.6 e 4.0. Junto com as Gravações Aceleradas, você pode obter um melhor desempenho para seus clusters HBase.
Distribuição de partição do Kafka em domínios de falha do Azure
Um domínio de falha é um agrupamento lógico de hardware subjacente em um data center do Azure. Cada domínio de falha tem um comutador de rede e uma fonte de alimentação em comum. O HDInsight Kafka pode antes armazenar todas as réplicas da partição no mesmo domínio de falha. A partir desta versão, o HDInsight agora dá suporte à distribuição automática de partições Kafka com base em domínios de falha do Azure.
Criptografia em trânsito
Os clientes podem habilitar a criptografia em trânsito entre os nós de cluster usando a criptografia IPsec com chaves gerenciadas por plataforma. Essa opção pode ser habilitada no momento da criação do cluster. Veja mais detalhes sobre como habilitar a criptografia em trânsito.
Criptografia no host
Quando você habilita a criptografia no host, os dados armazenados no host da VM são criptografados inativo e os fluxos são criptografados para o serviço de armazenamento. A partir desta versão, é possível habilitar a criptografia no disco de dados temporário ao criar o cluster. A criptografia no host só tem suporte em determinados SKUs de VM em regiões limitadas. O HDInsight dá suporte à seguinte configuração de nó e SKUs. Veja mais detalhes sobre como habilitar a criptografia no host.
Migrar para Conjuntos de Dimensionamento de Máquinas Virtuais do Azure
O HDInsight atualmente usa máquinas virtuais do Azure para provisionar o cluster. A partir desta versão, o serviço migrará gradualmente para os conjuntos de dimensionamento de máquinas virtuais do Azure. Todo o processo pode levar meses. Depois que suas regiões e assinaturas forem migradas, os clusters do HDInsight recém-criados serão executados em conjuntos de dimensionamento de máquinas virtuais sem ações do cliente. Nenhuma alteração interruptiva é esperada.
Reprovação
Nenhuma desativação para esta versão.
Alterações de comportamento
Nenhuma alteração de comportamento para esta versão.
Alterações futuras
As alterações a seguir ocorrerão em versões futuras.
Capacidade de selecionar um SKU Zookeeper diferente para os serviços Spark, Hadoop e ML
Atualmente, o HDInsight não dá suporte à alteração de SKU Zookeeper para tipos de cluster Spark, Hadoop e ML Services. Ele usa A2_v2 SKU/A2 para nós Zookeeper e os clientes não são cobrados por eles. Na próxima versão, os clientes podem alterar o Zookeeper SKU para os serviços Spark, Hadoop e ML, conforme necessário. Nós Zookeeper com SKU diferente de A2_v2/A2 serão cobrados. O SKU padrão ainda será A2_V2/A2 e sem encargos.
Correções de bug
O HDInsight continua a fazer aprimoramentos de desempenho e confiabilidade do cluster.
Alteração na versão do componente
Nenhuma alteração de versão de componente para esta versão. Você pode encontrar as versões de componente atuais para o HDInsight 4.0 e HDInsight 3.6 aqui.
Data do lançamento: 09/08/2020
Esta versão se aplica apenas ao HDInsight 4.0. A versão do HDInsight é disponibilizada para todas as regiões durante vários dias. A data de lançamento mostrada aqui indica a data de lançamento da primeira região. Caso as alterações a seguir não apareçam, aguarde alguns dias até que a versão esteja ativa em sua região.
Novos recursos
Suporte ao SparkCruise
SparkCruise é um sistema de reutilização de computação automática para Spark. Ele seleciona subexpressões comuns para materializar com base na carga de trabalho da consulta anterior. O SparkCruise materializa essas subexpressões como parte do processamento de consulta e a reutilização de computação é aplicada automaticamente em segundo plano. Você pode se beneficiar do SparkCruise sem nenhuma modificação no código do Spark.
Suporte Hive View para HDInsight 4.0
A Exibição do Hive do Apache Ambari foi projetada para ajudá-lo a criar, otimizar e executar consultas do hive a partir do seu navegador da Web. A Exibição do Hive tem suporte nativo para clusters HDInsight 4.0 a partir desta versão. Ele não se aplica a clusters existentes. Você precisa remover e recriar o cluster para obter a exibição interna do Hive.
Suporte à exibição do tez para o HDInsight 4.0
O Apache Tez View é usado para rastrear e depurar a execução do trabalho do Hive Tez. O Tez View tem suporte nativo para o HDInsight 4.0 a partir desta versão. Ele não se aplica a clusters existentes. Você precisa remover e recriar o cluster para obter a exibição Tez interna.
Reprovação
Substituição do Spark 2.1 e 2.2 no cluster do Spark do HDInsight 3.6
Desde 1º de julho de 2020, os clientes não podem criar clusters Spark com Spark 2.1 e 2.2 no HDInsight 3.6. Os clusters existentes serão executados como estão, sem o suporte da Microsoft. Considere a possibilidade de migrar para o Spark 2.3 no HDInsight 3.6 até 30 de junho de 2020 para evitar a interrupção potencial do sistema/suporte.
Substituição do Spark 2.3 no cluster do Spark do HDInsight 4.0
Desde 1º de julho de 2020, os clientes não podem criar clusters Spark com o Spark 2.3 no HDInsight 4.0. Os clusters existentes serão executados como estão, sem o suporte da Microsoft. Considere a possibilidade de migrar para o Spark 2.4 no HDInsight 4.0 até 30 de junho de 2020 para evitar a interrupção potencial do sistema/suporte.
Substituição do Kafka 1.1 no cluster Kafka do HDInsight 4.0
Desde 1º de julho de 2020, os clientes não podem criar clusters Kafka com Kafka 1.1 no HDInsight 4.0. Os clusters existentes serão executados como estão, sem o suporte da Microsoft. Considere a possibilidade de migrar para o Kafka 2.1 no HDInsight 4.0 até 30 de junho de 2020 para evitar a interrupção potencial do sistema/suporte.
Alterações de comportamento
Alteração da versão de pilha do Ambari
Nesta versão, a versão Ambari muda de 2. x. x para 4.1. A versão stack pode ser verificada (HDInsight 4.1) em Ambari: Ambari > User > Versions.
Alterações futuras
Não há alterações futuras nais quais é necessário prestar atenção.
Correções de bug
O HDInsight continua a fazer aprimoramentos de desempenho e confiabilidade do cluster.
Abaixo, os JIRAs são portados de volta para o Hive:
Abaixo, os JIRAs são portados de volta para o HBase:
Alteração na versão do componente
Nenhuma alteração de versão de componente para esta versão. Você pode encontrar as versões de componente atuais para o HDInsight 4.0 e HDInsight 3.6 aqui.
Problemas conhecidos
Um problema foi corrigido no portal do Azure. Os usuários recebiam um erro ao criar um cluster do Azure HDInsight usando um tipo de autenticação SSH de chave pública. Quando os usuários clicavam em Examinar + Criar, recebiam o erro "Não pode conter três caracteres consecutivos do nome de usuário do SSH". Esse problema foi corrigido, mas pode ser necessário atualizar o cache do navegador clicando em CTRL + F5 para carregar a exibição corrigida. A solução alternativa para esse problema era criar um cluster com um modelo do Resource Manager.
Data do lançamento: 13/07/2020
Esta versão se aplica tanto ao HDInsight 3.6 quanto ao 4.0. A versão do HDInsight é disponibilizada para todas as regiões durante vários dias. A data de lançamento mostrada aqui indica a data de lançamento da primeira região. Caso as alterações a seguir não apareçam, aguarde alguns dias até que a versão esteja ativa em sua região.
Novos recursos
Sistema de Proteção de Dados do Cliente para Microsoft Azure
O Azure HDInsight agora dá suporte ao Sistema de Proteção de Dados do Cliente do Azure. Ele fornece interface para que os clientes revisem e aprovem ou rejeitem as solicitações de acesso a dados do cliente. O HDInsight é usado quando um engenheiro da Microsoft precisa acessar os dados do cliente durante uma solicitação de suporte. Para obter mais informações, consulte Sistema de Proteção de Dados do Cliente para Microsoft Azure.
Políticas de ponto de extremidade de serviço para armazenamento
Agora, os clientes podem usar as políticas de ponto de extremidade de serviço (SEP) na sub-rede do cluster HDInsight. Saiba mais sobre a política de ponto de extremidade de serviço do Azure.
Reprovação
Substituição do Spark 2.1 e 2.2 no cluster do Spark do HDInsight 3.6
Desde 1º de julho de 2020, os clientes não podem criar clusters Spark com Spark 2.1 e 2.2 no HDInsight 3.6. Os clusters existentes serão executados como estão, sem o suporte da Microsoft. Considere a possibilidade de migrar para o Spark 2.3 no HDInsight 3.6 até 30 de junho de 2020 para evitar a interrupção potencial do sistema/suporte.
Substituição do Spark 2.3 no cluster do Spark do HDInsight 4.0
Desde 1º de julho de 2020, os clientes não podem criar clusters Spark com o Spark 2.3 no HDInsight 4.0. Os clusters existentes serão executados como estão, sem o suporte da Microsoft. Considere a possibilidade de migrar para o Spark 2.4 no HDInsight 4.0 até 30 de junho de 2020 para evitar a interrupção potencial do sistema/suporte.
Substituição do Kafka 1.1 no cluster Kafka do HDInsight 4.0
Desde 1º de julho de 2020, os clientes não podem criar clusters Kafka com Kafka 1.1 no HDInsight 4.0. Os clusters existentes serão executados como estão, sem o suporte da Microsoft. Considere a possibilidade de migrar para o Kafka 2.1 no HDInsight 4.0 até 30 de junho de 2020 para evitar a interrupção potencial do sistema/suporte.
Alterações de comportamento
Nenhuma alteração de comportamento na qual seja necessário prestar atenção.
Alterações futuras
As alterações a seguir ocorrerão em versões futuras.
Capacidade de selecionar um SKU Zookeeper diferente para os serviços Spark, Hadoop e ML
Atualmente, o HDInsight não dá suporte à alteração de SKU Zookeeper para tipos de cluster Spark, Hadoop e ML Services. Ele usa A2_v2 SKU/A2 para nós Zookeeper e os clientes não são cobrados por eles. Na próxima versão, os clientes poderão alterar Zookeeper SKU para os serviços Spark, Hadoop e ML, conforme necessário. Nós Zookeeper com SKU diferente de A2_v2/A2 serão cobrados. O SKU padrão ainda será A2_V2/A2 e sem encargos.
Correções de bug
O HDInsight continua a fazer aprimoramentos de desempenho e confiabilidade do cluster.
Correção do problema de Hive Warehouse Connector
Houve um problema para a usabilidade do conector do depósito do Hive na versão anterior. Esse problema foi corrigido.
O notebook Zeppelin fixo trunca o problema de zeros à esquerda
O Zeppelin estava truncando incorretamente os zeros à esquerda na saída da tabela para o formato da cadeia de caracteres. Corrigimos esse problema nesta versão.
Alteração na versão do componente
Nenhuma alteração de versão de componente para esta versão. Você pode encontrar as versões de componente atuais para o HDInsight 4.0 e HDInsight 3.6 aqui.
Data do lançamento: 11/06/2020
Esta versão se aplica tanto ao HDInsight 3.6 quanto ao 4.0. A versão do HDInsight é disponibilizada para todas as regiões durante vários dias. A data de lançamento mostrada aqui indica a data de lançamento da primeira região. Caso as alterações a seguir não apareçam, aguarde alguns dias até que a versão esteja ativa em sua região.
Novos recursos
Migrar para Conjuntos de Dimensionamento de Máquinas Virtuais do Azure
O HDInsight atualmente usa máquinas virtuais do Azure para provisionar o cluster. Nesta versão, os clusters HDInsight recém-criados começam a usar o conjunto de dimensionamento de máquinas virtuais do Azure. A alteração está sendo distribuída gradualmente. Não é esperada nenhuma alteração significativa. Saiba mais sobre os Conjuntos de Dimensionamento de Máquinas Virtuais do Azure.
Reinicializar VMs no cluster HDInsight
Nesta versão, damos suporte à reinicialização de VMs no cluster HDInsight para reinicializar nós sem resposta. Atualmente, só é possível fazer isso por meio da API. O PowerShell e o suporte à CLI estão a caminho. Para obter mais informações sobre API, confira este documento.
Reprovação
Substituição do Spark 2.1 e 2.2 no cluster do Spark do HDInsight 3.6
Desde 1º de julho de 2020, os clientes não podem criar clusters Spark com Spark 2.1 e 2.2 no HDInsight 3.6. Os clusters existentes serão executados como estão, sem o suporte da Microsoft. Considere a possibilidade de migrar para o Spark 2.3 no HDInsight 3.6 até 30 de junho de 2020 para evitar a interrupção potencial do sistema/suporte.
Substituição do Spark 2.3 no cluster do Spark do HDInsight 4.0
Desde 1º de julho de 2020, os clientes não podem criar clusters Spark com o Spark 2.3 no HDInsight 4.0. Os clusters existentes serão executados como estão, sem o suporte da Microsoft. Considere a possibilidade de migrar para o Spark 2.4 no HDInsight 4.0 até 30 de junho de 2020 para evitar a interrupção potencial do sistema/suporte.
Substituição do Kafka 1.1 no cluster Kafka do HDInsight 4.0
Desde 1º de julho de 2020, os clientes não podem criar clusters Kafka com Kafka 1.1 no HDInsight 4.0. Os clusters existentes serão executados como estão, sem o suporte da Microsoft. Considere a possibilidade de migrar para o Kafka 2.1 no HDInsight 4.0 até 30 de junho de 2020 para evitar a interrupção potencial do sistema/suporte.
Alterações de comportamento
Alteração do tamanho do nó de cluster do Spark do ESP
O tamanho mínimo permitido do nó de cabeçalho para o cluster do Spark do ESP é alterado para Standard_D13_V2. As VMs com poucos núcleos e memória como nó de cabeçalho podem causar problemas de cluster ESP devido à capacidade relativamente baixa de CPU e memória. AA partir do lançamento, use SKUs maiores que Standard_D13_V2 e Standard_E16_V3 como nó de cabeçalho para clusters do Spark do ESP.
Uma VM de quatro núcleos mínima é necessária para o nó de cabeçalho
Uma VM de quatro núcleos mínima é necessária para o nó de cabeçalho para garantir a alta disponibilidade e a confiabilidade dos clusters do HDInsight. A partir de 6 de abril de 2020, os clientes podem escolher apenas a VM de quatro núcleos ou mais como nó principal para os novos clusters HDInsight. Os clusters existentes continuarão a ser executados conforme o esperado.
Alteração de provisionamento de nó de trabalho do cluster
Quando 80% dos nós de trabalho estiverem prontos, o cluster entrará no estágio operacional. Nesse estágio, os clientes podem fazer todas as operações do plano de dados, como executar scripts e trabalhos. Mas os clientes não podem realizar nenhuma operação de plano de controle, como dimensionar/reduzir verticalmente. Suporte apenas para exclusão.
Após o estágio operacional, o cluster aguardará outros 60 minutos para os 20% nós de trabalho restantes. Ao final desses 60 minutos, o cluster se moverá para o estágio em execução, mesmo que todos os nós de trabalho ainda não estejam disponíveis. Depois que um cluster entra no estágio em execução, você pode usá-lo como de costume. Ambas as operações do plano de controle, como expansão/redução, e operações de plano de dados como executar scripts e trabalhos são aceitas. Se alguns dos nós de trabalho solicitados não estiverem disponíveis, o cluster será marcado como sucesso parcial. Os nós que foram implantados com êxito serão cobrados.
Criar nova entidade de serviço por meio do HDInsight
Anteriormente, com a criação do cluster, os clientes podem criar uma nova entidade de serviço para acessar a conta do ADLS Gen 1 conectada no portal do Azure. A partir de 15 de junho de 2020, a criação de uma nova entidade de serviço não será possível no fluxo de trabalho de criação do HDInsight, somente as entidades de serviço existentes terão suporte. Consulte criar entidade de serviço e certificados usando Azure Active Directory.
Tempo limite para ações de script com a criação do cluster
O HDInsight dá suporte à execução de ações de script com a criação do cluster. A partir dessa versão, todas as ações de script com criação de cluster precisam ser concluídas dentro de 60 minutos, ou irão atingir o tempo limite. As ações de script enviadas aos clusters em execução não serão afetadas. Veja mais detalhes aqui.
Alterações futuras
Não há alterações futuras nais quais é necessário prestar atenção.
Correções de bug
O HDInsight continua a fazer aprimoramentos de desempenho e confiabilidade do cluster.
Alteração na versão do componente
HBase 2.0 para 2.1.6
A versão HBase foi atualizada da versão 2.0 para a versão 2.1.6.
Spark 2.4.0 para 2.4.4
A versão Spark foi atualizada da versão 2.4.0 para a versão 2.4.4.
Kafka 2.1.0 para 2.1.1
A versão Kafka foi atualizada da versão 2.1.0 para a versão 2.1.1.
Você pode encontrar as versões de componente atuais para o HDInsight 4.0 e HDInsight 3.6 aqui
Problemas conhecidos
Problema do Hive Warehouse Connector
Há um problema nesta versão do Hive Warehouse Connector. A correção será incluída na próxima versão. Os clusters existentes criados antes dessa versão não serão afetados. Evite remover e recriar o cluster, se possível. Se for necessário obter mais ajuda sobre isso, abra o ticket de suporte.
Data de lançamento: 09/01/2020
Esta versão se aplica tanto ao HDInsight 3.6 quanto ao 4.0. A versão do HDInsight é disponibilizada para todas as regiões durante vários dias. A data de lançamento mostrada aqui indica a data de lançamento da primeira região. Caso as alterações a seguir não apareçam, aguarde alguns dias até que a versão esteja ativa em sua região.
Novos recursos
Imposição do TLS 1.2
Os protocolos TLS e SSL são protocolos criptográficos que fornecem segurança de comunicações em uma rede de computadores. Saiba mais sobre o TLS. O HDInsight usa o TLS 1.2 em pontos de extremidade HTTPs públicos, mas o TLS 1.1 ainda é compatível com versões anteriores.
Com esta versão, os clientes podem optar pelo TLS 1.2 apenas para todas as conexões por meio do ponto de extremidade do cluster público. Para dar suporte a isso, a nova propriedade minSupportedTlsVersion é introduzida e pode ser especificada durante a criação do cluster. Se a propriedade não estiver definida, o cluster ainda dará suporte a TLS 1.0, 1.1 e 1.2, que é o mesmo que o comportamento atual. Os clientes podem definir o valor dessa propriedade como "1.2", o que significa que o cluster só é compatível com TLS 1.2 e superior. Para obter mais informações, confira Protocolo TLS.
Bring Your Own Key para criptografia de disco
Todos os discos gerenciados no HDInsight são protegidos com o SSE (Criptografia do Serviço de Armazenamento) do Azure. Por padrão, os dados nesses discos são criptografados usando chaves gerenciadas pela Microsoft. Nesta versão e nas posteriores, você pode usar a criptografia de disco BYOK (Bring Your Own Key) e gerenciá-la usando o Azure Key Vault. A criptografia BYOK é uma configuração de uma etapa durante a criação do cluster sem nenhum outro custo. Basta registrar o HDInsight como uma identidade gerenciada com o Azure Key Vault e adicionar a chave de criptografia ao criar o cluster. Para obter mais informações, confira Criptografia de disco de chave gerenciada pelo cliente.
Reprovação
Nenhuma desativação para esta versão. Para se preparar para desativações futuras, confira Alterações futuras.
Alterações de comportamento
Nenhuma alteração de comportamento para esta versão. Para se preparar para alterações futuras, confira Alterações futuras.
Alterações futuras
As alterações a seguir ocorrerão em versões futuras.
Substituição do Spark 2.1 e 2.2 no cluster do Spark do HDInsight 3.6
Desde 1º de julho de 2020, os clientes não podem criar clusters Spark com Spark 2.1 e 2.2 no HDInsight 3.6. Os clusters existentes serão executados como estão, sem suporte da Microsoft. Considere a possibilidade de migrar para o Spark 2.3 no HDInsight 3.6 até 30 de junho de 2020 para evitar a interrupção potencial do sistema/suporte.
Substituição do Spark 2.3 no cluster do Spark do HDInsight 4.0
Desde 1º de julho de 2020, os clientes não podem criar clusters Spark com Spark 2.3 no HDInsight 4.0. Os clusters existentes serão executados como estão, sem suporte da Microsoft. Considere a possibilidade de migrar para o Spark 2.4 no HDInsight 4.0 até 30 de junho de 2020 para evitar a interrupção potencial do sistema/suporte.
Substituição do Kafka 1.1 no cluster Kafka do HDInsight 4.0
Desde 1º de julho de 2020, os clientes não podem criar clusters Kafka com Kafka 1.1 no HDInsight 4.0. Os clusters existentes serão executados como estão, sem suporte da Microsoft. Considere a possibilidade de migrar para o Kafka 2.1 no HDInsight 4.0 até 30 de junho de 2020 para evitar a interrupção potencial do sistema/suporte. Para obter mais informações, consulte Migrar cargas de trabalho de Apache Kafka para o Azure HDInsight 4,0.
HBase 2.0 para 2.1.6
Na próxima versão do HDInsight 4.0, a versão do HBase será atualizada da versão 2.0 para a 2.1.6
Spark 2.4.0 para 2.4.4
Na próxima versão do HDInsight 4.0, a versão do Spark será atualizada da versão 2.4.0 para a 2.4.4
Kafka 2.1.0 para 2.1.1
Na próxima versão do HDInsight 4.0, a versão do Kafka será atualizada da versão 2.1.0 para a 2.1.1
Uma VM de quatro núcleos mínima é necessária para o nó de cabeçalho
Uma VM de quatro núcleos mínima é necessária para o nó de cabeçalho para garantir a alta disponibilidade e a confiabilidade dos clusters do HDInsight. A partir de 6 de abril de 2020, os clientes podem escolher apenas a VM de quatro núcleos ou mais como nó principal para os novos clusters HDInsight. Os clusters existentes continuarão a ser executados conforme o esperado.
Alteração do tamanho do nó de cluster do Spark do ESP
Na próxima versão, o tamanho mínimo de nó permitido para o cluster do Spark do ESP será alterado para Standard_D13_V2. As VMs da série A podem causar problemas de cluster do ESP devido à capacidade relativamente baixa de CPU e de memória. As VMs da série A serão preteridas para a criação de clusters do ESP.
Migrar para Conjuntos de Dimensionamento de Máquinas Virtuais do Azure
O HDInsight atualmente usa máquinas virtuais do Azure para provisionar o cluster. Na próxima versão, em vez disso, o HDInsight usará os Conjuntos de Dimensionamento de Máquinas Virtuais do Azure. Saiba mais sobre os Conjuntos de Dimensionamento de Máquinas Virtuais do Azure.
Correções de bug
O HDInsight continua a fazer aprimoramentos de desempenho e confiabilidade do cluster.
Alteração na versão do componente
Nenhuma alteração de versão de componente para esta versão. Você pode encontrar as versões de componente atuais para o HDInsight 4.0 e HDInsight 3.6 aqui.
Data do lançamento: 17/12/2019
Esta versão se aplica tanto ao HDInsight 3.6 quanto ao 4.0.
Novos recursos
Marcas de serviço
As marcas de serviço simplificam a segurança para máquinas virtuais do Azure e redes virtuais do Azure, permitindo restringir facilmente o acesso à rede para os serviços do Azure. É possível usar marcas de serviço em suas regras de NSG (grupo de segurança de rede) para permitir ou negar o tráfego para um serviço específico do Azure globalmente ou por região do Azure. O Azure fornece a manutenção de endereços IP subjacentes a cada marca. As marcas de serviço do HDInsight para NSGs (grupos de segurança de rede) são grupos de endereços IP para serviços de integridade e gerenciamento. Esses grupos ajudam a minimizar a complexidade para a criação de regras de segurança. Os clientes do HDInsight podem habilitar a marca de serviço por meio do portal do Azure, do PowerShell e da API REST. Para obter mais informações, veja Marcas de serviço do grupo de segurança de rede (NSG) para o Azure HDInsight.
BD Ambari personalizado
O HDInsight agora permite que você use seu próprio BD SQL para Apache Ambari. É possível configurar esse Ambari DB personalizado no portal do Azure ou por meio do modelo do Resource Manager. Esse recurso permite escolher o BD SQL correto para suas necessidades de processamento e capacidade. Também é possível fazer upgrade facilmente para atender aos requisitos de crescimento de negócios. Para mais informações, consulte Configurar clusters do HDInsight com um AMBARI DB personalizado.

Reprovação
Nenhuma desativação para esta versão. Para se preparar para desativações futuras, confira Alterações futuras.
Alterações de comportamento
Nenhuma alteração de comportamento para esta versão. Para se preparar para alterações de comportamento futuras, confira Alterações futuras.
Alterações futuras
As alterações a seguir ocorrerão em versões futuras.
Protocolo TLS 1.2
Os protocolos TLS e SSL são protocolos criptográficos que fornecem segurança de comunicações em uma rede de computadores. Para obter mais informações, confira Protocolo TLS. Embora os clusters do Azure HDInsight aceitem conexões TLS 1.2 em pontos de extremidade HTTPS públicos, o TLS 1.1 ainda possui suporte para compatibilidade com versões anteriores de clientes mais antigos.
A partir da próxima versão, você poderá optar por aceitar e configurar seus novos clusters do HDInsight para apenas as conexões TLS 1.2.
Posteriormente no ano, a partir de 30/6/2020, o Azure HDInsight impedirá o TLS 1.2 ou versões posteriores para todas as conexões HTTPS. Recomendamos que verifique se todos os seus clientes estão prontos para lidar com o TLS 1.2 ou versões posteriores.
Migrar para Conjuntos de Dimensionamento de Máquinas Virtuais do Azure
O HDInsight atualmente usa máquinas virtuais do Azure para provisionar o cluster. A partir de fevereiro de 2020 (a data exata será comunicada posteriormente), o HDInsight usará os conjuntos de dimensionamento de máquinas virtuais do Azure. Saiba mais sobre os Conjuntos de Dimensionamento de Máquinas Virtuais do Azure.
Alteração do tamanho do nó de cluster do Spark do ESP
Na próxima versão:
- Na próxima versão, o tamanho mínimo de nó permitido para o cluster do Spark do ESP será alterado para Standard_D13_V2.
- As VMs da série serão preteridas para a criação de novos clusters ESP, pois as VMs da série A podem causar problemas de cluster ESP devido a uma capacidade relativamente baixa de CPU e memória.
HBase 2.0 para 2.1
Na próxima versão do HDInsight 4.0, a versão do HBase será atualizada da versão 2.0 para a 2.1.
Correções de bug
O HDInsight continua a fazer aprimoramentos de desempenho e confiabilidade do cluster.
Alteração na versão do componente
Ampliamos o suporte do HDInsight 3.6 para 31 de dezembro de 2020. Você pode encontrar mais detalhes em Versões HDInsight com suporte .
Nenhuma alteração de versão de componente para o HDInsight 4.0.
Apache Zeppelin em HDInsight 3.6: 0.7.0-->0.7.3.
É possível encontrar as versões de componente mais atualizadas deste documento.
Novas regiões
Norte dos EAU
Os IPs de gerenciamento do Norte dos EAU são: 65.52.252.96 e 65.52.252.97.
Data do lançamento: 07/11/2019
Esta versão se aplica tanto ao HDInsight 3.6 quanto ao 4.0.
Novos recursos
Integrar com o (HIB) Agente de Identidade do HDInsight (visualização)
O HIB (Agente de Identidade do HDInsight) permite que os usuários entrem no Apache Ambari usando a autenticação multifator (MFA) e obtenham os tíquetes Kerberos necessários sem precisar de hashes de senha no Azure Active Directory Domain Services (AAD-DS). Atualmente, o HIB só está disponível para clusters implantados por meio do modelo ARM (gerenciamento de recursos do Azure).
Proxy da API REST do Kafka (versão prévia)
O Proxy da API REST do Kafka fornece uma implantação de um único clique do proxy REST altamente disponível com o cluster Kafka por meio da autorização e do protocolo OAuth protegidos do Azure AD.
Escala automática
O dimensionamento automático para o Azure HDInsight agora está disponível em todas as regiões para tipos de cluster Apache Spark e Hadoop. Esse recurso possibilita o gerenciamento de cargas de trabalho de análise de Big Data de forma mais econômica e produtiva. Agora é possível otimizar o uso de seus clusters HDInsight e pagar apenas pelo que precisa.
Dependendo dos seus requisitos, é possível escolher entre dimensionamento automático baseado em carga e com base em agendamento. O dimensionamento automático baseado em carga pode dimensionar o tamanho do cluster para cima e para baixo com base nas necessidades do recurso atual, enquanto o dimensionamento automático baseado em agenda pode alterar o tamanho do cluster com base em uma agenda predefinida.
O suporte a dimensionamento automático para a carga de trabalho do HBase e do LLAP também é visualização pública. Para obter mais informações, consulte Dimensionar automaticamente clusters do Azure HDInsight.
Gravações aceleradas do Azure HDInsight para Apache HBase
As gravações aceleradas usam discos gerenciados do SSD premium do Azure para melhorar o desempenho do log de gravação antecipada do Apache HBase (WAL). Para obter mais informações, consulte Gravações aceleradas do Azure HDInsight para o Apache HBase.
BD Ambari personalizado
O HDInsight agora oferece uma nova capacidade para permitir que os clientes usem seu próprio BD SQL para Ambari. Agora, os clientes podem escolher o BD SQL correto para Ambari e atualizá-lo facilmente com base em seu próprio requisito de crescimento de negócios. Implantar uma ferramenta de gerenciamento com um modelo do Azure Resource Manager. Para obter mais informações, consulte Configurar clusters do HDInsight com um AMBARI DB personalizado.
As máquinas virtuais da série F agora estão disponíveis com o HDInsight
As VMs (máquinas virtuais) da série F são boas opções para começar com o HDInsight com requisitos leves de processamento. A um preço de lista inferior por hora, a série F é o melhor valor de preço/desempenho no portfólio do Azure com base na ACU (Unidade de Computação do Azure) por vCPU. Para obter mais informações, consulte Selecionando o tamanho correto da VM para o cluster HDInsight do Azure.
Reprovação
Substituição da máquina virtual da série G
Nesta versão, as VMs da série G não são mais oferecidas no HDInsight.
Descontinuação de máquinas virtuais Dv1
A partir desta versão, o uso de VMs Dv1 com o HDInsight está preterido. Qualquer solicitação do cliente do Dv1 será atendida pelo Dv2 automaticamente. Não há diferença de preço entre as VMs Dv1 e Dv2.
Alterações de comportamento
Alteração do tamanho do disco gerenciado do cluster
O HDInsight fornece o espaço em disco gerenciado com o cluster. A partir desta versão, o tamanho do disco gerenciado de cada nó no novo cluster criado é alterado para 128 GB.
Alterações futuras
As alterações a seguir serão aplicadas nas versões futuras.
Migrar para Conjuntos de Dimensionamento de Máquinas Virtuais do Azure
O HDInsight atualmente usa máquinas virtuais do Azure para provisionar o cluster. A partir de dezembro, o HDInsight usará os conjuntos de dimensionamento de máquinas virtuais do Azure em vez disso. Saiba mais sobre os Conjuntos de Dimensionamento de Máquinas Virtuais do Azure.
HBase 2.0 para 2.1
Na próxima versão do HDInsight 4.0, a versão do HBase será atualizada da versão 2.0 para a 2.1.
Reprovação de máquina virtual de série A para cluster ESP
As VMs da série A podem causar problemas de cluster do ESP devido à capacidade relativamente baixa de CPU e de memória. No próximo lançamento, as VMs da série A serão preteridas para a criação de clusters do ESP.
Correções de bug
O HDInsight continua a fazer aprimoramentos de desempenho e confiabilidade do cluster.
Alteração na versão do componente
Não há nenhuma alteração de versão de componente para esta versão. Você pode encontrar as versões de componente atuais para o HDInsight 4.0 e HDInsight 3.6 aqui.
Data do lançamento: 07/08/2019
Versões do componente
As versões do Apache oficiais de todos os componentes do HDInsight 4.0 estão listadas abaixo. Os componentes listados são versões das versões estáveis mais recentes disponíveis.
- Apache Ambari 2.7.1
- Apache Hadoop 3.1.1
- Apache HBase 2.0.0
- Apache Hive 3.1.0
- Apache Kafka 1.1.1, 2.1.0
- Apache Mahout 0.9.0+
- Apache Oozie 4.2.0
- Apache Phoenix 4.7.0
- Apache Pig 0.16.0
- Apache Ranger 0.7.0
- Apache Slider 0.92.0
- Apache Spark 2.3.1, 2.4.0
- Apache Sqoop 1.4.7
- Apache TEZ 0.9.1
- Apache Zeppelin 0.8.0
- Apache ZooKeeper 3.4.6
As versões posteriores dos componentes do Apache, às vezes, são agrupadas na distribuição HDP, além das versões listadas acima. Nesse caso, as versões posteriores estão listadas na tabela de Versões Técnicas e não devem substituir as versões do componente Apache da lista acima em um ambiente de produção.
Informações de patch do Apache
Para obter mais informações sobre os patches disponíveis no HDInsight 4.0, consulte a lista de patches para cada produto na tabela abaixo.
| Nome do produto | Informações de patch |
|---|---|
| Ambari | Informações de patch do Apache |
| O Hadoop | Informações de patch do Hadoop |
| HBase | Informações de patch do HBase |
| Hive | Essa versão fornece o Hive 3.1.0 sem mais patches do Apache. |
| Kafka | Essa versão fornece o Kafka 1.1.1 sem mais patches do Apache. |
| Oozie | Informações de patch do Oozie |
| Phoenix | Informações de patch do Phoenix |
| Pig | Informações de patch do Pig |
| Ranger | Informações de patch do Ranger |
| Spark | Informações de patch do Spark |
| Sqoop | Essa versão fornece o Sqoop 1.4.7 sem mais patches do Apache. |
| Tez | Essa versão fornece o Tez 0.9.1 sem mais patches do Apache. |
| Zeppelin | Essa versão fornece o Zeppelin 0.8.0 sem mais patches do Apache. |
| Zookeeper | Informações de patch do Zookeeper |
Common Vulnerabilities e Exposures Corrigidos
Para obter mais informações sobre os problemas de segurança resolvidos nesta versão, consulte Hortonworks' Fixed Common Vulnerabilities and Exposures for HDP 3.0.1.
Problemas conhecidos
A replicação foi interrompida para o HBase seguro com instalação padrão
Para o HDInsight 4.0, execute as seguintes etapas:
Habilite a comunicação entre clusters.
Entre no cabeçalho ativo.
Baixe um script para habilitar a replicação com o seguinte comando:
sudo wget https://raw.githubusercontent.com/Azure/hbase-utils/master/replication/hdi_enable_replication.shDigite o comando
sudo kinit <domainuser>.Digite o comando a seguir para executar o script:
sudo bash hdi_enable_replication.sh -m <hn*> -s <srclusterdns> -d <dstclusterdns> -sp <srcclusterpasswd> -dp <dstclusterpasswd> -copydata
Para HDInsight 3.6
Entre no Active HMaster ZK.
Baixe um script para habilitar a replicação com o seguinte comando:
sudo wget https://raw.githubusercontent.com/Azure/hbase-utils/master/replication/hdi_enable_replication.shDigite o comando
sudo kinit -k -t /etc/security/keytabs/hbase.service.keytab hbase/<FQDN>@<DOMAIN>.Digite o seguinte comando:
sudo bash hdi_enable_replication.sh -s <srclusterdns> -d <dstclusterdns> -sp <srcclusterpasswd> -dp <dstclusterpasswd> -copydata
O Phoenix Sqlline para de funcionar após a migração do cluster HBase para o HDInsight 4.0
Execute as seguintes etapas:
- Descarte as seguintes tabelas de Phoenix:
SYSTEM.FUNCTIONSYSTEM.SEQUENCESYSTEM.STATSSYSTEM.MUTEXSYSTEM.CATALOG
- Caso não seja possível excluir nenhuma das tabelas, reinicie o HBase para limpar todas as conexões com as tabelas.
- Execute
sqlline.pynovamente. O Phoenix recriará todas as tabelas que foram excluídas na etapa 1. - Regenerar tabelas e exibições Phoenix para seus dados do HBase.
O Phoenix Sqlline para de funcionar após a replicação de metadados do HBase Phoenix do HDInsight 3.6 para o 4.0
Execute as seguintes etapas:
- Antes de fazer a replicação, vá para o cluster de destino 4.0 e execute
sqlline.py. Esse comando gerará tabelas Phoenix, comoSYSTEM.MUTEXeSYSTEM.LOGque só existem em 4.0. - Exclua as tabelas a seguir:
SYSTEM.FUNCTIONSYSTEM.SEQUENCESYSTEM.STATSSYSTEM.CATALOG
- Iniciar a replicação HBase
Reprovação
Os serviços Apache Storm e ML não estão disponíveis no HDInsight 4.0.
Data do lançamento: 14/04/2019
Novos recursos
Os recursos e novas atualizações se enquadram nas categorias a seguir:
Atualize o Hadoop e outros projetos de código aberto – Além de mais de 1000 correções de erros em mais de 20 projetos de código aberto, esta atualização contém uma nova versão do Spark (2.3) e Kafka (1.0).
Atualize o Microsoft R Server 9.1 para os Serviços de Machine Learning 9.3 – Com esta versão, estamos oferecendo aos cientistas de dados e engenheiros o melhor do código aberto aprimorado com inovações algorítmicas e facilidade de operacionalização, todos disponíveis em seu idioma preferido com a velocidade do Apache Spark. Esta versão expande os recursos oferecidos no R Server com suporte adicional ao Python, levando à alteração do nome do cluster de R Server para ML Services.
Suporte ao armazenamento de dados do Azure Data Lake Gen2 – O HDInsight suportará a versão de visualização do Armazenamento de dados do Windows Azure Gen2. Nas regiões disponíveis, os clientes poderão escolher uma conta ADLS Gen2 como uma loja Primária ou Secundária para seus clusters HDInsight.
HDInsight Enterprise Security Package Updates (Preview) – (Preview) Suporte para Pontos de Extremidade de Serviço de Rede Virtual para Armazenamento de Blobs do Azure, ADLS Gen1, Azure Cosmos DB, e BD do Azure.
Versões do componente
As versões do Apache oficiais de todos os componentes do HDInsight 3.6 estão listadas abaixo. Todos os componentes relacionados aqui são versões oficiais do Apache das versões estáveis mais recentes disponíveis.
Apache Hadoop 2.7.3
Apache HBase 1.1.2
Apache Hive 1.2.1
Apache Hive 2.1.0
Apache Kafka 1.0.0
Apache Mahout 0.9.0+
Apache Oozie 4.2.0
Apache Phoenix 4.7.0
Apache Pig 0.16.0
Apache Ranger 0.7.0
Apache Slider 0.92.0
Apache Spark 2.2.0/2.3.0
Apache Sqoop 1.4.6
Apache Storm 1.1.0
Apache TEZ 0.7.0
Apache Zeppelin 0.7.3
Apache ZooKeeper 3.4.6
Versões mais recentes de alguns componentes do Apache, às vezes, estão incluídas na distribuição de HDP além das versões listadas acima. Nesse caso, as versões posteriores estão listadas na tabela de Versões Técnicas e não devem substituir as versões do componente Apache da lista acima em um ambiente de produção.
Informações de patch do Apache
O Hadoop
Esta versão oferece Hadoop Common 2.7.3 e os seguintes patches de Apache:
HADOOP-13190: mencionar LoadBalancingKMSClientProvider na documentação KMS HA.
HADOOP-13227: AsyncCallHandler deve usar um evento controlado por arquitetura para lidar com as chamadas assíncronas.
HADOOP-14104: cliente sempre deve pedir nameNode para o caminho do fornecedor.
HADOOP-14799: atualizar nimbus-jose-jwt para 4.41.1.
HADOOP-14814: corrigir a alteração de API incompatível em FsServerDefaults para 14104 HADOOP.
HADOOP-14903: adicionar json-smart para pom.xml.
HADOOP-15042: o Azure PageBlobInputStream.skip() pode retornar um valor negativo quando numberOfPagesRemaining for 0.
HADOOP 15255: suporte de conversão maiusculas e minúsculas para nomes de grupo em LdapGroupsMapping.
HADOOP-15265: excluir o json-smart explicitamente do hadoop-auth pom.xml.
HDFS-7922: ShortCircuitCache#close não está liberando ScheduledThreadPoolExecutors.
HDFS-8496: chamar stopWriter() com o bloqueio FSDatasetImpl mantido pode bloquear outros threads (cmccabe).
HDFS-10267: extra “sincronizado” no FsDatasetImpl#recoverAppend e FsDatasetImpl#recoverClose.
HDFS-10489: substituir dfs.encryption.key.provider.uri para zonas de criptografia do HDFS.
HDFS 11384: adicione a opção o balanceador para dispersar as chamadas getBlocks para evitar pico no rpc.CallQueueLength do NameNode.
HDFS-11689: nova exceção lançada por código hive
hackyquebrado deDFSClient%isHDFSEncryptionEnabled.HDFS-11711: DN não deve excluir o bloco na exceção "há muitos arquivos abertos".
HDFS-12347: TestBalancerRPCDelay#testBalancerRPCDelay falha com frequência.
HDFS-12781: após a desativação de
Datanode, a guiaDatanodeda interface do usuárioNamenodeexibirá uma mensagem de aviso.HDFS-13054: manipulação do PathIsNotEmptyDirectoryException na chamada de exclusão de
DFSClient.HDFS-13120: a diferença de instantâneo poderia ser corrompida após concat.
YARN-3742: o YARN RM será desligado se a criação de
ZKClientatingir o tempo limite.YARN-6061: adicionar um UncaughtExceptionHandler para threads críticos no RM.
YARN-7558: o comando de logs do yarn falha ao obter logs para executar os contêineres, se a autenticação de interface do usuário estiver habilitada.
YARN-7697: a busca de logs para o aplicativo concluído falha, mesmo que a agregação de log esteja concluída.
HDP 2.6.4 forneceu Hadoop Common 2.7.3 e os seguintes patches do Apache:
HADOOP-13700: remoção de
IOExceptionnão lançada de assinaturas de TrashPolicy#initialize e #getInstance.HADOOP-13709: capacidade de limpar subprocessos gerados pelo Shell quando o processo é encerrado.
HADOOP-14059: erro de digitação na mensagem de erro rename(self, subdir)
s3a.HADOOP-14542: adicionar IOUtils.cleanupWithLogger que aceita a API do agente slf4j.
HDFS-9887: os tempos limite de soquete WebHdfs devem ser configuráveis.
HDFS-9914: corrigir o tempo limite de conexão/leitura do WebhDFS configurável.
MAPREDUCE-6698: aumentar o tempo limite em TestUnnecessaryBlockingOnHist oryFileInfo.testTwoThreadsQueryingDifferentJobOfSameUser.
YARN-4550: alguns testes em TestContainerLanch falham em ambiente de localidade não inglês.
YARN-4717: o TestResourceLocalizationService.testPublicResourceInitializesLocalDir falha intermitentemente devido a IllegalArgumentException de limpeza.
YARN-5042: montagem /sys/fs/cgroup em contêineres do Docker como montagem de somente leitura.
YARN-5318: corrigir a falha de teste intermitente de TestRMAdminService#te stRefreshNodesResourceWithFileSystemBasedConfigurationProvider.
YARN-5641: o localizador deixa para trás tarballs após a conclusão do contêiner.
YARN-6004: refatorar o TestResourceLocalizationService#testDownloadingResourcesOnContainer de forma que tenha menos de 150 linhas.
YARN-6078: contêineres presos no estado de localização.
YARN-6805: NPE em LinuxContainerExecutor devido a código de saída PrivilegedOperationException nulo.
HBase
Esta versão oferece HBase 1.1.2 e os seguintes patches de Apache.
HBASE-13376: melhorias ao balanceador de carga Stochastic.
HBASE-13716: parar de usar FSConstants do Hadoop.
HBASE-13848: senhas de acesso InfoServer SSL por meio da API do provedor de credenciais.
HBASE-13947: Uso do MasterServices em vez de Servidor no AssignmentManager.
HBASE-14135: fase de restauração/backup do HBase 3: Mesclar imagens de backup.
HBASE-14473: localidade de região de computação em paralelo.
HBASE-14517: mostrar versão
regionserver'sna página de status do master.HBASE-14606: os testes TestSecureLoadIncrementalHFiles atingiram o tempo limite no tronco compilar no apache.
HBASE-15210: desfazer o registro em log de balanceador de carga agressivo em dezenas de linhas por milissegundo.
HBASE-15515: melhorar o LocalityBasedCandidateGenerator no balanceador.
HBASE-15615: tempo de espera incorreto quando
RegionServerCallableprecisa tentar novamente.HBASE-16135: o PeerClusterZnode sob rs do par removido nunca pode ser excluído.
HBASE-16570: localidade de região de computação ao startup.
HBASE-16810: o HBase Balancer lança ArrayIndexOutOfBoundsException quando
regionserversestá em /hbase/draining znode e é descarregado.HBASE-16852: TestDefaultCompactSelection falhou no branch 1.3.
HBASE-17387: reduzir a sobrecarga de relatório de exceção no RegionActionResult para multi ().
HBASE-17850: utilitário de reparo do sistema de backup.
HBASE-17931: atribuir as tabelas do sistema para servidores com a versão mais recente.
HBASE-18083: fazer com que o arquivo grande/pequeno limpe o número de thread configurável no HFileCleaner.
HBASE-18084: melhore o CleanerChore para limpar do diretório, que consome mais espaço em disco.
HBASE-18164: função do custo de localidade muito mais rápida e gerador do candidato.
HBASE-18212: no modo Autônomo com o sistema de arquivos locais da mensagem de Aviso de logs HBase: falha ao invocar o método “unbuffer” na classe org.apache.hadoop.fs.FSDataInputStream.
HBASE-18808: verificação da configuração ineficaz no BackupLogCleaner#getDeletableFiles().
HBASE-19052: FixedFileTrailer deve reconhecer a classe CellComparatorImpl no branch-1. x.
HBASE-19065: HRegion#bulkLoadHFiles() deve esperar a Region#flush() concorrente para concluir.
HBASE-19285: Adicionar histogramas de latência por tabela.
HBASE-19393: cabeçalho completo HTTP 413 acessando HBase da interface do usuário usando SSL.
HBASE-19395: [branch-1] TestEndToEndSplitTransaction.testMasterOpsWhileSplitting falha com NPE.
HBASE-19421: branch-1 não é compilado no Hadoop 3.0.0.
HBASE-19934: HBaseSnapshotException ao ler réplicas está habilitado e o instantâneo on-line é tirado após a divisão da região.
HBASE-20008: [backport] NullPointerException ao restaurar um instantâneo após a divisão de uma região.
Hive
Esta versão fornece Hive 1.2.1 e Hive 2.1.0 além dos patches a seguir:
Patches do Apache Hive 1.2.1:
HIVE-10697: ObjectInspectorConvertors#UnionConvertor faz uma conversão com defeito.
HIVE-11266: contagem(*) resultado incorreto com base nas estatísticas de tabela para tabelas externas.
HIVE-12245: comentários de coluna de suporte para um HBase com suporte de tabela.
HIVE-12315: corrigir a dupla vetorizada dividida por zero.
HIVE-12360: busca incorreta no ORC não compactado com a aplicação de predicado.
HIVE-12378: exceção no campo de HBaseSerDe.serialize binário.
HIVE-12785: exibição com o tipo de unição e UDF para o struct que está rompido.
HIVE-14013: descrever a tabela não mostra unicode corretamente.
HIVE-14205: Hive não dá suporte a tipo de união com o formato de arquivo do AVRO.
HIVE-14421: FS.deleteOnExit contém as referências para arquivos to _tmp_space.db.
HIVE-15563: Ignorar exceção de transição de estado de Operação Ilegal no SQLOperation.runQuery para expor a exceção real.
HIVE-15680: resultados incorretos quando hive.optimize.index.filter=true e a mesma tabela ORC é referenciada duas vezes na consulta, no modo de MR.
HIVE-15883: tabela mapeada HBase no Hive insere falha para décimo.
HIVE-16232: suporte a computação de estatísticas para colunas em QuotedIdentifier.
HIVE-16828: com CBO habilitada, a consulta em exibições particionadas gerará IndexOutOfBoundException.
HIVE-17013: solicitação de exclusão com uma subconsulta com base na seleção em uma exibição.
HIVE-17063: inserir a partição de substituição em uma tabela externa falha ao remover primeiro a partição.
HIVE-17259: JDBC do Hive não reconhece as colunas UNIONTYPE.
HIVE-17419: ANALISAR TABELA... COMPUTAR ESTATÍSTICAS PARA COLUNAS o comando exibe as estatísticas computadas para as tabelas mascaradas.
HIVE-17530: ClassCastException ao converter
uniontype.HIVE-17621: configurações de Hive-site serão ignoradas durante o cálculo de divisão HCatInputFormat.
HIVE-17636: adicionar teste multiple_agg.q para
blobstores.HIVE-17729: adicionar banco de dados e explicar testes de blobstore relacionados.
HIVE-17731: adicionar uma opção de
compatde retrocesso para usuários externos ao HIVE-11985.HIVE-17803: com a consulta de vários Pig, 2 HCatStorers escrevendo para a mesma tabela atrapalharão as saídas uns dos outros.
HIVE-17829: ArrayIndexOutOfBoundsException – Tabelas com suporte ao HBASE com esquema Avro em
Hive2.HIVE-17845: a inserção falhará se as colunas da tabela de destino estiverem em minúscula.
HIVE-17900: analisar estatísticas em colunas disparadas por Compactador gera SQL malformado com > coluna de partição 1.
HIVE-18026: otimização de configuração principal do webhcat do Hive.
HIVE-18031: replicação de suporte para a operação Alter Database.
HIVE-18090: falha de pulsação acid quando metastore está conectado por meio da credencial do hadoop.
HIVE-18189: consulta de Hive, retornando resultados incorretos quando definido hive.groupby.orderby.position.alias como true.
HIVE-18258: vetorização: reduzir lado do GRUPO POR MERGEPARTIAL com colunas duplicadas é interrompida.
HIVE-18293: o Hive está falhando ao compactar as tabelas contidas em uma pasta que não pertence à identidade que executa o HiveMetaStore.
HIVE-18327: remover a dependência HiveConf desnecessária para MiniHiveKdc.
HIVE-18341: adicionar suporte a carga repl para adicionar o namespace "bruto" para a TDE com as mesmas chaves de criptografia.
HIVE-18352: introduzir uma opção de METADATAONLY ao fazer o REPL DUMP para pemitir integrações das outras ferramentas.
HIVE-18353: o CompactorMR deve chamar jobclient.close() para disparar a limpeza.
HIVE-18390: IndexOutOfBoundsException ao consultar uma exibição particionada no ColumnPruner.
HIVE-18429: a compactação deve lidar com um caso quando ele não produz nenhuma saída.
HIVE-18447: JDBC: fornecem uma maneira para os usuários do JDBC para passar informações de cookie por meio da cadeia de caracteres de conexão.
HIVE-18460: o compactador não passa as propriedades da tabela para o gravador de Orc.
HIV-18467: dar suporte a despejo de warehouse inteiro / carregar + criar/remover eventos de banco de dados (Anishek Agarwal, revisadas por Sankar Hariappan).
HIVE-18551: vetorização: VectorMapOperator tenta gravar muitas colunas de vetor para Hybrid Grace.
HIVE-18587: evento de inserção de DML pode tentar calcular uma soma de verificação em diretórios.
HIVE-18613: estender JsonSerDe para dar suporte ao tipo BINÁRIO.
HIVE-18626: carga de Repl "com" cláusula não passa config para tarefas.
HIVE-18660: PCR não distingue entre partição e colunas virtuais.
HIVE-18754: STATUS de REPL deve dar suporte à cláusula “com”.
HIVE-18754: STATUS de REPL deve dar suporte à cláusula “com”.
HIVE-18788: limpar entradas no JDBC PreparedStatement.
HIVE-18794: carga Repl cláusula “com” não passa a configuração para as tarefas para tabelas de não participação.
HIVE-18808: tornar a compactação mais robusta, quando a atualização de estatísticas falhar.
HIVE-18817: exceção de ArrayIndexOutOfBounds durante a leitura da tabela ACID.
HIVE-18833: mesclagem automática falha ao "inserir no diretório como orcfile".
HIVE-18879: não permitir o elemento inserido na UDFXPathUtil precisa funcionar se xercesImpl. jar no classpath.
HIVE-18907: criar um utilitário para corrigir o problema de índice de chave acid do HIVE 18817.
Patches do Apache Hive2.1.0:
HIVE-14013: descrever a tabela não mostra unicode corretamente.
HIVE-14205: Hive não dá suporte a tipo de união com o formato de arquivo do AVRO.
HIVE-15563: Ignorar exceção de transição de estado de Operação Ilegal no SQLOperation.runQuery para expor a exceção real.
HIVE-15680: resultados incorretos quando hive.optimize.index.filter=true e a mesma tabela ORC é referenciada duas vezes na consulta, no modo de MR.
HIVE-15883: tabela mapeada HBase no Hive insere falha para décimo.
HIVE 16757: remover chamadas para AbstractRelNode.getRows preterido.
HIVE-16828: com CBO habilitada, a consulta em exibições particionadas gerará IndexOutOfBoundException.
HIVE-17063: inserir a partição de substituição em uma tabela externa falha ao remover primeiro a partição.
HIVE-17259: JDBC do Hive não reconhece as colunas UNIONTYPE.
HIVE-17530: ClassCastException ao converter
uniontype.HIVE 17600: tornar a enforceBufferSize do OrcFile definível pelo usuário.
HIVE-17601: melhorar o tratamento de erros em LlapServiceDriver.
HIVE-17613: remover pools de objeto para alocações curtas e o mesmo thread.
HIVE-17617: pacote cumulativo de atualizações de um conjunto de resultados vazio deve conter o agrupamento de conjunto vazio de agrupamento.
HIVE-17621: configurações de Hive-site serão ignoradas durante o cálculo de divisão HCatInputFormat.
HIVE-17629: CachedStore: tenha uma configuração de aprovado/não aprovado para permitir cache seletiva de tabelas/partições e permitir leitura durante a preparação.
HIVE-17636: adicionar teste multiple_agg.q para
blobstores.HIVE-17702: isRepeating incorreto tratamento no leitor decimal no ORC.
HIVE-17729: adicionar banco de dados e explicar testes de blobstore relacionados.
HIVE-17731: adicionar uma opção de
compatde retrocesso para usuários externos ao HIVE-11985.HIVE-17803: com a consulta de vários Pig, 2 HCatStorers escrevendo para a mesma tabela atrapalharão as saídas uns dos outros.
HIVE-17845: a inserção falhará se as colunas da tabela de destino estiverem em minúscula.
HIVE-17900: analisar estatísticas em colunas disparadas por Compactador gera SQL malformado com > coluna de partição 1.
HIVE-18006: otimizar o volume de memória do HLLDenseRegister.
HIVE-18026: otimização de configuração principal do webhcat do Hive.
HIVE-18031: replicação de suporte para a operação Alter Database.
HIVE-18090: falha de pulsação acid quando metastore está conectado por meio da credencial do hadoop.
HIVE-18189: a ordem por posição não funciona quando
cboestá desabilitado.HIVE-18258: vetorização: reduzir lado do GRUPO POR MERGEPARTIAL com colunas duplicadas é interrompida.
HIVE-18269: LLAP: O io
llaprápido com pipeline de processamento lento pode levar ao OOM.HIVE-18293: o Hive está falhando ao compactar as tabelas contidas em uma pasta que não pertence à identidade que executa o HiveMetaStore.
HIVE-18318: leitor do registro LLAP deve verificar a interrupção, mesmo quando não estiver bloqueando.
HIVE-18326: agendador LLAP - apropriação somente tarefas se há uma dependência entre eles.
HIVE-18327: remover a dependência HiveConf desnecessária para MiniHiveKdc.
HIVE-18331: adicionar tentativa de fazer login novamente quando o TGT expira e apresenta algum registro em log/lambda.
HIVE-18341: adicionar suporte a carga repl para adicionar o namespace "bruto" para a TDE com as mesmas chaves de criptografia.
HIVE-18352: introduzir uma opção de METADATAONLY ao fazer o REPL DUMP para pemitir integrações das outras ferramentas.
HIVE-18353: o CompactorMR deve chamar jobclient.close() para disparar a limpeza.
HIVE-18384: ConcurrentModificationException na biblioteca
log4j2.x.HIVE-18390: IndexOutOfBoundsException ao consultar uma exibição particionada no ColumnPruner.
HIVE-18447: JDBC: fornecem uma maneira para os usuários do JDBC para passar informações de cookie por meio da cadeia de caracteres de conexão.
HIVE-18460: o compactador não passa as propriedades da tabela para o gravador de Orc.
HIVE-18462: (Explain formatado para consultas com junção de mapa tem columnExprMap com nome de coluna não formatado).
HIVE-18467: dar suporte a despejo de warehouse inteiro / carregar + criar/remover eventos de banco de dados.
HIVE-18488: leitores LLAP ORC estão faltando algumas verificações nulas.
HIVE-18490: consulta com EXISTS e NOT EXISTS com predicado não equip pode produzir o resultado incorreto.
HIVE-18506: LlapBaseInputFormat - índice negativo da matriz.
HIVE-18517: vetorização: corrigir VectorMapOperator para aceitar VRBs e verificar o sinalizador vetorizado corretamente para dar suporte a cache LLAP).
HIVE-18523: corrigir a linha de resumo caso não haja nenhuma entrada.
HIVE-18528: estatísticas agregadas em ObjectStore obtém resultado incorreto.
HIVE-18530: a replicação deve ignorar a tabela MM (por enquanto).
HIVE-18548: correção da importação
log4j.HIVE-18551: vetorização: VectorMapOperator tenta gravar muitas colunas de vetor para Hybrid Grace.
HIVE-18577: SemanticAnalyzer.validate tem algumas chamadas de metastore inútil.
HIVE-18587: evento de inserção de DML pode tentar calcular uma soma de verificação em diretórios.
HIVE-18597: LLAP: sempre empacote o jar da API
log4j2paraorg.apache.log4j.HIVE-18613: estender JsonSerDe para dar suporte ao tipo BINÁRIO.
HIVE-18626: carga de Repl "com" cláusula não passa config para tarefas.
HIVE-18643: não marque para partições arquivadas para ops ACID.
HIVE-18660: PCR não distingue entre partição e colunas virtuais.
HIVE-18754: STATUS de REPL deve dar suporte à cláusula “com”.
HIVE-18788: limpar entradas no JDBC PreparedStatement.
HIVE-18794: carga Repl cláusula “com” não passa a configuração para as tarefas para tabelas de não participação.
HIVE-18808: tornar a compactação mais robusta, quando a atualização de estatísticas falhar.
HIVE-18815: remover o recurso não utilizado no HPL/SQL.
HIVE-18817: exceção de ArrayIndexOutOfBounds durante a leitura da tabela ACID.
HIVE-18833: mesclagem automática falha ao "inserir no diretório como orcfile".
HIVE-18879: não permitir o elemento inserido na UDFXPathUtil precisa funcionar se xercesImpl. jar no classpath.
HIVE-18944: o agrupamento de posição de conjuntos é definido incorretamente durante o protocolo DPP.
Kafka
Esta versão oferece Kakfa 1.0.0 e os seguintes patches de Apache.
KAFKA-4827: conectar-se à Kafka: erro com caracteres especiais no nome do conector.
KAFKA-6118: falha momentânea no kafka.api.SaslScramSslEndToEndAuthorizationTest.testTwoConsumersWithDifferentSaslCredentials.
6156-KAFKA: JmxReporter não pode lidar com caminhos de diretório de estilo do windows.
KAFKA-6164: os threads ClientQuotaManager impedem o desligamento ao encontrar um erro ao carregar os logs.
KAFK- 6167: carimbo de hora no diretório de fluxos contém dois-pontos, que é um caractere ilegal.
KAFKA-6179: o RecordQueue.clear() não limpa a lista mantida do MinTimestampTracker.
KAFKA-6185: vazamento de memória do seletor com alta probabilidade de OOM se houver uma conversão para baixo.
KAFKA-6190: GlobalKTable nunca conclui a restauração durante o consumo de mensagens transacionais.
KAFKA-6210: o IllegalArgumentException se 1.0.0 é usado para inter.broker.protocol.version ou log.message.format.version.
KAFKA-6214usar réplicas standby com um armazenamento de estado de memória fazem com que os Streams entrem em pane.
KAFKA-6215: o KafkaStreamsTest falhar no tronco.
KAFKA-6238: problemas com a versão de protocolo ao aplicar uma atualização sem interrupção para 1.0.0.
KAFKA-6260: o AbstractCoordinator claramente não lida com a exceção nula.
KAFKA-6261: solicitação de registro em log lança a exceção se acks = 0.
KAFKA-6274: aprimoramento dos nomes gerados automaticamente no armazenamento do estado de origem do
KTable.
Mahout
No HDP 2.3 e 2.4, em vez de envio de uma versão específica do Apache do Mahout, podemos sincronizados para um ponto de revisão específica no tronco do Apache Mahout. Esse ponto de revisão é após a versão 0.9.0, mas antes da versão 0.10.0. Isso fornece um grande número de correções de bug e aprimoramentos funcionais ao longo da versão 0.9.0, mas fornece uma versão estável da funcionalidade Mahout antes da conversão completa ao novo Mahout com base no Spark em 0.10.0.
O ponto de revisão escolhido para Mahout no HDP 2.3 e 2.4 é da ramificação do "mahout-0.10.x", a partir de 19 de dezembro de 2014, revisão 0f037cb03e77c096 no GitHub.
Em HDP 2.5 e 2.6, nós removos a biblioteca "commons httpclient" do Mahout, porque podemos exibi-lo como uma biblioteca obsoleta com possíveis problemas de segurança e atualizado o cliente do Hadoop no Mahout para a versão 2.7.3, a mesma versão usada em HDP 2.5. Como resultado:
Trabalhos de Mahout compilados anteriormente precisarão ser compilados no ambiente HDP-2.5 ou 2.6.
Existe uma possibilidade pequena de alguns trabalhos do Mahout encontrarem "ClassNotFoundException" ou os erros "não foi possível carregar a classe" relacionados a "org.apache.commons.httpclient", "net.java.dev.jets3t" ou prefixos de nomes de classe relacionada. Se esses erros acontecerem, você pode considerar se deve instalar manualmente os jars necessários no seu classpath para o trabalho, se o risco de problemas de segurança na biblioteca obsoleta é aceitável em seu ambiente.
Há uma possibilidade ainda menor que alguns trabalhos do Mahout podem encontrar falhas em chamadas de código de cliente hbase do Mahout para as bibliotecas comuns do hadoop, devido a problemas de compatibilidade binária. Infelizmente, não há como resolver esse problema, exceto reverter para a versão do HDP 2.4.2 do Mahout, que pode ter problemas de segurança. Novamente, isso deverá ser incomum e improvável que ocorra em qualquer conjunto de tarefas do Mahout.
Oozie
Esta versão oferece Oozie 4.2.0 e os seguintes patches de Apache.
OOZIE-2571: adicionar propriedade Maven spark.scala.binary.version para que possa ser usado Scala 2.11.
OOZIE-2606: defina spark.yarn.jars para corrigir Spark 2.0 com Oozie.
OOZIE-2658: – o caminho de classe de driver pode substituir o classpath no SparkMain.
OOZIE-2787: o Oozie distribui o jar do aplicativo fazendo duas vezes o trabalho do spark falhar.
OOZIE-2792: a ação do
Hive2não analisa corretamente a ID do aplicativo Spark do arquivo de log quando o Hive está no Spark.OOZIE-2799: local do log de configuração para o spark sql no hive.
OOZIE-2802: falha na ação do Spark 2.1.0 devido a uma duplicação de
sharelibs.OOZIE-2923: melhorar análise de opções de Spark.
OOZIE-3109: SCA: script de conectividade entre sites: refletido.
OOZIE-3139: Oozie valida incorretamente o fluxo de trabalho.
OOZIE-3167: versão de atualização do tomcat na ramificação de Oozie 4.3.
Phoenix
Esta versão oferece Phoenix 4.7.0 e os seguintes patches de Apache:
PHOENIX-1751: executar agregações, classificação, etc., em que o preScannerNext em vez de postScannerOpen.
PHOENIX-2714: os bytes correto estimam em BaseResultIterators e expõe como interface.
PHOENIX-2724: a consulta com um grande número de balizas é mais lenta comparado com nenhuma estatística.
PHOENIX-2855: intervalo de tempo de incremento de solução alternativa que está sendo serializado não para o HBase 1.2.
PHOENIX-3023: desempenho lento quando as consultes de limite são executadas em paralelo por padrão.
PHOENIX 3040: não use balizas para executar consultas em série.
PHOENIX-3112: o exame da linha parcial não manuseado corretamente.
PHOENIX-3240: ClassCastException do carregador de Pig.
PHOENIX-3452: NULLS FIRST/NULL LAST não deve afetar se GROUP BY for ordem de preservação.
PHOENIX-3469: ordem de classificação incorreta chave primária DESC para NULLS LAST/NULLS FIRST.
PHOENIX-3789: executar chamadas de manutenção de índice de região no postBatchMutateIndispensably.
PHOENIX-3865: IS NULL não retorna resultados corretos quando a primeira família de coluna não for filtrada.
PHOENIX-4290: verificação de tabela completa é executada para a exclusão com a tabela que tem índices imutáveis.
PHOENIX-4373: chave de comprimento variável de local de índice pode ter à direita nulos durante a inserção.
PHOENIX-4466: java.lang.RuntimeException: código de resposta 500 - executar um trabalho do spark para conectar-se ao servidor de consulta phoenix e carregar dados.
PHOENIX 4489: vazamento de Conexão de HBase em trabalhos de Phoenix MR.
PHOENIX-4525: estouro de inteiro na execução GroupBy.
PHOENIX-4560: ORDER BY com GROUP BY não funciona se houver WHERE na coluna
pk.PHOENIX-4586: UPSERT SELECT não usa operadores de comparação de conta para subconsultas.
PHOENIX-4588: clonar expressão também se os filhos tiverem Determinism.PER_INVOCATION.
Pig
Esta versão oferece Pig 0.16.0 e os seguintes patches de Apache.
PIG-5159: corrigir Pig sem salvar o histórico de grunt.
PIG-5175: atualização de
jrubypara a versão 1.7.26.
Ranger
Esta versão oferece Ranger 0.7.0 e os seguintes patches de Apache:
RANGER-1805: códigode aperfeiçoamento segue as melhores práticas em js.
RANGER-1960: levar o nome da tabela do instantâneo em consideração para exclusão.
RANGER-1982: melhoria do erro para a métrica de análise de administração do Ranger e Ranger KMS.
RANGER-1984: registros de log de auditoria do HBase não podem mostrar todas as marcas associadas à coluna acessada.
RANGER-1988: corrigir aleatoriedade insegura.
RANGER-1990: adicionar o suporte MySQL One-way no Administrador do Rager.
RANGER-2006: correção de problemas detectados pela análise de código estático no ranger
usersyncpara origem de sincronização deldap.RANGER-2008: a avaliação de política está falhando para condições da política de várias linhas.
Controle deslizante
Essa versão fornece Slider 0.92.0 sem mais patches do Apache.
Spark
Esta versão oferece Spark 2.3.0 e os seguintes patches de Apache:
SPARK-13587: suporte virtualenv no pyspark.
SPARK-19964: evitar a leitura de repositórios remotos no SparkSubmitSuite.
SPARK-22882: teste de ML para streaming estruturado: ml.classification.
SPARK-22915: testes de streaming para spark.ml.feature de N a Z.
SPARK-23020: corrigir outra corrida no teste do iniciador em processo.
SPARK-23040: o iterador passível de interrupção retorna para o leitor de ordem aleatória.
SPARK-23173: evitar a criação de arquivos parquet corrompido quando o carregamento de dados do JSON.
SPARK-23264: corrigir scala.MatchError em literals.sql.out.
SPARK-23288: corrigir métricas de saída com o coletor parquet.
SPARK-23329: corrigir a documentação de funções trigonométricas.
SPARK-23406 habilitar autojunções de fluxo-fluxo para branch 2.3.
SPARK-23434: o Spark não deveria avisar o `diretório de metadados` para um caminho de arquivo HDFS.
SPARK-23436: inferir partição como data somente se ele pode ser convertido em data.
SPARK-23457: registrar ouvintes de conclusão de tarefas primeiro no ParquetFileFormat.
SPARK-23462: : melhorar a mensagem de erro de campo ausente na `StructType`.
SPARK-23490: verificar storage.locationUri com uma tabela existente no CreateTable.
SPARK-23524: os blocos de ordem aleatória local grande não devem ser verificados quanto a corrupção.
SPARK-23525: suporte para ALTER TABLE CHANGE COLUMN COMMENT para tabela hive externa.
SPARK-23553: testes não devem presumir o valor padrão spark.sql.sources.default.
SPARK-23569: permitir pandas_udf para trabalhar com funções anotado pelo tipo de estilo python3.
SPARK-23570: adicionar Spark 2.3.0 HiveExternalCatalogVersionsSuite.
SPARK-23598: tornar os métodos públicos no BufferedRowIterator para evitar o erro do runtime para uma consulta grande.
SPARK-23599: adicionar um gerador UUID de números pseudoaleatórios.
SPARK-23599: usar RandomUUIDGenerator de uso na expressão de Uuid.
SPARK-23601: remoção de arquivos
.md5da versão.SPARK-23608: adicionar uma sincronização em SHS entre as funções attachSparkUI e detachSparkUI para evitar modificações simultâneas problema ao Jetty Handlers.
SPARK-23614: corrigir troca de reutilização incorreta quando o cache é usado.
SPARK-23623: evitar o uso simultâneo de consumidores em cache no CachedKafkaConsumer (2.3 branch).
SPARK-23624: revisar doc do método pushFilters no Datasource V2.
SPARK-23628: calculateParamLength não deve retornar 1 + de expressões.
SPARK-23630: permitir que as personalizações conf do hadoop entrem em vigor.
SPARK-23635: a variável env do executor Spark é substituído pelo mesmo nome variável env AM.
SPARK-23637: Yarn pode alocar mais recursos, se um executor mesmo é interrompido várias vezes.
SPARK-23639: obter token antes do cliente init metastore no SparkSQL CLI.
SPARK-23642: correção de
scaladocda subclasse isZero do AccumulatorV2.SPARK-23644: usar o caminho absoluto para a chamada REST em SHS.
SPARK-23645: adicione docs RE `pandas_udf` com os args de palavra-chave.
SPARK-23649: ignorando os caracteres não permitidos em UTF-8.
SPARK-23658: InProcessAppHandle usa a classe errada em getLogger.
SPARK-23660: corrigir exceção no modo de cluster yarn, quando o aplicativo termina rapidamente.
SPARK-23670: correção de perda de memória em SparkPlanGraphWrapper.
SPARK-23671: corrigir a condição para habilitar o pool de threads SHS.
SPARK 23691: usar o sql_util conf nos testes PySpark sempre que possível.
SPARK 23695: corrigir a mensagem de erro para os testes Kinesis de streaming.
SPARK-23706: spark.conf.get (valor padrão = Nenhum) deve produzir nenhum em PySpark.
SPARK-23728corrigir os testes ML com as exceções esperadas executando os testes de streaming.
SPARK 23729: respeitar o fragmento RI ao resolver globs.
SPARK-23759: não é possível associar a interface do usuário Spark ao nome do host específico / IP.
SPARK 23760: CodegenContext.withSubExprEliminationExprs deve salvar/restaurar o estado do CSE corretamente.
SPARK-23769: remova os comentários que desabilitam desnecessariamente a verificação de
Scalastyle.SPARK-23788: correção de corrida em StreamingQuerySuite.
SPARK-23802: o PropagateEmptyRelation pode deixar o plano de consulta em estado não resolvido.
SPARK-23806: o Broadcast.unpersist pode causar uma exceção fatal quando usado com alocação dinâmica.
SPARK-23808: definir a sessão do Spark padrão em sessões do spark somente para teste.
SPARK-23809: SparkSession Active Directory deve ser definido por getOrCreate.
SPARK-23816: tarefas encerradas devem ignorar FetchFailures.
SPARK-23822: melhorar a mensagem de erro de incompatibilidade de esquema Parquet.
SPARK-23823: mantenha a origem em transformExpression.
SPARK-23827: o StreamingJoinExec deve garantir que os dados de entrada sejam particionados em um número específico de partições.
SPARK-23838: a consulta SQL em execução é exibida como "concluída" no guia SQL.
SPARK-23881: correção instável teste JobCancellationSuite."iterador passível de interrupção do leitor de ordem aleatória".
Sqoop
Essa versão fornece o Sqoop 1.4.6 sem mais patches do Apache.
Storm
Esta versão oferece Storm 1.1.1 e os seguintes patches de Apache:
STORM 2652: exceção lançada no método aberto JmsSpout.
STORM-2841: testNoAcksIfFlushFails UT falha com NullPointerException.
STORM-2854: expor IEventLogger para tornar o log de eventos conectável.
STORM-2870: o FileBasedEventLogger vaza ExecutorService não-daemon, que impede que o processo seja concluído.
STORM-2960: melhor enfatizar a importância de configurar a conta apropriada do sistema operacional para o processo Storm.
Tez
Esta versão oferece Tez 0.7.0 e os seguintes patches de Apache:
- TEZ-1526: LoadingCache para TezTaskID lento para trabalhos grandes.
Zeppelin
Essa versão fornece o Zeppelin 0.7.3 sem mais patches do Apache.
ZEPPELIN-3072: a interface do usuário do Zeppelin não se torna lenta/irresponsivva se houver muitas anotações.
ZEPPELIN-3129: a interface do usuário do Zeppelin não sai no Internet Explorer.
ZEPPELIN-903: substituição de CXF por
Jersey2.
ZooKeeper
Esta versão oferece ZooKeeper 3.4.6 e os seguintes patches de Apache:
ZOOKEEPER-1256: ClientPortBindTest está falhando em macOS X.
ZOOKEEPER-1901: [JDK8] classificar filhos para comparação os testes AsyncOps.
ZOOKEEPER-2423: versão de atualização Netty devido à vulnerabilidade de segurança (CVE-2014 3488).
ZOOKEEPER-2693: ataque DOS em wchp/wchc de quatro letras (4lw).
ZOOKEEPER-2726: o patch introduz uma possível condição de corrida.
Common Vulnerabilities e Exposures Corrigidos
Esta seção aborda todos os Common Vulnerabilities and Exposures (CVE) que são abordados nesta versão.
CVE-2017-7676
| Resumo:A avaliação da política do Apache Ranger ignora os caracteres após o caractere curinga '*' |
|---|
| Gravidade: crítica |
| Fornecedor: Hortonworks |
| Versões afetadas: versões do HDInsight 3.6 incluindo as versões 0.5.x/0.6.x/0.7.0 do Apache Ranger |
| Usuários afetados:Ambientes que usam políticas do Ranger com caracteres após o caractere curinga '*' como meu*test, test*.txt |
| Impacto:O comparador de recursos de política ignora os caracteres após o caractere curinga '*', o que pode resultar em comportamento não intencional. |
| Corrigir detalhes: o correspondente de recurso de política do Ranger foi atualizado para lidar corretamente com correspondência de curinga. |
| Ação Recomendada: atualizar para o HDI 3.6 (com o Apache Ranger 0.7.1+). |
CVE-2017-7677
| Resumo: o autorizador Hive do Ranger deve Apache deve verificar a permissão RWX quando a localização for especificada |
|---|
| Gravidade: crítica |
| Fornecedor: Hortonworks |
| Versões afetadas: versões do HDInsight 3.6 incluindo as versões 0.5.x/0.6.x/0.7.0 do Apache Ranger |
| Usuários afetados: ambientes que usam o local externo para as tabelas do hive |
| Impacto: em ambientes que usam o local externo para tabelas hive, o Autorizador do Hive do Ranger Apache deve verificar se há permissões RWX para o local externo especificado para criar tabela. |
| Corrigir detalhes: o autorizador do hive Ranger foi atualizado para lidar corretamente com a verificação de permissão com o local externo. |
| Ação Recomendada: os usuários devem atualizar para HDI 3.6 (com Ranger Apache 0.7.1+). |
CVE-2017-9799
| Resumo: potencial execução de código como o usuário errado no Apache Storm |
|---|
| Gravidade: importante |
| Fornecedor: Hortonworks |
| Versões afetadas: HDP 2.4.0 HDP-2.5.0 2.6.0 HDP |
| Usuários afetados: usuários que usam o Storm no modo de segurança e que estão usando o blobstore para distribuir os artefatos baseados na topologia ou usar o blobstore para distribuir quaisquer recursos de topologia. |
| Impacto: em algumas situações e configurações de tempestade, é teoricamente possível para o proprietário de uma topologia enganar o supervisor para iniciar um trabalhador como um usuário diferente, que não seja raiz. Na pior das hipóteses, isso pode levar a proteger as credenciais do usuário de serem comprometidas. Essa vulnerabilidade só se aplica a instalações do Apache Storm com segurança habilitada. |
| Mitigação: atualizar para HDP 2.6.2.1, pois não há atualmente nenhuma solução alternativa. |
CVE-2016-4970
| Resumo: handler/ssl/OpenSslEngine.java no Netty 4.0.x antes de 4.0.37. Final e 4.1.x antes de 4.1.1. Final permite que invasores remotos causem uma negação de serviço (loop infinito) |
|---|
| Gravidade: moderada |
| Fornecedor: Hortonworks |
| Versões afetadas: HDP 2.x.x desde 2.3.x |
| Usuários afetados: todos os usuários que usam o HDFS. |
| Impacto: impacto é baixo, como Hortonworks não usa OpenSslEngine.java diretamente na Base de código do Hadoop. |
| Ação recomendada: atualizar para o HDP 2.6.3. |
CVE-2016-8746
| Resumo: problema na avaliação da política de correspondência de caminho de Ranger Apache |
|---|
| Gravidade: Normal |
| Fornecedor: Hortonworks |
| Versões afetadas: todas s versões HDP 2.5 incluindo as versões do Ranger Apache 0.6.0/0.6.1/0.6.2 |
| Usuários afetados: todos os usuários da ferramenta do administrador de política do ranger. |
| Impacto: o mecanismo de políticas do Ranger incorretamente corresponde a caminhos em certas condições quando uma política contém sinalizadores de curingas e recursivos. |
| Corrigir detalhes: corrigida a lógica de avaliação de política |
| Ação Recomendada: os usuários devem atualizar para HDP 2.5.4+ (com o Ranger Apache 0.6.3+) ou HDP 2.6+ (com o Ranger Apache 0.7.0+) |
CVE-2016-8751
| Resumo: problema de script armazenado entre sites do Ranger Apache |
|---|
| Gravidade: Normal |
| Fornecedor: Hortonworks |
| Versões afetadas: todas s versões HDP 2.3/2.4/2.5 incluindo as versões do Ranger 0.5.x/0.6.0/0.6.1/0.6.2 |
| Usuários afetados: todos os usuários da ferramenta do administrador de política do ranger. |
| Impacto: o Ranger Apache é vulnerável a um script entre sites armazenados ao inserir as condições de política personalizada. Os usuários administradores podem armazenar um código de JavaScript arbitrário quando usuários normais entrarem e acessarem as políticas. |
| Corrigir detalhes: adicionada lógica para limpar a entrada do usuário. |
| Ação Recomendada: os usuários devem atualizar para HDP 2.5.4+ (com o Ranger Apache 0.6.3+) ou HDP 2.6+ (com o Ranger Apache 0.7.0+) |
Correção de problemas para obter suporte
Problemas corrigidos representam problemas selecionados que foram registrados anteriormente por meio do suporte da Hortonworks, mas agora são abordados na versão atual. Esses problemas podem ter sido relatados nas versões anteriores dentro da seção de problemas conhecidos e isso significa que eles foram relatados por clientes ou identificados pela equipe de engenharia de qualidade do Hortonworks.
Resultados incorretos
| ID do bug | Apache JIRA | Resumo |
|---|---|---|
| BUG-100019 | YARN-8145 | yarn rmadmin - getGroups não retorna grupos atualizados para o usuário |
| BUG-100019 | PHOENIX-2645 | Caracteres curinga não coincidem com os caracteres de nova linha |
| BUG-100266 | PHOENIX-3521, PHOENIX-4190 | Resultados errados com índices de locais |
| BUG-88774 | HIVE-17617, HIVE-18413, HIVE-18523 | falha de query36, incompatibilidade de contagem de linhas |
| BUG-89765 | HIVE-17702 | isRepeating incorreto tratamento no leitor decimal no ORC |
| BUG 92293 | HADOOP-15042 | o Azure PageBlobInputStream.skip() pode retornar um valor negativo quando numberOfPagesRemaining for 0 |
| BUG 92345 | ATLAS-2285 | Interface do usuário: pesquisa salva renomeada com o atributo de data. |
| BUG-92563 | HIVE-17495, HIVE-18528 | estatísticas agregadas em ObjectStore obtém resultado incorreto |
| BUG-92957 | HIVE-11266 | contagem(*) resultado incorreto com base nas estatísticas de tabela para tabelas externas |
| BUG 93097 | RANGER-1944 | O filtro de ação para auditoria de administrador não está funcionando |
| BUG-93335 | HIVE-12315 | vectorization_short_regress.q tem um problema de resultado incorreto para um cálculo duplo |
| BUG 93415 | HIVE-18258, HIVE-18310 | vetorização: reduzir lado do GRUPO POR MERGEPARTIAL com colunas duplicadas é interrompida |
| BUG-93939 | ATLAS-2294 | "Descrição" de parâmetro extra durante a criação de um tipo |
| BUG-94007 | PHOENIX-1751, PHOENIX-3112 | As consultas de Phoenix retornam valores Null devido a linhas parciais HBase |
| BUG-94266 | HIVE-12505 | Inserir substituição na mesma zona criptografada falha silenciosamente para remover alguns arquivos existentes |
| BUG-94414 | HIVE-15680 | resultados incorretos quando hive.optimize.index.filter=true e a mesma tabela ORC é referenciada duas vezes na consulta, no modo de MR |
| BUG-95048 | HIVE-18490 | Consulta com EXISTS e NOT EXISTS com predicado não equip pode produzir o resultado incorreto |
| BUG-95053 | PHOENIX-3865 | IS NULL não retorna resultados corretos quando a primeira família de coluna não for filtrada |
| BUG-95476 | RANGER-1966 | Inicialização do mecanismo de política não cria os enriquecedores de contexto em alguns casos |
| BUG-95566 | SPARK-23281 | A consulta produz resultados em ordem incorreta, quando uma composição cláusula order por faz referência a colunas originais e aliases |
| BUG-95907 | PHOENIX-3451, PHOENIX-3452, PHOENIX-3469, PHOENIX-4560 | Corrigindo problemas com ORDER BY ASC, quando a consulta tem agregação |
| BUG-96389 | PHOENIX-4586 | UPSERT SELECT não usa operadores de comparação de conta para subconsultas. |
| BUG-96602 | HIVE-18660 | PCR não distingue entre partição e colunas virtuais |
| BUG-97686 | ATLAS-2468 | [Pesquisa básica] problema com casos OR quando NEQ é usado com tipos numéricos |
| BUG-97708 | HIVE-18817 | exceção de ArrayIndexOutOfBounds durante a leitura da tabela ACID. |
| BUG-97864 | HIVE-18833 | mesclagem automática falha ao "inserir no diretório como orcfile" |
| BUG-97889 | RANGER-2008 | A avaliação de política está falhando para condições da política de várias linhas. |
| BUG-98655 | RANGER-2066 | O acesso de família de coluna do HBase é autorizado por uma coluna marcada na família de colunas |
| BUG-99883 | HIVE-19073, HIVE-19145 | StatsOptimizer pode desconfigurar as colunas de constante |
Outras
| ID do bug | Apache JIRA | Resumo |
|---|---|---|
| BUG-100267 | HBASE-17170 | O HBase também está repetindo DoNotRetryIOException devido às diferenças de carregador de classe. |
| BUG-92367 | YARN-7558 | o comando de logs do yarn falha ao obter logs para executar os contêineres, se a autenticação de interface do usuário estiver habilitada. |
| BUG-93159 | OOZIE-3139 | O Oozie valida incorretamente o fluxo de trabalho |
| BUG-93936 | ATLAS-2289 | Código de iniciar/parar servidor inserido/do BUG-100019 inserido será movido para fora da implementação de KafkaNotification |
| BUG-93942 | ATLAS-2312 | Usar objetos de ThreadLocal DateFormat para evitar o uso simultâneo de vários threads |
| BUG-93946 | ATLAS-2319 | Interface do usuário: excluir uma marca que na posição 25+ na lista de marcas nas estruturas de Árvore e Plana precisa de uma atualização para remover a marca da lista. |
| BUG-94618 | YARN-5037, YARN-7274 | Capacidade de desabilitar a elasticidade no nível da fila de folha |
| BUG 94901 | HBASE-19285 | Adicionar histogramas de latência por tabela |
| BUG-95259 | HADOOP-15185, HADOOP-15186 | Atualizar o conector adls para usar a versão atual do SDK do ADLS |
| BUG 95619 | HIVE-18551 | Vetorização: VectorMapOperator tenta gravar muitas colunas de vetor para Hybrid Grace |
| BUG-97223 | SPARK-23434 | O Spark não deveria avisar o `diretório de metadados` para um caminho de arquivo HDFS |
Desempenho
| ID do bug | Apache JIRA | Resumo |
|---|---|---|
| BUG-83282 | HBASE-13376, HBASE-14473, HBASE-15210, HBASE-15515, HBASE-16570, HBASE-16810, HBASE-18164 | Computação de localidade rápida no balanceador |
| BUG-91300 | HBASE-17387 | Reduzir a sobrecarga de relatório de exceção no RegionActionResult para multi () |
| BUG-91804 | TEZ-1526 | LoadingCache para TezTaskID lento para trabalhos grandes |
| BUG-92760 | ACCUMULO-4578 | Cancelar a operação FATE de compactação não liberar a trava do namespace |
| BUG-93577 | RANGER-1938 | Solr para configuração de auditoria não usa DocValues efetivamente |
| BUG-93910 | HIVE-18293 | O Hive está falhando ao compactar as tabelas contidas em uma pasta que não pertence à identidade que executa o HiveMetaStore |
| BUG-94345 | HIVE-18429 | A compactação deve lidar com um caso quando ele não produz nenhuma saída |
| BUG-94381 | HADOOP-13227, HDFS-13054 | Tratando o pedido de RequestHedgingProxyProvider RetryAction: FAIL < RETRY < FAILOVER_AND_RETRY. |
| BUG-94432 | HIVE-18353 | O CompactorMR deve chamar jobclient.close() para disparar a limpeza |
| BUG-94869 | PHOENIX-4290, PHOENIX-4373 | Linha solicitada fora do intervalo para Get em HRegion da tabela local indexada e salgada do Phoenix. |
| BUG-94928 | HDFS-11078 | Corrigir NPE em LazyPersistFileScrubber |
| BUG-94964 | HIVE-18269, HIVE-18318, HIVE-18326 | Várias correções LLAP |
| BUG-95669 | HIVE-18577, HIVE-18643 | Ao executar uma consulta de atualização/exclusão em uma tabela particionada ACID, o HS2 lê todas as partições. |
| BUG-96390 | HDFS-10453 | O thread do ReplicationMonitor poderá ficar travado por muito tempo devido à corrida entre a replicação e a exclusão do mesmo arquivo em um cluster grande. |
| BUG-96625 | HIVE-16110 | Reversão de "Vetorização: suporte a 2 valores CASE WHEN em vez de fallback para VectorUDFAdaptor" |
| BUG-97109 | HIVE-16757 | Uso de getRows() preterido, em vez de novo estimateRowCount(RelMetadataQuery...) tem impacto no desempenho sério |
| BUG-97110 | PHOENIX-3789 | Executar chamadas de manutenção de índice de região no postBatchMutateIndispensably |
| BUG-98833 | YARN-6797 | TimelineWriter não consome totalmente a resposta de POSTAGEM |
| BUG 98931 | ATLAS-2491 | Atualizar gancho Hive para usar notificações do Atlas v2 |
Perda de dados potencial
| ID do bug | Apache JIRA | Resumo |
|---|---|---|
| BUG-95613 | HBASE-18808 | Check-in de configuração ineficaz BackupLogCleaner#getDeletableFiles() |
| BUG-97051 | HIVE-17403 | Falha de concatenação para tabelas transacionais e não gerenciados |
| BUG-97787 | HIVE-18460 | O compactador não passa as propriedades da tabela para o gravador de Orc |
| BUG-97788 | HIVE-18613 | Estender JsonSerDe para dar suporte ao tipo BINÁRIO |
Falha na consulta
| ID do bug | Apache JIRA | Resumo |
|---|---|---|
| BUG-100180 | CALCITE-2232 | Erro de asserção em AggregatePullUpConstantsRule ao ajustar índices de agregação |
| BUG-100422 | HIVE-19085 | FastHiveDecimal abs(0) define o sinal como +ve |
| BUG-100834 | PHOENIX-4658 | IllegalStateException: requestSeek não pode ser chamado em ReversedKeyValueHeap |
| BUG-102078 | HIVE-17978 | Consultas TPCDS 58 e 83 geram exceções na vetorização. |
| BUG-92483 | HIVE-17900 | analisar estatísticas em colunas disparadas por Compactador gera SQL malformado com > coluna de partição 1 |
| BUG-93135 | HIVE-15874, HIVE-18189 | Consulta de Hive, retornando resultados incorretos quando definido hive.groupby.orderby.position.alias como true |
| BUG-93136 | HIVE-18189 | A ordem por posição não funciona quando cbo está desabilitado |
| BUG-93595 | HIVE-12378, HIVE-15883 | Tabela mapeada HBase no Hive insere falha para décimo |
| BUG-94007 | PHOENIX-1751, PHOENIX-3112 | As consultas de Phoenix retornam valores Null devido a linhas parciais HBase |
| BUG-94144 | HIVE-17063 | a inserção de uma partição de substituição em uma tabela externa falha quando a partição é removida primeiro |
| BUG-94280 | HIVE-12785 | Exibição com o tipo de união e UDF para o `struct` que está rompido |
| BUG-94505 | PHOENIX-4525 | estouro de inteiro na execução GroupBy |
| BUG-95618 | HIVE-18506 | LlapBaseInputFormat - índice negativo da matriz |
| BUG-95644 | HIVE-9152 | CombineHiveInputFormat: consulta de Hive está falhando no Tez com exceção de java.lang.IllegalArgumentException |
| BUG-96762 | PHOENIX-4588 | Clonar expressão também se os filhos tiverem Determinism.PER_INVOCATION |
| BUG-97145 | HIVE-12245, HIVE-17829 | Comentários de coluna de suporte para um HBase com suporte de tabela |
| BUG-97741 | HIVE-18944 | A posição dos conjuntos de agrupamento foi definida incorretamente durante o DPP |
| BUG-98082 | HIVE-18597 | LLAP: sempre empacote o jar da API log4j2 para org.apache.log4j |
| BUG-99849 | N/D | Criar uma nova tabela a partir de um Assistente de arquivo que tenta usar o banco de dados padrão |
Segurança
| ID do bug | Apache JIRA | Resumo |
|---|---|---|
| BUG-100436 | RANGER-2060 | O proxy do Knox com não knox-sso está funcionando para o ranger |
| BUG 101038 | SPARK-24062 | Erro de "Conexão recusada", "uma chave secreta deve ser especificada..." Erro no HiveThriftServer de interpretador do Zeppelin % Spark |
| BUG-101359 | ACCUMULO-4056 | Versão de atualização da coleção de commons para 3.2.2 quando lançado |
| BUG-54240 | HIVE-18879 | Não permitir o elemento inserido na UDFXPathUtil precisa funcionar se xercesImpl. jar no classpath |
| BUG-79059 | OOZIE-3109 | Escapar os caracteres específicos HTM dos streamings de log |
| BUG-90041 | OOZIE-2723 | A Licença JSON.org agora é CatX |
| BUG-93754 | RANGER-1943 | A autorização do Ranger Solr é ignorada quando a coleção está vazia ou nula |
| BUG-93804 | HIVE-17419 | ANALISAR TABELA... COMPUTAR ESTATÍSTICAS PARA COLUNAS o comando exibe as estatísticas computadas para as tabelas mascaradas |
| BUG-94276 | ZEPPELIN-3129 | Interface do usuário do Zeppelin não sair no Internet Explorer |
| BUG-95349 | ZOOKEEPER-1256, ZOOKEEPER-1901 | Atualizar netty |
| BUG-95483 | N/D | Correção para CVE-2017-15713 |
| BUG-95646 | OOZIE-3167 | Versão de atualização do tomcat na ramificação de Oozie 4.3 |
| BUG-95823 | N/D |
Knox: Upgrade Beanutils |
| BUG-95908 | RANGER-1960 | HBase auth não considera o namespace da tabela de consideração para a exclusão de instantâneo |
| BUG-96191 | FALCON-2322, FALCON-2323 | Atualizar versões Jackson e Spring para evitar vulnerabilidades de segurança |
| BUG-96502 | RANGER-1990 | Adicionar o suporte MySQL One-way no Administrador do Rager |
| BUG-96712 | FLUME-3194 | atualizar derby para a versão mais recente (1.14.1.0) |
| BUG-96713 | FLUME-2678 | Atualizar xalan para 2.7.2 para cuidar da vulnerabilidade de CVE-2014-0107 |
| BUG-96714 | FLUME 2050 | Upgrade para log4j2 (quando GA) |
| BUG-96737 | N/D | Usar métodos de sistema de arquivos de e/s do Java para acessar arquivos locais |
| BUG-96925 | N/D | Atualizar Tomcat 6.0.48 para 6.0.53 no Hadoop |
| BUG-96977 | FLUME-3132 | Atualize as dependências da biblioteca jasper do tomcat |
| BUG-97022 | HADOOP-14799, HADOOP-14903, HADOOP-15265 | Atualizar biblioteca Nimbus-JOSE-JWT com uma versão acima 4.39 |
| BUG-97101 | RANGER-1988 | Corrigir aleatoriedade insegura |
| BUG-97178 | ATLAS-2467 | Dependência de atualização para o Spring e nimbus-jose-jwt |
| BUG-97180 | N/D | Atualização de Nimbus jose-jwt |
| BUG-98038 | HIVE-18788 | Limpar entradas no JDBC PreparedStatement |
| BUG-98353 | HADOOP-13707 | Reversão de "Se o kerberos estiver habilitado enquanto o HTTP SPNEGO não estiver configurado, alguns links não poderão ser acessados" |
| BUG-98372 | HBASE-13848 | Senhas de acesso InfoServer SSL por meio da API do provedor de credenciais |
| BUG-98385 | ATLAS-2500 | Adicione mais cabeçalhos à resposta do Atlas. |
| BUG-98564 | HADOOP-14651 | Atualizar versão okhttp para 2.7.5 |
| BUG-99440 | RANGER-2045 | As colunas da tabela Hive sem nenhuma política explícita estão listadas com o comando “desc table” |
| BUG-99803 | N/D | Oozie deve desabilitar o carregamento de classe dinâmica do HBase |
Estabilidade
| ID do bug | Apache JIRA | Resumo |
|---|---|---|
| BUG-100040 | ATLAS-2536 | NPE em Atlas Hive Hook |
| BUG-100057 | HIVE-19251 | ObjectStore.getNextNotification com limite deve usar menos memória |
| BUG-100072 | HIVE-19130 | A NPE é lançada quando a carga REPL aplicou eventos de partição de destino. |
| BUG-100073 | N/D | muitas conexões close_wait do hiveserver para o nó de dados |
| BUG-100319 | HIVE-19248 | CARGA de REPL não gerar erro se a cópia do arquivo falhar. |
| BUG-100352 | N/D | CLONE - lógica de limpeza do RM examina /registry znode com muita frequência |
| BUG-100427 | HIVE-19249 | Replicação: a cláusula WITH não está passando a configuração para a tarefa corretamente em todos os casos |
| BUG-100430 | HIVE-14483 | java.lang.ArrayIndexOutOfBoundsException org.apache.orc.impl.TreeReaderFactory$BytesColumnVectorUtil.commonReadByteArrays |
| BUG-100432 | HIVE-19219 | O incremento de REPL incremental deve lançar erro, se solicitado a eventos são limpas. |
| BUG-100448 | SPARK-23637, SPARK-23802, SPARK-23809, SPARK-23816, SPARK-23822, SPARK-23823, SPARK-23838, SPARK-23881 | Atualização de Spark2 para 2.3.0+ (4/11) |
| BUG-100740 | HIVE-16107 | JDBC: HttpClient deverá repetir mais uma vez no NoHttpResponseException |
| BUG 100810 | HIVE-19054 | Falha de replicação de funções de hive |
| BUG 100937 | MAPREDUCE-6889 | Adicione a API Job#close para desligar os serviços do cliente MR. |
| BUG 101065 | ATLAS-2587 | Defina a ACL de leitura para o znode /apache_atlas/active_server_info no HA para que o proxy Knox possa ler. |
| BUG 101093 | STORM-2993 | O bolt do Storm HDFS lança ClosedChannelException quando a política de rotação de tempo é usada |
| BUG 101181 | N/D | PhoenixStorageHandler não trata AND no predicado corretamente |
| BUG-101266 | PHOENIX-4635 | Vazamento de Conexão de HBase em org.apache.phoenix.hive.mapreduce.PhoenixInputFormat |
| BUG 101458 | HIVE-11464 | informações de linhagem ausentes se houver várias saídas |
| BUG-101485 | N/D | thrift de metastore do hive api é lento a faz com que causa o tempo limite ao cliente |
| BUG-101628 | HIVE-19331 | Falha na replicação incremental de hive para a nuvem. |
| BUG-102048 | HIVE-19381 | Falha de replicação de função do hive para a nuvem com FunctionTask |
| BUG-102064 | N/D | Falha nos testes de \[ onprem to onprem \] de Replicação do Hive em ReplCopyTask |
| BUG-102137 | HIVE-19423 | Falha nos testes de \[ Onprem to Cloud \] de Replicação do Hive em ReplCopyTask |
| BUG-102305 | HIVE-19430 | Despejos de OOM do HS2 e metastore do Hive |
| BUG-102361 | N/D | resultados de inserção múltipla em uma única inserção replicada para o cluster do hive de destino ( onprem - s3 ) |
| BUG-87624 | N/D | Habilitar os loggins de evento stom faz com que os trabalhadores continuem a morrer |
| BUG-88929 | HBASE-15615 | Tempo de suspensão errado quando RegionServerCallable precisar tentar novamente |
| BUG-89628 | HIVE-17613 | remover pools de objeto para alocações curtas e o mesmo thread |
| BUG 89813 | N/D | SCA: Correção de código: método sincronizado de substituições de método não sincronizadas |
| BUG-90437 | ZEPPELIN-3072 | a interface do usuário do Zeppelin não se torna lenta/irresponsivva se houver muitas anotações |
| BUG-90640 | HBASE-19065 | HRegion#bulkLoadHFiles() deve esperar a Region#flush() concorrente para concluir |
| BUG 91202 | HIVE-17013 | Solicitação de exclusão com uma subconsulta com base na seleção em uma exibição |
| BUG-91350 | KNOX-1108 | NiFiHaDispatch não fazendo failover |
| BUG-92054 | HIVE-13120 | propagar doAs quando gerar ORC divide |
| BUG-92373 | FALCON-2314 | Versão de TestNG rugosidade para 6.13.1 para evitar a dependência de BeanShell |
| BUG 92381 | N/D | Falha de UT testContainerLogsWithNewAPI e testContainerLogsWithOldAPI |
| BUG-92389 | STORM-2841 | testNoAcksIfFlushFails UT falha com NullPointerException |
| BUG-92586 | SPARK-17920, SPARK-20694, SPARK-21642, SPARK-22162, SPARK-22289, SPARK-22373, SPARK-22495, SPARK-22574, SPARK-22591, SPARK-22595, SPARK-22601, SPARK-22603, SPARK-22607, SPARK-22635, SPARK-22637, SPARK-22653, SPARK-22654, SPARK-22686, SPARK-22688, SPARK-22817, SPARK-22862, SPARK-22889, SPARK-22972, SPARK-22975, SPARK-22982, SPARK-22983, SPARK-22984, SPARK-23001, SPARK-23038, SPARK-23095 | Atualização do Spark2 para a versão 2.2.1 (16 de janeiro) |
| BUG-92680 | ATLAS-2288 | Exceção NoClassDefFoundError durante a execução de script do hive de importação quando a tabela do hbase é criada por meio do Hive |
| BUG-92760 | ACCUMULO-4578 | Cancelar a operação FATE de compactação não liberar a trava do namespace |
| BUG 92797 | HDFS-10267, HDFS-8496 | Reduzindo as contenções de bloqueio datanode em determinados casos de uso |
| BUG-92813 | FLUME-2973 | Um deadlock no coletor do hdfs |
| BUG-92957 | HIVE-11266 | contagem(*) resultado incorreto com base nas estatísticas de tabela para tabelas externas |
| BUG-93018 | ATLAS-2310 | Em HA, o nó passivo redireciona a solicitação com codificação de URL errado |
| BUG-93116 | RANGER-1957 | O Usersync do Ranger não está sincronizando usuários ou grupos periodicamente quando a sincronização incremental está habilitada. |
| BUG-93361 | HIVE-12360 | Busca incorreta no ORC não compactado com a aplicação de predicado |
| BUG-93426 | CALCITE-2086 | HTTP/413 em determinadas circunstâncias, devido à grandes cabeçalhos de autorização |
| BUG-93429 | PHOENIX-3240 | ClassCastException do carregador de Pig |
| BUG-93485 | N/D | não é possível obter a tabela mytestorg.apache.hadoop.hive.ql.metadata.InvalidTableException: tabela não encontrada ao executar a análise de tabela em colunas no LLAP |
| BUG-93512 | PHOENIX-4466 | código de resposta 500 - executar um trabalho do spark para conectar-se ao servidor de consulta phoenix e carregar dados |
| BUG-93550 | N/D | Zeppelin %spark.r não funciona com spark1 devido à incompatibilidade de versão do scala |
| BUG-93910 | HIVE-18293 | O Hive está falhando ao compactar as tabelas contidas em uma pasta que não pertence à identidade que executa o HiveMetaStore |
| BUG-93926 | ZEPPELIN-3114 | Blocos de anotações e interpretadores não estão sendo salvos no zeppelin após >1d de teste de estresse |
| BUG-93932 | ATLAS-2320 | classificação de "*" com a consulta gera exceção de servidor interno 500. |
| BUG-93948 | YARN-7697 | NM falha com OOM devido a vazamento na agregação de registro (parte#1) |
| BUG-93965 | ATLAS-2229 | Pesquisa DSL: atributo de cadeia de caracteres fora de ordem lança a exceção |
| BUG-93986 | YARN-7697 | NM falha com OOM devido a vazamento na agregação de registro (parte#2) |
| BUG-94030 | ATLAS-2332 | Criação do tipo com tendo aninhadas de tipo de dados de coleção de atributos |
| BUG-94080 | YARN-3742, YARN-6061 | Ambos os RM estão no modo de espera em um cluster seguro |
| BUG-94081 | HIVE-18384 | ConcurrentModificationException na biblioteca log4j2.x |
| BUG-94168 | N/D | Yarn RM falha com o registro do serviço está no estado errado erro |
| BUG-94330 | HADOOP-13190, HADOOP-14104, HADOOP-14814, HDFS-10489, HDFS-11689 | O HDFS deve oferecer suporte a vários KMS Uris |
| BUG-94345 | HIVE-18429 | A compactação deve lidar com um caso quando ele não produz nenhuma saída |
| BUG-94372 | ATLAS-2229 | Consulta DSL: hive_table name = ["t1","t2"] lança exceções de consulta inválida DSL |
| BUG-94381 | HADOOP-13227, HDFS-13054 | Tratando o pedido de RequestHedgingProxyProvider RetryAction: FAIL < RETRY < FAILOVER_AND_RETRY. |
| BUG-94432 | HIVE-18353 | O CompactorMR deve chamar jobclient.close() para disparar a limpeza |
| BUG-94575 | SPARK-22587 | Trabalho do Spark falhará se o jar do aplicativo e FS. defaultfs é outra url |
| BUG-94791 | SPARK-22793 | Vazamento de memória no servidor Thrift Spark |
| BUG-94928 | HDFS-11078 | Corrigir NPE em LazyPersistFileScrubber |
| BUG-95013 | HIVE-18488 | Leitores LLAP ORC estão faltando algumas verificações nulas. |
| BUG-95077 | HIVE-14205 | O Hive não dá suporte a tipo de união com o formato de arquivo do AVRO |
| BUG-95200 | HDFS-13061 | SaslDataTransferClient#checkTrustAndSend não deve confiar em um canal parcialmente confiável |
| BUG 95201 | HDFS-13060 | Adicionando um BlacklistBasedTrustedChannelResolver para TrustedChannelResolver |
| BUG-95284 | HBASE-19395 | [branch-1] TestEndToEndSplitTransaction.testMasterOpsWhileSplitting falha com NPE |
| BUG-95301 | HIVE-18517 | Vetorização: corrigir VectorMapOperator para aceitar VRBs e verificar o sinalizador vetorizado corretamente para dar suporte a cache LLAP |
| BUG-95542 | HBASE-16135 | PeerClusterZnode sob rs do par removido nunca poderá ser excluída |
| BUG-95595 | HIVE-15563 | Ignorar exceção de transição de estado de Operação Ilegal no SQLOperation.runQuery para expor a exceção real. |
| BUG-95596 | YARN-4126, YARN-5750 | Falha de TestClientRMService |
| BUG-96019 | HIVE-18548 | Corrigir importação de log4j |
| BUG-96196 | HDFS-13120 | Diferença de instantâneo poderia ser corrompida após concat |
| BUG-96289 | HDFS-11701 | NPE do Host não resolvido causa falhas de DFSInputStream permanentes |
| BUG-96291 | STORM-2652 | exceção lançada no método aberto JmsSpout |
| BUG-96363 | HIVE-18959 | Evite criar extra pool de threads na LLAP |
| BUG-96390 | HDFS-10453 | O thread do ReplicationMonitor poderia ficar preso por muito tempo devido à corrida entre a replicação e a exclusão do mesmo arquivo em um cluster grande. |
| BUG-96454 | YARN-4593 | Deadlock na AbstractService.getConfig() |
| BUG-96704 | FALCON-2322 | ClassCastException ao feed submitAndSchedule |
| BUG-96720 | SLIDER-1262 | Os testes de função do controle deslizante estão falhando no ambiente Kerberized |
| BUG-96931 | SPARK-23053, SPARK-23186, SPARK-23230, SPARK-23358, SPARK-23376, SPARK-23391 | Atualização do Spark2 (19 de fevereiro) |
| BUG-97067 | HIVE-10697 | ObjectInspectorConvertors#UnionConvertor faz uma conversão com defeito |
| BUG-97244 | KNOX-1083 | Tempo limite do HttpClient padrão deve ser um valor adequado |
| BUG-97459 | ZEPPELIN-3271 | Opção para desabilitar o agendador |
| BUG-97511 | KNOX-1197 | AnonymousAuthFilter não é adicionado quando authentication=Anonymous está em serviço |
| BUG-97601 | HIVE-17479 | Diretórios de preparo não sejam limpos para atualizar/excluir consultas |
| BUG-97605 | HIVE-18858 | Propriedades do sistema na configuração de trabalho não resolvido ao enviar trabalho MR |
| BUG-97674 | OOZIE-3186 | Oozie é não é possível usar a configuração vinculada usando jceks://file/... |
| BUG-97743 | N/D | exceção de java.lang.NoClassDefFoundError ao implantar a topologia do storm |
| BUG-97756 | PHOENIX-4576 | Correção de testes de LocalIndexSplitMergeIT com falha |
| BUG 97771 | HDFS-11711 | DN não deve excluir o bloco na exceção “Muitos arquivos abertos” |
| BUG-97869 | KNOX-1190 | O suporte de SSO do Knox para o Google OIDC não está funcionando. |
| BUG-97879 | PHOENIX-4489 | vazamento de Conexão de HBase em trabalhos de Phoenix MR |
| BUG-98392 | RANGER-2007 | tíquete de Kerberos do Ranger tagsync falha ao renovar |
| BUG-98484 | N/D | Falha na replicação incremental de hive para a nuvem |
| BUG-98533 | HBASE-19934, HBASE-20008 | Restauração de instantâneo do HBase está falhando devido à exceção de ponteiro Null |
| BUG-98555 | PHOENIX-4662 | NullPointerException em TableResultIterator.java no reenvio de cache |
| BUG-98579 | HBASE-13716 | Parar de usar FSConstants do Hadoop |
| BUG-98705 | KNOX-1230 | Muitas Solicitações Simultâneas para o Knox causam a desconfiguração da URL |
| BUG-98983 | KNOX-1108 | NiFiHaDispatch não fazendo failover |
| BUG-99107 | HIVE-19054 | Replicação de função deve usar "hive.repl.replica.functions.root.dir" como raiz |
| BUG-99145 | RANGER-2035 | Erros ao acessar servicedefs com implClass vazia com o back-end do Oracle |
| BUG-99160 | SLIDER-1259 | O Slider não funciona em multi ambientes de adaptadores de rede |
| BUG-99239 | ATLAS-2462 | Importação do Sqoop para todas as tabelas lança NPE para nenhuma tabela fornecida no comando |
| BUG-99301 | ATLAS-2530 | Nova linha no início do atributo de nome de um of a hive_process e hive_column_lineage |
| BUG-99453 | HIVE-19065 | A verificação de compatibilidade do cliente de Metastore deve incluir syncMetaStoreClient |
| BUG-99521 | N/D | O ServerCache para HashJoin não é recriado quando os iteradores são instanciados novamente |
| BUG-99590 | PHOENIX-3518 | Vazamento de memória em RenewLeaseTask |
| BUG-99618 | SPARK-23599, SPARK-23806 | Atualização do Spark2 para 2.3.0+ (3/28) |
| BUG-99672 | ATLAS-2524 | Hive hook com notificações V2 - incorretas de tratamento de operação “alterar exibição como” |
| BUG-99809 | HBASE-20375 | Remova o uso de getCurrentUserCredentials no módulo do hbase spark |
Capacidade de suporte
| ID do bug | Apache JIRA | Resumo |
|---|---|---|
| BUG-87343 | HIVE-18031 | Replicação de suporte para a operação Alter Database. |
| BUG 91293 | RANGER-2060 | O proxy do Knox com não knox-sso está funcionando para o ranger |
| BUG-93116 | RANGER-1957 | O Usersync do Ranger não está sincronizando usuários ou grupos periodicamente quando a sincronização incremental está habilitada. |
| BUG-93577 | RANGER-1938 | Solr para configuração de auditoria não usa DocValues efetivamente |
| BUG-96082 | RANGER-1982 | Melhoria de Erro para a Métrica de Análise de Administrador do Ranger e Kms de Ranger |
| BUG-96479 | HDFS-12781 | Após a desativação do Datanode, na guia Datanode da interface do usuário Namenode, está sendo exibida uma mensagem de aviso. |
| BUG-97864 | HIVE-18833 | mesclagem automática falha ao "inserir no diretório como orcfile" |
| BUG-98814 | HDFS-13314 | NameNode deve sair, opcionalmente, se ele detectar corrupção FsImage |
Atualizar
| ID do bug | Apache JIRA | Resumo |
|---|---|---|
| BUG-100134 | SPARK-22919 | Reverter de "Versões do httpclient tapa Apache" |
| BUG-95823 | N/D |
Knox: Upgrade Beanutils |
| BUG-96751 | KNOX-1076 | Atualizar nimbus-jose-jwt para 4.41.2 |
| BUG-97864 | HIVE-18833 | mesclagem automática falha ao "inserir no diretório como orcfile" |
| BUG-99056 | HADOOP-13556 | Alterar Configuration.getPropsWithPrefix para usar getProps em vez de iterador |
| BUG-99378 | ATLAS-2461, ATLAS-2554 | Utilitário de migração para exportar dados do Atlas no grafo Titan DB |
Usabilidade
| ID do bug | Apache JIRA | Resumo |
|---|---|---|
| UG-100045 | HIVE-19056 | IllegalArgumentException em FixAcidKeyIndex ao arquivo ORC tem 0 linhas |
| BUG-100139 | KNOX-1243 | Normalizar os DNs necessários que estão configurados no serviço KnoxToken |
| BUG-100570 | ATLAS-2557 | Correção para permitir a criação de grupos ldap do hadoop lookup quando os grupos de UGI estiverem definidos incorretamente ou não estiverem vazios |
| BUG-100646 | ATLAS-2102 | Aprimoramentos de interface do usuário do Atlas: página de resultados da pesquisa |
| BUG-100737 | HIVE-19049 | Adicionar suporte a tabela Alter adicionar colunas para Druid |
| BUG-100750 | KNOX-1246 | Atualize a configuração de serviço no Knox para oferecer suporte às configurações mais recentes do Ranger. |
| BUG 100965 | ATLAS-2581 | Regressão com as notificação de Hive Hook V2: movendo a tabela para banco de dados diferentes |
| BUG-84413 | ATLAS-1964 | Interface do usuário: auporte a ordem de colunas na tabela de pesquisa |
| BUG-90570 | HDFS-11384, HDFS-12347 | Adicione a opção o balanceador para dispersar as chamadas getBlocks para evitar pico no rpc.CallQueueLength do NameNode |
| BUG-90584 | HBASE-19052 | FixedFileTrailer deve reconhecer a classe CellComparatorImpl no branch-1. x |
| BUG 90979 | KNOX-1224 |
HADispatcher do Proxy do Knox para dar suporte ao Atlas em HA. |
| BUG 91293 | RANGER-2060 | O proxy do Knox com knox-sso não está funcionando para o Ranger |
| BUG-92236 | ATLAS-2281 | Salvando consultas de filtro do tipo de marca/atributo com filtros de null/not null. |
| BUG-92238 | ATLAS-2282 | Pesquisa salva favorita aparece somente na atualização após a criação quando há mais de 25 pesquisas favoritas. |
| BUG-92333 | ATLAS-2286 | Pré-criados em tipo 'kafka_topic' não devem declarar o atributo 'tópico' como exclusivo |
| BUG-92678 | ATLAS-2276 | Valor do caminho para a entidade do tipo de hdfs_path é definido em letras minúsculas de ponte de hive. |
| BUG 93097 | RANGER-1944 | O filtro de ação para auditoria de administrador não está funcionando |
| BUG-93135 | HIVE-15874, HIVE-18189 | Consulta de Hive, retornando resultados incorretos quando definido hive.groupby.orderby.position.alias como true |
| BUG-93136 | HIVE-18189 | A ordem por posição não funciona quando cbo está desabilitado |
| BUG-93387 | HIVE-17600 | Tornar a enforceBufferSize do OrcFile definível pelo usuário. |
| BUG-93495 | RANGER-1937 | O Ranger tagsync deve processar a notificação ENTITY_CREATE para oferecer suporte ao recurso de importação do Atlas |
| BUG-93512 | PHOENIX-4466 | código de resposta 500 - executar um trabalho do spark para conectar-se ao servidor de consulta phoenix e carregar dados |
| BUG-93801 | HBASE-19393 | Cabeçalho completo HTTP 413 acessando HBase da interface do usuário usando SSL. |
| BUG-93804 | HIVE-17419 | ANALISAR TABELA... COMPUTAR ESTATÍSTICAS PARA COLUNAS o comando exibe as estatísticas computadas para as tabelas mascaradas |
| BUG-93932 | ATLAS-2320 | classificação de "*" com a consulta gera exceção de servidor interno 500. |
| BUG-93933 | ATLAS-2286 | Pré-criados em tipo 'kafka_topic' não devem declarar o atributo 'tópico' como exclusivo |
| BUG-93938 | ATLAS-2283, ATLAS-2295 | Atualizações da interface do usuário para as classificações |
| BUG-93941 | ATLAS-2296, ATLAS-2307 | Aprimoramento básico de pesquisa para excluir opcionalmente entidades de subtipo e tipos de subclassificação |
| BUG-93944 | ATLAS-2318 | Interface do usuário: ao clicar duas vezes na marca secundária, a marca principal é selecionada |
| BUG-93946 | ATLAS-2319 | Interface do usuário: excluir uma marca que na posição 25+ na lista de marcas nas estruturas de Árvore e Plana precisa de uma atualização para remover a marca da lista. |
| BUG-93977 | HIVE-16232 | O suporte a computação de estatísticas para colunas em QuotedIdentifier |
| BUG-94030 | ATLAS-2332 | Criação do tipo com tendo aninhadas de tipo de dados de coleção de atributos |
| BUG-94099 | ATLAS-2352 | O servidor do Atlas deve fornecer a configuração para especificar a validade para Kerberos DelegationToken |
| BUG-94280 | HIVE-12785 | Exibição com o tipo de união e UDF para o `struct` que está rompido |
| BUG-94332 | SQOOP-2930 | Exec de trabalho de Sqoop não substitui as propriedades genéricas de trabalho salvas |
| BUG-94428 | N/D | Suporte do Knox à API REST do Agente do Profiler Dataplane |
| BUG-94514 | ATLAS-2339 | Interface do usuário: Modificações no "colunas" no modo de exibição de resultado de pesquisa básica afeta DSL também. |
| BUG-94515 | ATLAS-2169 | Excluir falhas de solicitação quando a exclusão ríida for configurada |
| BUG-94518 | ATLAS-2329 | A interface do usuário do Atlas de Vários Focos aparece se o usuário clicar em outra marca que estiver incorreta |
| BUG-94519 | ATLAS-2272 | Salve o estado de colunas arrastadas usando a API de pesquisa de salvamento. |
| BUG-94627 | HIVE-17731 | adicionar uma opção de compat de retrocesso para usuários externos ao HIVE-11985 |
| BUG-94786 | HIVE-6091 | São criados arquivos pipeout vazios para a criação/fechamento de conexões |
| BUG-94793 | HIVE-14013 | Descrever a tabela não mostra unicode corretamente |
| BUG-94900 | OOZIE-2606, OOZIE-2658, OOZIE-2787, OOZIE-2802 | Defina spark.yarn.jars para corrigir Spark 2.0 com Oozie |
| BUG 94901 | HBASE-19285 | Adicionar histogramas de latência por tabela |
| BUG-94908 | ATLAS-1921 | Interface do usuário: pesquisar usando os atributos de entidade e característica: interface do usuário não executa verificação de intervalo e permite fornecer os valores dos limites fora para tipos de dados integrais e float. |
| BUG-95086 | RANGER-1953 | melhoria na lista da página do grupo de usuários |
| BUG-95193 | SLIDER-1252 | O agente Slider falha com erros de validação de SSL com o Python 2.7.5-58 |
| BUG-95314 | YARN-7699 | queueUsagePercentage está vindo como INF para a chamada da API REST getApp |
| BUG-95315 | HBASE-13947, HBASE-14517, HBASE-17931 | Atribuir as tabelas do sistema para servidores com a versão mais recente |
| BUG-95392 | ATLAS-2421 | Notificação de atualizações para dar suporte a estruturas de dados V2 |
| BUG-95476 | RANGER-1966 | Inicialização do mecanismo de política não cria os enriquecedores de contexto em alguns casos |
| BUG-95512 | HIVE-18467 | Dar suporte a despejo de warehouse inteiro / carregar + criar/remover eventos de banco de dados |
| BUG-95593 | N/D | Estender os utilitários do Oozie DB para dar suporte à criação de Spark2sharelib |
| BUG-95595 | HIVE-15563 | Ignorar exceção de transição de estado de Operação Ilegal no SQLOperation.runQuery para expor a exceção real. |
| BUG-95685 | ATLAS-2422 | Exportação: Exportação de baseada no tipo de suporte |
| BUG 95798 | PHOENIX-2714, PHOENIX-2724, PHOENIX-3023, PHOENIX-3040 | Não use balizas para executar consultas em série |
| BUG-95969 | HIVE-16828, HIVE-17063, HIVE-18390 | Modo de exibição particionado falha com FAILED: índice IndexOutOfBoundsException: 1, tamanho: 1 |
| BUG-96019 | HIVE-18548 | Corrigir importação de log4j |
| BUG-96288 | HBASE-14123, HBASE-14135, HBASE-17850 | Backport HBase Backup/Restauração 2.0 |
| BUG-96313 | KNOX-1119 | OAuth/OpenID de Pac4J Precisa ser Configurável |
| BUG-96365 | ATLAS-2442 | Usuário com permissão somente leitura no recurso de entidade não é possível executar a pesquisa básica |
| BUG-96479 | HDFS-12781 | Após a desativação do Datanode, na guia Datanode da interface do usuário Namenode, está sendo exibida uma mensagem de aviso. |
| BUG-96502 | RANGER-1990 | Adicionar o suporte MySQL One-way no Administrador do Rager |
| BUG-96718 | ATLAS-2439 | Atualizar o Sqoop hook para usar notificações de V2 |
| BUG-96748 | HIVE-18587 | Evento de inserção de DML pode tentar calcular uma soma de verificação em diretórios |
| BUG-96821 | HBASE-18212 | No modo autônomo com sistema de arquivos local, o HBase registra uma mensagem de aviso: Falha ao invocar o método “unbuffer” na classe org.apache.hadoop.fs.FSDataInputStream |
| BUG-96847 | HIVE-18754 | STATUS de REPL deve dar suporte à cláusula “com” |
| BUG-96873 | ATLAS-2443 | Atributos de entidade necessária em mensagens de saída de EXCLUSÃO de captura |
| BUG-96880 | SPARK-23230 | Quando hive.default.fileformat é outro tipo de arquivo, a criação da tabela textfile causa um erro serde |
| BUG-96911 | OOZIE-2571, OOZIE-2792, OOZIE-2799, OOZIE-2923 | Melhorar análise de opções de Spark |
| BUG-97100 | RANGER-1984 | Os registros de log de auditoria do HBase não podem mostrar todas as marcas associadas à coluna acessada |
| BUG-97110 | PHOENIX-3789 | Executar chamadas de manutenção de índice de região no postBatchMutateIndispensably |
| BUG-97145 | HIVE-12245, HIVE-17829 | Comentários de coluna de suporte para um HBase com suporte de tabela |
| BUG-97409 | HADOOP-15255 | suporte de conversão maiusculas e minúsculas para nomes de grupo em LdapGroupsMapping |
| BUG-97535 | HIVE-18710 | estender inheritPerms para ACID no Hive 2. x |
| BUG-97742 | OOZIE-1624 | Padrão de exclusão para JARs sharelib |
| BUG-97744 | PHOENIX-3994 | Prioridade de RPC do índice ainda depende da propriedade de fábrica do controlador no hbase-site.xml |
| BUG-97787 | HIVE-18460 | O compactador não passa as propriedades da tabela para o gravador de Orc |
| BUG-97788 | HIVE-18613 | Estender JsonSerDe para dar suporte ao tipo BINÁRIO |
| BUG-97899 | HIVE-18808 | Tornar a compactação mais robusta, quando a atualização de estatísticas falhar |
| BUG-98038 | HIVE-18788 | Limpar entradas no JDBC PreparedStatement |
| BUG-98383 | HIVE-18907 | Criar um utilitário para corrigir o problema de índice de chave acid do HIVE 18817 |
| BUG-98388 | RANGER-1828 | Boa codificação prática-adicionar cabeçalhos adicionais no ranger |
| BUG-98392 | RANGER-2007 | tíquete de Kerberos do Ranger tagsync falha ao renovar |
| BUG-98533 | HBASE-19934, HBASE-20008 | Restauração de instantâneo do HBase está falhando devido à exceção de ponteiro Null |
| BUG-98552 | HBASE-18083, HBASE-18084 | fazer com que o arquivo grande/pequeno limpe o número de thread configurável no HFileCleaner. |
| BUG-98705 | KNOX-1230 | Muitas Solicitações Simultâneas para o Knox causam a desconfiguração da URL |
| BUG-98711 | N/D | Expedição NiFi não é possível usar o SSL bidirecional sem modificações service.xml |
| BUG-98880 | OOZIE-3199 | Permitir que a restrição de propriedade do sistema configurável |
| BUG 98931 | ATLAS-2491 | Atualizar gancho Hive para usar notificações do Atlas v2 |
| BUG-98983 | KNOX-1108 | NiFiHaDispatch não fazendo failover |
| BUG-99088 | ATLAS-2511 | Fornecer opções seletivamente para importar banco de dados / tabelas do Hive em Atlas |
| BUG-99154 | OOZIE-2844, OOZIE-2845, OOZIE-2858, OOZIE-2885 | A consulta Spark falhou com a exceção "java.io.FileNotFoundException: hive-site.xml (permissão negada)” |
| BUG-99239 | ATLAS-2462 | Importação do Sqoop para todas as tabelas lança NPE para nenhuma tabela fornecida no comando |
| BUG-99636 | KNOX-1238 | Corrigir configurações de Truststore personalizado para o Gateway |
| BUG-99650 | KNOX-1223 | O proxy do Knox do Zeppelin não redireciona /api/ticket como esperado |
| BUG-99804 | OOZIE-2858 | HiveMain, ShellMain e SparkMain não devem substituir as propriedades e os arquivos de configuração localmente |
| BUG-99805 | OOZIE-2885 | Executar ações do Spark não deve precisar de Hive no classpath |
| BUG-99806 | OOZIE-2845 | Substitua o código baseado na reflexão, que define a variável em HiveConf |
| BUG-99807 | OOZIE-2844 | Aumento da estabilidade das ações do Oozie quando log4j.properties está ausente ou não é legível |
| RMP-9995 | AMBARI-22222 | Alternar druid usar diretório /var/druid em vez de /apps/druid no disco local |
Alterações de comportamento
| Componente do Apache | Apache JIRA | Resumo | Detalhes |
|---|---|---|---|
| Spark 2.3 | N/A | Notas de versão de alterações conforme documentado no Apache Spark | -Há um documento de "Substituição" e um guia de "Alteração de comportamento", https://spark.apache.org/releases/spark-release-2-3-0.html#deprecations -Para parte do SQL, há outra guia de “migração” detalhada (de 2.2 a 2.3), https://spark.apache.org/docs/latest/sql-programming-guide.html#upgrading-from-spark-sql-22-to-23| |
| Spark | HIVE-12505 | Trabalho do Spark concluído com êxito, mas há um erro de total de cota de disco HDFS |
Cenário: Em execução inserir substituir quando uma cota é definida na pasta da Lixeira do usuário que executa o comando. Comportamento anterior: o trabalho for bem-sucedido, mesmo que ele não consegue mover os dados para a Lixeira. O resultado incorretamente pode conter alguns dos dados esteja presentes na tabela. Novo comportamento: quando a mudança para a pasta da Lixeira falha, os arquivos serão excluídos permanentemente. |
| Kafka 1.0 | N/A | Notas de versão de alterações conforme documentado no Apache Spark | https://kafka.apache.org/10/documentation.html#upgrade_100_notable |
| Hive / Ranger | Outras políticas de hive do ranger necessárias para INSERT OVERWRITE |
Cenário: outras políticas de hive do ranger necessárias para INSERT OVERWRITE Comportamento anterior: consultas do Hive INSERT OVERWRITE consultas realizadas com êxito como de costume. Novo comportamento: consultas do Hive INSERT OVERWRITE estão falhando inesperadamente após a atualização para HDP 2.6 com o erro: Erro durante a compilação de instrução: FAILED: HiveAccessControlException permissão negada: usuário jdoe não tem privilégios de gravação em /tmp/*(estado = 42000, código = 40000) A partir das consultas HDP-2.6.0 Hive INSERT OVERWRITE exigem uma política de URI do Ranger para permitir operações de gravação, mesmo se o usuário tem o privilégio de gravação concedido por meio da política HDFS. Solução alternativa/esperado ação do cliente: 1. Crie uma nova política do repositório do Hive. 2. Na lista suspensa onde se lê banco de dados, selecione URI. 3. Atualize o caminho (exemplo: /tmp/*) 4. Adicione os usuários e grupos e salve. 5. Tente novamente a consulta inserir. |
|
| HDFS | N/A | O HDFS deve oferecer suporte a vários KMS Uris |
Comportamento anterior: propriedade dfs.encryption.key.provider.uri foi usada para configurar o caminho de provedor do KMS. Novo comportamento: dfs.encryption.key.provider.uri foi preterido em favor de hadoop.security.key.provider.path para configurar o caminho de provedor do KMS. |
| Zeppelin | ZEPPELIN-3271 | Opção para desabilitar o agendador |
Componente afetado: Servidor Zeppelin Comportamento anterior: nas versões anteriores do Zeppelin, não havia nenhuma opção para desabilitar o Agendador. Novo Comportamento: por padrão, os usuários não poderão mais ver o agendador, que fica desabilitado por padrão. Ação do cliente esperado/solução alternativa: se você quiser habilitar o Agendador, você precisará adicionar azeppelin.notebook.cron.enable com valor de true no site do zeppelin personalizados nas configurações do Zeppelin do Ambari. |
Problemas conhecidos
Integração do HDInsight com o ADLS Gen 2 Há dois problemas em clusters do HDInsight ESP que usam o Azure Data Lake Storage Gen 2 com diretórios de usuário e permissões:
Os diretórios base para usuários não estão sendo criados no Nó de Cabeçalho 1. Como solução alternativa, crie os diretórios manualmente e altere a propriedade para o UPN do respectivo usuário.
As permissões no diretório /hdp atualmente não estão definidas como 751. Isso precisa ser definido como
chmod 751 /hdp chmod –R 755 /hdp/apps
Spark 2.3
[SPARK 23523][SQL] resultado incorreto causado pela regra OptimizeMetadataOnlyQuery
[SPARK 23406] autojunções Bugs no fluxo de fluxo
Anotações de amostra do Spark não estão disponíveis quando o Azure Data Lake Storage (Gen2) é o armazenamento padrão do cluster.
Enterprise Security Package
- O servidor Thrift Spark não aceita conexões de clientes do ODBC.
Etapas de solução alternativa:
- Aguarde cerca de 15 minutos após a criação do cluster.
- Verifique o ranger da interface do usuário para a existência de hivesampletable_policy.
- Reinicie o serviço do Spark. A conexão do STS deve trabalhar agora.
- O servidor Thrift Spark não aceita conexões de clientes do ODBC.
Etapas de solução alternativa:
Solução alternativa para falha de verificação de serviço do Ranger
RANGER 1607: solução alternativa para falha de verificação de serviço Ranger durante a atualização para HDP 2.6.2 de versões anteriores do HDP.
Observação
Somente quando o Ranger for SSL habilitado.
Esse problema surge ao tentar atualizar para HDP-2.6.1 das versões HDP anteriores através do Ambari. O Ambari usa uma chamada de curl para fazer uma verificação de serviço a serviço Ranger no Ambari. Se a versão do JDK usada pelo Ambari é JDK 1.7, a chamada de curl falhará com o erro abaixo:
curl: (35) error:14077410:SSL routines:SSL23_GET_SERVER_HELLO:sslv3 alert handshake failureO motivo para esse erro é a versão do tomcat usada no Ranger é Tomcat 7.0.7*. Usar o JDK 1.7 entra em conflito com as codificações de padrão fornecidas no Tomcat 7.0.7*.
Você pode resolver esse problema de duas maneiras:
Atualizar o JDK usado no Ambari do JDK 1.7 para o JDK 1.8 (consulte a seção alterar a versão do JDK no guia de referência do Ambari).
Se você quiser continuar a dar suporte a um ambiente de JDK 1.7:
Adicione a propriedade ranger.tomcat.ciphers na seção site de administração do ranger em sua configuração do Ambari Ranger com o valor abaixo:
SSL_RSA_WITH_RC4_128_MD5, SSL_RSA_WITH_RC4_128_SHA, TLS_RSA_WITH_AES_128_CBC_SHA, SSL_RSA_WITH_3DES_EDE_CBC_SHA
Se seu ambiente estiver configurado para o Ranger KMS, adicione a propriedade ranger.tomcat.ciphers na seção de kms-site-theranger em sua configuração do Ambari Ranger com o valor abaixo:
SSL_RSA_WITH_RC4_128_MD5, SSL_RSA_WITH_RC4_128_SHA, TLS_RSA_WITH_AES_128_CBC_SHA, SSL_RSA_WITH_3DES_EDE_CBC_SHA
Observação
Os valores observados são exemplos de trabalho e podem não representar o seu ambiente. Certifique-se de que corresponda à maneira de definir essas propriedades como o ambiente está configurado.
RangerUI: Escape do texto de condição de política inserido no formato de política
Componente afetado: Ranger
Descrição do problema
Se um usuário quiser criar uma política com condições de política personalizada e houver caracteres especiais no texto, a solicitação de política não funcionará. Caracteres especiais são convertidos em ASCII antes de salvar a política no banco de dados.
Caracteres especiais: & <> " ` '
Por exemplo, a condição tags.attributes['type']='abc' seria convertida para o seguinte quando a política for salva.
tags.attds['dsds']='cssdfs'
Você pode ver a condição da política com esses caracteres, abrindo a política no modo de edição.
Solução alternativa
Opção 1: criar/atualizar política por meio da API Rest do Ranger
REST de URL: http://<host>:6080/service/plugins/policies
Criação de política com a condição da política:
O exemplo a seguir criará uma política com tags como `tags-test` e atribuirá ao `grupo público` com a condição da política astags.attr['type']=='abc' selecionando todas as permissões do componente de seção como selecionar, atualizar, criar, descartar, alterar, indexar, bloquear, todas.
Exemplo:
curl -H "Content-Type: application/json" -X POST http://localhost:6080/service/plugins/policies -u admin:admin -d '{"policyType":"0","name":"P100","isEnabled":true,"isAuditEnabled":true,"description":"","resources":{"tag":{"values":["tags-test"],"isRecursive":"","isExcludes":false}},"policyItems":[{"groups":["public"],"conditions":[{"type":"accessed-after-expiry","values":[]},{"type":"tag-expression","values":["tags.attr['type']=='abc'"]}],"accesses":[{"type":"hive:select","isAllowed":true},{"type":"hive:update","isAllowed":true},{"type":"hive:create","isAllowed":true},{"type":"hive:drop","isAllowed":true},{"type":"hive:alter","isAllowed":true},{"type":"hive:index","isAllowed":true},{"type":"hive:lock","isAllowed":true},{"type":"hive:all","isAllowed":true}]}],"denyPolicyItems":[],"allowExceptions":[],"denyExceptions":[],"service":"tagdev"}'Atualizar a política existente com a condição da política:
O exemplo a seguir atualizará a política com tags como `tags-test` e a atribuirá ao `grupo público` com a condição da política astags.attr['type']=='abc' selecionando todas as permissões do componente de seção como selecionar, atualizar, criar, descartar, alterar, indexar, bloquear, todas.
REST de URL: http://<host-name>:6080/service/plugins/policies/<policy-id>
Exemplo:
curl -H "Content-Type: application/json" -X PUT http://localhost:6080/service/plugins/policies/18 -u admin:admin -d '{"id":18,"guid":"ea78a5ed-07a5-447a-978d-e636b0490a54","isEnabled":true,"createdBy":"Admin","updatedBy":"Admin","createTime":1490802077000,"updateTime":1490802077000,"version":1,"service":"tagdev","name":"P0101","policyType":0,"description":"","resourceSignature":"e5fdb911a25aa7f77af5a9546938d9ed","isAuditEnabled":true,"resources":{"tag":{"values":["tags"],"isExcludes":false,"isRecursive":false}},"policyItems":[{"accesses":[{"type":"hive:select","isAllowed":true},{"type":"hive:update","isAllowed":true},{"type":"hive:create","isAllowed":true},{"type":"hive:drop","isAllowed":true},{"type":"hive:alter","isAllowed":true},{"type":"hive:index","isAllowed":true},{"type":"hive:lock","isAllowed":true},{"type":"hive:all","isAllowed":true}],"users":[],"groups":["public"],"conditions":[{"type":"ip-range","values":["tags.attributes['type']=abc"]}],"delegateAdmin":false}],"denyPolicyItems":[],"allowExceptions":[],"denyExceptions":[],"dataMaskPolicyItems":[],"rowFilterPolicyItems":[]}'Opção nº2: Aplicar mudanças em Javascript
Etapas para atualizar o arquivo JS:
Localizar o arquivo PermissionList.js em /usr/hdp/current/ranger-admin
Localizar a definição de função renderPolicyCondtion (nº de linha: 404).
Remova a linha a seguir dessa função, ou seja, em Exibir função (nº de linha: 434)
val = _.escape(val);//Line No:460
Depois de remover a linha acima, a interface do usuário do Ranger permitirá que você crie políticas com a condição da política que pode conter caracteres especiais e a política de avaliação será bem-sucedida para a mesma política.
Integração do HDInsight com o ADLS Gen 2: problemas de diretórios e permissões de usuário com clusters do ESP 1. Os diretórios base para usuários não estão sendo criados no Nó de Cabeçalho 1. A solução alternativa é criá-los manualmente e alterar a propriedade para o UPN do respectivo usuário. 2. As permissões no /hdp não estão definidas atualmente como 751. Isso precisa ser definido como a. chmod 751 /hdp b. chmod –R 755 /hdp/apps
Reprovação
Portal do OMS: removemos o link da página de recursos do HDInsight que estava apontando para o portal do OMS. Inicialmente, os logs do Azure Monitor usava seu próprio portal, o portal do OMS, para gerenciar as configurações e analisar os dados coletados. Todas as funcionalidades desse portal foram transferidas para o Portal do Azure, onde continuarão a ser desenvolvidas. HDInsight preteriu o suporte para o portal do OMS. Os clientes usarão a integração dos logs do HDInsight Azure Monitor no portal do Microsoft Azure.
Spark 2.3:Reprovações do Spark versão 2.3.0
Atualizando
Todos esses recursos estão disponíveis no HDInsight 3.6. Para obter a versão mais recente do Spark, Kafka e Microsoft R Server (Serviços de Machine Learning), escolha a versão do Spark, Kafka, Serviços de ML ao criar um cluster HDInsight 3.6. Para obter suporte para o ADLS, você pode escolher o tipo de armazenamento do ADLS como uma opção. Clusters existentes não serão atualizados automaticamente para essas versões.
Todos os novos clusters criados após junho de 2018 receberão automaticamente as mais de 1.000 correções de bugs em todos os projetos de código aberto. Siga este guia para obter as melhores práticas de atualização para uma versão mais recente do HDInsight.