Copiar dados do Spark utilizando o Azure Data Factory ou Synapse Analytics
APLICA-SE A: Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Dica
Experimente o Data Factory no Microsoft Fabric, uma solução de análise tudo-em-um para empresas. O Microsoft Fabric abrange desde movimentação de dados até ciência de dados, análise em tempo real, business intelligence e relatórios. Saiba como iniciar uma avaliação gratuita!
Este artigo descreve como usar a atividade de cópia nos pipelines do Azure Data Factory ou do Azure Synapse Analytics para copiar dados de uma tabela do Spark. Ele amplia o artigo Visão geral da atividade de cópia que apresenta uma visão geral da atividade de cópia.
Funcionalidades com suporte
O conector do Spark é compatível com as seguintes funcionalidades:
| Funcionalidades com suporte | IR |
|---|---|
| Atividade de cópia (origem/-) | ① ② |
| Atividade de pesquisa | ① ② |
① Runtime de integração do Azure ② Runtime de integração auto-hospedada
Para obter uma lista de armazenamentos de dados com suporte como origens/coletores da atividade de cópia, confira a tabela Armazenamentos de dados com suporte.
O serviço fornece um driver interno para habilitar a conectividade, portanto, não é necessário instalar manualmente qualquer driver usando esse conector.
Pré-requisitos
Se o armazenamento de dados estiver localizado dentro de uma rede local, em uma rede virtual do Azure ou na Amazon Virtual Private Cloud, você precisará configurar um runtime de integração auto-hospedada para se conectar a ele.
Se o armazenamento de dados for um serviço de dados de nuvem gerenciado, você poderá usar o Azure Integration Runtime. Se o acesso for restrito aos IPs que estão aprovados nas regras de firewall, você poderá adicionar IPs do Azure Integration Runtime à lista de permissões.
Você também pode usar o recurso de runtime de integração da rede virtual gerenciada no Azure Data Factory para acessar a rede local sem instalar e configurar um runtime de integração auto-hospedada.
Para obter mais informações sobre os mecanismos de segurança de rede e as opções compatíveis com o Data Factory, consulte Estratégias de acesso a dados.
Introdução
Para executar a atividade de Cópia com um pipeline, será possível usar as ferramentas ou os SDKs abaixo:
- A ferramenta Copiar Dados
- O portal do Azure
- O SDK do .NET
- O SDK do Python
- PowerShell do Azure
- A API REST
- O modelo do Azure Resource Manager
Criar um serviço vinculado ao Spark com a interface do usuário
Use as etapas abaixo para criar um serviço vinculado ao Spark na interface do usuário do portal do Azure.
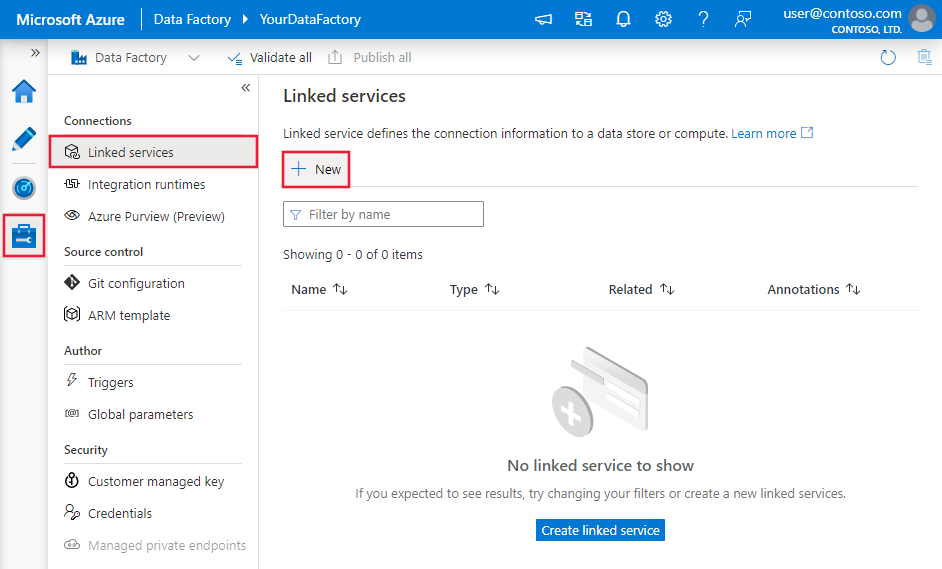
Navegue até a guia Gerenciar no workspace do Azure Data Factory ou do Synapse e selecione Serviços Vinculados. Depois, clique em Novo:
Pesquise Spark e selecione o conector correspondente.

Configure os detalhes do serviço, teste a conexão e crie o novo serviço vinculado.
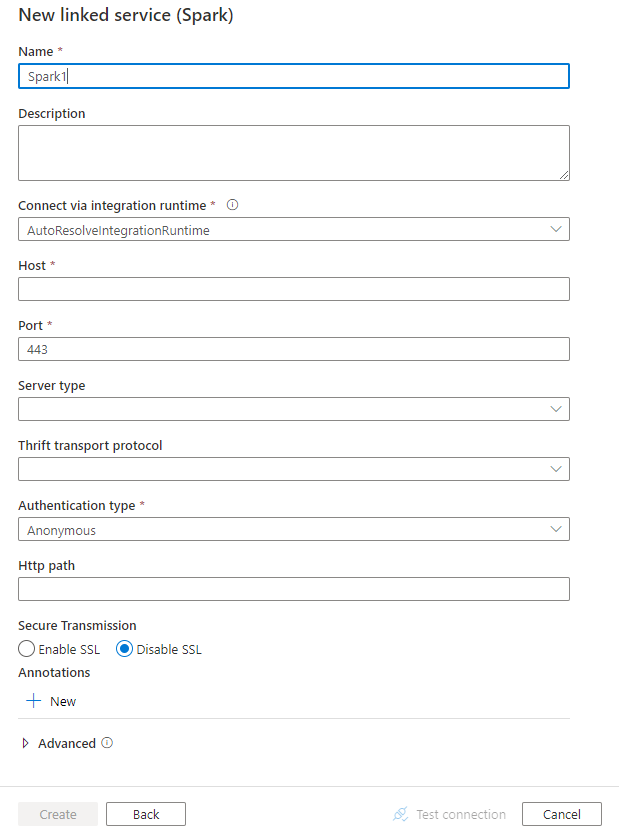
Detalhes da configuração do conector
As seções a seguir fornecem detalhes sobre as propriedades usadas para definir entidades do Data Factory específicas ao conector do Spark.
Propriedades do serviço vinculado
As propriedades a seguir têm suporte para o serviço vinculado do Spark:
| Propriedade | Descrição | Obrigatório |
|---|---|---|
| type | A propriedade type deve ser definida como: Spark | Sim |
| host | Endereço IP ou nome do host do servidor Spark | Sim |
| porta | A porta TCP usada pelo servidor Spark para ouvir conexões de cliente. Se você conectar ao Microsoft Azure HDInsights, especifique a porta como 443. | Sim |
| serverType | O tipo de servidor do Spark. Valores permitidos são: SharkServer, SharkServer2, SparkThriftServer |
Não |
| thriftTransportProtocol | O protocolo de transporte a ser usado na camada de Thrift. Os valores permitidos são: Binário, SASL, HTTP |
Não |
| authenticationType | O método de autenticação usado para acessar o servidor do Spark. Valores permitidos são: Anônimo, Username, UsernameAndPassword, WindowsAzureHDInsightService |
Sim |
| Nome de Usuário | O nome de usuário que você usa para acessar o servidor do Spark. | Não |
| password | A senha correspondente ao usuário. Marque este campo como um SecureString para armazená-lo com segurança ou referencie um segredo armazenado no Azure Key Vault. | Não |
| httpPath | A URL parcial correspondente ao servidor do Spark. | Não |
| enableSsl | Especifica se as conexões com o servidor são criptografadas via TLS. O valor padrão é false. | Não |
| trustedCertPath | O caminho completo do arquivo .pem que contém certificados de AC confiáveis para verificar o servidor ao se conectar via TLS. Essa propriedade só pode ser definida ao usar o TLS em IR auto-hospedado. O valor padrão é o arquivo de cacerts.pem instalado com o IR. | Não |
| useSystemTrustStore | Especifica se deve usar um certificado de autoridade de certificação do repositório de confiança de sistema ou de um arquivo PEM especificado. O valor padrão é false. | Não |
| allowHostNameCNMismatch | Especifica se é necessário o nome do certificado TLS/SSL emitido pela AC para corresponder ao nome de host do servidor ao se conectar via TLS. O valor padrão é false. | Não |
| allowSelfSignedServerCert | Especifica se deve permitir os certificados autoassinados do servidor. O valor padrão é false. | Não |
| connectVia | O Integration Runtime a ser usado para se conectar ao armazenamento de dados. Saiba mais na seção Pré-requisitos. Se não for especificado, ele usa o Integration Runtime padrão do Azure. | Não |
Exemplo:
{
"name": "SparkLinkedService",
"properties": {
"type": "Spark",
"typeProperties": {
"host" : "<cluster>.azurehdinsight.net",
"port" : "<port>",
"authenticationType" : "WindowsAzureHDInsightService",
"username" : "<username>",
"password": {
"type": "SecureString",
"value": "<password>"
}
}
}
}
Propriedades do conjunto de dados
Para obter uma lista completa das seções e propriedades disponíveis para definir os conjuntos de dados, confira o artigo sobre conjuntos de dados. Esta seção fornece uma lista das propriedades com suporte pelo conjunto de dados do Spark.
Para copiar dados do Spark, defina a propriedade type do conjunto de dados como SparkObject. Há suporte para as seguintes propriedades:
| Propriedade | Descrição | Obrigatório |
|---|---|---|
| type | A propriedade type do conjunto de dados precisa ser definida como: SparkObject | Sim |
| esquema | Nome do esquema. | Não (se "query" na fonte da atividade for especificada) |
| tabela | Nome da tabela. | Não (se "query" na fonte da atividade for especificada) |
| tableName | Nome da tabela com esquema. Essa propriedade é compatível com versões anteriores. Use schema e table para uma nova carga de trabalho. |
Não (se "query" na fonte da atividade for especificada) |
Exemplo
{
"name": "SparkDataset",
"properties": {
"type": "SparkObject",
"typeProperties": {},
"schema": [],
"linkedServiceName": {
"referenceName": "<Spark linked service name>",
"type": "LinkedServiceReference"
}
}
}
Propriedades da atividade de cópia
Para obter uma lista completa das seções e propriedades disponíveis para definir atividades, confia o artigo Pipelines. Esta seção fornece uma lista das propriedades com suporte pela origem do Spark.
Spark como fonte
Para copiar dados do Spark, defina o tipo de fonte na atividade de cópia como SparkSource. As propriedades a seguir têm suporte na seção source da atividade de cópia:
| Propriedade | Descrição | Obrigatório |
|---|---|---|
| type | A propriedade type da fonte da atividade de cópia deve ser definida como: SparkSource | Sim |
| Consulta | Utiliza a consulta SQL personalizada para ler os dados. Por exemplo: "SELECT * FROM MyTable". |
Não (se "tableName" no conjunto de dados for especificado) |
Exemplo:
"activities":[
{
"name": "CopyFromSpark",
"type": "Copy",
"inputs": [
{
"referenceName": "<Spark input dataset name>",
"type": "DatasetReference"
}
],
"outputs": [
{
"referenceName": "<output dataset name>",
"type": "DatasetReference"
}
],
"typeProperties": {
"source": {
"type": "SparkSource",
"query": "SELECT * FROM MyTable"
},
"sink": {
"type": "<sink type>"
}
}
}
]
Pesquisar propriedades de atividade
Para saber detalhes sobre as propriedades, verifique Pesquisar atividade.
Conteúdo relacionado
Para obter uma lista de armazenamentos de dados com suporte como coletores e fontes da atividade de cópia, confira os armazenamentos de dados com suporte.