Início rápido: Criar um Azure Data Factory usando o PowerShell
APLICA-SE A: Azure Data Factory
Azure Data Factory  Azure Synapse Analytics
Azure Synapse Analytics
Dica
Experimente o Data Factory no Microsoft Fabric, uma solução de análise tudo-em-um para empresas. O Microsoft Fabric abrange desde movimentação de dados até ciência de dados, análise em tempo real, business intelligence e relatórios. Saiba como iniciar uma avaliação gratuita!
Este guia de início rápido descreve como usar o PowerShell para criar um Azure Data Factory. O pipeline que você criar nesse data factory copia dados de uma pasta para outra em um Armazenamento de Blobs do Azure. Para obter um tutorial sobre como transformar dados usando o Azure Data Factory, confira Tutorial: Transformar dados usando o Spark.
Observação
Este artigo não fornece uma introdução detalhada do serviço Data Factory. Para obter uma introdução do serviço do Azure Data Factory, consulte Introdução ao Azure Data Factory.
Pré-requisitos
Assinatura do Azure
Se você não tiver uma assinatura do Azure, crie uma conta gratuita antes de começar.
Funções do Azure
Para criar instâncias de Data Factory, a conta de usuário usada para entrar no Azure deve ser um membro das funções colaborador ou proprietário, ou um administrador da assinatura do Azure. Para exibir as permissões que você tem na assinatura, acesse o portal do Azure, selecione seu nome de usuário no canto superior direito e selecione o ícone “ ... ” para obter mais opções; em seguida, selecione Minhas permissões. Se tiver acesso a várias assinaturas, selecione a que for adequada.
Para criar e gerenciar recursos filho para o Data Factory – incluindo conjuntos de dados, serviços vinculados, pipelines, gatilhos e runtimes de integração –, os requisitos a seguir são aplicáveis:
- Para criar e gerenciar recursos filho no portal do Azure, você precisa pertencer à função Colaborador do Data Factory no nível do grupo de recursos ou superior.
- Para criar e gerenciar recursos filho com o PowerShell ou o SDK, a função de colaborador no nível do recurso ou superior é suficiente.
Para obter instruções de exemplo sobre como adicionar um usuário a uma função, confira o artigo Adicionar funções.
Para obter mais informações, confira os seguintes artigos:
Conta de Armazenamento do Azure
Use uma conta de Armazenamento do Azure de uso geral (especificamente o Armazenamento de Blobs) como armazenamentos de dados de origem e destino neste início rápido. Se você não tiver uma conta de Armazenamento do Azure de uso geral, confira Criar uma conta de armazenamento para criar uma.
Obter o nome da conta de armazenamento
Você precisará do nome da sua conta de Armazenamento do Azure para este início rápido. O procedimento a seguir fornece as etapas para obter o nome da sua conta de armazenamento:
- Em um navegador da Web, vá para o portal do Azure e entre usando seu nome de usuário e senha do Azure.
- No menu do portal do Azure, selecione Todos os serviços, em seguida, selecione Armazenamento>Contas de armazenamento. Você também pode pesquisar e selecionar Contas de armazenamento de qualquer página.
- Na página Contas de armazenamento, filtre pela sua conta de armazenamento (se necessário) e selecione a sua conta de armazenamento.
Você também pode pesquisar e selecionar Contas de armazenamento de qualquer página.
Criar um contêiner de blob
Nesta seção, você cria um contêiner de blobs chamado adftutorial no armazenamento de Blobs do Azure.
Na página da conta de armazenamento, selecione Visão geral>Contêineres.
Na barra de ferramentas da página <Nome da conta> - Contêineres, selecione Contêiner.
Na caixa de diálogo Novo contêiner, insira adftutorial como o nome e selecione OK. A página <Nome da conta> - Contêineres é atualizada para incluir adftutorial na lista de contêineres.
Adicionar uma pasta de entrada e um arquivo ao contêiner de blob
Nesta seção, você pode adicionar uma pasta chamada entrada ao contêiner que acabou de criar e, em seguida, carregar um arquivo de exemplo na pasta de entrada. Antes de começar, abra um editor de texto como o Bloco de Notas e crie um arquivo chamado emp.txt com o seguinte conteúdo:
John, Doe
Jane, Doe
Salve o arquivo na pasta C:\ADFv2QuickStartPSH. (Se a pasta ainda não existir, crie-a.) Então volte ao portal do Azure e siga estas etapas:
Na página <Nome da conta> - Contêineres em que você parou, selecione adftutorial na lista atualizada de contêineres.
- Se você fechou a janela ou foi para outra página, entre no portal do Azure novamente.
- No menu do portal do Azure, selecione Todos os serviços, em seguida, selecione Armazenamento>Contas de armazenamento. Você também pode pesquisar e selecionar Contas de armazenamento de qualquer página.
- Selecione a sua conta de armazenamento e, em seguida, Contêineres>adftutorial.
Na barra de ferramentas da página de contêiner do adftutorial, selecione Carregar.
Na página Carregar blob, selecione a caixa Arquivos e, em seguida, navegue até o arquivo emp.txt e selecione-o.
Expanda o título Avançado. A página agora será exibida como mostrado:
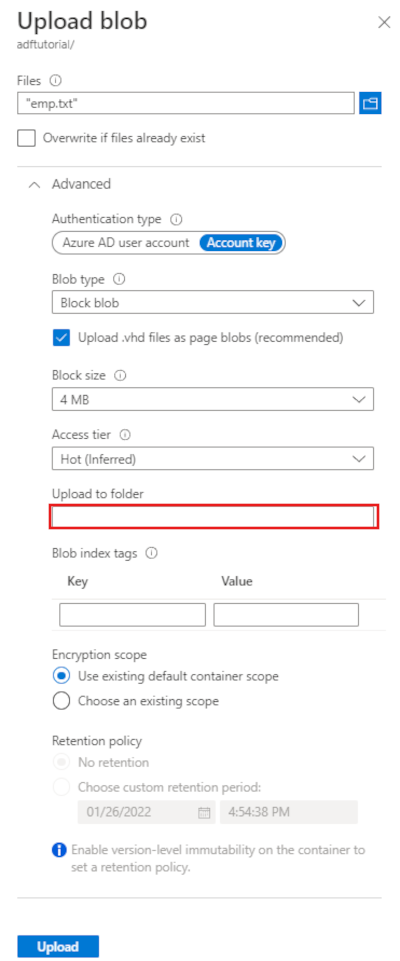
Na caixa Carregar para a pasta, insira entrada.
Selecione o botão Carregar. O arquivo emp.txt e o status do carregamento devem estar na lista.
Selecione o ícone Fechar (um X) para fechar a página Carregar blob.
Mantenha a página do contêiner adftutorial aberta. Você a usa para verificar a saída no final do guia de início rápido.
Azure PowerShell
Observação
Recomendamos que você use o módulo Az PowerShell do Azure para interagir com o Azure. Para começar, consulte Instalar o Azure PowerShell. Para saber como migrar para o módulo Az PowerShell, confira Migrar o Azure PowerShell do AzureRM para o Az.
Instale os módulos mais recentes do Azure PowerShell seguindo as instruções em Como instalar e configurar o Azure PowerShell.
Aviso
Se você não usar as versões mais recentes do PowerShell e o módulo do Data Factory, poderá encontrar erros de desserialização ao executar os comandos.
Fazer logon no PowerShell
Iniciar o PowerShell no seu computador. Mantenha o PowerShell aberto até o fim deste guia de início rápido. Se você fechá-la e reabri-la, precisará executar esses comandos novamente.
Execute o comando a seguir e insira o mesmo nome de usuário e senha do Azure que você usa para entrar no Portal do Azure:
Connect-AzAccountExecute o comando abaixo para exibir todas as assinaturas dessa conta:
Get-AzSubscriptionSe você vir várias assinaturas associadas à sua conta, execute o seguinte comando para selecionar a assinatura com que deseja trabalhar. Substitua SubscriptionId pela ID da assinatura do Azure:
Select-AzSubscription -SubscriptionId "<SubscriptionId>"
Criar uma data factory
Defina uma variável para o nome do grupo de recursos que você usa nos comandos do PowerShell posteriormente. Copie o seguinte texto de comando para o PowerShell, especifique um nome para o grupo de recursos do Azure entre aspas duplas e, em seguida, execute o comando. Por exemplo:
"ADFQuickStartRG".$resourceGroupName = "ADFQuickStartRG";Se o grupo de recursos já existir, não convém substituí-lo. Atribua um valor diferente para a variável
$ResourceGroupNamee execute o comando novamentePara criar o grupo de recursos do Azure, execute o seguinte comando:
$ResGrp = New-AzResourceGroup $resourceGroupName -location 'East US'Se o grupo de recursos já existir, não convém substituí-lo. Atribua um valor diferente para a variável
$ResourceGroupNamee execute o comando novamente.Defina uma variável para o nome do data factory.
Importante
Atualize o Nome do data factory para ser globalmente exclusivo. Por exemplo, ADFTutorialFactorySP1127.
$dataFactoryName = "ADFQuickStartFactory";Para criar o data factory, execute o cmdlet Set-AzDataFactoryV2 a seguir usando a propriedade Location e ResourceGroupName da variável $ResGrp:
$DataFactory = Set-AzDataFactoryV2 -ResourceGroupName $ResGrp.ResourceGroupName ` -Location $ResGrp.Location -Name $dataFactoryName
Observe os seguintes pontos:
O nome do Azure Data Factory deve ser globalmente exclusivo. Se você receber o erro a seguir, altere o nome e tente novamente.
The specified Data Factory name 'ADFv2QuickStartDataFactory' is already in use. Data Factory names must be globally unique.Para criar instâncias de Data Factory, a conta de usuário usada para fazer logon no Azure deve ser um membro das funções colaborador ou proprietário, ou um administrador da assinatura do Azure.
Para obter uma lista de regiões do Azure no qual o Data Factory está disponível no momento, selecione as regiões que relevantes para você na página a seguir e, em seguida, expanda Análise para localizar Data Factory: Produtos disponíveis por região. Os armazenamentos de dados (Armazenamento do Azure, Banco de Dados SQL do Azure, etc.) e serviços de computação (HDInsight, etc.) usados pelo data factory podem estar em outras regiões.
Criar um serviço vinculado
Crie serviços vinculados em um data factory para vincular seus armazenamentos de dados e serviços de computação ao data factory. Neste guia de início rápido, você cria um serviço vinculado do Armazenamento do Azure que é usado como armazenamento de origem e do coletor. O serviço vinculado tem as informações de conexão que o serviço do Data Factory usa no runtime para se conectar a ele.
Dica
Neste início rápido, você usa a Chave de conta como o tipo de autenticação para o armazenamento de dados, mas você pode escolher outros métodos de autenticação compatíveis: URI de SAS, Entidade de Serviço e Identidade Gerenciada se necessário. Veja as seções correspondentes neste artigo para obter detalhes. Para armazenar segredos de armazenamentos de dados com segurança, também é recomendável usar um Azure Key Vault. Veja este artigo para obter ilustrações detalhadas.
Crie um arquivo JSON chamado AzureStorageLinkedService.json na pasta C:\ADFv2QuickStartPSH com o seguinte conteúdo: (Crie a pasta ADFv2QuickStartPSH se ela ainda não existir.).
Importante
Antes de salvar o arquivo, substitua <accountName> e <accountKey> pelo nome e pela chave da sua conta de armazenamento do Azure, respectivamente.
{ "name": "AzureStorageLinkedService", "properties": { "annotations": [], "type": "AzureBlobStorage", "typeProperties": { "connectionString": "DefaultEndpointsProtocol=https;AccountName=<accountName>;AccountKey=<accountKey>;EndpointSuffix=core.windows.net" } } }Se você estiver usando o Bloco de Notas, selecione Todos os arquivos para o Salvar como tipo preenchido na caixa de diálogo Salvar como. Caso contrário, ele pode adicionar a extensão
.txtpara o arquivo. Por exemplo,AzureStorageLinkedService.json.txt. Se você criar o arquivo no Explorador de arquivos antes de abri-lo no Bloco de Notas, você não poderá ver a extensão.txt, já que a opção Ocultar extensões de tipos de arquivos conhecidos será definida por padrão. Remova a extensão.txtantes de prosseguir para a próxima etapa.No PowerShell, mude para a pasta ADFv2QuickStartPSH.
Set-Location 'C:\ADFv2QuickStartPSH'Execute o cmdlet Set-AzDataFactoryV2LinkedService para criar o serviço vinculado: AzureStorageLinkedService.
Set-AzDataFactoryV2LinkedService -DataFactoryName $DataFactory.DataFactoryName ` -ResourceGroupName $ResGrp.ResourceGroupName -Name "AzureStorageLinkedService" ` -DefinitionFile ".\AzureStorageLinkedService.json"Veja o exemplo de saída:
LinkedServiceName : AzureStorageLinkedService ResourceGroupName : <resourceGroupName> DataFactoryName : <dataFactoryName> Properties : Microsoft.Azure.Management.DataFactory.Models.AzureBlobStorageLinkedService
Criar conjuntos de dados
Neste procedimento, você criará dois conjuntos de dados: InputDataset e OutputDataset. Esses conjuntos de dados são do tipo Binário. Eles se referem ao Serviço vinculado do Armazenamento do Azure que você criou na seção anterior. O conjunto de dados de entrada representa os dados de origem na pasta de entrada. Na definição de conjunto de dados de entrada, especifique o contêiner de blob (adftutorial), a pasta (entrada) e o arquivo (emp.txt) que contém os dados de origem. Esse conjunto de dados de saída representa os dados que são copiados para o destino. Na definição de conjunto de dados de saída, especifique o contêiner de blob (adftutorial), a pasta (saída) e o arquivo para o qual os dados são copiados.
Crie um arquivo JSON chamado InputDataset.json na pasta C:\ADFv2QuickStartPSH com o seguinte conteúdo:
{ "name": "InputDataset", "properties": { "linkedServiceName": { "referenceName": "AzureStorageLinkedService", "type": "LinkedServiceReference" }, "annotations": [], "type": "Binary", "typeProperties": { "location": { "type": "AzureBlobStorageLocation", "fileName": "emp.txt", "folderPath": "input", "container": "adftutorial" } } } }Para criar o conjunto de dados: InputDataset; execute o cmdlet Set-AzDataFactoryV2Dataset.
Set-AzDataFactoryV2Dataset -DataFactoryName $DataFactory.DataFactoryName ` -ResourceGroupName $ResGrp.ResourceGroupName -Name "InputDataset" ` -DefinitionFile ".\InputDataset.json"Veja o exemplo de saída:
DatasetName : InputDataset ResourceGroupName : <resourceGroupname> DataFactoryName : <dataFactoryName> Structure : Properties : Microsoft.Azure.Management.DataFactory.Models.BinaryDatasetRepita as etapas para criar o conjunto de dados de saída. Crie um arquivo JSON chamado OutputDataset.json na pasta C:\ADFv2QuickStartPSH com o seguinte conteúdo:
{ "name": "OutputDataset", "properties": { "linkedServiceName": { "referenceName": "AzureStorageLinkedService", "type": "LinkedServiceReference" }, "annotations": [], "type": "Binary", "typeProperties": { "location": { "type": "AzureBlobStorageLocation", "folderPath": "output", "container": "adftutorial" } } } }Execute o cmdlet Set-AzDataFactoryV2Dataset para criar o OutDataset.
Set-AzDataFactoryV2Dataset -DataFactoryName $DataFactory.DataFactoryName ` -ResourceGroupName $ResGrp.ResourceGroupName -Name "OutputDataset" ` -DefinitionFile ".\OutputDataset.json"Veja o exemplo de saída:
DatasetName : OutputDataset ResourceGroupName : <resourceGroupname> DataFactoryName : <dataFactoryName> Structure : Properties : Microsoft.Azure.Management.DataFactory.Models.BinaryDataset
Criar um pipeline
Neste procedimento, você criará um pipeline com uma atividade de cópia que usa os conjuntos de dados de entrada e saída. A Atividade de cópia copia os dados do arquivo especificado por você nas configurações do conjunto de dados de entrada para o arquivo especificado por você nas configurações do conjunto de dados de saída.
Crie um arquivo JSON denominado Adfv2QuickStartPipeline.json na pasta C:\ADFv2QuickStartPSH com o seguinte conteúdo:
{ "name": "Adfv2QuickStartPipeline", "properties": { "activities": [ { "name": "CopyFromBlobToBlob", "type": "Copy", "dependsOn": [], "policy": { "timeout": "7.00:00:00", "retry": 0, "retryIntervalInSeconds": 30, "secureOutput": false, "secureInput": false }, "userProperties": [], "typeProperties": { "source": { "type": "BinarySource", "storeSettings": { "type": "AzureBlobStorageReadSettings", "recursive": true } }, "sink": { "type": "BinarySink", "storeSettings": { "type": "AzureBlobStorageWriteSettings" } }, "enableStaging": false }, "inputs": [ { "referenceName": "InputDataset", "type": "DatasetReference" } ], "outputs": [ { "referenceName": "OutputDataset", "type": "DatasetReference" } ] } ], "annotations": [] } }Para criar o pipeline: Adfv2QuickStartPipeline, execute o cmdlet Set-AzDataFactoryV2Pipeline.
$DFPipeLine = Set-AzDataFactoryV2Pipeline ` -DataFactoryName $DataFactory.DataFactoryName ` -ResourceGroupName $ResGrp.ResourceGroupName ` -Name "Adfv2QuickStartPipeline" ` -DefinitionFile ".\Adfv2QuickStartPipeline.json"
Criar uma execução de pipeline
Nesta etapa, você criará uma execução de pipeline.
Execute o cmdlet Invoke-AzDataFactoryV2Pipeline para criar uma execução de pipeline. O cmdlet retorna a ID da execução de pipeline para monitoramento futuro.
$RunId = Invoke-AzDataFactoryV2Pipeline `
-DataFactoryName $DataFactory.DataFactoryName `
-ResourceGroupName $ResGrp.ResourceGroupName `
-PipelineName $DFPipeLine.Name
Monitorar a execução de pipeline
Execute o script do PowerShell a seguir para verificar continuamente o status da execução de pipeline até que ela termine de copiar os dados. Copie/cole o script a seguir na janela do PowerShell e pressione ENTER.
while ($True) { $Run = Get-AzDataFactoryV2PipelineRun ` -ResourceGroupName $ResGrp.ResourceGroupName ` -DataFactoryName $DataFactory.DataFactoryName ` -PipelineRunId $RunId if ($Run) { if ( ($Run.Status -ne "InProgress") -and ($Run.Status -ne "Queued") ) { Write-Output ("Pipeline run finished. The status is: " + $Run.Status) $Run break } Write-Output ("Pipeline is running...status: " + $Run.Status) } Start-Sleep -Seconds 10 }Eis aqui a amostra de saída da execução de pipeline:
Pipeline is running...status: InProgress Pipeline run finished. The status is: Succeeded ResourceGroupName : ADFQuickStartRG DataFactoryName : ADFQuickStartFactory RunId : 00000000-0000-0000-0000-0000000000000 PipelineName : Adfv2QuickStartPipeline LastUpdated : 8/27/2019 7:23:07 AM Parameters : {} RunStart : 8/27/2019 7:22:56 AM RunEnd : 8/27/2019 7:23:07 AM DurationInMs : 11324 Status : Succeeded Message :Execute o script a seguir para recuperar os detalhes de execução da atividade de cópia, por exemplo, o tamanho dos dados lidos/gravados.
Write-Output "Activity run details:" $Result = Get-AzDataFactoryV2ActivityRun -DataFactoryName $DataFactory.DataFactoryName -ResourceGroupName $ResGrp.ResourceGroupName -PipelineRunId $RunId -RunStartedAfter (Get-Date).AddMinutes(-30) -RunStartedBefore (Get-Date).AddMinutes(30) $Result Write-Output "Activity 'Output' section:" $Result.Output -join "`r`n" Write-Output "Activity 'Error' section:" $Result.Error -join "`r`n"Verifique se você vê uma saída semelhante à amostra de saída do resultado da execução de atividade a seguir:
ResourceGroupName : ADFQuickStartRG DataFactoryName : ADFQuickStartFactory ActivityRunId : 00000000-0000-0000-0000-000000000000 ActivityName : CopyFromBlobToBlob PipelineRunId : 00000000-0000-0000-0000-000000000000 PipelineName : Adfv2QuickStartPipeline Input : {source, sink, enableStaging} Output : {dataRead, dataWritten, filesRead, filesWritten...} LinkedServiceName : ActivityRunStart : 8/27/2019 7:22:58 AM ActivityRunEnd : 8/27/2019 7:23:05 AM DurationInMs : 6828 Status : Succeeded Error : {errorCode, message, failureType, target} Activity 'Output' section: "dataRead": 20 "dataWritten": 20 "filesRead": 1 "filesWritten": 1 "sourcePeakConnections": 1 "sinkPeakConnections": 1 "copyDuration": 4 "throughput": 0.01 "errors": [] "effectiveIntegrationRuntime": "DefaultIntegrationRuntime (Central US)" "usedDataIntegrationUnits": 4 "usedParallelCopies": 1 "executionDetails": [ { "source": { "type": "AzureBlobStorage" }, "sink": { "type": "AzureBlobStorage" }, "status": "Succeeded", "start": "2019-08-27T07:22:59.1045645Z", "duration": 4, "usedDataIntegrationUnits": 4, "usedParallelCopies": 1, "detailedDurations": { "queuingDuration": 3, "transferDuration": 1 } } ] Activity 'Error' section: "errorCode": "" "message": "" "failureType": "" "target": "CopyFromBlobToBlob"
Examinar os recursos implantados
O pipeline cria automaticamente a pasta de saída no contêiner de blob adftutorial. Em seguida, ele copia o arquivo emp.txt da pasta de entrada para a pasta de saída.
No portal do Azure, na página do contêiner adftutorial, selecione Atualizar para ver a pasta de saída.
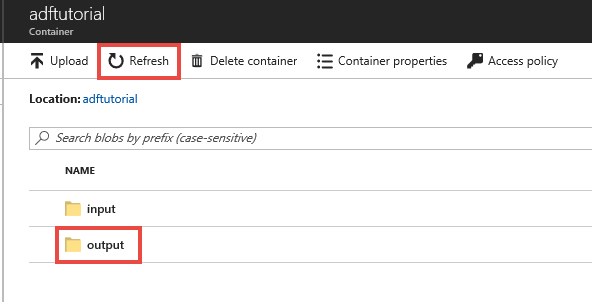
Selecione saída na lista de pastas.
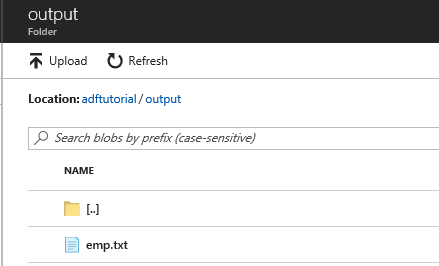
Confirme que emp.txt tenha sido copiado para a pasta de saída.
Limpar os recursos
Limpe os recursos criados no Guia de início rápido de duas maneiras. Você pode excluir o grupo de recursos do Azure, o que inclui todos os recursos do grupo. Se desejar manter os outros recursos intactos, exclua apenas o data factory que você criou neste tutorial.
Ao excluir um grupo de recursos, todos os recursos são excluídos, incluindo os data factories nele. Execute o comando a seguir para excluir o grupo de recursos inteiro:
Remove-AzResourceGroup -ResourceGroupName $resourcegroupname
Observação
A remoção de um grupo de recursos poderá levar algum tempo. Seja paciente com o processo
Se deseja excluir apenas o data factory e não o grupo de recursos inteiro, execute o seguinte comando:
Remove-AzDataFactoryV2 -Name $dataFactoryName -ResourceGroupName $resourceGroupName
Conteúdo relacionado
O pipeline nessa amostra copia dados de uma localização para outra em um Armazenamento de Blobs do Azure. Percorra os tutoriais para saber mais sobre o uso do Data Factory em mais cenários.