Integration Runtime no Azure Data Factory
APLICA-SE A: Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Dica
Experimente o Data Factory no Microsoft Fabric, uma solução de análise tudo-em-um para empresas. O Microsoft Fabric abrange desde movimentação de dados até ciência de dados, análise em tempo real, business intelligence e relatórios. Saiba como iniciar uma avaliação gratuita!
O IR (Integration Runtime) é a estrutura de computação usada pelos pipelines do Azure Data Factory e do Azure Synapse para fornecer os seguintes recursos de integração de dados em diferentes ambientes de rede:
- Fluxo de Dados: execute um fluxo de dados no ambiente de computação gerenciado do Azure.
- Movimentação de dados: copie dados entre armazenamentos de dados em redes públicas ou privadas (para redes privadas virtuais ou locais). O serviço fornece suporte para conectores internos, conversão de formato, mapeamento de coluna e transferência de dados de alto desempenho e escalonáveis.
- Expedição de atividades: distribua e monitore atividades de transformação em execução em vários serviços de computação, como Azure Databricks, Azure HDInsight, Estúdio do ML (clássico), Banco de Dados SQL do Azure, SQL Server e muito mais.
- Execução de pacote SSIS: execute nativamente pacotes do SSIS (SQL Server Integration Services) em um ambiente de computação gerenciada do Azure.
Nos pipelines do Data Factory e do Synapse, uma atividade define a ação a ser executada. Um serviço vinculado define um armazenamento de dados de destino ou um serviço de computação. Um Integration Runtime fornece a ponte entre as atividades e os serviços vinculados. O serviço vinculado ou atividade faz referência e fornece o ambiente de computação no qual a atividade é executada diretamente ou de onde é expedida. Essa associação permite que a atividade seja executada na região mais próxima possível do serviço de computação ou armazenamento de dados de destino a fim de maximizar o desempenho, permitindo também flexibilidade para atender ao serviços de segurança e conformidade.
Os runtimes de integração podem ser criados diretamente no Azure Data Factory e na interface do usuário do Azure Synapse por meio do hub de gerenciamento, bem como de atividades, conjuntos de dados ou fluxos de dados que os referenciem.
Tipos de Integration Runtime
O Data Factory oferece três tipos de Integration Runtime (IR) e você deve escolher o tipo que melhor atende aos seus requisitos de funcionalidades de integração de dados e de ambiente de rede. Os três tipos de IR são:
- Azure
- Auto-hospedado
- Azure-SSIS
Observação
Atualmente, os pipelines do Synapse dão suporte apenas a runtimes de integração do Azure ou auto-hospedados.
A tabela a seguir descreve as funcionalidades e o suporte de rede para cada um dos tipos de Integration Runtime:
| Tipo de IR | Suporte à rede pública | Suporte ao Link Privado |
|---|---|---|
| Azure | Fluxo de Dados Movimentação de dados Expedição de atividade |
Fluxo de Dados Movimentação de dados Expedição de atividade |
| Auto-hospedado | Movimentação de dados Expedição de atividade |
Movimentação de dados Expedição de atividade |
| Azure-SSIS | Execução do pacote SSIS | Execução do pacote SSIS |
Observação
Os controles de saída variam de acordo com o serviço do Azure IR. No Synapse, os workspaces têm opções para limitar o tráfego de saída da rede virtual gerenciada ao utilizar o Azure IR. No Data Factory, todas as portas são abertas para comunicações de saída ao utilizar o Azure IR. O Azure-SSIS IR pode ser integrado à sua rede virtual para fornecer controles de comunicação de saída.
Azure Integration runtime
Uma integração de runtime no Azure pode:
- Executar fluxos de dados no Azure
- Executar atividades de cópia entre armazenamentos de dados de nuvem
- Distribua as seguintes atividades de transformação na rede pública:
- Atividade personalizada do .NET
- Atividade do Azure Function
- Atividade do Databricks Notebook/Jar/Python
- Atividade do U-SQL do Data Lake Analytics
- Atividade de obtenção de metadados
- Atividade de Hive do HDInsight
- Atividade de Pig do HDInsight
- Atividade de MapReduce do HDInsight
- Atividade do Spark no HDInsight
- Atividade de Streaming do HDInsight
- Atividade de pesquisa
- Atividade Batch Execution do Machine Learning Studio (clássico)
- Atividade Update Resource do Machine Learning Studio (clássico)
- Atividade de procedimento armazenado
- Atividade Validation
- Atividade da Web
Ambiente de rede do IR do Azure
O Integration Runtime do Azure dá suporte à conexão a armazenamentos de dados e computa serviços com endpoints públicos acessíveis. Ao habilitar a rede virtual gerenciada, o Azure Integration Runtime dá suporte à conexão para armazenamentos de dados usando o serviço de link privado no ambiente de rede privada. No Synapse, os workspaces têm opções para limitar o tráfego de saída da rede virtual gerenciada do IR. No Data Factory, todas as portas são abertas para comunicações de saída. O Azure-SSIS IR pode ser integrado à sua rede virtual para fornecer controles de comunicação de saída.
Recurso de computação e dimensionamento do IR do Azure
O Integration Runtime do Azure fornece uma computação totalmente gerenciada e sem servidor no Azure. Você não precisa se preocupar com provisionamento de infraestrutura, instalação de software, aplicação de patch ou dimensionamento de capacidade. Além disso, você só paga durante a utilização real.
O Integration Runtime do Azure fornece a computação nativa de para mover dados entre armazenamentos de dados de nuvem de maneira segura, confiável e de alto desempenho. Você pode definir quantas unidades de integração de dados usar na atividade de cópia e o tamanho da computação do Azure IR é expandido elasticamente de modo adequado sem que você precise ajustar explicitamente o tamanho do Azure Integration Runtime.
A expedição de atividade é uma operação simples para rotear a atividade para o serviço de computação de destino, de modo que não há necessidade de expandir o tamanho da computação para esse cenário.
Para obter informações sobre como criar e configurar um IR do Azure, consulte Como criar e configurar o Azure Integration Runtime.
Observação
O Azure Integration Runtime tem propriedades relacionadas ao runtime do fluxo de dados, que define a infraestrutura de computação subjacente que seria usada para executar os fluxos de dados.
runtime de integração auto-hospedada
Um IR auto-hospedado é capaz de:
- Executar a atividade de cópia entre um armazenamento de dados de nuvem e um armazenamento de dados na rede privada.
- Distribua as seguintes atividades de transformação com relação aos recursos de computação locais ou da Rede Virtual do Microsoft Azure:
- Atividade do Azure Function
- Atividade personalizada (executada no Lote do Azure)
- Atividade do U-SQL do Data Lake Analytics
- Atividade de obtenção de metadados
- Atividade HDInsight Hive (BYOC – Traga Seu Próprio Cluster)
- Atividade HDInsight Pig (BYOC)
- Atividade HDInsight MapReduce (BYOC)
- Atividade HDInsight Spark (BYOC)
- Atividade HDInsight Streaming (BYOC)
- Atividade de pesquisa
- Atividade Batch Execution do Machine Learning Studio (clássico)
- Atividade Update Resource do Machine Learning Studio (clássico)
- Atividade Execute Pipeline do Machine Learning
- Atividade de procedimento armazenado
- Atividade Validation
- Atividade da Web
Observação
Use o runtime de integração auto-hospedado para dar suporte a armazenamentos de dados que requer traga seu próprio driver como SAP Hana, MySQL, etc. Para mais informações, confira os armazenamentos de dados suportados.
Observação
O JRE (Java Runtime Environment) é uma dependência do IR auto-hospedado. Verifique se o JRE está instalado no mesmo host.
Ambiente de rede do IR auto-hospedado
Se você deseja realizar a integração de dados com segurança em um ambiente de rede privada, que não tem uma linha de visão direta do ambiente de nuvem pública, pode instalar um IR auto-hospedado no seu ambiente local por trás de seu firewall ou então em uma rede virtual privada. O runtime de integração auto-hospedado só faz conexões de saída com baseadas em HTTP com a Internet.
Recurso de computação e dimensionamento do IR auto-hospedado
Instale um IR auto-hospedado em um computador local ou em uma máquina virtual dentro de uma rede privada. Atualmente, o IR auto-hospedado só tem suporte em um sistema operacional Windows. Para alta disponibilidade e escalabilidade, você pode expandir o IR auto-hospedado associando a instância lógica a vários computadores locais no modo ativo-ativo. Para obter mais informações e detalhes, confira o artigo em Como criar e configurar um IR auto-hospedado.
runtime de integração do Azure-SSIS
Para fazer lift-and-shift da carga de trabalho existente do SSIS, você pode criar um IR Azure-SSIS para executar pacotes do SSIS nativamente.
Ambiente de rede do IR do Azure-SSIS
O Azure-SSIS IR pode ser provisionado na rede pública ou na rede privada. Há suporte para o acesso a dados locais unindo o Azure-SSIS IR a uma rede virtual conectada à sua rede local.
Recurso de computação e dimensionamento do IR do Azure-SSIS
O Azure-SSIS IR é um cluster totalmente gerenciado das VMs do Azure dedicado para executar os pacotes de SSIS. É possível colocar seu próprio servidor do Banco de Dados SQL do Azure ou Instância Gerenciada do SQL para o catálogo de projetos/pacotes do SSIS (SSISDB). Você pode aumentar a potência de computação especificando o tamanho do nó e escalá-la horizontalmente especificando o número de nós no cluster. Você pode gerenciar o custo da execução do Azure-SSIS Integration Runtime, parando-o e iniciando-o conforme exigido pelos seus requisitos.
Para obter mais informações, confira Criar e configurar o Azure-SSIS IR. Depois de criado, você pode implantar e gerenciar seus pacotes SSIS existentes com pouca ou nenhuma alteração usando ferramentas familiares, como o SSDT (SQL Server Data Tools) e o SSMS (SQL Server Management Studio), assim como usando o SSIS localmente.
Confira estes artigos para obter mais informações sobre o runtime do Azure-SSIS:
- Tutorial: implantar pacotes do SSIS para o Azure. Este artigo fornece instruções passo a passo para criar um IR do Azure-SSIS e usa um Banco de dados SQL do Azure para hospedar o catálogo do SSIS.
- Como: Criar um runtime de integração do Azure-SSIS. Este artigo expande o tutorial e fornece instruções sobre como usar a Instância Gerenciada do SQL e unir o IR a uma rede virtual.
- Monitore um IR do Azure-SSIS. Este artigo mostra como recuperar informações sobre um Azure-SSIS IR e fornece descrições de status nas informações retornadas.
- Gerencie um IR do Azure-SSIS. Este artigo mostra como parar, iniciar ou remover um IR do Azure-SSIS. Ele também mostra como expandir o IR do Azure-SSIS adicionando mais nós ao IR.
- Unir um IR do Azure-SSIS a uma rede virtual. Este artigo fornece informações conceituais sobre como unir um IR do Azure-SSIS a uma rede virtual do Azure. Ele também fornece etapas para usar o portal do Azure para configurar uma rede virtual e unir um Azure-SSIS IR a ela.
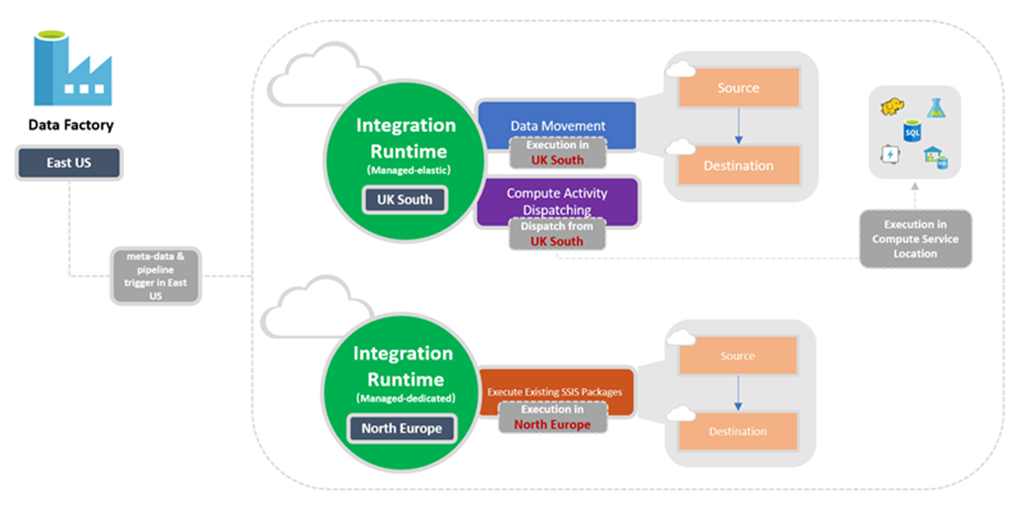
Localização do Integration Runtime
Relação entre o local de fábrica e o local de IR
Ao criar uma instância do Data Factory ou de um workspace do Synapse, você precisa especificar o local dela. Os metadados para a instância são armazenados nesse local, e o acionamento do pipeline é iniciado nele. Os metadados são armazenados apenas na região escolhida e não são armazenados em outras regiões.
No entanto, um pipeline pode acessar armazenamentos de dados e serviços de computação em outras regiões do Azure para mover dados entre armazenamentos de dados ou processar dados usando os serviços de computação. Esse comportamento é realizado por meio do IR disponível globalmente para garantir a conformidade de dados, a eficiência e os custos de saída de rede reduzidos.
A localização do IR define a localização da respectiva computação de back-end e a localização em que a movimentação de dados, a expedição de atividades e a execução de pacotes SSIS são executadas. A localização do IR pode ser diferente da localização do Data Factory ao qual ele pertence.
Localização do IR do Azure
Você poderá definir a região da localização de um Azure IR e, se o fizer, a execução ou a expedição de atividade ocorrerá na região selecionada.
O padrão é resolver automaticamente o Azure IR na rede pública. Com essa opção:
No caso da atividade Copy, o esforço será concentrado na detecção automática da localização do armazenamento de dados do coletor e no uso do IR na mesma região, se disponível, ou na mais próxima na mesma área geográfica. Caso contrário, se a região de armazenamento de dados do coletor não for detectável, o IR na região da instância será usado.
Por exemplo, um Data Factory ou workspace do Synapse foi criado no Leste dos EUA.
- Ao copiar dados para um Blob do Azure no Oeste dos EUA, se o blob for detectado na região Oeste dos EUA, a atividade Copy será executada no IR no Oeste dos EUA; Se a detecção da região falhar, a atividade Copy será executada no IR no Leste dos EUA.
- Quando os dados são copiados para o Salesforce, cuja região não é detectável, a atividade Copy é executada no IR no Leste dos EUA.
Dica
Se você tiver requisitos de conformidade de dados rigorosos e precisa garantir que os dados não saiam de uma determinada região geográfica, poderá criar explicitamente um Azure IR em uma determinada região e apontar o serviço vinculado a esse IR usando a propriedade ConnectVia. Por exemplo, se você quiser copiar dados de um blob no Sul do Reino Unido para um espaço de trabalho do Azure Synapse no Sul do Reino Unido e quiser garantir que os dados não saiam do Reino Unido, crie um Azure IR no Sul do Reino Unido e vincule os dois serviços vinculados a este IR.
No caso da execução das atividades de Pesquisa/GetMetadata/Exclusão (também conhecidas como atividades de pipeline), expedição de atividades de transformação (também conhecidas como atividades externas) e operações de criação (conexão de teste, lista de pastas de navegação e lista de tabelas e dados de visualização), o IR na mesma região em que o Data Factory ou Workspace do Synapse está será usado.
No caso do Fluxo de Dados, o IR na região do Data Factory ou do Workspace do Synapse será usado.
Dica
Uma prática recomendada é garantir que os fluxos de dados sejam executados na mesma região que os armazenamentos de dados correspondentes, quando possível. Você pode fazer isso por meio da resolução automática do Azure IR (se a localização do armazenamento de dados for a mesma que a localização do Data Factory ou do Espaço de trabalho do Synapse) ou criando uma nova instância do Azure IR na mesma região que os armazenamentos de dados e executando os fluxos de dados nele.
Se você habilitar a Rede Virtual Gerenciada para resolução automática do Azure IR, o IR na região do Data Factory ou do Espaço de trabalho do Synapse será usado.
Você pode monitorar qual local de IR entra em vigor durante a execução da atividade na exibição de monitoramento de atividade de pipeline no Data Factory Studio ou no Synapse Studio ou no conteúdo de monitoramento de atividades.
Local do IR auto-hospedado
O IR auto-hospedado é logicamente registrado no Data Factory ou no Workspace do Synapse, e o computador usado para dar suporte a suas funcionalidades é fornecido por você. Portanto, não há nenhuma propriedade de localização explícita para IR auto-hospedado.
Quando usado para realizar a movimentação de dados, o IR auto-hospedado extrai dados da origem e grava-os no destino.
Local do Azure-SSIS IR
Observação
Os runtimes de integração do Azure-SSIS não têm suporte atualmente em pipelines do Synapse.
Selecionar a localização certa para o IR do Azure-SSIS é essencial para alcançar alto desempenho em seus fluxos de trabalho de ETL (extrair, transformar e carregar).
- A localização do Azure-SSIS IR não precisa ser igual à localização do seu Data Factory, mas deve ser igual à localização do seu Banco de Dados SQL do Azure ou Instância Gerenciada de SQL em que o SSISDB está localizado. Desse modo, o Azure-SSIS IR pode acessar o SSISDB facilmente, sem incorrer em tráfego excessivo entre localizações diferentes.
- Se você não tiver um Banco de Dados SQL do Azure ou Instância Gerenciada de SQL, mas tiver fontes/destinos de dados locais, deverá criar um novo Banco de Dados SQL do Azure ou Instância Gerenciada de SQL na mesma localização de uma rede virtual conectada à rede local. Dessa forma, você pode criar seu Azure-SSIS IR usando o novo Banco de Dados SQL do Azure ou a nova Instância Gerenciada de SQL e ingressar nessa rede virtual. Tudo está na mesma localização, minimizando a movimentação de dados e os custos associados, maximizando o desempenho.
- Se a localização do seu Banco de Dados SQL do Azure/Instância Gerenciada do SQL existente no SSISDB não for a mesma que a localização de uma rede virtual conectada à rede local, primeiro crie o Azure-SSIS IR usando um Banco de Dados SQL do Azure/Instância Gerenciada do SQL e ingressando em outra rede virtual na mesma localização. Depois, configure uma rede virtual para a conexão de rede virtual entre as diferentes localizações.
O diagrama a seguir mostra as configurações de localização de Data Factory e os respectivos runtimes de integração:
Determinando qual IR usar
Se uma atividade for associada a mais de um tipo de runtime de integração, ela será resolvida para um deles. O runtime de integração auto-hospedado tem precedência sobre o Azure IR no Azure Data Factory ou as instâncias de workspace do Synapse usando uma rede virtual gerenciada. E essas instâncias têm precedência sobre o Azure IR global.
Por exemplo, uma atividade Copy é usada para copiar dados da origem para o coletor. O Azure IR global está associado ao serviço vinculado de origem, e um Azure IR em uma rede virtual gerenciada do Azure Data Factory se associa ao serviço vinculado de coletor. O resultado é que tanto o serviço vinculado de origem como o de coletor usam o Azure IR na rede virtual gerenciada do Azure Data Factory. Porém, se um runtime de integração auto-hospedada estiver associado ao serviço vinculado de origem, tanto o serviço vinculado de origem como o de coletor usarão o runtime de integração auto-hospedada.
Atividade de cópia
A atividade Copy requer que serviços vinculados de origem e de coletor definam a direção do fluxo de dados. A lógica a seguir é usada para determinar qual instância do Integration Runtime é usada para realizar a cópia:
- Cópia entre duas fontes de dados na nuvem: se os serviços vinculados de origem e de coletor estiver usando o Azure IR, o Azure IR regional será usado se for especificado, ou a localização do Azure IR será determinada automaticamente se a opção de resolução automática de IR (padrão) tiver sido escolhida, conforme descrito na seção Localização do runtime de integração.
- Copiando entre uma fonte de dados de nuvem e uma fonte de dados na rede privada: se o serviço vinculado de origem ou de coletor aponta para um IR auto-hospedado, a atividade de cópia é executada no runtime auto-hospedado.
- Copiando entre duas fontes de dados em uma rede privada: o serviço vinculado de origem e o de coletor devem apontar para a mesma instância de runtime de integração, e esse IR é usado para executar a atividade Copy.
Atividade de pesquisa e GetMetadata
A atividade de pesquisa e GetMetadata é executada no runtime de integração associado ao serviço vinculado de armazenamento de dados.
Atividades de transformação externa
Cada atividade de transformação externa que usa um mecanismo de computação externo tem um serviço vinculado de computação de destino, que aponta para um runtime de integração. Essa instância do runtime de integração determina o local do qual a atividade de transformação codificada externa é expedida.
Atividade de Fluxo de Dados
As atividades do Fluxo de Dados são executadas no Azure IR associado a ela. As propriedades de fluxo de dados em seu Azure IR determinam a computação do Spark utilizada e são totalmente gerenciadas pelo serviço.
Runtime de integração em CI/CD
Os runtimes de integração não são alterados com frequência e são semelhantes em todas as fases em sua CI/CD. O Data Factory espera que você tenha o mesmo nome e tipo de runtime de integração em todas as fases da integração contínua e entrega contínua. Se desejar compartilhar runtimes de integração em todas as fases, considere usar um alocador dedicado apenas para conter os runtimes de integração compartilhados. Você pode então usar esse alocador compartilhado em todos os seus ambientes como um tipo de runtime de integração vinculado.
Conteúdo relacionado
Veja os artigos a seguir:
- Criar o Integration Runtime do Azure
- Criar um Integration Runtime auto-hospedado
- Criar um Integration Runtime do Azure-SSIS. Este artigo expande o tutorial e fornece instruções sobre como usar a Instância Gerenciada do SQL e unir o IR a uma rede virtual.