Copiar dados de ou para um sistema de arquivos usando o Azure Data Factory ou o Azure Synapse Analytics
APLICA-SE A: Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Dica
Experimente o Data Factory no Microsoft Fabric, uma solução de análise tudo-em-um para empresas. O Microsoft Fabric abrange desde movimentação de dados até ciência de dados, análise em tempo real, business intelligence e relatórios. Saiba como iniciar uma nova avaliação gratuitamente!
Este artigo descreve como copiar os dados de e para o sistema de arquivos. Para saber mais, leia o artigo introdutório do Azure Data Factory ou do Azure Synapse Analytics.
Funcionalidades com suporte
Este conector do sistema de arquivos tem suporte para as seguintes funcionalidades:
| Funcionalidades com suporte | IR |
|---|---|
| Atividade de cópia (origem/coletor) | ① ② |
| Atividade de pesquisa | ① ② |
| Atividade GetMetadata | ① ② |
| Excluir atividade | ① ② |
① Runtime de integração do Azure ② Runtime de integração auto-hospedada
Especificamente, este conector do sistema de arquivos dá suporte à:
- Cópia de arquivos de/para o compartilhamento de arquivos da rede. Para usar um compartilhamento de arquivo do Linux, instale o Samba no seu servidor Linux.
- Cópia de arquivos usando a autenticação do Windows.
- Cópia de arquivos no estado em que se encontram ou análise/geração de arquivos com os formatos de arquivo e codecs de compactação com suporte.
Pré-requisitos
Se o armazenamento de dados estiver localizado dentro de uma rede local, em uma rede virtual do Azure ou na Amazon Virtual Private Cloud, você precisará configurar um runtime de integração auto-hospedada para se conectar a ele.
Se o armazenamento de dados for um serviço de dados de nuvem gerenciado, você poderá usar o Azure Integration Runtime. Se o acesso for restrito aos IPs que estão aprovados nas regras de firewall, você poderá adicionar IPs do Azure Integration Runtime à lista de permissões.
Você também pode usar o recurso de runtime de integração da rede virtual gerenciada no Azure Data Factory para acessar a rede local sem instalar e configurar um runtime de integração auto-hospedada.
Para obter mais informações sobre os mecanismos de segurança de rede e as opções compatíveis com o Data Factory, consulte Estratégias de acesso a dados.
Introdução
Para executar a atividade de Cópia com um pipeline, será possível usar as ferramentas ou os SDKs abaixo:
- A ferramenta Copiar Dados
- O portal do Azure
- O SDK do .NET
- O SDK do Python
- PowerShell do Azure
- A API REST
- O modelo do Azure Resource Manager
Criar um serviço vinculado ao sistema de arquivos usando a interface do usuário
Use as etapas a seguir para criar um serviço vinculado ao sistema de arquivos na interface do usuário do portal do Azure.
Navegue até a guia Gerenciar no workspace do Azure Data Factory ou do Synapse e selecione Serviços Vinculados. Depois, selecione Novo:
Pesquise por “arquivo” e selecione o conector do Sistema de Arquivos.
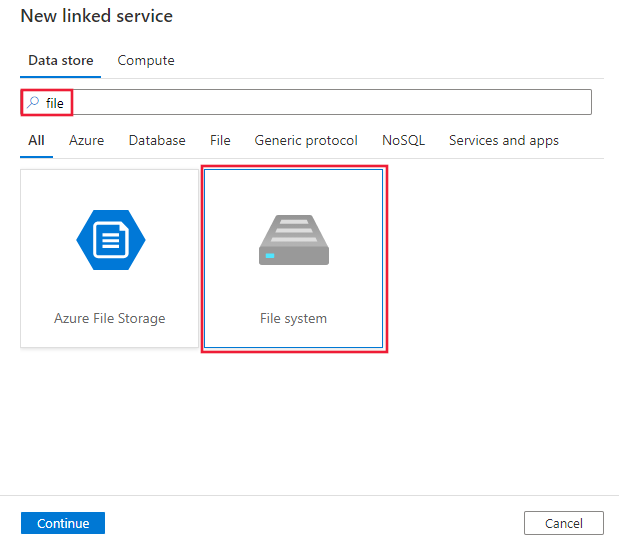
Configure os detalhes do serviço, teste a conexão e crie o novo serviço vinculado.
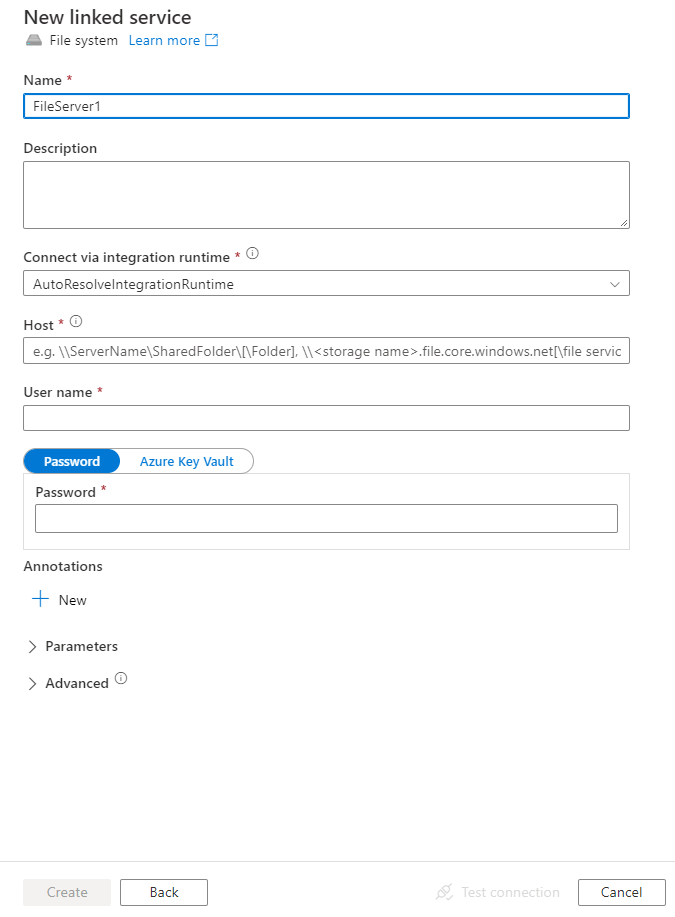
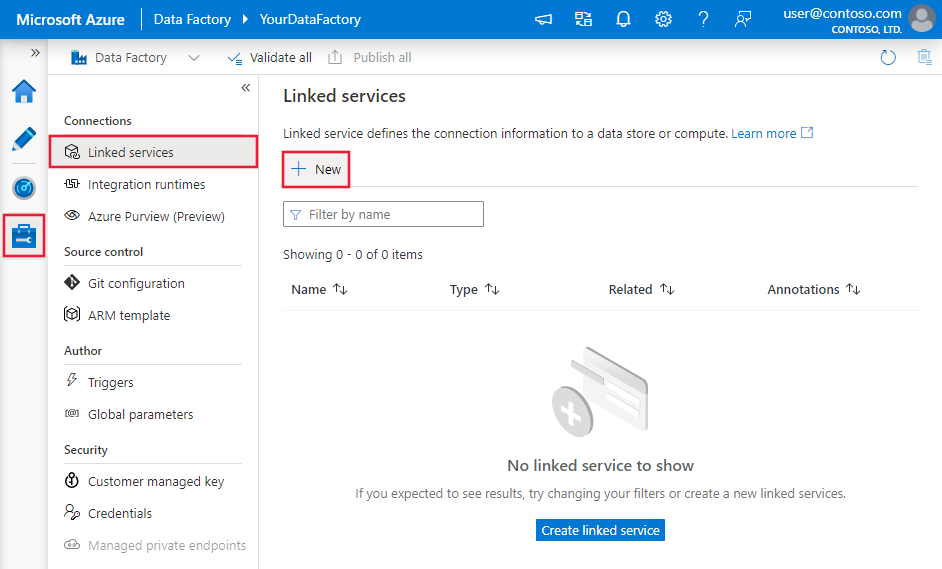
Detalhes da configuração do conector
As seções que se seguem fornecem detalhes sobre as propriedades que são usadas para definir entidades de pipeline do Data Factory e do Synapse específicas do sistema de arquivos.
Propriedades do serviço vinculado
As propriedades a seguir têm suporte no serviço vinculado do sistema de arquivos:
| Propriedade | Descrição | Obrigatório |
|---|---|---|
| type | A propriedade type deve ser definida como: FileServer. | Sim |
| host | Especifica o caminho raiz da pasta que você deseja copiar. Use o caractere de escape "" para caracteres especiais na cadeia de caracteres. Confira Definições de conjunto de dados e serviço vinculado de exemplo para obter exemplos. | Sim |
| userId | Especifique a ID do usuário que tem acesso ao servidor. | Sim |
| password | Especifique a senha do usuário (userId). Marque este campo como um SecureString para armazená-lo com segurança ou referencie um segredo armazenado no Azure Key Vault. | Sim |
| connectVia | O Integration Runtime a ser usado para se conectar ao armazenamento de dados. Saiba mais na seção Pré-requisitos. Se não for especificado, ele usa o Integration Runtime padrão do Azure. | Não |
Definições de conjunto de dados e serviço vinculado de exemplo
| Cenário | "host" em definição de serviço vinculado | "folderPath" em definição de conjunto de dados |
|---|---|---|
| Pasta compartilhada remota: Exemplos: \\myserver\share\* ou \\myserver\share\folder\subfolder\* |
Em JSON: \\\\myserver\\shareNa interface do usuário: \\myserver\share |
Em JSON: .\\ ou folder\\subfolderNa interface do usuário: .\ ou folder\subfolder |
Observação
Durante a criação via interface do usuário, não é necessário inserir barras invertidas duplas (\\) para escape, como é feito via JSON, especifique a barra invertida simples.
Observação
Não há suporte para a cópia de arquivos do computador local no Azure Integration Runtime.
Consulte a linha de comando aqui para habilitar o acesso ao computador local em runtime de integração auto-hospedada. Ele é desabilitado por padrão.
Exemplo:
{
"name": "FileLinkedService",
"properties": {
"type": "FileServer",
"typeProperties": {
"host": "<host>",
"userId": "<domain>\\<user>",
"password": {
"type": "SecureString",
"value": "<password>"
}
},
"connectVia": {
"referenceName": "<name of Integration Runtime>",
"type": "IntegrationRuntimeReference"
}
}
}
Propriedades do conjunto de dados
Para obter uma lista completa das seções e propriedades disponíveis para definir os conjuntos de dados, confira o artigo sobre Conjuntos de Dados.
O Azure Data Factory é compatível com os formatos de arquivo a seguir. Confira cada artigo para obter configurações baseadas em formato.
- Formato Avro
- Formato binário
- Formato de texto delimitado
- Formato do Excel
- Formato JSON
- Formato ORC
- Formato Parquet
- Formato XML
As seguintes propriedades são compatíveis com o sistema de arquivos em location configurações de conjunto de dados baseado no formato:
| Propriedade | Descrição | Obrigatório |
|---|---|---|
| type | A propriedade de tipo em location no conjunto de dados deve ser definida para FileServerLocation. |
Sim |
| folderPath | O caminho para a pasta. Se quiser usar um caractere curinga para filtrar a pasta, ignore essa configuração e especifique nas configurações de origem da atividade. Você precisará configurar o local de compartilhamento de arquivos no ambiente Windows ou Linux para expor a pasta para compartilhamento. | Não |
| fileName | O nome do arquivo sob o folderPath fornecido. Se quiser usar um caractere curinga para filtrar os arquivos, ignore essa configuração e especifique nas configurações de origem da atividade. | Não |
Exemplo:
{
"name": "DelimitedTextDataset",
"properties": {
"type": "DelimitedText",
"linkedServiceName": {
"referenceName": "<File system linked service name>",
"type": "LinkedServiceReference"
},
"schema": [ < physical schema, optional, auto retrieved during authoring > ],
"typeProperties": {
"location": {
"type": "FileServerLocation",
"folderPath": "root/folder/subfolder"
},
"columnDelimiter": ",",
"quoteChar": "\"",
"firstRowAsHeader": true,
"compressionCodec": "gzip"
}
}
}
Propriedades da atividade de cópia
Para obter uma lista completa das seções e propriedades disponíveis para definir atividades, confia o artigo Pipelines. Esta seção fornece uma lista das propriedades com suporte pela fonte e pelo coletor do sistema de arquivos.
Sistema de arquivos como origem
O Azure Data Factory é compatível com os formatos de arquivo a seguir. Confira cada artigo para obter configurações baseadas em formato.
- Formato Avro
- Formato binário
- Formato de texto delimitado
- Formato do Excel
- Formato JSON
- Formato ORC
- Formato Parquet
- Formato XML
As seguintes propriedades são compatíveis com o sistema de arquivos em storeSettings configurações de fonte de cópia com base no formato:
| Propriedade | Descrição | Obrigatório |
|---|---|---|
| type | A propriedade de tipo em storeSettings deve ser definida para FileServerReadSettings. |
Sim |
| Localize os arquivos a serem copiados: | ||
| OPÇÃO 1: caminho estático |
Copiar do caminho de pasta/arquivo especificado no conjunto de dados. Se quiser copiar todos os arquivos de uma pasta, especifique também wildcardFileName como *. |
|
| OPÇÃO 2: filtro no lado do servidor - fileFilter |
O filtro nativo do lado servidor de arquivos, que fornece melhor desempenho do que o filtro curinga da OPÇÃO 3. Use * para corresponder a zero ou mais caracteres e ? para corresponder a zero ou a um caractere. Saiba mais sobre a sintaxe e as observações em Comentáriosnesta seção. |
Não |
| OPÇÃO 3: filtro do lado do cliente - wildcardFolderPath |
O caminho da pasta com caracteres curinga para filtrar as pastas de origem. Esse filtro ocorre dentro do serviço, que enumera as pastas/arquivos no caminho fornecido e aplica o filtro de caractere curinga. Os curingas permitidos são: * (corresponde a zero ou mais caracteres) e ? (corresponde a zero ou caractere único); use ^ para escape se o nome de pasta atual tiver curinga ou esse caractere interno de escape. Veja mais exemplos em Exemplos de filtro de pastas e arquivos. |
Não |
| OPÇÃO 3: filtro do lado do cliente - wildcardFileName |
O nome do arquivo com caracteres curinga sob o folderPath/wildcardFolderPath fornecido para filtrar os arquivos de origem. Esse filtro ocorre dentro do serviço, que enumera os arquivos no caminho fornecido e aplica o filtro curinga. Os curingas permitidos são: * (corresponde a zero ou mais caracteres) e ? (corresponde a zero ou caractere único); use ^ para escape se o nome de arquivo real tiver curinga ou esse caractere interno de escape.Veja mais exemplos em Exemplos de filtro de pastas e arquivos. |
Sim |
| OPÇÃO 3: uma lista de arquivos - fileListPath |
Indica a cópia de um determinado conjunto de arquivos. Aponte para um arquivo de texto que inclui a lista de arquivos que você deseja copiar com um arquivo por linha, que é o caminho relativo para o caminho configurado no conjunto de dados. Ao utilizar essa opção, não especifique o nome do arquivo no conjunto de dados. Veja mais exemplos em Exemplos de lista de arquivos. |
Não |
| Configurações adicionais: | ||
| recursiva | Indica se os dados são lidos recursivamente das subpastas ou somente da pasta especificada. Quando recursiva é definida como true e o coletor é um armazenamento baseado em arquivo, uma pasta vazia ou subpasta não é copiada ou criada no coletor. Os valores permitidos são true (padrão) e false. Essa propriedade não se aplica quando você configura fileListPath. |
Não |
| deleteFilesAfterCompletion | Indica se os arquivos binários serão excluídos do armazenamento de origem após serem movidos com êxito para o armazenamento de destino. A exclusão de arquivo é por arquivo. Isto significa que, quando a atividade falhar, você visualizará alguns arquivos já copiados para o destino e excluídos da origem, enquanto outros ainda permanecem no repositório de origem. Essa propriedade só é válida no cenário de cópia de arquivos binários. O valor padrão é false. |
Não |
| modifiedDatetimeStart | Filtro de arquivos com base no atributo: Última Modificação. Os arquivos são selecionados se a hora da última modificação for maior ou igual a modifiedDatetimeStart e menor que modifiedDatetimeEnd. A hora é aplicada ao fuso horário UTC no formato YYYY-MM-DDTHH:mm:ssZ. As propriedades podem ser NULL, o que significa que nenhum filtro de atributo de arquivo é aplicado ao conjunto de dados. Quando modifiedDatetimeStart tem o valor de data e hora, mas modifiedDatetimeEnd for NULL, isso significa que serão selecionados os arquivos cujo último atributo modificado for maior ou igual ao valor de data e hora. Quando modifiedDatetimeEnd tiver o valor de datetime, mas modifiedDatetimeStart for NULL, isso significa que serão selecionados os arquivos cujo último atributo modificado for menor que o valor de datetime.Essa propriedade não se aplica quando você configura fileListPath. |
Não |
| modifiedDatetimeEnd | O mesmo que modifiedDateTimeStart. | Não |
| enablePartitionDiscovery | Para os arquivos que são particionados, especifique se deseja analisar as partições do caminho do arquivo e incluí-las como colunas de origem extras. Os valores permitidos são false (padrão) e true. |
No |
| partitionRootPath | Quando a descoberta de partição estiver habilitada, especifique o caminho raiz absoluto para ler as pastas particionadas como colunas de dados. Se não for especificado, será por padrão, – Quando você usa o caminho do arquivo no conjunto de dados ou na lista de arquivos na origem, o caminho raiz da partição é o caminho configurado no conjunto de dados. - Quando você utiliza o filtro da pasta curinga, o caminho raiz da partição é o subcaminho antes do primeiro curinga. Por exemplo, supondo que você configure o caminho no conjunto de dados como "root/folder/year=2020/month=08/day=27": - Se você especificar o caminho da raiz da partição como "root/folder/year=2020", a atividade de Cópia gerará mais duas colunas month e day com valor "08" e "27", respectivamente, além das colunas dentro dos arquivos.- Se o caminho da raiz da partição não for especificado, nenhuma coluna extra será gerada. |
Não |
| maxConcurrentConnections | O limite superior de conexões simultâneas estabelecidas com o armazenamento de dados durante a execução da atividade. Especifique um valor somente quando desejar limitar as conexões simultâneas. | Não |
Exemplo:
"activities":[
{
"name": "CopyFromFileSystem",
"type": "Copy",
"inputs": [
{
"referenceName": "<Delimited text input dataset name>",
"type": "DatasetReference"
}
],
"outputs": [
{
"referenceName": "<output dataset name>",
"type": "DatasetReference"
}
],
"typeProperties": {
"source": {
"type": "DelimitedTextSource",
"formatSettings":{
"type": "DelimitedTextReadSettings",
"skipLineCount": 10
},
"storeSettings":{
"type": "FileServerReadSettings",
"recursive": true,
"wildcardFolderPath": "myfolder*A",
"wildcardFileName": "*.csv"
}
},
"sink": {
"type": "<sink type>"
}
}
}
]
Sistema de arquivos como coletor
O Azure Data Factory é compatível com os formatos de arquivo a seguir. Confira cada artigo para obter configurações baseadas em formato.
Observação
A opção MergeFiles copyBehavior só está disponível em pipelines do Azure Data Factory e não em pipelines do Synapse Analytics.
As seguinte propriedades são compatíveis com o sistema de arquivos em storeSettings configurações de coletor de cópia com base no formato:
| Propriedade | Descrição | Obrigatório |
|---|---|---|
| type | A propriedade de tipo em storeSettings deve ser definida para FileServerWriteSettings. |
Sim |
| copyBehavior | Define o comportamento de cópia quando a fonte for de arquivos de um armazenamento de dados baseado em arquivo. Valores permitidos são: – PreserveHierarchy (padrão): Preserva a hierarquia de arquivos na pasta de destino. O caminho relativo do arquivo de origem para a pasta de origem é idêntico ao caminho relativo do arquivo de destino para a pasta de destino. – FlattenHierarchy: Todos os arquivos da pasta de origem estão no primeiro nível da pasta de destino. Os arquivos de destino têm os nomes gerados automaticamente. – MergeFiles: Mescla todos os arquivos da pasta de origem em um arquivo. Se o nome do arquivo for especificado, o nome do arquivo mesclado será o nome especificado. Caso contrário, ele será um nome de arquivo gerado automaticamente. |
Não |
| maxConcurrentConnections | O limite superior de conexões simultâneas estabelecidas com o armazenamento de dados durante a execução da atividade. Especifique um valor somente quando desejar limitar as conexões simultâneas. | Não |
Exemplo:
"activities":[
{
"name": "CopyToFileSystem",
"type": "Copy",
"inputs": [
{
"referenceName": "<input dataset name>",
"type": "DatasetReference"
}
],
"outputs": [
{
"referenceName": "<Parquet output dataset name>",
"type": "DatasetReference"
}
],
"typeProperties": {
"source": {
"type": "<source type>"
},
"sink": {
"type": "ParquetSink",
"storeSettings":{
"type": "FileServerWriteSettings",
"copyBehavior": "PreserveHierarchy"
}
}
}
}
]
Exemplos de filtro de pasta e arquivo
Esta seção descreve o comportamento resultante do caminho da pasta e do nome de arquivo com filtros curinga.
| folderPath | fileName | recursiva | Estrutura da pasta de origem e resultado do filtro (os arquivos em negrito são recuperados) |
|---|---|---|---|
Folder* |
(vazio, usar padrão) | false | FolderA Arquivo1.csv File2.json Subpasta1 File3.csv File4.json File5.csv OutraPastaB Arquivo6.csv |
Folder* |
(vazio, usar padrão) | true | FolderA Arquivo1.csv File2.json Subpasta1 File3.csv File4.json File5.csv OutraPastaB Arquivo6.csv |
Folder* |
*.csv |
false | FolderA Arquivo1.csv Arquivo2.json Subpasta1 File3.csv File4.json File5.csv OutraPastaB Arquivo6.csv |
Folder* |
*.csv |
true | FolderA Arquivo1.csv Arquivo2.json Subpasta1 File3.csv File4.json File5.csv OutraPastaB Arquivo6.csv |
Exemplos de lista de arquivos
Esta seção descreve o comportamento resultante do uso do caminho da lista de arquivos na origem da atividade de cópia.
Supondo que você tenha a seguinte estrutura de pasta de origem e queira copiar os arquivos em negrito:
| Exemplo de estrutura de origem | Conteúdo em FileListToCopy.txt | Configuração do pipeline |
|---|---|---|
| root FolderA Arquivo1.csv Arquivo2.json Subpasta1 File3.csv File4.json File5.csv Metadados FileListToCopy.txt |
File1.csv Subfolder1/File3.csv Subfolder1/File5.csv |
No conjunto de dados: - Caminho da pasta: root/FolderANa origem da atividade de cópia: - Caminho da lista de arquivos: root/Metadata/FileListToCopy.txt O caminho da lista de arquivos aponta para um arquivo de texto no mesmo armazenamento de dados. Ele inclui uma lista de arquivos a serem copiados. Cada linha contém o caminho relativo para o arquivo com base no caminho raiz configurado no conjunto de dados. |
exemplos de recursive e copyBehavior
Esta seção descreve o comportamento resultante da operação de cópia para diferentes combinações de valores recursive e copyBehavior.
| recursiva | copyBehavior | Estrutura de pasta de origem | Destino resultante |
|---|---|---|---|
| true | preserveHierarchy | Pasta1 Arquivo1 Arquivo2 Subpasta1 Arquivo3 Arquivo4 Arquivo5 |
A pasta de destino Pasta1 é criada com a mesma estrutura da origem: Pasta1 Arquivo1 Arquivo2 Subpasta1 Arquivo3 Arquivo4 Arquivo5. |
| true | flattenHierarchy | Pasta1 Arquivo1 Arquivo2 Subpasta1 Arquivo3 Arquivo4 Arquivo5 |
A Pasta1 de destino é criada com a seguinte estrutura: Pasta1 nome gerado automaticamente para o Arquivo1 nome gerado automaticamente para o Arquivo2 nome gerado automaticamente para o Arquivo3 nome gerado automaticamente para o Arquivo4 nome gerado automaticamente para o Arquivo5 |
| true | mergeFiles | Pasta1 Arquivo1 Arquivo2 Subpasta1 Arquivo3 Arquivo4 Arquivo5 |
A Pasta1 de destino é criada com a seguinte estrutura: Pasta1 Os conteúdos de Arquivo1 + Arquivo2 + Arquivo3 + Arquivo4 + Arquivo5 são mesclados em um único arquivo com um nome de arquivo gerado automaticamente |
| false | preserveHierarchy | Pasta1 Arquivo1 Arquivo2 Subpasta1 Arquivo3 Arquivo4 Arquivo5 |
A pasta de destino Pasta1 é criada com a seguinte estrutura Pasta1 Arquivo1 Arquivo2 Subpasta1 com Arquivo3, Arquivo4 e Arquivo5 não selecionada. |
| false | flattenHierarchy | Pasta1 Arquivo1 Arquivo2 Subpasta1 Arquivo3 Arquivo4 Arquivo5 |
A pasta de destino Pasta1 é criada com a seguinte estrutura Pasta1 nome gerado automaticamente para o Arquivo1 nome gerado automaticamente para o Arquivo2 Subpasta1 com Arquivo3, Arquivo4 e Arquivo5 não são selecionados. |
| false | mergeFiles | Pasta1 Arquivo1 Arquivo2 Subpasta1 Arquivo3 Arquivo4 Arquivo5 |
A pasta de destino Pasta1 é criada com a seguinte estrutura Pasta1 Os conteúdos de Arquivo1 + Arquivo2 são mesclados em um arquivo com um nome de arquivo gerado automaticamente. nome gerado automaticamente para o Arquivo1 Subpasta1 com Arquivo3, Arquivo4 e Arquivo5 não selecionada. |
Pesquisar propriedades de atividade
Para saber detalhes sobre as propriedades, verifique Atividade de pesquisa.
Propriedades de atividade GetMetadata
Para saber detalhes sobre as propriedades, confira Atividade GetMetadata.
Excluir propriedades da atividade
Para saber mais detalhes sobre as propriedades, confira Atividade Delete.
Modelos herdados
Observação
Os modelos a seguir ainda têm suporte no estado em que se encontram, para compatibilidade com versões anteriores. É recomendável usar o novo modelo mencionado nas seções acima no futuro, e a interface do usuário de criação mudou para gerar o novo modelo.
Modelo de conjunto de dados herdado
| Propriedade | Descrição | Obrigatório |
|---|---|---|
| type | A propriedade type do conjunto de dados deve ser definida como: FileShare | Sim |
| folderPath | Caminho para a pasta. O filtro curinga tem suporte. Os curingas permitidos são: * (corresponde a zero ou mais caracteres) e ? (corresponde a zero ou caractere único); use ^ para escape se o nome de pasta atual tiver curinga ou esse caractere interno de escape. Exemplos: rootfolder/subfolder /, veja mais exemplos nas definições de conjunto de dados e de serviço vinculado de exemplo e exemplos de filtro de arquivo e pasta. |
Não |
| fileName | Filtro de nome ou curinga para os arquivos no "folderPath" especificado. Se você não especificar um valor para essa propriedade, o conjunto de dados apontará para todos os arquivos na pasta. Para filtro, os curingas permitidos são: * (corresponde a zero ou mais caracteres) e ? (corresponde a zero ou caractere único).– Exemplo 1: "fileName": "*.csv"– Exemplo 2: "fileName": "???20180427.txt"Use ^ para se seu nome de arquivo real curinga ou esse caractere de escape dentro de escape.Quando fileName não é especificado para um conjunto de dados de saída e preserveHierarchy não é especificado no coletor de atividade, a atividade de cópia gera automaticamente o nome do arquivo com o seguinte padrão: "Data.[GUID da ID da execução de atividade].[GUID se FlattenHierarchy].[formato se configurado].[compactação se configurada] ", por exemplo: "Data.0a405f8a-93ff-4c6f-b3be-f69616f1df7a.txt.gz". Se você copiar da origem da tabela usando o nome da tabela em vez da consulta, o nome padrão será " [nome da tabela].[formato].[compactação se configurada] ", por exemplo: "MyTable.csv". |
Não |
| modifiedDatetimeStart | Filtro de arquivos com base no atributo: Última Modificação. Os arquivos são selecionados se a hora da última modificação for maior ou igual a modifiedDatetimeStart e menor que modifiedDatetimeEnd. A hora é aplicada ao fuso horário UTC no formato YYYY-MM-DDTHH:mm:ssZ. Lembre-se de que o desempenho geral da movimentação de dados é afetado com a habilitação dessa configuração quando você deseja filtrar grandes quantidades de arquivos. As propriedades podem ser NULL, o que significa que nenhum filtro de atributo de arquivo é aplicado ao conjunto de dados. Quando modifiedDatetimeStart tem o valor de data e hora, mas modifiedDatetimeEnd for NULL, isso significa que serão selecionados os arquivos cujo último atributo modificado for maior ou igual ao valor de data e hora. Quando modifiedDatetimeEnd tiver o valor de datetime, mas modifiedDatetimeStart for NULL, isso significa que serão selecionados os arquivos cujo último atributo modificado for menor que o valor de datetime. |
Não |
| modifiedDatetimeEnd | Filtro de arquivos com base no atributo: Última Modificação. Os arquivos são selecionados se a hora da última modificação for maior ou igual a modifiedDatetimeStart e menor que modifiedDatetimeEnd. A hora é aplicada ao fuso horário de UTC no formato "2018-12-01T05:00:00Z". Lembre-se de que o desempenho geral da movimentação de dados é afetado com a habilitação dessa configuração quando você deseja filtrar grandes quantidades de arquivos. As propriedades podem ser NULL, o que significa que nenhum filtro de atributo de arquivo é aplicado ao conjunto de dados. Quando modifiedDatetimeStart tem o valor de data e hora, mas modifiedDatetimeEnd for NULL, isso significa que serão selecionados os arquivos cujo último atributo modificado for maior ou igual ao valor de data e hora. Quando modifiedDatetimeEnd tiver o valor de datetime, mas modifiedDatetimeStart for NULL, isso significa que serão selecionados os arquivos cujo último atributo modificado for menor que o valor de datetime. |
Não |
| format | Se você quiser copiar arquivos no estado em que se encontram entre repositórios baseados em arquivo (cópia binária), ignore a seção de formato nas duas definições de conjunto de dados de entrada e de saída. Se você quer analisar ou gerar arquivos com um formato específico, os seguintes tipos de formato de arquivo são compatíveis: TextFormat, JsonFormat, AvroFormat, OrcFormat, ParquetFormat. Defina a propriedade type sob formato como um desses valores. Para saber mais, veja as seções Formato de texto, Formato Json, Formato Avro, Formato Orc, e Formato Parquet. |
Não (somente para o cenário de cópia binária) |
| compactação | Especifique o tipo e o nível de compactação para os dados. Para obter mais informações, consulte Formatos de arquivo e codecs de compactação com suporte. Tipos compatíveis são: GZip, Deflate, BZip2 e ZipDeflate. Níveis compatíveis são: Ideal e Mais Rápido. |
Não |
Dica
Para copiar todos os arquivos em uma pasta, especifique folderPath somente.
Para copiar um único arquivo com um determinado nome, especifique folderPath com parte da pasta e fileName com nome de arquivo.
Para copiar um subconjunto de arquivos em uma pasta, especifique folderPath com parte da pasta e fileName com filtro curinga.
Observação
Se você estivesse usando a propriedade "fileFilter" para o filtro de arquivo, ele ainda tem suporte como-é, enquanto são sugeridos para usar o novo recurso de filtro adicionado ao "fileName" no futuro.
Exemplo:
{
"name": "FileSystemDataset",
"properties": {
"type": "FileShare",
"linkedServiceName":{
"referenceName": "<file system linked service name>",
"type": "LinkedServiceReference"
},
"typeProperties": {
"folderPath": "folder/subfolder/",
"fileName": "*",
"modifiedDatetimeStart": "2018-12-01T05:00:00Z",
"modifiedDatetimeEnd": "2018-12-01T06:00:00Z",
"format": {
"type": "TextFormat",
"columnDelimiter": ",",
"rowDelimiter": "\n"
},
"compression": {
"type": "GZip",
"level": "Optimal"
}
}
}
}
Modelo de origem de atividade de cópia herdado
| Propriedade | Descrição | Obrigatório |
|---|---|---|
| type | A propriedade type da fonte da atividade de cópia deve ser definida como: FileSystemSource | Sim |
| recursiva | Indica se os dados são lidos recursivamente das subpastas ou somente da pasta especificada. Quando o recursivo estiver definido como verdadeiro e o coletor for um armazenamento baseado em arquivo, a subpasta/pasta vazia não será copiada/criada no coletor. Os valores permitidos são: true (padrão), false |
Não |
| maxConcurrentConnections | O limite superior de conexões simultâneas estabelecidas com o armazenamento de dados durante a execução da atividade. Especifique um valor somente quando desejar limitar as conexões simultâneas. | Não |
Exemplo:
"activities":[
{
"name": "CopyFromFileSystem",
"type": "Copy",
"inputs": [
{
"referenceName": "<file system input dataset name>",
"type": "DatasetReference"
}
],
"outputs": [
{
"referenceName": "<output dataset name>",
"type": "DatasetReference"
}
],
"typeProperties": {
"source": {
"type": "FileSystemSource",
"recursive": true
},
"sink": {
"type": "<sink type>"
}
}
}
]
Modelo do coletor de atividade de cópia herdado
| Propriedade | Descrição | Obrigatório |
|---|---|---|
| type | A propriedade type do coletor da atividade de cópia deve ser definida como: FileSystemSink | Sim |
| copyBehavior | Define o comportamento de cópia quando a fonte for de arquivos de armazenamento de dados baseado em arquivo. Valores permitidos são: - PreserveHierarchy (padrão): preserva a hierarquia de arquivos na pasta de destino. O caminho relativo do arquivo de origem para a pasta de origem é idêntico ao caminho relativo do arquivo de destino para a pasta de destino. - FlattenHierarchy: todos os arquivos da pasta de origem estão no primeiro nível da pasta de destino. Os nomes de arquivo de destino são gerados automaticamente. - MergeFiles: mescla todos os arquivos da pasta de origem em um arquivo. Nenhuma eliminação de duplicação de registro é executada durante a mesclagem. Se o nome do arquivo for especificado, o nome do arquivo mesclado será o nome especificado; caso contrário, será o nome de arquivo gerado automaticamente. |
Não |
| maxConcurrentConnections | O limite superior de conexões simultâneas estabelecidas com o armazenamento de dados durante a execução da atividade. Especifique um valor somente quando desejar limitar as conexões simultâneas. | Não |
Exemplo:
"activities":[
{
"name": "CopyToFileSystem",
"type": "Copy",
"inputs": [
{
"referenceName": "<input dataset name>",
"type": "DatasetReference"
}
],
"outputs": [
{
"referenceName": "<file system output dataset name>",
"type": "DatasetReference"
}
],
"typeProperties": {
"source": {
"type": "<source type>"
},
"sink": {
"type": "FileSystemSink",
"copyBehavior": "PreserveHierarchy"
}
}
}
]
Conteúdo relacionado
Para obter uma lista de armazenamentos de dados com suporte como coletores e fontes da atividade de cópia, confira os armazenamentos de dados com suporte.