Copiar dados para ou do Delta Lake do Azure Databricks usando o Azure Data Factory ou o Azure Synapse Analytics
APLICA-SE A: Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Dica
Experimente o Data Factory no Microsoft Fabric, uma solução de análise tudo-em-um para empresas. O Microsoft Fabric abrange desde movimentação de dados até ciência de dados, análise em tempo real, business intelligence e relatórios. Saiba como iniciar uma avaliação gratuita!
Este artigo descreve como usar a atividade Copy no Azure Data Factory e no Azure Synapse para copiar dados de e para o Delta Lake do Azure Databricks. Ele amplia o artigo Atividade Copy, que apresenta uma visão geral da atividade Copy.
Funcionalidades com suporte
Este conector do Delta Lake do Azure Databricks é compatível com as seguintes funcionalidades:
| Funcionalidades com suporte | IR |
|---|---|
| Atividade de cópia (origem/coletor) | ① ② |
| Fluxo de dados de mapeamento (origem/coletor) | ① |
| Atividade de pesquisa | ① ② |
① Runtime de integração do Azure ② Runtime de integração auto-hospedada
Em geral, o serviço dá suporte ao Delta Lake com as funcionalidades a seguir para atender às suas diversas necessidades.
- A atividade Copy dá suporte ao conector do Delta Lake do Azure Databricks para copiar dados de qualquer armazenamento de dados de origem compatível para uma tabela do Delta Lake do Azure Databricks e de uma tabela do delta lake para qualquer armazenamento de dados de coletor compatível. Ela faz uso do cluster do Databricks para executar a movimentação de dados. Confira detalhes a respeito na seção de Pré-requisitos.
- O fluxo de dados de mapeamento dá suporte ao formato Delta genérico no Armazenamento do Azure como origem e coletor para leitura e gravação de arquivos delta para ETL sem código. Ele é executado no Azure Integration Runtime gerenciado.
- As atividades do Databricks dão suporte à orquestração do ETL voltado para código ou da carga de trabalho de machine learning sobre o delta lake.
Pré-requisitos
Para usar este conector do Delta Lake do Azure Databricks, você precisa configurar um cluster no Azure Databricks.
- Para copiar dados para o Delta Lake, a atividade Copy invoca o cluster do Azure Databricks para ler dados de um Armazenamento do Microsoft Azure, que é a fonte original ou uma área de preparo onde o serviço grava pela primeira vez os dados de origem por meio de cópia preparada internamente. Saiba mais em Delta Lake como o coletor.
- De modo similar, para copiar dados do Delta Lake, a atividade Copy invoca o cluster do Azure Databricks para gravar dados em um Armazenamento do Microsoft Azure, que é o coletor original ou uma área de preparo de onde o serviço continua a gravar dados para o coletor final por meio de cópia preparada interna. Saiba mais em Delta Lake como a origem.
O cluster do Databricks precisa ter acesso a uma conta do Blob do Azure ou do Azure Data Lake Storage Gen2, ao contêiner de armazenamento/sistema de arquivos usado para origem/coletor/preparo e também ao contêiner/sistema de arquivos no qual você deseja gravar as tabelas do Delta Lake.
Para usar o Azure Data Lake Storage Gen2, você pode configurar uma entidade de serviço no cluster do Databricks como parte da configuração do Apache Spark. Siga as etapas em Acessar diretamente com a entidade de serviço.
Para usar o Armazenamento de Blobs do Azure, você pode configurar uma chave de acesso da conta de armazenamento ou token SAS no cluster do Databricks como parte da configuração do Apache Spark. Siga as etapas em Acessar o Armazenamento de Blobs do Azure usando a API do RDD.
Durante a execução da atividade Copy, se o cluster configurado for encerrado, o serviço o iniciará automaticamente. Se você cria um pipeline autor usando a interface do usuário de criação, será preciso ter um cluster ativo para operações como visualização de dados, pois o serviço não iniciará o cluster em seu nome.
Especificar a configuração de cluster
Na lista suspensa Modo de Cluster, selecione Standard.
Na lista suspensa Versão do Databricks Runtime, selecione uma versão do Databricks Runtime.
Ative a Otimização Automática adicionando as seguintes propriedades à sua Configuração do Spark:
spark.databricks.delta.optimizeWrite.enabled true spark.databricks.delta.autoCompact.enabled trueConfigure o cluster de acordo com as suas necessidades de integração e de dimensionamento.
Para obter detalhes de configuração do cluster, confira Configurar clusters.
Introdução
Para executar a atividade de Cópia com um pipeline, será possível usar as ferramentas ou os SDKs abaixo:
- A ferramenta Copiar Dados
- O portal do Azure
- O SDK do .NET
- O SDK do Python
- PowerShell do Azure
- A API REST
- O modelo do Azure Resource Manager
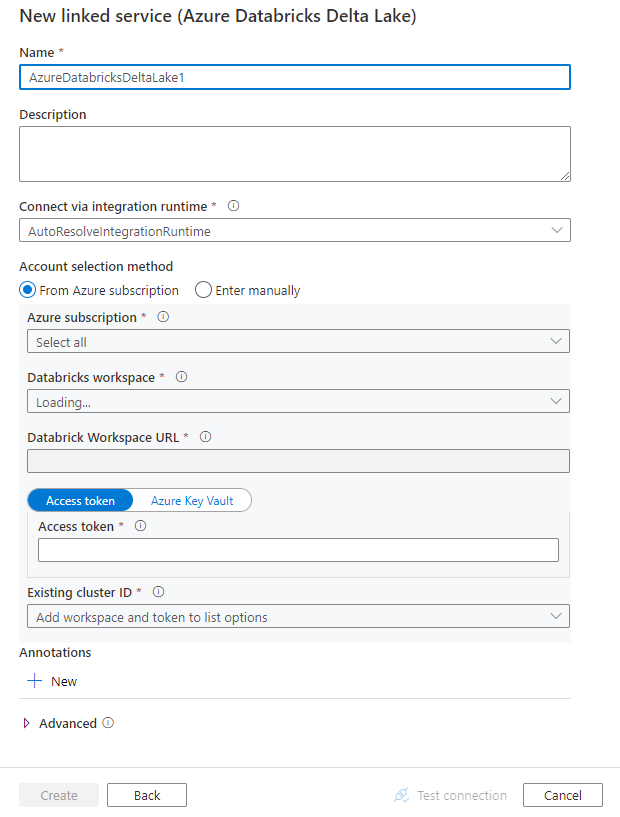
Criar um serviço vinculado ao Delta Lake do Azure Databricks usando a interface do usuário
Use as etapas a seguir para criar um serviço vinculado ao Delta Lake do Azure Databricks na interface do usuário do portal do Microsoft Azure.
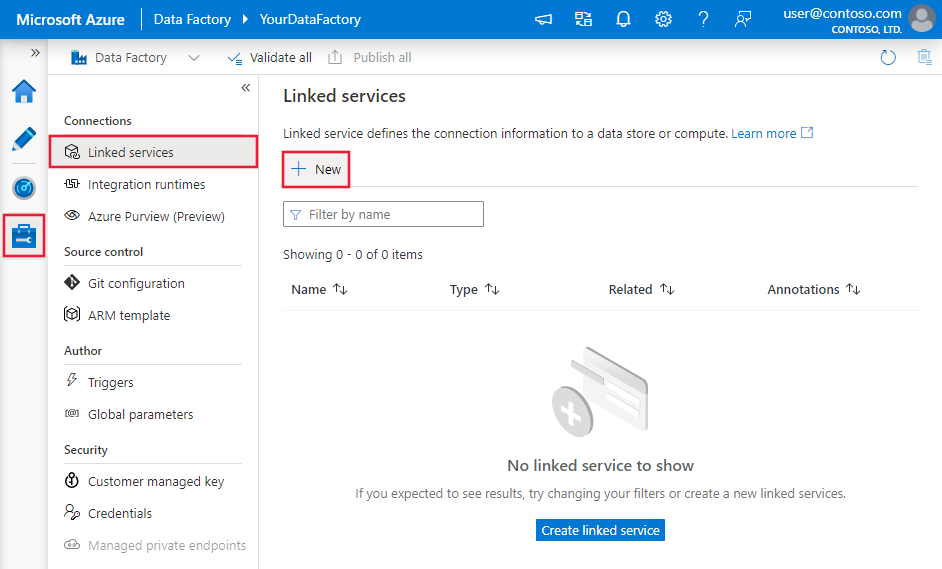
Navegue até a guia Gerenciar em seu espaço de trabalho do Azure Data Factory ou do Synapse e selecione Serviços Vinculados, em seguida, clique em Novo:
Pesquise por Delta e selecione o conector Delta Lake do Azure Databricks.

Configure os detalhes do serviço, teste a conexão e crie o novo serviço vinculado.
Detalhes da configuração do conector
As seções a seguir fornecem detalhes sobre propriedades que definem entidades específicas para um conector do Delta Lake do Azure Databricks.
Propriedades do serviço vinculado
O conector do Delta Lake do Azure Databricks dá suporte aos seguintes tipos de autenticação. Consulte as seções correspondentes para obter detalhes.
- Token de acesso
- Autenticação de identidade gerenciada atribuída pelo sistema
- Autenticação de identidade gerenciada atribuída pelo usuário
Token de acesso
As propriedades a seguir são compatíveis com o serviço vinculado do Delta Lake do Azure Databricks:
| Propriedade | Descrição | Obrigatório |
|---|---|---|
| type | A propriedade type precisa ser definida como: AzureDatabricksDeltaLake. | Sim |
| domínio | Especifique a URL do workspace do Azure Databricks, por exemplo, https://adb-xxxxxxxxx.xx.azuredatabricks.net. |
|
| clusterId | Especifique a ID de um cluster existente. Esse deve ser um cluster interativo já criado. Você pode encontrar a ID do cluster de um cluster interativo no workspace do Databricks -> Clusters -> Nome do Cluster Interativo -> Configuração -> Marcas. Saiba mais. |
|
| accessToken | O token de acesso é necessário para que o serviço seja autenticado no Azure Databricks. O token de acesso precisa ser gerado a partir do workspace do Databricks. Etapas mais detalhadas para encontrar o token de acesso podem ser encontradas aqui. | |
| connectVia | O runtime de integração que é usado para se conectar ao armazenamento de dados. Você poderá usar o runtime de integração do Azure ou um runtime de integração auto-hospedada (se o seu armazenamento de dados estiver localizado em uma rede privada). Se não for especificado, ele usará o runtime de integração padrão do Azure. | Não |
Exemplo:
{
"name": "AzureDatabricksDeltaLakeLinkedService",
"properties": {
"type": "AzureDatabricksDeltaLake",
"typeProperties": {
"domain": "https://adb-xxxxxxxxx.xx.azuredatabricks.net",
"clusterId": "<cluster id>",
"accessToken": {
"type": "SecureString",
"value": "<access token>"
}
}
}
}
Autenticação de identidade gerenciada atribuída pelo sistema
Para saber mais sobre identidades gerenciadas atribuídas pelo sistema para recursos do Azure, confira Identidade gerenciada atribuída pelo sistema para recursos do Azure.
Para usar a autenticação de identidade gerenciada atribuída pelo sistema, siga estas etapas para conceder permissões:
Recuperar as informações de identidade gerenciada copiando o valor de ID do objeto de identidade gerenciada gerado junto com seu data factory ou no workspace do Synapse.
Conceda à identidade gerenciada as permissões corretas no Azure Databricks. Em geral, você deve conceder pelo menos a função Colaborador à sua identidade gerenciada atribuída pelo sistema no Controle de acesso (IAM) do Azure Databricks.
As propriedades a seguir são compatíveis com o serviço vinculado do Delta Lake do Azure Databricks:
| Propriedade | Descrição | Obrigatório |
|---|---|---|
| type | A propriedade type precisa ser definida como: AzureDatabricksDeltaLake. | Sim |
| domínio | Especifique a URL do workspace do Azure Databricks, por exemplo, https://adb-xxxxxxxxx.xx.azuredatabricks.net. |
Sim |
| clusterId | Especifique a ID de um cluster existente. Esse deve ser um cluster interativo já criado. Você pode encontrar a ID do cluster de um cluster interativo no workspace do Databricks -> Clusters -> Nome do Cluster Interativo -> Configuração -> Marcas. Saiba mais. |
Sim |
| workspaceResourceId | Especifique a ID de recurso do workspace do Azure Databricks. | Sim |
| connectVia | O runtime de integração que é usado para se conectar ao armazenamento de dados. Você poderá usar o runtime de integração do Azure ou um runtime de integração auto-hospedada (se o seu armazenamento de dados estiver localizado em uma rede privada). Se não for especificado, ele usará o runtime de integração padrão do Azure. | Não |
Exemplo:
{
"name": "AzureDatabricksDeltaLakeLinkedService",
"properties": {
"type": "AzureDatabricksDeltaLake",
"typeProperties": {
"domain": "https://adb-xxxxxxxxx.xx.azuredatabricks.net",
"clusterId": "<cluster id>",
"workspaceResourceId": "<workspace resource id>"
},
"connectVia": {
"referenceName": "<name of Integration Runtime>",
"type": "IntegrationRuntimeReference"
}
}
}
Autenticação de identidade gerenciada atribuída pelo usuário
Para saber mais sobre identidades gerenciadas atribuídas pelo usuário para recursos do Azure, confira Identidades gerenciadas atribuídas pelo usuário
Para usar a autenticação de identidade gerenciada atribuída pelo usuário, siga estas etapas:
Crie uma ou várias identidades gerenciadas atribuídas pelo usuário e conceda permissão no Azure Databricks. Em geral, você deve conceder pelo menos a função Colaborador à sua identidade gerenciada atribuída pelo usuário no Controle de acesso (IAM) do Azure Databricks.
Atribua uma ou várias identidades gerenciadas atribuídas pelo usuário ao data factory ou Synapse Workspace e crie credenciais para cada identidade gerenciada atribuída pelo usuário.
As propriedades a seguir são compatíveis com o serviço vinculado do Delta Lake do Azure Databricks:
| Propriedade | Descrição | Obrigatório |
|---|---|---|
| type | A propriedade type precisa ser definida como: AzureDatabricksDeltaLake. | Sim |
| domínio | Especifique a URL do workspace do Azure Databricks, por exemplo, https://adb-xxxxxxxxx.xx.azuredatabricks.net. |
Sim |
| clusterId | Especifique a ID de um cluster existente. Esse deve ser um cluster interativo já criado. Você pode encontrar a ID do cluster de um cluster interativo no workspace do Databricks -> Clusters -> Nome do Cluster Interativo -> Configuração -> Marcas. Saiba mais. |
Sim |
| credenciais | Especifique a identidade gerenciada atribuída pelo usuário como o objeto da credencial. | Sim |
| workspaceResourceId | Especifique a ID de recurso do workspace do Azure Databricks. | Sim |
| connectVia | O runtime de integração que é usado para se conectar ao armazenamento de dados. Você poderá usar o runtime de integração do Azure ou um runtime de integração auto-hospedada (se o seu armazenamento de dados estiver localizado em uma rede privada). Se não for especificado, ele usará o runtime de integração padrão do Azure. | Não |
Exemplo:
{
"name": "AzureDatabricksDeltaLakeLinkedService",
"properties": {
"type": "AzureDatabricksDeltaLake",
"typeProperties": {
"domain": "https://adb-xxxxxxxxx.xx.azuredatabricks.net",
"clusterId": "<cluster id>",
"credential": {
"referenceName": "credential1",
"type": "CredentialReference"
},
"workspaceResourceId": "<workspace resource id>"
},
"connectVia": {
"referenceName": "<name of Integration Runtime>",
"type": "IntegrationRuntimeReference"
}
}
}
Propriedades do conjunto de dados
Para obter uma lista completa das seções e propriedades disponíveis para definir os conjuntos de dados, confira o artigo sobre Conjuntos de Dados.
As propriedades a seguir são compatíveis com o conjunto de dados do Delta Lake do Azure Databricks.
| Propriedade | Descrição | Obrigatório |
|---|---|---|
| type | A propriedade type do conjunto de dados precisa ser definida como AzureDatabricksDeltaLakeDataset. | Sim |
| Banco de Dados | Nome do banco de dados. | Não para origem, Sim para coletor |
| table | Nome da tabela delta. | Não para origem, Sim para coletor |
Exemplo:
{
"name": "AzureDatabricksDeltaLakeDataset",
"properties": {
"type": "AzureDatabricksDeltaLakeDataset",
"typeProperties": {
"database": "<database name>",
"table": "<delta table name>"
},
"schema": [ < physical schema, optional, retrievable during authoring > ],
"linkedServiceName": {
"referenceName": "<name of linked service>",
"type": "LinkedServiceReference"
}
}
}
Propriedades da atividade de cópia
Para obter uma lista completa das seções e propriedades disponíveis para definir atividades, confia o artigo Pipelines. Esta seção fornece uma lista das propriedades compatíveis com a origem e o coletor do Azure Databricks Data Lake.
Delta lake como origem
Para copiar dados do Azure Databricks Data Lake, as propriedades a seguir são compatíveis com a seção origem da atividade Copy.
| Propriedade | Descrição | Obrigatório |
|---|---|---|
| type | A propriedade type da origem da atividade Copy deve ser definida como: AzureDatabricksDeltaLakeSource. | Sim |
| Consulta | Especifique a consulta SQL para ler dados. Para o controle de viagem no tempo, siga o padrão abaixo: - SELECT * FROM events TIMESTAMP AS OF timestamp_expression- SELECT * FROM events VERSION AS OF version |
Não |
| exportSettings | Configurações avançadas usadas para recuperar dados da tabela delta. | Não |
Em exportSettings: |
||
| type | O tipo de comando de exportação, definido como AzureDatabricksDeltaLakeExportCommand. | Sim |
| dateFormat | Formate o tipo de data como cadeia de caracteres com um formato de data. Formatos de data personalizados seguem os formatos no padrão datetime. Se esse campo não for especificado, o valor padrão será yyyy-MM-dd. |
Não |
| timestampFormat | Formate o tipo timestamp como cadeia de caracteres com um formato de carimbo de data/hora. Formatos de data personalizados seguem os formatos no padrão datetime. Se esse campo não for especificado, o valor padrão será yyyy-MM-dd'T'HH:mm:ss[.SSS][XXX]. |
Não |
Cópia direta do Delta Lake
Se o armazenamento e o formato de dados do coletor atenderem aos critérios descritos nesta seção, você poderá usar a atividade Copy para copiar diretamente da tabela delta do Azure Databricks para o coletor. O serviço verificará as configurações e falhará na execução de atividade Copy se os seguintes critérios não forem atendidos:
O serviço vinculado do coletor é o Armazenamento de Blobs do Azure ou Azure Data Lake Storage Gen2. A credencial da conta deve ser pré-configurada na configuração do cluster Azure Databricks. Saiba mais em Pré-requisitos.
O formato de dados do coletor tem as configurações a seguir, é Parquet, texto delimitado ou Avro e aponta para uma pasta em vez de um arquivo.
- Para o formato Parquet, o codec de compactação é none, snappy ou gzip.
- Para formato de texto delimitado:
rowDelimiteré qualquer caractere único.compressionpode ser nenhum, bzip2 e gzip.encodingNameUTF-7 não é compatível.
- Para o formato Avro, o codec de compactação é none, deflate ou snappy.
Na origem da atividade Copy,
additionalColumnsnão está especificado.Ao copiar dados para um texto delimitado, no coletor da atividade Copy,
fileExtensionprecisa ser ".csv".No mapeamento da atividade Copy, a conversão de tipo não está habilitada.
Exemplo:
"activities":[
{
"name": "CopyFromDeltaLake",
"type": "Copy",
"inputs": [
{
"referenceName": "<Delta lake input dataset name>",
"type": "DatasetReference"
}
],
"outputs": [
{
"referenceName": "<output dataset name>",
"type": "DatasetReference"
}
],
"typeProperties": {
"source": {
"type": "AzureDatabricksDeltaLakeSource",
"sqlReaderQuery": "SELECT * FROM events TIMESTAMP AS OF timestamp_expression"
},
"sink": {
"type": "<sink type>"
}
}
}
]
Cópia preparada do delta lake
Quando o formato ou armazenamento de dados do coletor não corresponde aos critérios de cópia direta, conforme mencionado na última seção, habilite a cópia preparada interna usando uma instância provisória do Armazenamento do Azure. O recurso de cópia preparada também oferece melhor rendimento. O serviço exporta dados do Delta Lake do Azure Databricks para o armazenamento de preparo, depois copia os dados para o coletor e, por fim, limpa os dados temporários do armazenamento de preparo. Confira Cópia preparada para obter detalhes sobre a cópia de dados por meio do preparo.
Para usar esse recurso, crie um serviço vinculado do Armazenamento de Blobs do Azure ou serviço vinculado do Azure Data Lake Storage Gen2 que se refere à conta de armazenamento como o preparo provisório. Em seguida, especifique as propriedades enableStaging e stagingSettings na atividade Copy.
Observação
A credencial da conta de armazenamento de preparo deve ser pré-configurada na configuração do cluster do Azure Databricks. Saiba mais em Pré-requisitos.
Exemplo:
"activities":[
{
"name": "CopyFromDeltaLake",
"type": "Copy",
"inputs": [
{
"referenceName": "<Delta lake input dataset name>",
"type": "DatasetReference"
}
],
"outputs": [
{
"referenceName": "<output dataset name>",
"type": "DatasetReference"
}
],
"typeProperties": {
"source": {
"type": "AzureDatabricksDeltaLakeSource",
"sqlReaderQuery": "SELECT * FROM events TIMESTAMP AS OF timestamp_expression"
},
"sink": {
"type": "<sink type>"
},
"enableStaging": true,
"stagingSettings": {
"linkedServiceName": {
"referenceName": "MyStagingStorage",
"type": "LinkedServiceReference"
},
"path": "mystagingpath"
}
}
}
]
Delta lake como coletor
Para copiar dados para o Azure Databricks Data Lake, as propriedades a seguir são compatíveis com a seção coletor da atividade Copy.
| Propriedade | Descrição | Obrigatório |
|---|---|---|
| type | A propriedade type do coletor da atividade Copy, definida para AzureDatabricksDeltaLakeSink. | Sim |
| preCopyScript | Especifique uma consulta SQL para a atividade Copy, a ser executada antes de gravar dados na tabela delta do Databricks em cada execução. Exemplo: VACUUM eventsTable DRY RUN use essa propriedade para limpar os dados pré-carregados ou adicionar uma instrução de tabela truncada ou Vacuum. |
Não |
| importSettings | Configurações avançadas usadas para gravar dados na tabela delta. | Não |
Em importSettings: |
||
| type | O tipo de comando de exportação, definido como AzureDatabricksDeltaLakeImportCommand. | Sim |
| dateFormat | Formatar cadeia de caracteres para tipo date com um formato de data. Formatos de data personalizados seguem os formatos no padrão datetime. Se esse campo não for especificado, o valor padrão será yyyy-MM-dd. |
Não |
| timestampFormat | Formatar cadeia de caracteres para tipo timestamp com um formato de carimbo de data/hora. Formatos de data personalizados seguem os formatos no padrão datetime. Se esse campo não for especificado, o valor padrão será yyyy-MM-dd'T'HH:mm:ss[.SSS][XXX]. |
Não |
Cópia direta para o delta lake
Se o armazenamento e o formato de dados de origem atenderem aos critérios descritos nesta seção, você poderá usar a atividade Copy para copiar diretamente da origem para o Delta Lake do Azure Databricks. O serviço verificará as configurações e falhará na execução de atividade Copy se os seguintes critérios não forem atendidos:
O serviço vinculado de origem é o Armazenamento de Blobs do Azure ou Azure Data Lake Storage Gen2. A credencial da conta deve ser pré-configurada na configuração do cluster Azure Databricks. Saiba mais em Pré-requisitos.
O formato de dados de origem tem as configurações a seguir, é Parquet, texto delimitado ou Avro e aponta para uma pasta em vez de um arquivo.
- Para o formato Parquet, o codec de compactação é none, snappy ou gzip.
- Para formato de texto delimitado:
rowDelimiteré padrão ou qualquer caractere único.compressionpode ser nenhum, bzip2 e gzip.encodingNameUTF-7 não é compatível.
- Para o formato Avro, o codec de compactação é none, deflate ou snappy.
Na origem da atividade Copy:
wildcardFileNamecontém somente o curinga*, mas não?;wildcardFolderNamenão é especificado.prefix,modifiedDateTimeStart,modifiedDateTimeEndeenablePartitionDiscoverynão foram especificados.additionalColumnsnão está especificado.
No mapeamento da atividade Copy, a conversão de tipo não está habilitada.
Exemplo:
"activities":[
{
"name": "CopyToDeltaLake",
"type": "Copy",
"inputs": [
{
"referenceName": "<input dataset name>",
"type": "DatasetReference"
}
],
"outputs": [
{
"referenceName": "<Delta lake output dataset name>",
"type": "DatasetReference"
}
],
"typeProperties": {
"source": {
"type": "<source type>"
},
"sink": {
"type": "AzureDatabricksDeltaLakeSink",
"sqlReaderQuery": "VACUUM eventsTable DRY RUN"
}
}
}
]
Cópia preparada para o delta lake
Quando o formato ou armazenamento de dados de origem não corresponde aos critérios de cópia direta, conforme mencionado na última seção, habilite a cópia preparada interna usando uma instância provisória do Armazenamento do Azure. O recurso de cópia preparada também oferece melhor rendimento. O serviço converte automaticamente os dados para atender aos requisitos de formato de dados no armazenamento de preparo e carrega os dados de lá para o Delta Lake. Por fim, ele limpa os dados temporários do armazenamento. Confira Cópia preparada para obter detalhes sobre a cópia de dados por meio do preparo.
Para usar esse recurso, crie um serviço vinculado do Armazenamento de Blobs do Azure ou serviço vinculado do Azure Data Lake Storage Gen2 que se refere à conta de armazenamento como o preparo provisório. Em seguida, especifique as propriedades enableStaging e stagingSettings na atividade Copy.
Observação
A credencial da conta de armazenamento de preparo deve ser pré-configurada na configuração do cluster do Azure Databricks. Saiba mais em Pré-requisitos.
Exemplo:
"activities":[
{
"name": "CopyToDeltaLake",
"type": "Copy",
"inputs": [
{
"referenceName": "<input dataset name>",
"type": "DatasetReference"
}
],
"outputs": [
{
"referenceName": "<Delta lake output dataset name>",
"type": "DatasetReference"
}
],
"typeProperties": {
"source": {
"type": "<source type>"
},
"sink": {
"type": "AzureDatabricksDeltaLakeSink"
},
"enableStaging": true,
"stagingSettings": {
"linkedServiceName": {
"referenceName": "MyStagingBlob",
"type": "LinkedServiceReference"
},
"path": "mystagingpath"
}
}
}
]
Monitoramento
A mesma experiência de monitoramento da atividade Copy que aquela oferecida por outros conectores. Além disso, já que o carregamento de dados de/para o delta lake está em execução no cluster do Azure Databricks, você pode ver mais logs detalhados do cluster e monitorar o desempenho.
Pesquisar propriedades de atividade
Para obter mais informações sobre as propriedades, confira Atividade de pesquisa.
A atividade de pesquisa pode retornar até 1.000 linhas; se o conjunto de resultados contiver mais registros, as primeiras 1.000 linhas serão retornadas.
Conteúdo relacionado
Para obter uma lista de armazenamentos de dados com suporte como fontes e coletores por atividade Copy, consulte armazenamentos e formatos de dados compatíveis.