Copie e transforme dados no Banco de Dados do Azure para PostgreSQL usando o Azure Data Factory ou o Synapse Analytics
APLICA-SE A: Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Dica
Experimente o Data Factory no Microsoft Fabric, uma solução de análise tudo-em-um para empresas. O Microsoft Fabric abrange desde movimentação de dados até ciência de dados, análise em tempo real, business intelligence e relatórios. Saiba como iniciar uma avaliação gratuita!
Este artigo descreve como usar a atividade Copy nos pipelines do Azure Data Factory e do Synapse Analytics para copiar dados de e para o Banco de Dados do Azure para PostgreSQL e como usar o Fluxo de Dados para transformar dados no Banco de Dados do Azure para PostgreSQL. Para saber mais, leia o artigo introdutório do Azure Data Factory e do Synapse Analytics.
Esse conector é especializado para o serviço Banco de Dados do Azure para PostgreSQL. Para copiar dados de um banco de dados PostgreSQL genérico localizado localmente ou na nuvem, use o conector PostgreSQL.
Funcionalidades com suporte
Este conector do Banco de Dados do Azure para PostgreSQL é compatível com as seguintes funcionalidades:
| Funcionalidades com suporte | IR | Ponto de extremidade privado gerenciado |
|---|---|---|
| Atividade de cópia (origem/coletor) | ① ② | ✓ |
| Fluxo de dados de mapeamento (origem/coletor) | ① | ✓ |
| Atividade de pesquisa | ① ② | ✓ |
① Runtime de integração do Azure ② Runtime de integração auto-hospedada
As três atividades funcionam em todas as opções de implantação do Banco de Dados do Azure para PostgreSQL:
Introdução
Para executar a atividade de Cópia com um pipeline, será possível usar as ferramentas ou os SDKs abaixo:
- A ferramenta Copiar Dados
- O portal do Azure
- O SDK do .NET
- O SDK do Python
- PowerShell do Azure
- A API REST
- O modelo do Azure Resource Manager
Criar um serviço vinculado para o Banco de Dados do Azure para PostgreSQL usando a interface do usuário
Use as etapas a seguir para criar um serviço vinculado para o Banco de Dados do Azure para PostgreSQL na interface do usuário do portal do Azure.
Navegue até a guia Gerenciar no workspace do Azure Data Factory ou do Synapse, selecione Serviços Vinculados e clique em Novo:
Procure PostgreSQL e selecione o conector do Banco de Dados do Azure para PostgreSQL.
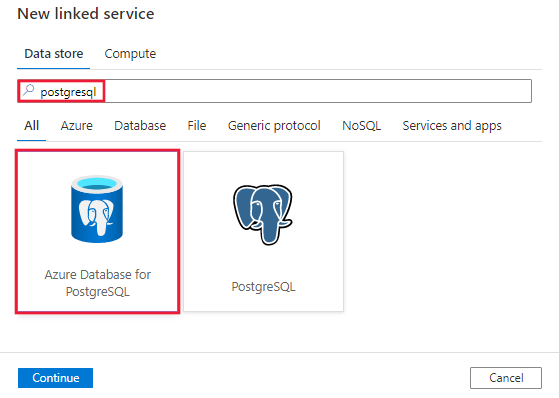
Configure os detalhes do serviço, teste a conexão e crie o novo serviço vinculado.
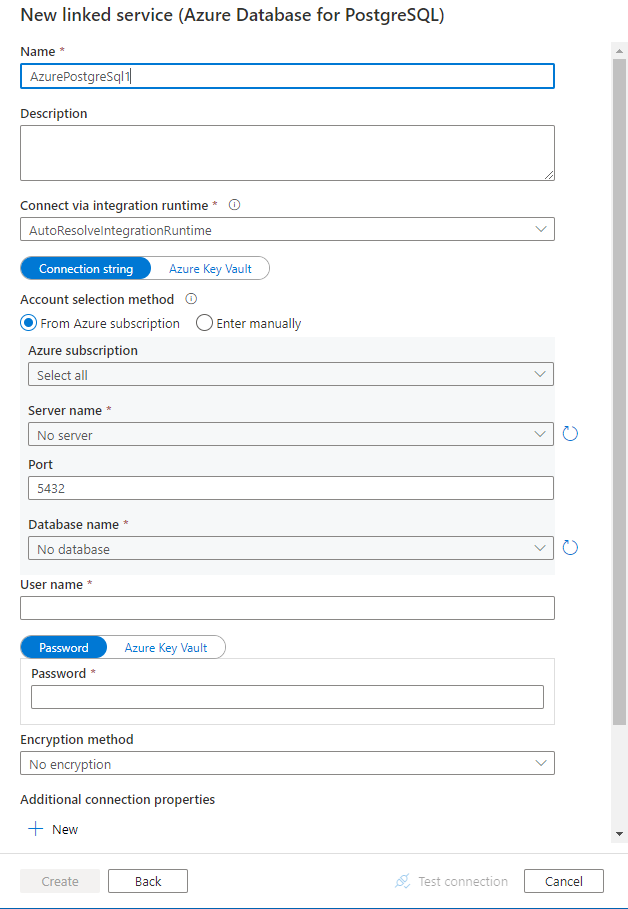
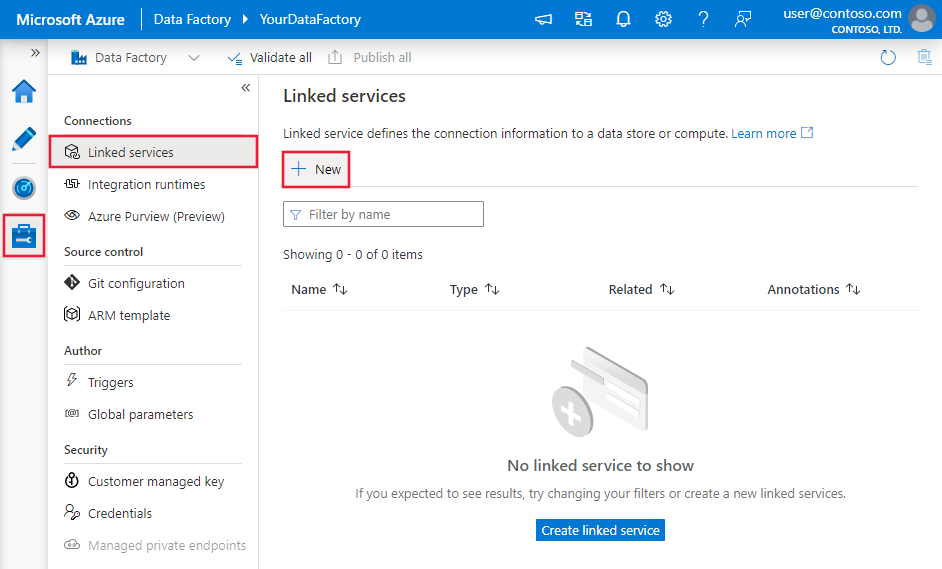
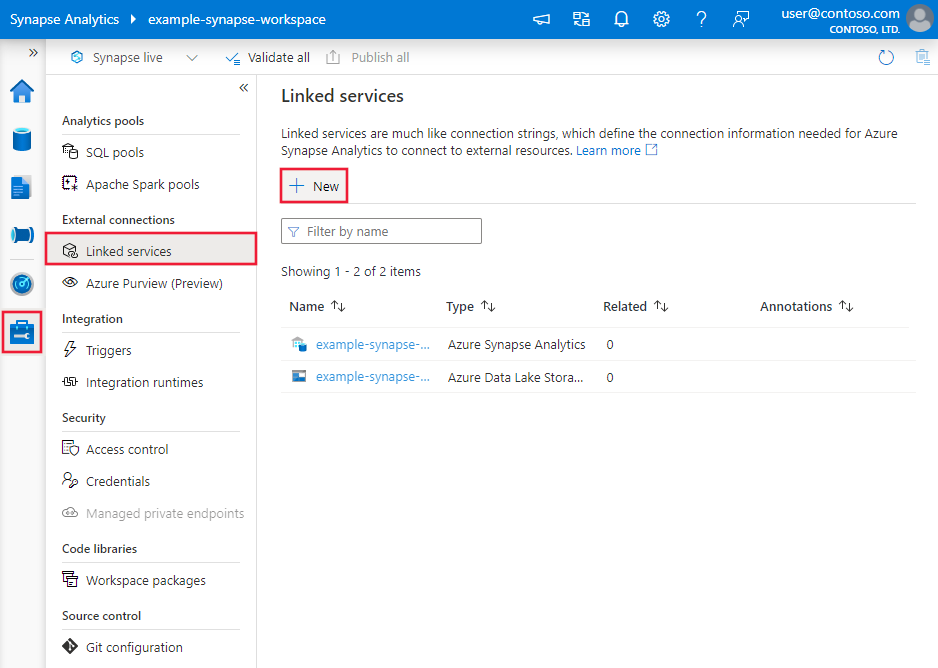
Detalhes da configuração do conector
As seções a seguir oferecem detalhes sobre as propriedades que são usadas para definir entidades do Data Factory específicas ao conector do Banco de Dados do Azure para PostgreSQL.
Propriedades do serviço vinculado
As seguintes propriedades têm suporte no serviço vinculado do Banco de Dados do Azure para PostgreSQL:
| Propriedade | Descrição | Obrigatório |
|---|---|---|
| type | A propriedade type deve ser definida como: AzurePostgreSql. | Sim |
| connectionString | Uma cadeia de conexão ODBC para se conectar ao Banco de Dados do Azure para PostgreSQL. Também é possível colocar uma senha no Azure Key Vault e extrair a configuração password da cadeia de conexão. Confira os exemplos a seguir e Armazenar credenciais no Azure Key Vault para obter mais detalhes. |
Sim |
| connectVia | Esta propriedade representa o runtime de integração que será usado para se conectar ao armazenamento de dados. Você pode usar o Integration Runtime do Azure ou o Integration Runtime auto-hospedado (se o armazenamento de dados estiver localizado em uma rede privada). Se não for especificado, ele usa o Integration Runtime padrão do Azure. | Não |
Uma cadeia de conexão válida é Server=<server>.postgres.database.azure.com;Database=<database>;Port=<port>;UID=<username>;Password=<Password>. Estas são outras propriedades que podem ser definidas para seu caso:
| Propriedade | Descrição | Opções | Obrigatório |
|---|---|---|---|
| EncryptionMethod (EM) | O método que o driver usa para criptografar dados enviados entre o driver e o servidor de banco de dados. Por exemplo, EncryptionMethod=<0/1/6>; |
0 (Sem criptografia) (Padrão) / 1 (SSL) / 6 (RequestSSL) | Não |
| ValidateServerCertificate (VSC) | Determina se o driver validará o certificado que é enviado pelo servidor de banco de dados quando a criptografia SSL está habilitada (Método de Criptografia = 1). Por exemplo, ValidateServerCertificate=<0/1>; |
0 (Desabilitado) (Padrão) / 1 (Habilitado) | Não |
Exemplo:
{
"name": "AzurePostgreSqlLinkedService",
"properties": {
"type": "AzurePostgreSql",
"typeProperties": {
"connectionString": "Server=<server>.postgres.database.azure.com;Database=<database>;Port=<port>;UID=<username>;Password=<Password>"
}
}
}
Exemplo:
Armazenar senha no Azure Key Vault
{
"name": "AzurePostgreSqlLinkedService",
"properties": {
"type": "AzurePostgreSql",
"typeProperties": {
"connectionString": "Server=<server>.postgres.database.azure.com;Database=<database>;Port=<port>;UID=<username>;",
"password": {
"type": "AzureKeyVaultSecret",
"store": {
"referenceName": "<Azure Key Vault linked service name>",
"type": "LinkedServiceReference"
},
"secretName": "<secretName>"
}
}
}
}
Propriedades do conjunto de dados
Para obter uma lista completa das seções e propriedades disponíveis para definir os conjuntos de dados, confira Conjuntos de dados. Esta seção fornece uma lista das propriedades com suporte pelo Banco de Dados do Azure para PostgreSQL no conjunto de dados.
Para copiar dados de/para o Banco de Dados do Azure para PostgreSQL, defina o tipo da propriedade do conjunto de dados como AzurePostgreSqlTable. Há suporte para as seguintes propriedades:
| Propriedade | Descrição | Obrigatório |
|---|---|---|
| type | A propriedade type do conjunto de dados deve ser definida como AzurePostgreSqlTable | Sim |
| tableName | Nome da tabela | Não (se "query" na fonte da atividade for especificada) |
Exemplo:
{
"name": "AzurePostgreSqlDataset",
"properties": {
"type": "AzurePostgreSqlTable",
"linkedServiceName": {
"referenceName": "<AzurePostgreSql linked service name>",
"type": "LinkedServiceReference"
},
"typeProperties": {}
}
}
Propriedades da atividade de cópia
Para obter uma lista completa das seções e propriedades disponíveis para definir as atividades, confira Pipelines e atividades. Esta seção fornece uma lista das propriedades com suporte por uma fonte do Banco de Dados do Azure para PostgreSQL.
O Banco de Dados do Azure para PostgreSQL como fonte
Para copiar dados do Banco de Dados do Azure para PostgreSQL, defina o tipo de fonte na atividade de cópia como AzurePostgreSqlSource. As propriedades a seguir têm suporte na seção source da atividade de cópia:
| Propriedade | Descrição | Obrigatório |
|---|---|---|
| type | A propriedade type da fonte da atividade de cópia deve ser definida como AzurePostgreSqlSource | Sim |
| Consulta | Utiliza a consulta SQL personalizada para ler os dados. Por exemplo: SELECT * FROM mytable ou SELECT * FROM "MyTable". Observe que no PostgreSQL o nome da entidade não diferencia maiúsculas de minúsculas se não estiver entre aspas. |
Não (se a propriedade tableName de um conjunto de dados for especificada) |
| queryTimeout | O tempo de espera antes de encerrar a tentativa de executar um comando ou gerar um erro. O padrão é 120 minutos. Se um parâmetro for definido para essa propriedade, os valores permitidos são o intervalo de tempo, como "02:00:00" (120 minutos). Para obter mais informações, confira CommandTimeout. | Não |
| partitionOptions | Especifica as opções de particionamento de dados usadas para carregar dados do Banco de Dados SQL do Azure. Os valores permitidos são: None (padrão), PhysicalPartitionsOfTable e DynamicRange. Quando uma opção de partição está habilitada (ou seja, não None), o grau de paralelismo para carregar dados simultaneamente do Banco de Dados SQL do Azure é controlado pela configuração parallelCopies na atividade Copy. |
Não |
| partitionSettings | Especifique o grupo de configurações para o particionamento de dados. Aplicar quando a opção de partição não for None. |
No |
Em partitionSettings: |
||
| partitionNames | A lista de partições físicas que precisam ser copiadas. Aplicar quando a opção de partição for PhysicalPartitionsOfTable. Se você usar uma consulta para recuperar os dados de origem, conecte ?AdfTabularPartitionName na cláusula WHERE. Para ver um exemplo, confira a seção Cópia paralela do Banco de Dados do Azure para PostgreSQL. |
Não |
| partitionColumnName | Especifique o nome da coluna de origem no tipo inteiro ou data/datetime (int, smallint, bigint, date, timestamp without time zone, timestamp with time zone ou time without time zone) que será usado pelo particionamento de intervalo para cópia paralela. Se não especificado, a chave primária da tabela será detectada automaticamente e usada como a coluna de partição.Aplicar quando a opção de partição for DynamicRange. Se você usar uma consulta para recuperar os dados de origem, conecte ?AdfRangePartitionColumnName na cláusula WHERE. Para ver um exemplo, confira a seção Cópia paralela do Banco de Dados do Azure para PostgreSQL. |
Não |
| partitionUpperBound | O valor máximo da coluna de partição para copiar dados. Aplicar quando a opção de partição for DynamicRange. Se você usar uma consulta para recuperar os dados de origem, conecte ?AdfRangePartitionUpbound na cláusula WHERE. Para ver um exemplo, confira a seção Cópia paralela do Banco de Dados do Azure para PostgreSQL. |
Não |
| partitionLowerBound | O valor mínimo da coluna de partição para copiar dados. Aplicar quando a opção de partição for DynamicRange. Se você usar uma consulta para recuperar os dados de origem, conecte ?AdfRangePartitionLowbound na cláusula WHERE. Para ver um exemplo, confira a seção Cópia paralela do Banco de Dados do Azure para PostgreSQL. |
Não |
Exemplo:
"activities":[
{
"name": "CopyFromAzurePostgreSql",
"type": "Copy",
"inputs": [
{
"referenceName": "<AzurePostgreSql input dataset name>",
"type": "DatasetReference"
}
],
"outputs": [
{
"referenceName": "<output dataset name>",
"type": "DatasetReference"
}
],
"typeProperties": {
"source": {
"type": "AzurePostgreSqlSource",
"query": "<custom query e.g. SELECT * FROM mytable>",
"queryTimeout": "00:10:00"
},
"sink": {
"type": "<sink type>"
}
}
}
]
Banco de Dados do Azure para PostgreSQL como coletor
Para copiar dados para o Banco de Dados do Azure para PostgreSQL, são permitidas as seguintes propriedades na seção coletor da atividade Copy:
| Propriedade | Descrição | Obrigatório |
|---|---|---|
| type | A propriedade type do coletor da atividade Copy deve ser definida como AzurePostgreSQLSink. | Sim |
| preCopyScript | Especifica uma consulta SQL para a atividade de cópia, a ser executada antes de gravar dados no Banco de Dados do Azure para PostgreSQL em cada execução. Você pode usar essa propriedade para limpar os dados previamente carregados. | Não |
| writeMethod | O método usado para gravar dados no Banco de Dados do Azure para PostgreSQL. Os valores permitidos são: CopyCommand (padrão, que tem maior desempenho), BulkInsert. |
Não |
| writeBatchSize | O número de linhas carregadas no Banco de Dados do Azure para PostgreSQL por lote. O valor permitido é um número inteiro que representa o número de linhas. |
Não (o padrão é 1.000.000) |
| writeBatchTimeout | Tempo de espera para a operação de inserção em lotes ser concluída antes de atingir o tempo limite. Os valores permitidos são cadeias de caracteres Timespan. Um exemplo é 00:30:00 (30 minutos). |
Não (o padrão é 00:30:00) |
Exemplo:
"activities":[
{
"name": "CopyToAzureDatabaseForPostgreSQL",
"type": "Copy",
"inputs": [
{
"referenceName": "<input dataset name>",
"type": "DatasetReference"
}
],
"outputs": [
{
"referenceName": "<Azure PostgreSQL output dataset name>",
"type": "DatasetReference"
}
],
"typeProperties": {
"source": {
"type": "<source type>"
},
"sink": {
"type": "AzurePostgreSQLSink",
"preCopyScript": "<custom SQL script>",
"writeMethod": "CopyCommand",
"writeBatchSize": 1000000
}
}
}
]
Cópia paralela do Banco de Dados do Azure para PostgreSQL
O conector do Banco de Dados PostgreSQL do Azure na atividade Copy fornece particionamento de dados interno para copiar dados em paralelo. Você pode encontrar opções de particionamento de dados na guia Origem da atividade de cópia.
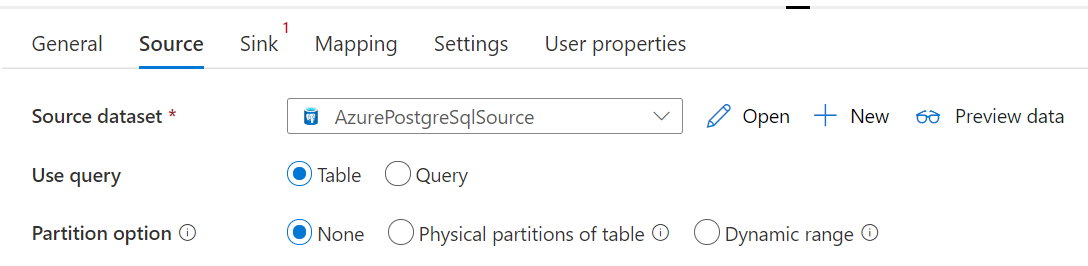
Quando você habilita a cópia particionada, a atividade Copy executa consultas paralelas com relação à origem do Banco de Dados PostgreSQL do Azure para carregar dados por partições. O grau paralelo é controlado pela configuração do parallelCopies na atividade de cópia. Por exemplo, ao definir parallelCopies como quatro, o serviço gera e executa simultaneamente quatro consultas com base na opção de partição e nas configurações especificadas. Cada consulta recupera uma parte dos dados do Banco de Dados PostgreSQL do Azure.
É recomendável habilitar a cópia paralela com o particionamento de dados, especialmente quando você carrega grandes quantidades de dados do Banco de Dados PostgreSQL do Azure. Veja a seguir as configurações sugeridas para cenários diferentes. Ao copiar dados para o armazenamento de dados baseado em arquivo, recomendamos gravá-los em uma pasta como vários arquivos (apenas especifique o nome da pasta) para ter um desempenho melhor do que gravar em um arquivo.
| Cenário | Configurações sugeridas |
|---|---|
| Carregamento completo de uma tabela grande com partições físicas. | Opção de partição: partições físicas da tabela. Durante a execução, o serviço detecta automaticamente as partições físicas e copia os dados por partição. |
| Carregamento completo de uma tabela grande, sem partições físicas e com uma coluna de inteiro ou para o particionamento de dados. | Opções de partição: partição de intervalo dinâmico. Coluna de partição: especifique a coluna usada para particionar dados. Se não for especificada, a coluna de chave primária será usada. |
| Carregue uma grande quantidade de dados usando uma consulta personalizada, com partições físicas. | Opção de partição: partições físicas da tabela. Consulta: SELECT * FROM ?AdfTabularPartitionName WHERE <your_additional_where_clause>.Nome da partição: especifique os nomes de partição dos quais copiar dados. Se não for especificado, o serviço detectará automaticamente as partições físicas na tabela que você especificou no conjunto de dados do PostgreSQL. Durante a execução, o serviço substitui ?AdfTabularPartitionName pelo nome real da partição e envia ao Banco de Dados do Azure para PostgreSQL. |
| Carregue uma grande quantidade de dados usando uma consulta personalizada, sem partições físicas, com uma coluna de inteiro para o particionamento de dados. | Opções de partição: partição de intervalo dinâmico. Consulta: SELECT * FROM ?AdfTabularPartitionName WHERE ?AdfRangePartitionColumnName <= ?AdfRangePartitionUpbound AND ?AdfRangePartitionColumnName >= ?AdfRangePartitionLowbound AND <your_additional_where_clause>.Coluna de partição: especifique a coluna usada para particionar dados. Você pode particionar em relação à coluna com tipo de dados inteiro ou data/datetime. Limite superior da partição e Limite inferior da partição: especifique se quiser filtrar a coluna de partição para recuperar dados somente entre os intervalos inferior e superior. Durante a execução, o serviço substitui ?AdfRangePartitionColumnName, ?AdfRangePartitionUpbound e ?AdfRangePartitionLowbound pelo nome da coluna e pelos intervalos de valores reais para cada partição, e os envia para o Banco de Dados do Azure para PostgreSQL. Por exemplo, se a coluna de partição "ID" for definida com o limite inferior de 1 e o limite superior de 80, com a cópia paralela definida como 4, o serviço recuperará dados por 4 partições. Suas IDs estão entre [1, 20], [21, 40], [41, 60] e [61, 80], respectivamente. |
Melhores práticas para carregar dados com a opção de partição:
- Escolha a coluna distinta como coluna de partição (como chave primária ou chave exclusiva) para evitar a distorção de dados.
- Se a tabela tiver uma partição interna, use a opção de partição "Partições físicas da tabela" para ter um melhor desempenho.
- Se você usa o Azure Integration Runtime para copiar dados, pode definir "DIUs (unidades de integração de dados)" maiores (>4) para utilizar mais recursos de computação. Verifique os cenários aplicáveis.
- O "grau de paralelismo de cópia" controla os números de partições. Às vezes, definir um número muito grande afeta o desempenho; é recomendável definir esse número como (DIU ou número de nós de IR auto-hospedados) * (2 a 4).
Exemplo: carregamento completo de uma tabela grande com partições físicas
"source": {
"type": "AzurePostgreSqlSource",
"partitionOption": "PhysicalPartitionsOfTable"
}
Exemplo: consulta com a partição do intervalo dinâmico
"source": {
"type": "AzurePostgreSqlSource",
"query": "SELECT * FROM <TableName> WHERE ?AdfDynamicRangePartitionCondition AND <your_additional_where_clause>",
"partitionOption": "DynamicRange",
"partitionSettings": {
"partitionColumnName": "<partition_column_name>",
"partitionUpperBound": "<upper_value_of_partition_column (optional) to decide the partition stride, not as data filter>",
"partitionLowerBound": "<lower_value_of_partition_column (optional) to decide the partition stride, not as data filter>"
}
}
Propriedades do fluxo de dados de mapeamento
Ao transformar dados no fluxo de dados de mapeamento, você pode ler e gravar em tabelas do Banco de Dados do Azure para PostgreSQL. Para obter mais informações, confira transformação de origem e transformação do coletor nos fluxos de dados de mapeamento. Você pode optar por usar um conjunto de dados do Banco de Dados do Azure para PostgreSQL ou um conjunto de dados em linha como fonte e tipo de coletor.
Transformação de origem
A tabela abaixo lista as propriedades compatíveis com a fonte do Banco de Dados do Azure para PostgreSQL. Você pode editar essas propriedades na guia Opções de origem.
| Nome | Descrição | Obrigatório | Valores permitidos | Propriedade do script do Fluxo de Dados |
|---|---|---|---|---|
| Tabela | Se você selecionar Tabela como entrada, o fluxo de dados buscará todos os dados da tabela especificada no conjunto de dados. | Não | - | (somente para o conjuntos de dados em linha) tableName |
| Consulta | Se você selecionar consulta como entrada, especifique uma consulta SQL para buscar dados da origem, o que substitui qualquer tabela que você especificar no conjunto de dados. O uso de consultas também é uma ótima maneira de reduzir linhas para testes ou pesquisas. Não há suporte para a cláusula Ordenar por aqui, mas você pode definir uma instrução SELECT FROM completa. Também pode usar funções de tabela definidas pelo usuário. select * from udfGetData() é um UDF no SQL que retorna uma tabela que você pode usar no fluxo de dados. Exemplo de consulta: select * from mytable where customerId > 1000 and customerId < 2000 ou select * from "MyTable". Observe que no PostgreSQL o nome da entidade não diferencia maiúsculas de minúsculas se não estiver entre aspas. |
Não | String | Consulta |
| Nome do esquema | Se você selecionar Procedimento armazenado como a entrada, especifique um nome de esquema do procedimento armazenado ou selecione Atualizar para solicitar que o serviço descubra os nomes de esquema. | Não | String | schemaName |
| Procedimento armazenado | Se você selecionar o procedimento armazenado como entrada, especifique um nome do procedimento armazenado para ler dados na tabela de origem ou selecione Atualizar para solicitar ao serviço que descubra os nomes dos procedimentos. | Sim (se você selecionar o procedimento armazenado como entrada) | String | procedureName |
| Parâmetros de procedimento | Se você selecionar o procedimento armazenado como entrada, especifique os parâmetros de entrada para o procedimento armazenado na ordem definida no procedimento ou selecione Importar para importar todos os parâmetros de procedimento usando o formulário @paraName. |
Não | Array | entradas |
| Tamanho do lote | Especifique um tamanho de lote para dividir em partes os dados grandes em lotes. | Não | Integer | batchSize |
| Nível de Isolamento | Escolha um dos seguintes níveis de isolamento: - Leitura confirmada - Leitura não confirmada (padrão) - Leitura repetida - Serializável - Nenhum (ignorar o nível de isolamento) |
No | READ_COMMITTED READ_UNCOMMITTED REPEATABLE_READ SERIALIZABLE NONE |
isolationLevel |
Exemplo de script de fonte do Banco de Dados do Azure para PostgreSQL
Quando você usa o Banco de Dados do Azure para PostgreSQL como tipo de origem, o script de fluxo de dados associado é:
source(allowSchemaDrift: true,
validateSchema: false,
isolationLevel: 'READ_UNCOMMITTED',
query: 'select * from mytable',
format: 'query') ~> AzurePostgreSQLSource
Transformação de coletor
A tabela abaixo lista as propriedades compatíveis com o coletor do Banco de Dados do Azure para PostgreSQL. Você pode editar essas propriedades na guia Opções do coletor.
| Nome | Descrição | Obrigatório | Valores permitidos | Propriedade do script do Fluxo de Dados |
|---|---|---|---|---|
| Método Update | Especifique quais operações são permitidas no destino do banco de dados. O padrão é permitir apenas inserções. Para atualizar, fazer upsert ou excluir linhas, uma transformação Alter row é necessária para marcar as linhas para essas ações. |
Sim | true ou false |
deletable insertable Pode ser atualizado upsertable |
| Colunas de chaves | Para atualizações, upserts e exclusões, coluna(s) de chave devem ser definidas para determinar qual linha alterar. O nome da coluna que você escolhe como chave será usado como parte da atualização, upsert, exclusão seguinte. Portanto, você deve escolher uma coluna que exista no mapeamento de coletor. |
Não | Array | chaves |
| Ignorar colunas de chave de gravação | Se você não quiser gravar o valor na coluna de chave, selecione "Ignorar gravação de colunas de chave". | No | true ou false |
skipKeyWrites |
| Ação tabela | determina se deve-se recriar ou remover todas as linhas da tabela de destino antes da gravação. - None: nenhuma ação será feita na tabela. - Recreate: a tabela será descartada e recriada. Necessário ao criar uma tabela dinamicamente. - Truncate: todas as linhas da tabela de destino serão removidas. |
Não | true ou false |
recreate truncate |
| Tamanho do lote | Especifique quantas linhas estão sendo gravadas em cada lote. Tamanhos de lote maiores aprimoram a compactação e a otimização de memória, mas geram risco de exceções de memória insuficiente ao armazenar dados em cache. | No | Integer | batchSize |
| Selecionar o esquema de banco de dados do usuário | Por padrão, uma tabela temporária será criada no esquema do coletor como processo de preparo. Como alternativa, você pode desmarcar a opção Usar esquema de coletor e, em vez disso, especificar um nome de esquema em que o Data Factory criará uma tabela de preparo para carregar dados upstream e limpá-los automaticamente após a conclusão. Crie a permissão de tabela no banco de dados e altere a permissão no esquema. | Não | String | stagingSchemaName |
| Pré-scripts e Pós-scripts SQL | Especifique scripts SQL multilinhas que serão executados antes (pré-processamento) e após (pós-processamento) os dados serem gravados no banco de dados do coletor. | Não | String | preSQLs postSQLs |
Dica
- É recomendável quebrar scripts de lote únicos com vários comandos em vários lotes.
- Apenas as instruções DDL (linguagem de definição de dados) e DML (linguagem de manipulação de dados) que retornam uma contagem de atualização simples podem ser executadas como parte de um lote. Saiba mais sobre Executando operações em lote
Habilitar extração incremental: use essa opção para dizer ao ADF para processar apenas as linhas que foram alteradas desde a última vez em que o pipeline foi executado.
Coluna de data incremental: ao usar o recurso de extração incremental, escolha a coluna data/hora ou numérica que você deseja usar como marca d'água na tabela de origem.
Comece a ler desde o início: definir essa opção com a extração incremental dirá ao ADF para ler todas as linhas na primeira execução de um pipeline com a extração incremental ativada.
Exemplo de script de coletor do Banco de Dados do Azure para PostgreSQL
Quando você usa o Banco de Dados do Azure para PostgreSQL como tipo de coletor, o script de fluxo de dados associado é:
IncomingStream sink(allowSchemaDrift: true,
validateSchema: false,
deletable:false,
insertable:true,
updateable:true,
upsertable:true,
keys:['keyColumn'],
format: 'table',
skipDuplicateMapInputs: true,
skipDuplicateMapOutputs: true) ~> AzurePostgreSQLSink
Pesquisar propriedades de atividade
Para obter mais informações sobre as propriedades, confira Atividade de pesquisa.
Conteúdo relacionado
Para obter uma lista dos armazenamentos de dados com suporte como coletores e fontes da atividade de cópia, confira os Armazenamentos de dados com suporte.