Copiar dados do Amazon RDS para SQL Server usando o Azure Data Factory ou o Azure Synapse Analytics
Este artigo descreve como usar a atividade Copy nos pipelines do Azure Data Factory e do Azure Synapse para copiar dados do banco de dados do Amazon RDS para o SQL Server. Para saber mais, leia o artigo introdutório do Azure Data Factory ou do Azure Synapse Analytics.
Funcionalidades com suporte
Este conector do Amazon RDS for SQL Server é compatível com os seguintes recursos:
| Funcionalidades com suporte | IR |
|---|---|
| Atividade de cópia (origem/-) | ① ② |
| Atividade de pesquisa | ① ② |
| Atividade GetMetadata | ① ② |
| Stored procedure activity (Atividade de procedimento armazenado) | ① ② |
① Runtime de integração do Azure ② Runtime de integração auto-hospedada
Para obter uma lista de armazenamentos de dados que têm suporte como fontes ou coletores da atividade de cópia, confira a tabela Armazenamentos de dados com suporte.
Especificamente, esse conector do Amazon RDS para SQL Server dá suporte a:
- SQL Server versão 2005 e superior.
- Copiar dados usando a autenticação do SQL ou do Windows.
- Como uma origem, recuperar dados usando uma consulta SQL ou um procedimento armazenado. Você também pode optar por copiar paralelamente do Amazon RDS para o SQL Server, consulte a seção cópia paralela do banco de dados SQL para obter detalhes.
Não há suporte para SQL Server Express LocalDB.
Pré-requisitos
Se o armazenamento de dados estiver localizado dentro de uma rede local, em uma rede virtual do Azure ou na Amazon Virtual Private Cloud, você precisará configurar um runtime de integração auto-hospedada para se conectar a ele.
Se o armazenamento de dados for um serviço de dados de nuvem gerenciado, você poderá usar o Azure Integration Runtime. Se o acesso for restrito aos IPs que estão aprovados nas regras de firewall, você poderá adicionar IPs do Azure Integration Runtime à lista de permissões.
Você também pode usar o recurso de runtime de integração da rede virtual gerenciada no Azure Data Factory para acessar a rede local sem instalar e configurar um runtime de integração auto-hospedada.
Para obter mais informações sobre os mecanismos de segurança de rede e as opções compatíveis com o Data Factory, consulte Estratégias de acesso a dados.
Introdução
Para executar a atividade de Cópia com um pipeline, será possível usar as ferramentas ou os SDKs abaixo:
- A ferramenta Copiar Dados
- O portal do Azure
- O SDK do .NET
- O SDK do Python
- PowerShell do Azure
- A API REST
- O modelo do Azure Resource Manager
Criar um Amazon RDS para SQL Server vinculado usando a interface do usuário
Use as etapas a seguir para criar um serviço vinculado do Amazon RDS para o SQL Server na interface do usuário do portal do Azure.
Navegue até a guia Gerenciar no workspace do Azure Data Factory ou do Synapse, selecione Serviços Vinculados e clique em Novo:
Pesquise amazon RDS para SQL servidor e selecione o Amazon RDS para SQL Server conector.
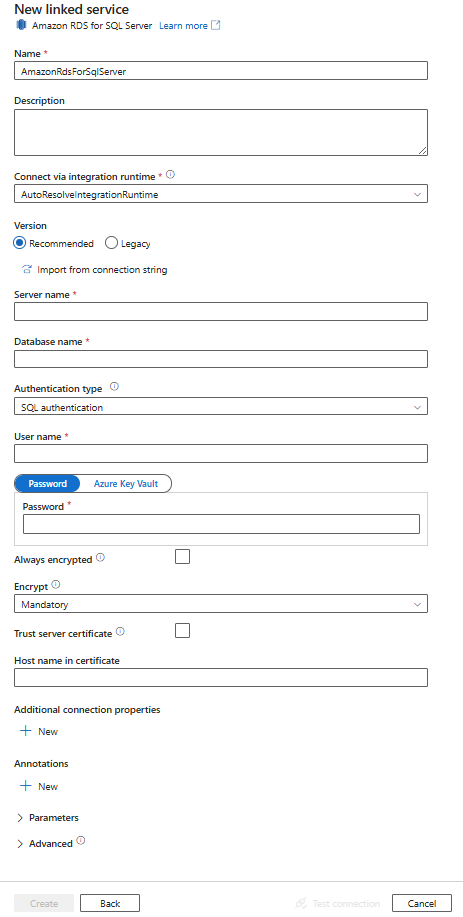
Configure os detalhes do serviço, teste a conexão e crie o novo serviço vinculado.
Detalhes da configuração do conector
As seções que se seguem fornecem detalhes sobre as propriedades usadas para definir entidades dos pipelines do Data Factory e do Synapse específicas ao conector do banco de dados do Amazon RDS para o SQL Server.
Propriedades do serviço vinculado
A versão Recomendada do conector Amazon RDS para SQL Server dá suporte para TLS 1.3. Consulte esta seção para atualizar a versão do seu conector do Amazon RDS para SQL Server da versão Herdada. Para obter detalhes sobre as propriedades, consulte as seções correspondentes.
Observação
Não há suporte para o Always Encrypted do Amazon RDS para SQL Server no fluxo de dados.
Dica
Se você encontrar erro com o código de erro "UserErrorFailedToConnectToSqlServer" e uma mensagem como "O limite da sessão para o banco de dados é XXX e foi atingido," adicione Pooling=false à cadeia de conexão e tente novamente.
Versão recomendada
Essas propriedades genéricas têm suporte para um serviço vinculado ao Amazon RDS para SQL Server quando você aplica a versão Recomendada:
| Propriedade | Descrição | Obrigatório |
|---|---|---|
| type | A propriedade type precisa ser definida como: AmazonRdsForSqlServer. | Yes |
| Servidor | O nome ou o endereço de rede da instância de servidor SQL à qual você deseja se conectar. | Yes |
| Banco de Dados | O nome do banco de dados. | Yes |
| authenticationType | O tipo usado para autenticação. Os valores permitidos são SQL (padrão), Windows. Entre na seção de autenticação relevante sobre propriedades e pré-requisitos específicos. | Yes |
| alwaysEncryptedSettings | Especifique as informações alwaysencryptedsettings necessárias para habilitar o Always Encrypted e proteger dados confidenciais armazenados no Amazon RDS para SQL Server usando a identidade gerenciada ou a entidade de serviço. Para obter mais informações, confira o exemplo JSON após a tabela e a seção Usar o Always Encrypted. Se não for especificada, a configuração padrão sempre criptografada estará desabilitada. | Não |
| criptografar | Indique se a criptografia TLS é necessária em todos os dados enviados entre o cliente e o servidor. Opções: obrigatória (para true, padrão)/opcional (para false)/strict. | Não |
| trustServerCertificate | Indica se o canal será criptografado ao passar pela cadeia de certificados para validar a confiança. | Não |
| hostNameInCertificate | O nome do host a ser usado ao validar o certificado do servidor para a conexão. Quando não é especificado, o nome do servidor é usado para validação de certificado. | Não |
| connectVia | Esse Integration Runtime é usado para se conectar ao armazenamento de dados. Saiba mais na seção Pré-requisitos. Se não especificado, o Azure Integration Runtime padrão será usado. | Não |
Consulte a tabela abaixo para obter as propriedades de conexão adicionais:
| Propriedade | Descrição | Obrigatório |
|---|---|---|
| applicationIntent | O tipo de carga de trabalho de aplicativo ao conectar-se a um servidor. Os valores permitidos são ReadOnly e ReadWrite. |
Não |
| connectTimeout | O período time (em segundos) a aguardar para uma conexão ao servidor antes de terminar a tentativa e gerar um erro. | Não |
| connectRetryCount | O número de tentativas de reconexões após identificar uma falha por conexão ociosa. O valor deve ser um número inteiro entre 0 e 255. | Não |
| connectRetryInterval | O tempo (em segundos) entre cada tentativa de reconexão após identificar uma falha por conexão ociosa. O valor deve ser um número inteiro entre 1 e 60. | Não |
| loadBalanceTimeout | O tempo mínimo (em segundos) para que a conexão resida no pool de conexões antes da conexão ser destruída. | Não |
| commandTimeout | Define o tempo de espera (em segundos) antes de encerrar a tentativa de executar um comando e antes de gerar um erro. | Não |
| integratedSecurity | Os valores permitidos são true e false. Ao especificar false, indique se userName e password estão especificados na conexão. Ao especificar true, indica se as credenciais atuais da conta do Windows são usadas para autenticação. |
Não |
| failoverPartner | O nome ou endereço do servidor parceiro ao qual se conectar se o servidor primário estiver inativo. | Não |
| maxPoolSize | O número máximo de conexões permitidas no pool de conexões para a conexão específica. | Não |
| minPoolSize | O número mínimo de conexões permitidas no pool de conexões para a conexão específica. | Não |
| multipleActiveResultSets | Os valores permitidos são true e false. Ao especificar true, um aplicativo pode manter vários conjuntos de resultados ativos múltiplos (MARS). Ao você especificar false, um aplicativo deve processar ou cancelar todos os conjuntos de resultados de um lote antes de poder executar outros lotes nessa conexão. |
Não |
| multiSubnetFailover | Os valores permitidos são true e false. Se o aplicativo estiver se conectando a um AG (grupo de disponibilidade) AlwaysOn em diferentes sub-redes, definir true como true fornece uma detecção e uma conexão mais rápida ao servidor atualmente ativo. |
Não |
| packetSize | Tamanho em bytes dos pacotes de rede usados para comunicar-se com uma instância de servidor. | Não |
| pooling | Os valores permitidos são true e false. Ao especificar true, a conexão será colocada em pool. Ao especificar false, a conexão será aberta explicitamente toda vez que a conexão for solicitada. |
Não |
Autenticação do SQL
Para usar a autenticação SQL, além das propriedades genéricas descritas na seção anterior, especifique as seguintes propriedades:
| Propriedade | Descrição | Obrigatório |
|---|---|---|
| userName | O nome de usuário usado para se conectar ao servidor. | Yes |
| password | A senha do nome de usuário. Marque esse campo como SecureString para armazená-lo com segurança. Você também pode referenciar um segredo armazenado no Azure Key Vault. | Yes |
Exemplo: usar autenticação SQL
{
"name": "AmazonSqlLinkedService",
"properties": {
"type": "AmazonRdsForSqlServer",
"typeProperties": {
"server": "<name or network address of the SQL server instance>",
"database": "<database name>",
"encrypt": "<encrypt>",
"trustServerCertificate": false,
"authenticationType": "SQL",
"userName": "<user name>",
"password": {
"type": "SecureString",
"value": "<password>"
}
},
"connectVia": {
"referenceName": "<name of Integration Runtime>",
"type": "IntegrationRuntimeReference"
}
}
}
Exemplo: usar autenticação SQL com uma senha no Azure Key Vault
{
"name": "AmazonSqlLinkedService",
"properties": {
"type": "AmazonRdsForSqlServer",
"typeProperties": {
"server": "<name or network address of the SQL server instance>",
"database": "<database name>",
"encrypt": "<encrypt>",
"trustServerCertificate": false,
"authenticationType": "SQL",
"userName": "<user name>",
"password": {
"type": "AzureKeyVaultSecret",
"store": {
"referenceName": "<Azure Key Vault linked service name>",
"type": "LinkedServiceReference"
},
"secretName": "<secretName>"
}
},
"connectVia": {
"referenceName": "<name of Integration Runtime>",
"type": "IntegrationRuntimeReference"
}
}
}
Exemplo: Usar o Always Encrypted
{
"name": "AmazonSqlLinkedService",
"properties": {
"type": "AmazonRdsForSqlServer",
"typeProperties": {
"server": "<name or network address of the SQL server instance>",
"database": "<database name>",
"encrypt": "<encrypt>",
"trustServerCertificate": false,
"authenticationType": "SQL",
"userName": "<user name>",
"password": {
"type": "SecureString",
"value": "<password>"
},
"alwaysEncryptedSettings": {
"alwaysEncryptedAkvAuthType": "ServicePrincipal",
"servicePrincipalId": "<service principal id>",
"servicePrincipalKey": {
"type": "SecureString",
"value": "<service principal key>"
}
}
},
"connectVia": {
"referenceName": "<name of Integration Runtime>",
"type": "IntegrationRuntimeReference"
}
}
}
Autenticação do Windows
Para usar a autenticação do Windows, além das propriedades genéricas descritas na seção anterior, especifique as seguintes propriedades:
| Propriedade | Descrição | Obrigatório |
|---|---|---|
| userName | Especifique um nome de usuário. Um exemplo é domainname\username. | Sim |
| password | Especifique uma senha para a conta de usuário que você especificou para o nome de usuário. Marque esse campo como SecureString para armazená-lo com segurança. Você também pode referenciar um segredo armazenado no Azure Key Vault. | Yes |
Exemplo: usar autenticação do Windows
{
"name": "AmazonSqlLinkedService",
"properties": {
"type": "AmazonRdsForSqlServer",
"typeProperties": {
"server": "<name or network address of the SQL server instance>",
"database": "<database name>",
"encrypt": "<encrypt>",
"trustServerCertificate": false,
"authenticationType": "Windows",
"userName": "<domain\\username>",
"password": {
"type": "SecureString",
"value": "<password>"
}
},
"connectVia": {
"referenceName": "<name of Integration Runtime>",
"type": "IntegrationRuntimeReference"
}
}
}
Versão herdada
Essas propriedades genéricas têm suporte para um serviço vinculado ao Amazon RDS para SQL Server quando você aplica a versão Herdada:
| Propriedade | Descrição | Obrigatório |
|---|---|---|
| type | A propriedade type precisa ser definida como: AmazonRdsForSqlServer. | Yes |
| alwaysEncryptedSettings | Especifique as informações alwaysencryptedsettings necessárias para habilitar o Always Encrypted e proteger dados confidenciais armazenados no Amazon RDS para SQL Server usando a identidade gerenciada ou a entidade de serviço. Para saber mais, confira a seção Usar Always Encrypted. Se não for especificada, a configuração padrão sempre criptografada estará desabilitada. | Não |
| connectVia | Esse Integration Runtime é usado para se conectar ao armazenamento de dados. Saiba mais na seção Pré-requisitos. Se não especificado, o Azure Integration Runtime padrão será usado. | Não |
Esse conector Amazon RDS para SQL Server dá suporte aos seguintes tipos de autenticação. Consulte as seções correspondentes para obter detalhes.
Autenticação do SQL para a versão herdada
Para usar a autenticação do SQL, além das propriedades genéricas descritas na seção anterior, especifique as seguintes propriedades:
| Propriedade | Descrição | Obrigatório |
|---|---|---|
| connectionString | Especifique as informações connectionString necessárias para se conectar ao banco de dados do Amazon RDS para SQL Server. Especifique um nome de logon como seu nome de usuário e verifique se o banco de dados que deseja conectar está mapeado para esse logon. | Yes |
| password | Se quiser colocar uma senha no Azure Key Vault, efetue pull da configuração password da cadeia de conexão. Para obter mais informações, confira Armazenar credenciais no Azure Key Vault. |
Não |
Autenticação do Windows para a versão herdada
Para usar a autenticação do Windows, além das propriedades genéricas descritas na seção anterior, especifique as seguintes propriedades:
| Propriedade | Descrição | Obrigatório |
|---|---|---|
| connectionString | Especifique as informações connectionString necessárias para se conectar ao banco de dados do Amazon RDS para SQL Server. | Yes |
| userName | Especifique um nome de usuário. Um exemplo é domainname\username. | Sim |
| password | Especifique uma senha para a conta de usuário que você especificou para o nome de usuário. Marque esse campo como SecureString para armazená-lo com segurança. Você também pode referenciar um segredo armazenado no Azure Key Vault. | Yes |
Propriedades do conjunto de dados
Para obter uma lista completa das seções e propriedades disponíveis para definir os conjuntos de dados, confira o artigo sobre conjuntos de dados. Esta seção fornece uma lista das propriedades com suporte do conjunto de dados do Amazon RDS para SQL Server.
Para copiar dados do AMazon RDS para SQL Server, há suporte para as seguintes propriedades:
| Propriedade | Descrição | Obrigatório |
|---|---|---|
| type | A propriedade type do conjunto de dados deve ser definida como: AmazonRdsForSqlServerTable. | Sim |
| esquema | Nome do esquema. | Não |
| tabela | Nome da tabela/exibição. | No |
| tableName | Nome da tabela/exibição com esquema. Essa propriedade é compatível com versões anteriores. Para uma nova carga de trabalho, use schema e table. |
Não |
Exemplo
{
"name": "AmazonRdsForSQLServerDataset",
"properties":
{
"type": "AmazonRdsForSqlServerTable",
"linkedServiceName": {
"referenceName": "<Amazon RDS for SQL Server linked service name>",
"type": "LinkedServiceReference"
},
"schema": [ < physical schema, optional, retrievable during authoring > ],
"typeProperties": {
"schema": "<schema_name>",
"table": "<table_name>"
}
}
}
Propriedades da atividade de cópia
Para obter uma lista completa das seções e propriedades disponíveis para uso para definir atividades, confia o artigo Pipelines. Esta seção fornece uma lista das propriedades com suporte da fonte do Amazon RDS para SQL Server.
Amazon RDS para SQL Server como fonte
Dica
Para carregar dados do Amazon RDS para SQL Server com eficiência usando o particionamento de dados, saiba mais na seção cópia paralela do banco de dados SQL.
Para copiar dados do Amazon RDS para SQL Server, defina o tipo de origem na atividade de cópia como AmazonRdsForSqlServerSource. As propriedades a seguir têm suporte na seção de origem da atividade de cópia:
| Propriedade | Descrição | Obrigatório |
|---|---|---|
| type | A propriedade type da fonte da atividade de cópia deve ser definida como: AmazonRdsForSqlServerSource. | Sim |
| sqlReaderQuery | Utiliza a consulta SQL personalizada para ler os dados. Um exemplo é select * from MyTable. |
Não |
| sqlReaderStoredProcedureName | Essa propriedade é o nome do procedimento armazenado que lê dados da tabela de origem. A última instrução SQL deve ser uma instrução SELECT no procedimento armazenado. | Não |
| storedProcedureParameters | Esses parâmetros são para o procedimento armazenado. Valores permitidos são pares de nome ou valor. Os nomes e o uso de maiúsculas e minúsculas de parâmetros devem corresponder aos nomes e o uso de maiúsculas e minúsculas dos parâmetros do procedimento armazenado. |
Não |
| isolationLevel | Especifica o comportamento de bloqueio de transação para a origem do SQL. Os valores permitidos são: ReadCommitted, ReadUncommitted, RepeatableRead, Serializable, Snapshot. Se não for especificado, o nível de isolamento padrão do banco de dados será usado. Veja este documento para obter mais detalhes. | Não |
| partitionOptions | Especifica as opções de particionamento de dados usadas para carregar dados do Amazon RDS para SQL Server. Os valores permitidos são: None (padrão), PhysicalPartitionsOfTable e DynamicRange. Quando uma opção de partição é habilitada (ou seja, não None), o grau de paralelismo para carregar dados simultaneamente do Amazon RDS para SQL Server é controlado pela configuração parallelCopies na atividade de cópia. |
Não |
| partitionSettings | Especifique o grupo de configurações para o particionamento de dados. Aplicar quando a opção de partição não for None. |
No |
Em partitionSettings: |
||
| partitionColumnName | Especifique o nome da coluna de origem no tipo inteiro ou data/datetime (int, smallint, bigint, date, smalldatetime, datetime, datetime2 ou datetimeoffset) que será usado pelo particionamento de intervalo para cópia paralela. Se não for especificado, o índice ou a chave primária da tabela será auto-detectado e usado como coluna de partição.Aplicar quando a opção de partição for DynamicRange. Se você usar uma consulta para recuperar os dados de origem, conecte ?DfDynamicRangePartitionCondition na cláusula WHERE. Para ver um exemplo, confira a seção Cópia paralela do banco de dados SQL. |
Não |
| partitionUpperBound | O valor máximo da coluna de partição para divisão do intervalo de partição. Esse valor é usado para decidir o stride da partição, e não para filtrar as linhas na tabela. Todas as linhas da tabela ou do resultado da consulta serão particionadas e copiadas. Se não for especificado, a atividade de cópia detectará o valor automaticamente. Aplicar quando a opção de partição for DynamicRange. Para ver um exemplo, confira a seção Cópia paralela do banco de dados SQL. |
Não |
| partitionLowerBound | O valor mínimo da coluna de partição para divisão do intervalo de partição. Esse valor é usado para decidir o stride da partição, e não para filtrar as linhas na tabela. Todas as linhas da tabela ou do resultado da consulta serão particionadas e copiadas. Se não for especificado, a atividade de cópia detectará o valor automaticamente. Aplicar quando a opção de partição for DynamicRange. Para ver um exemplo, confira a seção Cópia paralela do banco de dados SQL. |
No |
Observe os seguintes pontos:
- Se sqlReaderQuery for especificado para AmazonRdsForSqlServerSource, a atividade de cópia executará essa consulta na origem do Amazon RDS para SQL Server para obter os dados. Você também pode especificar um procedimento armazenado especificando o sqlReaderStoredProcedureName e o storedProcedureParameters se o procedimento armazenado usa parâmetros.
- ao usar um procedimento armazenado na origem para recuperar dados, observe que, se o procedimento armazenado for projetado para retornar um esquema diferente quando um valor de parâmetro diferente for passado, você poderá ter uma falha ou um resultado inesperado ao importar o esquema da interface do usuário ou ao copiar dados para o banco de dados SQL com a criação automática de tabela.
Exemplo: usar a consulta SQL
"activities":[
{
"name": "CopyFromAmazonRdsForSQLServer",
"type": "Copy",
"inputs": [
{
"referenceName": "<Amazon RDS for SQL Server input dataset name>",
"type": "DatasetReference"
}
],
"outputs": [
{
"referenceName": "<output dataset name>",
"type": "DatasetReference"
}
],
"typeProperties": {
"source": {
"type": "AmazonRdsForSqlServerSource",
"sqlReaderQuery": "SELECT * FROM MyTable"
},
"sink": {
"type": "<sink type>"
}
}
}
]
Exemplo: usar um procedimento armazenado
"activities":[
{
"name": "CopyFromAmazonRdsForSQLServer",
"type": "Copy",
"inputs": [
{
"referenceName": "<Amazon RDS for SQL Server input dataset name>",
"type": "DatasetReference"
}
],
"outputs": [
{
"referenceName": "<output dataset name>",
"type": "DatasetReference"
}
],
"typeProperties": {
"source": {
"type": "AmazonRdsForSqlServerSource",
"sqlReaderStoredProcedureName": "CopyTestSrcStoredProcedureWithParameters",
"storedProcedureParameters": {
"stringData": { "value": "str3" },
"identifier": { "value": "$$Text.Format('{0:yyyy}', <datetime parameter>)", "type": "Int"}
}
},
"sink": {
"type": "<sink type>"
}
}
}
]
A definição do procedimento armazenado
CREATE PROCEDURE CopyTestSrcStoredProcedureWithParameters
(
@stringData varchar(20),
@identifier int
)
AS
SET NOCOUNT ON;
BEGIN
select *
from dbo.UnitTestSrcTable
where dbo.UnitTestSrcTable.stringData != stringData
and dbo.UnitTestSrcTable.identifier != identifier
END
GO
Cópia paralela do banco de dados SQL
O conector do Amazon RDS para SQL Server na atividade de cópia fornece particionamento de dados interno para copiar dados em paralelo. Você pode encontrar opções de particionamento de dados na guia Origem da atividade de cópia.
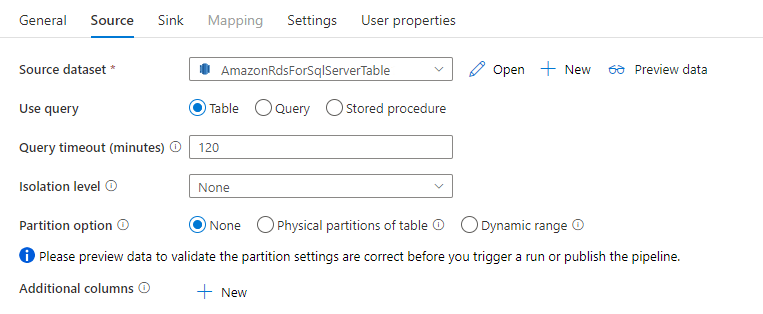
Quando você habilita a cópia particionada, a atividade de cópia executa consultas paralelas com relação à sua fonte do Amazon RDS para SQL Server para carregar dados por partições. O grau paralelo é controlado pela configuração do parallelCopies na atividade de cópia. Por exemplo, ao definir parallelCopies como quatro, o serviço gera e executa simultaneamente quatro consultas com base na opção de partição especificada e nas configurações, e cada consulta recupera uma parte dos dados do Amazon RDS para SQL Server.
É recomendável habilitar a cópia paralela com o particionamento de dados, especialmente quando você carrega grandes quantidades de dados do banco de dados do Amazon RDS para SQL Server. Veja a seguir as configurações sugeridas para cenários diferentes. Ao copiar dados para o armazenamento de dados baseado em arquivo, recomendamos gravá-los em uma pasta como vários arquivos (apenas especifique o nome da pasta) para ter um desempenho melhor do que gravar em um arquivo.
| Cenário | Configurações sugeridas |
|---|---|
| Carregamento completo de uma tabela grande com partições físicas. | Opção de partição: partições físicas da tabela. Durante a execução, o serviço detecta automaticamente as partições físicas e copia os dados por partição. Para verificar se a tabela tem partição física, confira esta consulta. |
| Carregamento completo de uma tabela grande, sem partições físicas e com uma coluna de inteiro ou de datetime para o particionamento de dados. | Opções de partição: partição de intervalo dinâmico. Coluna de partição (opcional): especifique a coluna usada para particionar dados. Se não for especificada, a coluna de chave primária será usada. Limite superior da partição e limite inferior da partição (opcional): especifique se deseja determinar o stride da partição. A finalidade não é filtrar as linhas na tabela, todas as linhas da tabela serão particionadas e copiadas. Se não for especificado, a atividade de cópia detectará automaticamente os valores e poderá levar muito tempo, dependendo dos valores MÍN e MÁX. É recomendável fornecer o limite superior e o limite inferior. Por exemplo, se a “ID” da coluna de partição tiver valores no intervalo de 1 a 100 e você definir o limite inferior como 20 e o limite superior como 80, com a cópia paralela definida como 4, o serviço recuperará dados por 4 IDs de partição no intervalo <=20, [21, 50], [51, 80], e >=81, respectivamente. |
| Carregar uma grande quantidade de dados usando uma consulta personalizada, sem partições físicas, com uma coluna de inteiro ou data/datetime para o particionamento de dados. | Opções de partição: partição de intervalo dinâmico. Consulta: SELECT * FROM <TableName> WHERE ?DfDynamicRangePartitionCondition AND <your_additional_where_clause>.Coluna de partição: especifique a coluna usada para particionar dados. Limite superior da partição e limite inferior da partição (opcional): especifique se deseja determinar o stride da partição. A finalidade não é filtrar as linhas na tabela, todas as linhas na consulta serão particionadas e copiadas. Se não for especificado, a atividade de cópia detectará o valor automaticamente. Por exemplo, se a “ID” da coluna de partição tiver valores no intervalo de 1 a 100 e você definir o limite inferior como 20 e o limite superior como 80, com a cópia paralela definida como 4, o serviço recuperará dados por 4 IDs de partição no intervalo <=20, [21, 50], [51, 80], e >=81, respectivamente. Veja mais exemplos de consultas para diferentes cenários: 1. Consultar a tabela inteira: SELECT * FROM <TableName> WHERE ?DfDynamicRangePartitionCondition2. Consultar em uma tabela com seleção de coluna e filtros de cláusula "where" adicionais: SELECT <column_list> FROM <TableName> WHERE ?DfDynamicRangePartitionCondition AND <your_additional_where_clause>3. Consultar com sub-consultas: SELECT <column_list> FROM (<your_sub_query>) AS T WHERE ?DfDynamicRangePartitionCondition AND <your_additional_where_clause>4. Consultar com partição na sub-consulta: SELECT <column_list> FROM (SELECT <your_sub_query_column_list> FROM <TableName> WHERE ?DfDynamicRangePartitionCondition) AS T |
Melhores práticas para carregar dados com a opção de partição:
- Escolha a coluna distinta como coluna de partição (como chave primária ou chave exclusiva) para evitar a distorção de dados.
- Se a tabela tiver uma partição interna, use a opção de partição "Partições físicas da tabela" para ter um melhor desempenho.
- Se você usa o Azure Integration Runtime para copiar dados, pode definir "DIUs (unidades de integração de dados)" maiores (>4) para utilizar mais recursos de computação. Verifique os cenários aplicáveis.
- O "grau de paralelismo de cópia" controla os números de partições. Às vezes, definir um número muito grande afeta o desempenho; é recomendável definir esse número como (DIU ou número de nós de IR auto-hospedados) * (2 a 4).
Exemplo: carregamento completo de uma tabela grande com partições físicas
"source": {
"type": "AmazonRdsForSqlServerSource",
"partitionOption": "PhysicalPartitionsOfTable"
}
Exemplo: consulta com a partição do intervalo dinâmico
"source": {
"type": "AmazonRdsForSqlServerSource",
"query": "SELECT * FROM <TableName> WHERE ?DfDynamicRangePartitionCondition AND <your_additional_where_clause>",
"partitionOption": "DynamicRange",
"partitionSettings": {
"partitionColumnName": "<partition_column_name>",
"partitionUpperBound": "<upper_value_of_partition_column (optional) to decide the partition stride, not as data filter>",
"partitionLowerBound": "<lower_value_of_partition_column (optional) to decide the partition stride, not as data filter>"
}
}
Exemplo de consulta para verificar a partição física
SELECT DISTINCT s.name AS SchemaName, t.name AS TableName, pf.name AS PartitionFunctionName, c.name AS ColumnName, iif(pf.name is null, 'no', 'yes') AS HasPartition
FROM sys.tables AS t
LEFT JOIN sys.objects AS o ON t.object_id = o.object_id
LEFT JOIN sys.schemas AS s ON o.schema_id = s.schema_id
LEFT JOIN sys.indexes AS i ON t.object_id = i.object_id
LEFT JOIN sys.index_columns AS ic ON ic.partition_ordinal > 0 AND ic.index_id = i.index_id AND ic.object_id = t.object_id
LEFT JOIN sys.columns AS c ON c.object_id = ic.object_id AND c.column_id = ic.column_id
LEFT JOIN sys.partition_schemes ps ON i.data_space_id = ps.data_space_id
LEFT JOIN sys.partition_functions pf ON pf.function_id = ps.function_id
WHERE s.name='[your schema]' AND t.name = '[your table name]'
Se a tabela tiver uma partição física, você verá "HasPartition" como "yes" conforme segue.

Pesquisar propriedades de atividade
Para saber detalhes sobre as propriedades, verifique Atividade de pesquisa.
Propriedades de atividade GetMetadata
Para saber detalhes sobre as propriedades, verifique Atividade GetMetadata
Como usar o Always Encrypted
Ao copiar dados do Amazon RDS para SQL Server com o Always Encrypted, siga as etapas abaixo:
Armazene a chave mestra de coluna (CMK) em um Azure Key Vault. Saiba mais sobre como configurar o Always Encrypted usando o Azure Key Vault
Certifique-se de conceder acesso ao cofre de chaves onde a CMK (chave mestra de coluna) está armazenada. Veja este artigo para obter as permissões necessárias.
Crie um serviço vinculado para se conectar ao banco de dados SQL e habilite a função “Always Encrypted” usando a identidade gerenciada ou a entidade de serviço.
Solucionar problemas de conexão
Configure o Amazon RDS para SQL Server para aceitar conexões remotas. Inicie o Amazon RDS para SQL Server Management Studio, clique com o botão direito do mouse em servidor e selecione propriedades. Selecione Conexões na lista e marque a caixa de seleção Permitir conexões remotas com este servidor.
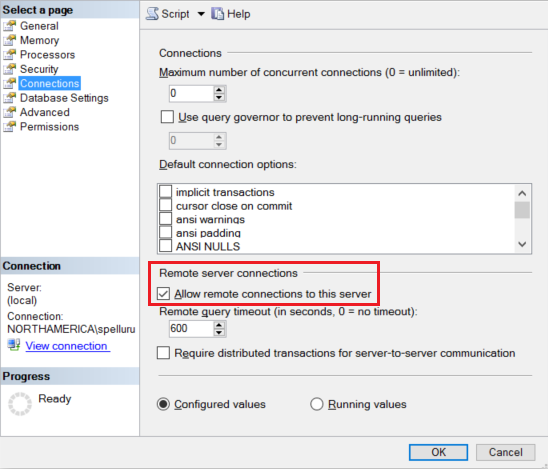
Para obter etapas detalhadas, consulteConfigurar a opção de configuração do servidor de acesso remoto para obter as etapas detalhadas.
Inicie o Amazon RDS para SQL Server Configuration Manager. Expanda o Amazon RDS do SQL Server para a instância desejada e selecione Protocolos para MSSQLSERVER. Os protocolos aparecem no painel direito. Habilite o TCP/IP clicando com o botão direito do mouse em TCP/IP e selecionando Habilitar.
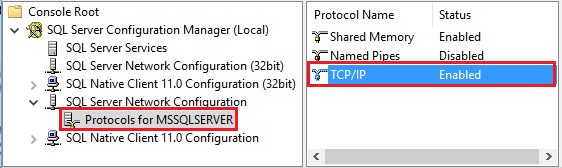
Para obter mais informações e maneiras alternativas de habilitar o protocolo TCP/IP, consulte, Habilitar ou desabilitar um protocolo de rede do servidor.
Na mesma janela, clique duas vezes em TCP/IP para iniciar a janela Propriedades de TCP/IP.
Alterne para a guia Endereços IP. Role para baixo para ver a seção IPAll. Anote a porta TCP. O padrão é 1433.
Crie uma regra para o Firewall do Windows no computador para permitir a entrada de tráfego por essa porta.
Verifique a conexão: para se conectar ao Amazon RDS para SQL Server usando um nome totalmente qualificado, use o Amazon RDS para SQL Server Management Studio de um computador diferente. Um exemplo é
"<machine>.<domain>.corp.<company>.com,1433".
Atualizar a versão do Amazon RDS para SQL Server
Para atualizar a versão do Amazon RDS para SQL Server, na página Editar serviço vinculado, selecione Recomendado em Versão e configure o serviço vinculado conforme as Propriedades do serviço vinculado para a versão recomendada.
Diferenças entre a versão recomendada e a versão herdada
A tabela abaixo mostra as diferenças entre o Amazon RDS for SQL Server usando a versão recomendada e a versão legada.
| Versão recomendada | Versão herdada |
|---|---|
Suporta TLS 1.3 via encrypt como strict. |
TLS 1.3 não é compatível. |
Conteúdo relacionado
Para obter uma lista dos armazenamentos de dados com suporte como coletores e fontes da atividade de cópia, confira os Armazenamentos de dados com suporte.