Resiliência e recuperação de desastre no Serviço do Azure Web PubSub
Resiliência e recuperação de desastre são necessidades comuns de sistemas online. O Serviço do Azure Web PubSub já garante uma disponibilidade de 99,9%, mas ainda é um serviço regional. Quando há uma interrupção em toda a região, é essencial que o serviço continue processando mensagens em tempo real em uma região diferente.
Para recuperação de desastres regional, recomendamos as duas abordagens a seguir:
- Habilite a replicação geográfica (maneira fácil). Esse recurso lidará com failover regional para você automaticamente. Quando habilitado, permanece apenas uma instância do Azure SignalR e nenhuma alteração de código é introduzida. Verifique a replicação geográfica para obter detalhes.
- Utilize vários pontos de extremidade. Você aprenderá a fazer isso neste documento
Arquitetura de alta disponibilidade para o serviço do Web PubSub
Há dois padrões típicos usando o serviço Web PubSub:
- Um deles é o padrão cliente-servidor em que os clientes enviam eventos para o servidor e o servidor envia mensagens por push para os clientes.
- Outro é o padrão cliente-cliente que os clientes publicam/sub mensagens por meio do serviço Web PubSub para outros clientes.
As seções abaixo descrevem diferentes maneiras desses dois padrões de fazer a recuperação de desastres:
Arquitetura de alta disponibilidade para o padrão cliente-servidor
Para ter resiliência entre regiões para o Serviço do Web PubSub, você precisa configurar várias instâncias do serviço em diferentes regiões. Assim, quando uma região estiver inativa, as outras poderão ser usadas como backup.
Uma configuração típica do cenário com várias regiões é ter dois (ou mais) pares de instâncias do Serviço do Web PubSub e servidores de aplicativos.
Em cada par, o servidor de aplicativo e o serviço do Web PubSub estão localizados na mesma região, e o serviço Web PubSub define o manipulador de eventos upstream para o servidor de aplicativos na mesma região.
Para ilustrar melhor a arquitetura, chamamos o serviço do Web PubSub de serviço primário para o servidor de aplicativos no mesmo par. E chamamos serviços do Web PubSub em outros pares como os serviços secundários para o servidor de aplicativos.
O servidor de aplicativos pode usar a API de verificação de integridade do serviço para detectar se os seus serviços primários e secundários estão íntegros ou não. Por exemplo, para um serviço do Web PubSub chamado demo, o ponto de extremidade https://demo.webpubsub.azure.com/api/health retorna 200 quando o serviço está íntegro. O servidor de aplicativos pode chamar periodicamente os pontos de extremidade ou os pontos de extremidade sob demanda para verificar se eles estão íntegros. Os clientes WebSocket geralmente negotiate com o servidor de aplicativos primeiro para obter a URL que se conecta ao serviço do Web PubSub, e o aplicativo usa essa etapa de negotiate para fazer failover dos clientes para outros serviços secundário íntegros. Etapas detalhadas conforme abaixo:
- Quando um cliente negocia com o servidor de aplicativos, o servidor de aplicativo DEVE retornar apenas os pontos de extremidade de serviço do Web PubSub primário, portanto, em casos normais, os clientes se conectem apenas aos pontos de extremidade primários.
- Quando a instância primária estiver inoperante, negociar DEVERÁ retornar um ponto de extremidade secundário íntegro para que o cliente ainda possa fazer conexões e o cliente se conecte ao ponto de extremidade secundário.
- Quando a instância primária estiver ativa, negotiate DEVE retornar o ponto de extremidade primário íntegro para que os clientes agora possam se conectar ao ponto de extremidade primário
- Quando o servidor de aplicativos transmitir mensagens, ele DEVE transmitir as mensagens para todos os pontos de extremidade íntegros, incluindo primário e secundário.
- O servidor de aplicativos pode fechar conexões conectadas a pontos de extremidade secundários para forçar os clientes a se reconectar ao ponto de extremidade primário íntegro.
Com esta topologia, mensagens de um servidor ainda podem ser entregues a todos os clientes, uma vez que todos os servidores de aplicativos e instâncias do Serviço do Web PubSub são interconectados.
A aplicativo precisa implementar essa estratégia por conta própria por enquanto, pois ainda não a integramos ao SDK.
Resumindo, o lado do aplicativo precisa implementar:
- A verificação de integridade. O aplicativo pode verificar se o serviço está usando de forma íntegra a API de verificação de integridade do serviço periodicamente em segundo plano ou sob demanda em cada chamada negotiate.
- A Negotiate lógica. O aplicativo retorna o ponto de extremidade primário íntegro, por padrão. Quando o ponto de extremidade primário está inoperante, o aplicativo retorna o ponto de extremidade secundário íntegro.
- Lógica de transmissão. Quando as mensagens são enviadas para vários clientes, o aplicativo precisa garantir que ele transmita mensagens para todos os pontos de extremidade íntegros .
A seguir, há um diagrama que ilustra essa topologia:
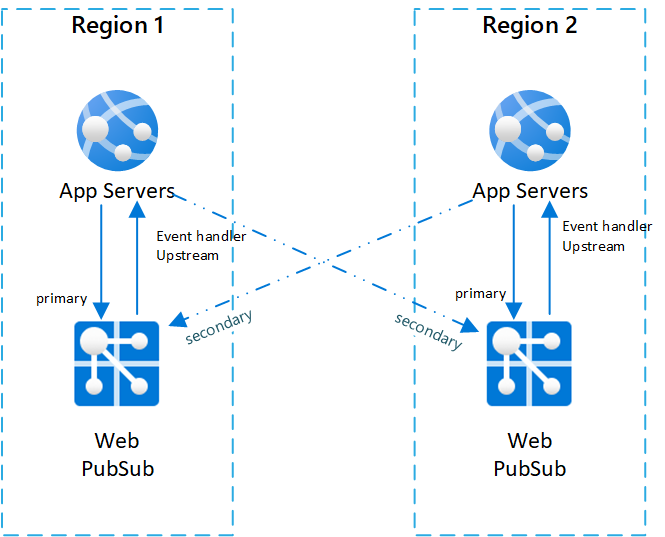
Sequência de failover e melhor prática
Agora, você tem a topologia de sistema certa configurada. Sempre que uma instância do Serviço do Web PubSub estiver inativa, o tráfego online será roteado para outras instâncias. Veja o que acontece quando uma instância primária está inativa (e se recupera após algum tempo):
- A instância de serviço primária está inativa, todos os clientes nesta instância serão removidos.
- Novos clientes ou cliente de reconexão negociam com o servidor de aplicativos
- O servidor de aplicativo detecta que a instância de serviço primário está inoperante e a negociação para de retornar esse ponto de extremidade e começa a retornar um ponto de extremidade secundário íntegro.
- Os clientes se conectam à instância secundária.
- Agora, a instância secundária recebe todo o tráfego online. Todas as mensagens do servidor para os clientes ainda podem ser entregues, pois o ponto de extremidade secundário está conectado a todos os servidores de aplicativos. Mas as mensagens de evento de cliente para servidor são enviadas apenas para o servidor de aplicativos upstream na mesma região.
- Depois que a instância primária for recuperada e estiver novamente online, o servidor de aplicativos detectará que a instância primária está novamente íntegra. Agora, negociar voltará a retornar o ponto de extremidade primário e, assim, os clientes serão conectados de volta ao primário. No entanto, clientes existentes não serão descartados e continuarão conectados no secundário até que se desconectem.
Os diagramas abaixo ilustram como o failover é feito:
Fig.1 Antes do failover 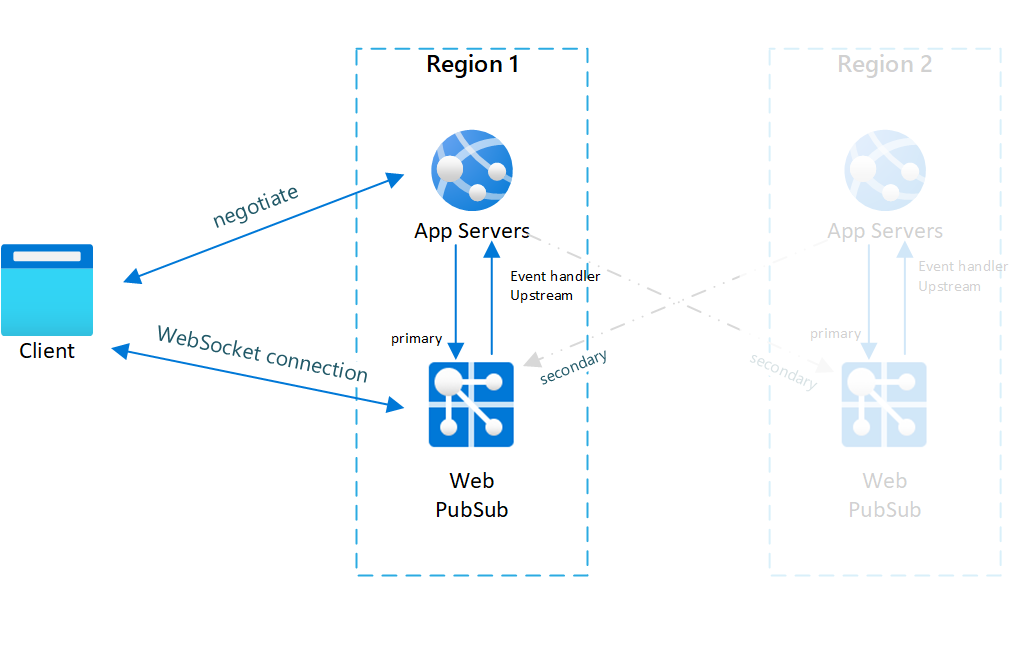
Fig.2 Após failover 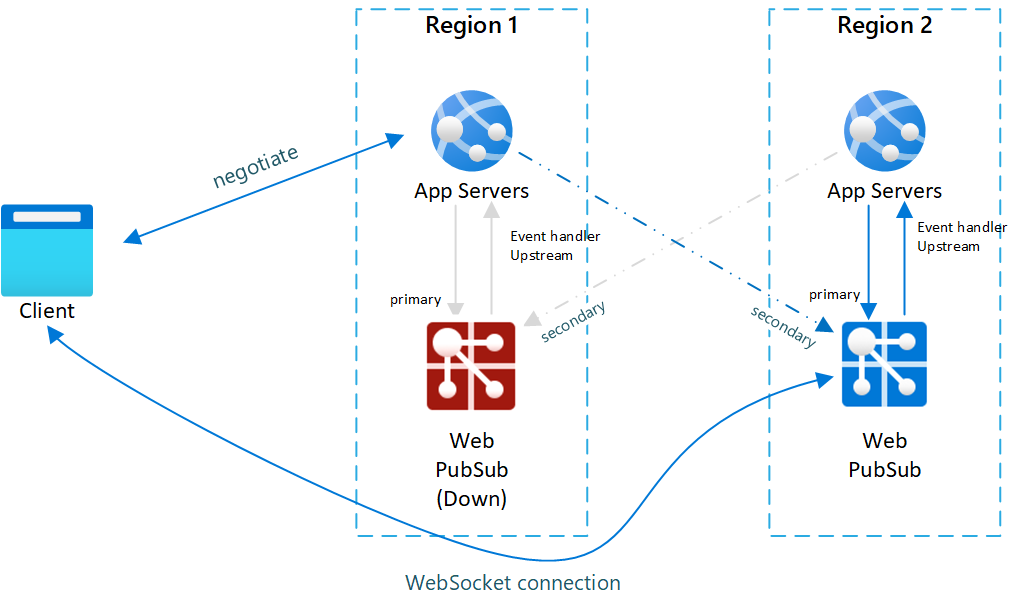
Fig.3 Pouco tempo após a recuperação primária 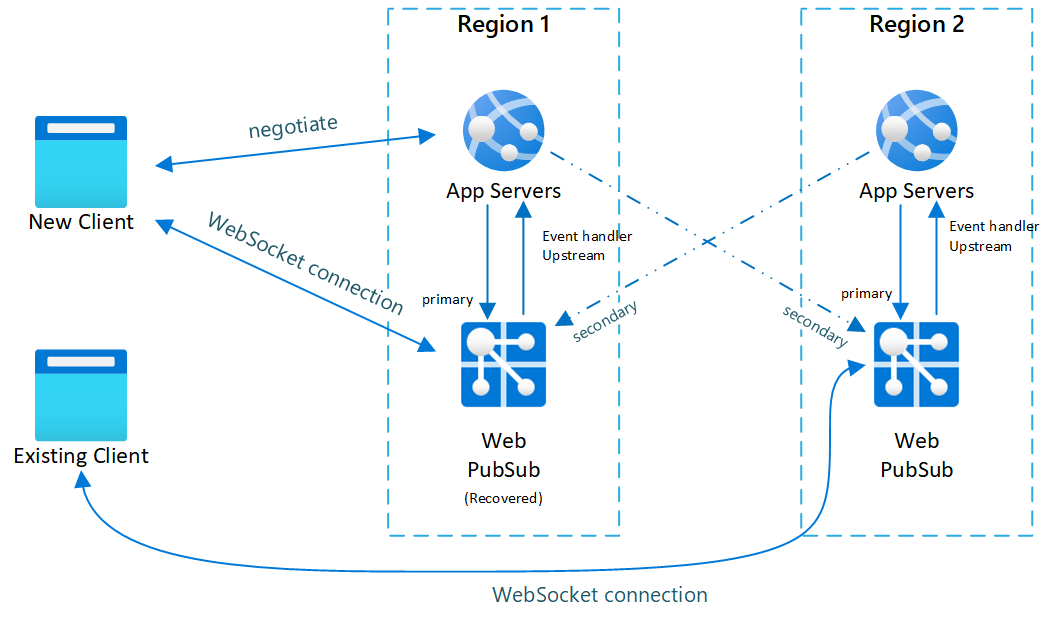
Você pode ver que, no funcionamento normal, somente o servidor de aplicativos e o Serviço do Web PubSub primários têm tráfego online (em azul).
Após o failover, o servidor de aplicativos e o Serviço do Web PubSub secundários também se tornam ativos. Após o Serviço do Web PubSub primário voltar a ficar online, novos clientes se conectam a ele. No entanto, clientes existentes ainda se conectam ao serviço secundário, de modo que as duas instâncias têm tráfego.
Após todos os clientes existentes se desconectarem, o sistema voltará ao normal (Fig.1).
Há dois padrões principais para implementar uma arquitetura entre regiões de alta disponibilidade:
- O primeiro é ter um par de servidor de aplicativos e instância do Serviço do Web PubSub que recebe todo o tráfego online e ter outro par como backup (chamado de ativo/passivo, ilustrado na Fig.1).
- O outro padrão é ter dois pares (ou mais) de servidores de aplicativos e instâncias do Serviço do Web PubSub, cada um deles recebendo parte do tráfego online e servindo como backup para os outros pares (chamado de ativo/ativo, semelhante à Fig.3).
O Serviço do Web PubSub pode dar suporte aos dois padrões, a principal diferença é como você implementa os servidores de aplicativos. Se os servidores de aplicativos forem do tipo ativo/passivo, o Serviço do Web PubSub também será ativo/passivo (pois o servidor de aplicativos primário retorna apenas sua instância primária do Serviço do Web PubSub). Se os servidores de aplicativos forem do tipo ativo/ativo, o Serviço do Web PubSub também será ativo/ativo (pois todos os servidores de aplicativos retornarão suas próprias instâncias primárias do Web PubSub, para que todos eles possam receber tráfego).
Não esqueça que, independente dos padrões que escolher usar, você precisará conectar cada instância de serviço do Web PubSub a um servidor de aplicativos como uma função primária.
Além disso, devido à natureza da conexão do WebSocket (trata-se de uma conexão longa), os clientes enfrentarão quedas de conexão quando houver um desastre e o failover ocorrer. Você precisará lidar com tais casos no lado do cliente para torná-los transparentes para seus clientes finais. Por exemplo, reconecte-se após uma conexão ser encerrada.
Arquitetura de alta disponibilidade para o padrão cliente-cliente
Para o padrão cliente-cliente, atualmente ainda não é possível oferecer suporte a uma recuperação de desastres de tempo de inatividade zero usando várias instâncias. Se você tiver requisitos de alta disponibilidade, considere o uso de replicação geográfica.
Como testar um failover
Siga as etapas para acionar o failover:
- Na guia Rede do recurso principal no portal, desabilite o acesso à rede pública. Se o recurso tiver rede privada habilitada, use regras de controle de acesso para negar todo o tráfego.
- Reinicie o recurso principal.
Próximas etapas
Neste artigo, você aprendeu a configurar seu aplicativo para ter resiliência para o Serviço do Web PubSub.
Use estes recursos para começar a criar seu aplicativo: