Depurar aplicativos do Apache Spark em um cluster HDInsight com o Azure Toolkit for IntelliJ por meio do SSH
Este artigo fornece orientação passo-a-passo sobre como usar as Ferramentas do HDInsight no Azure Toolkit for IntelliJ para depurar aplicativos remotamente em um cluster do HDInsight.
Pré-requisitos
Um cluster do Apache Spark no HDInsight. Veja Criar um cluster do Apache Spark.
Para usuários do Windows: durante a execução do aplicativo Scala Spark local em um computador Windows, talvez ocorra uma exceção, conforme explicado em SPARK-2356. A exceção ocorre porque WinUtils.exe está ausente no Windows.
Para solucionar o erro, baixe Winutils.exe em um local como C:\WinUtils\bin. Em seguida, adicione uma variável de ambiente HADOOP_HOME e defina o valor da variável para C\WinUtils.
IntelliJ IDEA (a Community Edition é gratuita).
Um cliente SSH. Para saber mais, confira Conectar-se ao HDInsight (Apache Hadoop) usando SSH.
Criar um aplicativo Spark Scala
Inicie o IntelliJ IDEA e selecione Criar novo projeto para abrir a janela Novo projeto.
Selecione Apache Spark/HDInsight no painel esquerdo.
Selecione Projeto Spark com Exemplos (Scala) na janela principal.
Na lista suspensa Ferramenta de build, selecione uma das seguintes opções:
- Maven para obter suporte ao assistente de criação de projetos Scala.
- SBT para gerenciar as dependências e para criar no projeto Scala.
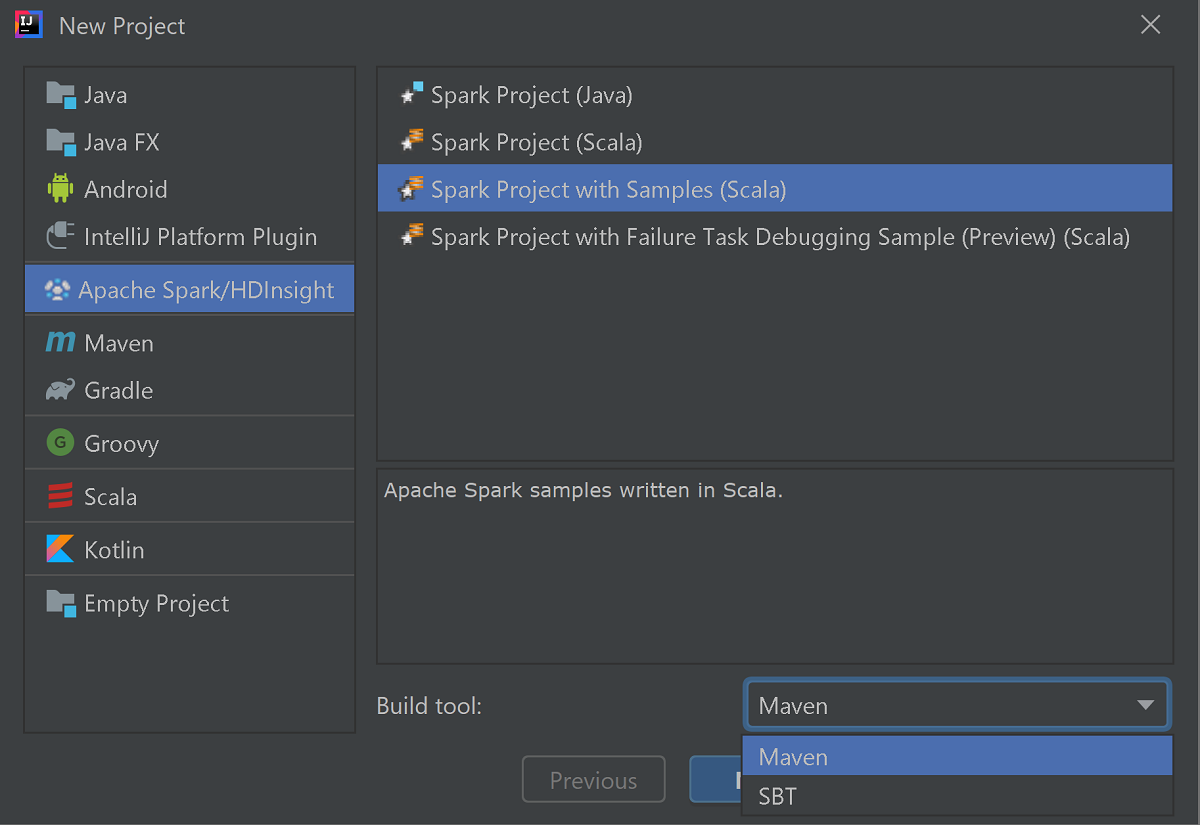
Selecione Avançar.
Na próxima janela Novo Projeto, forneça as seguintes informações:
Propriedade Descrição Nome do projeto Insira um nome. Essa explicação usa myApp.Localização do projeto Insira o local desejado para salvar o projeto. SDK do projeto Se estiver em branco, selecione Novo... e navegue até o JDK. Versão do Spark O assistente de criação integra a versão apropriada para o SDK do Spark e o SDK do Scala. Se a versão do cluster do Spark for anterior à 2.0, selecione Spark 1.x. Caso contrário, selecione Spark 2.x. Esse exemplo usa o Spark 2.3.0 (Scala 2.11.8) . 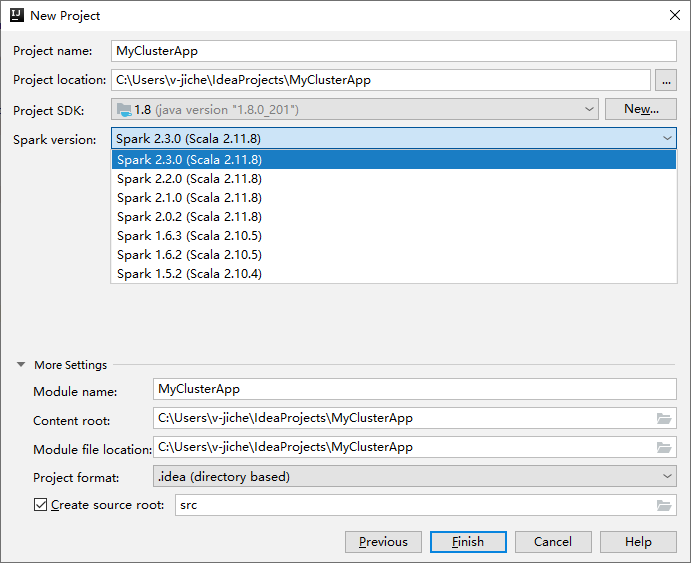
Selecione Concluir. Pode levar alguns minutos antes que o projeto fique disponível. Observe o progresso no canto inferior direito.
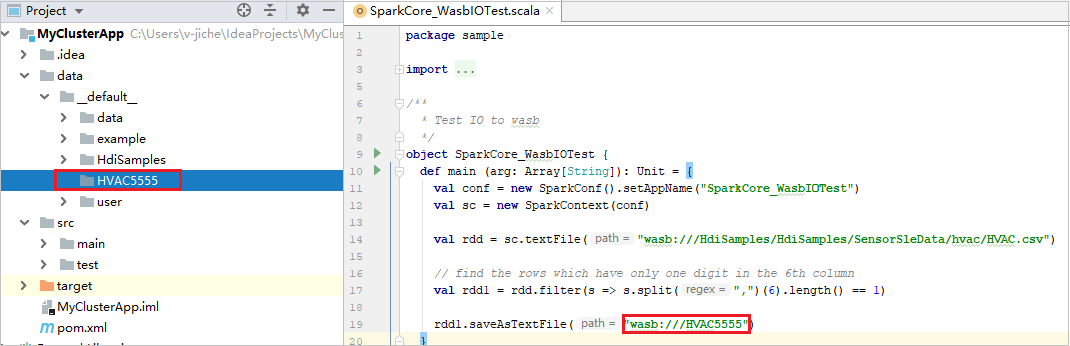
Expanda o projeto e navegue até src>main>scala>sample. Clique duas vezes em SparkCore_WasbIOTest.
Realizar execução local
No script SparkCore_WasbIOTest, clique com o botão direito do mouse no editor de script e selecione a opção Executar 'SparkCore_WasbIOTest' para realizar a execução local.
Assim que a execução local estiver concluída, você pode ver o arquivo de saída salvo no Explorador de projeto atual dados>padrão.
Nossas ferramentas definiram a configuração de execução local automaticamente quando você executar a execução local e depuração local. Abra a configuração [Spark no HDInsight] XXX no canto superior direito, você verá [Spark no HDInsight]XXX já criado em Apache Spark no HDInsight. Mude para a guia Executar localmente.
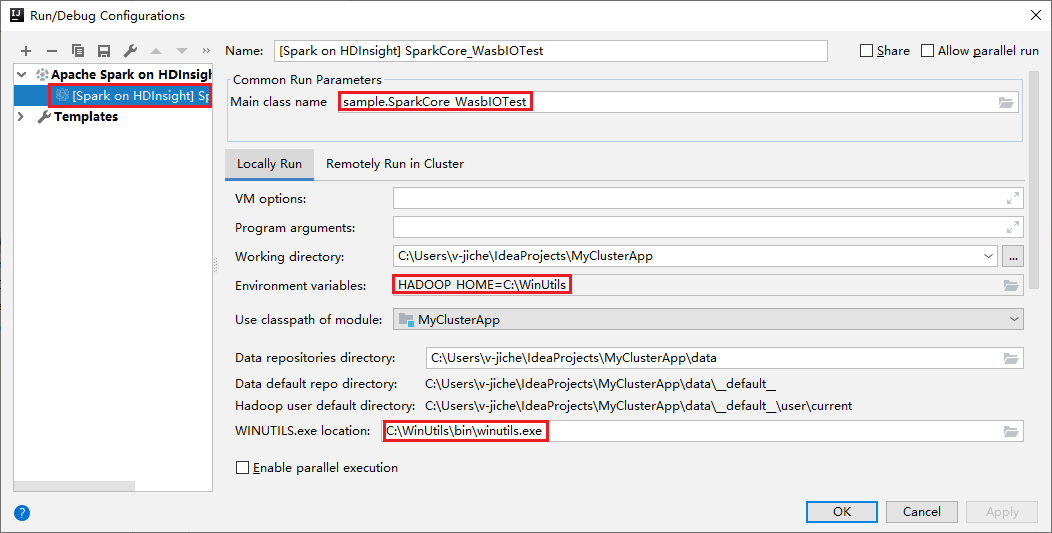
- Variáveis de ambiente: se você já definiu a variável de ambiente do sistema HADOOP_HOME como C:\WinUtils, ela pode detectar automaticamente que não é necessário adicionar manualmente.
- Local de WinUtils.exe: se você não tiver definido a variável de ambiente do sistema, poderá encontrar o local clicando em seu botão.
- Basta escolher uma das duas opções, e elas não são necessárias em macOS e Linux.
Você também pode definir a configuração manualmente antes de executar a depuração e execução local. Na captura de tela acima, selecione o sinal de adição ( + ). Em seguida, selecione a opção Apache Spark no HDInsight. Insira as informações para Nome, Nome da classe principal para salvar, em seguida, clique no botão de execução local.
Executar depuração local
Abra o script SparkCore_wasbloTest e defina os pontos de interrupção.
Clique com o botão direito do mouse no editor de script e, em seguida, selecione a opção Depurar '[Spark no HDInsight]XXX' para realizar a depuração local.
Realizar execução remota
Navegue para Executar>Editar configurações... . Nesse menu, você pode criar ou editar as configurações para depuração remota.
Na caixa de diálogo Configurações de Execução/Depuração, selecione o sinal de mais (+). Em seguida, selecione a opção Apache Spark no HDInsight.
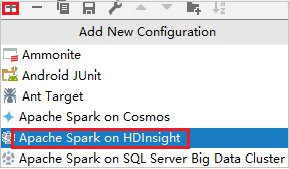
Alterne para a guia Executar Remotamente no Cluster. Insira as informações de Nome, Cluster do Spark e Nome da classe principal. Em seguida, clique em Configuração avançada (depuração remota) . Nossas ferramentas oferecem suporte à depuração com Executores. O numExecutors, o valor padrão é 5. É melhor não definir como maior que 3.
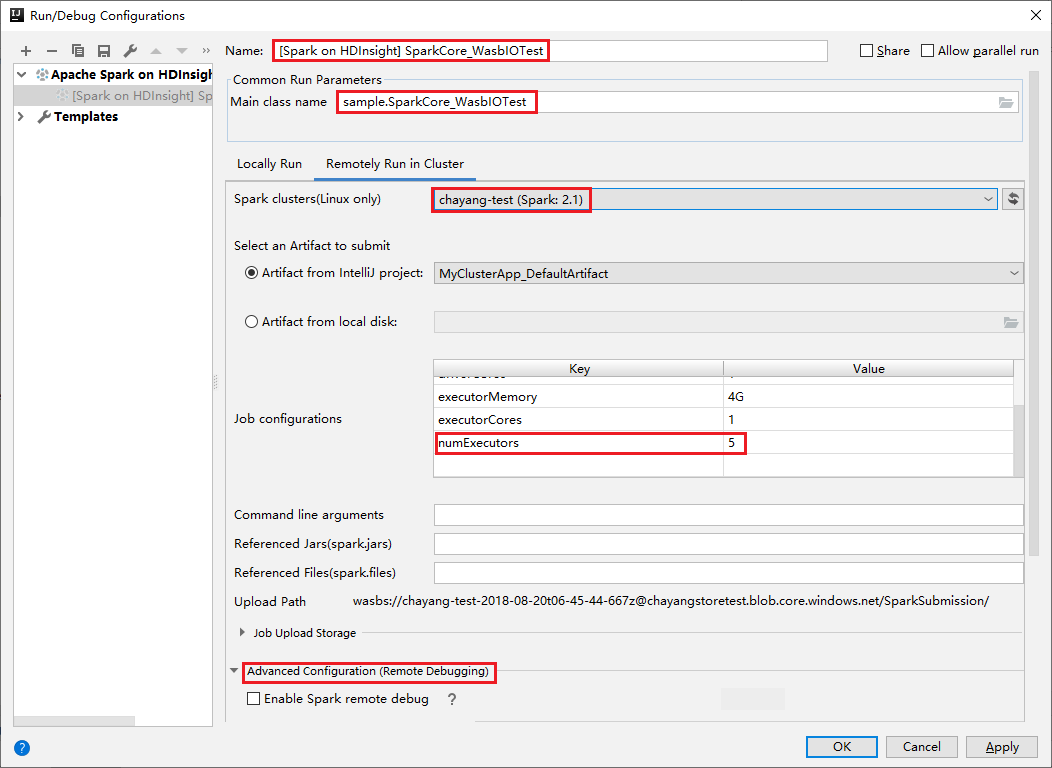
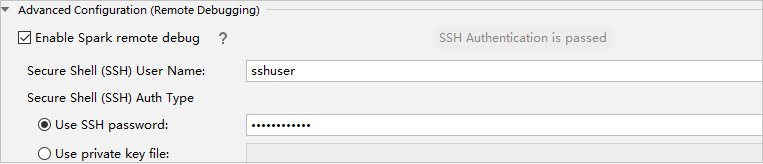
Na parte Configuração Avançada (Depuração Remota) , selecione Habilitar depuração remota do Spark. Insira o nome de usuário do SSH e insira uma senha ou use um arquivo de chave privada. Se desejar executar a depuração remota, será necessário configurá-la. Não será necessário configurá-la se quiser usar apenas a execução remota.
Agora, a configuração está salva com o nome fornecido. Para exibir os detalhes de configuração, selecione o nome da configuração. Para fazer alterações, selecione Editar configurações.
Após concluir as definições de configurações, você poderá executar o projeto no cluster remoto ou realizar a depuração remota.

Clique no botão Desconectar para ocultar os logs de envio do painel esquerdo. Eles continuarão sendo executados em segundo plano.
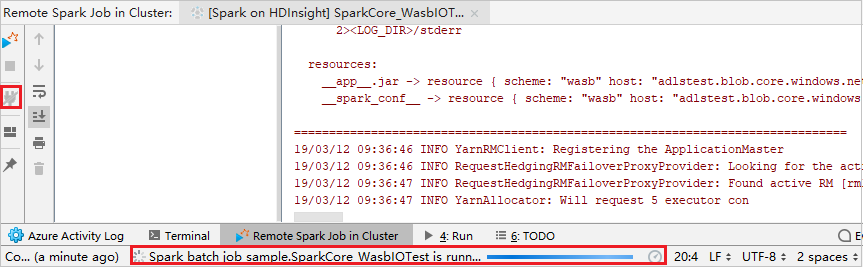
Executar depuração remota
Configure pontos de interrupção e, em seguida, clique no ícone Depuração remota. A diferença com envio remoto é que o nome de usuário/senha de SSH devem ser configurados.

Quando a execução do programa atingir o ponto de interrupção, você verá uma guia Driver e duas guias Executor no painel Depurador. Selecione o ícone Retomar Programa para continuar a execução do código, que alcança o próximo ponto de interrupção. Você precisará mudar para a guia Executor correta para localizar o executor de destino para depurar. Você pode visualizar os logs de execução na guia Console correspondente.
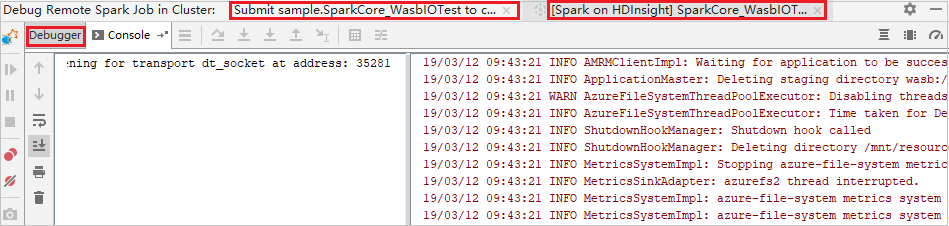
Para realizar depuração remota e correção de bugs
Configure dois pontos de interrupção e, em seguida, selecione o ícone Depurar para iniciar o processo de depuração remota.
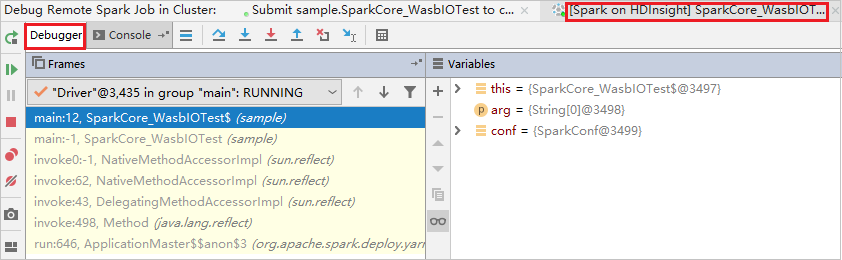
O código para no primeiro ponto de interrupção e as informações de parâmetro e de variáveis são mostradas no painel Variáveis.
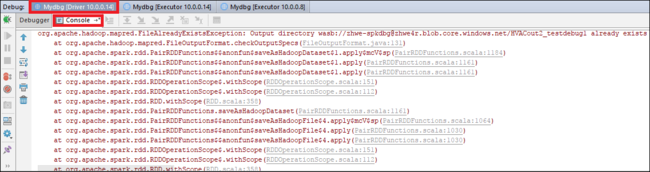
Selecione o ícone Retomar Programa para continuar. O código para no segundo ponto. A exceção é capturada conforme o esperado.
Selecione o ícone Retomar Programa novamente. A janela Envio do HDInsight Spark exibe um erro de “falha na execução do trabalho”.
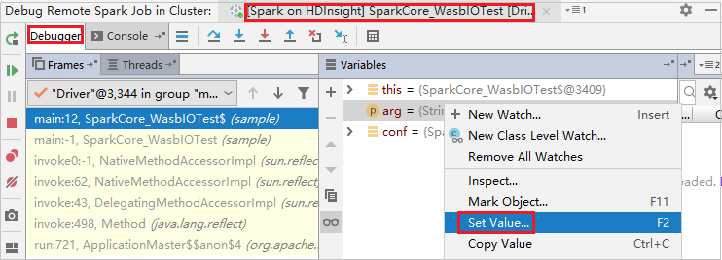
Para atualizar dinamicamente o valor da variável usando a capacidade de depuração do IntelliJ, selecione Depurar novamente. O painel Variáveis é exibido novamente.
Clique com o botão direito do mouse no destino na guia Depurar e, então, selecione Definir valor. Em seguida, insira um novo valor para a variável. Depois, selecione Enter para salvar o valor.
Selecione o ícone Retomar Programa para continuar a execução do programa. Neste momento, nenhuma exceção é detectada. Você pode ver que o projeto é executado com êxito, sem exceções.
Próximas etapas
Cenários
- Apache Spark com BI: realize a análise interativa de dados usando o Spark no HDInsight com ferramentas de BI
- Apache Spark com Machine Learning: use o Spark no HDInsight para analisar a temperatura do edifício usando dados de HVAC
- Apache Spark com Machine Learning: use o Spark no HDInsight para prever os resultados da inspeção de alimentos
- Análise de log do site usando o Apache Spark no HDInsight
Criar e executar aplicativos
- Criar um aplicativo autônomo usando Scala
- Execute trabalhos remotamente em um cluster do Apache Spark usando o Apache Livy
Ferramentas e extensões
- Use o Azure Toolkit for IntelliJ para criar aplicativos do Apache Spark para um cluster do HDInsight
- Use o Azure Toolkit for IntelliJ para depurar aplicativos Apache Spark remotamente por meio de VPN
- Use as ferramentas do HDInsight no Azure Toolkit for Eclipse para criar aplicativos do Apache Spark
- Use os blocos de anotações do Apache Zeppelin com um cluster do Apache Spark no HDInsight
- Kernels disponíveis para o Jupyter Notebook no cluster do Apache Spark para HDInsight
- Usar pacotes externos com Jupyter Notebooks
- Instalar o Jupyter em seu computador e conectar-se a um cluster Spark do HDInsight