Kernels para o Jupyter Notebook em clusters do Apache Spark no Azure HDInsight
Os clusters do HDInsight Spark fornecem kernels que você pode usar com o Jupyter Notebook do Apache Spark para testar seus aplicativos. Um kernel é um programa que é executado e que interpreta seu código. Os três kernels são:
- PySpark - para aplicativos escritos em Python2. (Aplicável apenas para clusters da versão do Spark 2.4)
- PySpark3 - para aplicativos escritos em Python3.
- Spark - para aplicativos escritos em Scala.
Neste artigo, você aprenderá como usar esses kernels e os benefícios de usá-los.
Pré-requisitos
Um cluster do Apache Spark no HDInsight. Para obter instruções, consulte o artigo sobre como Criar clusters do Apache Spark no Azure HDInsight.
Criar um Jupyter Notebook no Spark HDInsight
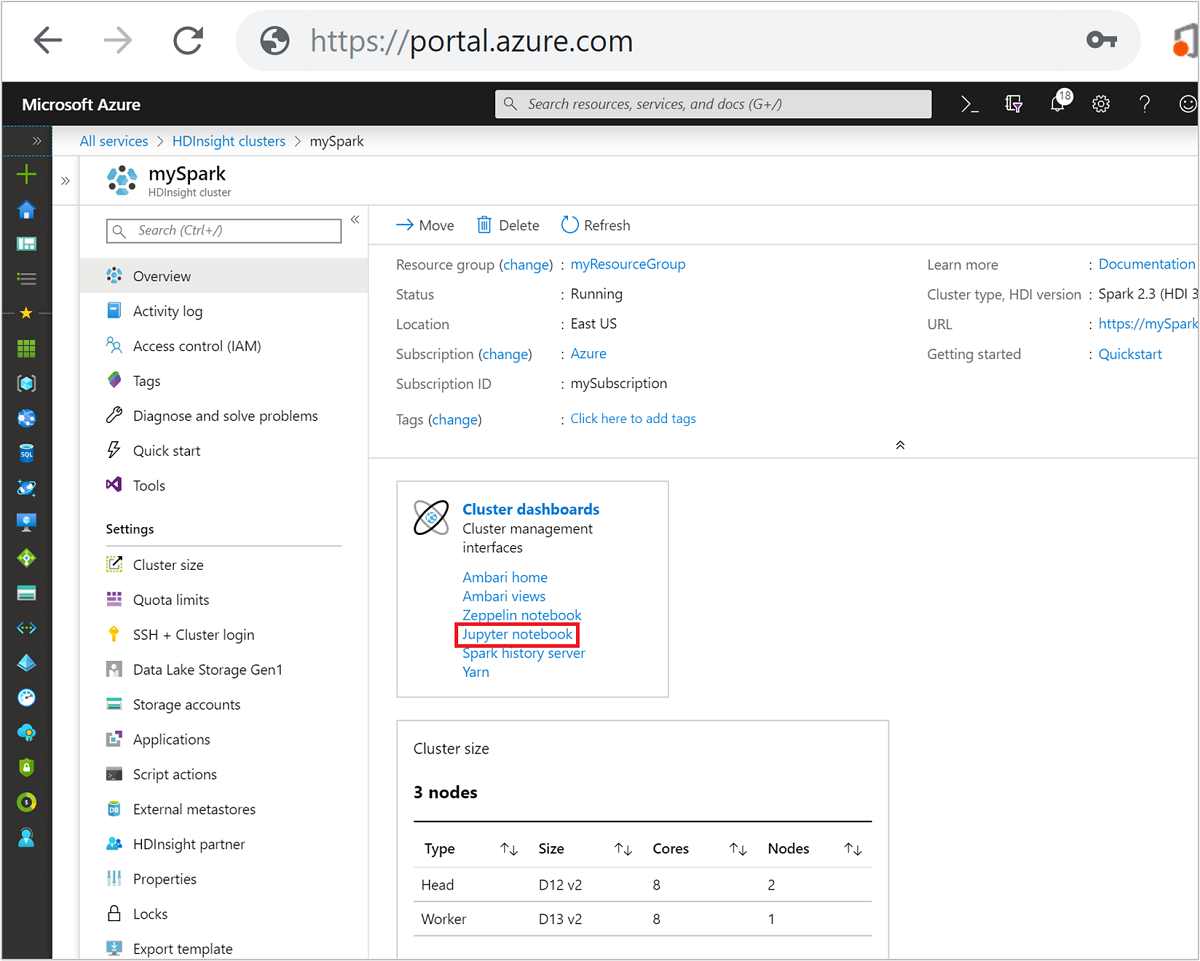
No Portal do Azure, selecione seu cluster do Spark. Consulte lista e mostrar clusters para obter instruções. A exibição Visão geral é aberta.
No modo de exibição Visão geral, na caixa Painéis do cluster, selecione Jupyter Notebook. Se você receber uma solicitação, insira as credenciais de administrador para o cluster.
Observação
Você também pode acessar o Jupyter Notebook de seu cluster do Spark abrindo o seguinte URL no navegador. Substitua CLUSTERNAME pelo nome do cluster:
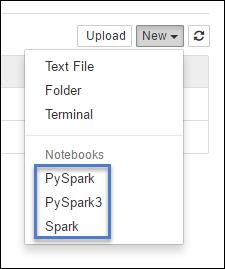
https://CLUSTERNAME.azurehdinsight.net/jupyterSelecione Novo e, em seguida, selecione Pyspark, PySpark3 ou Spark para criar um notebook. Use o kernel Spark para aplicativos em Scala, o kernel PySpark para aplicativos em Python2 e o kernel PySpark3 para aplicativos em Python3.
Observação
Para Spark 3.1, apenas o PySpark3 ou o Spark estará disponível.
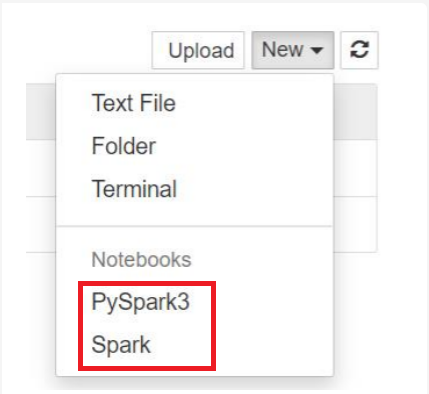
- Um notebook é aberto com o kernel selecionado.
Benefícios de usar os kernels
Estes são alguns dos benefícios de usar os novos kernels com o Jupyter Notebook nos clusters do Spark HDInsight.
Contextos de predefinição. Com o PySpark, o PySpark3 ou os kernels do Spark não é necessário definir os contextos do Spark e do Hive explicitamente para começar a trabalhar com os aplicativos. Esses contextos estão disponíveis por padrão. Esses contextos são:
sc - para o contexto do Spark
sqlContext : para o contexto Hive
Portanto, você não precisa executar instruções como as seguintes para definir os contextos:
sc = SparkContext('yarn-client') sqlContext = HiveContext(sc)Em vez disso, pode usar os contextos predefinidos diretamente em seu aplicativo.
A mágica da célula. O kernel de PySpark fornece algumas "mágicas"” predefinidas, que são comandos especiais que podem ser chamados com
%%(por exemplo,%%MAGIC<args>). O comando mágico deve ser a primeira palavra em uma célula do código e de permitir várias linhas de conteúdo. A palavra mágica deve ser a primeira palavra na célula. Adicionar algo antes da palavra mágica, até mesmo comentários, causa um erro. Para saber mais sobre palavras mágicas, clique aqui.A tabela a seguir lista as diferentes palavras mágicas disponíveis por meio dos kernels.
Mágica Exemplo Descrição ajuda %%helpGera uma tabela de todos os comandos mágicos disponíveis com exemplo e descrição informações %%infoEnvia informações de sessão para o ponto de extremidade Livy atual CONFIGURAR %%configure -f{"executorMemory": "1000M","executorCores": 4}Configura os parâmetros para a criação de uma sessão. O sinalizador force ( -f) será obrigatório se uma sessão já tiver sido criada, o que garante que a sessão será descartada e recriada. Veja o Corpo da Solicitação POST /sessions da Livy para obter uma lista de parâmetros válidos. Os parâmetros devem ser passados como uma cadeia de caracteres JSON e devem estar na linha seguinte, logo após a mágica, conforme mostrado na coluna de exemplo.sql %%sql -o <variable name>
SHOW TABLESExecuta uma consulta do Hive no dqlContext. Se o parâmetro -ofor passado, o resultado da consulta será persistido no contexto %%local do Python como um dataframe do Pandas .local %%locala=1Todo o código nas linhas posteriores é executado localmente. O código deve ser um código de Python2 válido, não importa qual kernel você está usando. Portanto, mesmo se você selecionou os kernels PySpark3 ou Spark ao criar o notebook, se você usar a palavra mágica %%localem uma célula, essa célula só poderá ter um código Python2 válido.logs %%logsGera os logs da sessão atual do Livy. excluir %%delete -f -s <session number>Exclui uma sessão específica do ponto de extremidade atual do Livy. Você não pode excluir a sessão iniciada para o próprio kernel. limpeza %%cleanup -fExclui todas as sessões do ponto de extremidade atual do Livy, incluindo a sessão deste notebook. O sinalizador de força -f é obrigatório. Observação
Além das mágicas adicionados pelo kernel PySpark, você também pode usar as mágicas internas do IPython, incluindo
%%sh. Você pode usar a mágica%%shpara executar scripts e bloco de código no nó principal do cluster.Visualização automática. O kernel Pyspark visualiza automaticamente a saída das consultas Hive e SQL. Escolha entre vários tipos diferentes de visualização, incluindo Tabela, Pizza, Linha, Área, Barra.
Parâmetros compatíveis com a mágica de %%sql
A palavra mágica %%sql é compatível com diversos parâmetros que podem ser usados para controlar o tipo de saída que você recebe ao executar consultas. A tabela a seguir lista as saídas.
| Parâmetro | Exemplo | Descrição |
|---|---|---|
| -o | -o <VARIABLE NAME> |
Use esse parâmetro para manter o resultado da consulta, no contexto Python %%local, como um dataframe Pandas . O nome da variável dataframe é o nome da variável que você especificar. |
| -Q | -q |
Use este parâmetro para desativar visualizações da célula. Se não desejar visualizar o conteúdo de uma célula automaticamente, mas apenas capturá-la como um dataframe, use -q -o <VARIABLE>. Se desejar desativar as visualizações sem capturar os resultados (por exemplo, para executar uma consulta SQL, como uma instrução CREATE TABLE), use -q sem especificar um argumento -o. |
| -M | -m <METHOD> |
Onde METHOD é take ou sample (o padrão é take). Se o método for take , o kernel selecionará elementos da parte superior do conjunto de dados de resultados especificado por MAXROWS (descrito posteriormente nesta tabela). Se o método for sample, o kernel experimentará aleatoriamente os elementos do conjunto de dados segundo o parâmetro -r, descrito a seguir nesta tabela. |
| -r | -r <FRACTION> |
Aqui FRACTION é um número de ponto flutuante entre 0.0 e 1.0. Se o método de amostragem para a consulta SQL for sample, o kernel experimentará aleatoriamente a fração especificada dos elementos do conjunto de resultados. Por exemplo, se você executar uma consulta SQL com os argumentos -m sample -r 0.01, 1% das linhas resultantes serão amostradas aleatoriamente. |
| -n | -n <MAXROWS> |
MAXROWS é um valor inteiro. O kernel limita o número de linhas de saída para MAXROWS. Se MAXROWS for um número negativo como -1, o número de linhas no conjunto de resultados não será limitado. |
Exemplo:
%%sql -q -m sample -r 0.1 -n 500 -o query2
SELECT * FROM hivesampletable
A instrução acima executa as seguintes ações:
- Seleciona todos os registros de hivesampletable.
- Como usamos - q, ele desativa a visualização automática.
- Como usamos
-m sample -r 0.1 -n 500, ele recolhe um exemplo de 10% das linhas na hivesampletable aleatoriamente e limita o tamanho do conjunto de resultados a 500 linhas. - Por fim, como usamos
-o query2, ele também salva a saída em um dataframe chamado query2.
Considerações ao usar os novos kernels
Seja qual for o kernel usado, deixar os notebooks em execução consumirá os recursos de cluster. Com esses kernels, como os contextos são predefinidos, simplesmente sair dos notebooks não elimina o contexto. Portanto, os recursos de cluster continuam em uso. Uma prática recomendada é usar a opção Fechar e Interromper do menu Arquivo do notebook quando você terminar de usar o notebook. O fechamento elimina o contexto e encerra o notebook.
Onde os blocos de anotações são armazenados?
Se o cluster usa o armazenamento do Azure como a conta de armazenamento padrão, os Jupyter Notebooks são salvos para a conta de armazenamento na pasta /HdiNotebooks. Os notebooks, arquivos de texto e pastas que você cria no Jupyter podem ser acessados na conta de armazenamento. Por exemplo, se você usar o Jupyter para criar uma pasta myfolder e um notebook myfolder/mynotebook.ipynb, poderá acessar esse notebook em /HdiNotebooks/myfolder/mynotebook.ipynb dentro da conta de armazenamento. O inverso também é possível, ou seja, se você carregar um notebook diretamente em sua conta de armazenamento em /HdiNotebooks/mynotebook1.ipynb, ele também ficará visível no Jupyter. Os logs são mantidos na conta de armazenamento mesmo após a exclusão do cluster.
Observação
Os clusters HDInsight com o Azure Data Lake Storage como armazenamento padrão não armazenam notebooks no armazenamento associado.
A forma como os blocos de anotações são salvos na conta de armazenamento é compatível com Apache Hadoop HDFS. Se você se conectar por SSH ao cluster, poderá usar comandos de gerenciamento de arquivos:
| Comando | Descrição |
|---|---|
hdfs dfs -ls /HdiNotebooks |
# Liste tudo no diretório raiz – tudo neste diretório está visível para Jupyter da página inicial |
hdfs dfs –copyToLocal /HdiNotebooks |
# Baixar o conteúdo da pasta HdiNotebooks |
hdfs dfs –copyFromLocal example.ipynb /HdiNotebooks |
# Carregar um bloco de anotações example.ipynb na pasta raiz para que fique visível em Jupyter |
Se o cluster usa o armazenamento do Azure ou o Azure Data Lake Storage como a conta de armazenamento padrão, os notebooks também são salvos em um nó principal do cluster em /var/lib/jupyter.
Navegador com suporte
Os Jupyter Notebooks em clusters do Spark HDInsight só têm suporte no Google Chrome.
Sugestões
Os kernels novos estão evoluindo e amadurecerão com o tempo. Portanto, as APIs podem mudar à medida que esses kernels amadurecem. Agradecemos o envio quaisquer comentários que você tenha ao usar esses novos kernels. Estes comentários são muito úteis na formação da versão final desses kernels. Você pode deixar seus comentários/feedback na seção Comentários no final deste artigo.