Use os cadernos Apache Zeppelin com o cluster do Apache Spark no HDInsight do Azure
Os clusters do Spark no HDInsight incluem notebooks do Apache Zeppelin. Use os notebooks para executar trabalhos do Apache Spark. Neste artigo, você aprenderá a usar o notebook Zeppelin em um cluster HDInsight.
Pré-requisitos
- Um cluster do Apache Spark no HDInsight. Para obter instruções, consulte o artigo sobre como Criar clusters do Apache Spark no Azure HDInsight.
- O esquema de URI do seu armazenamento primário de clusters. O esquema seria
wasb://para o Armazenamento de Blobs do Azure,abfs://para o Azure Data Lake Storage Gen2 ouadl://para o Azure Data Lake Storage Gen1. Se a transferência segura estiver habilitada para o Armazenamento de Blobs, o URI seráwasbs://. Para obter mais informações, veja Exigir transferência segura no Armazenamento do Microsoft Azure.
Inicie um notebook do Apache Zeppelin
Na Visão geral do cluster do Spark, selecione Notebook Zeppelin em Painéis do cluster. Insira as credenciais de administrador para o cluster.
Observação
Você também pode acessar o Bloco de Notas Zeppelin de seu cluster abrindo a seguinte URL no navegador. Substitua CLUSTERNAME pelo nome do cluster:
https://CLUSTERNAME.azurehdinsight.net/zeppelinCrie um novo bloco de anotações. No painel de cabeçalho, navegue até Notebook>Criar nova anotação.
Insira um nome para o notebook e clique em Criar Anotação.
Verifique se o cabeçalho do notebook mostra um status conectado. Isso é indicado por um ponto verde no canto superior direito.
Carregar dados de exemplo em uma tabela temporária. Quando você cria um cluster do Spark no HDInsight, o arquivo de dados de amostra,
hvac.csv, é copiado para a conta de armazenamento associada em\HdiSamples\SensorSampleData\hvac.No parágrafo vazio criado por padrão no novo bloco de anotações, cole o snippet a seguir.
%livy2.spark //The above magic instructs Zeppelin to use the Livy Scala interpreter // Create an RDD using the default Spark context, sc val hvacText = sc.textFile("wasbs:///HdiSamples/HdiSamples/SensorSampleData/hvac/HVAC.csv") // Define a schema case class Hvac(date: String, time: String, targettemp: Integer, actualtemp: Integer, buildingID: String) // Map the values in the .csv file to the schema val hvac = hvacText.map(s => s.split(",")).filter(s => s(0) != "Date").map( s => Hvac(s(0), s(1), s(2).toInt, s(3).toInt, s(6) ) ).toDF() // Register as a temporary table called "hvac" hvac.registerTempTable("hvac")Pressione SHIFT + ENTER ou clique no botão Executar do parágrafo para executar o snippet. O status no canto direito do parágrafo deve progredir de PRONTO, PENDENTE, EM EXCECUÇÃO para CONCLUÍDO. A saída é exibida na parte inferior do mesmo parágrafo. A captura de tela se parece com a seguinte imagem:
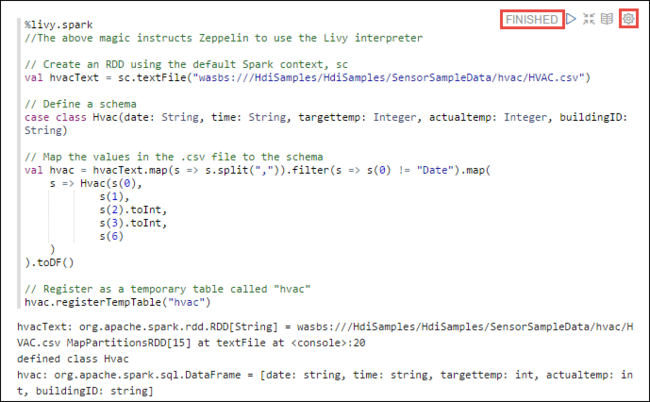
Você também pode fornecer um título para cada parágrafo. No canto direito do parágrafo, selecione o ícone de Configurações (engrenagem) e, em seguida, Mostrar título.
Observação
O intérprete %spark2 não é suportado nos blocos de notas Zeppelin em todas as versões do HDInsight, e o intérprete %sh não é suportado pelo HDInsight 4.0 em diante.
Agora você pode executar instruções SQL do Spark na tabela
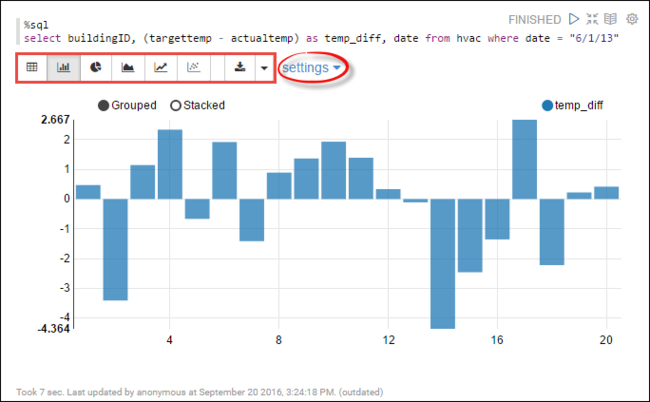
hvac. Cole a seguinte consulta em um novo parágrafo. A consulta recupera a ID do edifício. Além disso, a diferença entre as temperaturas desejadas e reais para cada edifício em uma determinada data. Pressione SHIFT+ENTER.%sql select buildingID, (targettemp - actualtemp) as temp_diff, date from hvac where date = "6/1/13"A instrução %sql no início informa ao bloco de anotações para usar o interpretador Scala Livy.
Selecione o ícone de Gráfico de Barras para alterar a exibição. As configurações, exibidas depois de selecionar Gráfico de Barras, permitem que você escolha Chaves e Valores. A captura de tela a seguir mostra o resultado.
Você também pode executar instruções Spark SQL usando variáveis na consulta. O seguinte snippet mostra como definir uma variável,
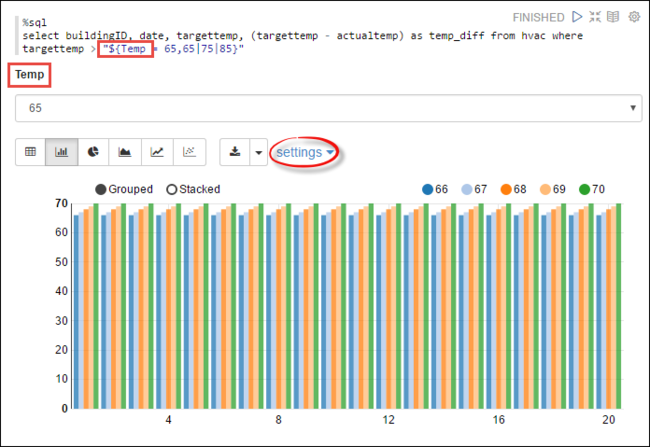
Temp, na consulta com os possíveis valores com os quais você deseja consultar. Quando você executa a consulta pela primeira vez, uma lista suspensa é preenchida automaticamente com os valores especificados para a variável.%sql select buildingID, date, targettemp, (targettemp - actualtemp) as temp_diff from hvac where targettemp > "${Temp = 65,65|75|85}"Cole esse snippet em um novo parágrafo e pressione SHIFT+ENTER. Em seguida, selecione 65 na lista suspensa Temp.
Selecione o ícone de Gráfico de Barras para alterar a exibição. Em seguida, selecione configurações e faça as seguintes alterações:
Grupos: adicione targettemp.
Valores: 1. Remova data. 2. Adicione temp_diff. 3. Altere o agregador de SUM para AVG.
A captura de tela a seguir mostra o resultado.
Como usar pacotes externos com o notebook?
O notebook Zeppelin no cluster Apache Spark no HDInsight pode usar pacotes externos enviados pela comunidade que não estão incluídos no cluster. Pesquise o repositório Maven para obter uma lista completa de pacotes disponíveis. Você também pode obter uma lista de pacotes disponíveis de outras fontes. Por exemplo, uma lista completa dos pacotes enviados pela comunidade está disponível em Pacotes do Spark.
Neste artigo, você aprenderá a usar o pacote spark csv com o Jupyter Notebook.
Abra as configurações do interpretador. No canto superior direito, selecione o nome de usuário conectado e, em seguida, selecione Interpretador.
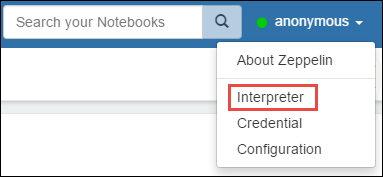
Role até livy2 e selecione Editar.
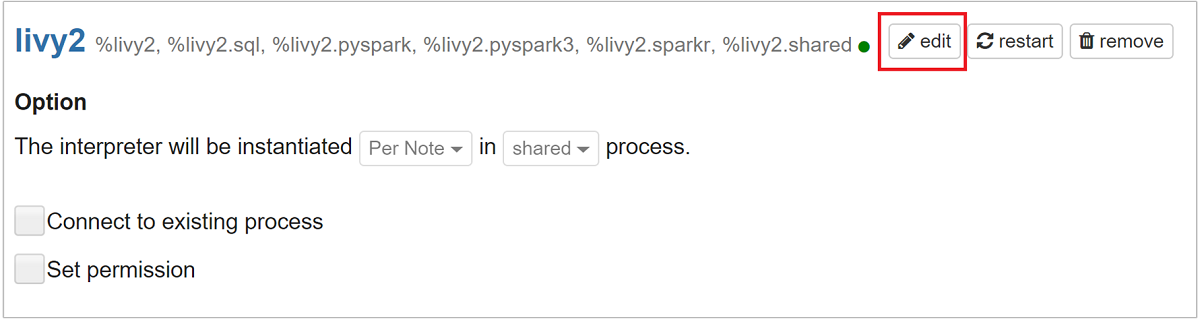
Navegue até a chave
livy.spark.jars.packagese defina seu valor no formatogroup:id:version. Dessa forma, se você quiser usar o pacote spark csv, deverá definir o valor da chave comocom.databricks:spark-csv_2.10:1.4.0.
Selecione Salvar e OK para reiniciar o interpretador Livy.
Se quiser saber como chegar ao valor da chave inserida, veja aqui como.
a. Localize o pacote no Repositório Maven. Para este artigo, usamos spark-csv.
b. No repositório, colete os valores para GroupId, ArtifactId e Version.
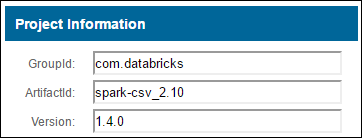
c. Concatene os três valores, separados por dois pontos (:).
com.databricks:spark-csv_2.10:1.4.0
Onde os notebooks Zeppelin são salvos?
Os blocos de notas do Zeppelin são salvos nos nós de cabeçalho do cluster. Portanto, se você excluir o cluster, os notebooks também serão excluídos. Se você quiser preservar os blocos de notas para uso posterior em outros clusters, deverá exportá-los depois de concluir os trabalhos em execução. Para exportar um bloco de notas, clique no ícone Exportar conforme mostrado na imagem a seguir.
Isso salva o notebook como um arquivo JSON no local de download.
Observação
No HDI 4.0, o caminho para o diretório do notebook zeppelin é
/usr/hdp/<version>/zeppelin/notebook/<notebook_session_id>/Por exemplo: /usr/hdp/4.1.17.10/zeppelin/2JMC9BZ8X/
Já no HDI 5.0, esse caminho muda para
/usr/hdp/<version>/zeppelin/notebook/<Kernel_name>/Por exemplo: /usr/hdp/5.1.4.5/zeppelin/notebook/Scala/
O nome do arquivo armazenado também é diferente no HDI 5.0. Ele é armazenado como
<notebook_name>_<sessionid>.zplnPor exemplo: testzeppelin_2JJK53XQA.zpln
No HDI 4.0, o nome do arquivo é apenas note.json e fica armazenado no diretório session_id.
Por exemplo: /2JMC9BZ8X/note.json
O HDI Zeppelin sempre salva o notebook no caminho
/usr/hdp/<version>/zeppelin/notebook/no disco local hn0.Se você quiser que o bloco de notas fique disponível mesmo após a exclusão do cluster, tente usar o armazenamento de arquivos do Azure (usando o protocolo SMB) e vincule-o ao caminho local. Para mais informações, confira Como montar um compartilhamento de arquivos do Azure via SMB no Linux
Depois de montá-lo, você pode modificar a configuração do zeppelin em zeppelin.notebook.dir para o caminho montado na interface do usuário do Ambari.
- Não é recomendado usar o compartilhamento de arquivos SMB como armazenamento GitNotebookRepo para a versão 0.10.1 do Zeppelin
Use Shiro para configurar o acesso aos interpretadores Zeppelin em clusters do Enterprise Security Package (ESP)
Conforme observado acima, o interpretador %sh não é compatível com o HDInsight 4.0 e superior. Além disso, como o interpretador %sh apresenta possíveis problemas de segurança, como keytabs de acesso usando comandos do Shell, ele também foi removido dos clusters ESP no HDInsight 3.6. Isso significa que o interpretador %sh não está disponível ao clicar em Criar nova anotação ou na interface do usuário do interpretador por padrão.
Os usuários de domínio com privilégios podem usar o arquivo Shiro.ini para controlar o acesso à interface do usuário do interpretador. Somente esses usuários podem criar novos interpretadores %sh e definir permissões em cada interpretador %sh novo. Para controlar o acesso usando o arquivo shiro.ini, use as seguintes etapas:
Defina uma nova função usando um nome de grupo de domínio existente. No exemplo a seguir,
adminGroupNameé um grupo de usuários privilegiados no Microsoft Entra ID. Não use caracteres especiais nem espaços em branco no nome do grupo. Os caracteres após=fornecem as permissões para essa função.*significa que o grupo tem permissões completas.[roles] adminGroupName = *Adicione a nova função para acesso aos interpretadores do Zeppelin. No exemplo a seguir, todos os usuários no
adminGroupNamerecebem acesso aos interpretadores Zeppelin e podem criar novos interpretadores. Você pode colocar várias funções entre colchetes emroles[], separadas por vírgulas. Em seguida, os usuários que têm as permissões necessárias podem acessar os interpretadores Zeppelin.[urls] /api/interpreter/** = authc, roles[adminGroupName]
Exemplo de shiro.ini para vários grupos de domínio:
[main]
anyofrolesuser = org.apache.zeppelin.utils.AnyOfRolesUserAuthorizationFilter
[roles]
group1 = *
group2 = *
group3 = *
[urls]
/api/interpreter/** = authc, anyofrolesuser[group1, group2, group3]
Gerenciamento de sessões do Livy
O primeiro parágrafo de código no notebook Zeppelin cria uma nova sessão do Livy no cluster. Essa sessão será compartilhada entre todos os notebooks Zeppelin que você criar posteriormente. Se a sessão do Livy for interrompida por qualquer motivo, os trabalhos não serão executados no notebook Zeppelin.
Nesse caso, você deverá executar as etapas a seguir antes de iniciar a execução de trabalhos de um notebook Zeppelin.
Reinicie o interpretador Livy no notebook Zeppelin. Para fazer isso, abra as configurações do interpretador selecionando o nome do usuário conectado no canto superior direito e selecione Interpretador.
Role até livy2 e selecione Reiniciar.
Execute uma célula de código de um notebook Zeppelin existente. Esse código cria uma nova sessão do Livy no cluster do HDInsight.
Informações gerais
Validar o serviço
Para validar o serviço do Ambari, navegue até https://CLUSTERNAME.azurehdinsight.net/#/main/services/ZEPPELIN/summary, em que CLUSTERNAME é o nome do cluster.
Para validar o serviço de uma linha de comando, use SSH para o nó de cabeçalho. Alterne o usuário para Zeppelin usando o comando sudo su zeppelin. Comandos de status:
| Comando | Descrição |
|---|---|
/usr/hdp/current/zeppelin-server/bin/zeppelin-daemon.sh status |
Status de serviço. |
/usr/hdp/current/zeppelin-server/bin/zeppelin-daemon.sh --version |
Versão do serviço. |
ps -aux | grep zeppelin |
PID de identificação. |
Locais dos logs
| Serviço | Caminho |
|---|---|
| zeppelin-server | /usr/hdp/current/zeppelin-server/ |
| Logs do servidor | /var/log/zeppelin |
Interpretador de Configuração, Shiro, site.xml, log4j |
/usr/hdp/current/zeppelin-server/conf ou /etc/zeppelin/conf |
| Diretório PID | /var/run/zeppelin |
Habilitar o log de depuração
Navegue até
https://CLUSTERNAME.azurehdinsight.net/#/main/services/ZEPPELIN/summary, em que CLUSTERNAME é o nome do cluster.Navegue até CONFIGS>Advanced zeppelin-log4j-properties>log4j_properties_content.
Modifique
log4j.appender.dailyfile.Threshold = INFOparalog4j.appender.dailyfile.Threshold = DEBUG.Adicione
log4j.logger.org.apache.zeppelin.realm=DEBUG.Salve as alterações e reinicie o serviço.