Configurar clusters no HDInsight com Apache Hadoop, Spark, Kafka e mais
Neste artigo, você aprenderá a configurar o Apache Hadoop, o Apache Spark, o Apache Kafka, o Interactive Query ou o Apache HBase no Azure HDInsight. Você também aprenderá como personalizar clusters e adicionar segurança ingressando-os em um domínio.
Um cluster Hadoop é composto por várias máquinas virtuais (VMs, também conhecidas como nós) usadas para processamento distribuído de tarefas. O HDInsight manipula os detalhes de implementação da instalação e da configuração de nós individuais. Você fornece apenas informações gerais de configurações.
Importante
O faturamento de cluster do HDInsight é iniciado depois que um cluster é criado e pára quando o cluster é excluído. A cobrança ocorre por minuto. Portanto, sempre exclua o cluster quando ele não estiver mais sendo usado. Saiba como excluir um cluster.
Se você usar vários clusters juntos, deseja criar uma rede virtual. Se você usar um cluster Spark, também deseja usar o Hive Warehouse Connector. Para obter mais informações, confira Planejar uma rede virtual para o Azure HDInsight e Integrar o Apache Spark e o Apache Hive com o Hive Warehouse Connector.
Métodos de instalação de cluster
A tabela a seguir mostra os diferentes métodos que você pode usar para configurar um cluster HDInsight.
| Clusters criados com | Navegador da Web | Linha de comando | API REST | . |
|---|---|---|---|---|
| Portal do Azure | ✅ | |||
| Azure Data Factory | ✅ | ✅ | ✅ | ✅ |
| CLI do Azure | ✅ | |||
| PowerShell do Azure | ✅ | |||
| Curl | ✅ | ✅ | ||
| Modelos do Gerenciador de Recursos do Azure | ✅ |
Este artigo o orienta pela configuração no portal do Azure, onde você pode criar um cluster HDInsight.
Noções básicas
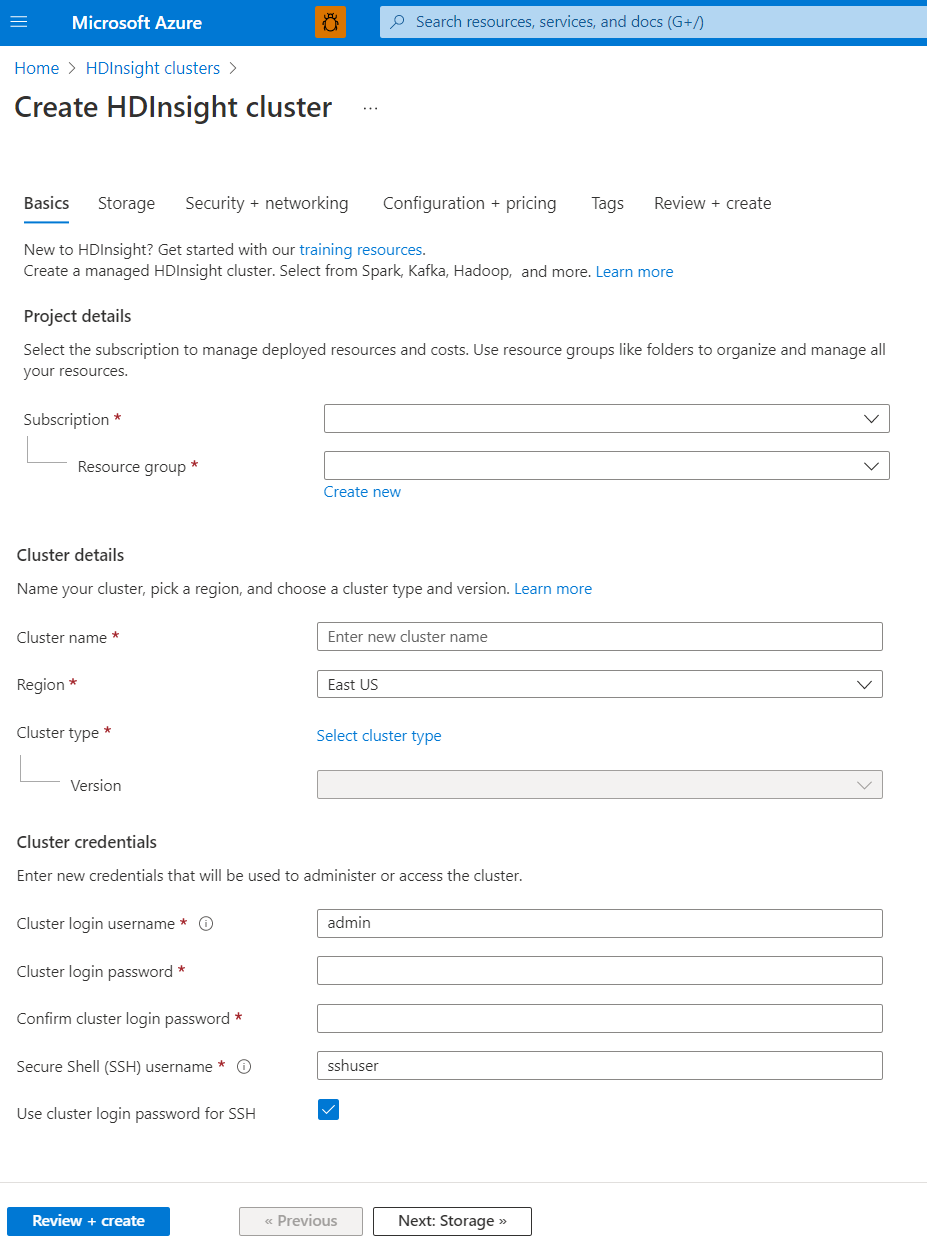
Detalhes do projeto
O Azure Resource Manager ajuda você a trabalhar com os recursos do aplicativo como um grupo, conhecido como um grupo de recursos do Azure. Você pode implantar, atualizar, monitorar ou excluir todos os recursos do seu aplicativo com uma única operação coordenada.
Detalhes do cluster
Os detalhes do cluster incluem o nome, a região, o tipo e a versão.
Nome do cluster
Os nomes de cluster HDInsight têm as seguintes restrições:
- Caracteres permitidos: a-z, 0-9 e A-Z
- Comprimento máximo: 59
- Nomes reservados: aplicativos
- Nomenclatura de cluster: o escopo é para todo o Azure, em todas as assinaturas. O nome do cluster deve ser exclusivo no mundo inteiro. Os primeiros seis caracteres devem ser exclusivos em uma rede virtual.
Region
Você não precisa especificar o local do cluster explicitamente. O cluster está no mesmo local que o armazenamento padrão. Para obter uma lista de regiões com suporte, selecione a lista suspensa Região em Preços do HDInsight.
Tipo de cluster
Na tabela a seguir, o HDInsight atualmente fornece os tipos de cluster, cada um com um conjunto de componentes para fornecer determinadas funcionalidades.
Importante
Clusters HDInsight estão disponíveis em vários tipos, cada um para uma carga de trabalho ou tecnologia distinta. Não há nenhum método com suporte para criar um cluster que combina vários tipos, como HBase em um cluster. Se sua solução exige tecnologias que sejam distribuídas entre vários tipos de cluster HDInsight, uma rede virtual do Azure pode conectar os tipos de cluster necessários.
| Tipo de cluster | Funcionalidade |
|---|---|
| Hadoop | Consulte de lote e análise de dados armazenados. |
| HBase | Processamento de grandes quantidades de dados NoSQL sem esquema. |
| Consulta Interativa | Caching na memória para consultas de Hive interativas e mais rápidas. |
| Kafka | Uma plataforma de streaming distribuída que você pode usar para compilar pipelines e aplicativos de dados de streaming em tempo real. |
| Spark | Processamento na memória, consultas interativas, processamento de transmissão de microlotes. |
Versão
Escolha a versão do HDInsight para este cluster. Para saber mais, confira Versões do HDInsight com suporte.
Credenciais do cluster
Com os clusters HDInsight, você pode configurar duas contas de usuário durante a criação de cluster:
- Nome de usuário de logon do cluster: o nome de usuário padrão é admin. Ele usa a configuração básica no portal do Azure. Também é chamado de Usuário do cluster ou Usuário HTTP.
- Nome de usuário do Secure Shell (SSH): usado para se conectar ao cluster por meio do SSH. Para obter mais informações, confira Usar SSH com HDInsight.
O nome de usuário HTTP tem as seguintes restrições:
- Caracteres especiais permitidos: _ e @
- Caracteres não permitidos: #;."',/:!*?$(){}[]<>|&--=+%~^espaço
- Comprimento máximo: 20
O nome de usuário SSH tem as seguintes restrições:
- Caracteres especiais permitidos: _ e @
- Caracteres não permitidos: #;."',/:!*?$(){}[]<>|&--=+%~^espaço
- Comprimento máximo: 64
- Nomes reservados: hadoop, users, oozie, hive, mapred, ambari-qa, zookeeper, tez, hdfs, sqoop, yarn, hcat, ams, hbase, administrator, admin, user, user1, test, user2, test1, user3, admin1, 1, 123, a, actuser, adm, admin2, aspnet, backup, console, David, guest, John, owner, root, server, sql, support, support_388945a0, sys, test2, test3, user4, user5, spark
Armazenamento
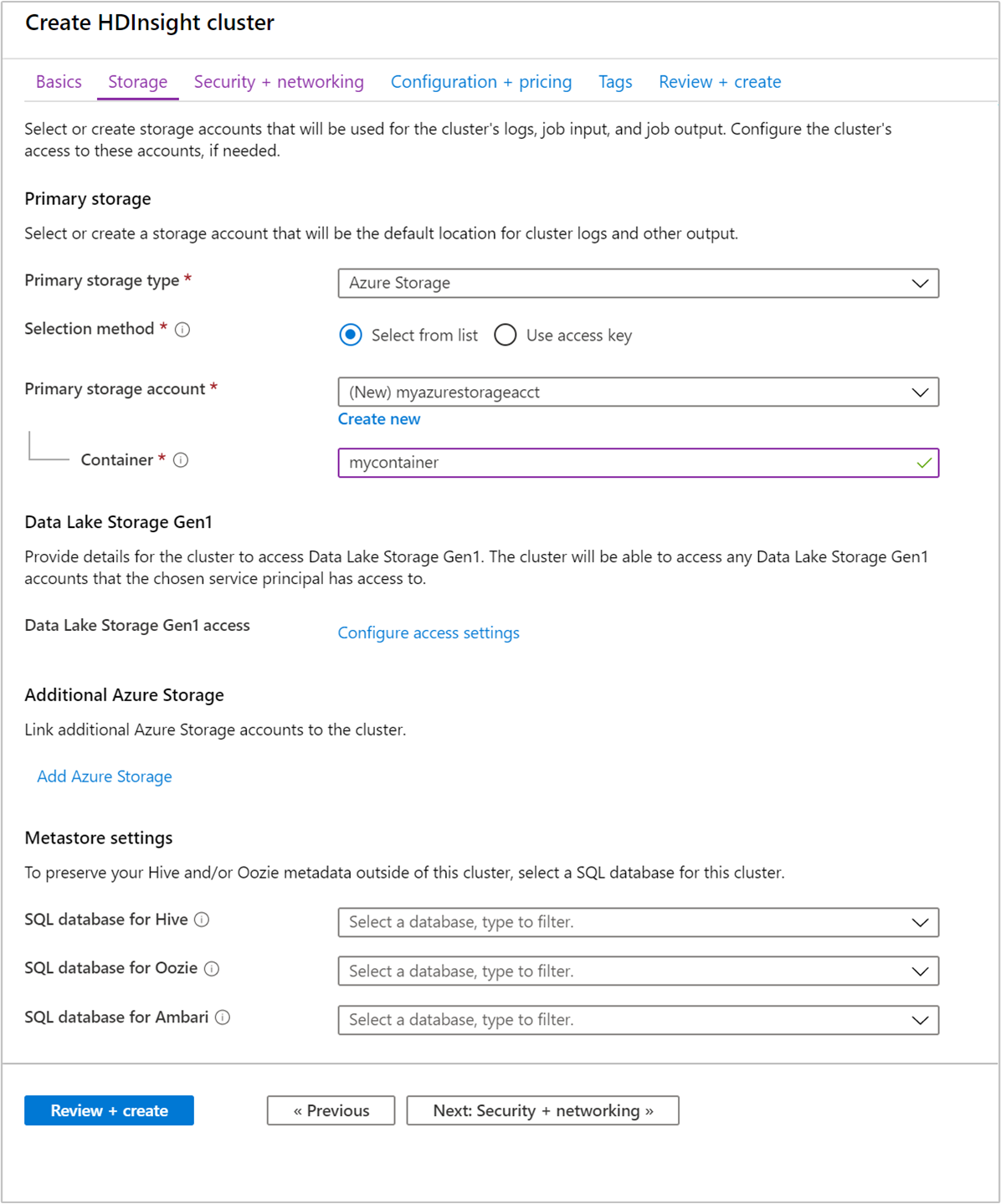
Embora uma instalação local do Hadoop usa o HDFS (Sistema de Arquivos Distribuído Hadoop) para armazenamento no cluster, na nuvem você usa pontos de extremidade de armazenamento conectados ao cluster. Usar o armazenamento em nuvem significa que você pode excluir com segurança os clusters HDInsight usados para computação, mantendo seus dados.
Os clusters HDInsight podem usar as seguintes opções de armazenamento:
- Azure Data Lake Storage Gen2
- Armazenamento do Microsoft Azure de Uso Geral v2
- Blob de blocos do Armazenamento do Microsoft Azure (com suporte apenas como armazenamento secundário)
Para obter mais informações sobre opções de armazenamento com o HDInsight, veja Comparar as opções de armazenamento para uso com clusters Azure HDInsight.
Não há suporte para o uso de mais contas de armazenamento em um local diferente do cluster HDInsight.
Durante a configuração, para o ponto de extremidade de armazenamento padrão, você especifica um contêiner de blob de uma conta de armazenamento ou Data Lake Storage. O armazenamento padrão contém os logs de aplicativo e de sistema. Opcionalmente, você pode especificar mais contas de armazenamento vinculadas e do Data Lake Storage que o cluster possa acessar. O cluster HDInsight e as contas de armazenamento padrão dependentes devem estar na mesma localização do Azure.
Observação
O recurso que exige transferência segura passa todas as solicitações para sua conta por uma conexão segura. Somente o cluster do HDInsight versão 3.6 ou mais recente oferece suporte a esse recurso. Para saber mais, confira Criar um cluster Apache Hadoop com contas de armazenamento para transferência segura no Azure HDInsight.
Não habilite a transferência de armazenamento seguro após a criação de um cluster, pois o uso da conta de armazenamento pode resultar em erros. É melhor criar um novo cluster usando uma conta de armazenamento com a transferência segura já habilitada.
O HDInsight não transfere, move ou copia automaticamente os dados armazenados no armazenamento de uma região para outra.
Configurações de metastore
Você pode criar metastores Hive ou Apache Oozie opcionais. Nem todos os tipos de cluster dão suporte a metastores e o Azure Synapse Analytics não é compatível com metastores.
Para obter mais informações, consulte Usar armazenamentos de metadados externos no Azure HDInsight.
Ao criar um metastore personalizado, não use traços, hifens ou espaços no nome do banco de dados. Esses caracteres podem causar falha no processo de criação do cluster.
Banco de dados SQL para Hive
Se você deseja reter suas tabelas Hive depois de excluir um cluster HDInsight, use uma metastore personalizada. Você poderá então anexar a metastore a outro cluster HDInsight.
Um metastore HDInsight criado para uma versão de cluster HDInsight não pode ser compartilhado entre diferentes versões de cluster HDInsight. Para obter uma lista das versões do HDInsight, consulte Versões do HDInsight com suporte.
Você pode usar identidades gerenciadas para autenticar com o banco de dados SQL para Hive. Para obter mais informações, consulte Usar identidade gerenciada para autenticação do Banco de Dados SQL no HDInsight.
O metastore padrão fornece um banco de dados SQL com um limite de DTU básico de camada 5 (não atualizável). Ele é adequado para fins de testes básicos. Para cargas de trabalho grandes ou de produção, é recomendável migrar para um metastore externo.
Banco de dados SQL para Oozie
Para aumentar o desempenho durante o uso do Oozie, use um metastore personalizado. Uma metastore também pode fornecer acesso a dados de trabalho do Oozie depois de você excluir o cluster.
Você pode usar identidades gerenciadas para autenticar com o banco de dados SQL para Oozie. Para obter mais informações, consulte Usar identidade gerenciada para autenticação do Banco de Dados SQL no HDInsight.
Banco de dados SQL para Ambari
O Ambari é usado para monitorar clusters HDInsight, fazer alterações de configuração e armazenar informações de gerenciamento de cluster e o histórico de trabalhos. Com o recurso de banco de dados personalizado do Ambari, você pode implantar um novo cluster e configurar o Ambari em um banco de dados externo gerenciado por você. Para obter mais informações, consulte Banco de dados personalizado do Ambari.
Você pode usar identidades gerenciadas para autenticar com o banco de dados SQL para Ambari. Para obter mais informações, consulte Usar identidade gerenciada para autenticação do Banco de Dados SQL no HDInsight.
Não é possível reutilizar um metastore personalizado do Oozie. Para usar um metastore personalizado do Oozie, você deve fornecer um banco de dados SQL vazio ao criar o cluster HDInsight.
Segurança + rede
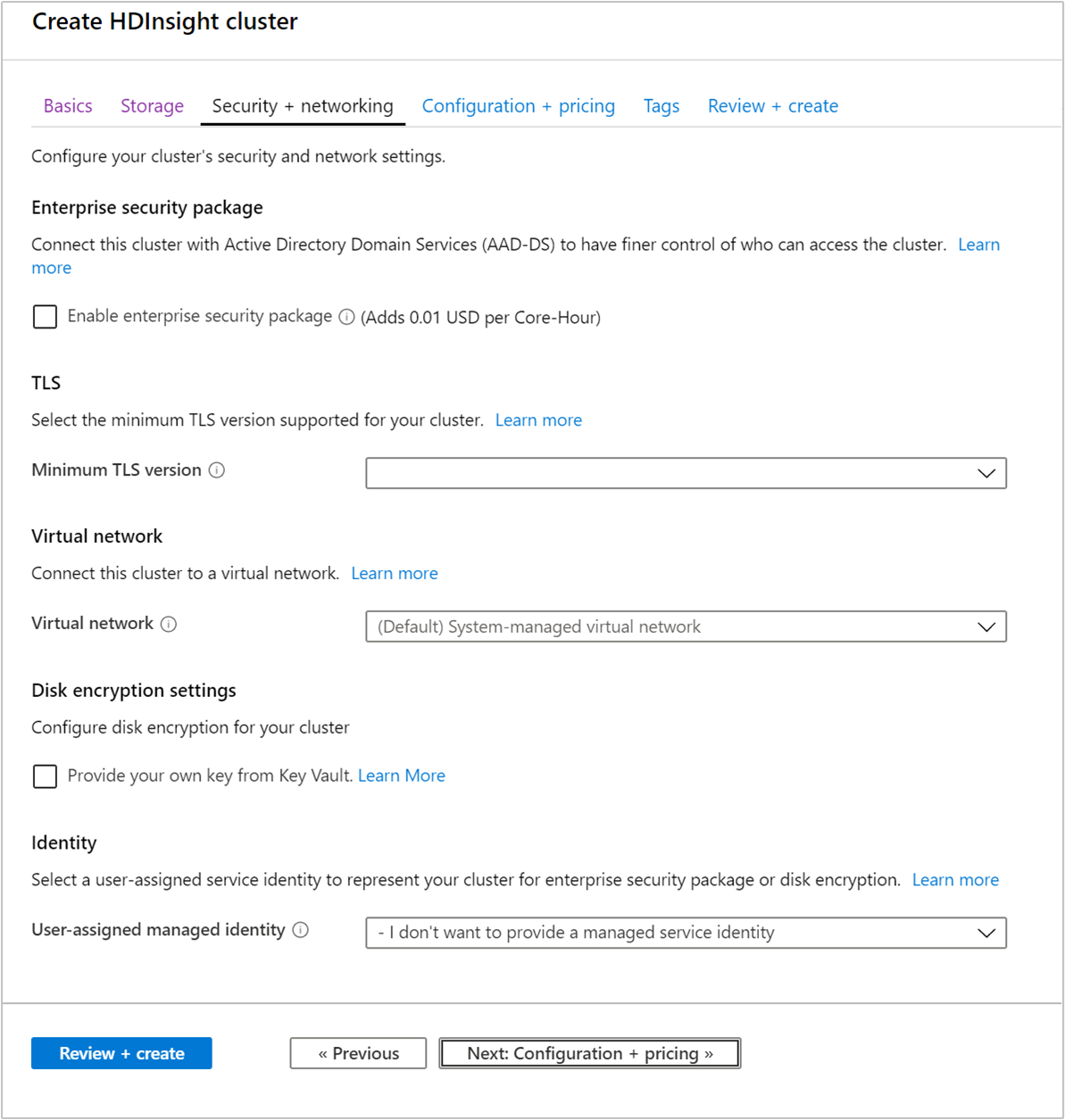
Pacote de segurança empresarial
Para tipos de cluster Hadoop, Spark, HBase, Kafka e Interactive Query, você pode optar por habilitar o Enterprise Security Package. Esse pacote fornece a opção de ter uma configuração de cluster mais segura usando o Apache Range e integrando com o Microsoft Entra. Para obter mais informações, veja Visão geral do Enterprise Security no Azure HDInsight.
Com o Enterprise Security Package, você pode integrar o HDInsight com o Microsoft Entra e o Apache Ranger. Você pode usar o Enterprise Security Package para criar vários usuários.
Para obter mais informações sobre como criar um cluster HDInsight conectado domínio, consulte Criar ambiente de área restrita do HDInsight conectado ao domínio.
Protocolo TLS
Para obter mais informações, confira Protocolo TLS.
Rede virtual
Se sua solução exige tecnologias que sejam distribuídas entre vários tipos de cluster HDInsight, uma rede virtual do Azure pode conectar os tipos de cluster necessários. Essa configuração permite que os clusters e qualquer código que você implantar neles se comuniquem diretamente uns com os outros.
Para obter mais informações sobre como usar uma rede virtual do Azure com HDInsight, veja Planejar uma rede virtual para HDInsight.
Para obter um exemplo de como usar dois tipos de cluster em uma rede virtual do Azure, confira Usar Streaming Estruturado do Apache Spark com o Apache Kafka. Para obter mais informações sobre como usar o HDInsight com uma rede virtual, incluindo requisitos de configuração específicos para a rede virtual, veja Planejar uma rede virtual para HDInsight.
Configurações de criptografia de disco
Para obter mais informações, confira Criptografia de disco de chave gerenciada pelo cliente.
Proxy REST do Kafka
Essa configuração está disponível apenas para o tipo de cluster Kafka. Para obter mais informações, consulte Usar um proxy REST.
Identidade
Para obter mais informações, veja Identidades gerenciadas no Azure HDInsight.
Configuração + preço
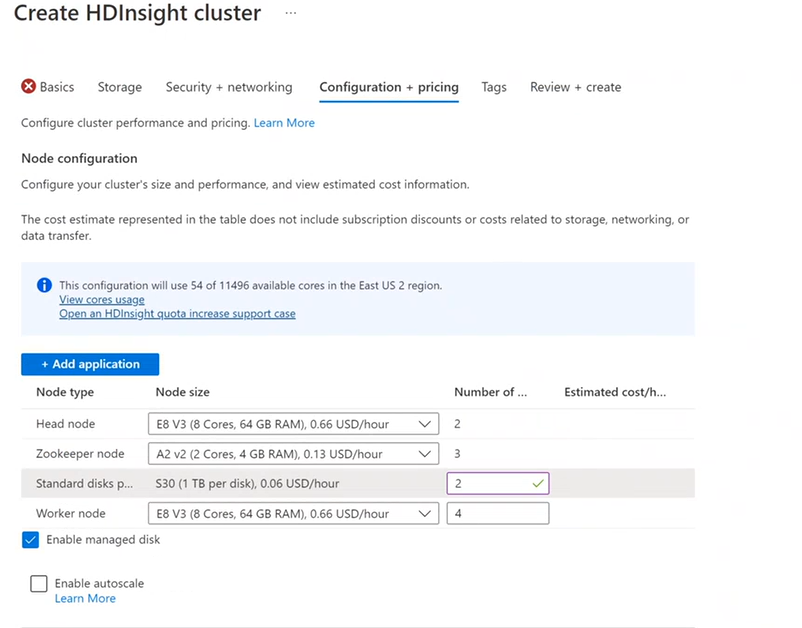
Você é cobrado pelo uso do nó enquanto o cluster existir. A cobrança é iniciada quando um cluster é criado e para quando o cluster é excluído. Os clusters não podem ser desalocados ou colocados em espera.
Configuração do nó
Cada tipo de cluster tem seu próprio número de nós, terminologia para nós no cluster e tamanho da VM padrão. Na tabela a seguir, o número de nós para cada tipo de nó está listado entre parênteses.
| Tipo | Nós | Diagrama |
|---|---|---|
| O Hadoop | Nó de Cabeçalho (2), Nó de Trabalho (1+) |
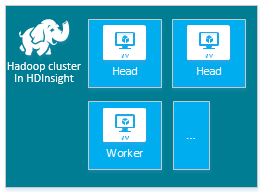
|
| HBase | Servidor principal (2), servidor de região (1+), nó mestre/do ZooKeeper (3) |
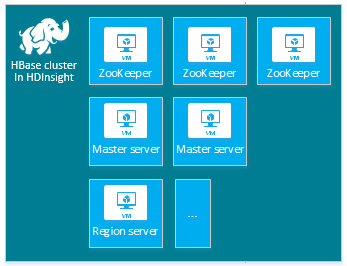
|
| Spark | Nó de cabeçalho (2), Nó de trabalho (1+), Nó do ZooKeeper (3) (gratuito para tamanho de VM A1 do ZooKeeper) |
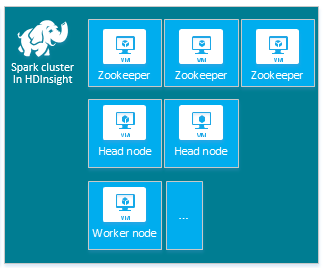
|
Para obter mais informações, consulte Configuração de nó padrão e tamanhos de VM para clusters.
O custo de clusters HDInsight determinado pelo número de nós e pelos tamanhos de VM para os nós.
Diferentes tipos de cluster têm diferentes tipos de nó, números de nós e tamanhos de nós:
Padrão de tipo de cluster Hadoop:
- Dois nós de cabeçalho
- Quatro nós de trabalho
Se você estiver experimentando o HDInsight, recomenda-se o uso de um nó de trabalho. Para obter mais informações sobre os preços do HDInsight, confira Preços do HDInsight.
Observação
O limite de tamanho do cluster varia entre as assinaturas do Azure. Contate o suporte de cobrança do Azure para aumentar o limite.
Quando você usa o portal do Azure para configurar o cluster, o tamanho do nó está disponível por meio da guia Configuração + preço. No portal, você também pode ver o custo associado aos diferentes tamanhos de nó.
Tamanhos de máquina virtual
Quando você implanta clusters, escolha os recursos de computação com base na solução que você planeja implantar. As VMs a seguir são usadas para clusters HDInsight:
- VMs A e série D1-4: Tamanhos de VM Linux de uso geral
- VM série D11-14: Tamanhos de VM Linux com otimização de memória
Para descobrir qual valor você deve usar para especificar um tamanho de VM ao criar um cluster usando os diferentes SDKs ou o Azure PowerShell, consulte Tamanhos de VM a serem usados para clusters HDInsight. Deste artigo vinculado, use o valor na coluna tamanho das tabelas.
Importante
Se você precisa de mais de 32 nós de trabalho em um cluster, você precisa selecionar um tamanho de nó de cabeçalho com pelo menos 8 núcleos e 14 GB de RAM.
Para obter mais informações, consulte Tamanhos das VMs. Para obter informações sobre os preços dos vários tamanhos, confira Preços do HDInsight.
Anexo de disco
Observação
Os discos adicionados são configurados apenas para diretórios locais do gerenciador de nós e não para diretórios de datanodes.
Um clusters HDInsight vem com espaço em disco predefinido com base na versão. A execução de alguns aplicativos grandes pode resultar em espaço em disco insuficiente, com erro de disco cheio LinkId=221672#ERROR_NOT_ENOUGH_DISK_SPACE e falhas de trabalho.
Você pode adicionar mais discos ao cluster usando o novo recurso de diretório local NodeManager. No momento da criação do cluster Hive e Spark, você pode selecionar o número de discos e adicioná-los aos nós de trabalho. Os discos selecionados podem ter 1 TB cada e fazem parte de diretórios locais NodeManager.
- Na guia Configuração + preço, selecione Habilitar disco gerenciado.
- Em Discos Standard, insira o número de discos.
- Selecione o nó de trabalho.
Você pode verificar o número de discos na guia Examinar + criar, em Configuração do cluster.
Adicionar aplicativo
É possível instalar aplicativos HDInsight em um cluster HDInsight baseado em Linux. Você pode usar aplicativos fornecidos pela Microsoft ou terceiros ou desenvolvidos por você. Para saber mais, confira Instalar aplicativos de terceiros do Apache Hadoop no Azure HDInsight.
A maioria dos aplicativos HDInsight é instalada em um nó de borda vazia. Um nó de borda vazio é uma VM do Linux com as mesmas ferramentas de cliente instaladas e configuradas do nó principal. Você pode usar o nó de borda para acessar o cluster, testar e hospedar seus aplicativos clientes. Para saber mais, confira Usar nós de borda vazia no HDInsight.
Ações de script
Você pode instalar mais componentes ou personalizar a configuração de cluster por meio de scripts durante a criação. Tais scripts são invocados por meio de ações de script, que é uma opção de configuração que pode ser usada no portal do Azure, nos cmdlets do Windows PowerShell do HDInsight ou no SDK do .NET do HDInsight. Para obter mais informações, consulte Personalizar o cluster HDInsight usando ações de script.
Alguns componentes nativos do Java, como Apache Mahout e Cascading, pode ser executados no cluster como arquivos Java Archive (JAR). Você pode distribuir esses arquivos JAR para o armazenamento e enviá-los aos clusters HDInsight por meio de mecanismos de envio de trabalho do Hadoop. Para obter mais informações, consulte Enviar Apache trabalhos do Hadoop por meio de programação.
Observação
Se você tiver problemas para implantar arquivos JAR nos clusters do HDInsight ou ao chamar arquivos JAR nesses clusters, entre em contato com o Suporte da Microsoft.
O HDInsight não dá suporte a Cascading e não é qualificado para o Suporte da Microsoft. Para obter as listas dos componentes suportados, confira Novidades nas versões de cluster fornecidas pelo HDInsight.
Às vezes, você deseja definir os seguintes arquivos de configuração durante o processo de criação:
- clusterIdentity.xml
- core-site.xml
- gateway.xml
- hbase-env.xml
- hbase-site.xml
- hdfs-site.xml
- hive-env.xml
- hive-site.xml
- mapred-site
- oozie-site.xml
- oozie-env.xml
- tez-site.xml
- webhcat-site.xml
- yarn-site.xml
Para saber mais, confira Personalizar clusters HDInsight usando a Inicialização.