Rozruch maszyny wirtualnej z systemem Linux platformy Azure kończy się niepowodzeniem po zastosowaniu zmian jądra
Dotyczy: ✔️ maszyny wirtualne z systemem Linux
Uwaga 16.
CentOS, do których odwołuje się ten artykuł, jest dystrybucją systemu Linux i osiągnie koniec życia (EOL). Rozważ odpowiednie użycie i zaplanuj. Aby uzyskać więcej informacji, zobacz CentOS End Of Life guidance (Wskazówki dotyczące zakończenia życia systemu CentOS).
Ten artykuł zawiera rozwiązania problemu, w którym maszyna wirtualna z systemem Linux nie może uruchomić się po zastosowaniu zmian jądra.
Wymagania wstępne
Upewnij się, że konsola szeregowa jest włączona i funkcjonalna na maszynie wirtualnej z systemem Linux.
Jak zidentyfikować problem z rozruchem powiązanym z jądrem
Aby zidentyfikować problem z rozruchem związany z jądrem, sprawdź określony ciąg paniki jądra. W tym celu użyj interfejsu wiersza polecenia platformy Azure lub witryny Azure Portal, aby wyświetlić dane wyjściowe dziennika konsoli szeregowej maszyny wirtualnej w okienku diagnostyki rozruchu lub okienku konsoli szeregowej.
Panika jądra wygląda podobnie do następujących danych wyjściowych i zostanie wyświetlona na końcu dziennika konsoli szeregowej:
Probing EDD (edd=off to disable)... ok
Memory KASLR using RDRAND RDTSC...
[ 300.206297] Kernel panic - xxxxxxxx
[ 300.207216] CPU: 1 PID: 1 Comm: swapper/0 Tainted: G ------------ T 3.xxx.x86_64 #1
Rozwiązywanie problemów w trybie online
Napiwek
Jeśli masz najnowszą kopię zapasową maszyny wirtualnej, przywróć maszynę wirtualną z kopii zapasowej, aby rozwiązać problem z rozruchem.
Konsola szeregowa jest najszybszą metodą rozwiązania problemu z rozruchem. Umożliwia bezpośrednie rozwiązanie problemu bez konieczności prezentowania dysku systemowego na maszynie wirtualnej odzyskiwania. Upewnij się, że spełniasz niezbędne wymagania wstępne dotyczące dystrybucji. Aby uzyskać więcej informacji, zobacz Konsola szeregowa maszyny wirtualnej dla systemu Linux.
Zidentyfikuj konkretny problem z rozruchem powiązanym z jądrem.
Użyj konsoli szeregowej platformy Azure, aby przerwać maszynę wirtualną w menu GRUB i wybrać poprzednie jądro, aby go uruchomić. Aby uzyskać więcej informacji, zobacz Rozruch systemu w starszej wersji jądra.
Przejdź do odpowiedniej sekcji, aby rozwiązać problem z rozruchem powiązanym z jądrem:
Po rozwiązaniu problemu z rozruchem związanym z jądrem uruchom ponownie maszynę wirtualną, aby mogła zostać uruchomiona w najnowszej wersji jądra.
Rozwiązywanie problemów w trybie offline
Napiwek
Jeśli masz najnowszą kopię zapasową maszyny wirtualnej, przywróć maszynę wirtualną z kopii zapasowej, aby rozwiązać problem z rozruchem.
Jeśli konsola szeregowa platformy Azure nie działa na określonej maszynie wirtualnej lub nie jest opcją w subskrypcji, rozwiąż problem z rozruchem przy użyciu maszyny wirtualnej ratowniczej/naprawy. W tym celu wykonaj następujące kroki:
Użyj poleceń naprawy maszyny wirtualnej, aby utworzyć maszynę wirtualną naprawy, która ma kopię dołączonego dysku systemu operacyjnego maszyny wirtualnej, której dotyczy problem. Zainstaluj kopię systemów plików systemu operacyjnego na maszynie wirtualnej naprawy przy użyciu katalogu chroot.
Uwaga 16.
Alternatywnie możesz ręcznie utworzyć ratunkową maszynę wirtualną przy użyciu witryny Azure Portal. Aby uzyskać więcej informacji, zobacz Rozwiązywanie problemów z maszyną wirtualną z systemem Linux przez dołączenie dysku systemu operacyjnego do maszyny wirtualnej odzyskiwania przy użyciu witryny Azure Portal.
Zidentyfikuj konkretny problem z rozruchem powiązanym z jądrem.
Przejdź do odpowiedniej sekcji, aby rozwiązać problem z rozruchem powiązanym z jądrem:
Po rozwiązaniu problemu z rozruchem związanym z jądrem wykonaj następujące czynności:
- Zamknij plik chroot.
- Odinstalowywanie kopii systemów plików z maszyny wirtualnej ratownictwa/naprawy.
- Uruchom polecenie ,
az vm repair restoreaby zamienić naprawiony dysk systemu operacyjnego na oryginalny dysk systemu operacyjnego maszyny wirtualnej. Aby uzyskać więcej informacji, zobacz Krok 5 w temacie Naprawianie maszyny wirtualnej z systemem Linux przy użyciu poleceń naprawy maszyny wirtualnej platformy Azure. - Sprawdź, czy maszyna wirtualna może uruchomić się, przeglądając konsolę szeregową platformy Azure lub próbując nawiązać połączenie z maszyną wirtualną.
Jeśli brakuje ważnej zawartości związanej z jądrem, brakuje całej
/bootpartycji lub innej ważnej zawartości i nie można ich odzyskać, zalecamy przywrócenie maszyny wirtualnej z kopii zapasowej. Aby uzyskać więcej informacji, zobacz Jak przywrócić dane maszyny wirtualnej platformy Azure w witrynie Azure Portal.
System rozruchowy w starszej wersji jądra
Korzystanie z konsoli szeregowej platformy Azure
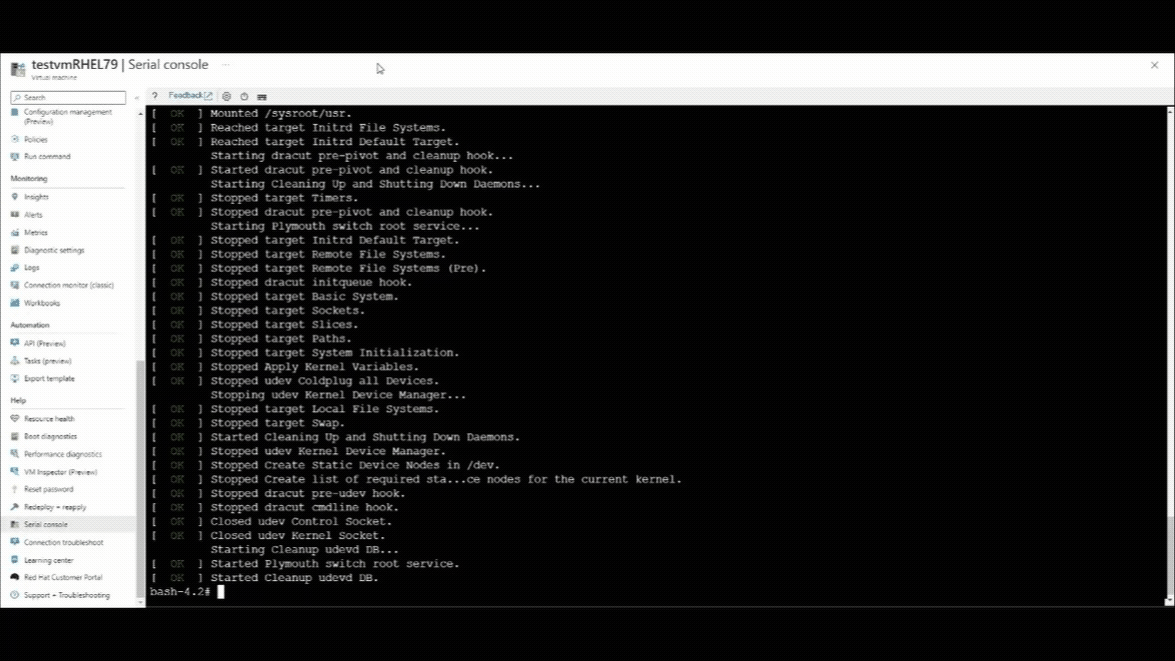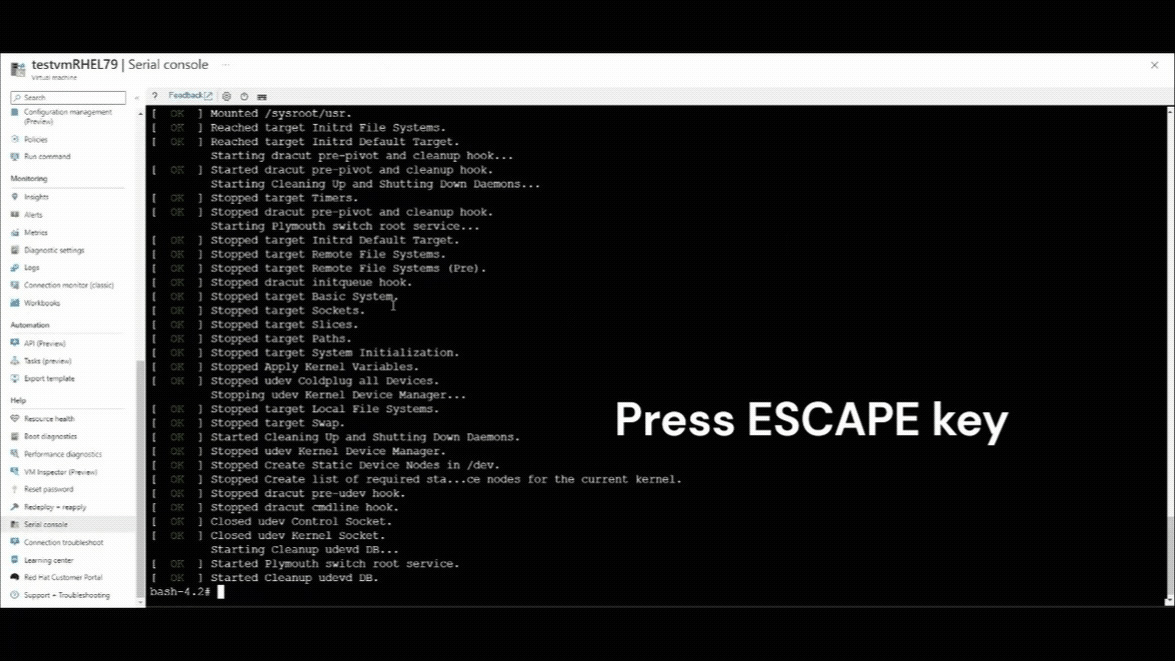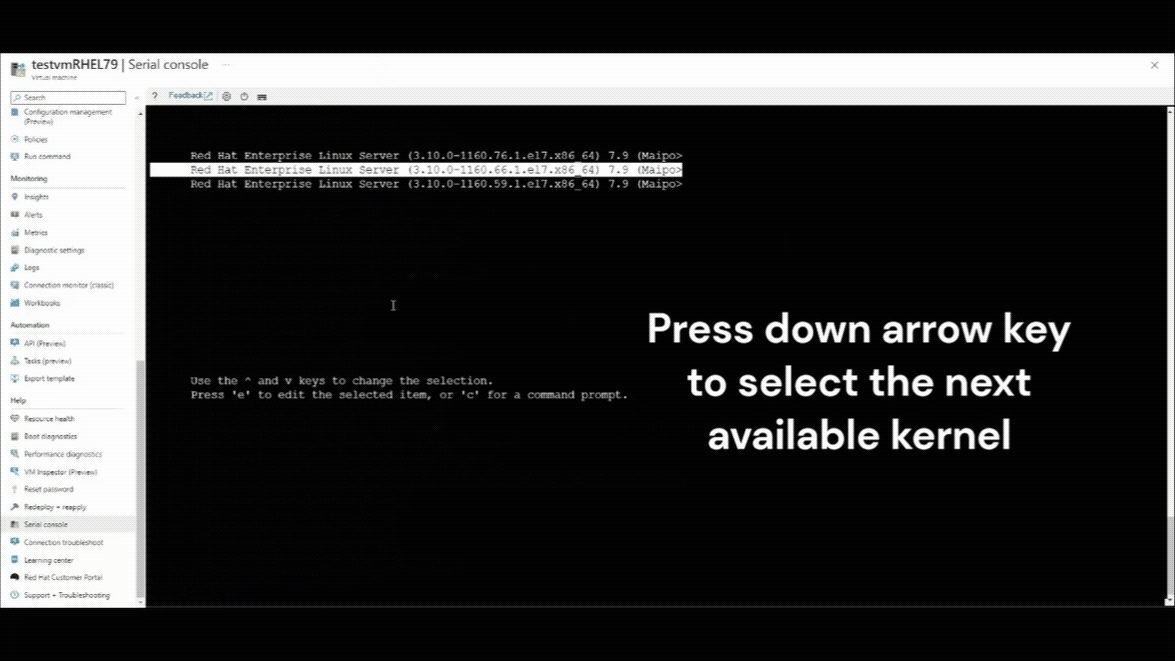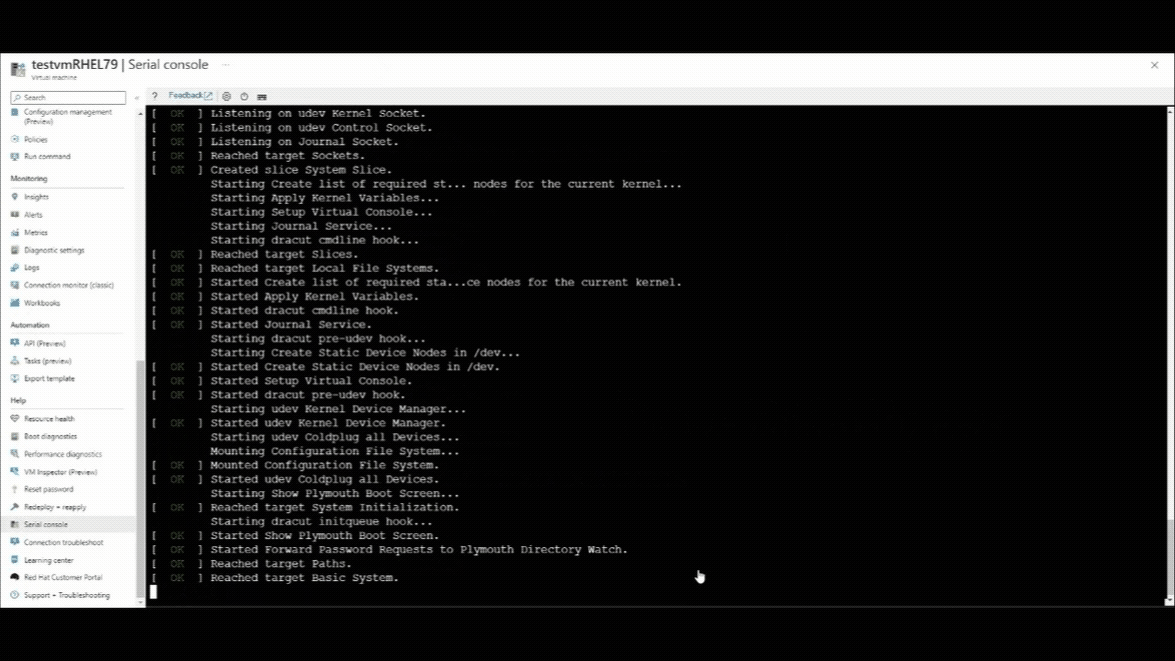
Uruchom ponownie maszynę wirtualną przy użyciu konsoli szeregowej platformy Azure.
- Wybierz przycisk zamykania w górnej części okna konsoli szeregowej.
- Wybierz opcję Uruchom ponownie maszynę wirtualną (hard).
Po wznowieniu połączenia konsoli szeregowej w lewym górnym rogu okna konsoli szeregowej zobaczysz licznik odliczania. Naciśnij ESCAPE, aby przerwać maszynę wirtualną w menu GRUB.
Naciśnij strzałki w dół, aby wybrać dowolną poprzednią wersję jądra.
Zmień zmienną
GRUB_DEFAULTw pliku /etc/default/grub zgodnie z instrukcją w temacie Ręczne zmienianie domyślnej wersji jądra. Jest to trwała zmiana.

Uwaga 16.
Jeśli w menu GRUB jest wyświetlana tylko jedna wersja jądra, postępuj zgodnie z podejściem do rozwiązywania problemów w trybie offline, aby rozwiązać ten problem z maszyny wirtualnej naprawy.
Używanie naprawy maszyny wirtualnej (skrypty ALAR)
Uruchom następujące polecenie powłoki bash w usłudze Azure Cloud Shell, aby utworzyć naprawę maszyny wirtualnej. Aby uzyskać więcej informacji, zobacz Używanie usługi Azure Linux Auto Repair (ALAR) do naprawienia maszyny wirtualnej z systemem Linux — jądra.
az vm repair create --verbose -g $RGNAME -n $VMNAME --repair-username rescue --repair-password 'password!234' --copy-disk-name repairdiskcopyUruchom następujące polecenie, aby zastąpić uszkodzone jądro wcześniej zainstalowaną wersją:
az vm repair run --verbose -g $RGNAME -n $VMNAME --run-id linux-alar2 --parameters kernel --run-on-repair az vm repair restore --verbose -g $RGNAME -n $VMNAME
Uwaga 16.
Jeśli w systemie jest zainstalowana tylko jedna wersja jądra, postępuj zgodnie z podejściem rozwiązywania problemów w trybie offline, aby rozwiązać ten problem z maszyny wirtualnej naprawy.
Ręczne zmienianie domyślnej wersji jądra
Aby zmodyfikować domyślną wersję jądra z maszyny wirtualnej naprawy (wewnątrz katalogu chroot) lub na uruchomionej maszynie wirtualnej, wykonaj następujące kroki:
Uwaga 16.
Jeśli wycofanie jądra na starszą wersję jest wykonywane, wybierz najnowszą wersję jądra zamiast starszej.
RHEL 7, Oracle Linux 7 i CentOS 7
Zweryfikuj listę dostępnych jąder w pliku konfiguracji GRUB, uruchamiając jedno z następujących poleceń:
Maszyny wirtualne gen1:
cat /boot/grub2/grub.cfg | grep menuentryMaszyny wirtualne gen2:
cat /boot/efi/EFI/*/grub.cfg | grep menuentry
Ustaw nowe domyślne jądro i określ odpowiedni tytuł jądra, uruchamiając następujące polecenie:
# grub2-set-default 'Red Hat Enterprise Linux Server, with Linux 3.10.0-123.el7.x86_64'Uwaga 16.
Zastąp
Red Hat Enterprise Linux Server, with Linux 3.10.0-123.el7.x86_64element odpowiednim tytułem wpisu menu.Sprawdź, czy nowe domyślne jądro jest żądane, uruchamiając następujące polecenie:
grub2-editenv listUpewnij się, że wartość zmiennej
GRUB_DEFAULTw pliku /etc/default/grub jest ustawiona nasavedwartość . Aby go zmodyfikować, upewnij się, że ponownie wygenerowany plik konfiguracji GRUB w celu zastosowania zmian.
RHEL 8/9 i CentOS 8
Wyświetl listę dostępnych jąder, uruchamiając następujące polecenie:
ls -l /boot/vmlinuz-*Ustaw nowe domyślne jądro, uruchamiając następujące polecenie:
grubby --set-default /boot/vmlinuz-4.18.0-372.19.1.el8_6.x86_64Uwaga 16.
Zastąp
4.18.0-372.19.1.el8_6.x86_64element odpowiednią wersją jądra.Sprawdź, czy nowe domyślne jądro jest żądane, uruchamiając następujące polecenie:
grubby --default-kernel
SLES 12/15, Ubuntu 18.04/20.04
Wyświetl listę dostępnych jąder w pliku konfiguracji GRUB, uruchamiając następujące polecenie:
Maszyny wirtualne gen1:
SLES 12/15:
cat /boot/grub2/grub.cfg | grep menuentryUbuntu 18.04/20.04:
cat /boot/grub/grub.cfg | grep menuentry
Maszyny wirtualne gen2:
cat /boot/efi/EFI/*/grub.cfg | grep menuentry
Ustaw nowe domyślne jądro, modyfikując wartość
GRUB_DEFAULTzmiennej w pliku /etc/default/grub . W przypadku najnowszej wersji jądra zainstalowanej w systemie wartość domyślna to 0. Następne dostępne jądro ma wartość "1>2".vi /etc/default/grub GRUB_DEFAULT="1>2"Uwaga 16.
Aby uzyskać więcej informacji na temat konfigurowania zmiennej
GRUB_DEFAULT, zobacz Moduł ładujący rozruchu SUSE GRUB2 i Ubuntu Grub2/Setup. Jako odwołanie: wartość menu najwyższego poziomu wynosi 0, pierwsza wartość podmenu najwyższego poziomu to 1, a każda zagnieżdżona wartość menu zaczyna się od 0. Na przykład "1>2" to trzecie menu z pierwszego podmenu.Wygeneruj ponownie plik konfiguracji GRUB, aby zastosować zmiany. Postępuj zgodnie z instrukcjami w artykule Ponowne instalowanie pliku konfiguracji GRUB i ponowne generowanie kodu GRUB dla odpowiedniej dystrybucji systemu Linux i generowania maszyn wirtualnych.
Panika jądra — brak synchronizacji: VFS: Nie można zainstalować katalogu głównego fs na nieznanym bloku (0,0)
Ten błąd występuje z powodu niedawnej aktualizacji systemu (jądra). Jest to najczęściej spotykane w dystrybucjach opartych na systemie RHEL. Ten problem można zidentyfikować w konsoli szeregowej platformy Azure. Zobaczysz dowolny z następujących komunikatów o błędach:
"Panika jądra — brak synchronizacji: VFS: Nie można zainstalować katalogu głównego fs na nieznanym bloku(0,0)"
[ 301.026129] Kernel panic - not syncing: VFS: Unable to mount root fs on unknown-block(0,0) [ 301.027122] CPU: 0 PID: 1 Comm: swapper/0 Tainted: G ------------ T 3.10.0-1160.36.2.el7.x86_64 #1 [ 301.027122] Hardware name: Microsoft Corporation Virtual Machine/Virtual Machine, BIOS 090008 12/07/2018 [ 301.027122] Call Trace: [ 301.027122] [<ffffffff82383559>] dump_stack+0x19/0x1b [ 301.027122] [<ffffffff8237d261>] panic+0xe8/0x21f [ 301.027122] [<ffffffff8298b794>] mount_block_root+0x291/0x2a0 [ 301.027122] [<ffffffff8298b7f6>] mount_root+0x53/0x56 [ 301.027122] [<ffffffff8298b935>] prepare_namespace+0x13c/0x174 [ 301.027122] [<ffffffff8298b412>] kernel_init_freeable+0x222/0x249 [ 301.027122] [<ffffffff8298ab28>] ? initcall_blcklist+0xb0/0xb0 [ 301.027122] [<ffffffff82372350>] ? rest_init+0x80/0x80 [ 301.027122] [<ffffffff8237235e>] kernel_init+0xe/0x100 [ 301.027122] [<ffffffff82395df7>] ret_from_fork_nospec_begin+0x21/0x21 [ 301.027122] [<ffffffff82372350>] ? rest_init+0x80/0x80 [ 301.027122] Kernel Offset: 0xc00000 from 0xffffffff81000000 (relocation range: 0xffffffff80000000-0xffffffffbfffffff)"błąd: nie znaleziono pliku '/initramfs-*.img'"
błąd: nie znaleziono pliku "/initramfs-3.10.0-1160.36.2.el7.x86_64.img".
Ten rodzaj błędu wskazuje, że plik initramfs nie jest generowany, plik konfiguracji GRUB ma brak wpisu initrd po procesie stosowania poprawek lub błędną konfigurację ręczną GRUB.
Przed ponownym uruchomieniem serwera zalecamy zweryfikowanie konfiguracji i /boot zawartości programu GRUB, jeśli istnieje aktualizacja jądra, uruchamiając jedno z następujących poleceń. Ważne jest, aby upewnić się, że aktualizacja jest wykonywana i nie ma brakujących plików initramfs.
System BIOS — systemy Gen1
# ls -l /boot # cat /boot/grub2/grub.cfgOparte na interfejsie UEFI — systemy Gen2
# ls -l /boot # cat /boot/efi/EFI/*/grub.cfg
Ponowne generowanie brakujących initramfs przy użyciu skryptów ALAR maszyny wirtualnej naprawy platformy Azure
Utwórz maszynę wirtualną naprawy, uruchamiając następujący wiersz polecenia powłoki Bash w usłudze Azure Cloud Shell. Aby uzyskać więcej informacji, zobacz Używanie automatycznej naprawy systemu Linux (ALAR) platformy Azure w celu naprawienia maszyny wirtualnej z systemem Linux — initrd opcji.
az vm repair create --verbose -g $RGNAME -n $VMNAME --repair-username rescue --repair-password 'password!234' --copy-disk-name repairdiskcopyWygeneruj ponownie obraz initrd/initramfs i ponownie wygeneruj plik konfiguracji GRUB, jeśli brakuje initrd wpisu. Aby to zrobić, uruchom następujące polecenie:
az vm repair run --verbose -g $RGNAME -n $VMNAME --run-id linux-alar2 --parameters initrd --run-on-repair az vm repair restore --verbose -g $RGNAME -n $VMNAMEPo wykonaniu polecenia przywracania uruchom ponownie oryginalną maszynę wirtualną i sprawdź, czy można go uruchomić.
Ponowne generowanie brakujących initramfs ręcznie
Ważne
- Jeśli możesz uruchomić maszynę wirtualną przy użyciu poprzedniej wersji jądra lub wewnątrz katalogu głównego z maszyny wirtualnej naprawy/ratownictwa, ponownie wygeneruj brakujące initramfs ręcznie.
- Aby ponownie wygenerować brakujące initramfs ręcznie z maszyny wirtualnej naprawy, upewnij się, że krok 1 w rozwiązywaniu problemów w trybie offline został już wykonany, a te polecenia są wykonywane wewnątrz katalogu chroot.
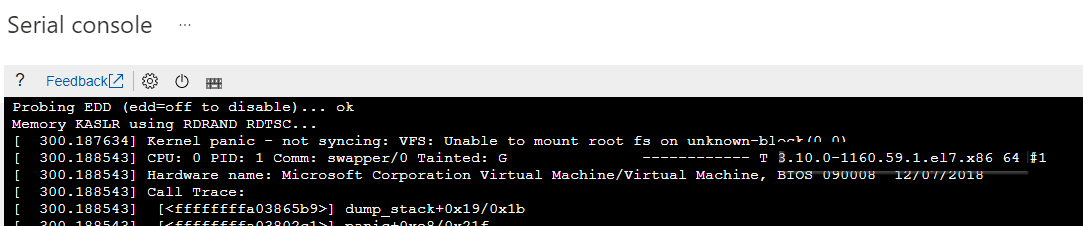
Zidentyfikuj określoną wersję jądra, która ma problemy z rozruchem. Informacje o wersji można wyodrębnić z odpowiedniego błędu paniki jądra.
Zapoznaj się z poniższym zrzutem ekranu jako przykładem. Błąd paniki jądra pokazuje, że wersja jądra to "3.10.0-1160.59.1.el7.x86_64":
Wygeneruj ponownie brakujący plik initramfs, uruchamiając jedno z następujących poleceń:
RHEL/CentOS/Oracle Linux 7/8
sudo depmod -a 3.10.0-1160.59.1.el7.x86_64 sudo dracut -f /boot/initramfs-3.10.0-1160.59.1.el7.x86_64.img 3.10.0-1160.59.1.el7.x86_64Ważne
Zastąp
3.10.0-1160.59.1.el7.x86_64element odpowiednią wersją jądra.SLES 12/15
sudo depmod -a 5.3.18-150300.38.53-azure sudo dracut -f /boot/initrd-5.3.18-150300.38.53-azure 5.3.18-150300.38.53-azureWażne
Zastąp
5.3.18-150300.38.53-azureelement odpowiednią wersją jądra.Ubuntu 18.04
sudo depmod -a 5.4.0-1077-azure sudo mkinitramfs -k -o /boot/initrd.img-5.4.0-1077-azureWażne
Zastąp
5.4.0-1077-azureelement odpowiednią wersją jądra.
Wygeneruj ponownie plik konfiguracji GRUB. Postępuj zgodnie z instrukcjami w temacie Ponowne instalowanie pliku konfiguracji GRUB i ponowne generowanie kodu GRUB dla odpowiedniej dystrybucji systemu Linux i generowania maszyn wirtualnych
Jeśli powyższe kroki są wykonywane z maszyny wirtualnej naprawy, wykonaj krok 3 w temacie Rozwiązywanie problemów w trybie offline. Jeśli powyższe kroki są wykonywane z konsoli szeregowej platformy Azure, postępuj zgodnie z metodą rozwiązywania problemów online.
Uruchom ponownie maszynę wirtualną w najnowszej wersji jądra.
Panika jądra — brak synchronizacji: podjęto próbę zabicia init
Zidentyfikuj ten problem z konsoli szeregowej platformy Azure. Zostaną wyświetlone dane wyjściowe podobne do następujących:
dracut Warning: Boot has failed. To debug this issue add "rdshell" to the kernel command line.
Kernel panic - not syncing: Attempted to kill init!
Pid: 1, comm: init Not tainted 2.6.32-754.17.1.el6.x86_64 #1
Call Trace:
[<ffffffff81558bfa>] ? panic+0xa7/0x18b
[<ffffffff81130370>] ? perf_event_exit_task+0xc0/0x340
[<ffffffff81086433>] ? do_exit+0x853/0x860
[<ffffffff811a33b5>] ? fput+0x25/0x30
[<ffffffff81564272>] ? system_call_after_swapgs+0xa2/0x152
[<ffffffff81086498>] ? do_group_exit+0x58/0xd0
[<ffffffff81086527>] ? sys_exit_group+0x17/0x20
[<ffffffff81564357>] ? system_call_fastpath+0x35/0x3a
[<ffffffff8156427e>] ? system_call_after_swapgs+0xae/0x152
Ten rodzaj paniki jądra występuje z powodu następujących możliwych przyczyn:
Zapoznaj się z poniższymi sekcjami, aby uzyskać szczegółowe informacje i rozwiązania. Upewnij się, że polecenia są wykonywane z maszyny wirtualnej naprawy/ratowania w środowisku chroot zgodnie z instrukcjami w temacie Rozwiązywanie problemów w trybie offline.
Brak ważnych plików i katalogów
Brakuje ważnych plików i katalogów systemu Linux z powodu błędu ludzkiego. Na przykład pliki są przypadkowo usuwane lub uszkodzenie systemu plików.
Zweryfikuj zawartość dysku systemu operacyjnego po dołączeniu kopii dysku systemu operacyjnego do maszyny wirtualnej naprawy i zainstalowaniu odpowiednich systemów plików przy użyciu pakietu chroot. Możesz porównać dane wyjściowe z tymi z działającej maszyny wirtualnej z uruchomioną tą samą wersją systemu operacyjnego.
ls -l / ls -l /usr/lib ls -l /usr/lib64 ls -lR / | morePrzywróć brakujące pliki z kopii zapasowej. Aby uzyskać więcej informacji, zobacz Odzyskiwanie plików z kopii zapasowej maszyny wirtualnej platformy Azure. W zależności od liczby brakujących plików może być lepiej wykonać pełne przywracanie maszyny wirtualnej. Aby uzyskać więcej informacji, zobacz Jak przywrócić dane maszyny wirtualnej platformy Azure w witrynie Azure Portal.
Brak ważnych bibliotek i pakietów podstawowych systemu
Ważne biblioteki podstawowe systemu, pliki lub pakiety są usuwane z systemu lub są uszkodzone. Aby rozwiązać ten problem, zainstaluj ponownie biblioteki, pliki lub pakiety, których dotyczy problem. To rozwiązanie działa w dystrybucjach opartych na rpm, takich jak maszyny wirtualne Red Hat/CentOS/SUSE. W przypadku innych dystrybucji systemu Linux zalecamy przywrócenie maszyny wirtualnej z kopii zapasowej.
Aby przeprowadzić ponowną instalację, wykonaj następujące kroki:
Utwórz maszynę wirtualną ratunkową przy użyciu nieprzetworzonego obrazu z tą samą wersją systemu operacyjnego i generowaniem co maszyna wirtualna, której dotyczy problem.
Aby rozwiązać ten problem, uzyskaj dostęp do środowiska chroot na maszynie wirtualnej ratowniczej.
sudo chroot /rescueDane wyjściowe polecenia wskazują, której biblioteki brakuje lub która jest uszkodzona, jak pokazano poniżej:
/bin/bash: error while loading shared libraries: libc.so.6: cannot open shared object file: No such file or directorySprawdź wszystkie pakiety systemowe i ich odpowiedni stan na maszynie wirtualnej ratowniczej. Porównaj dane wyjściowe z maszyną wirtualną w dobrej kondycji z tą samą wersją systemu operacyjnego.
sudo rpm --verify --all --root=/rescueOto przykładowe dane wyjściowe polecenia:
error: Failed to dlopen /usr/lib64/rpm-plugins/systemd_inhibit.so /lib64/librt.so.1: undefined symbol: __pthread_attr_copy, version GLIBC_PRIVATE S.5....T. c /etc/dnf/dnf.conf S.5....T. c /etc/ssh/sshd_config .M....... /boot/efi/EFI/BOOT/BOOTX64.EFI .M....... /boot/efi/EFI/BOOT/fbx64.efi .M....... /boot/efi/EFI/redhat/BOOTX64.CSV .M....... /boot/efi/EFI/redhat/mmx64.efi .M....... /boot/efi/EFI/redhat/shimx64-redhat.efi .M....... /boot/efi/EFI/redhat/shimx64.efi missing /run/motd.d .M....... g /var/spool/anacron/cron.daily .M....... g /var/spool/anacron/cron.monthly .M....... g /var/spool/anacron/cron.weekly missing /lib64/libc-2.28.so <------- .M....... /boot/efi/EFI/redhat S.5....T. c /etc/security/pwquality.confWiersz
missing /lib64/libc-2.28.sodanych wyjściowych jest powiązany z poprzednim błędem w kroku 2 i wskazuje, że brakuje pakietu libc-2.28.so . Można jednak zmodyfikować pakiet libc-2.28.so. W takim przypadku dane wyjściowe będą wyświetlane.M.....zamiastmissing. Pakiet libc-2.28.so jest przywołyny jako przykład w poniższych krokach.Na maszynie wirtualnej ratowniczej sprawdź, który pakiet zawiera bibliotekę /lib64/libc-2.28.so.
sudo rpm -qf /lib64/libc-2.28.soglibc-2.28-127.0.1.el8.x86_64Uwaga 16.
W danych wyjściowych zostanie wyświetlony pakiet, który należy ponownie zainstalować, w tym nazwę pakietu i wersję. Wersja pakietu może się różnić od wersji zainstalowanej na maszynie wirtualnej, której dotyczy problem.
Na maszynie wirtualnej, której dotyczy problem, sprawdź, która wersja pakietu glibc jest zainstalowana.
sudo rpm -qa --all --root=/rescue | grep -i glibcglibc-common-2.28-211.0.1.el8.x86_64 glibc-gconv-extra-2.28-211.0.1.el8.x86_64 glibc-2.28-211.0.1.el8.x86_64 <---- glibc-langpack-en-2.28-211.0.1.el8.x86_64Pobierz pakiet glibc-2.28-211.0.1.el8.x86_64. Możesz pobrać go z oficjalnej witryny internetowej dostawcy systemu operacyjnego lub z maszyny wirtualnej ratowniczej przy użyciu narzędzia do zarządzania pakietami, takiego jak
yumdownloaderlubzypper install --download-only <packagename>w zależności od uruchomionego systemu operacyjnego.Oto przykład użycia
yumdownloadernarzędzia:cd /tmp sudo yumdownloader glibc-2.28-211.0.1.el8.x86_64Last metadata expiration check: 0:03:24 ago on Thu 25 May 2023 02:36:25 PM UTC. glibc-2.28-211.0.1.el8.x86_64.rpm 8.7 MB/s | 2.2 MB 00:00Zainstaluj ponownie pakiet, którego dotyczy problem, na maszynie wirtualnej ratownictwa.
sudo rpm -ivh --root=/rescue /tmp/glibc-*.rpm --replacepkgs --replacefileswarning: /tmp/glibc-2.28-211.0.1.el8.x86_64.rpm: Header V3 RSA/SHA256 Signature, key ID ad986da3: NOKEY Verifying... ################################# [100%] Preparing... ################################# [100%] Updating / installing... 1:glibc-2.28-211.0.1.el8 ################################# [100%]Uzyskaj dostęp do środowiska chroot na maszynie wirtualnej ratowniczej, aby zweryfikować ponowną instalację.
sudo chroot /rescueWyłącz ratowniczą maszynę wirtualną i zamień dysk systemu operacyjnego na maszynę wirtualną, której dotyczy problem.
Nieprawidłowe uprawnienia do plików
Nieprawidłowe uprawnienia do plików całego systemu są modyfikowane z powodu błędu ludzkiego (na przykład ktoś działa chmod 777 w / innych ważnych systemach plików systemu operacyjnego). Aby rozwiązać ten problem, przywróć uprawnienia do pliku. To rozwiązanie działa w dystrybucjach opartych na rpm, takich jak maszyny wirtualne Red Hat/CentOS/SUSE. W przypadku innych dystrybucji systemu Linux zalecamy przywrócenie maszyny wirtualnej z kopii zapasowej.
Aby przywrócić uprawnienia do pliku, uruchom następujące polecenie po dołączeniu kopii dysku systemu operacyjnego do maszyny wirtualnej naprawy i zainstalowaniu odpowiednich systemów plików przy użyciu katalogu chroot:
rpm -a --setperms
rpm --setugids --all
chmod u+s /bin/sudo
chmod 660 /etc/sudoers.d/*
chmod 644 /etc/ssh/*.pub
chmod 640 /etc/ssh/*.key
Uwaga 16.
Nie uruchamiaj tego polecenia w uruchomionych systemach produkcyjnych.
Jeśli problem nadal występuje po ręcznym odzyskaniu odpowiednich uprawnień do pliku, wykonaj przywracanie z kopii zapasowej.
Brakujące partycje
W przypadkach, gdy /usrsystemy plików , /opt, /var/home, /tmpi / są rozłożone na różne partycje, dane mogą być niedostępne z powodu problemów na poziomie partycji, co może być spowodowane błędami podczas operacji zmiany rozmiaru partycji lub innych.
W tym scenariuszu, jeśli dokumentujesz oryginalny układ tabeli partycji, z dokładnymi sektorami początkowymi i końcowymi dla każdej z oryginalnych partycji, a w systemie nie są wykonywane żadne dalsze modyfikacje, takie jak tworzenie nowych systemów plików, ponowne utworzenie partycji przy użyciu tego samego oryginalnego układu z narzędziami takimi jak fdisk (w przypadku tabel partycji MBR) lub dyskietki (dla tabel partycji GPT) w celu uzyskania dostępu do brakującego systemu plików.
Jeśli takie podejście nie zadziała, wykonaj przywracanie z kopii zapasowej.
Problemy z programem SELinux
Nieprawidłowe uprawnienia SELinux mogą uniemożliwić systemowi dostęp do ważnych plików. Aby rozwiązać ten problem, wykonaj poniższe czynności:
Aby sprawdzić, czy system ma problemy z nieprawidłowymi uprawnieniami SELinux, uruchom system z wyłączonym seLinux, dodając opcję selinux=0 jądra do wiersza GRUB linux16.
Jeśli system jest w stanie uruchomić system, uruchom następujące polecenie, aby wyzwolić ponowne oznaczenie SELinux w czasie rozruchu i ponownie uruchomić system:
touch /.autorelabelJeśli maszyna wirtualna nadal nie może uruchomić się, wykonaj pełne przywracanie maszyny wirtualnej z kopii zapasowej. Aby uzyskać więcej informacji, zobacz Jak przywrócić dane maszyny wirtualnej platformy Azure w witrynie Azure Portal.
Inne problemy z rozruchem związane z jądrem
W tym artykule opisano najczęstsze paniki jądra systemu Linux zidentyfikowane na platformie Azure. Aby uzyskać więcej informacji na temat typowych scenariuszy paniki jądra, zobacz Panika jądra na maszynach wirtualnych z systemem Linux platformy Azure — typowe zdarzenia paniki jądra.
Istnieją inne ważne możliwe paniki jądra, które mogą spowodować brak rozruchu lub brak bezpiecznych scenariuszy powłoki (SSH).
Upewnij się, że wszystkie polecenia z maszyny wirtualnej naprawy w środowisku chroot zostały wykonane zgodnie z instrukcjami w temacie Rozwiązywanie problemów w trybie offline. Jeśli system jest już uruchomiony w poprzedniej wersji jądra, te polecenia można również wykonać z oryginalnej maszyny wirtualnej przy użyciu uprawnień głównych lub sudo, zgodnie z instrukcją w temacie Rozwiązywanie problemów online.
Ostatnie uaktualnienie jądra
Jeśli jądro uruchomi się po ostatnim uaktualnieniu jądra, uruchom maszynę wirtualną w poprzedniej wersji jądra. Aby uzyskać więcej informacji, zobacz Rozruch systemu w starszej wersji jądra.
Możesz również sprawdzić, czy jest już nowsza wersja jądra wydana przez dostawcę dystrybucji systemu Linux i zainstalować ją. Aby uzyskać więcej informacji na temat sposobu instalowania najnowszej wersji jądra, zobacz Proces aktualizacji jądra.
Ostatnia obniżanie poziomu jądra
Jeśli jądro wystartuje po ostatnim obniżeniu poziomu jądra, wróć do najnowszego zainstalowanego jądra. Możesz również sprawdzić, czy jest już nowsza wersja jądra wydana przez dostawcę dystrybucji systemu Linux i zainstalować ją. Aby uzyskać więcej informacji na temat sposobu instalowania najnowszej wersji jądra, zobacz Proces aktualizacji jądra.
Aby uruchomić system w najnowszej wersji jądra, postępuj zgodnie z instrukcjami w temacie Ręczne zmienianie domyślnej wersji jądra, ale wybierz pierwsze jądro wymienione w menu GRUB. W modyfikacji ręcznej można ustawić GRUB_DEFAULT wartość 0 i ponownie wygenerować odpowiedni plik konfiguracji GRUB.
Zmiany modułu jądra
Może wystąpić panika jądra związana z nowym modułem jądra lub brakującym modułem jądra. Aby uzyskać szczegółowe informacje na temat określonego modułu jądra, który powoduje problemy (jeśli istnieje), sprawdź odpowiedni ślad paniki jądra.
Aby zweryfikować załadowane moduły jądra i wyłączone w plikach /etc/modprobe.d/*.conf , uruchom jedno z następujących poleceń:
RHEL/CentOS/Oracle Linux 7/8
lsinitrd /boot/initramfs-3.10.0-1160.59.1.el7.x86_64.img lsmod cat /etc/modprobe.d/*.confWażne
Zastąp
3.10.0-1160.59.1.el7.x86_64element odpowiednią wersją jądra.SLES 12/15
lsinitrd /boot/initrd-5.3.18-150300.38.53-azure lsmod cat /etc/modprobe.d/*.confWażne
Zastąp
5.3.18-150300.38.53-azureelement odpowiednią wersją jądra.Ubuntu 18.04
lsinitramfs /boot/initrd.img-5.4.0-1077-azure lsmod cat /etc/modprobe.d/*.confWażne
Zastąp
5.4.0-1077-azureelement odpowiednią wersją jądra.
Aby usunąć dowolny konkretny moduł jądra, uruchom następujące polecenie i w razie potrzeby ponownie wygeneruj initramfs .
rmmod <kernel_module_name>
Jeśli usługa systemowa używa określonego modułu jądra, wyłącz go, uruchamiając systemctl disable <serviceName> polecenie lub systemctl stop <serviceName> .
Najnowsze zmiany konfiguracji systemu operacyjnego
Zidentyfikuj wszelkie ostatnie zmiany konfiguracji jądra, które mogą powodować problemy. Aby rozwiązać te problemy, dostosuj te ustawienia lub wycofaj zmiany konfiguracji.
Uruchom następujące polecenie, aby znaleźć trwałe parametry jądra skonfigurowane w jednym z następujących plików:
cat /etc/systctl.conf
cat /etc/sysctl.d/*
Uruchom następujące polecenie, aby przeanalizować bieżące parametry jądra i ich bieżące wartości:
sysctl -a
Uwaga 16.
Uruchom to polecenie w uruchomionym systemie, a nie ze środowiska chroot.
Możliwe brakujące pliki
Aby uzyskać więcej informacji na temat tego rodzaju problemu, zobacz Brak ważnych plików i katalogów.
Nieprawidłowe uprawnienia do plików
Aby uzyskać więcej informacji na temat tego rodzaju problemu, zobacz Nieprawidłowe uprawnienia do pliku.
Brakujące partycje
Aby uzyskać więcej informacji na temat tego rodzaju problemu, zobacz Brakujące partycje.
Błędy jądra
Zidentyfikuj ten problem z konsoli szeregowej platformy Azure. Ten rodzaj problemu będzie wyglądać podobnie do następujących danych wyjściowych:
[5275698.017004] kernel BUG at XXX/YYY.c:72!
[5275698.017004] invalid opcode: 0000 [#1] SMP
Ten rodzaj paniki jądra jest związany z usterkami jądra lub usterkami jądra innych firm.
Aby naprawić błędy jądra, przeszukuj dostawcę bazy wiedzy przy użyciu ciągu BUG jądra i poszukaj znanych problemów w odpowiedniej wersji jądra, z którą działa system. Oto kilka ważnych zasobów dostawcy:
-
To narzędzie jest przeznaczone do diagnozowania awarii jądra. Podczas wprowadzania tekstu, vmcore-dmesg.txt lub pliku zawierającego co najmniej jeden komunikat oops jądra, przeprowadzi Cię przez diagnozowanie problemu z awarią jądra.
-
Aby uzyskać dostęp do zasobów Red Hat, połącz swoje konta platformy Microsoft Azure i systemu Red Hat. Aby uzyskać więcej informacji, zobacz How Microsoft Azure Customers Can Access the Red Hat Customer Portal (Jak klienci platformy Microsoft Azure mogą uzyskać dostęp do portalu klienta red hat).
Zalecamy aktualizowanie wszystkich systemów, aby wykluczyć wszelkie możliwe usterki, które zostały już naprawione w najnowszych wersjach jądra. Aby uzyskać więcej informacji, zobacz Proces aktualizacji jądra.
Jeśli wymagana jest dalsza analiza od dostawcy, skonfiguruj i włącz narzędzie kdump w celu wygenerowania zrzutu pamięci:
- Konfiguracja narzędzia kdump na maszynach wirtualnych opartych na systemie Red Hat.
- Konfiguracja zrzutu awaryjnego jądra na maszynach wirtualnych z systemem Ubuntu.
- Konfiguracja zrzutu rdzenia jądra na maszynach wirtualnych z systemem SLES
Proces aktualizacji jądra
Aby zainstalować najnowszą dostępną wersję jądra, uruchom jedno z następujących poleceń:
RHEL/CentOS/Oracle Linux
yum update kernelSLES 12/15
zypper refresh zypper update kernel*Ubuntu 18.04/20.04
apt update apt install linux-azure
Aby ponownie zainstalować określoną wersję jądra, uruchom jedno z następujących poleceń. Upewnij się, że nie uruchamiasz się w tej samej wersji jądra, którą próbujesz ponownie zainstalować. Aby uzyskać więcej informacji, zobacz Rozruch systemu w starszej wersji jądra.
RHEL/CentOS/Oracle Linux
yum reinstall kernel-3.10.0-1160.59.1.el7.x86_64Ważne
Zastąp
3.10.0-1160.59.1.el7.x86_64element odpowiednią wersją jądra.SLES 12/15
zypper refresh zypper install -f kernel-azure-5.3.18-150300.38.75.1.x86_64Ważne
Zastąp
kernel-azure-5.3.18-150300.38.75.1.x86_64element odpowiednią wersją jądra.Ubuntu 18.04/20.04
apt update apt install --reinstall linux-azure=5.4.0.1091.68Ważne
Zastąp
5.4.0.1091.68element odpowiednią wersją jądra.
Aby zaktualizować system i zastosować najnowsze dostępne zmiany, uruchom jedno z następujących poleceń:
RHEL/CentOS/Oracle Linux
yum updateSLES 12/15
zypper refresh zypper updateUbuntu 18.04/20.04
apt update apt upgrade
Paniki jądra mogą być związane z dowolnym z następujących elementów. Aby uzyskać więcej informacji, zobacz Panika jądra w czasie wykonywania.
- Zmiany obciążenia aplikacji.
- Tworzenie aplikacji lub błędy aplikacji.
- Problemy związane z wydajnością itd.
Następne kroki
Jeśli określony błąd rozruchu nie jest problemem z rozruchem związany z jądrem, zobacz Rozwiązywanie problemów z błędami rozruchu maszyn wirtualnych z systemem Linux na platformie Azure, aby uzyskać dalsze opcje rozwiązywania problemów.
Skontaktuj się z nami, aby uzyskać pomoc
Jeśli masz pytania lub potrzebujesz pomocy, utwórz wniosek o pomoc techniczną lub zadaj pytanie w społeczności wsparcia dla platformy Azure. Możesz również przesłać opinię o produkcie do społeczności opinii na temat platformy Azure.