Przygotowanie do korzystania z platformy Apache Spark
Apache Spark to rozproszona struktura przetwarzania danych, która umożliwia analizę danych na dużą skalę, koordynując pracę między wieloma węzłami przetwarzania w klastrze znanym w usłudze Microsoft Fabric jako pula platformy Spark. Mówiąc bardziej prosto, platforma Spark wykorzystuje podejście "dzielenia i podbijania" do szybkiego przetwarzania dużych ilości danych przez dystrybucję pracy na wielu komputerach. Proces dystrybucji zadań i sortowania wyników jest obsługiwany przez platformę Spark.
Platforma Spark może uruchamiać kod napisany w wielu różnych językach, w tym Java, Scala (język skryptowy oparty na języku Java), Spark R, Spark SQL i PySpark (wariant specyficzny dla platformy Spark języka Python). W praktyce większość obciążeń inżynieryjnych i analitycznych jest realizowana przy użyciu kombinacji narzędzi PySpark i Spark SQL.
Pule zadań platformy Spark
Pula platformy Spark składa się z węzłów obliczeniowych, które dystrybuują zadania przetwarzania danych. Ogólna architektura jest pokazana na poniższym diagramie.
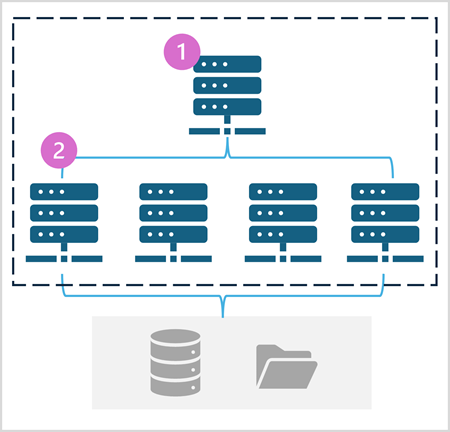
Jak pokazano na diagramie, pula platformy Spark zawiera dwa rodzaje węzłów:
- Węzeł główny w puli Spark koordynuje rozproszone procesy za pośrednictwem programu sterowników.
- Pula zawiera wiele węzłów roboczych , na których procesy wykonawcze wykonują rzeczywiste zadania przetwarzania danych.
Pula Platformy Spark używa tej rozproszonej architektury obliczeniowej do uzyskiwania dostępu do danych i przetwarzania ich w zgodnym magazynie danych , takim jak usługa Data Lakehouse oparta na usłudze OneLake.
Pule platformy Spark w usłudze Microsoft Fabric
Usługa Microsoft Fabric udostępnia pulę początkową w każdym obszarze roboczym, umożliwiając uruchamianie i szybkie uruchamianie zadań platformy Spark przy minimalnej konfiguracji i konfiguracji. Pulę początkową można skonfigurować tak, aby zoptymalizować węzły, które zawiera zgodnie z określonymi potrzebami obciążeń lub ograniczeniami kosztów.
Ponadto można tworzyć niestandardowe pule platformy Spark z określonymi konfiguracjami węzłów, które obsługują określone potrzeby przetwarzania danych.
Uwaga
Możliwość dostosowywania ustawień puli platformy Spark można wyłączyć przez administratorów sieci szkieletowej na poziomie pojemności sieci szkieletowej. Aby uzyskać więcej informacji, zobacz Ustawienia administrowania pojemnością na potrzeby inżynierowie danych i Nauka o danych w dokumentacji sieci szkieletowej.
Ustawienia puli początkowej można zarządzać i tworzyć nowe pule platformy Spark w sekcji inżynierowie danych ing/Science w ustawieniach obszaru roboczego.
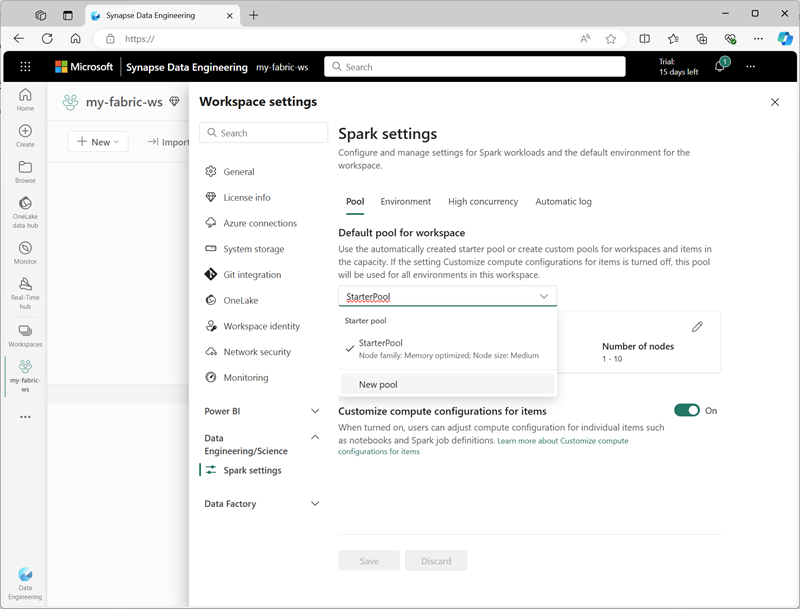
Określone ustawienia konfiguracji dla pul platformy Spark obejmują:
- Rodzina węzłów: typ maszyn wirtualnych używanych dla węzłów klastra Spark. W większości przypadków węzły zoptymalizowane pod kątem pamięci zapewniają optymalną wydajność.
- Automatyczne skalowanie: określa, czy automatycznie aprowizować węzły zgodnie z potrzebami, a jeśli tak, początkowa i maksymalna liczba węzłów do przydzielenia do puli.
- Alokacja dynamiczna: określa, czy dynamicznie przydzielać procesy wykonawcze na węzłach procesu roboczego na podstawie woluminów danych.
Jeśli tworzysz co najmniej jedną niestandardową pulę platformy Spark w obszarze roboczym, możesz ustawić jedną z nich (lub pulę początkową) jako domyślną pulę, która ma być używana, jeśli określona pula nie zostanie określona dla danego zadania platformy Spark.
Napiwek
Aby uzyskać więcej informacji na temat zarządzania pulami platformy Spark w usłudze Microsoft Fabric, zobacz Konfigurowanie pul startowych w usłudze Microsoft Fabric i Jak tworzyć niestandardowe pule platformy Spark w usłudze Microsoft Fabric w dokumentacji usługi Microsoft Fabric.
Środowiska uruchomieniowe i środowiska
Ekosystem open source platformy Spark obejmuje wiele wersji środowiska uruchomieniowego Platformy Spark, które określa wersję zainstalowanych składników oprogramowania Apache Spark, Delta Lake, Python i innych podstawowych składników oprogramowania. Ponadto w środowisku uruchomieniowym można zainstalować i używać szerokiego wyboru bibliotek kodu do typowych (a czasami bardzo wyspecjalizowanych) zadań. Ponieważ wiele operacji przetwarzania platformy Spark jest wykonywane przy użyciu narzędzia PySpark, ogromny zakres bibliotek języka Python gwarantuje, że niezależnie od tego, co należy wykonać, prawdopodobnie istnieje biblioteka, która pomoże.
W niektórych przypadkach organizacje mogą wymagać zdefiniowania wielu środowisk w celu obsługi różnych zadań przetwarzania danych. Każde środowisko definiuje określoną wersję środowiska uruchomieniowego, a także biblioteki, które należy zainstalować, aby wykonywać określone operacje. Inżynierowie danych i analitycy mogą następnie wybrać środowisko, które ma być używane z pulą spark dla określonego zadania.
Środowiska uruchomieniowe platformy Spark — Microsoft Fabric
Usługa Microsoft Fabric obsługuje wiele środowisk uruchomieniowych platformy Spark i będzie nadal dodawać obsługę nowych środowisk uruchomieniowych w miarę ich wydawania. Interfejs ustawień obszaru roboczego umożliwia określenie środowiska uruchomieniowego platformy Spark używanego domyślnie podczas uruchamiania puli platformy Spark.
Napiwek
Aby uzyskać więcej informacji na temat środowisk uruchomieniowych platformy Spark w usłudze Microsoft Fabric, zobacz Apache Spark Runtimes in Fabric (Środowiska uruchomieniowe platformy Apache Spark w sieci szkieletowej ) w dokumentacji usługi Microsoft Fabric.
Środowiska w usłudze Microsoft Fabric
Środowiska niestandardowe można tworzyć w obszarze roboczym Sieć szkieletowa, umożliwiając korzystanie z określonych środowisk uruchomieniowych platformy Spark, bibliotek i ustawień konfiguracji dla różnych operacji przetwarzania danych.
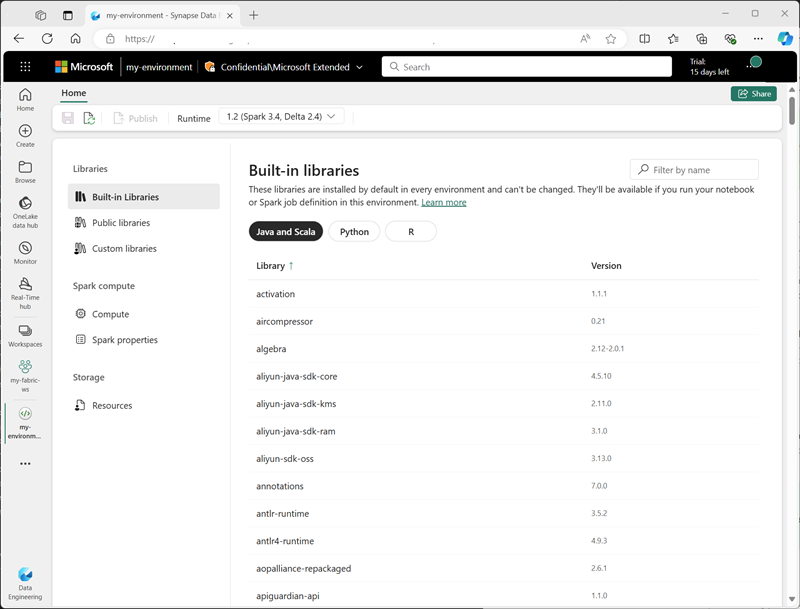
Podczas tworzenia środowiska można wykonywać następujące czynności:
- Określ środowisko uruchomieniowe platformy Spark, które ma być używane.
- Wyświetl wbudowane biblioteki zainstalowane w każdym środowisku.
- Zainstaluj określone biblioteki publiczne z indeksu pakietów języka Python (PyPI).
- Zainstaluj biblioteki niestandardowe, przekazując plik pakietu.
- Określ pulę platformy Spark, która ma być używana przez środowisko.
- Określ właściwości konfiguracji platformy Spark, aby zastąpić domyślne zachowanie.
- Przekaż pliki zasobów, które muszą być dostępne w środowisku.
Po utworzeniu co najmniej jednego środowiska niestandardowego można określić je jako domyślne środowisko w ustawieniach obszaru roboczego.
Napiwek
Aby uzyskać więcej informacji na temat używania środowisk niestandardowych w usłudze Microsoft Fabric, zobacz Tworzenie, konfigurowanie i używanie środowiska w usłudze Microsoft Fabric w dokumentacji usługi Microsoft Fabric .
Dodatkowe opcje konfiguracji platformy Spark
Zarządzanie pulami i środowiskami platformy Spark to podstawowe sposoby zarządzania przetwarzaniem platformy Spark w obszarze roboczym sieć szkieletowa. Istnieją jednak pewne dodatkowe opcje, których można użyć do dalszej optymalizacji.
Aparat wykonywania natywnego
Natywny aparat wykonywania w usłudze Microsoft Fabric to wektoryzowany aparat przetwarzania, który uruchamia operacje platformy Spark bezpośrednio w infrastrukturze lakehouse. Korzystanie z natywnego aparatu wykonywania może znacznie poprawić wydajność zapytań podczas pracy z dużymi zestawami danych w formatach plików Parquet lub Delta.
Aby użyć aparatu wykonywania natywnego, możesz włączyć go na poziomie środowiska lub w ramach pojedynczego notesu. Aby włączyć natywny aparat wykonywania na poziomie środowiska, ustaw następujące właściwości platformy Spark w konfiguracji środowiska:
- spark.native.enabled: true
- spark.shuffle.manager: org.apache.spark.shuffle.sort.ColumnarShuffleManager
Aby włączyć aparat wykonywania natywnego dla określonego skryptu lub notesu, możesz ustawić te właściwości konfiguracji na początku kodu w następujący sposób:
%%configure
{
"conf": {
"spark.native.enabled": "true",
"spark.shuffle.manager": "org.apache.spark.shuffle.sort.ColumnarShuffleManager"
}
}
Napiwek
Aby uzyskać więcej informacji na temat natywnego aparatu wykonywania, zobacz Natywny aparat wykonywania dla platformy Spark w dokumentacji usługi Microsoft Fabric.
Tryb wysokiej współbieżności
Po uruchomieniu kodu Spark w usłudze Microsoft Fabric inicjowana jest sesja platformy Spark. Wydajność użycia zasobów platformy Spark można zoptymalizować przy użyciu trybu wysokiej współbieżności, aby udostępniać sesje platformy Spark wielu równoczesnych użytkowników lub procesów. W przypadku włączenia trybu wysokiej współbieżności dla notesów wielu użytkowników może uruchamiać kod w notesach korzystających z tej samej sesji platformy Spark, zapewniając jednocześnie izolację kodu, aby uniknąć wpływu zmiennych w jednym notesie przez kod w innym notesie. Możesz również włączyć tryb wysokiej współbieżności dla zadań platformy Spark, umożliwiając podobne efektywność dla współbieżnego wykonywania skryptów platformy Spark nieinterakcyjnych.
Aby włączyć tryb wysokiej współbieżności, użyj sekcji inżynierowie danych ing/Science w interfejsie ustawień obszaru roboczego.
Napiwek
Aby uzyskać więcej informacji na temat trybu wysokiej współbieżności, zobacz Tryb wysokiej współbieżności w usłudze Apache Spark for Fabric w dokumentacji usługi Microsoft Fabric .
Automatyczne rejestrowanie w usłudze MLFlow
MLFlow to biblioteka typu open source używana w obciążeniach nauki o danych do zarządzania uczeniem maszynowym i wdrażaniem modeli. Kluczową funkcją platformy MLFlow jest możliwość rejestrowania operacji trenowania modelu i zarządzania nimi. Domyślnie usługa Microsoft Fabric używa platformy MLFlow do niejawnego rejestrowania działań eksperymentu uczenia maszynowego bez konieczności dołączania jawnego kodu do tego celu przez analityka danych. Tę funkcję można wyłączyć w ustawieniach obszaru roboczego.
Administrowanie platformą Spark dla pojemności sieci szkieletowej
Administratorzy mogą zarządzać ustawieniami platformy Spark na poziomie pojemności sieci szkieletowej, umożliwiając im ograniczanie i zastępowanie ustawień platformy Spark w obszarach roboczych w organizacji.
Napiwek
Aby uzyskać więcej informacji na temat zarządzania konfiguracją platformy Spark na poziomie pojemności sieci szkieletowej, zobacz Konfigurowanie ustawień inżynierii danych i nauki o danych dla pojemności sieci szkieletowej oraz zarządzanie nimi w dokumentacji usługi Microsoft Fabric.