Środowiska uruchomieniowe platformy Apache Spark w sieci szkieletowej
Microsoft Fabric Runtime to zintegrowana z platformą Azure platforma oparta na platformie Apache Spark, która umożliwia wykonywanie i zarządzanie środowiskami inżynierii danych i nauki o danych. Łączy kluczowe składniki zarówno ze źródeł wewnętrznych, jak i open source, zapewniając klientom kompleksowe rozwiązanie. Dla uproszczenia odwołujemy się do środowiska uruchomieniowego usługi Microsoft Fabric obsługiwanego przez platformę Apache Spark jako środowiska uruchomieniowego usługi Fabric.
Główne składniki środowiska uruchomieniowego sieci szkieletowej:
Apache Spark — zaawansowana rozproszona biblioteka obliczeniowa typu open source, która umożliwia przetwarzanie i analizowanie danych na dużą skalę. Platforma Apache Spark udostępnia wszechstronną i wysokowydajną platformę do inżynierii danych i środowiska nauki o danych.
Delta Lake — warstwa magazynu typu open source, która zapewnia transakcje ACID i inne funkcje niezawodności danych na platformie Apache Spark. Zintegrowane w środowisku uruchomieniowym sieci szkieletowej usługa Delta Lake zwiększa możliwości przetwarzania danych i zapewnia spójność danych w wielu współbieżnych operacjach.
Natywny aparat wykonywania — to rozszerzenie transformacyjne dla obciążeń platformy Apache Spark, które oferuje znaczne wzrosty wydajności dzięki bezpośredniej wykonywaniu zapytań platformy Spark w infrastrukturze typu lakehouse. Integracja bezproblemowo wymaga żadnych zmian w kodzie i pozwala uniknąć blokady dostawcy, obsługując zarówno formaty Parquet, jak i Delta w interfejsach API platformy Apache Spark w środowisku uruchomieniowym 1.3 (Spark 3.5). Ten aparat zwiększa szybkość zapytań do czterech razy szybciej niż tradycyjny system operacyjny Spark, jak pokazano w tezie porównawczym TPC-DS 1 TB, zmniejszając koszty operacyjne i zwiększając wydajność w różnych zadaniach danych— w tym pozyskiwanie danych, ETL, analizy i interakcyjne zapytania. Oparty na technologii Velox i Apache Gluten firmy Intel firmy Meta optymalizuje użycie zasobów podczas obsługi różnych scenariuszy przetwarzania danych.
Pakiety na poziomie domyślnym dla języków Java/Scala, Python i R — pakiety obsługujące różne języki programowania i środowiska. Te pakiety są instalowane i konfigurowane automatycznie, co umożliwia deweloperom stosowanie preferowanych języków programowania na potrzeby zadań przetwarzania danych.
Środowisko uruchomieniowe usługi Microsoft Fabric jest oparte na niezawodnym systemie operacyjnym typu open source, zapewniając zgodność z różnymi konfiguracjami sprzętowymi i wymaganiami systemowymi.
Poniżej znajdziesz kompleksowe porównanie kluczowych składników, w tym wersji platformy Apache Spark, obsługiwanych systemów operacyjnych, Java, Scala, Python, Delta Lake i R dla środowisk uruchomieniowych opartych na platformie Microsoft Fabric.
Napiwek
Zawsze używaj najnowszej, ogólnie dostępnej wersji środowiska uruchomieniowego dla obciążenia produkcyjnego, który jest obecnie środowiskiem uruchomieniowym 1.3.
| Środowisko uruchomieniowe 1.1 | Środowisko uruchomieniowe 1.2 | Środowisko uruchomieniowe 1.3 | |
|---|---|---|---|
| Etap wydania | EOSA | GA | GA |
| Apache Spark | 3.3.1 | 3.4.1 | 3.5.0 |
| System operacyjny | Ubuntu 18.04 | Mariner 2.0 | Mariner 2.0 |
| Java | 8 | 11 | 11 |
| Scala | 2.12.15 | 2.12.17 | 2.12.17 |
| Python | 3,10 | 3,10 | 3.11 |
| Delta Lake | 2.2.0 | 2.4.0 | 3.2 |
| R | 4.2.2 | 4.2.2 | 4.4.1 |
Odwiedź stronę Runtime 1.1, Runtime 1.2 lub Runtime 1.3, aby zapoznać się ze szczegółami, nowymi funkcjami, ulepszeniami i scenariuszami migracji dla określonej wersji środowiska uruchomieniowego.
Optymalizacje sieci szkieletowej
W usłudze Microsoft Fabric zarówno aparat Spark, jak i implementacje usługi Delta Lake obejmują optymalizacje i funkcje specyficzne dla platformy. Te funkcje są przeznaczone do korzystania z integracji natywnych w ramach platformy. Należy pamiętać, że wszystkie te funkcje można wyłączyć, aby osiągnąć standardowe funkcje platformy Spark i usługi Delta Lake. Środowiska uruchomieniowe sieci szkieletowej dla platformy Apache Spark obejmują:
- Kompletna wersja typu open source platformy Apache Spark.
- Kolekcja prawie 100 wbudowanych, unikatowych ulepszeń wydajności zapytań. Te ulepszenia obejmują funkcje, takie jak buforowanie partycji (włączenie pamięci podręcznej partycji Systemu plików w celu zmniejszenia wywołań magazynu metadanych) i sprzężenie krzyżowe do projekcji podzapytania skalarnego.
- Wbudowana inteligentna pamięć podręczna.
W środowisku uruchomieniowym sieci szkieletowej dla platform Apache Spark i usługi Delta Lake istnieją natywne funkcje zapisywania, które służą dwóm kluczowym celom:
- Oferują one zróżnicowaną wydajność pisania obciążeń, optymalizując proces pisania.
- Domyślnie są one ustawione na optymalizację kolejności V plików Delta Parquet. Optymalizacja usługi Delta Lake V-Order ma kluczowe znaczenie dla zapewnienia najwyższej wydajności odczytu we wszystkich aparatach sieci szkieletowych. Aby lepiej zrozumieć, jak działa i jak nim zarządzać, zapoznaj się z dedykowanym artykułem dotyczącym optymalizacji tabel usługi Delta Lake i zamówieniami wirtualnymi.
Obsługa wielu środowisk uruchomieniowych
Sieć szkieletowa obsługuje wiele środowisk uruchomieniowych, oferując użytkownikom elastyczność bezproblemowego przełączania się między nimi, minimalizując ryzyko niezgodności lub zakłóceń.
Domyślnie wszystkie nowe obszary robocze używają najnowszej wersji środowiska uruchomieniowego, która jest obecnie środowiskiem uruchomieniowym 1.3.
Aby zmienić wersję środowiska uruchomieniowego na poziomie obszaru roboczego, przejdź do Ustawienia obszaru roboczego>Inżynieria danych/Nauka>Ustawienia platformy Spark. Na karcie środowiska
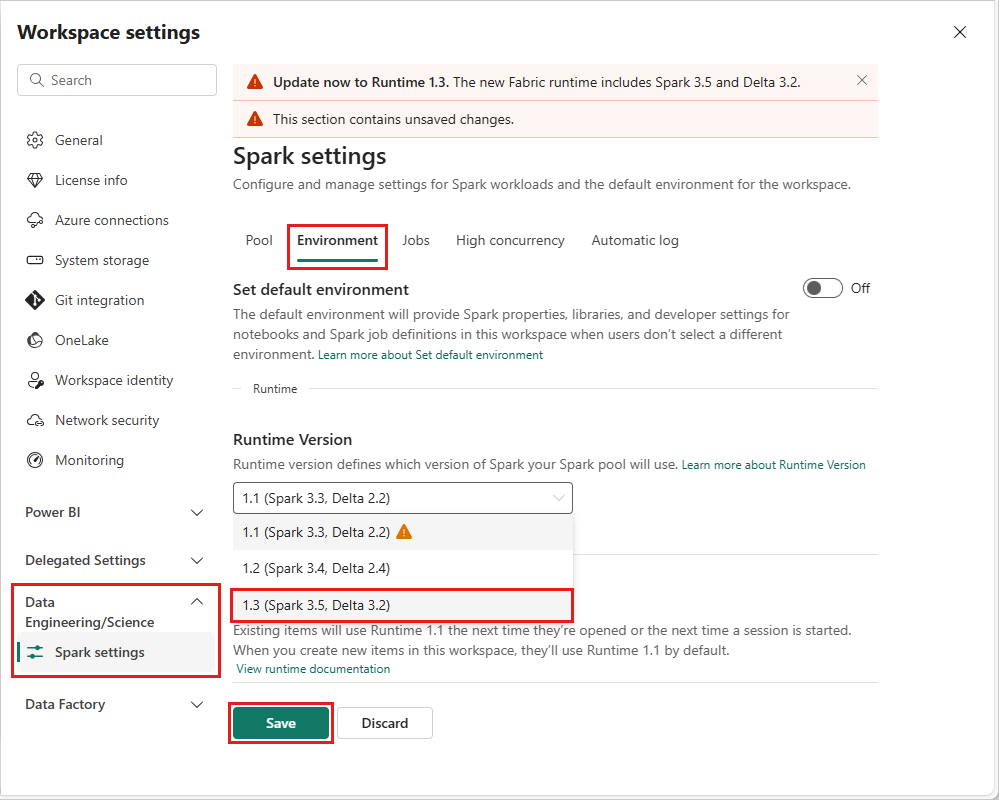
Po wprowadzeniu tej zmiany wszystkie elementy utworzone przez system w obszarze roboczym, w tym Lakehouses, SJDs i Notebooks, będą działać przy użyciu nowo wybranej wersji środowiska uruchomieniowego na poziomie obszaru roboczego, począwszy od następnej sesji platformy Spark. Jeśli obecnie używasz notesu z istniejącą sesją dla zadania lub dowolnego działania związanego z usługą Lakehouse, sesja platformy Spark będzie kontynuowana tak, jak to jest. Jednak począwszy od następnej sesji lub zadania, zostanie zastosowana wybrana wersja środowiska uruchomieniowego.
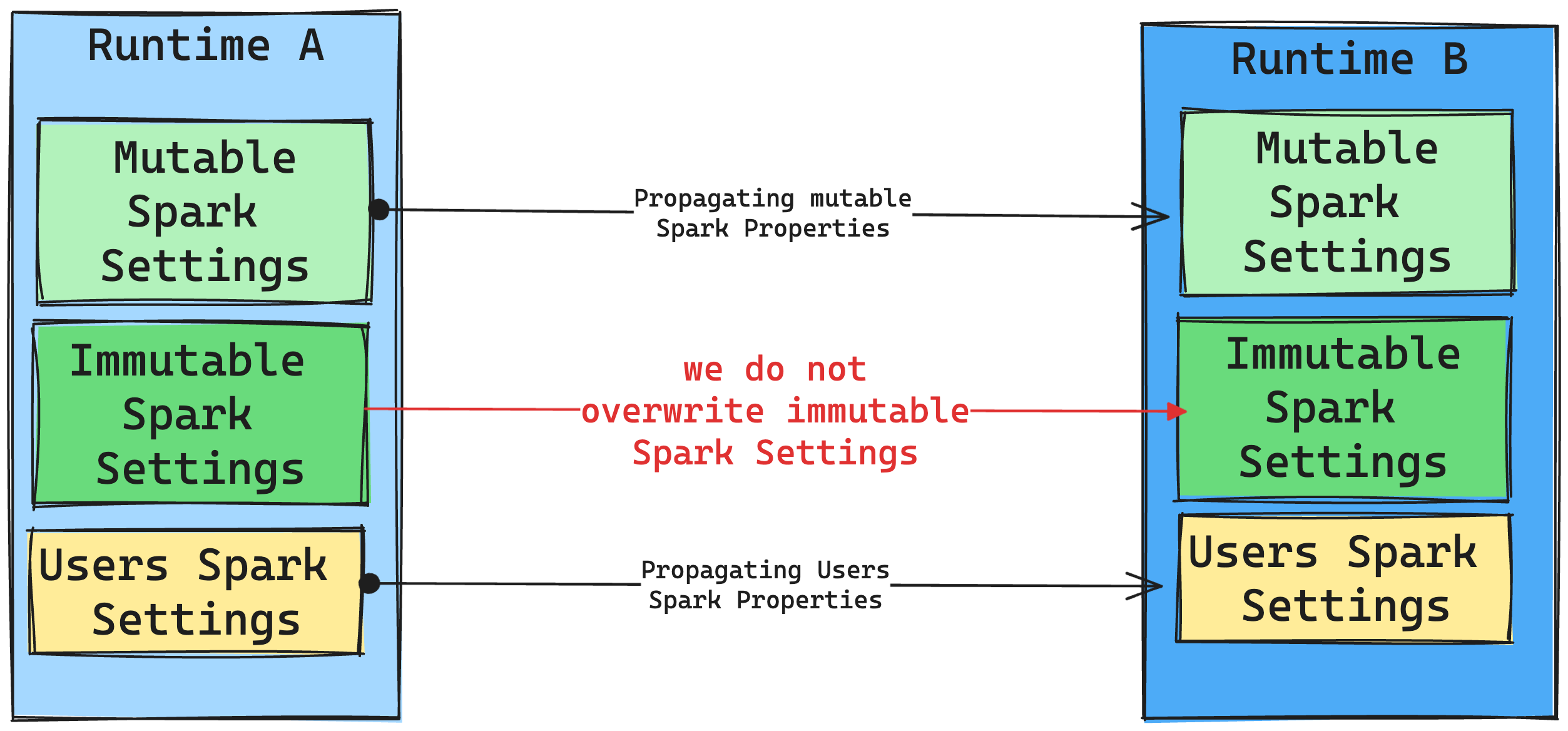
Konsekwencje zmian środowiska uruchomieniowego w ustawieniach platformy Spark
Ogólnie rzecz biorąc, chcemy przeprowadzić migrację wszystkich ustawień platformy Spark. Jeśli jednak zidentyfikujemy, że ustawienie platformy Spark nie jest zgodne ze środowiskiem uruchomieniowym B, wydamy komunikat ostrzegawczy i powstrzymamy się od zaimplementowania tego ustawienia.
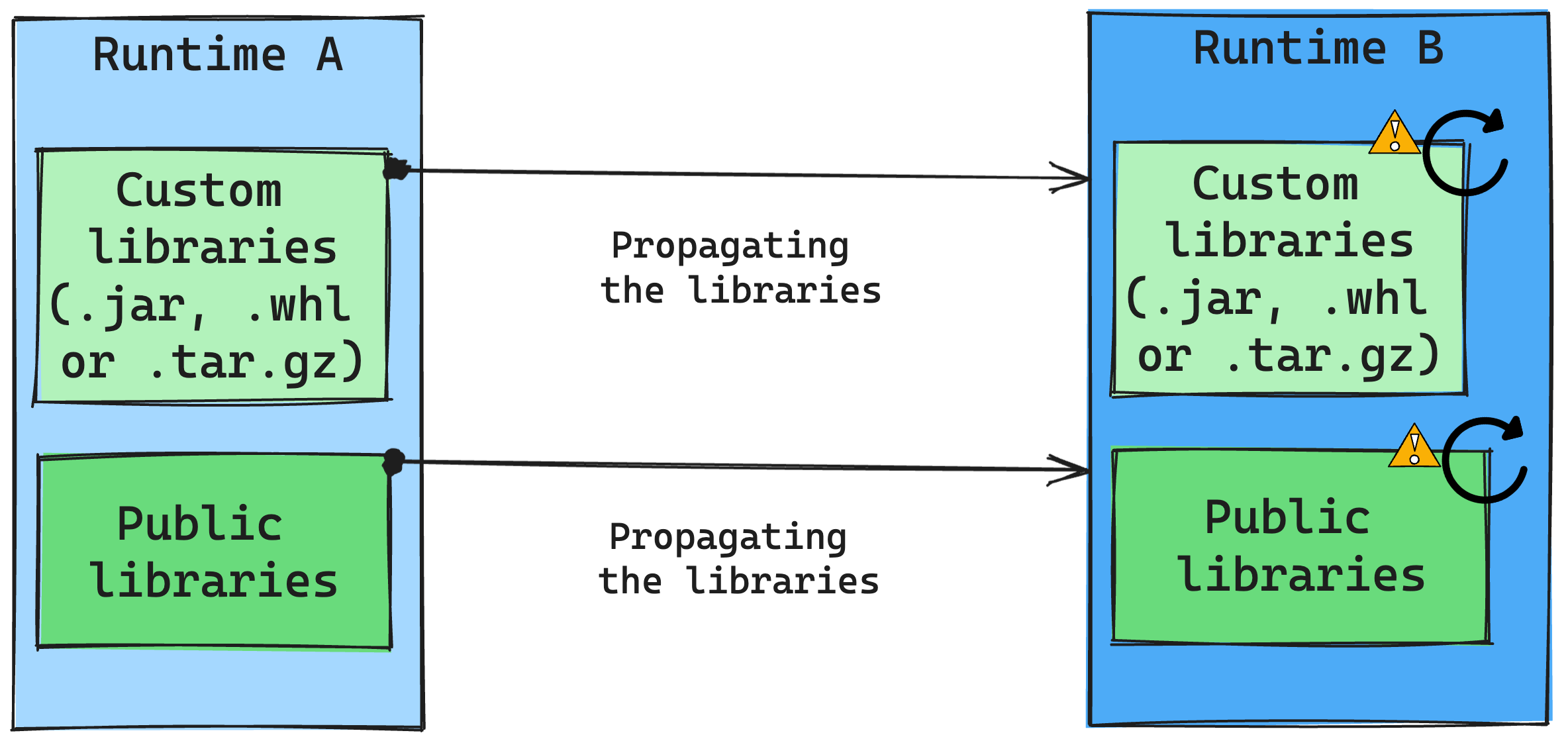
Konsekwencje zmian środowiska uruchomieniowego w zarządzaniu bibliotekami
Ogólnie rzecz biorąc, naszym podejściem jest migrowanie wszystkich bibliotek ze środowiska uruchomieniowego A do środowiska uruchomieniowego B, w tym publicznych i niestandardowych środowisk uruchomieniowych. Jeśli wersje języka Python i R pozostaną niezmienione, biblioteki powinny działać prawidłowo. Jednak w przypadku plików Jar istnieje znaczne prawdopodobieństwo, że może nie działać z powodu zmian w zależnościach oraz innych czynników, takich jak zmiany w języku Scala, Java, Spark i systemie operacyjnym.
Użytkownik jest odpowiedzialny za aktualizowanie lub zastępowanie wszystkich bibliotek, które nie działają z środowiskiem uruchomieniowym B. Jeśli wystąpi konflikt, co oznacza, że środowisko uruchomieniowe B zawiera bibliotekę zdefiniowaną pierwotnie w środowisku uruchomieniowym A, nasz system zarządzania biblioteką spróbuje utworzyć niezbędną zależność dla środowiska uruchomieniowego B na podstawie ustawień użytkownika. Jednak proces kompilacji zakończy się niepowodzeniem, jeśli wystąpi konflikt. W dzienniku błędów użytkownicy mogą zobaczyć, które biblioteki powodują konflikty, i wprowadzić zmiany w ich wersjach lub specyfikacji.
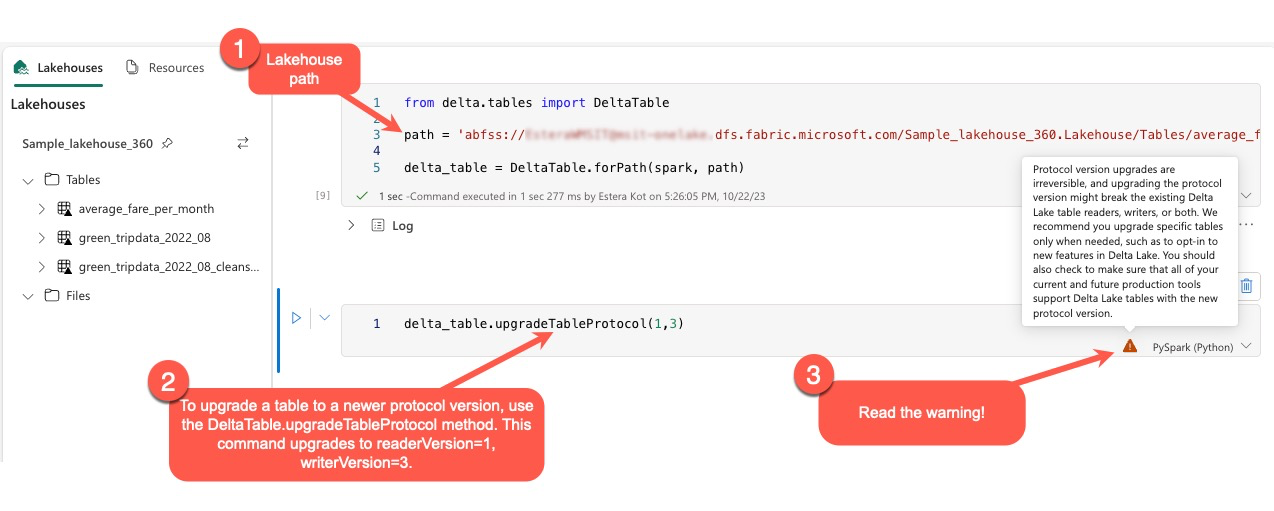
Uaktualnianie protokołu usługi Delta Lake
Funkcje usługi Delta Lake są zawsze zgodne z poprzednimi wersjami, dzięki czemu tabele utworzone w niższej wersji usługi Delta Lake mogą bezproblemowo współdziałać z wyższymi wersjami. Jeśli jednak niektóre funkcje są włączone (na przykład przy użyciu delta.upgradeTableProtocol(minReaderVersion, minWriterVersion) metody, zgodność z niższymi wersjami usługi Delta Lake może zostać naruszona. W takich przypadkach niezbędne jest zmodyfikowanie obciążeń odwołujących się do uaktualnionych tabel w celu dostosowania ich do wersji usługi Delta Lake, która utrzymuje zgodność.
Każda tabela delty jest skojarzona ze specyfikacją protokołu, definiując obsługiwane funkcje. Aplikacje, które wchodzą w interakcję z tabelą do odczytu lub zapisu, korzystają z tej specyfikacji protokołu, aby określić, czy są one zgodne z zestawem funkcji tabeli. Jeśli aplikacja nie ma możliwości obsługi funkcji wymienionej jako obsługiwana w protokole tabeli, nie może odczytać ani zapisać w tej tabeli.
Specyfikacja protokołu jest podzielona na dwa odrębne składniki: protokół odczytu i protokół zapisu. Odwiedź stronę "Jak usługa Delta Lake zarządza zgodnością funkcji?", aby przeczytać o nim szczegółowe informacje.

Użytkownicy mogą wykonywać polecenie delta.upgradeTableProtocol(minReaderVersion, minWriterVersion) w środowisku PySpark oraz w usługach Spark SQL i Scala. To polecenie umożliwia im zainicjowanie aktualizacji w tabeli delty.
Należy pamiętać, że podczas przeprowadzania tego uaktualnienia użytkownicy otrzymują ostrzeżenie wskazujące, że uaktualnienie wersji protokołu delta jest procesem niezweryfikowalnym. Oznacza to, że po wykonaniu aktualizacji nie można jej cofnąć.
Uaktualnienia wersji protokołu mogą potencjalnie mieć wpływ na zgodność istniejących czytników tabel usługi Delta Lake, składników zapisywania lub obu tych typów. Dlatego zaleca się zachowanie ostrożności i uaktualnienie wersji protokołu tylko wtedy, gdy jest to konieczne, na przykład podczas wdrażania nowych funkcji w usłudze Delta Lake.
Ponadto użytkownicy powinni sprawdzić, czy wszystkie bieżące i przyszłe obciążenia produkcyjne i procesy są zgodne z tabelami usługi Delta Lake przy użyciu nowej wersji protokołu, aby zapewnić bezproblemowe przejście i zapobiec potencjalnym zakłóceniom.
Zmiany delta 2.2 vs Delta 2.4
W najnowszym środowisku uruchomieniowym sieci Szkieletowej w wersji 1.3 i środowisku uruchomieniowym sieci szkieletowej w wersji 1.2 domyślny format tabeli (spark.sql.sources.default) to teraz delta. W poprzednich wersjach środowiska Fabric Runtime w wersji 1.1 i we wszystkich środowiskach Synapse Runtime dla platformy Apache Spark zawierających platformę Spark 3.3 lub nowszą domyślny format tabeli został zdefiniowany jako parquet. Zapoznaj się z tabelą ze szczegółami konfiguracji platformy Apache Spark, aby uzyskać różnice między usługą Azure Synapse Analytics i usługą Microsoft Fabric.
Wszystkie tabele utworzone przy użyciu języka Spark SQL, PySpark, Scala Spark i Spark R zawsze, gdy typ tabeli zostanie pominięty, domyślnie utworzy tabelę delta jako domyślną. Jeśli skrypty jawnie ustawią format tabeli, będzie to przestrzegane. Polecenie USING DELTA w narzędziu Spark create table commands staje się nadmiarowe.
Skrypty, które oczekują lub zakładają, że format tabeli parquet powinien zostać poprawiony. Następujące polecenia nie są obsługiwane w tabelach delty:
ANALYZE TABLE $partitionedTableName PARTITION (p1) COMPUTE STATISTICSALTER TABLE $partitionedTableName ADD PARTITION (p1=3)ALTER TABLE DROP PARTITIONALTER TABLE RECOVER PARTITIONSALTER TABLE SET SERDEPROPERTIESLOAD DATAINSERT OVERWRITE DIRECTORYSHOW CREATE TABLECREATE TABLE LIKE