Natywny aparat wykonywania dla platformy Spark sieci szkieletowej
Natywny aparat wykonywania to przełomowe rozszerzenie wykonywania zadań platformy Apache Spark w usłudze Microsoft Fabric. Ten wektoryzowany aparat optymalizuje wydajność i wydajność zapytań platformy Spark, uruchamiając je bezpośrednio w infrastrukturze typu lakehouse. Bezproblemowa integracja aparatu oznacza, że nie wymaga modyfikacji kodu i unika blokady dostawcy. Obsługuje ona interfejsy API platformy Apache Spark i jest zgodna ze środowiskiem Uruchomieniowym 1.3 (Apache Spark 3.5) i współpracuje zarówno z formatami Parquet, jak i Delta. Niezależnie od lokalizacji danych w usłudze OneLake lub w przypadku uzyskiwania dostępu do danych za pomocą skrótów aparat wykonywania natywnego maksymalizuje wydajność i wydajność.
Aparat wykonywania natywnego znacznie podnosi wydajność zapytań przy jednoczesnym zminimalizowaniu kosztów operacyjnych. Zapewnia niezwykłą szybkość, osiągając maksymalnie cztery razy szybszą wydajność w porównaniu z tradycyjnym systemem operacyjnym (oprogramowaniem typu open source) Spark, zweryfikowanym przez test porównawczy TPC-DS 1 TB. Aparat jest biegły w zarządzaniu szeroką gamą scenariuszy przetwarzania danych, począwszy od rutynowego pozyskiwania danych, zadań wsadowych i zadań ETL (wyodrębnianie, przekształcanie, ładowanie) do złożonych analiz danych i dynamicznych zapytań interakcyjnych. Użytkownicy korzystają z przyspieszonego czasu przetwarzania, zwiększonej przepływności i zoptymalizowanego wykorzystania zasobów.
Aparat wykonywania natywnego opiera się na dwóch kluczowych składnikach systemu operacyjnego: Velox, bibliotece przyspieszania bazy danych C++ wprowadzonej przez meta i Apache Gluten (inkubacja) — warstwie środkowej odpowiedzialnej za odciążanie aparatów SQL opartych na maszynach JVM do aparatów natywnych wprowadzonych przez intel.
Uwaga
Aparat wykonywania natywnego jest obecnie w publicznej wersji zapoznawczej. Aby uzyskać więcej informacji, zobacz bieżące ograniczenia. Zachęcamy do włączenia natywnego aparatu wykonawczego dla obciążeń bez dodatkowych kosztów. Będziesz korzystać z szybszego wykonywania zadań bez płacenia więcej — efektywnie płacisz mniej za tę samą pracę.
Kiedy należy używać aparatu wykonywania natywnego
Aparat wykonywania natywnego oferuje rozwiązanie do uruchamiania zapytań w zestawach danych na dużą skalę; Optymalizuje wydajność przy użyciu natywnych możliwości bazowych źródeł danych i zminimalizowania obciążenia związanego zwykle z przenoszeniem i serializacji danych w tradycyjnych środowiskach Spark. Aparat obsługuje różne operatory i typy danych, w tym agregację skrótów zbiorczych, sprzężenia zagnieżdżonej pętli emisji (BNLJ) i dokładne formaty znacznika czasu. Jednak aby w pełni korzystać z możliwości silnika, należy wziąć pod uwagę jego optymalne przypadki użycia:
- Aparat jest skuteczny podczas pracy z danymi w formatach Parquet i Delta, które mogą przetwarzać natywnie i wydajnie.
- Zapytania obejmujące skomplikowane przekształcenia i agregacje znacznie korzystają z możliwości przetwarzania kolumnowego i wektoryzacji aparatu.
- Zwiększenie wydajności jest najbardziej istotne w scenariuszach, w których zapytania nie wyzwalają mechanizmu rezerwowego, unikając nieobsługiwanych funkcji lub wyrażeń.
- Aparat jest dobrze dopasowany do zapytań intensywnie korzystających z obliczeń, a nie prostych lub powiązanych we/wy.
Aby uzyskać informacje na temat operatorów i funkcji obsługiwanych przez aparat wykonywania natywnego, zobacz dokumentację platformy Apache Gluten.
Włączanie aparatu wykonywania natywnego
Aby korzystać z pełnych możliwości natywnego aparatu wykonawczego w fazie zapoznawczej, niezbędne są określone konfiguracje. Poniższe procedury pokazują, jak aktywować tę funkcję dla notesów, definicji zadań platformy Spark i całych środowisk.
Ważne
Natywny aparat wykonywania obsługuje najnowszą wersję środowiska uruchomieniowego ogólnie dostępnego, czyli Runtime 1.3 (Apache Spark 3.5, Delta Lake 3.2). Wraz z wydaniem natywnego aparatu wykonawczego w środowisku Uruchomieniowym 1.3 obsługa poprzedniej wersji — Środowisko uruchomieniowe 1.2 (Apache Spark 3.4, Delta Lake 2.4) — zostało przerwane. Zachęcamy wszystkich klientów do uaktualnienia do najnowszego środowiska uruchomieniowego 1.3. Jeśli korzystasz z natywnego silnika wykonawczego w środowisku uruchomieniowym w wersji 1.2, natywne przyspieszenie wkrótce zostanie wyłączone.
Włącz na poziomie środowiska
Aby zapewnić jednolite zwiększenie wydajności, włącz natywny aparat wykonywania we wszystkich zadaniach i notesach skojarzonych ze środowiskiem:
Przejdź do ustawień środowiska.
Przejdź do obszaru Obliczenia platformy Spark.
Przejdź do karty Przyspieszanie .
Zaznacz pole wyboru z etykietą Włącz aparat wykonywania natywnego.
Zapisz i opublikuj zmiany.
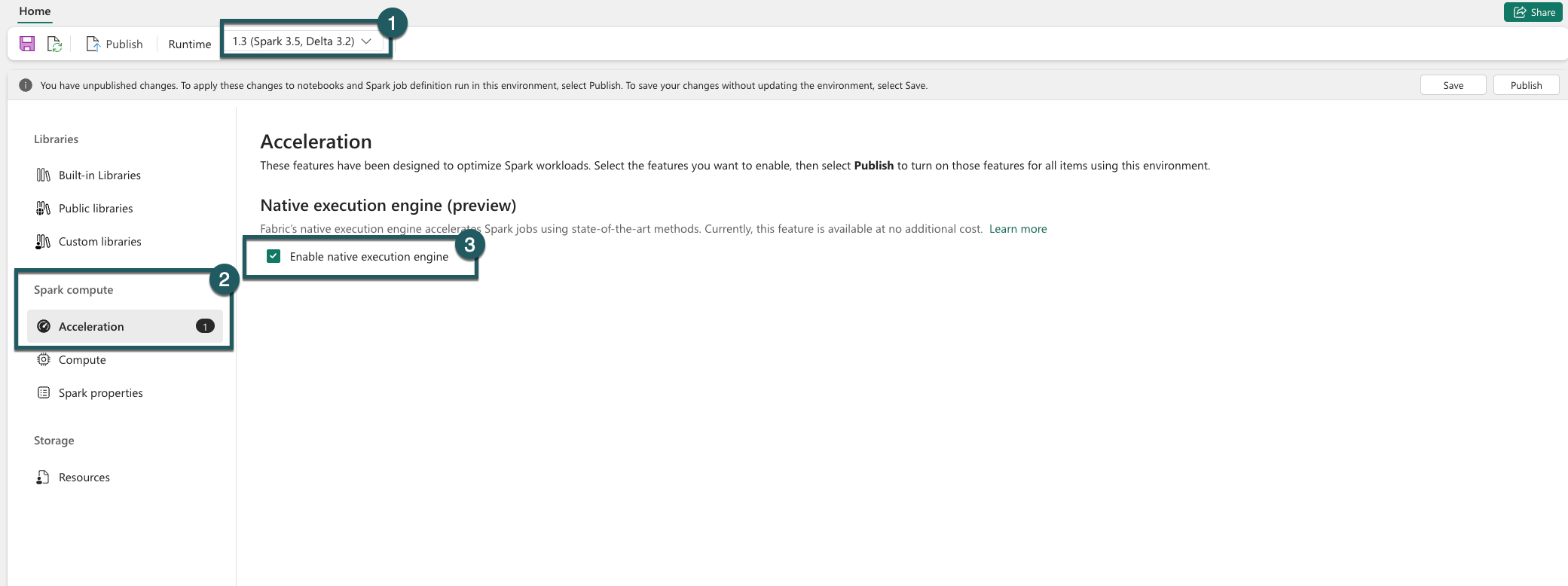

Po włączeniu na poziomie środowiska wszystkie kolejne zadania i notesy dziedziczą ustawienie. To dziedziczenie gwarantuje, że wszystkie nowe sesje lub zasoby utworzone w środowisku automatycznie korzystają z rozszerzonych możliwości wykonywania.
Ważne
Wcześniej aparat wykonywania natywnego był włączony za pomocą ustawień platformy Spark w ramach konfiguracji środowiska. Dzięki naszej najnowszej aktualizacji (w toku wdrażania) uprościliśmy ten proces, wprowadzając przycisk przełącznika na karcie Przyspieszanie ustawień środowiska. Ponownie włącz aparat wykonywania natywnego przy użyciu nowego przełącznika — aby kontynuować korzystanie z aparatu wykonywania natywnego, przejdź do karty Przyspieszanie w ustawieniach środowiska i włącz go za pomocą przycisku przełącznika. Nowe ustawienie przełącznika w interfejsie użytkownika ma teraz priorytet nad wszystkimi poprzednimi konfiguracjami właściwości platformy Spark. Jeśli wcześniej włączyłeś/lub włączyłaś Native Execution Engine za pomocą ustawień platformy Spark, zostaje on wyłączony do momentu ponownego włączenia za pomocą przełącznika w interfejsie użytkownika.
Włączanie dla notesu lub definicji zadania platformy Spark
Aby włączyć aparat wykonywania natywnego dla pojedynczego notesu lub definicji zadania platformy Spark, należy uwzględnić niezbędne konfiguracje na początku skryptu wykonywania:
%%configure
{
"conf": {
"spark.native.enabled": "true",
}
}
W przypadku notesów wstaw wymagane polecenia konfiguracji w pierwszej komórce. W przypadku definicji zadań platformy Spark uwzględnij konfiguracje w pierwszej linii definicji zadania platformy Spark. Aparat wykonywania natywnego jest zintegrowany z pulami na żywo, więc po włączeniu tej funkcji funkcja będzie obowiązywać natychmiast bez konieczności inicjowania nowej sesji.
Ważne
Przed rozpoczęciem sesji platformy Spark należy przeprowadzić konfigurację natywnego aparatu wykonawczego. Po rozpoczęciu spark.shuffle.manager sesji platformy Spark ustawienie stanie się niezmienne i nie można go zmienić. Upewnij się, że te konfiguracje są ustawione w %%configure bloku w notesach lub w konstruktorze sesji platformy Spark dla definicji zadań platformy Spark.
Kontrola na poziomie zapytania
Mechanizmy włączania aparatu wykonywania natywnego na poziomie dzierżawy, obszaru roboczego i środowiska, bezproblemowo zintegrowane z interfejsem użytkownika, są aktywnie opracowywane. W międzyczasie można wyłączyć natywny aparat wykonywania dla określonych zapytań, szczególnie jeśli obejmują operatory, które nie są obecnie obsługiwane (zobacz ograniczenia). Aby wyłączyć, ustaw wartość false dla określonej komórki zawierającej zapytanie, ustaw wartość spark.native.enabled na wartość false.
%%sql
SET spark.native.enabled=FALSE;

Po wykonaniu zapytania, w którym aparat wykonywania natywnego jest wyłączony, należy ponownie włączyć go dla kolejnych komórek, ustawiając wartość spark.native.enabled na true. Ten krok jest niezbędny, ponieważ platforma Spark wykonuje sekwencyjnie komórki kodu.
%%sql
SET spark.native.enabled=TRUE;
Identyfikowanie operacji wykonywanych przez aparat
Istnieje kilka metod określania, czy operator w zadaniu platformy Apache Spark został przetworzony przy użyciu natywnego aparatu wykonywania.
Interfejs użytkownika platformy Spark i serwer historii platformy Spark
Uzyskaj dostęp do serwera historii platformy Spark lub interfejsu użytkownika platformy Spark, aby zlokalizować zapytanie, które należy sprawdzić. Aby uzyskać dostęp do internetowego interfejsu użytkownika platformy Spark, przejdź do definicji zadania platformy Spark i uruchom go. Na zakładce Uruchomienia wybierz ... obok nazwy aplikacji i wybierz Otwórz internetowy interfejs użytkownika platformy Spark. Możesz również uzyskać dostęp do interfejsu użytkownika platformy Spark na karcie monitora

W planie zapytania wyświetlanym w interfejsie interfejsu użytkownika platformy Spark wyszukaj nazwy węzłów, które kończą się sufiksem Transformer, *NativeFileScan lub VeloxColumnarToRowExec. Sufiks wskazuje, że aparat wykonywania natywnego wykonał operację. Na przykład węzły mogą być oznaczone jako RollUpHashAggregateTransformer, ProjectExecTransformer, BroadcastHashJoinExecTransformer, ShuffledHashJoinExecTransformer lub BroadcastNestedLoopJoinExecTransformer.

Objaśnienie ramki danych
Alternatywnie możesz wykonać df.explain() polecenie w notesie, aby wyświetlić plan wykonania. W danych wyjściowych wyszukaj te same sufiksy Transformer, *NativeFileScan lub VeloxColumnarToRowExec. Ta metoda zapewnia szybki sposób potwierdzenia, czy określone operacje są obsługiwane przez natywny aparat wykonywania.

Mechanizm rezerwowy
W niektórych przypadkach aparat wykonywania natywnego może nie być w stanie wykonać zapytania z powodów, takich jak nieobsługiwane funkcje. W takich przypadkach operacja wraca do tradycyjnego aparatu Spark. Ten automatyczny mechanizm rezerwowania gwarantuje, że przepływ pracy nie będzie przerywany.


Monitorowanie zapytań i ramek danych wykonywanych przez aparat
Aby lepiej zrozumieć, jak aparat wykonywania natywnego jest stosowany do zapytań SQL i operacji ramki danych oraz przechodzenia do szczegółów poziomów etapów i operatorów, możesz zapoznać się z interfejsem użytkownika platformy Spark i serwerem historii platformy Spark, aby uzyskać bardziej szczegółowe informacje na temat wykonywania aparatu natywnego.
Karta Aparat wykonywania natywnego
Możesz przejść do nowej karty "Gluten SQL / DataFrame", aby wyświetlić informacje o kompilacji glutenu i szczegóły wykonywania zapytania. Tabela Query (Zapytania) zawiera szczegółowe informacje o liczbie węzłów uruchomionych w aucie natywnym i powracających do maszyny JVM dla każdego zapytania.

Wykres wykonywania zapytań
Możesz również wybrać opis zapytania dla wizualizacji planu wykonywania zapytań platformy Apache Spark. Wykres wykonywania zawiera natywne szczegóły wykonywania na różnych etapach i ich odpowiednich operacjach. Kolory tła odróżniają aparat wykonywania: zielony reprezentuje aparat wykonywania natywnego, a jasnoniebieski wskazuje, że operacja jest uruchomiona w domyślnym aucie JVM.

Ograniczenia
Aparat wykonywania natywnego zwiększa wydajność zadań platformy Apache Spark, ale zwróć uwagę na bieżące ograniczenia.
- Niektóre operacje specyficzne dla Delta nie są jeszcze obsługiwane (choć aktywnie nad tym pracujemy), w tym operacje scalania, skanowania punktów kontrolnych i wektory usunięcia.
- Niektóre funkcje i wyrażenia platformy Spark nie są zgodne z natywnym aparatem wykonywania, takimi jak funkcje zdefiniowane przez użytkownika (UDF) i
array_containsfunkcja, a także przesyłanie strumieniowe ze strukturą platformy Spark. Użycie tych niezgodnych operacji lub funkcji w ramach zaimportowanej biblioteki spowoduje również powrót do aparatu Spark. - Skanowanie z rozwiązań magazynowych korzystających z prywatnych punktów końcowych nie jest jeszcze obsługiwane, ale aktualnie nad tym aktywnie pracujemy.
- Aparat nie obsługuje trybu ANSI, więc wyszukuje i po włączeniu trybu ANSI automatycznie wraca do platformy Spark waniliowej.
W przypadku korzystania z filtrów dat w zapytaniach należy upewnić się, że typy danych po obu stronach porównania są zgodne, aby uniknąć problemów z wydajnością. Niezgodne typy danych mogą nie zwiększać wykonywania zapytań i mogą wymagać jawnego rzutu. Zawsze upewnij się, że typy danych po lewej stronie (LHS) i po prawej stronie (RHS) porównania są identyczne, ponieważ niezgodne typy nie zawsze będą automatycznie rzutowane. Jeśli niezgodność typu jest nieunikniona, użyj jawnego rzutowania, aby dopasować typy danych, takie jak CAST(order_date AS DATE) = '2024-05-20'. Zapytania z niezgodnymi typami danych, które wymagają konwersji rzutowej, nie będą przyspieszane przez Natywny Silnik Wykonawczy, dlatego zapewnienie spójności typów ma kluczowe znaczenie dla utrzymania wydajności. Na przykład zamiast order_date = '2024-05-20' gdzie order_date jest DATETIME i ciąg jest DATE, jawnie rzutuje order_date , aby DATE zapewnić spójne typy danych i poprawić wydajność.