Wskazówki dotyczące modelu DirectQuery w programie Power BI Desktop
W tym artykule elementy docelowe są modelami danych tworzącymi modele DirectQuery usługi Power BI opracowane przy użyciu programu Power BI Desktop lub usługa Power BI. W tym artykule opisano przypadki użycia zapytania bezpośredniego, ograniczenia i wskazówki. W szczególności wskazówki zostały zaprojektowane tak, aby ułatwić określenie, czy tryb DirectQuery jest odpowiednim trybem dla modelu, oraz w celu poprawy wydajności raportów na podstawie modeli DirectQuery. Ten artykuł dotyczy modeli DirectQuery hostowanych w usługa Power BI lub Serwer raportów usługi Power BI.
Ten artykuł nie jest przeznaczony do zapewnienia pełnej dyskusji na temat projektowania modelu DirectQuery. Aby zapoznać się z wprowadzeniem, zapoznaj się z artykułem Dotyczącym modeli Trybu DirectQuery w programie Power BI Desktop . Aby uzyskać bardziej szczegółowe informacje, zapoznaj się bezpośrednio z oficjalnym dokumentem trybu DirectQuery w usługach SQL Server 2016 Analysis Services . Należy pamiętać, że oficjalny dokument opisuje używanie trybu DirectQuery w usługach SQL Server Analysis Services. Jednak większość zawartości nadal ma zastosowanie do modeli DirectQuery usługi Power BI.
Uwaga
Aby zapoznać się z zagadnieniami dotyczącymi korzystania z trybu przechowywania trybu DirectQuery dla usługi Dataverse, zobacz Power BI modeling guidance for Power Platform (Wskazówki dotyczące modelowania usługi Power BI dla platformy Power Platform).
Ten artykuł nie obejmuje bezpośrednio modeli złożonych. Model złożony składa się z co najmniej jednego źródła DirectQuery i prawdopodobnie więcej. Wskazówki opisane w tym artykule są nadal istotne — przynajmniej częściowo — do projektowania modelu złożonego. Jednak implikacje łączenia tabel importu z tabelami DirectQuery nie są w zakresie tego artykułu. Aby uzyskać więcej informacji, zobacz Używanie modeli złożonych w programie Power BI Desktop.
Ważne jest, aby zrozumieć, że modele DirectQuery nakładają inne obciążenie na środowisko usługi Power BI (usługa Power BI lub Serwer raportów usługi Power BI), a także na bazowe źródła danych. Jeśli ustalisz, że tryb DirectQuery jest odpowiednim podejściem projektowym, zalecamy zaangażowanie odpowiednich osób w projekt. Często widzimy, że pomyślne wdrożenie modelu DirectQuery jest wynikiem ścisłej współpracy zespołu specjalistów IT. Zespół zwykle składa się z deweloperów modeli i administratorów źródłowej bazy danych. Może również obejmować architektów danych, magazyn danych i deweloperów ETL. Często optymalizacje muszą być stosowane bezpośrednio do źródła danych, aby osiągnąć dobre wyniki wydajności.
Optymalizowanie wydajności źródła danych
Źródło relacyjnej bazy danych można zoptymalizować na kilka sposobów, zgodnie z opisem na poniższej liście punktowanej.
Uwaga
Rozumiemy, że nie wszyscy modelujący mają uprawnienia lub umiejętności optymalizacji relacyjnej bazy danych. Chociaż preferowana jest warstwa przygotowania danych do modelu DirectQuery, niektóre optymalizacje można również osiągnąć w projekcie modelu bez modyfikowania źródłowej bazy danych. Jednak najlepsze wyniki optymalizacji są często osiągane przez zastosowanie optymalizacji do źródłowej bazy danych.
Upewnij się, że integralność danych jest kompletna: szczególnie ważne jest, aby tabele wymiarów zawierały kolumnę unikatowych wartości (klucz wymiaru), które są mapujące na tabele faktów. Ważne jest również, aby kolumny wymiarów typu faktów zawierały prawidłowe wartości klucza wymiaru. Umożliwią one skonfigurowanie bardziej wydajnych relacji modelu, które oczekują dopasowanych wartości po obu stronach relacji. Gdy dane źródłowe nie mają integralności, zaleca się dodanie "nieznanego" rekordu wymiaru w celu skutecznego naprawiania danych. Możesz na przykład dodać wiersz do tabeli Product w celu reprezentowania nieznanego produktu, a następnie przypisać mu klucz poza zakresem, taki jak -1. Jeśli wiersze w tabeli Sales zawierają brakującą wartość klucza produktu, zastąp je wartością -1. Gwarantuje to, że każda wartość klucza produktu Sales ma odpowiedni wiersz w tabeli Product .
Dodawanie indeksów: Zdefiniuj odpowiednie indeksy — w tabelach lub widokach — aby obsługiwać efektywne pobieranie danych dla oczekiwanego filtrowania i grupowania wizualizacji raportu. Aby uzyskać przydatne informacje na temat wskazówek dotyczących projektowania indeksów, zobacz Sql Server Index Architecture and Design Guide (Przewodnik projektowania i architektury indeksu programu SQL Server) w usługach Azure SQL Server Database lub Azure Synapse Analytics (dawniej SQL Data Warehouse). W przypadku nietrwałych źródeł programu SQL Server lub usługi Azure SQL Database zobacz Wprowadzenie do magazynu kolumn na potrzeby analizy operacyjnej w czasie rzeczywistym.
Projektowanie tabel rozproszonych: w przypadku źródeł usługi Azure Synapse Analytics (dawniej SQL Data Warehouse), które używają architektury masowego przetwarzania równoległego (MPP), należy rozważyć skonfigurowanie dużych tabel faktów jako rozproszonych skrótów i tabel wymiarów do replikacji we wszystkich węzłach obliczeniowych. Aby uzyskać więcej informacji, zobacz Wskazówki dotyczące projektowania tabel rozproszonych w usłudze Azure Synapse Analytics (dawniej SQL Data Warehouse).
Upewnij się, że wymagane przekształcenia danych są zmaterializowane: w przypadku źródeł relacyjnych baz danych programu SQL Server (i innych źródeł relacyjnych baz danych) do tabel można dodać obliczone kolumny. Te kolumny są oparte na wyrażeniu, na przykład Ilość pomnożona przez jednostkęPrice. Obliczone kolumny mogą być utrwalane (zmaterializowane) i, takie jak zwykłe kolumny, czasami mogą być indeksowane. Aby uzyskać więcej informacji, zobacz Indeksy w kolumnach obliczanych.
Rozważ również indeksowane widoki, które mogą wstępnie agregować dane tabeli faktów w większym stopniu. Jeśli na przykład tabela Sales przechowuje dane na poziomie wiersza zamówienia, możesz utworzyć widok podsumowujący te dane. Widok może być oparty na instrukcji SELECT, która grupuje dane tabeli Sales według daty (na poziomie miesiąca), klienta, produktu i podsumowania wartości miar, takich jak sprzedaż, ilość itp. Następnie można indeksować widok. W przypadku źródeł programu SQL Server lub usługi Azure SQL Database zobacz Tworzenie widoków indeksowanych.
Materializowanie tabeli dat: typowe wymaganie modelowania obejmuje dodanie tabeli dat do obsługi filtrowania opartego na czasie. Aby obsługiwać znane filtry oparte na czasie w organizacji, utwórz tabelę w źródłowej bazie danych i upewnij się, że jest załadowana z zakresem dat obejmujących daty tabeli faktów. Upewnij się również, że zawiera kolumny dla przydatnych okresów, takich jak rok, kwartał, miesiąc, tydzień itp.
Optymalizowanie projektu modelu
Model DirectQuery można zoptymalizować na wiele sposobów, zgodnie z opisem na poniższej liście punktowanej.
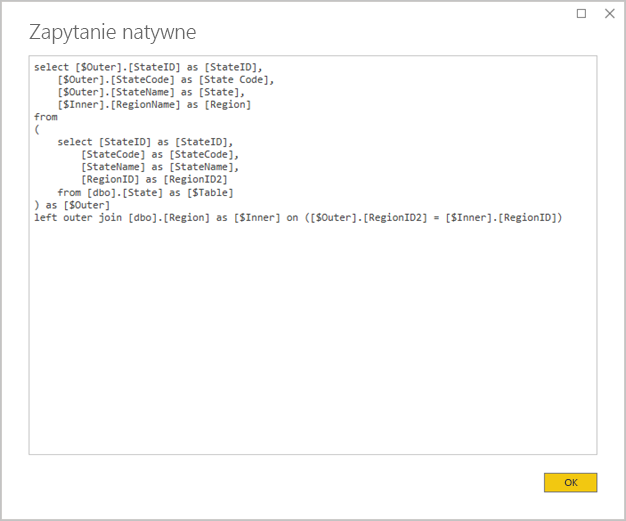
Unikaj złożonych zapytań Dodatku Power Query: wydajny projekt modelu można osiągnąć, usuwając konieczność stosowania dowolnych przekształceń przez zapytania Power Query. Oznacza to, że każde zapytanie mapuje na jedną tabelę źródłową lub widok relacyjnej bazy danych. Możesz wyświetlić podgląd rzeczywistej instrukcji zapytania SQL dla zastosowanego kroku dodatku Power Query, wybierając opcję Wyświetl zapytanie natywne.
Sprawdź użycie kolumn obliczeniowych i zmian typu danych: modele DirectQuery obsługują dodawanie obliczeń i kroków dodatku Power Query w celu konwertowania typów danych. Jednak lepsza wydajność jest często osiągana przez materializowanie wyników transformacji w relacyjnym źródle bazy danych, jeśli jest to możliwe.
Nie używaj filtrowania dat względnych dodatku Power Query: można zdefiniować filtrowanie dat względnych w zapytaniu Power Query. Na przykład aby pobrać do zamówień sprzedaży utworzonych w ostatnim roku (względem dzisiejszej daty). Ten typ filtru przekłada się na nieefektywne zapytanie natywne w następujący sposób:
… from [dbo].[Sales] as [_] where [_].[OrderDate] >= convert(datetime2, '2018-01-01 00:00:00') and [_].[OrderDate] < convert(datetime2, '2019-01-01 00:00:00'))Lepszym podejściem projektowym jest uwzględnienie kolumn czasu względnego w tabeli dat. Te kolumny przechowują wartości przesunięcia względem bieżącej daty. Na przykład w kolumnie RelativeYear wartość zero reprezentuje bieżący rok, -1 reprezentuje poprzedni rok itp. Najlepiej kolumna RelativeYear jest zmaterializowana w tabeli dat. Chociaż mniej wydajne, można go również dodać jako kolumnę obliczeniową modelu na podstawie wyrażenia przy użyciu funkcji JĘZYKA DAX TODAY i DATE .
Zachowaj proste miary: przynajmniej początkowo zaleca się ograniczenie miar do prostych agregacji. Funkcje agregujące obejmują SUM, COUNT, MIN, MAX i AVERAGE. Następnie, jeśli miary są wystarczająco dynamiczne, możesz eksperymentować z bardziej złożonymi miarami, ale zwracając uwagę na wydajność każdego z nich. Funkcja CALCULATE języka DAX może służyć do tworzenia zaawansowanych wyrażeń miar, które manipulują kontekstem filtru, ale mogą generować kosztowne zapytania natywne, które nie działają prawidłowo.
Unikaj relacji w kolumnach obliczeniowych: relacje modelu mogą powiązać tylko jedną kolumnę w jednej tabeli z jedną kolumną w innej tabeli. Czasami jednak konieczne jest powiązanie tabel przy użyciu wielu kolumn. Na przykład tabele Sales (Sprzedaż) i Geography (Geografia) są powiązane z dwiema kolumnami: CountryRegion (KrajRegion) i City (Miasto). Aby utworzyć relację między tabelami, wymagana jest pojedyncza kolumna, a w tabeli Geography (Geografia ) kolumna musi zawierać unikatowe wartości. Połączenie kraju/regionu i miasta z separatorem łącznika może osiągnąć ten wynik.
Kolumnę połączoną można utworzyć przy użyciu kolumny niestandardowej dodatku Power Query lub w modelu jako kolumny obliczeniowej. Należy go jednak unikać, ponieważ wyrażenie obliczeniowe zostanie osadzone w zapytaniach źródłowych. Nie tylko jest nieefektywny, często uniemożliwia korzystanie z indeksów. Zamiast tego dodaj zmaterializowane kolumny w źródle relacyjnej bazy danych i rozważ ich indeksowanie. Możesz również rozważyć dodanie kolumn kluczy zastępczych do tabel wymiarów, co jest powszechną praktyką w projektach relacyjnych magazynów danych.
Istnieje jeden wyjątek od tych wskazówek i dotyczy korzystania z funkcji JĘZYKA DAX COMBINEVALUES . Celem tej funkcji jest obsługa relacji modelu wielokolumnach. Zamiast generować wyrażenie używane przez relację, generuje wielokolumny predykat sprzężenia SQL.
Unikaj relacji w kolumnach "Unikatowy identyfikator": usługa Power BI nie obsługuje natywnie typu danych unikatowego identyfikatora (GUID). Podczas definiowania relacji między kolumnami tego typu usługa Power BI generuje zapytanie źródłowe ze sprzężeniami obejmującymi rzutowanie. Ta konwersja danych w czasie zapytania często skutkuje niską wydajnością. Dopóki ten przypadek nie zostanie zoptymalizowany, jedynym obejściem jest zmaterializowanie kolumn alternatywnego typu danych w bazowej bazie danych.
Ukryj jednostronną kolumnę relacji: jednostronna kolumna relacji powinna być ukryta. (Zazwyczaj jest to kolumna klucza podstawowego tabel wymiarów). Po ukryciu nie jest ona dostępna w okienku Pola i nie można jej używać do konfigurowania wizualizacji. Kolumna wiele stron może pozostać widoczna, jeśli jest przydatna do grupowania lub filtrowania raportów według wartości kolumn. Rozważmy na przykład model, w którym istnieje relacja między tabelami Sales i Product . Kolumny relacji zawierają wartości jednostki SKU produktu (jednostka przechowywania zapasów). Jeśli jednostka SKU produktu musi zostać dodana do wizualizacji, powinna być widoczna tylko w tabeli Sales . Gdy ta kolumna jest używana do filtrowania lub grupowania w wizualizacji, usługa Power BI generuje zapytanie, które nie musi łączyć tabel Sales i Product .
Ustaw relacje, aby wymusić integralność: właściwość Przyjmij integralność referencyjną relacji zapytania bezpośredniego określa, czy usługa Power BI generuje zapytania źródłowe przy użyciu sprzężenia wewnętrznego, a nie sprzężenia zewnętrznego. Ogólnie poprawia wydajność zapytań, chociaż zależy od specyfiki źródła relacyjnej bazy danych. Aby uzyskać więcej informacji, zobacz Przyjmij ustawienia integralności referencyjnej w programie Power BI Desktop.
Unikaj używania filtrowania relacji dwukierunkowych: korzystanie z filtrowania relacji dwukierunkowych może prowadzić do wykonywania instrukcji zapytań, które nie działają prawidłowo. Tej funkcji relacji należy używać tylko wtedy, gdy jest to konieczne, i zwykle jest to przypadek podczas implementowania relacji wiele-do-wielu w tabeli pomostowej. Aby uzyskać więcej informacji, zobacz Relacje z kardynalnością wiele-do-wielu w programie Power BI Desktop.
Ogranicz zapytania równoległe: dla każdego bazowego źródła danych można ustawić maksymalną liczbę połączeń, które są otwierane w trybie DirectQuery. Steruje ona liczbą zapytań wysyłanych współbieżnie do źródła danych.
- To ustawienie jest włączone tylko wtedy, gdy w modelu znajduje się co najmniej jedno źródło DirectQuery. Wartość ma zastosowanie do wszystkich źródeł trybu DirectQuery oraz do wszystkich nowych źródeł directQuery dodanych do modelu.
- Zwiększenie wartości Maksymalna liczba połączeń na źródło danych zapewnia wysyłanie większej liczby zapytań (maksymalnie określonej liczby) do bazowego źródła danych, co jest przydatne, gdy wiele wizualizacji znajduje się na jednej stronie lub wielu użytkowników uzyskuje dostęp do raportu w tym samym czasie. Po osiągnięciu maksymalnej liczby połączeń kolejne zapytania są kolejkowane do momentu udostępnienia połączenia. Zwiększenie tego limitu powoduje większe obciążenie bazowego źródła danych, więc ustawienie nie ma gwarancji poprawy ogólnej wydajności.
- Po opublikowaniu modelu w usłudze Power BI maksymalna liczba współbieżnych zapytań wysyłanych do bazowego źródła danych zależy również od środowiska. Różne środowiska (takie jak Power BI, Power BI Premium lub Serwer raportów usługi Power BI) mogą nakładać różne ograniczenia przepływności. Aby uzyskać więcej informacji na temat ograniczeń zasobów pojemności, zobacz Licencje pojemności usługi Microsoft Fabric i Konfigurowanie pojemności i zarządzanie nimi w usłudze Power BI Premium.
Ważne
Czasami w tym artykule opisano usługę Power BI Premium lub jej subskrypcje pojemności (jednostki SKU P). Należy pamiętać, że firma Microsoft obecnie konsoliduje opcje zakupu i cofnie usługę Power BI Premium na jednostki SKU pojemności. Nowi i istniejący klienci powinni rozważyć zakup subskrypcji pojemności sieci szkieletowej (jednostki SKU F).
Aby uzyskać więcej informacji, zobacz Ważne aktualizacje dostępne w licencjonowaniu usługi Power BI Premium i Power BI Premium — często zadawane pytania.
Optymalizowanie projektów raportów
Raporty oparte na semantycznym modelu DirectQuery można zoptymalizować na wiele sposobów, zgodnie z opisem na poniższej liście punktowanej.
- Włącz techniki redukcji zapytań: Opcje i ustawienia programu Power BI Desktop zawierają stronę Redukcji zapytań. Ta strona ma trzy przydatne opcje. Można domyślnie wyłączyć wyróżnianie krzyżowe i filtrowanie krzyżowe, chociaż można je zastąpić przez edytowanie interakcji. Można również wyświetlić przycisk Zastosuj we fragmentatorach i filtrach. Opcje fragmentatora lub filtru nie zostaną zastosowane, dopóki użytkownik raportu nie kliknie przycisku. Jeśli włączysz te opcje, zalecamy wykonanie tej czynności podczas pierwszego tworzenia raportu.
- Najpierw zastosuj filtry: podczas pierwszego projektowania raportów zalecamy zastosowanie wszelkich odpowiednich filtrów — na poziomie raportu, strony lub wizualizacji — przed mapowaniem pól do pól wizualizacji. Na przykład zamiast przeciągać miar CountryRegion i Sales , a następnie filtrować według określonego roku, najpierw zastosuj filtr w polu Rok . Jest to spowodowane tym, że każdy krok tworzenia wizualizacji wyśle zapytanie i chociaż można wprowadzić kolejną zmianę przed ukończeniem pierwszego zapytania, nadal powoduje niepotrzebne obciążenie bazowego źródła danych. Wczesne stosowanie filtrów sprawia, że te zapytania pośrednie są mniej kosztowne i szybsze. Ponadto niepowodzenie stosowania filtrów na początku może spowodować przekroczenie limitu 1 miliona wierszy, zgodnie z opisem w temacie DirectQuery.
- Ogranicz liczbę wizualizacji na stronie: po otwarciu strony raportu (i zastosowaniu filtrów stron) wszystkie wizualizacje na stronie są odświeżane. Istnieje jednak limit liczby zapytań, które mogą być wysyłane równolegle, narzucone przez środowisko usługi Power BI i ustawienie modelu Maksymalna liczba połączeń na źródło danych, zgodnie z powyższym opisem. W miarę zwiększania się liczby wizualizacji strony istnieje większe prawdopodobieństwo, że zostaną odświeżone w sposób seryjny. Zwiększa to czas potrzebny na odświeżenie całej strony, a także zwiększa prawdopodobieństwo, że wizualizacje mogą wyświetlać niespójne wyniki (w przypadku nietrwałych źródeł danych). Z tych powodów zaleca się ograniczenie liczby wizualizacji na dowolnej stronie i zamiast tego ma prostsze strony. Zamiana wielu wizualizacji kart na jedną wizualizację karty wielowierszowej może osiągnąć podobny układ strony.
- Wyłącz interakcję między wizualizacjami: interakcje wyróżniania krzyżowego i filtrowania krzyżowego wymagają przesłania zapytań do bazowego źródła. Jeśli te interakcje nie są konieczne, zaleca się ich wyłączenie, jeśli czas potrzebny na reagowanie na wybory użytkowników byłby zbyt długi. Te interakcje można wyłączyć dla całego raportu (zgodnie z powyższym opisem w przypadku opcji redukcji zapytań) lub w zależności od przypadku. Aby uzyskać więcej informacji, zobacz Jak wizualizacje filtrować krzyżowo w raporcie usługi Power BI.
Oprócz powyższej listy technik optymalizacji każda z następujących funkcji raportowania może przyczynić się do problemów z wydajnością:
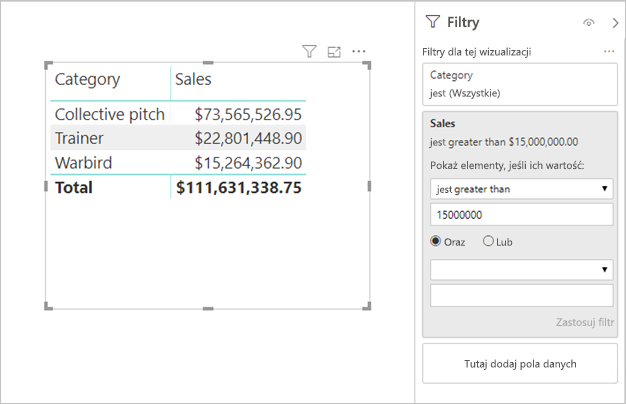
Filtry miar: wizualizacje zawierające miary (lub agregacje kolumn) mogą mieć filtry stosowane do tych miar. Na przykład poniższa wizualizacja pokazuje sprzedaż według kategorii, ale tylko dla kategorii z ponad 15 milionami dolarów sprzedaży.
Może to spowodować wysłanie dwóch zapytań do bazowego źródła:
- Pierwsze zapytanie pobierze kategorie spełniające warunek (sprzedaż > 15 milionów USD)
- Drugie zapytanie pobierze następnie niezbędne dane dla wizualizacji, dodając kategorie spełniające warunek do klauzuli WHERE
Zazwyczaj działa prawidłowo, jeśli istnieją setki lub tysiące kategorii, jak w tym przykładzie. Wydajność może jednak obniżyć się, jeśli liczba kategorii jest znacznie większa (i rzeczywiście zapytanie zakończy się niepowodzeniem, jeśli istnieje ponad 1 milion kategorii spełniających warunek, ze względu na limit 1 miliona wierszy opisany powyżej).
Filtry TopN: Filtry zaawansowane można zdefiniować tak, aby filtrować tylko na pierwszych (lub dolnych) N wartości sklasyfikowanych według miary. Aby na przykład wyświetlić tylko pięć pierwszych kategorii w powyższej wizualizacji. Podobnie jak w przypadku filtrów miar, spowoduje to również wysłanie dwóch zapytań do bazowego źródła danych. Jednak pierwsze zapytanie zwróci wszystkie kategorie z bazowego źródła, a następnie pierwsze N są określane na podstawie zwróconych wyników. W zależności od kardynalności zaangażowanej kolumny może to prowadzić do problemów z wydajnością (lub niepowodzeń zapytań z powodu limitu 1 miliona wierszy).
Mediana: ogólnie wszystkie agregacje (Suma, Liczba unikatowych itp.) są wypychane do bazowego źródła. Nie jest to jednak prawdziwe w przypadku mediany, ponieważ ta agregacja nie jest obsługiwana przez bazowe źródło. W takich przypadkach szczegółowe dane są pobierane z bazowego źródła, a usługa Power BI ocenia medianę zwróconych wyników. Jest to w porządku, gdy mediana ma być obliczana na stosunkowo małej liczbie wyników, ale problemy z wydajnością (lub niepowodzenia zapytań z powodu limitu 1 miliona wierszy) wystąpią, jeśli kardynalność jest duża. Na przykład mediana populacji kraju/regionu może być rozsądna, ale mediana ceny sprzedaży może nie być.
Fragmentatory wielokrotnego wyboru: umożliwianie wielokrotnego wyboru we fragmentatorach i filtrach może powodować problemy z wydajnością. Dzieje się tak dlatego, że gdy użytkownik wybiera dodatkowe elementy fragmentatora (na przykład tworząc do 10 zainteresowanych produktów), każde nowe zaznaczenie powoduje wysłanie nowego zapytania do bazowego źródła. Gdy użytkownik może wybrać następny element przed ukończeniem zapytania, powoduje to dodatkowe obciążenie bazowego źródła. Tę sytuację można uniknąć, wyświetlając przycisk Zastosuj zgodnie z powyższym opisem w technikach redukcji zapytań.
Sumy wizualne: domyślnie tabele i macierze wyświetlają sumy i sumy częściowe. W wielu przypadkach dodatkowe zapytania muszą być wysyłane do bazowego źródła, aby uzyskać wartości sum. Stosuje się je za każdym razem, gdy używasz agregacji Count Distinct lub Median, a w każdym przypadku korzystania z trybu DirectQuery za pośrednictwem platformy SAP HANA lub SAP Business Warehouse. Takie sumy należy wyłączyć (przy użyciu okienka Format), jeśli nie jest to konieczne.
Konwertowanie na model złożony
Zalety modeli Import i DirectQuery można połączyć w jeden model, konfigurując tryb przechowywania tabel modelu. Tryb przechowywania tabel może mieć wartość Import lub DirectQuery albo oba te tryby, nazywane podwójnymi. Gdy model zawiera tabele z różnymi trybami przechowywania, jest znany jako model złożony. Aby uzyskać więcej informacji, zobacz Używanie modeli złożonych w programie Power BI Desktop.
Istnieje wiele ulepszeń funkcjonalności i wydajności, które można osiągnąć, konwertując model DirectQuery na model złożony. Model złożony może integrować więcej niż jedno źródło DirectQuery i może również zawierać agregacje. Tabele agregacji można dodać do tabel DirectQuery w celu zaimportowania podsumowanej reprezentacji tabeli. Mogą one osiągnąć znaczne ulepszenia wydajności, gdy wizualizacje wysyłają zapytania na wyższym poziomie agregacji. Aby uzyskać więcej informacji, zobacz Agregacje w programie Power BI Desktop.
Edukuj użytkowników
Ważne jest, aby edukować użytkowników, jak wydajnie pracować z raportami na podstawie modeli semantycznych DirectQuery. Autorzy raportów powinni być informowani o zawartości opisanej w sekcji Optymalizowanie projektów raportów .
Zalecamy informowanie użytkowników raportów o raportach opartych na modelach semantycznych trybu DirectQuery. Przydatne może być zrozumienie ogólnej architektury danych, w tym wszelkich odpowiednich ograniczeń opisanych w tym artykule. Poinformuj ich, że odpowiedzi odświeżania i filtrowanie interakcyjne mogą czasami działać wolno. Gdy użytkownicy raportu rozumieją, dlaczego występuje spadek wydajności, mniej prawdopodobne jest, aby utracić zaufanie do raportów i danych.
Podczas dostarczania raportów dotyczących nietrwałych źródeł danych należy informować użytkowników raportów o użyciu przycisku Odśwież. Poinformuj ich również, że może być możliwe wyświetlenie niespójnych wyników i że odświeżanie raportu może rozwiązać wszelkie niespójności na stronie raportu.
Powiązana zawartość
Aby uzyskać więcej informacji na temat trybu DirectQuery, zapoznaj się z następującymi zasobami: