Uwaga
Dostęp do tej strony wymaga autoryzacji. Może spróbować zalogować się lub zmienić katalogi.
Dostęp do tej strony wymaga autoryzacji. Możesz spróbować zmienić katalogi.
Dotyczy:![]() SQL Server
SQL Server![]() Azure SQL Database
Azure SQL Database![]() Azure SQL Managed Instance
Azure SQL Managed Instance![]() SQL Database w Microsoft Fabric
SQL Database w Microsoft Fabric
Program SQL Server 2016 (13.x) wprowadza analizę operacyjną w czasie rzeczywistym, możliwość uruchamiania zarówno obciążeń analitycznych, jak i OLTP w tych samych tabelach bazy danych w tym samym czasie. Oprócz uruchamiania analiz w czasie rzeczywistym można również wyeliminować potrzebę etl i magazynu danych.
Analiza operacyjna w czasie rzeczywistym — objaśniona
Tradycyjnie firmy miały oddzielne systemy operacyjne (czyli OLTP) i obciążenia analityczne. W przypadku takich systemów zadania wyodrębniania, przekształcania i ładowania (ETL) regularnie przenoszą dane z magazynu operacyjnego do magazynu analitycznego. Dane analityczne są zwykle przechowywane w magazynie danych lub składce danych przeznaczonej do uruchamiania zapytań analitycznych. Chociaż to rozwiązanie było standardem, ma trzy kluczowe wyzwania:
- Złożoność. Implementowanie etL może wymagać znacznego kodowania, szczególnie w celu załadowania tylko zmodyfikowanych wierszy. Może to być złożone, aby określić, które wiersze zostały zmodyfikowane.
- Koszt Implementacja ETL wymaga kosztu zakupu dodatkowych licencji sprzętowych i oprogramowania.
- Opóźnienie danych. Implementowanie funkcji ETL dodaje opóźnienie czasu na potrzeby uruchamiania analizy. Jeśli na przykład zadanie ETL zostanie uruchomione na końcu każdego dnia roboczego, zapytania analityczne będą uruchamiane na danych, które mają co najmniej jeden dzień. W przypadku wielu firm opóźnienie jest niedopuszczalne, ponieważ firma zależy od analizowania danych w czasie rzeczywistym. Na przykład wykrywanie oszustw wymaga analizy danych operacyjnych w czasie rzeczywistym.
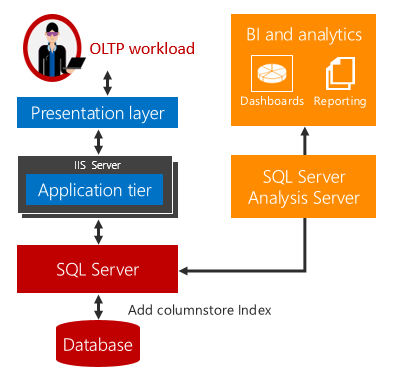
Analiza operacyjna w czasie rzeczywistym oferuje rozwiązanie tych wyzwań.
Nie ma opóźnienia czasu, gdy obciążenia analizy i OLTP są uruchamiane w tej samej tabeli bazowej. W przypadku scenariuszy, które mogą korzystać z analizy w czasie rzeczywistym, koszty i złożoność są znacznie mniejsze, eliminując potrzebę etl i potrzebę zakupu i obsługi oddzielnego magazynu danych.
Uwaga
Analiza operacyjna w czasie rzeczywistym jest przeznaczona dla scenariusza pojedynczego źródła danych, takiego jak aplikacja do planowania zasobów przedsiębiorstwa (ERP), na której można uruchamiać zarówno obciążenie operacyjne, jak i analityczne. Nie zastępuje to potrzeby oddzielnego magazynu danych, gdy trzeba zintegrować dane z wielu źródeł przed uruchomieniem obciążenia analitycznego lub gdy wymagana jest ekstremalna wydajność analizy przy użyciu wstępnie zagregowanych danych, takich jak moduły.
Analiza w czasie rzeczywistym używa indeksu magazynu kolumn nieklastrowanego z możliwością aktualizacji w tabeli magazynu wierszy. Indeks magazynu kolumn przechowuje kopię danych, więc obciążenia OLTP i analityczne są uruchamiane względem oddzielnych kopii danych. Minimalizuje to wpływ na wydajność obu obciążeń uruchomionych w tym samym czasie. Aparat bazy danych automatycznie zachowuje zmiany indeksu, dzięki czemu zmiany OLTP są zawsze up-to-date na potrzeby analizy. Dzięki temu projektowi możliwe jest i praktyczne uruchamianie analiz w czasie rzeczywistym na up-todanych daty. Działa to zarówno w przypadku tabel opartych na dyskach, jak i zoptymalizowanych pod kątem pamięci.
Przykład rozpoczynania pracy
Aby rozpocząć pracę z analizą w czasie rzeczywistym:
Zidentyfikuj tabele w schemacie operacyjnym, które zawierają dane wymagane do analizy.
Dla każdej tabeli porzucaj wszystkie indeksy drzewa B, które zostały zaprojektowane głównie w celu przyspieszenia istniejącej analizy obciążenia OLTP. Zastąp je pojedynczym nieklastrowanym indeksem magazynu kolumnowego. Może to poprawić ogólną wydajność obciążenia OLTP, ponieważ istnieje mniej indeksów do utrzymania.
--This example creates a nonclustered columnstore index on an existing OLTP table. --Create the table CREATE TABLE t_account ( accountkey int PRIMARY KEY, accountdescription nvarchar (50), accounttype nvarchar(50), unitsold int ); --Create the columnstore index with a filtered condition CREATE NONCLUSTERED COLUMNSTORE INDEX account_NCCI ON t_account (accountkey, accountdescription, unitsold) ;Indeks magazynu kolumn w tabeli zoptymalizowanej pod kątem pamięci umożliwia analizę operacyjną dzięki integracji technologii OLTP w pamięci i magazynu kolumn w celu zapewnienia wysokiej wydajności zarówno dla obciążeń OLTP, jak i analitycznych. Indeks magazynowy kolumn w tabeli zoptymalizowanej pod kątem pamięci musi być indeksem klastrowanym, innymi słowy musi zawierać wszystkie kolumny.
-- This example creates a memory-optimized table with a columnstore index. CREATE TABLE t_account ( accountkey int NOT NULL PRIMARY KEY NONCLUSTERED, Accountdescription nvarchar (50), accounttype nvarchar(50), unitsold int, INDEX t_account_cci CLUSTERED COLUMNSTORE ) WITH (MEMORY_OPTIMIZED = ON );
Teraz możesz uruchomić analizę operacyjną w czasie rzeczywistym bez wprowadzania żadnych zmian w aplikacji. Zapytania analityczne będą uruchamiane względem indeksu magazynu kolumn, a operacje OLTP będą nadal działać względem indeksów drzewa B-tree OLTP. Obciążenia OLTP nadal działają efektywnie, ale wiążą się z pewnymi dodatkowymi kosztami w celu utrzymania indeksu kolumnowego. Zobacz optymalizacje wydajności w następnej sekcji.
Wpisy w blogu
Przeczytaj następujące wpisy w blogu, aby dowiedzieć się więcej o analizie operacyjnej w czasie rzeczywistym. Jeśli najpierw przyjrzysz się wpisom w blogu, łatwiej zrozumieć sekcje porad dotyczących wydajności.
Przypadek biznesowy analizy operacyjnej w czasie rzeczywistym
Prosty przykład używający indeksu kolumnowego nieklastrowanego
Jak program SQL Server utrzymuje indeks magazynu kolumn nieklastrowanego w obciążeniu transakcyjnym
Zminimalizowanie wpływu konserwacji nieklastrowanego indeksu magazynu kolumn przy użyciu opóźnienia kompresji
Analiza operacyjna w czasie rzeczywistym z tabelami zoptymalizowanymi pod kątem pamięci
Wideo
Seria wideo "Data Exposed" przedstawia więcej szczegółów dotyczących niektórych funkcji i zagadnień.
- Część 1. Jak usługa Azure SQL włącza analizę operacyjną w czasie rzeczywistym (HTAP)
- Część 2. Optymalizowanie istniejących baz danych i aplikacji za pomocą analizy operacyjnej
- Część 3. Jak utworzyć analizę operacyjną za pomocą funkcji okna.
Porada dotycząca wydajności nr 1: Użyj filtrowanych indeksów, aby zwiększyć wydajność zapytań
Uruchamianie analizy operacyjnej w czasie rzeczywistym może mieć wpływ na wydajność obciążenia OLTP. Ten wpływ powinien być minimalny. Przykład A pokazuje, jak używać filtrowanych indeksów w celu zminimalizowania wpływu indeksu magazynu kolumn nieklastrowanego na obciążenie transakcyjne, jednocześnie dostarczając analizy w czasie rzeczywistym.
Aby zminimalizować obciążenie związane z utrzymywaniem nieklastrowanego indeksu magazynu kolumn w obciążeniu operacyjnym, można użyć filtrowanego warunku, aby utworzyć nieklastrowany indeks magazynu kolumn tylko na ciepłych lub powoli zmieniających się danych. Na przykład w aplikacji do zarządzania zamówieniami można utworzyć nieklastrowany indeks columnstore na zamówieniach, które zostały już wysłane. Po wysłaniu zamówienia rzadko się zmienia i dlatego można je traktować jako ciepłe dane. W przypadku filtrowanego indeksu dane w nieklastrowanym indeksie magazynu kolumn wymagają ograniczonej liczby aktualizacji, co zmniejsza wpływ na obciążenie transakcyjne.
Zapytania analityczne transparentnie uzyskują dostęp do ciepłych i gorących danych, umożliwiając przeprowadzanie analizy w czasie rzeczywistym. Jeśli znaczna część obciążenia operacyjnego dotyka "gorących" danych, te operacje nie wymagają dodatkowej konserwacji indeksu kolumnowego. Najlepszym rozwiązaniem jest utworzenie indeksu klastrowanego magazynu wierszy w kolumnach używanych w definicji filtrowanego indeksu. Aparat bazy danych używa indeksu klastrowanego do szybkiego skanowania wierszy, które nie spełniają filtrowanego warunku. Bez tego klastrowanego indeksu wymagane jest pełne skanowanie tabeli magazynu wierszy w celu znalezienia tych wierszy, co może negatywnie wpłynąć na wydajność zapytań analitycznych. W przypadku braku indeksu klastrowanego można utworzyć filtrowany indeks nieklastrowanego drzewa B w celu zidentyfikowania takich wierszy, ale nie jest to zalecane, ponieważ uzyskiwanie dostępu do wielu wierszy za pośrednictwem indeksów nieklastrowanych drzewa B jest kosztowne.
Uwaga
Filtrowany indeks magazynu kolumn nieklastrowanego jest obsługiwany tylko w tabelach opartych na dyskach. Nie jest obsługiwana w tabelach zoptymalizowanych pod kątem pamięci.
Przykład A: Uzyskiwanie dostępu do gorących danych z indeksu drzewa B, ciepłe dane z indeksu magazynu kolumn
W tym przykładzie użyto filtrowanego warunku (accountkey > 0) w celu ustalenia, które wiersze znajdują się w indeksie magazynu kolumn. Celem jest zaprojektowanie filtrowanego warunku i kolejnych zapytań w celu uzyskania dostępu do często zmieniających się "gorących" danych z indeksu drzewa B+ oraz uzyskiwania dostępu do bardziej stabilnych "ciepłych" danych z indeksu magazynu kolumn.

Uwaga
Optymalizator zapytań uwzględnia, ale nie zawsze wybiera indeks magazynu kolumn dla planu zapytania. Gdy optymalizator zapytań wybierze filtrowany indeks magazynu kolumn, w sposób przezroczysty łączy wiersze zarówno z indeksu magazynu kolumn, jak i wierszy, które nie spełniają filtrowanego warunku, aby umożliwić analizę w czasie rzeczywistym. Różni się to od zwykłego nieklastrowanego indeksu filtrowanego, który może być używany tylko w zapytaniach, które ograniczają się do wierszy znajdujących się w indeksie.
-- Use a filtered condition to separate hot data in a rowstore table
-- from "warm" data in a columnstore index.
-- create the table
CREATE TABLE orders (
AccountKey int not null,
CustomerName nvarchar (50),
OrderNumber bigint,
PurchasePrice decimal (9,2),
OrderStatus smallint not null,
OrderStatusDesc nvarchar (50)
);
-- OrderStatusDesc
-- 0 => 'Order Started'
-- 1 => 'Order Closed'
-- 2 => 'Order Paid'
-- 3 => 'Order Fulfillment Wait'
-- 4 => 'Order Shipped'
-- 5 => 'Order Received'
CREATE CLUSTERED INDEX orders_ci ON orders(OrderStatus);
--Create the columnstore index with a filtered condition
CREATE NONCLUSTERED COLUMNSTORE INDEX orders_ncci ON orders (accountkey, customername, purchaseprice, orderstatus)
WHERE OrderStatus = 5;
-- The following query returns the total purchase done by customers for items > $100 .00
-- This query will pick rows both from NCCI and from 'hot' rows that are not part of NCCI
SELECT TOP (5) CustomerName, SUM(PurchasePrice)
FROM orders
WHERE PurchasePrice > 100.0
GROUP BY CustomerName;
Zapytanie analityczne jest wykonywane przy użyciu następującego planu zapytania. Możesz zauważyć, że wiersze, które nie spełniają warunku filtru, są dostępne za pośrednictwem wskaźnika B-drzewa zgrupowanego.

Aby uzyskać więcej informacji, zobacz Blog: Filtered nonclustered columnstore index (Blog: filtrowany indeks magazynu kolumn nieklastrowanych).
Porada dotycząca wydajności nr 2: Odciążanie analizy do pomocniczej funkcji Always On readable
Mimo że można zminimalizować konserwację indeksu magazynu kolumn przy użyciu filtrowanego indeksu magazynu kolumn, zapytania analityczne mogą nadal wymagać znacznych zasobów obliczeniowych (procesora CPU, operacji we/wy, pamięci), które mają wpływ na wydajność obciążenia operacyjnego. W przypadku większości obciążeń o krytycznym znaczeniu zalecamy użycie zawsze włączonej konfiguracji. W tej konfiguracji można wyeliminować wpływ uruchamiania analiz, przenosząc je na czytelną replikę.
Porada dotycząca wydajności nr 3: Zmniejszanie fragmentacji indeksu przez utrzymywanie gorących danych w delta grupach wierszy.
Tabele z indeksem kolumnowym mogą zostać znacznie pofragmentowane, jeśli obciążenie robocze aktualizuje lub usuwa wiersze, które zostały skompresowane. Fragmentowany indeks magazynu kolumnowego prowadzi do nieefektywnego wykorzystania pamięci/przechowywania. Poza nieefektywnym użyciem zasobów negatywnie wpływa również na wydajność zapytań analitycznych ze względu na dodatkowe we/wy i konieczność filtrowania usuniętych wierszy z zestawu wyników.
Usunięte wiersze nie są fizycznie usuwane do momentu uruchomienia defragmentacji indeksu za pomocą REORGANIZE polecenia lub ponownego skompilowania indeksu magazynu kolumn w całej tabeli lub partycji, których dotyczy problem. Zarówno indeks REORGANIZE , jak i REBUILD są kosztownymi operacjami, które w przeciwnym razie mogą być używane dla obciążenia. Ponadto, jeśli wiersze są kompresowane zbyt wcześnie, może być konieczne wielokrotne ponowne skompresowanie z powodu aktualizacji prowadzących do marnowania obciążenia kompresji.
Fragmentację indeksu można zminimalizować przy użyciu COMPRESSION_DELAY opcji .
-- Create a sample table
CREATE TABLE t_colstor (
accountkey int not null,
accountdescription nvarchar (50) not null,
accounttype nvarchar(50),
accountCodeAlternatekey int
);
-- Creating nonclustered columnstore index with COMPRESSION_DELAY.
-- The columnstore index will keep the rows in closed delta rowgroup
-- for 100 minutes after it has been marked closed.
CREATE NONCLUSTERED COLUMNSTORE INDEX t_colstor_cci ON t_colstor
(accountkey, accountdescription, accounttype)
WITH (DATA_COMPRESSION = COLUMNSTORE, COMPRESSION_DELAY = 100);
Aby uzyskać więcej informacji, zobacz Blog: Compression delay (Blog: Opóźnienie kompresji).
Poniżej przedstawiono zalecane najlepsze rozwiązania:
Wstawianie/wykonywanie zapytań — obciążenie: Jeśli obciążenie jest przede wszystkim wstawianiem danych i wykonywaniem względem niego zapytań, zalecaną opcją jest wartość domyślna
COMPRESSION_DELAY0. Nowo wstawione wiersze zostaną skompresowane po wstawieniu 1 miliona wierszy do pojedynczej grupy wierszy delta. Niektóre przykłady takich obciążeń to tradycyjne obciążenie dw lub analiza wybranego strumienia, gdy trzeba przeanalizować wzorzec wyboru w aplikacji internetowej.Obciążenie OLTP: Jeśli obciążenie jest DML o dużym natężeniu (czyli duża liczba operacji Aktualizuj, Usuń i Dodaj), można zauważyć fragmentację indeksu magazynu kolumn, sprawdzając dynamiczny widok zarządzania
sys.dm_db_column_store_row_group_physical_stats. Jeśli zobaczysz, że > 10% wierszy jest oznaczonych jako usunięte w ostatnio skompresowanych grupach wierszy, możesz użyćCOMPRESSION_DELAYopcji dodania opóźnienia czasowego, gdy wiersze kwalifikują się do kompresji. Jeśli w przypadku obciążenia nowo wstawiony element pozostaje gorący (czyli jest aktualizowany wielokrotnie) przez około 60 minut, należy ustawić wartośćCOMPRESSION_DELAYna 60.
Wartość domyślna COMPRESSION_DELAY opcji powinna działać dla większości klientów.
W przypadku użytkowników zaawansowanych zalecamy uruchomienie następującego zapytania i zebranie % usuniętych wierszy w ciągu ostatnich siedmiu dni.
SELECT row_group_id,
CAST(deleted_rows AS float)/CAST(total_rows AS float)*100 AS [% fragmented],
created_time
FROM sys.dm_db_column_store_row_group_physical_stats
WHERE object_id = OBJECT_ID('FactOnlineSales2')
AND state_desc = 'COMPRESSED'
AND deleted_rows > 0
AND created_time > DATEADD(day, -7, GETDATE())
ORDER BY created_time DESC;
Jeśli liczba usuniętych wierszy w skompresowanych grupach wierszy > jest mniejsza niż 20%, a liczba staje się stała w starszych grupach wierszy z odchyleniem 5% (zwanych zimnymi grupami wierszy), ustaw COMPRESSION_DELAY = (czas_utworzenia_najmłodszej_grupy_wierszy - obecny_czas). Takie podejście najlepiej sprawdza się w przypadku stabilnego i stosunkowo jednorodnego obciążenia.