Agregacje automatyczne
Automatyczne agregacje używają najnowocześniejszego uczenia maszynowego (ML) do ciągłego optymalizowania modeli semantycznych DirectQuery w celu uzyskania maksymalnej wydajności zapytań w raporcie. Automatyczne agregacje są oparte na istniejącej infrastrukturze agregacji zdefiniowanej przez użytkownika po raz pierwszy wprowadzonej z modelami złożonymi dla usługi Power BI. W przeciwieństwie do agregacji zdefiniowanych przez użytkownika automatyczne agregacje nie wymagają rozbudowanych umiejętności modelowania danych i optymalizacji zapytań w celu konfigurowania i konserwacji. Agregacje automatyczne są zarówno samodzielne trenowanie, jak i samo optymalizowanie. Umożliwiają właścicielom modeli dowolny poziom umiejętności, aby poprawić wydajność zapytań, zapewniając szybsze wizualizacje raportów dla dużych modeli.
Za pomocą agregacji automatycznych:
- Wizualizacje raportów są szybsze — optymalny procent zapytań raportów jest zwracany przez automatycznie utrzymywaną pamięć podręczną agregacji w pamięci zamiast systemów źródeł danych zaplecza. Zapytania odstające, które nie są zwracane przez pamięć podręczną, są przekazywane bezpośrednio do źródła danych przy użyciu trybu DirectQuery.
- Zrównoważona architektura — w porównaniu do czystego trybu DirectQuery większość wyników zapytań jest zwracana przez aparat zapytań usługi Power BI i pamięć podręczną agregacji w pamięci. Obciążenie przetwarzania zapytań w systemach źródeł danych w godzinach szczytu raportowania może zostać znacznie zmniejszone, co oznacza zwiększenie skalowalności zaplecza źródła danych.
- Łatwa konfiguracja — właściciele modeli mogą włączyć automatyczne trenowanie agregacji i zaplanować co najmniej jedno odświeżenie modelu. Po pierwszym trenowaniu i odświeżaniu automatyczne agregacje zaczynają tworzyć platformę agregacji i optymalne agregacje. System automatycznie dostraja się w czasie.
- Dostrajanie — za pomocą prostego i intuicyjnego interfejsu użytkownika w ustawieniach modelu można oszacować wzrost wydajności dla innego procentu zapytań zwracanych z pamięci podręcznej agregacji w pamięci i wprowadzić korekty w celu uzyskania jeszcze większych zysków. Kontrolka pojedynczego paska slajdów ułatwia dostosowanie środowiska.
Wymagania
Obsługiwane plany
Automatyczne agregacje są obsługiwane w przypadku usługi Power BI Premium dla pojemności, Premium na użytkownika i modeli usługi Power BI Embedded.
Obsługiwane źródła danych
Automatyczne agregacje są obsługiwane dla następujących źródeł danych:
- Azure SQL Database
- Dedykowana pula SQL usługi Azure Synapse
- SQL Server 2019 lub nowszy
- Google BigQuery
- Snowflake
- Databricks
- Amazon Redshift
Obsługiwane tryby
Automatyczne agregacje są obsługiwane w przypadku modeli trybu DirectQuery. Obsługiwane są modele modelu złożonego z tabelami importu i połączeniami DirectQuery. Automatyczne agregacje są obsługiwane tylko w przypadku połączenia DirectQuery.
Uprawnienia
Aby włączyć i skonfigurować automatyczne agregacje, musisz być właścicielem modelu. Administratorzy obszaru roboczego mogą przejąć rolę właściciela w celu skonfigurowania ustawień agregacji automatycznych.
Konfigurowanie agregacji automatycznych
Agregacje automatyczne są konfigurowane w Ustawienia modelu. Konfigurowanie jest proste — włącz trenowanie agregacji automatycznych i zaplanuj co najmniej jedno odświeżanie. Przed skonfigurowaniem automatycznych agregacji dla modelu pamiętaj, aby całkowicie przeczytać ten artykuł. Zapewnia dobre zrozumienie sposobu działania agregacji automatycznych i może pomóc w podjęciu decyzji, czy automatyczne agregacje są odpowiednie dla danego środowiska. Gdy wszystko będzie gotowe do instrukcji krok po kroku dotyczących włączania trenowania agregacji automatycznych, konfigurowania harmonogramu odświeżania i dostosowywania środowiska, zobacz Konfigurowanie agregacji automatycznych.
Świadczenia
W trybie DirectQuery za każdym razem, gdy użytkownik modelu otworzy raport lub wchodzi w interakcję z wizualizacją raportu, zapytania języka DAX (Data Analysis Expressions) są przekazywane do aparatu zapytań, a następnie do źródła danych zaplecza jako zapytania SQL. Źródło danych musi obliczyć i zwrócić wyniki dla każdego zapytania. W porównaniu z modelami trybu importu przechowywanymi w pamięci, runda źródła danych DirectQuery może być zarówno czasochłonna, jak i intensywnie przetwarzana, co często powoduje powolne czasy odpowiedzi zapytań w wizualizacjach raportu.
Po włączeniu modelu DirectQuery automatyczne agregacje mogą zwiększyć wydajność zapytań raportu, unikając rund zapytań źródła danych. Wstępnie zagregowane wyniki zapytania są automatycznie zwracane przez pamięć podręczną agregacji w pamięci, a nie wysyłane do źródła danych i zwracane przez nie. Ilość wstępnie zagregowanych danych w pamięci podręcznej agregacji w pamięci to niewielki ułamek ilości danych przechowywanych w rzeczywistości i tabelach szczegółów w źródle danych. Wynik nie jest tylko lepszą wydajnością zapytań raportów, ale także zmniejszonym obciążeniem systemów źródeł danych zaplecza. W przypadku agregacji automatycznych tylko niewielka część raportów i zapytań ad hoc, które wymagają agregacji nieuwzględnianych w pamięci podręcznej, są przekazywane do źródła danych zaplecza, podobnie jak w przypadku zwykłego trybu DirectQuery.
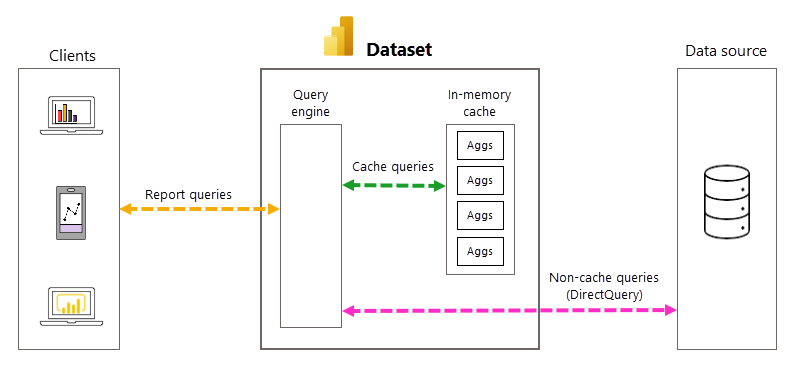
Automatyczne zarządzanie zapytaniami i agregacjami
Chociaż automatyczne agregacje eliminują konieczność tworzenia tabel agregacji zdefiniowanych przez użytkownika i znacznie upraszczają implementowanie wstępnie zagregowanego rozwiązania danych, głębsza znajomość podstawowych procesów i zależności jest pomocna w zrozumieniu sposobu działania agregacji automatycznych. Usługa Power BI opiera się na następujących elementach, aby tworzyć agregacje automatyczne i zarządzać nimi.
Dziennik zapytań
Usługa Power BI śledzi zapytania dotyczące modelu i raportów użytkowników w dzienniku zapytań. W przypadku każdego modelu usługa Power BI przechowuje siedem dni danych dziennika zapytań. Dane dziennika zapytań są przekazywane każdego dnia. Dziennik zapytań jest bezpieczny i niewidoczny dla użytkowników lub za pośrednictwem punktu końcowego XMLA.
Operacje trenowania
W ramach pierwszej zaplanowanej operacji odświeżania modelu dla wybranej częstotliwości (dzień lub tydzień) usługa Power BI najpierw inicjuje operację trenowania, która ocenia dziennik zapytań, aby zapewnić agregacje w pamięci podręcznej agregacji w pamięci dostosowane do zmieniających się wzorców zapytań. Tabele agregacji w pamięci są tworzone, aktualizowane lub porzucane, a zapytania specjalne są wysyłane do źródła danych w celu określenia agregacji, które mają być uwzględnione w pamięci podręcznej. Obliczone dane agregacji nie są jednak ładowane do pamięci podręcznej w pamięci podczas trenowania — są ładowane podczas kolejnej operacji odświeżania.
Jeśli na przykład wybierzesz częstotliwość dzień i harmonogram odświeża się o godzinie 4:00, 9:00, 2:00 i 19:00, tylko odświeżanie o godzinie 4:00 każdego dnia będzie obejmować zarówno operację trenowania, jak i operację odświeżania. Kolejne 9:00, 2:00 i 19:00 zaplanowane odświeżenia dla tego dnia są tylko operacjami odświeżania, które aktualizują istniejące agregacje w pamięci podręcznej.
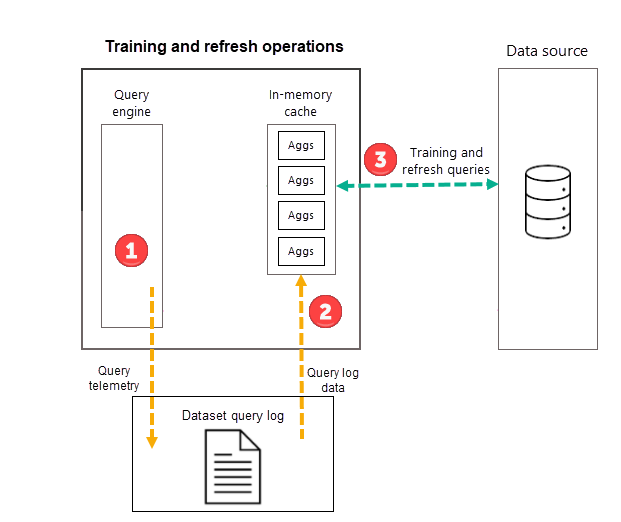
Podczas gdy operacje trenowania oceniają wcześniejsze zapytania z dziennika zapytań, wyniki są wystarczająco dokładne, aby zapewnić, że przyszłe zapytania są objęte. Nie ma jednak gwarancji, że przyszłe zapytania będą zwracane przez pamięć podręczną agregacji w pamięci, ponieważ te nowe zapytania mogą być inne niż te pochodzące z dziennika zapytań. Te zapytania, które nie są zwracane przez pamięć podręczną agregacji w pamięci, są przekazywane do źródła danych przy użyciu trybu DirectQuery. W zależności od częstotliwości i klasyfikacji tych nowych zapytań agregacje mogą być uwzględniane w pamięci podręcznej agregacji w pamięci przy następnej operacji trenowania.
Operacja trenowania ma 60-minutowy limit czasu. Jeśli trenowanie nie może przetworzyć całego dziennika zapytań w limicie czasu, zostanie zarejestrowane powiadomienie w historii odświeżania modelu i wznawia trenowanie przy następnym uruchomieniu. Cykl trenowania kończy się i zastępuje istniejące automatyczne agregacje po przetworzeniu całego dziennika zapytań.
Operacje odświeżania
Jak opisano wcześniej, po zakończeniu operacji trenowania w ramach pierwszego zaplanowanego odświeżania dla wybranej częstotliwości usługa Power BI wykonuje operację odświeżania, która wysyła zapytania i ładuje nowe i zaktualizowane dane agregacji do pamięci podręcznej agregacji w pamięci i usuwa wszelkie agregacje, które nie są już wystarczająco wysokie (zgodnie z algorytmem trenowania). Wszystkie kolejne odświeżenia dla wybranej częstotliwości Dzień lub Tydzień to tylko operacje odświeżania, które wysyłają zapytanie do źródła danych w celu zaktualizowania istniejących danych agregacji w pamięci podręcznej. Korzystając z naszego poprzedniego przykładu, zaplanowane odświeżenia 9:00, 2:00 i 19:00 zaplanowane odświeżenia dla tego dnia są operacjami tylko odświeżania.
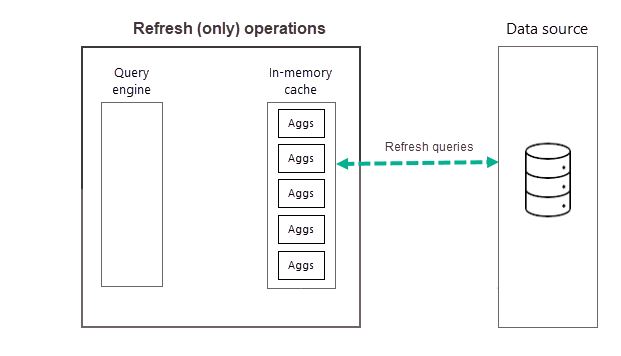
Regularne zaplanowane odświeżanie przez cały dzień (lub tydzień) zapewnia, że dane agregacji w pamięci podręcznej są bardziej aktualne z danymi w źródle danych zaplecza. Za pomocą Ustawienia modelu można zaplanować maksymalnie 48 odświeżeń dziennie, aby upewnić się, że zapytania raportów zwracane przez pamięć podręczną agregacji uzyskują wyniki na podstawie najnowszych odświeżonych danych ze źródła danych zaplecza.
Uwaga
Operacje trenowania i odświeżania są procesami i intensywnymi zasobami zarówno dla usługa Power BI, jak i systemów źródła danych. Zwiększenie wartości procentowej zapytań korzystających z agregacji oznacza, że więcej agregacji musi być odpytywane i obliczane na podstawie źródeł danych podczas operacji trenowania i odświeżania, zwiększając prawdopodobieństwo nadmiernego użycia zasobów systemowych i potencjalnie powodując przekroczenie limitu czasu. Aby dowiedzieć się więcej, zobacz Dostosowywanie grzywny.
Szkolenie na żądanie
Jak wspomniano wcześniej, cykl trenowania może nie zostać ukończony w ramach limitów czasu pojedynczego cyklu odświeżania danych. Jeśli nie chcesz czekać do następnego zaplanowanego cyklu odświeżania, który obejmuje trenowanie, możesz również wyzwolić automatyczne trenowanie agregacji na żądanie, wybierając pozycję Trenuj i Odśwież teraz w modelu Ustawienia. Przy użyciu polecenia Train and Refresh Now wyzwala zarówno operację trenowania, jak i operację odświeżania. Sprawdź historię odświeżania modelu, aby sprawdzić, czy bieżąca operacja została zakończona przed uruchomieniem innej operacji trenowania i odświeżania na żądanie, jeśli jest to konieczne.
Historia odświeżania
Każda operacja odświeżania jest rejestrowana w historii odświeżania modelu. Zostaną wyświetlone ważne informacje o każdym odświeżeniu, w tym liczba agregacji pamięci w pamięci podręcznej zużywanych przez skonfigurowaną wartość procentową zapytania. Aby wyświetlić historię odświeżania, na stronie Ustawienia modelu wybierz pozycję Historia odświeżania. Jeśli chcesz przejść do szczegółów, wybierz pozycję Pokaż szczegóły.
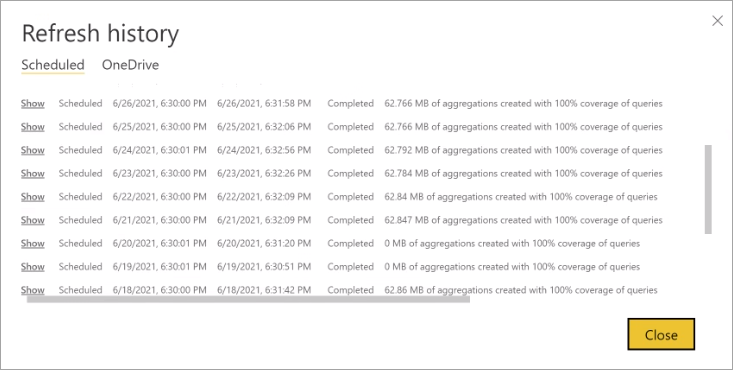
Regularnie sprawdzając historię odświeżania, możesz upewnić się, że zaplanowane operacje odświeżania są wykonywane w akceptowalnym okresie. Przed rozpoczęciem następnego zaplanowanego odświeżania upewnij się, że operacje odświeżania zostały wykonane pomyślnie.
Niepowodzenia trenowania i odświeżania
Podczas gdy usługa Power BI wykonuje operacje trenowania i odświeżania w ramach pierwszego zaplanowanego odświeżania wybranej częstotliwości dnia lub tygodnia, te operacje są implementowane jako oddzielne transakcje. Jeśli operacja trenowania nie może w pełni przetworzyć dziennika zapytań w ramach limitów czasu, usługa Power BI będzie kontynuować odświeżanie istniejących agregacji (i zwykłych tabel w modelu złożonym) przy użyciu poprzedniego stanu trenowania. W takim przypadku historia odświeżania będzie wskazywać, że odświeżanie zakończyło się pomyślnie, a szkolenie wznowi przetwarzanie dziennika zapytań przy następnym uruchomieniu trenowania. Wydajność zapytań może być mniej zoptymalizowana, jeśli wzorce zapytań raportu klienta uległy zmianie, a agregacje nie uległy jeszcze zmianie, ale osiągnięty poziom wydajności powinien być jeszcze znacznie lepszy niż czysty model DirectQuery bez żadnych agregacji.
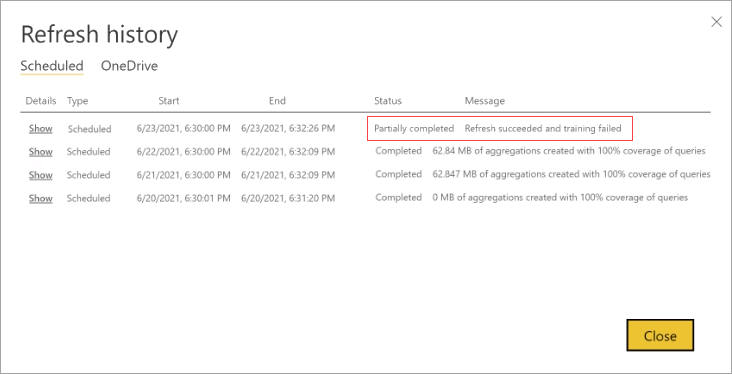
Jeśli operacja trenowania wymaga zbyt wielu cykli do zakończenia przetwarzania dziennika zapytań, rozważ zmniejszenie procentu zapytań korzystających z pamięci podręcznej agregacji w pamięci w modelu Ustawienia. Spowoduje to zmniejszenie liczby agregacji utworzonych w pamięci podręcznej, ale pozwoli więcej czasu na ukończenie operacji trenowania i odświeżania. Aby dowiedzieć się więcej, zobacz Dostosowywanie grzywny.
Jeśli trenowanie zakończy się pomyślnie, ale odświeżanie zakończy się niepowodzeniem, całe odświeżanie zostanie oznaczone jako Niepowodzenie, ponieważ wynik jest niedostępną pamięcią podręczną agregacji w pamięci.
Podczas planowania odświeżania można określić powiadomienia e-mail, jeśli występują błędy odświeżania.
Agregacje zdefiniowane przez użytkownika i automatyczne
Agregacje zdefiniowane przez użytkownika w usłudze Power BI można skonfigurować ręcznie na podstawie ukrytych zagregowanych tabel w modelu. Konfigurowanie agregacji zdefiniowanych przez użytkownika jest często złożone, co wymaga większego poziomu umiejętności modelowania danych i optymalizacji zapytań. Z drugiej strony automatyczne agregacje eliminują tę złożoność w ramach systemu opartego na sztucznej inteligencji. W przeciwieństwie do agregacji zdefiniowanych przez użytkownika, które pozostają statyczne, usługa Power BI stale utrzymuje dzienniki zapytań i z tych dzienników określa wzorce zapytań oparte na algorytmach modelowania predykcyjnego uczenia maszynowego (ML). Wstępnie zagregowane dane są obliczane i przechowywane w pamięci na podstawie analizy wzorca zapytania. W przypadku agregacji automatycznych modele są zarówno samotrenowane, jak i samo optymalizowanie. W miarę zmiany wzorców zapytań raportów klienta automatyczne agregacje są dostosowywane, priorytetyzacja i buforowanie tych agregacji używanych najczęściej.
Ponieważ agregacje automatyczne są oparte na istniejącej infrastrukturze agregacji zdefiniowanej przez użytkownika, można używać zarówno agregacji zdefiniowanych przez użytkownika, jak i automatycznych agregacji w tym samym modelu. Wykwalifikowani modelujący dane mogą definiować agregacje dla tabel przy użyciu trybu DirectQuery, Importuj (z odświeżaniem przyrostowym lub bez) lub Tryby przechowywania podwójnego, a jednocześnie mają zalety bardziej automatycznych agregacji dla zapytań za pośrednictwem połączeń DirectQuery, które nie trafiają do tabel agregacji zdefiniowanych przez użytkownika. Ta elastyczność umożliwia zrównoważone architektury, które mogą zmniejszyć obciążenia zapytań i uniknąć wąskich gardeł.
Agregacje utworzone w pamięci podręcznej przez algorytm trenowania agregacji automatycznych są identyfikowane jako System agregacje. Algorytm trenowania tworzy i usuwa tylko te System agregacje, ponieważ zapytania raportowania są analizowane, a dostosowania są wykonywane w celu utrzymania optymalnych agregacji dla modelu. Zarówno zdefiniowane przez użytkownika, jak i automatyczne agregacje są odświeżane za pomocą odświeżania. Tylko te agregacje utworzone przez agregacje automatyczne i oznaczone jako agregacje generowane przez system są uwzględniane w automatycznym przetwarzaniu agregacji.
Buforowanie zapytań i automatyczne agregacje
Usługa Power BI Premium obsługuje również buforowanie zapytań w usłudze Power BI Premium/Embedded w celu zachowania wyników zapytań. Buforowanie zapytań jest inną funkcją niż automatyczne agregacje. W przypadku buforowania zapytań usługa Power BI Premium używa lokalnej usługi buforowania do implementowania buforowania, natomiast automatyczne agregacje są implementowane na poziomie modelu. W przypadku buforowania zapytań usługa buforuje tylko zapytania dotyczące początkowego ładowania strony raportu, dlatego wydajność zapytań nie jest poprawiana, gdy użytkownicy wchodzą w interakcję z raportem. Natomiast automatyczne agregacje optymalizują większość zapytań raportów przez wstępne buforowanie zagregowanych wyników zapytań, w tym zapytania generowane podczas interakcji użytkowników z raportami. Buforowanie zapytań i automatyczne agregacje można włączyć dla modelu, ale prawdopodobnie nie jest to konieczne.
Monitorowanie za pomocą usługi Azure Log Analytics
Azure Log Analytics (LA) to usługa w usłudze Azure Monitor, której usługa Power BI może używać do zapisywania dzienników aktywności. Pakiet usługi Azure Monitor umożliwia zbieranie, analizowanie i wykonywanie działań dotyczących danych telemetrycznych z platformy Azure i środowisk lokalnych. Oferuje ona magazyn długoterminowy, interfejs zapytań ad hoc i dostęp do interfejsu API w celu umożliwienia eksportowania i integracji danych z innymi systemami. Aby dowiedzieć się więcej, zobacz Korzystanie z usługi Azure Log Analytics w usłudze Power BI.
Jeśli usługa Power BI jest skonfigurowana przy użyciu konta usługi Azure LA, zgodnie z opisem w temacie Konfigurowanie usługi Azure Log Analytics dla usługi Power BI, możesz przeanalizować współczynnik powodzenia automatycznych agregacji. Między innymi można określić, czy zapytania raportów są odbierane z pamięci podręcznej w pamięci.
Aby użyć tej możliwości, pobierz szablon PBIT i połącz go z kontem usługi Log Analytics, zgodnie z opisem w tym wpisie w blogu usługi Power BI. W raporcie można wyświetlać dane na trzech różnych poziomach: widok podsumowania, widok poziomu zapytania języka DAX i widok na poziomie zapytania SQL.
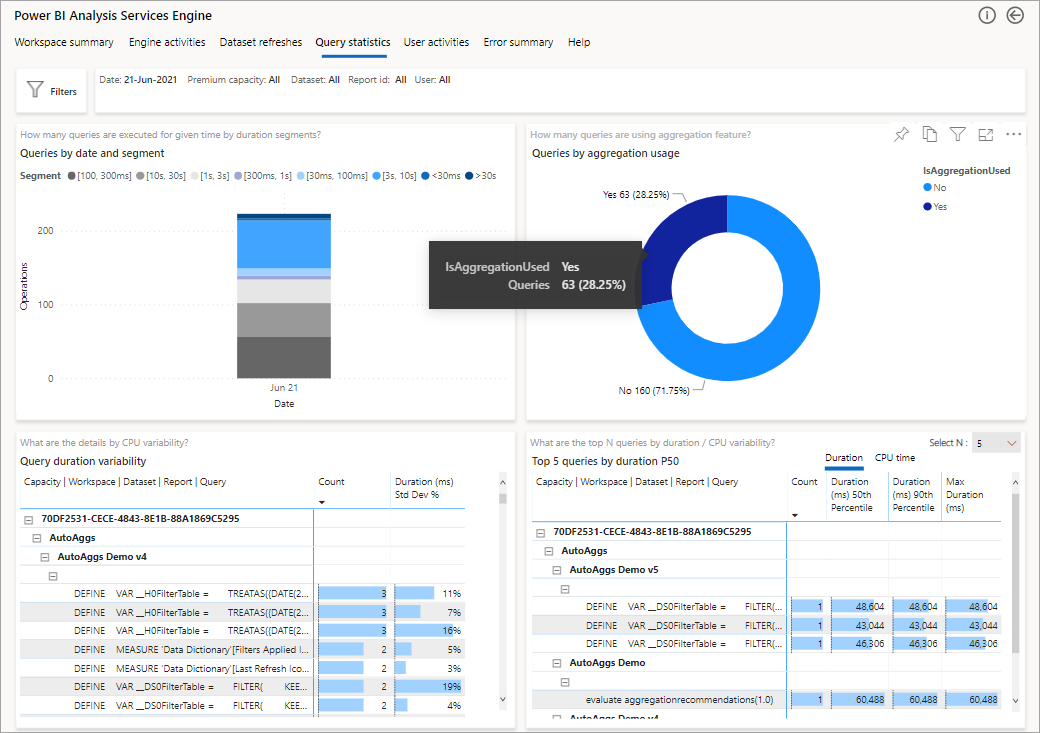
Na poniższej ilustracji przedstawiono stronę podsumowania dla wszystkich zapytań. Jak widać, oznaczony wykres przedstawia procent całkowitych zapytań, które zostały spełnione przez agregacje, a te, które musiały korzystać ze źródła danych.
Następnym krokiem do dokładniejszego zapoznania się jest zapoznanie się z użyciem agregacji na poziomie zapytania języka DAX. Kliknij prawym przyciskiem myszy zapytanie języka DAX z listy (w lewym dolnym rogu) >Przeglądanie szczegółowe historii> zapytań.
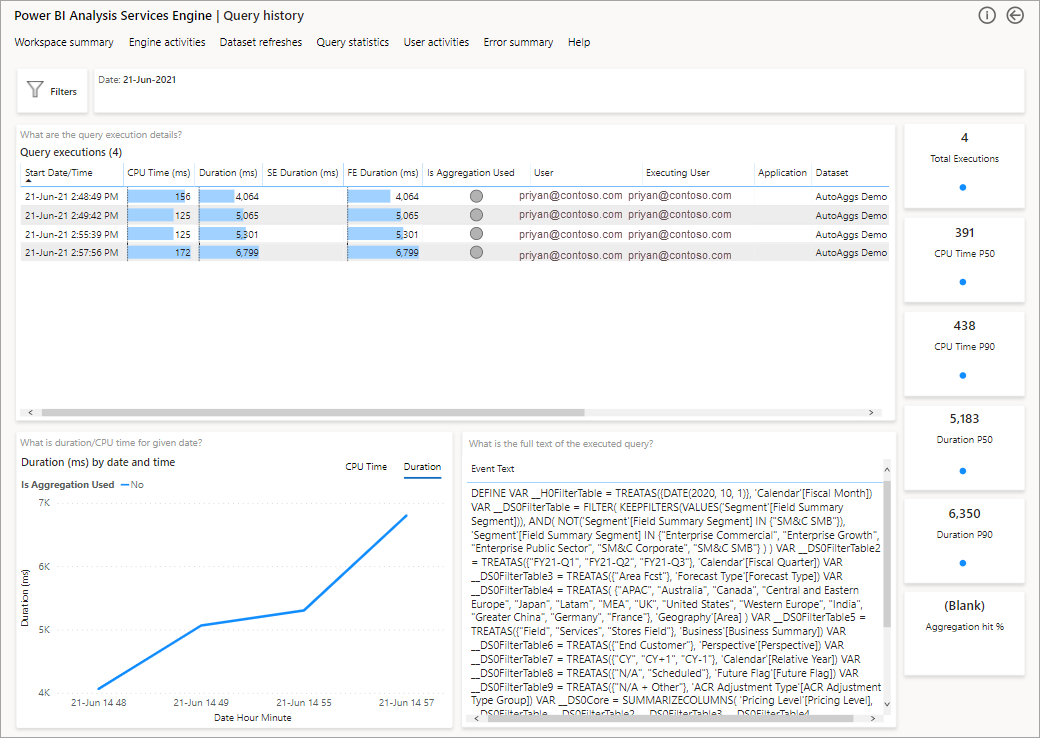
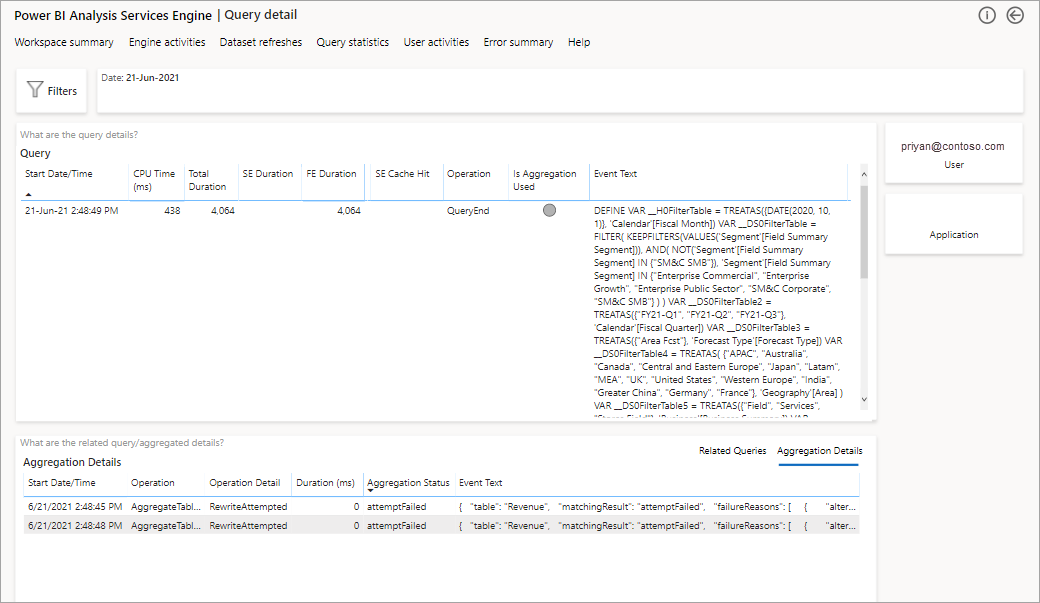
Spowoduje to wyświetlenie listy wszystkich odpowiednich zapytań. Przejdź do następnego poziomu, aby wyświetlić więcej szczegółów agregacji.
Zarządzanie cyklem życia aplikacji
Od programowania do testowania i testowania do środowiska produkcyjnego modele z włączonymi automatycznymi agregacjami mają specjalne wymagania dotyczące rozwiązań ALM.
Potoki wdrażania
W przypadku potoków wdrażania usługa Power BI może skopiować modele z konfiguracją modelu z bieżącego etapu do etapu docelowego. Jednak automatyczne agregacje muszą być resetowane na etapie docelowym, ponieważ ustawienia nie są przenoszone z bieżącego do etapu docelowego. Zawartość można również wdrożyć programowo przy użyciu interfejsów API REST potoków wdrażania. Aby dowiedzieć się więcej na temat tego procesu, zobacz Automatyzowanie potoku wdrażania przy użyciu interfejsów API i metodyki DevOps.
Niestandardowe rozwiązania ALM
Jeśli używasz niestandardowego rozwiązania ALM opartego na punktach końcowych XMLA, pamiętaj, że rozwiązanie może być w stanie skopiować tabele agregacji generowane przez system i utworzone przez użytkownika w ramach metadanych modelu. Jednak po każdym kroku wdrażania na etapie docelowym należy włączyć automatyczne agregacje. Usługa Power BI zachowa konfigurację, jeśli zastąpisz istniejący model.
Uwaga
Jeśli przekażesz lub ponownie opublikujesz model w ramach pliku programu Power BI Desktop (pbix), tabele agregacji utworzone przez system zostaną utracone, ponieważ usługa Power BI zastąpi istniejący model wszystkimi jego metadanymi i danymi w docelowym obszarze roboczym.
Zmienianie modelu
Po zmianie modelu z automatycznymi agregacjami włączonymi za pośrednictwem punktów końcowych XMLA, takich jak dodawanie lub usuwanie tabel, usługa Power BI zachowuje wszelkie istniejące agregacje, które mogą być i usuwa te, które nie są już potrzebne lub istotne. Może to mieć wpływ na wydajność zapytań do momentu wyzwolenia następnej fazy trenowania.
Elementy metadanych
Modele z włączonymi agregacjami automatycznymi zawierają unikatowe tabele agregacji generowane przez system. Tabele agregacji nie są widoczne dla użytkowników w narzędziach raportowania. Są one widoczne za pośrednictwem punktu końcowego XMLA przy użyciu narzędzi z bibliotekami klienta usług Analysis Services w wersji 19.22.5 lub nowszej. Podczas pracy z modelami z włączonymi automatycznymi agregacjami pamiętaj o uaktualnieniu narzędzi do modelowania danych i narzędzi administracyjnych do najnowszej wersji bibliotek klienckich. W przypadku programu SQL Server Management Studio (SSMS) uaktualnij program do programu SSMS w wersji 18.9.2 lub nowszej. Wcześniejsze wersje programu SSMS nie mogą wyliczać tabel ani tworzyć skryptów dla tych modeli.
Tabele agregacji automatycznych są identyfikowane przez SystemManaged właściwość tabeli, która jest nowa dla tabelarycznego modelu obiektów (TOM) w bibliotekach klienta usług Analysis Services w wersji 19.22.5 lub nowszej. Poniższy fragment kodu przedstawia właściwość ustawioną SystemManaged na true dla tabel agregacji automatycznych i false dla zwykłych tabel.
using System;
using System.Collections.Generic;
using System.Linq;
using Microsoft.AnalysisServices.Tabular;
namespace AutoAggs
{
class Program
{
static void Main(string[] args)
{
string workspaceUri = "<Specify the URL of the workspace where your model resides>";
string datasetName = "<Specify the name of your dataset>";
Server sourceWorkspace = new Server();
sourceWorkspace.Connect(workspaceUri);
Database dataset = sourceWorkspace.Databases.GetByName(datasetName);
// Enumerate system-managed tables.
IEnumerable<Table> aggregationsTables = dataset.Model.Tables.Where(tbl => tbl.SystemManaged == true);
if (aggregationsTables.Any())
{
Console.WriteLine("The following auto aggs tables exist in this dataset:");
foreach (Table table in aggregationsTables)
{
Console.WriteLine($"\t{table.Name}");
}
}
else
{
Console.WriteLine($"This dataset has no auto aggs tables.");
}
Console.WriteLine("\n\rPress [Enter] to exit the sample app...");
Console.ReadLine();
}
}
}
Wykonanie tego fragmentu kodu wyprowadza automatyczne tabele agregacji, które są obecnie uwzględnione w modelu w konsoli.
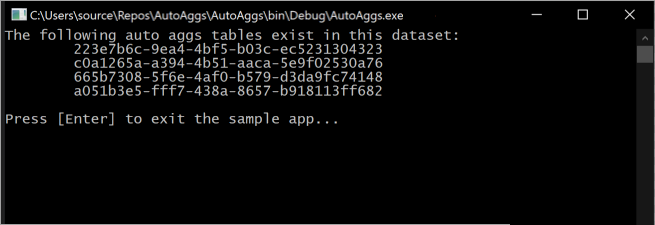
Pamiętaj, że tabele agregacji stale się zmieniają, ponieważ operacje trenowania określają optymalne agregacje, które mają być uwzględniane w pamięci podręcznej agregacji w pamięci.
Ważne
Usługa Power BI w pełni zarządza automatycznymi agregacjami wygenerowanymi przez system obiektów tabeli. Nie usuwaj ani nie modyfikuj tych tabel samodzielnie. Może to spowodować obniżoną wydajność.
Usługa Power BI utrzymuje konfigurację modelu poza modelem. Obecność tabeli agregacji zarządzanych przez system w modelu niekoniecznie oznacza, że model jest w rzeczywistości włączony na potrzeby trenowania agregacji automatycznych. Innymi słowy, jeśli utworzysz pełną definicję modelu dla modelu z włączonymi automatycznymi agregacjami i utworzysz nową kopię modelu (z inną nazwą/obszarem roboczym/pojemnością), nowy wynikowy model nie jest włączony na potrzeby trenowania automatycznych agregacji. Nadal musisz włączyć trenowanie agregacji automatycznych dla nowego modelu w Ustawienia modelu.
Rozważania i ograniczenia
Podczas korzystania z agregacji automatycznych należy pamiętać o następujących kwestiach:
- Agregacje nie obsługują dynamicznych parametrów zapytania języka M.
- Zapytania SQL generowane podczas początkowej fazy trenowania mogą generować znaczne obciążenie magazynu danych. Jeśli szkolenie będzie nadal niekompletne i możesz sprawdzić po stronie magazynu danych, że zapytania napotykają przekroczenie limitu czasu, rozważ tymczasowe skalowanie magazynu danych w celu spełnienia wymagań szkoleniowych.
- Agregacje przechowywane w pamięci podręcznej agregacji w pamięci mogą nie być obliczane na podstawie najnowszych danych w źródle danych. W przeciwieństwie do zwykłego trybu DirectQuery i podobnie jak zwykłe tabele importu, istnieje opóźnienie między aktualizacjami w źródle danych a danymi agregacji przechowywanymi w pamięci podręcznej agregacji w pamięci. Mimo że zawsze wystąpi pewne opóźnienie, można temu zapobiec za pomocą efektywnego harmonogramu odświeżania.
- Aby jeszcze bardziej zoptymalizować wydajność, ustaw wszystkie tabele wymiarów na Tryb podwójny i pozostaw tabele faktów w trybie DirectQuery.
- Automatyczne agregacje nie są dostępne w usługach Power BI Pro, Azure Analysis Services ani SQL Server Analysis Services.
- Usługa Power BI nie obsługuje pobierania modeli z włączonymi automatycznymi agregacjami. Jeśli przekazano lub opublikowano plik programu Power BI Desktop (pbix) do usługi Power BI, a następnie włączono automatyczne agregacje, nie można już pobrać pliku PBIX. Upewnij się, że kopia pliku PBIX jest przechowywana lokalnie.
- Automatyczne agregacje z tabelami zewnętrznymi w usłudze Azure Synapse Analytics nie są obsługiwane. Tabele zewnętrzne można wyliczyć w usłudze Synapse przy użyciu następującego zapytania SQL:
SELECT SCHEMA_NAME(schema_id) AS schema_name, name AS table_name FROM sys.external_tables. - Automatyczne agregacje są dostępne tylko dla modeli przy użyciu rozszerzonych metadanych. Jeśli chcesz włączyć automatyczne agregacje dla starszego modelu, najpierw uaktualnij model do rozszerzonych metadanych. Aby dowiedzieć się więcej, zobacz Używanie rozszerzonych metadanych modelu.
- Nie włączaj agregacji automatycznych, jeśli źródło danych DirectQuery jest skonfigurowane do logowania jednokrotnego i używa dynamicznych widoków danych lub mechanizmów kontroli zabezpieczeń w celu ograniczenia danych, do których użytkownik może uzyskać dostęp. Automatyczne agregacje nie są świadome tych mechanizmów kontroli na poziomie źródła danych, co uniemożliwia zapewnienie prawidłowych danych na podstawie poszczególnych użytkowników. Szkolenie zarejestruje ostrzeżenie w historii odświeżania, że wykryło źródło danych skonfigurowane do logowania jednokrotnego i pominąło tabele korzystające z tego źródła danych. Jeśli to możliwe, wyłącz logowanie jednokrotne dla tych źródeł danych, aby w pełni wykorzystać zoptymalizowaną wydajność zapytań, które mogą zapewnić automatyczne agregacje.
- Nie włączaj agregacji automatycznych, jeśli model zawiera tylko tabele hybrydowe, aby uniknąć niepotrzebnych obciążeń związanych z przetwarzaniem. Tabela hybrydowa używa zarówno partycji importu, jak i partycji DirectQuery. Typowym scenariuszem jest odświeżanie przyrostowe z danymi w czasie rzeczywistym, w których partycja DirectQuery pobiera transakcje ze źródła danych, które wystąpiły po ostatnim odświeżeniu danych. Jednak usługa Power BI importuje agregacje podczas odświeżania. Agregacje automatyczne nie mogą zawierać transakcji, które wystąpiły po ostatnim odświeżeniu danych. Trenowanie spowoduje zarejestrowanie ostrzeżenia w historii odświeżania, które wykryło i pominięto tabele hybrydowe.
- Kolumny obliczeniowe nie są brane pod uwagę w przypadku agregacji automatycznych. Jeśli używasz kolumny obliczeniowej w trybie DirectQuery, na przykład przy użyciu
COMBINEVALUESfunkcji języka DAX, aby utworzyć relację opartą na wielu kolumnach z dwóch tabel DirectQuery, odpowiednie zapytania raportu nie trafią do pamięci podręcznej agregacji w pamięci. - Agregacje automatyczne są dostępne tylko w usługa Power BI. Program Power BI Desktop nie tworzy tabel agregacji generowanych przez system.
- Jeśli zmodyfikujesz metadane modelu z włączonymi automatycznymi agregacjami, wydajność zapytań może obniżyć się do momentu wyzwolenia następnego procesu trenowania. Najlepszym rozwiązaniem jest usunięcie agregacji automatycznych, wprowadzenie zmian, a następnie ponowne trenowanie.
- Nie modyfikuj ani nie usuwaj tabel agregacji generowanych przez system, chyba że masz wyłączone automatyczne agregacje i czyścisz model. System ponosi odpowiedzialność za zarządzanie tymi obiektami.
Społeczność
Usługa Power BI ma żywą społeczność, w której specjaliści MVP, specjaliści bi i rówieśnicy dzielą się wiedzą w grupach dyskusyjnych, filmach wideo, blogach i nie tylko. Podczas poznawania automatycznych agregacji należy zapoznać się z innymi zasobami: