Samouczek: konfigurowanie bazy danych dbt dla magazynu danych sieci szkieletowej
Dotyczy:✅ Magazyn w usłudze Microsoft Fabric
Ten samouczek przeprowadzi Cię przez proces konfigurowania bazy danych dbt i wdrażania pierwszego projektu w magazynie sieci szkieletowej.
Wprowadzenie
Struktura open source dbt (Data Build Tool) upraszcza przekształcanie danych i inżynierię analiz. Koncentruje się on na przekształceniach opartych na języku SQL w warstwie analizy, traktując język SQL jako kod. Usługa dbt obsługuje kontrolę wersji, modułyzację, testowanie i dokumentację.
Adapter dbt dla usługi Microsoft Fabric może służyć do tworzenia projektów dbt, które następnie można wdrożyć w magazynie danych sieci szkieletowej.
Możesz również zmienić platformę docelową projektu dbt, zmieniając na przykład kartę. Projekt utworzony dla dedykowanej puli SQL usługi Azure Synapse można uaktualnić w ciągu kilku sekund do magazynu danych sieci szkieletowej.
Wymagania wstępne dotyczące adaptera dbt dla usługi Microsoft Fabric
Postępuj zgodnie z tą listą, aby zainstalować i skonfigurować wymagania wstępne bazy danych:
Najnowsza wersja karty dbt-fabric z repozytorium PyPI (Python Package Index) przy użyciu polecenia
pip install dbt-fabric.pip install dbt-fabricUwaga
pip install dbt-fabricZmieniając wartość napip install dbt-synapsei korzystając z poniższych instrukcji, możesz zainstalować kartę dbt dla dedykowanej puli SQL usługi Synapse.Upewnij się, że funkcja dbt-fabric i jej zależności są zainstalowane przy użyciu
pip listpolecenia :pip listDługa lista pakietów i bieżących wersji powinna zostać zwrócona z tego polecenia.
Jeśli jeszcze go nie masz, utwórz magazyn. W tym ćwiczeniu możesz użyć pojemności próbnej: utwórz bezpłatną wersję próbną usługi Microsoft Fabric, utwórz obszar roboczy, a następnie utwórz magazyn.
Wprowadzenie do karty dbt-fabric
W tym samouczku jest używany program Visual Studio Code, ale możesz użyć wybranego preferowanego narzędzia.
Sklonuj projekt demonstracyjny dbt jaffle_shop na maszynę.
- Repozytorium można sklonować za pomocą wbudowanej kontroli źródła programu Visual Studio Code.
- Możesz na przykład użyć
git clonepolecenia :
git clone https://github.com/dbt-labs/jaffle_shop.gitjaffle_shopOtwórz folder projektu w programie Visual Studio Code.
Jeśli utworzono już magazyn, możesz pominąć rejestrację.
Utwórz plik
profiles.yml. Dodaj następującą konfigurację doprofiles.yml. Ten plik konfiguruje połączenie z magazynem w usłudze Microsoft Fabric przy użyciu karty dbt-fabric.config: partial_parse: true jaffle_shop: target: fabric-dev outputs: fabric-dev: authentication: CLI database: <put the database name here> driver: ODBC Driver 18 for SQL Server host: <enter your SQL analytics endpoint here> schema: dbo threads: 4 type: fabricUwaga
typeW razie potrzeby zmień wartość zfabricsynapsena , aby przełączyć kartę bazy danych na usługę Azure Synapse Analytics. Dowolna istniejąca platforma danych projektu dbt może zostać zaktualizowana przez zmianę karty bazy danych. Aby uzyskać więcej informacji, zobacz listę obsługiwanych platform danych dbt.Uwierzytelnij się na platformie Azure w terminalu programu Visual Studio Code.
- Uruchom polecenie
az loginw terminalu programu Visual Studio Code, jeśli używasz uwierzytelniania interfejsu wiersza polecenia platformy Azure. - W przypadku uwierzytelniania jednostki usługi lub innego identyfikatora entra firmy Microsoft (dawniej Azure Active Directory) w usłudze Microsoft Fabric zapoznaj się z tematem dbt (Data Build Tool) setup and dbt Resource Configurations (Konfiguracja zasobów dbt). Aby uzyskać więcej informacji, zobacz Microsoft Entra authentication as an alternative to SQL authentication in Microsoft Fabric (Uwierzytelnianie entra firmy Microsoft jako alternatywa dla uwierzytelniania SQL w usłudze Microsoft Fabric).
- Uruchom polecenie
Teraz możesz przetestować łączność. Aby przetestować łączność z magazynem, uruchom polecenie
dbt debugw terminalu programu Visual Studio Code.dbt debug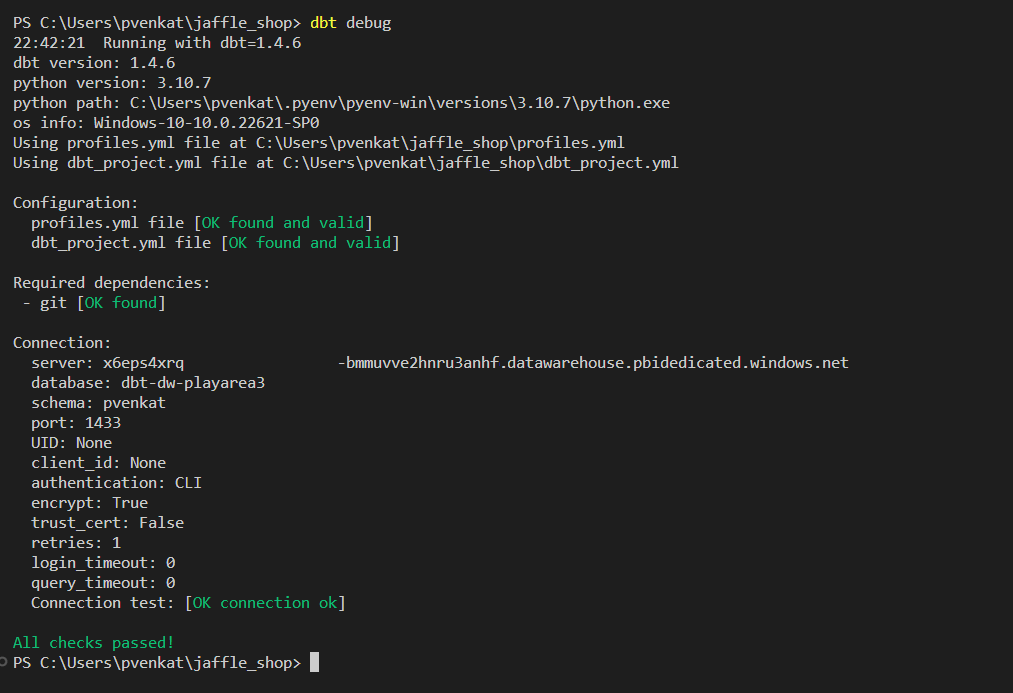
Wszystkie testy są przekazywane, co oznacza, że można połączyć magazyn przy użyciu karty dbt-fabric z
jaffle_shopprojektu dbt.Teraz nadszedł czas, aby sprawdzić, czy karta działa, czy nie. Najpierw uruchom polecenie
dbt seed, aby wstawić przykładowe dane do magazynu.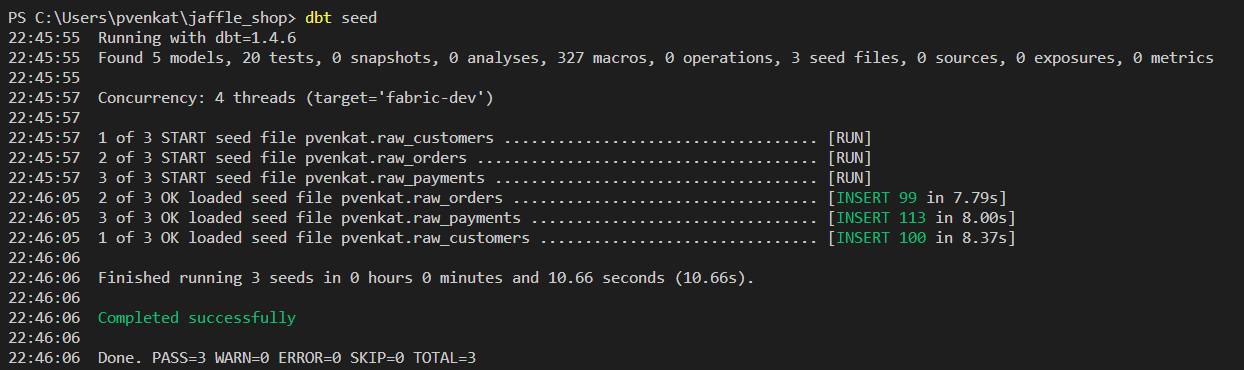
Uruchom polecenie
dbt run, aby zweryfikować dane względem niektórych testów.dbt run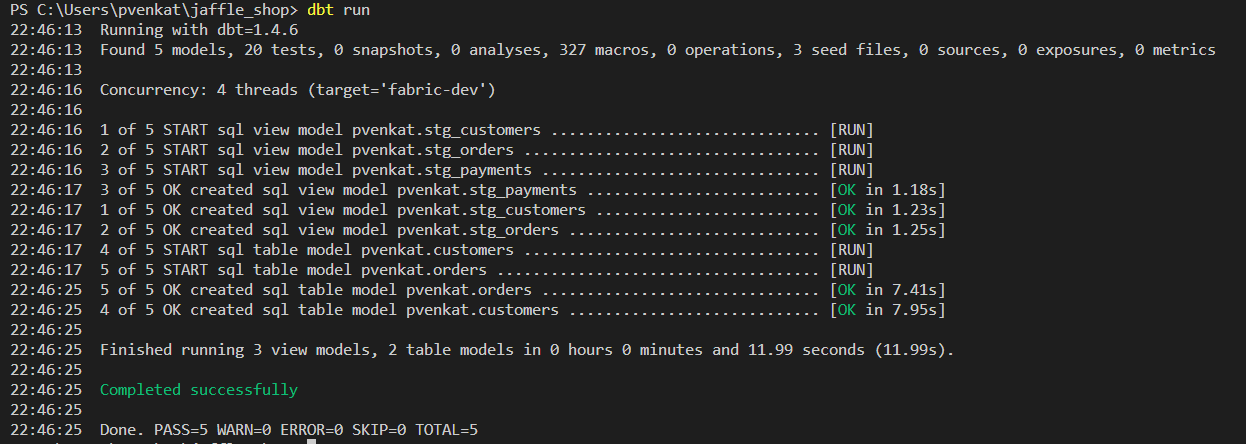
Uruchom polecenie
dbt test, aby uruchomić modele zdefiniowane w projekcie demo dbt.dbt test




Projekt dbt został wdrożony w magazynie danych sieci szkieletowej.
Przenoszenie między różnymi magazynami
Proste przenoszenie projektu dbt między różnymi magazynami. Projekt dbt w dowolnym obsługiwanym magazynie można szybko migrować przy użyciu tego trzyetapowego procesu:
Zainstaluj nową kartę. Aby uzyskać więcej informacji i pełne instrukcje instalacji, zobacz dbt adaptery.
typeZaktualizuj właściwość wprofiles.ymlpliku.Skompiluj projekt.
dbt w usłudze Fabric Data Factory
W przypadku integracji z platformą Apache Airflow popularny system zarządzania przepływami pracy dbt staje się zaawansowanym narzędziem do organizowania przekształceń danych. Funkcje planowania i zarządzania zadaniami airflow umożliwiają zespołom danych automatyzowanie przebiegów dbt. Zapewnia regularne aktualizacje danych i utrzymuje spójny przepływ danych wysokiej jakości na potrzeby analizy i raportowania. To połączone podejście, wykorzystując wiedzę na temat transformacji dbt z zarządzaniem przepływami pracy firmy Airflow, zapewnia wydajne i niezawodne potoki danych, co ostatecznie prowadzi do szybszych i bardziej szczegółowych decyzji opartych na danych.
Apache Airflow to platforma typu open source używana do programowego tworzenia, planowania i monitorowania złożonych przepływów pracy danych. Umożliwia zdefiniowanie zestawu zadań nazywanych operatorami, które można połączyć w skierowane grafy acykliczne (DAG) do reprezentowania potoków danych.
Aby uzyskać więcej informacji na temat operacjonalizacji bazy danych w magazynie, zobacz Przekształcanie danych przy użyciu bazy danych za pomocą usługi Data Factory w usłudze Microsoft Fabric.
Kwestie wymagające rozważenia
Ważne kwestie, które należy wziąć pod uwagę podczas korzystania z adaptera dbt-fabric:
Przejrzyj bieżące ograniczenia dotyczące magazynowania danych w usłudze Microsoft Fabric.
Sieć szkieletowa obsługuje uwierzytelnianie microsoft Entra ID (dawniej Azure Active Directory) dla podmiotów zabezpieczeń użytkowników, tożsamości użytkowników i jednostek usługi. Zalecanym trybem uwierzytelniania do interaktywnej pracy w magazynie jest interfejs wiersza polecenia (interfejsy wiersza polecenia) i używanie jednostek usługi do automatyzacji.
Przejrzyj polecenia języka T-SQL (Transact-SQL) nieobsługiwane w usłudze Fabric Data Warehouse.
Niektóre polecenia języka T-SQL są obsługiwane przez kartę dbt-fabric przy użyciu
Create Table as Select(CTAS),DROPiCREATEpoleceń, takich jakALTER TABLE ADD/ALTER/DROP COLUMN,MERGE,TRUNCATE, ,sp_rename.Przejrzyj nieobsługiwane typy danych, aby dowiedzieć się więcej o obsługiwanych i nieobsługiwanych typach danych.
Problemy z kartą dbt-fabric w usłudze GitHub można rejestrować, odwiedzając stronę Problemy · microsoft/dbt-fabric · GitHub.